Программирование сокетов в Python (Руководство)
Сокеты и API сокетов используются для отправки сообщений по сети. Они предоставляют форму inter-process communication (IPC). Сеть может представлять собой логическую локальную сеть с компьютером или физически подключенную к внешней сети с собственными подключениями к другим сетям. Очевидным примером является Интернет, к которому вы подключаетесь через своего интернет-провайдера.
Этот учебник имеет три разных итерации построения сокет-сервера и клиента с Python:
-
Мы начнем учебник с рассмотрения простого сокет-сервера и клиента.
-
После того, как вы увидели API и то, как все работает в этом первоначальном примере, мы рассмотрим улучшенную версию, которая обрабатывает несколько соединений одновременно.
-
Наконец, мы приступим к созданию примера сервера и клиента, который функционирует как полноценное приложение для сокетов, со своим собственным настраиваемым заголовком и содержимым.
К концу этого урока вы поймете, как использовать основные функции и методы в модуле Python socket для написания собственных клиент-серверных приложений. , Это включает в себя показ того, как использовать пользовательский класс для отправки сообщений и данных между конечными точками, которые вы можете использовать и использовать для своих собственных приложений.
Примеры в этом руководстве используют Python 3.6. Вы можете найти source код на GitHub.
Сеть и розетки - это большие предметы. О них написаны буквальные тома. Если вы плохо знакомы с сокетами или сетями, это совершенно нормально, если вы чувствуете себя перегруженными всеми терминами и частями. Я знаю, что сделал!
Не расстраивайтесь, хотя. Я написал этот урок для вас. Как и в случае с Python, мы можем учиться понемногу. Используйте функцию закладок браузера и возвращайтесь, когда будете готовы к следующему разделу.
Давайте начнем!
Фон
Розетки имеют долгую историю. Их использование originated с ARPANET в 1971 году и позднее стало API в операционной системе Berkeley Software Distribution (BSD), выпущенной в 1983 году, под названием https://en.wikipedia .org/wiki/Berkeley_sockets [Беркли сокеты].
Когда в 1990-х годах появился Интернет со Всемирной паутиной, то же самое произошло и с сетевым программированием. Веб-серверы и браузеры были не единственными приложениями, использующими преимущества новых подключенных сетей и использующих сокеты. Клиент-серверные приложения всех типов и размеров получили широкое распространение.
Сегодня, несмотря на то, что базовые протоколы, используемые API сокетов, развивались годами, и мы видели новые, низкоуровневый API остался прежним.
Наиболее распространенным типом приложений сокетов являются клиент-серверные приложения, где одна сторона выступает в качестве сервера и ожидает подключения от клиентов. Это тип приложения, о котором я расскажу в этом руководстве. Более конкретно, мы рассмотрим API сокетов для сокетов Internet, иногда называемых сокетами Беркли или BSD. Также есть Unix сокеты домена, которые можно использовать только для связи между процессами на одном хосте.
Обзор Socket API
Https://docs.python.org/3/library/socket.html модуль[socket Python] предоставляет интерфейс для API сокетов Berkeley. Это модуль, который мы будем использовать и обсудить в этом руководстве.
Основные функции и методы API сокетов в этом модуле:
-
+ Раструб () + -
+ Связывания () + -
+ Слушать () + -
+ Принимаю () + -
+ Connect () + -
+ Connect_ex () + -
+ Send () + -
+ RECV () + -
+ Закрытие () +
Python предоставляет удобный и непротиворечивый API, который отображается непосредственно на эти системные вызовы, их C-аналоги. Мы рассмотрим, как они используются вместе, в следующем разделе.
Как часть своей стандартной библиотеки, Python также имеет классы, которые облегчают использование этих низкоуровневых функций сокетов. Хотя это и не рассматривается в этом руководстве, см. Https://docs.python.org/3/library/socketserver.html[socketserver module], среду для сетевых серверов. Есть также много доступных модулей, которые реализуют высокоуровневые интернет-протоколы, такие как HTTP и SMTP. Для обзора см. Https://docs.python.org/3/library/internet.html[Internet Протоколы и поддержка].
TCP-сокеты
Как вы вскоре увидите, мы создадим объект сокета с помощью + socket.socket () + и определим тип сокета как + socket.SOCK_STREAM +. Когда вы делаете это, используется протокол по умолчанию Transmission Control Protocol (TCP). Это хороший вариант по умолчанию и, вероятно, то, что вы хотите.
Почему вы должны использовать TCP? Протокол управления передачей (TCP):
-
Надежен: отброшенные в сети пакеты обнаруживаются и повторно передаются отправителем.
-
Имеет порядок доставки данных: данные читаются вашим приложением в том порядке, в котором они были написаны отправителем.
Напротив, User Datagram Protocol (UDP) сокеты, созданные с помощью + socket.SOCK_DGRAM +, не являются надежными, и данные, считываемые получателем, могут быть вне приказ от отправителя пишет.
Почему это важно? Сети - это система доставки с максимальными усилиями. Нет никакой гарантии, что ваши данные достигнут пункта назначения или что вы получите то, что было отправлено вам.
Сетевые устройства (например, маршрутизаторы и коммутаторы) имеют ограниченную доступную полосу пропускания и собственные системные ограничения. Они имеют процессоры, память, шины и интерфейсные буферы пакетов, как наши клиенты и серверы. TCP освобождает вас от необходимости беспокоиться о потере packet, поступлении данных не по порядку и многих других вещах, которые неизменно происходят, когда вы общаетесь по сети.
На диаграмме ниже давайте рассмотрим последовательность вызовов API сокетов и поток данных для TCP:
Левый столбец представляет сервер. На правой стороне находится клиент.
Начиная с верхнего левого столбца, обратите внимание на API-вызовы, которые сервер делает для настройки «слушающего» сокета:
-
+ Раструб () + -
+ Связывания () + -
+ Слушать () + -
+ Принимаю () +
Разъем для прослушивания делает именно так, как он звучит. Он слушает соединения от клиентов. Когда клиент подключается, сервер вызывает + accept () +, чтобы принять или завершить соединение.
Клиент вызывает + connect () +, чтобы установить соединение с сервером и инициировать трехстороннее рукопожатие. Этап рукопожатия важен, поскольку он гарантирует, что каждая сторона соединения доступна в сети, другими словами, что клиент может достичь сервера и наоборот. Может случиться так, что только один хост, клиент или сервер может связаться с другим.
В середине находится раздел «туда-обратно», где данные обмениваются между клиентом и сервером с помощью вызовов + send () + и + recv () +.
Внизу клиент и сервер + close () + их соответствующие сокеты.
Эхо-клиент и сервер
Теперь, когда вы увидели обзор API сокетов и взаимодействия клиента и сервера, давайте создадим наш первый клиент и сервер. Начнем с простой реализации. Сервер будет просто отображать все, что он получает обратно клиенту.
Эхо-сервер
Вот сервер, + echo-server.py +:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # Standard loopback interface address (localhost)
PORT = 65432 # Port to listen on (non-privileged ports are > 1023)
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((HOST, PORT))
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)*Примечание:* Не беспокойтесь о понимании всего вышесказанного прямо сейчас. В этих нескольких строках кода много чего происходит. Это только отправная точка, чтобы вы могли увидеть базовый сервер в действии.
В конце этого руководства есть ссылка: #reference [reference section], которая содержит больше информации и ссылки на дополнительные ресурсы. Я буду ссылаться на эти и другие ресурсы на протяжении всего урока.
Давайте пройдемся по каждому вызову API и посмотрим, что происходит.
+ socket.socket () + создает объект сокета, который поддерживает тип менеджера context, так что вы можете использовать его в https://docs.python.org/3/reference/compound_stmts.html#with [+ с оператором +]. Нет необходимости вызывать + s.close () +:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
pass # Use the socket object without calling s.close().Аргументы, передаваемые в https://docs.python.org/3/library/socket.html#socket.socket [+ socket () +], указывают ссылку: # socket-address-family [семейство адресов] и сокет тип. + AF_INET + - это семейство интернет-адресов для IPv4. + SOCK_STREAM + - это тип сокета для ссылки: # tcp-sockets [TCP], протокол, который будет использоваться для передачи наших сообщений в сети.
+ bind () + используется для связывания сокета с определенным сетевым интерфейсом и номером порта:
HOST = '127.0.0.1' # Standard loopback interface address (localhost)
PORT = 65432 # Port to listen on (non-privileged ports are > 1023)
# ...
s.bind((HOST, PORT))Значения, передаваемые в + bind () +, зависят от ссылки: # socket-address-family [address family] сокета. В этом примере мы используем + socket.AF_INET + (IPv4). Так что ожидается 2 кортежа: + (хост, порт) +.
+ host + может быть именем хоста, IP-адресом или пустой строкой. Если используется IP-адрес, + host + должен быть строкой адреса в формате IPv4. IP-адрес + 127.0.0.1 + является стандартным IPv4-адресом для интерфейса loopback, поэтому только процессы на хосте смогут подключаться к серверу. Если вы передадите пустую строку, сервер будет принимать соединения на всех доступных интерфейсах IPv4.
+ port + должно быть целым числом из + 1 + -` + 65535 + ( + 0 + зарезервировано). Это TCP port номер для приема соединений от клиентов. Некоторые системы могут требовать привилегий суперпользователя, если порт <+ 1024 +`.
Вот примечание об использовании имен хостов с + bind () +:
_ «Если вы используете имя хоста в части хоста адреса сокета IPv4/v6, программа может показывать недетерминированное поведение, так как Python использует первый адрес, возвращенный из разрешения DNS. Адрес сокета будет по-разному преобразован в фактический адрес IPv4/v6, в зависимости от результатов разрешения DNS и/или конфигурации хоста. Для детерминированного поведения используйте числовой адрес в части хоста ». (Source) _
Я расскажу об этом позже в ссылке: # using-hostnames [Using Hostnames], но об этом стоит упомянуть здесь. А пока, просто поймите, что при использовании имени хоста вы можете увидеть разные результаты в зависимости от того, что возвращается из процесса разрешения имени.
Это может быть что угодно. При первом запуске приложения это может быть адрес + 10.1.2.3 +. В следующий раз это будет другой адрес, + 192.168.0.1 +. В третий раз это может быть + 172.16.7.8 + и так далее.
Продолжая пример с сервером, + listen () + позволяет серверу + accept () + соединений. Это делает его «слушающим» сокетом:
s.listen()
conn, addr = s.accept()+ listen () + имеет параметр + backlog +. Он указывает количество неприемлемых подключений, которые система разрешит перед отказом в новых подключениях. Начиная с Python 3.5, это необязательно. Если не указано, выбирается значение по умолчанию + backlog +.
Если ваш сервер получает много запросов на соединение одновременно, увеличение значения + backlog + может помочь, установив максимальную длину очереди для ожидающих соединений. Максимальное значение зависит от системы. Например, в Linux см. Https://serverfault.com/questions/518862/will-increasing-net-core-somaxconn-make-a-difference/519152 [+/proc/sys/net/core/somaxconn + ].
+ accept () + link: # blocking-вызывает [блокирует] и ждет входящего соединения. Когда клиент подключается, он возвращает новый объект сокета, представляющий соединение, и кортеж, содержащий адрес клиента. Кортеж будет содержать + (хост, порт) + для соединений IPv4 или + (хост, порт, flowinfo, scopeid) + для IPv6. См. Ссылку: # socket-address-family [Семейства адресов сокетов] в справочном разделе для получения подробной информации о значениях кортежей.
Одна вещь, которую необходимо понять, это то, что теперь у нас есть новый объект сокета из + accept () +. Это важно, так как это сокет, который вы будете использовать для связи с клиентом. Он отличается от сокета прослушивания, который сервер использует для приема новых соединений:
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)После получения объекта клиентского сокета + conn + из + accept () + бесконечный цикл + while + используется для циклического перемещения по ссылке: # blocking-call [blocking messages] to + conn.recv () + `. Это читает любые данные, которые клиент отправляет, и возвращает их обратно, используя `+ conn.sendall () +.
Если + conn.recv () + возвращает пустой https://docs.python.org/3/library/stdtypes.html#bytes-objects [+ bytes +] объект, + b '' +, затем клиент закрыл соединение и цикл прерывается. Оператор + with + используется с + conn + для автоматического закрытия сокета в конце блока.
Эхо-клиент
Теперь давайте посмотрим на клиента, + echo-client.py +:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # The server's hostname or IP address
PORT = 65432 # The port used by the server
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect((HOST, PORT))
s.sendall(b'Hello, world')
data = s.recv(1024)
print('Received', repr(data))По сравнению с сервером клиент довольно прост. Он создает объект сокета, подключается к серверу и вызывает + s.sendall () + для отправки своего сообщения. Наконец, он вызывает + s.recv () +, чтобы прочитать ответ сервера, а затем распечатать его.
Запуск клиента и сервера Echo
Давайте запустим клиент и сервер, чтобы посмотреть, как они себя ведут, и проверить, что происходит.
*Примечание:* Если у вас возникли проблемы с запуском примеров или собственного кода из командной строки, прочитайте https://dbader.org/blog/how-to-make-command-line-commands-with-python [Как создавать свои собственные команды командной строки с использованием Python?] Если вы работаете в Windows, проверьте https://docs.python.org/3.6/faq/windows.html[Python Windows FAQ].
Откройте терминал или командную строку, перейдите в каталог, содержащий ваши сценарии, и запустите сервер:
$ ./echo-server.pyВаш терминал будет зависать. Это потому, что сервер является ссылкой: # blocking-Call [заблокирован] (приостановлено) в вызове:
conn, addr = s.accept()Он ждет подключения клиента. Теперь откройте другое окно терминала или командную строку и запустите клиент:
$ ./echo-client.py
Received b'Hello, world'В окне сервера вы должны увидеть:
$ ./echo-server.py
Connected by ('127.0.0.1', 64623)В приведенном выше выводе сервер напечатал кортеж + addr +, возвращенный из + s.accept () +. Это IP-адрес клиента и номер порта TCP. Номер порта + 64623 +, скорее всего, будет другим, когда вы запустите его на своем компьютере.
Просмотр состояния сокета
Чтобы увидеть текущее состояние сокетов на вашем хосте, используйте + netstat +. Он доступен по умолчанию в macOS, Linux и Windows.
Вот вывод netstat из macOS после запуска сервера:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 127.0.0.1.65432 *. *LISTENОбратите внимание, что + Local Address + равно + 127.0.0.1.65432 +. Если бы + echo-server.py + использовал + HOST = '' + вместо + HOST = '127.0.0.1' +, netstat показал бы это:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 * .65432 *. *LISTEN+ Local Address + равно +* . 65432 +, что означает, что все доступные хост-интерфейсы, которые поддерживают семейство адресов, будут использоваться для приема входящих соединений. В этом примере при вызове + socket () + было использовано + socket.AF_INET + (IPv4). Вы можете увидеть это в столбце + Proto +: + tcp4 +.
Я обрезал вывод выше, чтобы показать только эхо-сервер. Скорее всего, вы увидите гораздо больше результатов, в зависимости от того, на какой системе вы его используете. Обратите внимание на столбцы + Proto +, + Local Address + и + (state) +. В последнем примере выше netstat показывает, что эхо-сервер использует TCP-сокет IPv4 (+ tcp4 +), на порту 65432 на всех интерфейсах (+ *. 65432 +), и он находится в состоянии прослушивания (`+ LISTEN + `).
Другой способ увидеть это вместе с дополнительной полезной информацией - использовать + lsof + (список открытых файлов). Он доступен по умолчанию в macOS и может быть установлен в Linux с помощью диспетчера пакетов, если это еще не сделано:
$ lsof -i -n
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
Python 67982 nathan 3u IPv4 0xecf272 0t0 TCP *:65432 (LISTEN)+ lsof + дает вам + COMMAND +, + PID + (идентификатор процесса) и + USER + (идентификатор пользователя) открытых интернет-сокетов при использовании с опцией + -i +. Выше процесс эхо-сервера.
+ netstat + и + lsof + имеют много доступных опций и различаются в зависимости от ОС, на которой вы их используете. Проверьте страницу + man + или документацию для обоих. Им определенно стоит потратить немного времени и узнать поближе. Вы будете вознаграждены. В macOS и Linux используйте + man netstat + и + man lsof +. Для Windows используйте + netstat/? +.
Вот типичная ошибка, которую вы увидите, когда будет предпринята попытка подключения к порту без прослушивающего сокета:
$ ./echo-client.py
Traceback (most recent call last):
File "./echo-client.py", line 9, in <module>
s.connect((HOST, PORT))
ConnectionRefusedError: [Errno 61] Connection refusedЛибо указан неверный номер порта, либо сервер не работает. А может, на пути к файлу есть брандмауэр, блокирующий соединение, о котором легко забыть. Вы также можете увидеть ошибку + Время ожидания истекло +. Добавьте правило брандмауэра, которое позволяет клиенту подключаться к порту TCP!
Список ссылок: #errors [errors] в справочном разделе.
Отсутствие взаимопонимания
Давайте подробнее рассмотрим, как клиент и сервер взаимодействуют друг с другом:
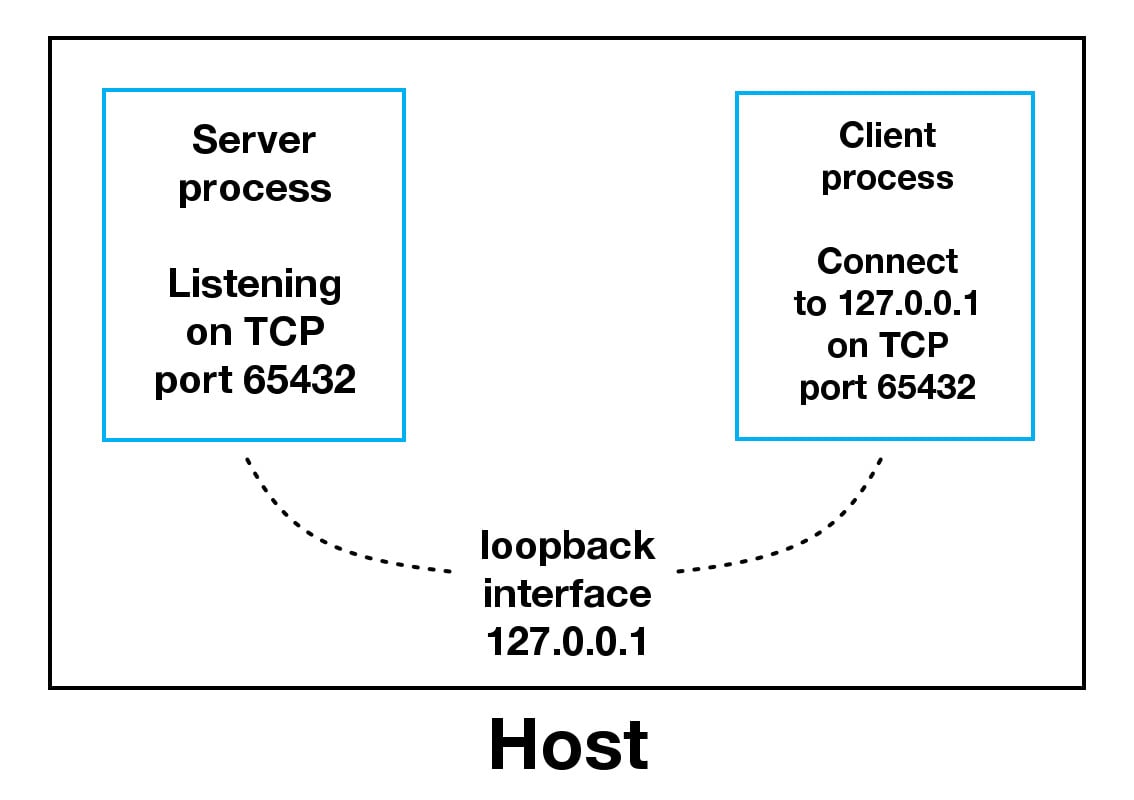
- При использовании интерфейса loopback (адрес IPv4
+ 127.0.0.1 +или адрес IPv6 `+ -
1 `) данные никогда не покидают хост или не касаются внешняя сеть. На приведенной выше схеме интерфейс обратной связи находится внутри хоста. Это представляет внутреннюю природу интерфейса обратной связи и то, что соединения и данные, которые передают его, являются локальными для хоста. Вот почему вы также услышите интерфейс обратной связи и IP-адрес ` 127.0.0.1 ` или ` :: 1 +`, называемый «localhost».
Приложения используют интерфейс обратной связи для связи с другими процессами, запущенными на хосте, а также для обеспечения безопасности и изоляции от внешней сети. Поскольку он внутренний и доступен только изнутри хоста, он не раскрывается.
Это можно увидеть в действии, если у вас есть сервер приложений, который использует собственную частную базу данных. Если это не база данных, используемая другими серверами, возможно, она настроена на прослушивание соединений только через интерфейс обратной связи. В этом случае другие хосты в сети не могут подключиться к нему.
- Когда вы используете в своих приложениях IP-адрес, отличный от
+ 127.0.0.1 +или `+ -
1 +`, он, вероятно, связан с интерфейсом Ethernet, который подключен к внешней сети. Это ваши ворота к другим хостам за пределами вашего «локального» королевства:
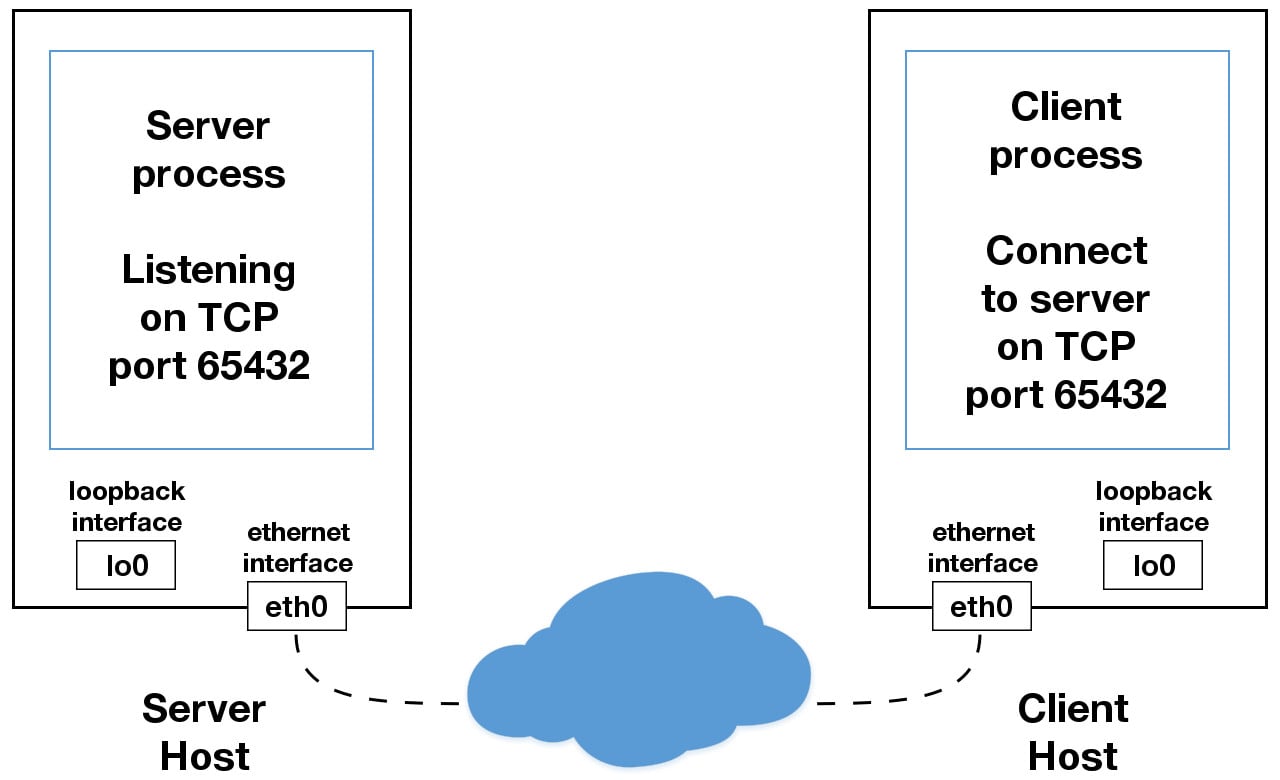
Будь осторожен там. Это неприятный, жестокий мир. Обязательно прочитайте ссылку на раздел: # using-hostnames [Using Hostnames], прежде чем выходить из безопасных границ «localhost». Есть примечание о безопасности, которое применяется, даже если вы не используете имена хостов и используете только IP-адреса.
Обработка нескольких соединений
Эхо-сервер определенно имеет свои ограничения. Самое большое, что он обслуживает только одного клиента и затем выходит. Клиент echo также имеет это ограничение, но есть дополнительная проблема. Когда клиент делает следующий вызов, возможно, что + s.recv () + вернет только один байт, + b’H '+ из + b’Hello, world' +:
data = s.recv(1024)Аргумент + bufsize + для + 1024 +, использованный выше, является максимальным объемом данных, которые должны быть получены одновременно. Это не означает, что + recv () + вернет + 1024 + байт.
+ send () + также ведет себя так. + send () + возвращает количество отправленных байтов, которое может быть меньше размера передаваемых данных. Вы несете ответственность за проверку этого и вызываете + send () + столько раз, сколько необходимо для отправки всех данных:
_ «Приложения отвечают за проверку того, что все данные были отправлены; если были переданы только некоторые данные, приложение должно попытаться доставить оставшиеся данные ». (Source) _
Мы избежали необходимости делать это с помощью + sendall () +:
_ «В отличие от send (), этот метод продолжает отправлять данные из байтов до тех пор, пока не будут отправлены все данные или пока не произойдет ошибка. Никто не возвращается в случае успеха ». (Source) _
На данный момент у нас есть две проблемы:
-
Как мы обрабатываем несколько соединений одновременно?
-
Нам нужно вызывать
+ send () +и+ recv () +, пока все данные не будут отправлены или получены.
Что мы делаем? Существует множество подходов к concurrency. В последнее время популярным подходом является использование Asynchronous I/O. + asyncio + была введена в стандартную библиотеку в Python 3.4. Традиционный выбор - использовать threads.
Проблема с параллелизмом состоит в том, что трудно понять правильно. Есть много тонкостей, которые нужно учитывать и оберегать. Все, что требуется для того, чтобы один из них проявил себя, и ваше приложение может внезапно выйти из строя не очень тонкими способами.
Я не говорю это, чтобы отпугнуть вас от обучения и использования параллельного программирования. Если ваше приложение нуждается в масштабировании, это необходимо, если вы хотите использовать более одного процессора или одно ядро. Тем не менее, для этого урока мы будем использовать нечто более традиционное, чем потоки, и о котором легче рассуждать. Мы собираемся использовать дедушку системных вызовов: https://docs.python.org/3/library/selectors.html#selectors.BaseSelector.select [+ select () +].
+ select () + позволяет проверять завершение ввода/вывода в нескольких сокетах. Таким образом, вы можете вызвать + select () +, чтобы увидеть, какие сокеты имеют ввод/вывод, готовый для чтения и/или записи. Но это Python, так что это еще не все. Мы собираемся использовать модуль selectors в стандартной библиотеке, чтобы использовать наиболее эффективную реализацию независимо от операционной системы, в которой мы работаем на:
_ «Этот модуль обеспечивает высокоуровневое и эффективное мультиплексирование ввода/вывода, построенное на примитивах выбранного модуля. Вместо этого пользователям рекомендуется использовать этот модуль, если они не хотят точно контролировать используемые примитивы уровня ОС ». (Source) _
Несмотря на то, что с помощью + select () + мы не можем работать одновременно, в зависимости от вашей рабочей нагрузки, этот подход все еще может быть достаточно быстрым. Это зависит от того, что ваше приложение должно делать, когда оно обслуживает запрос, и от количества клиентов, которые ему необходимо поддерживать.
https://docs.python.org/3/library/asyncio.html [+ asyncio +] использует однопотоковую совместную многозадачность и цикл обработки событий для управления задачами. С помощью + select () + мы напишем нашу собственную версию цикла событий, хотя и более просто и синхронно. При использовании нескольких потоков, даже если у вас есть параллелизм, в настоящее время мы должны использовать GIL с CPython и PyPy . Это эффективно ограничивает объем работы, которую мы можем выполнять параллельно.
Я говорю все это, чтобы объяснить, что использование + select () + может быть идеальным выбором. Не думайте, что вам нужно использовать + asyncio +, потоки или последнюю асинхронную библиотеку. Как правило, в сетевом приложении ваше приложение связано с вводом/выводом: оно может ожидать в локальной сети, конечных точках на другой стороне сети, на диске и т. Д.
Если вы получаете запросы от клиентов, которые инициируют работу с привязкой к процессору, посмотрите на модуль concurrent.futures. Он содержит класс ProcessPoolExecutor, который использует пул процессов для асинхронного выполнения вызовов.
Если вы используете несколько процессов, операционная система может запланировать параллельный запуск кода Python на нескольких процессорах или ядрах без GIL. Для идей и вдохновения см. Доклад PyCon John Reese - Размышление вне GIL с помощью AsyncIO и многопроцессорной обработки - PyCon 2018.
В следующем разделе мы рассмотрим примеры сервера и клиента, которые решают эти проблемы. Они используют + select () + для одновременной обработки нескольких соединений и вызывают + send () + и + recv () + столько раз, сколько необходимо.
Многоканальный клиент и сервер
В следующих двух разделах мы создадим сервер и клиент, который будет обрабатывать несколько соединений, используя объект + selector +, созданный из модуля selectors.
Multi-Connection Server
Во-первых, давайте посмотрим на сервер множественных соединений + multiconn-server.py +. Вот первая часть, которая устанавливает сокет прослушивания:
import selectors
sel = selectors.DefaultSelector()
# ...
lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
lsock.bind((host, port))
lsock.listen()
print('listening on', (host, port))
lsock.setblocking(False)
sel.register(lsock, selectors.EVENT_READ, data=None)Самое большое различие между этим сервером и сервером эха - это вызов + lsock.setblocking (False) + для настройки сокета в неблокирующем режиме. Вызовы, сделанные на этот сокет, больше не будут связывать: # blocking-Call [block] Когда он используется с + sel.select () +, как вы увидите ниже, мы можем ожидать события на одном или нескольких сокетах, а затем читать и записывать данные, когда они будут готовы.
+ sel.register () + регистрирует сокет, который будет отслеживаться с помощью + sel.select () + для интересующих вас событий. Для сокета прослушивания мы хотим прочитать события: + selectors.EVENT_READ +.
+ data + используется для хранения любых произвольных данных вместе с сокетом. Возвращается, когда возвращается + select () +. Мы будем использовать + data + для отслеживания того, что было отправлено и получено в сокете.
Далее идет цикл событий:
import selectors
sel = selectors.DefaultSelector()
# ...
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
service_connection(key, mask)https://docs.python.org/3/library/selectors.html#selectors.BaseSelector.select [+ sel.select (timeout = None) +] ссылка: # blocking-call [blocks] до появления сокетов готов к вводу/выводу. Он возвращает список (ключ, события) кортежей, по одному для каждого сокета. + key + является SelectorKey + namedtuple +, который содержит атрибут + fileobj +. + key.fileobj + - объект сокета, а + mask + - маска события готовых операций.
Если + key.data + равно + None +, то мы знаем, что это из сокета прослушивания, и нам нужно + accept () + соединение. Мы вызовем нашу собственную функцию-оболочку + accept () +, чтобы получить новый объект сокета и зарегистрировать его с помощью селектора. Мы посмотрим на это через мгновение.
Если + key.data + не равно + None +, то мы знаем, что это клиентский сокет, который уже принят, и нам нужно его обслужить. Затем вызывается + service_connection () + и передается + key + и + mask +, которые содержат все, что нам нужно для работы с сокетом.
Давайте посмотрим, что делает наша функция + accept_wrapper () +:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
data = types.SimpleNamespace(addr=addr, inb=b'', outb=b'')
events = selectors.EVENT_READ | selectors.EVENT_WRITE
sel.register(conn, events, data=data)Поскольку прослушивающий сокет был зарегистрирован для события + selectors.EVENT_READ +, он должен быть готов к чтению. Мы вызываем + sock.accept () +, а затем сразу же вызываем + conn.setblocking (False) +, чтобы перевести сокет в неблокирующий режим.
Помните, что это главная цель в этой версии сервера, так как мы не хотим, чтобы он связывал: # blocking-Call [block]. Если он блокируется, то весь сервер останавливается, пока не вернется. Это означает, что другие сокеты остаются в ожидании. Это ужасное состояние зависания, при котором вы не хотите, чтобы ваш сервер находился в режиме ожидания.
Затем мы создаем объект для хранения данных, которые мы хотим включить вместе с сокетом, используя класс + types.SimpleNamespace +. Поскольку мы хотим знать, когда клиентское соединение готово для чтения и записи, оба эти события устанавливаются с использованием следующего:
events = selectors.EVENT_READ | selectors.EVENT_WRITEЗатем маска + events +, сокет и объекты данных передаются в + sel.register () +.
Теперь давайте посмотрим на + service_connection () +, чтобы увидеть, как обрабатывается клиентское соединение, когда оно готово:
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if data.outb:
print('echoing', repr(data.outb), 'to', data.addr)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]Это сердце простого сервера мультисвязи. + key + - это + namedtuple +, возвращаемый из + select () +, который содержит объект сокета (+ fileobj +) и объект данных. + mask + содержит события, которые готовы.
Если сокет готов к чтению, то + mask & selectors.EVENT_READ + равно true и вызывается + sock.recv () +. Любые прочитанные данные добавляются в + data.outb +, поэтому их можно отправить позже.
Обратите внимание на блок + else: +, если данные не получены:
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()Это означает, что клиент закрыл свой сокет, так что сервер тоже должен. Но не забудьте сначала вызвать + sel.unregister () +, чтобы он больше не отслеживался + select () +.
Когда сокет готов к записи, что всегда должно быть в случае работоспособного сокета, любые полученные данные, хранящиеся в + data.outb +, передаются клиенту с помощью + sock.send () +. Отправленные байты затем удаляются из буфера отправки:
data.outb = data.outb[sent:]Multi-Connection Client
Теперь давайте посмотрим на клиент множественного подключения, + multiconn-client.py +. Он очень похож на сервер, но вместо прослушивания соединений он начинается с инициализации соединений с помощью + start_connections () +:
messages = [b'Message 1 from client.', b'Message 2 from client.']
def start_connections(host, port, num_conns):
server_addr = (host, port)
for i in range(0, num_conns):
connid = i + 1
print('starting connection', connid, 'to', server_addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(server_addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
data = types.SimpleNamespace(connid=connid,
msg_total=sum(len(m) for m in messages),
recv_total=0,
messages=list(messages),
outb=b'')
sel.register(sock, events, data=data)+ num_conns + читается из командной строки, которая является числом соединений, которые нужно создать с сервером. Как и сервер, каждый сокет установлен в неблокирующий режим.
+ connect_ex () + используется вместо + connect () +, поскольку + connect () + немедленно вызовет исключение + BlockingIOError +. + connect_ex () + изначально возвращает индикатор ошибки + errno.EINPROGRESS + вместо того, чтобы вызывать исключение во время соединения. Как только соединение завершено, сокет готов к чтению и записи и возвращается как таковой + select () +.
После настройки сокета данные, которые мы хотим сохранить в сокете, создаются с использованием класса + types.SimpleNamespace +. Сообщения, которые клиент отправит на сервер, копируются с использованием + list (messages) +, поскольку каждое соединение вызывает + socket.send () + и изменяет список. Все необходимое для отслеживания того, что клиент должен отправить, отправил и получил, а общее количество байтов в сообщениях хранится в объекте + data +.
Давайте посмотрим на + service_connection () +. Он в основном такой же, как сервер:
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
print('received', repr(recv_data), 'from connection', data.connid)
data.recv_total += len(recv_data)
if not recv_data or data.recv_total == data.msg_total:
print('closing connection', data.connid)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if not data.outb and data.messages:
data.outb = data.messages.pop(0)
if data.outb:
print('sending', repr(data.outb), 'to connection', data.connid)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]Есть одно важное отличие. Он отслеживает количество байтов, полученных от сервера, чтобы он мог закрыть свою сторону соединения. Когда сервер обнаруживает это, он также закрывает свою сторону соединения.
Обратите внимание, что при этом сервер зависит от хорошего поведения клиента: сервер ожидает, что клиент закроет свою сторону соединения после завершения отправки сообщений. Если клиент не закрывается, сервер оставит соединение открытым. В реальном приложении вы можете принять меры против этого на своем сервере и предотвратить накопление клиентских подключений, если они не отправляют запрос через определенное время.
Запуск клиента и сервера Multi-Connection
Теперь давайте запустим + multiconn-server.py + и + multiconn-client.py +. Они оба используют аргументы командной строки. Вы можете запустить их без аргументов, чтобы увидеть варианты.
Для сервера передайте номера + host + и + port +:
$ ./multiconn-server.py
usage: ./multiconn-server.py <host> <port>Для клиента также передайте количество соединений, которые нужно создать, на сервер, + num_connections +:
$ ./multiconn-client.py
usage: ./multiconn-client.py <host> <port> <num_connections>Ниже приведены выходные данные сервера при прослушивании интерфейса обратной связи через порт 65432:
$ ./multiconn-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)
accepted connection from ('127.0.0.1', 61354)
accepted connection from ('127.0.0.1', 61355)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61354)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61355)
closing connection to ('127.0.0.1', 61354)
closing connection to ('127.0.0.1', 61355)Ниже приведен вывод клиента, когда он создает два соединения с сервером выше:
$ ./multiconn-client.py 127.0.0.1 65432 2
starting connection 1 to ('127.0.0.1', 65432)
starting connection 2 to ('127.0.0.1', 65432)
sending b'Message 1 from client.' to connection 1
sending b'Message 2 from client.' to connection 1
sending b'Message 1 from client.' to connection 2
sending b'Message 2 from client.' to connection 2
received b'Message 1 from client.Message 2 from client.' from connection 1
closing connection 1
received b'Message 1 from client.Message 2 from client.' from connection 2
closing connection 2Клиент приложения и сервер
Пример клиента и сервера с несколькими подключениями, безусловно, является улучшением по сравнению с тем, с чего мы начали. Однако давайте сделаем еще один шаг и рассмотрим недостатки предыдущего примера «multiconn» в окончательной реализации: клиент приложения и сервер.
Мы хотим, чтобы клиент и сервер обрабатывали ошибки соответствующим образом, чтобы другие соединения не были затронуты. Очевидно, что наш клиент или сервер не должны рухнуть в ярости, если исключение не поймано. Это то, что мы не обсуждали до сих пор. Я намеренно пропустил обработку ошибок для краткости и ясности в примерах.
Теперь, когда вы знакомы с базовым API, неблокирующими сокетами и + select () +, мы можем добавить некоторую обработку ошибок и обсудить «слона в комнате», который я скрыл от вас за этим большой занавес там. Да, я говорю о пользовательском классе, который я упоминал еще во введении. Я знал, что ты не забудешь.
Во-первых, давайте исправим ошибки:
_
«Все ошибки вызывают исключения. Нормальные исключения для недопустимых типов аргументов и условий нехватки памяти могут быть вызваны; начиная с Python 3.3, ошибки, связанные с семантикой сокетов или адресов, приводят к + OSError + или одному из его подклассов. ” (Source)
_
Нам нужно отловить + OSError +. Еще одна вещь, которую я не упомянул в связи с ошибками, это тайм-ауты. Вы увидите их во многих местах в документации. Тайм-ауты случаются и являются «нормальной» ошибкой. Хосты и маршрутизаторы перезагружаются, порты коммутатора выходят из строя, кабели выходят из строя, кабели отключаются, вы называете это. Вы должны быть готовы к этим и другим ошибкам и обрабатывать их в своем коде.
Что насчет «слона в комнате»? Как подсказывает тип сокета + socket.SOCK_STREAM +, при использовании TCP вы читаете из непрерывного потока байтов. Это похоже на чтение из файла на диске, но вместо этого вы читаете байты из сети.
Однако, в отличие от чтения файла, здесь нет https://docs.python.org/3/tutorial/inputoutput.html#methods-of-file-objects [+ f.seek () +]. Другими словами, вы не можете перемещать указатель сокета, если он был, и перемещаться случайным образом по данным, читая что угодно и когда угодно.
Когда байты поступают в ваш сокет, включаются сетевые буферы. Как только вы их прочитаете, их нужно где-то сохранить. Вызов + recv () + снова считывает следующий поток байтов, доступных из сокета.
Это означает, что вы будете читать из сокета порциями. Вам нужно вызвать + recv () + и сохранить данные в буфере, пока вы не прочитаете достаточно байтов, чтобы получить полное сообщение, которое имеет смысл для вашего приложения.
Вы сами должны определить и отслеживать границы сообщений. Что касается сокета TCP, то он просто отправляет и получает необработанные байты в и из сети. Он ничего не знает о том, что означают эти необработанные байты.
Это подводит нас к определению протокола прикладного уровня. Что такое протокол прикладного уровня? Проще говоря, ваше приложение будет отправлять и получать сообщения. Эти сообщения являются протоколом вашего приложения.
Другими словами, длина и формат, который вы выбираете для этих сообщений, определяют семантику и поведение вашего приложения. Это напрямую связано с тем, что я объяснил в предыдущем параграфе относительно чтения байтов из сокета. Когда вы читаете байты с помощью + recv () +, вам нужно следить за тем, сколько байтов было прочитано, и выяснить, где находятся границы сообщения.
Как это сделать? Одним из способов является отправка сообщений фиксированной длины. Если они всегда одинакового размера, то это легко. Когда вы прочитали это количество байтов в буфер, вы знаете, что у вас есть одно полное сообщение.
Тем не менее, использование сообщений фиксированной длины неэффективно для небольших сообщений, где вам нужно использовать заполнение для их заполнения. Кроме того, у вас все еще остается проблема с тем, что делать с данными, которые не вписываются в одно сообщение.
В этом уроке мы будем использовать общий подход. Подход, который используется многими протоколами, включая HTTP. Мы добавим в префикс сообщения заголовок, который включает в себя длину содержимого, а также любые другие необходимые нам поля. Делая это, нам нужно только идти в ногу с заголовком. После того, как мы прочитали заголовок, мы можем обработать его, чтобы определить длину содержимого сообщения, а затем прочитать это количество байтов, чтобы использовать его.
Мы реализуем это, создав собственный класс, который может отправлять и получать сообщения, содержащие текстовые или двоичные данные. Вы можете улучшить и расширить его для своих собственных приложений. Самое главное, что вы сможете увидеть пример того, как это делается.
Мне нужно упомянуть кое-что о сокетах и байтах, которые могут повлиять на вас. Как мы говорили ранее, при отправке и получении данных через сокеты вы отправляете и получаете необработанные байты.
Если вы получаете данные и хотите использовать их в контексте, в котором они интерпретируются как несколько байтов, например, 4-байтовое целое число, вам необходимо учитывать, что они могут быть в формате, который не является родным для ЦП вашей машины. Клиент или сервер на другом конце может иметь ЦП, который использует порядок байтов, отличный от вашего собственного. Если это так, перед использованием его необходимо преобразовать его в собственный порядок байтов вашего хоста.
Этот порядок байтов называется процессором endianness. Смотрите ссылку: # byte-endianness [Byte Endianness] в справочном разделе для деталей. Мы избежим этой проблемы, воспользовавшись Unicode для нашего заголовка сообщения и используя кодировку UTF-8. Поскольку UTF-8 использует 8-битное кодирование, проблем с порядком байтов не возникает.
Вы можете найти объяснение в документации Python Encodings and Unicode. Обратите внимание, что это относится только к текстовому заголовку. Мы будем использовать явный тип и кодировку, определенные в заголовке для содержимого, которое отправляется, полезной нагрузки сообщения. Это позволит нам передавать любые данные, которые нам нужны (текстовые или двоичные), в любом формате.
Вы можете легко определить порядок байтов вашей машины, используя + sys.byteorder +. Например, на моем ноутбуке Intel это происходит:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'little'Если я запускаю это на виртуальной машине с emulations процессором с прямым порядком байтов (PowerPC), то это происходит:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'big'В этом примере приложения наш протокол прикладного уровня определяет заголовок как текст Unicode с кодировкой UTF-8. Для реального содержимого сообщения, полезной нагрузки сообщения, вам все равно придется поменять порядок байтов вручную, если это необходимо.
Это будет зависеть от вашего приложения и от того, нужно ли ему обрабатывать многобайтовые двоичные данные с компьютера с другим порядком байтов. Вы можете помочь вашему клиенту или серверу реализовать двоичную поддержку, добавив дополнительные заголовки и используя их для передачи параметров, аналогично HTTP.
Не волнуйтесь, если это еще не имеет смысла. В следующем разделе вы увидите, как все это работает и соответствует друг другу.
Заголовок протокола приложения
Давайте полностью определим заголовок протокола. Заголовок протокола:
-
Текст переменной длины
-
Юникод с кодировкой UTF-8
-
Словарь Python, сериализованный с использованием JSON
Требуемые заголовки или подзаголовки в словаре заголовка протокола следующие:
| Name | Description |
|---|---|
|
The byte order of the machine (uses |
|
The length of the content in bytes. |
|
The type of content in the payload, for example, |
|
The encoding used by the content, for example, |
Эти заголовки информируют получателя о содержании в полезной нагрузке сообщения. Это позволяет отправлять произвольные данные, предоставляя достаточно информации, чтобы получатель мог правильно декодировать и интерпретировать содержимое. Поскольку заголовки находятся в словаре, легко добавить дополнительные заголовки, вставляя пары ключ/значение по мере необходимости.
Отправка сообщения приложения
Есть еще небольшая проблема. У нас есть заголовок переменной длины, который хорош и гибок, но как узнать длину заголовка при чтении его с помощью + recv () +?
Когда мы ранее говорили об использовании + recv () + и границ сообщения, я упоминал, что заголовки фиксированной длины могут быть неэффективными. Это правда, но мы собираемся использовать небольшой 2-байтовый заголовок фиксированной длины для префикса заголовка JSON, который содержит его длину.
Вы можете думать об этом как о гибридном подходе к отправке сообщений. По сути, мы запускаем процесс получения сообщения, отправляя сначала длину заголовка. Это позволяет нашему получателю легко деконструировать сообщение.
Чтобы лучше понять формат сообщения, давайте рассмотрим сообщение целиком:
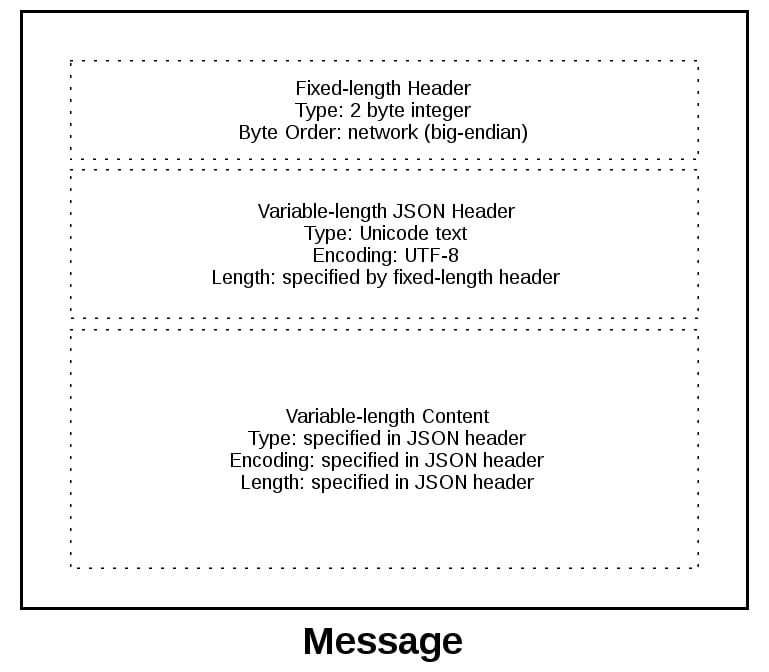
Сообщение начинается с заголовка фиксированной длины в 2 байта, который является целым числом в сетевом порядке байтов. Это длина следующего заголовка, JSON-заголовка переменной длины. После того, как мы прочитали 2 байта с помощью + recv () +, мы знаем, что можем обработать 2 байта как целое число и затем прочитать это число байтов перед декодированием заголовка JSON UTF-8.
Ссылка: # application-protocol-header [JSON header] содержит словарь дополнительных заголовков. Одним из них является + content-length +, которое представляет собой количество байтов содержимого сообщения (не включая заголовок JSON). Как только мы вызвали + recv () + и прочитали + content-length + байтов, мы достигли границы сообщения и прочитали все сообщение.
Класс сообщения приложения
Наконец, выигрыш! Давайте посмотрим на класс + Message + и посмотрим, как он используется с + select () +, когда в сокете происходят события чтения и записи.
Для этого примера приложения мне нужно было придумать, какие типы сообщений будут использовать клиент и сервер. На данный момент мы намного больше, чем просто клиенты и серверы игрушечного эха.
Для простоты и демонстрации того, как все будет работать в реальном приложении, я создал протокол приложения, который реализует базовую функцию поиска. Клиент отправляет запрос поиска, а сервер выполняет поиск совпадения. Если запрос, отправленный клиентом, не распознается как поиск, сервер предполагает, что это двоичный запрос, и возвращает двоичный ответ.
Прочитав следующие разделы, выполнив примеры и поэкспериментировав с кодом, вы увидите, как все работает. Затем вы можете использовать класс + Message + в качестве отправной точки и изменить его для своего собственного использования.
Мы на самом деле не так уж далеки от «многоконного» примера клиента и сервера. Код цикла событий остается тем же в + app-client.py + и + app-server.py +. Что я сделал, так это переместил код сообщения в класс с именем + Message + и добавил методы для поддержки чтения, записи и обработки заголовков и содержимого. Это отличный пример использования класса.
Как мы уже говорили ранее, и вы увидите ниже, работа с сокетами подразумевает сохранение состояния. Используя класс, мы сохраняем все состояние, данные и код в единое целое. Экземпляр класса создается для каждого сокета на клиенте и сервере, когда соединение установлено или принято.
Класс в основном одинаков как для клиента, так и для сервера для методов-оболочек и утилит. Они начинаются с подчеркивания, например + Message._json_encode () +. Эти методы упрощают работу с классом. Они помогают другим методам, позволяя им оставаться короче и поддерживают принцип DRY.
Серверный класс + Message + работает по сути так же, как и клиентский, и наоборот. Разница в том, что клиент инициирует соединение и отправляет сообщение с запросом, после чего обрабатывает ответное сообщение сервера. И наоборот, сервер ожидает подключения, обрабатывает сообщение запроса клиента и затем отправляет ответное сообщение.
Это выглядит так:
| Step | Endpoint | Action/Message Content |
|---|---|---|
1 |
Client |
Sends a |
2 |
Server |
Receives and processes client request |
3 |
Server |
Sends a |
4 |
Client |
Receives and processes server response |
Вот расположение файла и кода:
| Application | File | Code |
|---|---|---|
Server |
|
The server’s main script |
Server |
|
The server’s |
Client |
|
The client’s main script |
Client |
|
The client’s |
Точка ввода сообщения
Я хотел бы обсудить, как работает класс «+ Message +», упомянув сначала об одном аспекте его дизайна, который не был сразу очевиден для меня. Только после рефакторинга, по крайней мере, пять раз я пришел к тому, чем он является в настоящее время Why? Управляющий государством.
После того, как объект + Message + создан, он связывается с сокетом, который отслеживается для событий с помощью + selector.register () +:
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)*Примечание:* Некоторые примеры кода в этом разделе взяты из основного сценария сервера и класса `+ Message +`, но этот раздел и обсуждение в равной степени относятся и к клиенту. Я покажу и объясню версию клиента, когда она будет отличаться.
Когда события готовы к сокету, они возвращаются с помощью + selector.select () +. Затем мы можем получить ссылку обратно на объект сообщения, используя атрибут + data + объекта + key +, и вызвать метод в + Message +:
while True:
events = sel.select(timeout=None)
for key, mask in events:
# ...
message = key.data
message.process_events(mask)Посмотрев на цикл событий выше, вы увидите, что + sel.select () + находится на месте водителя. Это блокировка, ожидание наверху цикла событий. Он отвечает за пробуждение, когда события чтения и записи готовы для обработки в сокете. Это означает, что косвенно он также отвечает за вызов метода + process_events () +. Это то, что я имею в виду, когда говорю, что метод + process_events () + является точкой входа.
Давайте посмотрим, что делает метод + process_events () +:
def process_events(self, mask):
if mask & selectors.EVENT_READ:
self.read()
if mask & selectors.EVENT_WRITE:
self.write()Это хорошо: + process_events () + просто. Он может делать только две вещи: вызывать + read () + и + write () +.
Это возвращает нас к управлению государством. После нескольких рефакторингов я решил, что если другой метод зависит от переменных состояния, имеющих определенное значение, то они будут вызываться только из + read () + и + write () +. Это сохраняет логику настолько простой, насколько это возможно, так как события поступают в сокет для обработки.
Это может показаться очевидным, но первые несколько итераций класса представляли собой смесь некоторых методов, которые проверяли текущее состояние и, в зависимости от их значения, вызывали другие методы для обработки данных вне + read () + или `+ write ( ) + `. В конце концов, это оказалось слишком сложным, чтобы справиться и не отставать.
Вам определенно следует изменить класс в соответствии с вашими потребностями, чтобы он работал лучше для вас, но я бы рекомендовал вам сохранять проверки состояния и вызовы методов, которые зависят от этого состояния, для + read () + и ` + write () + `методы, если это возможно.
Давайте посмотрим на + read () +. Это версия сервера, но версия клиента такая же. Он просто использует другое имя метода, + process_response () + вместо + process_request () +:
def read(self):
self._read()
if self._jsonheader_len is None:
self.process_protoheader()
if self._jsonheader_len is not None:
if self.jsonheader is None:
self.process_jsonheader()
if self.jsonheader:
if self.request is None:
self.process_request()Метод + _read () + вызывается первым. Он вызывает + socket.recv () + для чтения данных из сокета и сохранения их в приемном буфере.
Помните, что когда вызывается + socket.recv () +, все данные, составляющие полное сообщение, возможно, еще не поступили. + socket.recv () + может потребоваться вызвать снова. Вот почему существуют проверки состояния для каждой части сообщения перед вызовом соответствующего метода для его обработки.
Перед тем, как метод обрабатывает свою часть сообщения, он сначала проверяет, было ли прочитано достаточно байтов в приемный буфер. Если они есть, он обрабатывает свои соответствующие байты, удаляет их из буфера и записывает свои выходные данные в переменную, которая используется на следующем этапе обработки. Поскольку в сообщении есть три компонента, есть три проверки состояния и вызовы метода + process +:
| Message Component | Method | Output |
|---|---|---|
Fixed-length header |
|
|
JSON header |
|
|
Content |
|
|
Далее давайте посмотрим на + write () +. Это версия сервера:
def write(self):
if self.request:
if not self.response_created:
self.create_response()
self._write()+ write () + сначала проверяет наличие + request +. Если он существует и ответ не был создан, вызывается + create_response () +. + create_response () + устанавливает переменную состояния + response_created + и записывает ответ в буфер отправки.
Метод + _write () + вызывает + socket.send () +, если в буфере отправки есть данные.
Помните, что когда вызывается + socket.send () +, все данные в буфере отправки могут не помещаться в очередь для передачи. Сетевые буферы для сокета могут быть заполнены, и может потребоваться повторный вызов + socket.send () +. Вот почему существуют государственные проверки. + create_response () + следует вызывать только один раз, но ожидается, что + _write () + нужно будет вызывать несколько раз.
Клиентская версия + write () + похожа:
def write(self):
if not self._request_queued:
self.queue_request()
self._write()
if self._request_queued:
if not self._send_buffer:
# Set selector to listen for read events, we're done writing.
self._set_selector_events_mask('r')Так как клиент инициирует соединение с сервером и сначала отправляет запрос, проверяется переменная состояния + _request_queued +. Если запрос не был поставлен в очередь, он вызывает + queue_request () +. + queue_request () + создает запрос и записывает его в буфер отправки. Он также устанавливает переменную состояния + _request_queued +, поэтому она вызывается только один раз.
Как и сервер, + _write () + вызывает + socket.send () +, если в буфере отправки есть данные.
Заметная разница в версии клиента + write () + - это последняя проверка, чтобы увидеть, был ли запрос поставлен в очередь. Это будет объяснено более подробно в ссылке раздела: # client-main-script [Client Main Script], но причина этого состоит в том, чтобы сказать + selector.select () +, чтобы прекратить мониторинг сокета на наличие событий записи. Если запрос был поставлен в очередь, а буфер отправки пуст, тогда мы закончили запись и нас интересуют только события чтения. Нет причин получать уведомление о том, что сокет доступен для записи.
Я завершу этот раздел, оставив вас с одной мыслью. Основной целью этого раздела было объяснить, что + selector.select () + вызывает класс + Message + через метод + process_events () +, и описать, как управляется состояние.
Это важно, потому что + process_events () + будет вызываться много раз в течение жизни соединения. Поэтому убедитесь, что любые методы, которые должны вызываться только один раз, либо сами проверяют переменную состояния, либо переменная состояния, установленная методом, проверяется вызывающей стороной.
Главный скрипт сервера
В основном скрипте сервера + app-server.py + аргументы считываются из командной строки, которые определяют интерфейс и порт для прослушивания:
$ ./app-server.py
usage: ./app-server.py <host> <port>Например, чтобы прослушивать интерфейс обратной связи на порту + 65432 +, введите:
$ ./app-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)Используйте пустую строку для + <host> + для прослушивания всех интерфейсов.
После создания сокета вызывается + socket.setsockopt () + с опцией + socket.SO_REUSEADDR +:
# Avoid bind() exception: OSError: [Errno 48] Address already in use
lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)Установка этой опции сокета позволяет избежать ошибки + Адрес уже используется +. Вы увидите это при запуске сервера, и ранее использованный сокет TCP на том же порту имеет соединения в http://www.serverframework.com/asynchronousevents/2011/01/time-wait-and-its-design-implications -for-протоколы-и-масштабируемые-серверы.html [TIME_WAIT] состояние.
Например, если сервер активно закрыл соединение, оно будет оставаться в состоянии «+ TIME_WAIT » в течение двух или более минут, в зависимости от операционной системы. Если вы попытаетесь запустить сервер еще раз до истечения состояния ` TIME_WAIT `, вы получите исключение ` OSError ` для ` Адрес уже используется +`. Это гарантия того, что любые задержанные пакеты в сети не будут доставлены не тому приложению.
Цикл обработки событий фиксирует любые ошибки, чтобы сервер мог оставаться в рабочем состоянии и продолжать работу:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()Когда клиентское соединение принято, создается объект + Message +:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)Объект + Message + связан с сокетом в вызове + sel.register () + и изначально настроен на мониторинг только для событий чтения. Как только запрос будет прочитан, мы изменим его, чтобы прослушивать только события записи.
Преимущество такого подхода на сервере заключается в том, что в большинстве случаев, когда сокет исправен и нет проблем с сетью, он всегда будет доступен для записи.
Если бы мы сказали + sel.register () + также контролировать + EVENT_WRITE +, цикл обработки событий немедленно активировался бы и уведомил нас, что это так. Однако в этот момент нет причин просыпаться и вызывать + send () + для сокета. Ответа нет, поскольку запрос еще не обработан. Это будет потреблять и тратить ценные циклы процессора.
Класс сообщения сервера
В ссылке на раздел: # message-entry-point [Точка входа в сообщение] мы рассмотрели, как объект + Message + был вызван в действие, когда события сокета были готовы через + process_events () +. Теперь давайте посмотрим, что происходит, когда данные считываются в сокет и компонент или часть сообщения готова для обработки сервером.
Класс сообщений сервера находится в + libserver.py +. Вы можете найти source код на GitHub.
Методы появляются в классе в том порядке, в котором происходит обработка сообщения.
Когда сервер прочитал как минимум 2 байта, заголовок фиксированной длины может быть обработан:
def process_protoheader(self):
hdrlen = 2
if len(self._recv_buffer) >= hdrlen:
self._jsonheader_len = struct.unpack('>H',
self._recv_buffer[:hdrlen])[0]
self._recv_buffer = self._recv_buffer[hdrlen:]Заголовок фиксированной длины представляет собой 2-байтовое целое число в сетевом порядке (с прямым порядком байтов), которое содержит длину заголовка JSON. https://docs.python.org/3/library/struct.html [struct.unpack ()] используется для чтения значения, его декодирования и сохранения в + self._jsonheader_len +. После обработки фрагмента сообщения, за которое он отвечает, + process_protoheader () + удаляет его из буфера приема.
Как и заголовок фиксированной длины, когда в буфере приема достаточно данных для заголовка JSON, он также может быть обработан:
def process_jsonheader(self):
hdrlen = self._jsonheader_len
if len(self._recv_buffer) >= hdrlen:
self.jsonheader = self._json_decode(self._recv_buffer[:hdrlen],
'utf-8')
self._recv_buffer = self._recv_buffer[hdrlen:]
for reqhdr in ('byteorder', 'content-length', 'content-type',
'content-encoding'):
if reqhdr not in self.jsonheader:
raise ValueError(f'Missing required header "{reqhdr}".')Метод + self._json_decode () + вызывается для декодирования и десериализации заголовка JSON в словарь. Поскольку заголовок JSON определен как Unicode с кодировкой UTF-8, в вызове жестко кодируется + utf-8 +. Результат сохраняется в + self.jsonheader +. После обработки фрагмента сообщения, за которое он отвечает, + process_jsonheader () + удаляет его из буфера приема.
Далее идет фактическое содержание или полезная нагрузка сообщения. Это описывается заголовком JSON в + self.jsonheader +. Когда байты + content-length + доступны в приемном буфере, запрос может быть обработан:
def process_request(self):
content_len = self.jsonheader['content-length']
if not len(self._recv_buffer) >= content_len:
return
data = self._recv_buffer[:content_len]
self._recv_buffer = self._recv_buffer[content_len:]
if self.jsonheader['content-type'] == 'text/json':
encoding = self.jsonheader['content-encoding']
self.request = self._json_decode(data, encoding)
print('received request', repr(self.request), 'from', self.addr)
else:
# Binary or unknown content-type
self.request = data
print(f'received {self.jsonheader["content-type"]} request from',
self.addr)
# Set selector to listen for write events, we're done reading.
self._set_selector_events_mask('w')После сохранения содержимого сообщения в переменную + data +, + process_request () + удаляет его из буфера приема. Затем, если тип контента JSON, он декодирует и десериализует его. Если это не так, для этого примера приложения предполагается, что это двоичный запрос, и просто печатается тип содержимого.
Последнее, что делает + process_request () +, это модифицирует селектор для мониторинга только событий записи. В основном сценарии сервера + app-server.py + сокет изначально настроен на мониторинг только событий чтения. Теперь, когда запрос был полностью обработан, мы больше не заинтересованы в чтении.
Теперь можно создать ответ и записать его в сокет. Когда сокет доступен для записи, + create_response () + вызывается из + write () +:
def create_response(self):
if self.jsonheader['content-type'] == 'text/json':
response = self._create_response_json_content()
else:
# Binary or unknown content-type
response = self._create_response_binary_content()
message = self._create_message(**response)
self.response_created = True
self._send_buffer += messageОтвет создается путем вызова других методов, в зависимости от типа содержимого. В этом примере приложения простой поиск по словарю выполняется для запросов JSON, когда + action == 'search' +. Вы можете определить другие методы для своих собственных приложений, которые вызываются здесь.
После создания ответного сообщения устанавливается переменная состояния + self.response_created +, поэтому + write () + больше не вызывает + create_response () +. Наконец, ответ добавляется в буфер отправки. Это видно и отправлено через + _write () +.
Один хитрый момент, который нужно выяснить, - как закрыть соединение после написания ответа. Я поместил вызов + close () + в методе + _write () +:
def _write(self):
if self._send_buffer:
print('sending', repr(self._send_buffer), 'to', self.addr)
try:
# Should be ready to write
sent = self.sock.send(self._send_buffer)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
self._send_buffer = self._send_buffer[sent:]
# Close when the buffer is drained. The response has been sent.
if sent and not self._send_buffer:
self.close()Хотя это несколько «скрыто», я думаю, что это приемлемый компромисс, учитывая, что класс «+ Message +» обрабатывает только одно сообщение на соединение. После того как ответ написан, серверу ничего не остается сделать. Он завершил свою работу.
Основной скрипт клиента
В основном скрипте клиента + app-client.py + аргументы считываются из командной строки и используются для создания запросов и запуска соединений с сервером:
$ ./app-client.py
usage: ./app-client.py <host> <port> <action> <value>Вот пример:
$ ./app-client.py 127.0.0.1 65432 search needleПосле создания словаря, представляющего запрос из аргументов командной строки, хост, порт и словарь запроса передаются в + start_connection () +:
def start_connection(host, port, request):
addr = (host, port)
print('starting connection to', addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
message = libclient.Message(sel, sock, addr, request)
sel.register(sock, events, data=message)Для соединения с сервером создается сокет, а также объект + Message + с использованием словаря + request +.
Как и сервер, объект + Message + связан с сокетом при вызове + sel.register () +. Однако для клиента сокет изначально настроен на мониторинг событий чтения и записи. Как только запрос будет написан, мы изменим его, чтобы прослушивать только события чтения.
Такой подход дает нам то же преимущество, что и сервер: не тратить время процессора. После того, как запрос был отправлен, мы больше не интересуемся записью событий, поэтому нет причин просыпаться и обрабатывать их.
Класс сообщения клиента
В ссылке на раздел: # message-entry-point [Точка входа в сообщение] мы рассмотрели, как объект сообщения вызывался в действии, когда события сокета были готовы через + process_events () +. Теперь давайте посмотрим, что происходит после того, как данные прочитаны и записаны в сокет, и сообщение готово для обработки клиентом.
Класс сообщений клиента находится в + libclient.py +. Вы можете найти source код на GitHub.
Методы появляются в классе в том порядке, в котором происходит обработка сообщения.
Первая задача для клиента - поставить запрос в очередь:
def queue_request(self):
content = self.request['content']
content_type = self.request['type']
content_encoding = self.request['encoding']
if content_type == 'text/json':
req = {
'content_bytes': self._json_encode(content, content_encoding),
'content_type': content_type,
'content_encoding': content_encoding
}
else:
req = {
'content_bytes': content,
'content_type': content_type,
'content_encoding': content_encoding
}
message = self._create_message(**req)
self._send_buffer += message
self._request_queued = TrueСловари, используемые для создания запроса, в зависимости от того, что было передано в командной строке, находятся в основном скрипте клиента, + app-client.py +. Словарь запроса передается классу в качестве аргумента при создании объекта + Message +.
Сообщение запроса создается и добавляется в буфер отправки, который затем просматривается и отправляется с помощью + _write () +. Переменная состояния + self._request_queued + установлена так, что + queue_request () + больше не вызывается.
После того, как запрос был отправлен, клиент ожидает ответа от сервера.
Способы чтения и обработки сообщения на клиенте такие же, как на сервере. Когда данные ответа считываются из сокета, вызываются методы заголовка + process +: + process_protoheader () + и + process_jsonheader () +.
Разница заключается в именовании окончательных методов + process + и в том, что они обрабатывают ответ, а не создают его: + process_response () +, + _process_response_json_content () + и `+ _process_response_binary_content ( ) + `.
И последнее, но не менее важное, это последний вызов + process_response () +:
def process_response(self):
# ...
# Close when response has been processed
self.close()Заключение класса сообщений
Я завершу обсуждение класса «+ Message +», упомянув пару вещей, которые важно заметить с помощью нескольких поддерживающих методов.
Любые исключения, вызванные классом, перехватываются главным скриптом в его предложении + кроме +:
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()Обратите внимание на последнюю строку: + message.close () +.
Это действительно важная линия по нескольким причинам! Он не только гарантирует, что сокет закрыт, но + message.close () + также удаляет сокет из списка + select () +. Это значительно упрощает код в классе и уменьшает сложность. Если есть исключение или мы явно вызываем его сами, мы знаем, что + close () + позаботится об очистке.
Методы + Message._read () + и + Message._write () + также содержат что-то интересное:
def _read(self):
try:
# Should be ready to read
data = self.sock.recv(4096)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
if data:
self._recv_buffer += data
else:
raise RuntimeError('Peer closed.')Обратите внимание на строку + кроме +: + кроме BlockingIOError: +.
У + _write () + тоже есть. Эти строки важны, потому что они ловят временную ошибку и пропускают ее, используя + pass +. Временная ошибка возникает, когда сокет связывает: # blocking-Call [block], например, если он ожидает в сети или на другом конце соединения (его одноранговый узел).
Перехватывая и пропуская исключение с помощью + pass +, + select () + в конечном итоге снова вызовет нас, и мы получим еще один шанс прочитать или записать данные.
Запуск приложения-клиента и сервера
После всей этой тяжелой работы давайте повеселимся и начнем поиски!
В этих примерах я запускаю сервер, чтобы он прослушивал все интерфейсы, передавая пустую строку для аргумента + host +. Это позволит мне запустить клиент и подключиться с виртуальной машины, которая находится в другой сети. Он эмулирует машину PowerPC с прямым порядком байтов.
Во-первых, давайте запустим сервер:
$ ./app-server.py '' 65432
listening on ('', 65432)Теперь давайте запустим клиент и введем поиск. Давайте посмотрим, сможем ли мы найти его:
$ ./app-client.py 10.0.1.1 65432 search morpheus
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432)
received response {'result': 'Follow the white rabbit. ????'} from ('10.0.1.1', 65432)
got result: Follow the white rabbit. ????
closing connection to ('10.0.1.1', 65432)В моем терминале запущена оболочка с текстовой кодировкой Unicode (UTF-8), поэтому вышеприведенный вывод хорошо печатается с помощью emojis.
Давайте посмотрим, сможем ли мы найти щенков:
$ ./app-client.py 10.0.1.1 65432 search ????
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
received response {'result': '???? Playing ball! ????'} from ('10.0.1.1', 65432)
got result: ???? Playing ball! ????
closing connection to ('10.0.1.1', 65432)Обратите внимание на строку байтов, отправленную по сети для запроса, в строке + send +. Проще увидеть, если вы ищите байты, напечатанные в шестнадцатеричном формате, которые представляют смайлики щенка: + \ xf0 \ x9f \ x90 \ xb6 +. Я смог enter emoji для поиска, так как мой терминал использует Unicode с кодировкой UTF-8.
Это показывает, что мы отправляем необработанные байты по сети, и они должны быть декодированы получателем для правильной интерпретации. Вот почему мы пошли на все проблемы, чтобы создать заголовок, который содержит тип содержимого и кодировку.
Вот выходные данные сервера из обоих клиентских подключений выше:
accepted connection from ('10.0.2.2', 55340)
received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
closing connection to ('10.0.2.2', 55340)
accepted connection from ('10.0.2.2', 55338)
received request {'action': 'search', 'value': '????'} from ('10.0.2.2', 55338)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
closing connection to ('10.0.2.2', 55338)Посмотрите на строку + send +, чтобы увидеть байты, которые были записаны в сокет клиента. Это ответное сообщение сервера.
Вы также можете проверить отправку двоичных запросов на сервер, если аргумент + action + отличается от + search +:
$ ./app-client.py 10.0.1.1 65432 binary ????
starting connection to ('10.0.1.1', 65432)
sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
closing connection to ('10.0.1.1', 65432)Поскольку запрос + content-type + не является + text/json +, сервер обрабатывает его как пользовательский двоичный тип и не выполняет JSON-декодирование. Он просто печатает + content-type + и возвращает первые 10 байтов клиенту:
$ ./app-server.py '' 65432
listening on ('', 65432)
accepted connection from ('10.0.2.2', 55320)
received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
closing connection to ('10.0.2.2', 55320)Поиск проблемы
Неизбежно, что-то не сработает, и вам будет интересно, что делать. Не волнуйся, это случается со всеми нами. Надеемся, что с помощью этого руководства, вашего отладчика и любимой поисковой системы вы сможете снова начать работу с частью исходного кода.
Если нет, то вашей первой остановкой должна стать документация Python socket module. Убедитесь, что вы прочитали всю документацию для каждой функции или метода, который вы вызываете. Кроме того, прочитайте ссылку: #reference [Ссылка] раздел для идей. В частности, проверьте ссылку: #errors [Errors] раздел.
Иногда дело не только в исходном коде. Исходный код может быть правильным, и это просто другой хост, клиент или сервер. Или это может быть сеть, например, маршрутизатор, брандмауэр или какое-то другое сетевое устройство, играющее «человек посередине».
Для этих типов проблем необходимы дополнительные инструменты. Ниже приведены несколько инструментов и утилит, которые могут помочь или, по крайней мере, предоставить некоторые подсказки.
ping
+ ping + проверит, если хост жив и подключен к сети, отправив эхо-запрос ICMP. Он напрямую связывается со стеком протоколов TCP/IP операционной системы, поэтому он работает независимо от любого приложения, работающего на хосте.
Ниже приведен пример запуска ping на macOS:
$ ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 msОбратите внимание на статистику в конце вывода. Это может быть полезно, когда вы пытаетесь обнаружить периодически возникающие проблемы с подключением. Например, есть ли потеря пакетов? Сколько существует задержка (см. Время туда-обратно)?
Если между вами и другим хостом установлен брандмауэр, эхо-запрос эхо-запроса может быть запрещен. Некоторые администраторы брандмауэра реализуют политики, обеспечивающие это. Идея в том, что они не хотят, чтобы их хосты были доступны для обнаружения. Если это так, и вы добавили правила брандмауэра, чтобы узлы могли обмениваться данными, убедитесь, что правила также позволяют ICMP проходить между ними.
ICMP - это протокол, используемый + ping +, но также протокол TCP и другие протоколы более низкого уровня, используемые для передачи сообщений об ошибках. Если вы испытываете странное поведение или медленные соединения, это может быть причиной.
Сообщения ICMP идентифицируются по типу и коду. Чтобы дать вам представление о важной информации, которую они несут, вот некоторые из них:
| ICMP Type | ICMP Code | Description |
|---|---|---|
8 |
0 |
Echo request |
0 |
0 |
Echo reply |
3 |
0 |
Destination network unreachable |
3 |
1 |
Destination host unreachable |
3 |
2 |
Destination protocol unreachable |
3 |
3 |
Destination port unreachable |
3 |
4 |
Fragmentation required, and DF flag set |
11 |
0 |
TTL expired in transit |
См. Статью Path[Path MTU Discovery для получения информации о фрагментации и сообщениях ICMP. Это пример чего-то, что может вызвать странное поведение, о котором я упоминал ранее.
NetStat
В ссылке на раздел: # view-socket-state [Просмотр состояния сокета] мы рассмотрели, как + netstat + можно использовать для отображения информации о сокетах и их текущем состоянии. Эта утилита доступна в macOS, Linux и Windows.
Я не упоминал столбцы + Recv-Q + и + Send-Q + в выходных данных примера. В этих столбцах будет показано количество байтов, которые хранятся в сетевых буферах, которые находятся в очереди для передачи или получения, но по какой-то причине не были прочитаны или записаны удаленным или локальным приложением.
Другими словами, байты ожидают в сетевых буферах в очередях операционной системы. Одной из причин может быть то, что приложение связано с процессором или не может вызвать + socket.recv () + или + socket.send () + и обработать байты. Или могут быть проблемы с сетью, влияющие на связь, такие как перегрузка или сбой сетевого оборудования или кабелей.
Чтобы продемонстрировать это и увидеть, сколько данных я могу отправить до появления ошибки, я написал тестовый клиент, который подключается к тестовому серверу и многократно вызывает + socket.send () +. Тестовый сервер никогда не вызывает + socket.recv () +. Он просто принимает соединение. Это приводит к заполнению сетевых буферов на сервере, что в конечном итоге приводит к ошибке на клиенте.
Сначала я запустил сервер:
$ ./app-server-test.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)Затем я запустил клиент. Давайте посмотрим, в чем ошибка:
$ ./app-client-test.py 127.0.0.1 65432 binary test
error: socket.send() blocking io exception for ('127.0.0.1', 65432):
BlockingIOError(35, 'Resource temporarily unavailable')Вот вывод + netstat +, в то время как клиент и сервер все еще работали, с клиентом, выводящим сообщение об ошибке выше несколько раз:
$ netstat -an | grep 65432
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
tcp4 0 0 127.0.0.1.65432 *.* LISTENПервая запись - это сервер (+ Local Address + имеет порт 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHEDОбратите внимание на + Recv-Q +: + 408300 +.
Вторая запись - это клиент (+ Foreign Address + имеет порт 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHEDОбратите внимание на + Send-Q +: + 269868 +.
Конечно, клиент пытался записать байты, но сервер их не читал. Это привело к тому, что очередь сетевого буфера сервера заполнялась на стороне приема, а очередь сетевого буфера клиента заполнялась на стороне отправки.
Windows
Если вы работаете с Windows, есть набор утилит, которые вы обязательно должны проверить, если вы еще этого не сделали: Windows Sysinternals.
Одним из них является + TCPView.exe +. TCPView является графическим + netstat + для Windows. В дополнение к адресам, номерам портов и состоянию сокета, он покажет вам промежуточные итоги для количества пакетов и байтов, отправленных и полученных. Как и утилита Unix + lsof +, вы также получаете имя и идентификатор процесса. Проверьте меню для других вариантов отображения.
Wireshark
Иногда вам нужно посмотреть, что происходит на проводе. Забудьте о том, что говорит журнал приложения или каково значение, которое возвращается из библиотечного вызова. Вы хотите увидеть, что на самом деле отправляется или принимается в сети. Так же, как отладчики, когда вам нужно это увидеть, нет замены.
Wireshark - это анализатор сетевых протоколов и приложение для захвата трафика, которое работает в MacOS, Linux и Windows и других. Существует версия графического интерфейса с именем + wireshark +, а также терминальная текстовая версия с именем + tshark +.
Выполнение захвата трафика - отличный способ наблюдать за тем, как приложение ведет себя в сети, и собирать данные о том, что оно отправляет и получает, как часто и как много. Вы также сможете увидеть, когда клиент или сервер закрывает или прерывает соединение или перестает отвечать на запросы. Эта информация может быть чрезвычайно полезна при устранении неполадок.
В Интернете есть много хороших учебных пособий и других ресурсов, которые познакомят вас с основами использования Wireshark и TShark.
Вот пример захвата трафика с использованием Wireshark на интерфейсе обратной связи:
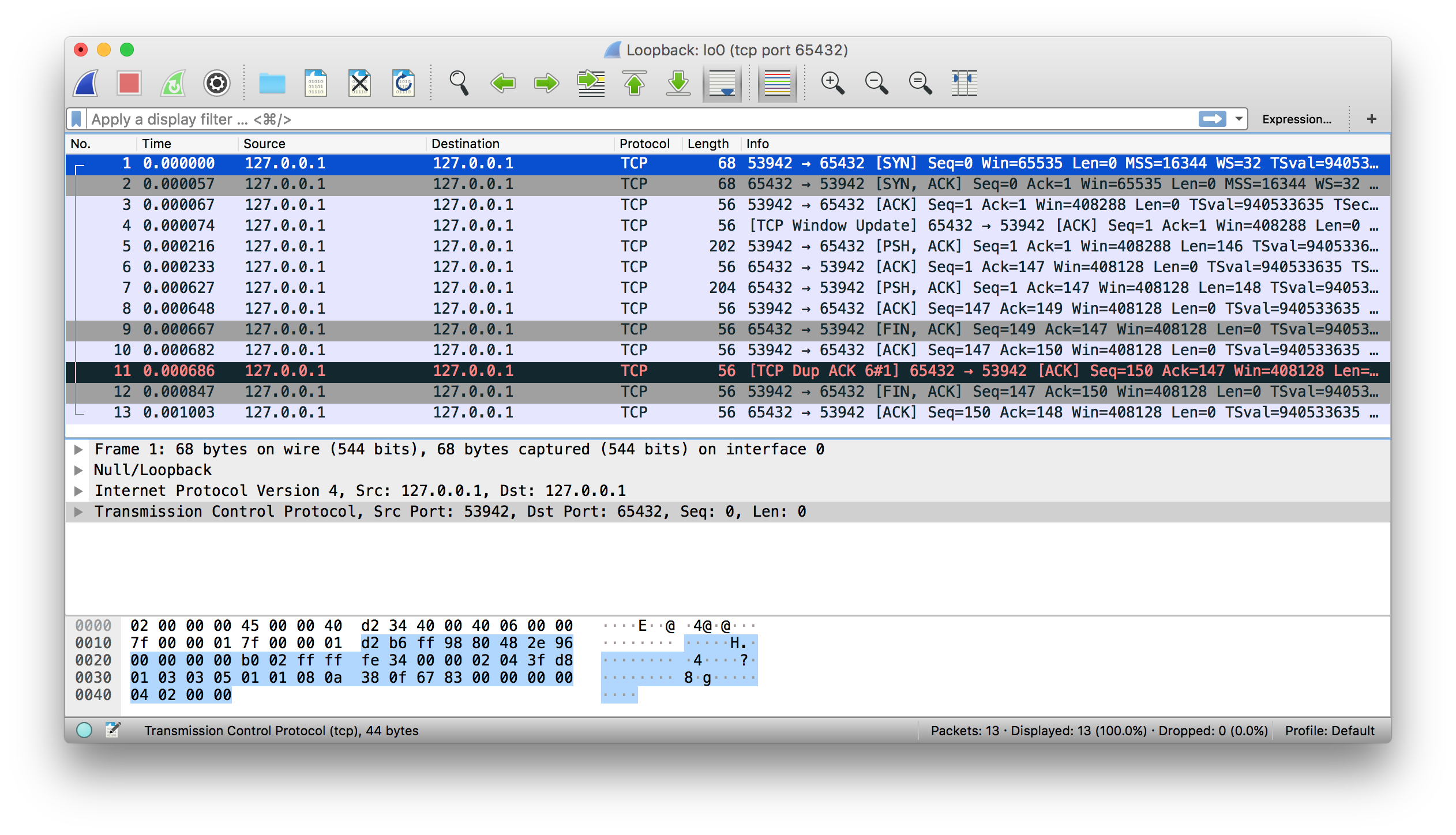
Вот тот же пример, показанный выше с использованием + tshark +:
$ tshark -i lo0 'tcp port 65432'
Capturing on 'Loopback'
1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1
2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1
3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635
6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635
8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635
9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635
^C13 packets capturedСсылка
Этот раздел служит общей ссылкой с дополнительной информацией и ссылками на внешние ресурсы.
Документация Python
-
Https://docs.python.org/3/library/socket.html[socket модуль Python]
-
Https://docs.python.org/3/howto/sockets.html#socket-howto[Socket Programming HOWTO Python’s]
ошибки
Следующее из документации модуля + socket + в Python:
_
«Все ошибки вызывают исключения. Нормальные исключения для недопустимых типов аргументов и условий нехватки памяти могут быть вызваны; начиная с Python 3.3, ошибки, связанные с семантикой сокетов или адресов, приводят к + OSError + или одному из его подклассов. ” (Source)
_
Вот некоторые распространенные ошибки, с которыми вы, вероятно, столкнетесь при работе с сокетами:
| Exception | errno Constant |
Description |
|---|---|---|
BlockingIOError |
EWOULDBLOCK |
Resource temporarily unavailable. For example, in non-blocking mode, when calling |
OSError |
EADDRINUSE |
Address already in use. Make sure there’s not another process running that’s using the same port number and your server is setting the socket option |
ConnectionResetError |
ECONNRESET |
Connection reset by peer. The remote process crashed or did not close its socket properly (unclean shutdown). Or there’s a firewall or other device in the network path that’s missing rules or misbehaving. |
TimeoutError |
ETIMEDOUT |
Operation timed out. No response from peer. |
ConnectionRefusedError |
ECONNREFUSED |
Connection refused. No application listening on specified port. |
Семейство адресов с сокетами
+ socket.AF_INET + и + socket.AF_INET6 + представляют адреса и семейства протоколов, используемые для первого аргумента + socket.socket () +. API, которые используют адрес, ожидают, что он будет в определенном формате, в зависимости от того, был ли сокет создан с помощью + socket.AF_INET + или + socket.AF_INET6 +.
| Address Family | Protocol | Address Tuple | Description |
|---|---|---|---|
|
IPv4 |
|
|
|
IPv6 |
|
|
Обратите внимание на приведенную ниже выдержку из документации модуля сокетов Python относительно значения + host + для кортежа адресов:
_
«Для адресов IPv4 вместо адреса хоста принимаются две специальные формы: пустая строка представляет` + INADDR_ANY + , а строка + '<broadcast>' + представляет + INADDR_BROADCAST + `. Такое поведение несовместимо с IPv6, поэтому вы можете избежать этого, если намереваетесь поддерживать IPv6 с вашими программами Python ». (Source)
_
Смотрите Python Socket семейства документации для получения дополнительной информации.
Я использовал сокеты IPv4 в этом руководстве, но если ваша сеть поддерживает это, попробуйте протестировать и использовать IPv6, если это возможно. Один из способов легко это сделать - использовать функцию https://docs.python.org/3/library/socket.html#socket.getaddrinfo [socket.getaddrinfo ()]. Он переводит аргументы + host + и + port + в последовательность из 5 кортежей, которая содержит все необходимые аргументы для создания сокета, подключенного к этому сервису. + socket.getaddrinfo () + будет понимать и интерпретировать переданные IPv6-адреса и имена хостов, которые преобразуются в IPv6-адреса, в дополнение к IPv4.
В следующем примере информация об адресе для TCP-соединения возвращается в + example.org + через порт + 80 +
>>>
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP)
[(<AddressFamily.AF_INET6: 10>, <SocketType.SOCK_STREAM: 1>,
6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)),
(<AddressFamily.AF_INET: 2>, <SocketType.SOCK_STREAM: 1>,
6, '', ('93.184.216.34', 80))]Результаты могут отличаться в вашей системе, если IPv6 не включен. Возвращенные выше значения можно использовать, передав их в + socket.socket () + и + socket.connect () +. Пример клиента и сервера приведен в разделе Example документации по модулю сокетов Python.
Использование имен хостов
Для контекста этот раздел в основном применяется к использованию имен хостов с + bind () + и + connect () + или + connect_ex () +), когда вы собираетесь использовать интерфейс обратной петли «localhost». Тем не менее, он применяется всякий раз, когда вы используете имя хоста, и ожидается, что оно разрешится по определенному адресу и будет иметь особое значение для вашего приложения, которое влияет на его поведение или предположения. Это отличается от типичного сценария, когда клиент использует имя хоста для подключения к серверу, который разрешен DNS, например, www.example.com.
Следующее из документации модуля + socket + в Python:
_ «Если вы используете имя хоста в части хоста адреса сокета IPv4/v6, программа может показывать недетерминированное поведение, так как Python использует первый адрес, возвращенный из разрешения DNS. Адрес сокета будет по-разному преобразован в фактический адрес IPv4/v6, в зависимости от результатов разрешения DNS и/или конфигурации хоста. Для детерминированного поведения используйте числовой адрес в части хоста ». (Source) _
- Стандартное соглашение для имени «https://en.wikipedia.org/wiki/Localhost[localhost]» предусматривает разрешение на «+ 127.0.0.1 » или «
-
1 +», интерфейс обратной петли. Это, скорее всего, будет иметь место для вас в вашей системе, но, возможно, нет. Это зависит от того, как ваша система настроена для разрешения имен. Как и во всем, что касается ИТ, всегда есть исключения, и нет никаких гарантий, что использование имени «localhost» будет подключаться к интерфейсу обратной связи.
Например, в Linux см. + Man nsswitch.conf +, файл конфигурации переключателя службы имен. Еще одно место для проверки в macOS и Linux - файл +/etc/hosts +. В Windows смотрите + C: \ Windows \ System32 \ drivers \ etc \ hosts +. Файл + hosts + содержит статическую таблицу имен для сопоставления адресов в простом текстовом формате. DNS - еще одна часть головоломки.
Интересно, что на момент написания этой статьи (июнь 2018 года) есть проект RFC Let 'localhost' be localhost , в котором обсуждаются условные обозначения, предположения и безопасность, связанные с использованием названия «localhost».
Важно понимать, что когда вы используете имена хостов в своем приложении, возвращаемый адрес (адреса) может быть буквально любым. Не делайте предположений относительно имени, если у вас есть приложение, чувствительное к безопасности. В зависимости от вашего приложения и среды, это может или не может беспокоить вас.
*Примечание:* Меры предосторожности и лучшие практики по-прежнему применяются, даже если ваше приложение не «чувствительно к безопасности». Если ваше приложение обращается к сети, оно должно быть защищено и поддержано. Это означает, как минимум:
-
Системные обновления программного обеспечения и исправления безопасности применяются регулярно, включая Python. Вы используете сторонние библиотеки? Если это так, убедитесь, что они также проверены и обновлены.
-
Если возможно, используйте выделенный или основанный на хосте брандмауэр, чтобы ограничить подключения только к доверенным системам.
-
Какие DNS-серверы настроены? Вы доверяете им и их администраторам?
-
Перед тем, как вызывать другой код, обрабатывающий эти данные, убедитесь, что данные запроса максимально проверены и проверены. Используйте (нечеткие) тесты для этого и регулярно запускайте их.
Независимо от того, используете ли вы имена хостов, если ваше приложение должно поддерживать безопасные соединения (шифрование и аутентификация), вы, вероятно, захотите изучить использование TLS , Это отдельная тема, выходящая за рамки данного руководства. Для начала ознакомьтесь с документацией по Python ssl module. Это тот же протокол, который используется вашим веб-браузером для безопасного подключения к веб-сайтам.
С учетом интерфейсов, IP-адресов и разрешения имен существует много переменных. Что вы должны сделать? Вот несколько рекомендаций, которые вы можете использовать, если у вас нет процесса рассмотрения сетевых приложений:
| Application | Usage | Recommendation |
|---|---|---|
Server |
loopback interface |
Use an IP address, for example, |
Server |
ethernet interface |
Use an IP address, for example, |
Client |
loopback interface |
Use an IP address, for example, |
Client |
ethernet interface |
Use an IP address for consistency and non-reliance on name resolution. For the typical case, use a hostname. See the security note above. |
Для клиентов или серверов, если вам нужно аутентифицировать хост, к которому вы подключаетесь, изучите использование TLS.
Блокировка звонков
Функция сокета или метод, который временно приостанавливает ваше приложение, является блокирующим вызовом. Например, + accept () +, + connect () +, + send () + и + recv () + “block”). Они не возвращаются сразу. Блокирующие вызовы должны ждать завершения системных вызовов (I/O), прежде чем они смогут вернуть значение. Таким образом, вы, вызывающий абонент, блокируетесь до тех пор, пока они не завершат работу или не произойдет таймаут или другая ошибка.
Блокирующие вызовы сокетов могут быть установлены в неблокирующий режим, поэтому они немедленно возвращаются. Если вы сделаете это, вам потребуется как минимум рефакторинг или редизайн вашего приложения для обработки операции сокета, когда она будет готова.
Поскольку вызов немедленно возвращается, данные могут быть не готовы. Вызываемый ожидает в сети и не успел завершить свою работу. Если это так, текущим статусом является + errno + значение + socket.EWOULDBLOCK +. Неблокирующий режим поддерживается с помощью https://docs.python.org/3/library/socket.html#socket.socket.setblocking [setblocking ()].
По умолчанию сокеты всегда создаются в режиме блокировки. См. Https://docs.python.org/3/library/socket.html#notes-on-socket-timeouts[Notes на время ожидания сокета] для описания трех режимов.
Закрытие соединения
Интересно отметить, что для TCP или клиента вполне законно закрывать свою сторону соединения, в то время как другая сторона остается открытой. Это называется «полуоткрытым» соединением. Решение приложения является желательным или нет. В общем, это не так. В этом состоянии сторона, которая закрыла свой конец соединения, больше не может отправлять данные. Они могут только получить это.
Я не рекомендую использовать этот подход, но в качестве примера HTTP использует заголовок с именем «Соединение», который используется для стандартизации того, как приложения должны закрывать или сохранять открытые соединения. Для получения дополнительной информации см. Https://tools.ietf.org/html/rfc7230#section-6.3[section 6.3 в RFC 7230, Протокол передачи гипертекста (HTTP/1.1): синтаксис сообщения и маршрутизация].
При разработке и написании вашего приложения и его протокола уровня приложений хорошей идеей будет пойти дальше и выяснить, как вы ожидаете, что соединения будут закрыты. Иногда это очевидно и просто, или это то, что может потребовать некоторого первоначального прототипирования и тестирования. Это зависит от приложения и способа обработки цикла сообщений с ожидаемыми данными. Просто убедитесь, что розетки всегда закрыты своевременно после завершения работы.
Байтовый порядок
См. Https://en.wikipedia.org/wiki/Endianness[Wikipedia статью о порядке байтов], чтобы узнать, как разные процессоры хранят порядок байтов в памяти. При интерпретации отдельных байтов это не проблема. Однако при обработке нескольких байтов, которые считываются и обрабатываются как одно значение, например 4-байтовое целое число, порядок следования байтов должен быть обратным, если вы общаетесь с машиной, которая использует другой порядок байтов.
Порядок байтов также важен для текстовых строк, которые представлены в виде многобайтовых последовательностей, таких как Юникод. Если вы не всегда используете «true», строгий ASCII и управляете реализациями клиента и сервера, вам, вероятно, лучше использовать Unicode с кодировкой, подобной UTF-8 или тот, который поддерживает метку заказа byte (BOM).
Важно четко определить кодировку, используемую в протоколе уровня приложения. Вы можете сделать это, указав, что весь текст имеет формат UTF-8 или используя заголовок «content-encoding», который задает кодировку. Это препятствует тому, чтобы ваше приложение обнаружило кодировку, которую вы должны избегать, если это возможно.
Это становится проблематичным, когда имеются данные, которые хранятся в файлах или базе данных, и нет доступных метаданных, определяющих их кодировку. Когда данные передаются в другую конечную точку, она должна попытаться определить кодировку. Для обсуждения см. Https://en.wikipedia.org/wiki/Unicode[Wikipedia статью Unicode], в которой содержится ссылка на RFC 3629: UTF-8, формат преобразования ISO 10646:
_ «Однако RFC 3629, стандарт UTF-8, рекомендует запрещать метки порядка байтов в протоколах, использующих UTF-8, но обсуждает случаи, когда это может быть невозможно. Кроме того, большое ограничение на возможные шаблоны в UTF-8 (например, не может быть никаких одиночных байтов с установленным старшим битом) означает, что должна быть возможность отличить UTF-8 от других кодировок символов, не полагаясь на BOM ». (Source) _
Вывод из этого заключается в том, чтобы всегда хранить кодировку, используемую для данных, обрабатываемых вашим приложением, если она может варьироваться. Другими словами, попытайтесь как-то сохранить кодировку в виде метаданных, если это не всегда UTF-8 или какая-либо другая кодировка с спецификацией. Затем вы можете отправить эту кодировку в заголовке вместе с данными, чтобы сообщить получателю, что это такое.
Порядок байтов, используемый в TCP/IP, называется big-endian и называется сетевым порядком. Сетевой порядок используется для представления целых чисел на нижних уровнях стека протоколов, таких как IP-адреса и номера портов. Модуль сокетов Python включает в себя функции, которые преобразуют целые числа в сетевой и из байтовых порядков:
| Function | Description |
|---|---|
|
Convert 32-bit positive integers from network to host byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 4-byte swap operation. |
|
Convert 16-bit positive integers from network to host byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 2-byte swap operation. |
|
Convert 32-bit positive integers from host to network byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 4-byte swap operation. |
|
Convert 16-bit positive integers from host to network byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 2-byte swap operation. |
Вы также можете использовать struct module для упаковки и распаковки двоичных данных, используя строки формата:
import struct
network_byteorder_int = struct.pack('>H', 256)
python_int = struct.unpack('>H', network_byteorder_int)[0]Заключение
Мы рассмотрели много вопросов в этом уроке. Сеть и розетки - это большие предметы. Если вы плохо знакомы с сетью или сокетами, не расстраивайтесь от всех терминов и сокращений.
Есть много вещей, с которыми нужно ознакомиться, чтобы понять, как все работает вместе. Однако, как и в Python, он станет более понятным, когда вы узнаете отдельные части и будете проводить с ними больше времени.
Мы рассмотрели низкоуровневый API сокетов в модуле Python + socket + и увидели, как его можно использовать для создания клиент-серверных приложений. Мы также создали наш собственный класс и использовали его в качестве протокола прикладного уровня для обмена сообщениями и данными между конечными точками. Вы можете использовать этот класс и использовать его для изучения и помощи в создании и упрощении создания собственных приложений для сокетов.
Вы можете найти source код на GitHub.
Поздравляем с завершением! Теперь вы уже на пути к использованию сокетов в своих приложениях.
Я надеюсь, что это руководство дало вам информацию, примеры и вдохновение, необходимые для того, чтобы начать вас в процессе разработки сокетов.