Вступление
Любое приложение или веб-сайт, которые видят значительный рост, в конечном итоге должны будут масштабироваться, чтобы учесть увеличение трафика. Для приложений и веб-сайтов, управляемых данными, очень важно, чтобы масштабирование выполнялось таким образом, чтобы обеспечить безопасность и целостность их данных. Может быть трудно предсказать, насколько популярным станет веб-сайт или приложение или как долго он будет поддерживать эту популярность, поэтому некоторые организации выбирают архитектуру базы данных, которая позволяет им динамически масштабировать свои базы данных.
В этой концептуальной статье мы обсудим одну такую архитектуру базы данных:sharded databases. В последние годы шардингу уделяется много внимания, но многие не имеют четкого понимания того, что это такое, или сценариев, в которых может иметь смысл ограждать базу данных. Мы рассмотрим, что такое шардинг, некоторые из его основных преимуществ и недостатков, а также несколько общих методов шардинга.
Что такое шардинг?
Шардинг - это шаблон архитектуры базы данных, связанный сhorizontal partitioning - практикой разделения строк одной таблицы на несколько разных таблиц, известных как разделы. Каждый раздел имеет одинаковую схему и столбцы, но также и совершенно разные строки. Аналогично, данные, хранящиеся в каждом, уникальны и не зависят от данных, хранящихся в других разделах.
Может быть полезно подумать о горизонтальном разбиении с точки зрения того, как оно соотносится сvertical partitioning. В таблице с вертикальным разделением целые столбцы разделяются и помещаются в новые отдельные таблицы. Данные, содержащиеся в одном вертикальном разделе, не зависят от данных всех остальных, и каждый из них содержит как отдельные строки, так и столбцы. Следующая диаграмма иллюстрирует, как можно разделить таблицу по горизонтали и вертикали:
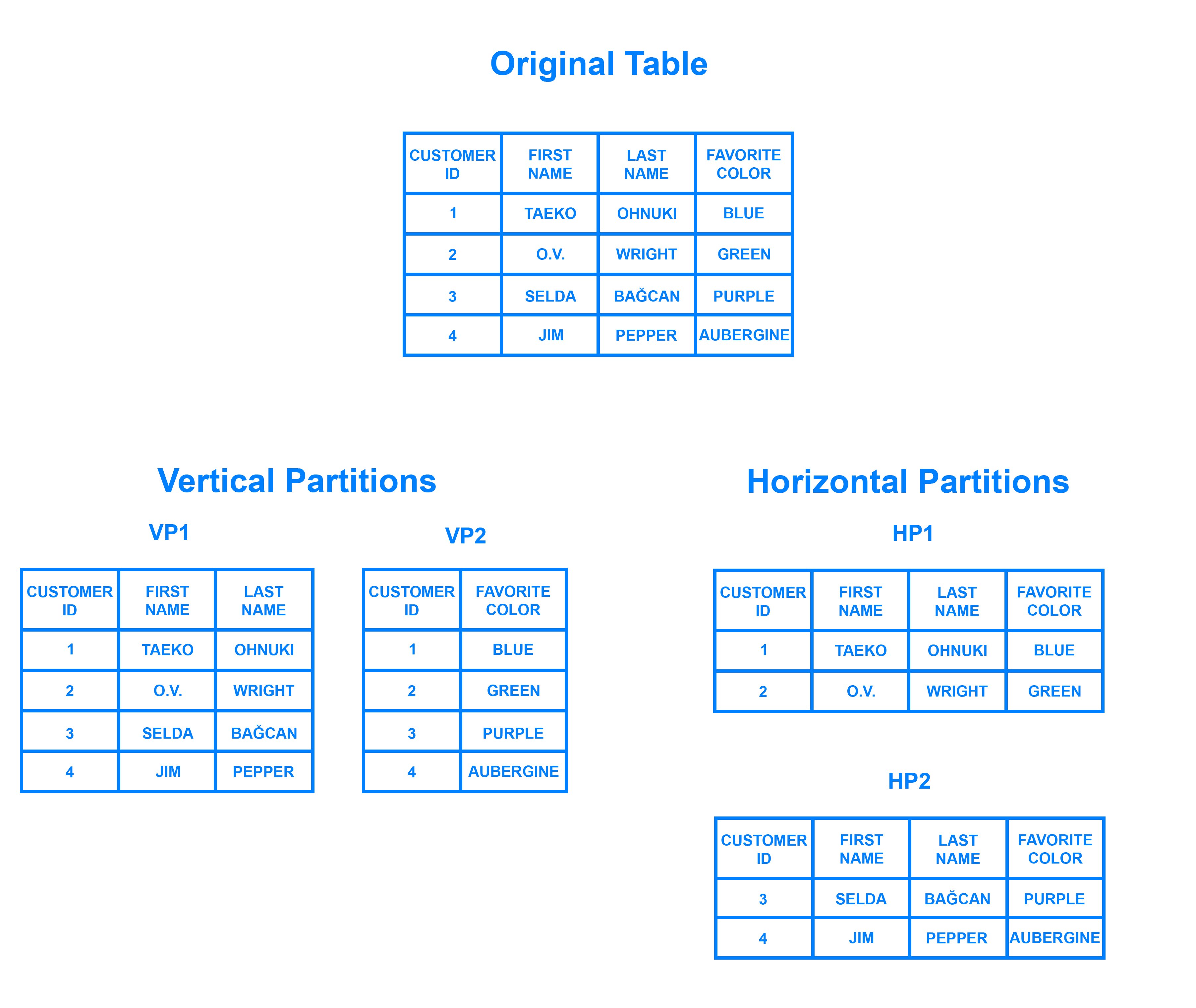
Шардинг предполагает разбиение данных на два или более небольших фрагмента, называемыхlogical shards. Затем логические сегменты распределяются по отдельным узлам базы данных, называемымphysical shards, которые могут содержать несколько логических сегментов. Несмотря на это, данные, хранящиеся во всех шардах, представляют собой целый набор логических данных.
Осколки базы данных представляют собойshared-nothing architecture. Это означает, что осколки автономны; они не используют одни и те же данные или вычислительные ресурсы. Однако в некоторых случаях имеет смысл скопировать определенные таблицы в каждый шард, чтобы они служили справочными таблицами. Например, предположим, что есть база данных для приложения, которая зависит от фиксированных коэффициентов пересчета для измерения веса. Реплицируя таблицу, содержащую необходимые данные о коэффициенте конверсии, в каждый шард, это поможет гарантировать, что все данные, необходимые для запросов, хранятся в каждом шарде.
Часто сегментирование реализуется на уровне приложения, что означает, что приложение включает в себя код, который определяет, какой сегмент передавать на чтение и запись. Тем не менее, некоторые системы управления базами данных имеют встроенные возможности шардинга, что позволяет вам применять шардинг непосредственно на уровне базы данных.
Учитывая этот общий обзор шардинга, давайте рассмотрим некоторые плюсы и минусы, связанные с этой архитектурой базы данных.
Преимущества шардинга
Основная привлекательность сегментирования базы данных заключается в том, что он может помочь облегчитьhorizontal scaling, также известный какscaling out. Горизонтальное масштабирование - это практика добавления большего количества машин к существующему стеку, чтобы распределить нагрузку и обеспечить больший трафик и более быструю обработку. Это часто противопоставляетсяvertical scaling, иначе известному какscaling up, который включает в себя обновление оборудования существующего сервера, обычно путем добавления дополнительной оперативной памяти или процессора.
Относительно просто иметь реляционную базу данных, работающую на одной машине, и масштабировать ее по мере необходимости, обновляя ее вычислительные ресурсы. В конечном счете, однако, любая нераспределенная база данных будет ограничена с точки зрения хранения и вычислительной мощности, поэтому свобода масштабирования по горизонтали делает вашу установку гораздо более гибкой.
Другой причиной, по которой некоторые могут выбрать архитектуру изолированной базы данных, является ускорение времени ответа на запрос. Когда вы отправляете запрос к базе данных, которая не была очищена, ему, возможно, придется искать каждую строку в таблице, к которой вы обращаетесь, прежде чем он сможет найти набор результатов, который вы ищете. Для приложения с большой монолитной базой данных запросы могут стать чрезмерно медленными. Однако, разделяя одну таблицу на несколько, запросы должны проходить через меньшее количество строк, и их результирующие наборы возвращаются намного быстрее.
Разделение может также помочь сделать приложение более надежным за счет смягчения последствий отключений. Если ваше приложение или веб-сайт опирается на незащищенную базу данных, сбой может привести к недоступности всего приложения. Однако при использовании защищенной базы данных отключение может повлиять только на один фрагмент. Даже при том, что это может сделать некоторые части приложения или веб-сайта недоступными для некоторых пользователей, общее воздействие все равно будет меньше, чем в случае сбоя всей базы данных.
Недостатки шардинга
Хотя ограждение базы данных может облегчить масштабирование и повысить производительность, оно также может накладывать определенные ограничения. Здесь мы обсудим некоторые из них и почему они могут быть причинами, чтобы вообще не использовать шардинг.
Первая трудность, с которой люди сталкиваются при использовании шардинга, - это сложность правильной реализации архитектуры сегментированной базы данных. Если все сделано неправильно, существует значительный риск того, что процесс разделения может привести к потере данных или повреждению таблиц. Тем не менее, даже если все сделано правильно, разделение может оказать значительное влияние на рабочие процессы вашей команды. Вместо того чтобы обращаться к своим данным и управлять ими из единой точки входа, пользователи должны управлять данными в нескольких местах сегментов, что потенциально может помешать работе некоторых групп.
Одна проблема, с которой пользователи иногда сталкиваются после разделения базы данных, заключается в том, что фрагменты в конечном итоге становятся несбалансированными. Например, предположим, у вас есть база данных с двумя отдельными сегментами: одна для клиентов, чьи фамилии начинаются с букв от A до M, а другая для тех, чьи имена начинаются с букв от N до Z. Однако ваше заявление обслуживает чрезмерное количество людей, чьи фамилии начинаются с буквы G. Соответственно, в сегменте A-M постепенно накапливается больше данных, чем в сегменте N-Z, в результате чего приложение замедляется и блокируется для значительной части ваших пользователей. Осколок A-M стал известен какdatabase hotspot. В этом случае любые преимущества шардинга базы данных сводятся на нет замедлениями и сбоями. Скорее всего, базу данных необходимо будет отремонтировать и перенастроить, чтобы обеспечить более равномерное распределение данных.
Другим существенным недостатком является то, что после того, как база данных была очищена, может быть очень трудно вернуть ее к неохраняемой архитектуре. Любые резервные копии базы данных, сделанные до ее обработки, не будут содержать данные, записанные после разбиения. Следовательно, для восстановления исходной неохраняемой архитектуры потребуется объединить новые многораздельные данные со старыми резервными копиями или, наоборот, преобразовать многораздельные БД обратно в одну БД, что потребует больших затрат и времени.
Последний недостаток, который следует учитывать, заключается в том, что разделение не поддерживается изначально каждым механизмом базы данных. Например, PostgreSQL не включает автоматическое разбиение как функцию, хотя есть возможность вручную разделить базу данных PostgreSQL. Существует ряд форков Postgres, которые включают автоматическое разбиение, но они часто отстают от последнего выпуска PostgreSQL и не имеют определенных других функций. Некоторые специализированные технологии баз данных, такие как MySQL Cluster или некоторые продукты базы данных как услуга, такие как MongoDB Atlas, действительно включают в себя функцию автоматического разделения, но ванильные версии этих систем управления базами данных этого не делают. Из-за этого шардинг часто требует подхода «покатись сам». Это означает, что зачастую трудно найти документацию по шардингу или советы по устранению неполадок.
Это, конечно, только некоторые общие вопросы, которые необходимо рассмотреть перед тем, как разбирать их на части. В зависимости от варианта использования может быть гораздо больше потенциальных недостатков для разделения базы данных.
Теперь, когда мы рассмотрели некоторые недостатки и преимущества шардинга, мы рассмотрим несколько различных архитектур для сегментированных баз данных.
Sharding Architecture
После того, как вы решили огородить свою базу данных, вам нужно выяснить, как вы будете поступать так. При выполнении запросов или рассылке входящих данных в сегментированные таблицы или базы данных очень важно, чтобы они передавались в правильный сегмент. В противном случае это может привести к потере данных или мучительно медленным запросам. В этом разделе мы рассмотрим несколько распространенных архитектур шардинга, каждая из которых использует немного другой процесс для распределения данных между шардами.
Основанный на ключе Sharding
Key based sharding, также известный какhash based sharding, предполагает использование значения, взятого из вновь записанных данных, таких как идентификационный номер клиента, IP-адрес клиентского приложения, почтовый индекс и т. д. - и подключив его кhash function, чтобы определить, в какой сегмент должны идти данные. Хеш-функция - это функция, которая принимает на входе часть данных (например, электронную почту клиента) и выводит дискретное значение, известное какhash value. В случае шардинга значение хэша - это идентификатор шарда, используемый для определения, на каком шарде будут храниться входящие данные. В целом процесс выглядит так:

Чтобы обеспечить правильное размещение записей в правильных сегментах, все значения, введенные в хэш-функцию, должны поступать из одного столбца. Этот столбец известен какshard key. Проще говоря, ключи сегментов похожи наprimary keys, поскольку оба являются столбцами, которые используются для определения уникального идентификатора для отдельных строк. Вообще говоря, ключ шарда должен быть статическим, то есть он не должен содержать значений, которые могут меняться со временем. В противном случае это увеличит объем работы, выполняемой операциями обновления, и может снизить производительность.
Хотя основанное на ключах разбиение является довольно распространенной архитектурой разбиения, оно может усложнить задачу при динамическом добавлении или удалении дополнительных серверов в базе данных. Когда вы добавляете серверы, каждому из них потребуется соответствующее значение хеш-функции, и многие из ваших существующих записей, если не все, необходимо будет переназначить на новое, правильное значение хеш-функции, а затем перенести на соответствующий сервер. Когда вы начнете перебалансировать данные, ни новые, ни старые хеширующие функции не будут действительны. Следовательно, ваш сервер не сможет записывать какие-либо новые данные во время миграции, и ваше приложение может быть подвержено простою.
Основная привлекательность этой стратегии заключается в том, что ее можно использовать для равномерного распределения данных с целью предотвращения горячих точек. Кроме того, поскольку он распределяет данные алгоритмически, нет необходимости поддерживать карту расположения всех данных, как это необходимо для других стратегий, таких как разделение на основе диапазона или каталога.
Sharding на основе диапазона
Range based sharding включает данные сегментирования на основе диапазонов заданного значения. Для иллюстрации, скажем, у вас есть база данных, в которой хранится информация обо всех продуктах в каталоге продавца. Вы можете создать несколько разных осколков и разделить информацию о каждом продукте в зависимости от ценового диапазона, в который они попадают, например:

Основное преимущество шардинга на основе диапазона заключается в том, что его относительно просто реализовать. Каждый шард содержит различный набор данных, но все они имеют идентичную схему, а также исходную базу данных. Код приложения просто читает, в какой диапазон попадают данные, и записывает их в соответствующий фрагмент.
С другой стороны, сегментирование на основе диапазона не защищает данные от неравномерного распределения, что приводит к вышеупомянутым «горячим точкам» базы данных. Если посмотреть на диаграмму примера, даже если каждый шард содержит одинаковое количество данных, существует вероятность того, что конкретным продуктам будет уделено больше внимания, чем другим. Их соответствующие осколки, в свою очередь, получат непропорциональное количество операций чтения.
Шардинг на основе каталогов
Чтобы реализоватьdirectory based sharding, необходимо создать и поддерживатьlookup table, который использует ключ осколка, чтобы отслеживать, какой осколок содержит какие данные. В двух словах, таблица поиска - это таблица, которая содержит статический набор информации о том, где можно найти конкретные данные. Следующая диаграмма показывает упрощенный пример шардинга на основе каталогов:
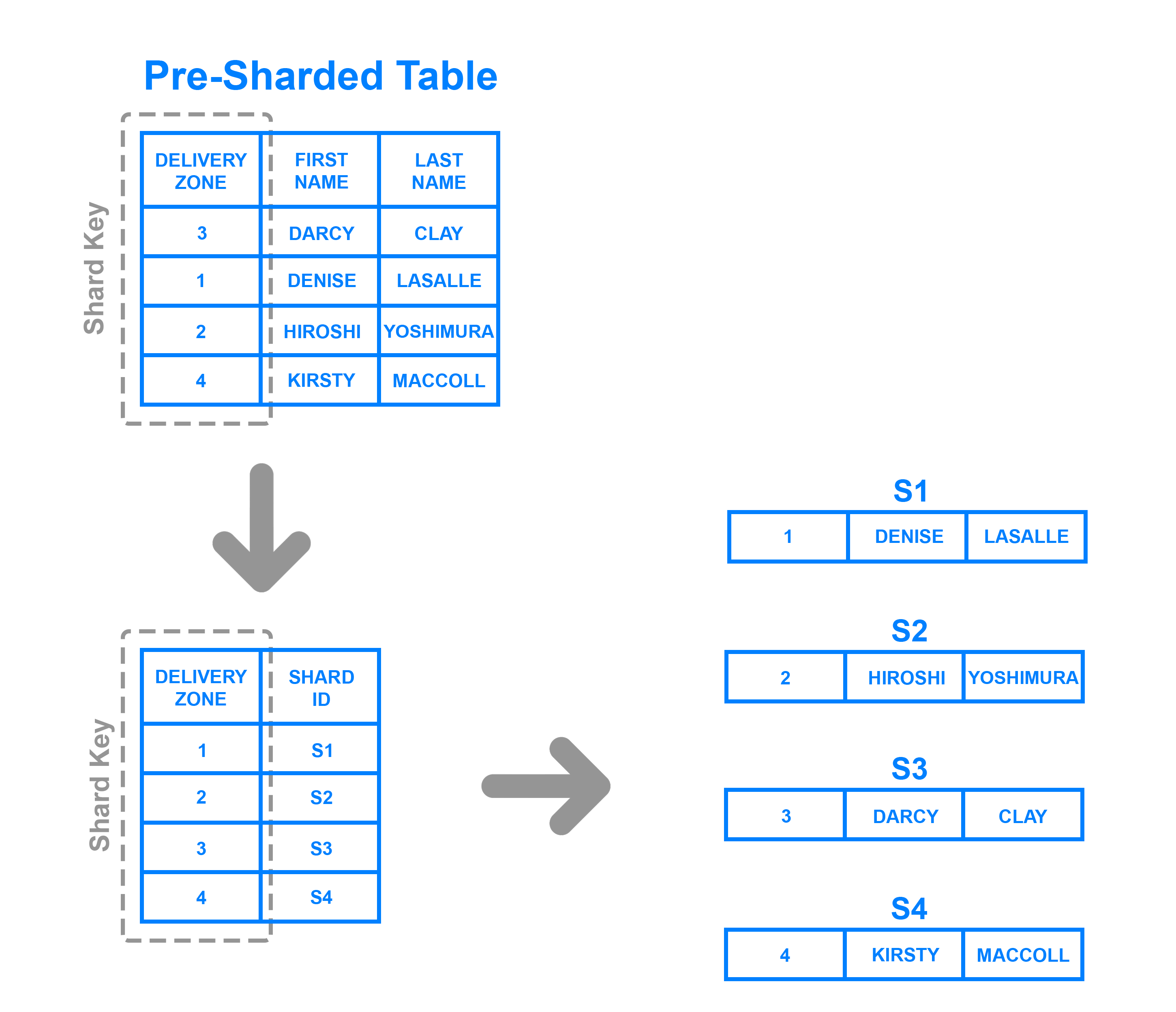
Здесь столбецDelivery Zone определяется как ключ осколка. Данные от ключа шарда записываются в таблицу поиска вместе с любым шардом, в который должна быть записана каждая соответствующая строка. Это похоже на сегментирование на основе диапазона, но вместо определения того, в какой диапазон попадают данные ключа сегмента, каждый ключ привязывается к своему определенному фрагменту. Разделение на основе каталогов является хорошим выбором по сравнению с разделением на основе диапазона в случаях, когда ключ сегмента имеет низкую мощность, и для сегмента не имеет смысла хранить диапазон ключей. Обратите внимание, что он также отличается от шардинга на основе ключей тем, что он не обрабатывает ключ шарда с помощью хэш-функции; он просто проверяет ключ по таблице соответствия, чтобы увидеть, куда должны быть записаны данные.
Основная привлекательность шардинга на основе каталогов - это его гибкость. Архитектуры сегментирования на основе диапазонов ограничивают вас указанием диапазонов значений, тогда как архитектуры на основе ключей ограничивают вас использованием фиксированной хеш-функции, которую, как упоминалось ранее, впоследствии может быть чрезвычайно трудно изменить. Разделение на основе каталогов, с другой стороны, позволяет вам использовать любую систему или алгоритм, который вы хотите назначить для ввода данных в сегменты, и сравнительно легко динамически добавлять фрагменты с помощью этого подхода.
В то время как разделение на основе каталогов является наиболее гибким из рассмотренных здесь методов разделения, необходимость подключения к таблице соответствия перед каждым запросом или записью может отрицательно сказаться на производительности приложения. Кроме того, таблица поиска может стать единой точкой отказа: если она повреждена или иным образом выходит из строя, это может повлиять на способность записывать новые данные или получать доступ к их существующим данным.
Должен ли я осколок?
Вопрос о том, следует ли реализовывать архитектуру сегментированных баз данных, почти всегда является предметом споров. Некоторые рассматривают разделение как неизбежный результат для баз данных, которые достигают определенного размера, в то время как другие рассматривают его как головную боль, которую следует избегать, если только это не является абсолютно необходимым, из-за сложности операций, которую добавляет разделение.
Из-за этой дополнительной сложности разбиение обычно выполняется только при работе с очень большими объемами данных. Вот несколько распространенных сценариев, в которых может быть полезно разделить базу данных:
-
Объем данных приложения увеличивается, чтобы превысить емкость хранилища одного узла базы данных.
-
Объем операций записи или чтения в базу данных превосходит возможности отдельного узла или его реплик чтения, что приводит к замедлению времени отклика или превышению времени ожидания.
-
Пропускная способность сети, требуемая приложением, превышает пропускную способность, доступную для одного узла базы данных и любых реплик чтения, что приводит к замедлению времени отклика или тайм-аутам.
Перед разделением, вы должны исчерпать все другие возможности для оптимизации вашей базы данных. Некоторые оптимизации, которые вы можете рассмотреть, включают:
-
Setting up a remote database. Если вы работаете с монолитным приложением, в котором все его компоненты находятся на одном сервере, вы можете повысить производительность своей базы данных, перенеся ее на свой компьютер. Это не добавляет такой сложности, как сегментирование, поскольку таблицы базы данных остаются нетронутыми. Тем не менее, он по-прежнему позволяет вам вертикальное масштабирование вашей базы данных отдельно от остальной части вашей инфраструктуры.
-
Implementing caching. Если производительность чтения вашего приложения вызывает у вас проблемы, кэширование - это одна из стратегий, которая может помочь улучшить ее. Кэширование включает временное хранение данных, которые уже были запрошены в памяти, что позволяет вам гораздо быстрее получить к ним доступ в дальнейшем.
-
Creating one or more read replicas. Другая стратегия, которая может помочь улучшить производительность чтения, включает копирование данных с одного сервера базы данных (primary server) на один или несколькоsecondary servers. После этого каждая новая запись передается первичному серверу, а затем копируется во вторичные, а чтения производятся исключительно на вторичные серверы. Распределение операций чтения и записи таким образом предотвращает слишком большую нагрузку на любую машину, предотвращая замедления и сбои. Обратите внимание, что создание реплик чтения требует больше вычислительных ресурсов и, следовательно, стоит больше денег, что может быть существенным ограничением для некоторых.
-
Upgrading to a larger server. В большинстве случаев масштабирование сервера базы данных до компьютера с большим количеством ресурсов требует меньших усилий, чем шардинг. Как и при создании реплик чтения, обновленный сервер с большим количеством ресурсов, вероятно, будет стоить больше денег. Соответственно, вам следует выполнять изменение размера только в том случае, если оно действительно окажется вашим лучшим вариантом.
Имейте в виду, что если ваше приложение или веб-сайт дойдут до определенного уровня, ни одна из этих стратегий не будет достаточной для повышения производительности самостоятельно. В таких случаях шардинг действительно может быть лучшим вариантом для вас.
Заключение
Sharding может быть отличным решением для тех, кто хочет масштабировать свою базу данных по горизонтали. Тем не менее, это также добавляет большую сложность и создает больше потенциальных точек сбоя для вашего приложения. Разделение может быть необходимо для некоторых, но время и ресурсы, необходимые для создания и поддержки изолированной архитектуры, могут перевесить преимущества для других.
Прочитав эту концептуальную статью, вы должны иметь более четкое представление о плюсах и минусах шардинга. Продвигаясь вперед, вы можете использовать эту информацию, чтобы принять более обоснованное решение о том, подходит ли архитектура сегментированных баз данных для вашего приложения.