Itertools в Python 3, на примере
Он был назван“gem” и“pretty much the coolest thing ever,”, и если вы не слышали о нем, то вы упускаете один из величайших уголков стандартной библиотеки Python 3:itertools.
Существует несколько отличных ресурсов для изучения того, какие функции доступны в модулеitertools. Самиdocs - отличное место для начала. Как иthis post.
Однако проблемаitertools заключается в том, что недостаточно просто знать определения содержащихся в нем функций. Настоящая сила заключается в составлении этих функций для создания быстрого, эффективного по памяти и красивого кода.
Эта статья использует другой подход. Вместо того, чтобы знакомить вас сitertools по одной функции за раз, вы будете создавать практические примеры, призванные побудить вас «думать итеративно». В общем, сначала примеры будут простыми, а их сложность будет постепенно увеличиваться.
Предупреждение: эта статья длинная и предназначена для среднего и продвинутого программиста Python. Перед погружением вы должны быть уверены в использовании итераторов и генераторов в Python 3, множественных назначений и распаковки кортежей. Если вы этого не делаете, или если вам нужно освежить свои знания, попробуйте проверить следующее, прежде чем читать дальше:
Free Bonus:Click here to get our itertools cheat sheet, в котором резюмируются методы, продемонстрированные в этом руководстве.
Все готово? Давайте начнем с любого хорошего путешествия - с вопроса.
Что такоеItertools и почему вы должны его использовать?
Согласноitertools docs, это «модуль, [который] реализует ряд строительных блоков итераторов, вдохновленных конструкциями из APL, Haskell и SML… Вместе они образуют« алгебру итераторов », позволяющую создавать специализированные инструменты кратко и эффективно на чистом Python ».
Грубо говоря, это означает, что функции вitertools «работают» с итераторами, создавая более сложные итераторы. Рассмотрим, например,built-in zip() function, который принимает любое количество итераций в качестве аргументов и возвращает итератор по кортежам соответствующих им элементов:
>>>
>>> list(zip([1, 2, 3], ['a', 'b', 'c']))
[(1, 'a'), (2, 'b'), (3, 'c')]Как именно работаетzip()?
[1, 2, 3] и['a', 'b', 'c'], как и все списки, являются повторяемыми, что означает, что они могут возвращать свои элементы по одному. Технически любой объект Python, реализующий методы.__iter__() или.__getitem__(), является итеративным. (См.Python 3 docs glossary для более подробного объяснения.)
iter() built-in function, когда вызывается на итерации, возвращаетiterator object для этой итерации:
>>>
>>> iter([1, 2, 3, 4])
Под капотом функцияzip() работает, по сути, путем вызоваiter() для каждого из своих аргументов, затем продвижения каждого итератора, возвращаемогоiter(), с помощьюnext() и агрегирования результатов в кортежи. Итератор, возвращаемыйzip(), выполняет итерацию по этим кортежам.
The map() built-in function - еще один «оператор итератора», который в своей простейшей форме применяет однопараметрическую функцию к каждому элементу итерируемого по одному элементу за раз:
>>>
>>> list(map(len, ['abc', 'de', 'fghi']))
[3, 2, 4]Функцияmap() работает, вызываяiter() для второго аргумента, продвигая этот итератор с помощьюnext() до тех пор, пока итератор не будет исчерпан, и применяя функцию, переданную ее первому аргументу, к значению, возвращаемомуnext() на каждом шаге. В приведенном выше примереlen() вызывается для каждого элемента['abc', 'de', 'fghi'], чтобы вернуть итератор по длине каждой строки в списке.
Посколькуiterators are iterable, вы можете составитьzip() иmap(), чтобы создать итератор по комбинациям элементов в более чем одной итерации. Например, следующие суммы суммируют соответствующие элементы двух списков:
>>>
>>> list(map(sum, zip([1, 2, 3], [4, 5, 6])))
[5, 7, 9]Это то, что подразумевается под функциями вitertools, образующими «алгебру итераторов». itertools лучше всего рассматривать как набор строительных блоков, которые можно комбинировать для формирования специализированных «конвейеров данных», подобных показанному в примере выше.
Historical Note: В Python 2 встроенные функции
zip()иmap()возвращают не итератор, а список. Чтобы вернуть итератор, необходимо использовать функцииizip()иimap()изitertools. В Python 3izip()иimap()былиremoved fromitertoolsи заменили встроенные модулиzip()иmap(). В некотором смысле, если вы когда-либо использовалиzip()илиmap()в Python 3, вы уже использовалиitertools!
Есть две основные причины, по которым такая «алгебра итераторов» полезна: улучшенная эффективность памяти (черезlazy evaluation) и более быстрое время выполнения. Чтобы увидеть это, рассмотрим следующую проблему:
Учитывая список значений
inputsи положительное целое числоn, напишите функцию, которая разбиваетinputsна группы длинойn. Для простоты предположим, что длина входного списка делится наn. Например, еслиinputs = [1, 2, 3, 4, 5, 6]иn = 2, ваша функция должна вернуть[(1, 2), (3, 4), (5, 6)].
Используя наивный подход, вы можете написать что-то вроде этого:
def naive_grouper(inputs, n):
num_groups = len(inputs) // n
return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)]Когда вы проверяете его, вы видите, что он работает как положено:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> naive_grouper(nums, 2)
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]Что происходит, когда вы пытаетесь передать ему список, скажем, со 100 миллионами элементов? Вам понадобится много доступной памяти! Даже если у вас достаточно памяти, ваша программа будет зависать некоторое время, пока не будет заполнен список вывода.
Чтобы увидеть это, сохраните следующее в скрипте под названиемnaive.py:
def naive_grouper(inputs, n):
num_groups = len(inputs) // n
return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)]
for _ in naive_grouper(range(100000000), 10):
passС консоли вы можете использовать командуtime (в системах UNIX) для измерения использования памяти и пользовательского времени процессора. Make sure you have at least 5GB of free memory before executing the following:
$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 naive.py
Memory used (kB): 4551872
User time (seconds): 11.04Note: В Ubuntu вам может потребоваться запустить
/usr/bin/timeвместоtime, чтобы приведенный выше пример работал.
Реализацияlist иtuple вnaive_grouper() требует примерно 4,5 ГБ памяти для обработкиrange(100000000). Работа с итераторами значительно улучшает эту ситуацию. Учтите следующее:
def better_grouper(inputs, n):
iters = [iter(inputs)] * n
return zip(*iters)В этой маленькой функции много чего происходит, поэтому давайте разберем ее на конкретном примере. Выражение[iters(inputs)] * n создает список ссылокn на тот же итератор:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> iters = [iter(nums)] * 2
>>> list(id(itr) for itr in iters) # IDs are the same.
[139949748267160, 139949748267160]Затемzip(*iters) возвращает итератор по парам соответствующих элементов каждого итератора вiters. Когда первый элемент,1, берется из «первого» итератора, «второй» итератор теперь начинается с2, поскольку это просто ссылка на «первый» итератор и поэтому был расширен. один шаг. Итак, первый кортеж, созданныйzip(), - это(1, 2).
В этот момент «оба» итератора вiters начинаются с3, поэтому, когдаzip() извлекает3 из «первого» итератора, он получает4 из «второй» для создания кортежа(3, 4). Этот процесс продолжается до тех пор, покаzip(), наконец, не создаст(9, 10), и «оба» итератора вiters не будут исчерпаны:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(better_grouper(nums, 2))
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]Функцияbetter_grouper() лучше по нескольким причинам. Во-первых, без ссылки на встроенныйlen(),better_grouper() может принимать в качестве аргумента любую итерацию (даже бесконечные итераторы). Во-вторых, возвращая итератор, а не список,better_grouper() может без проблем обрабатывать огромные итерации и использует гораздо меньше памяти.
Сохраните следующее в файле с именемbetter.py и снова запустите его с помощьюtime с консоли:
def better_grouper(inputs, n):
iters = [iter(inputs)] * n
return zip(*iters)
for _ in better_grouper(range(100000000), 10):
pass$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 better.py
Memory used (kB): 7224
User time (seconds): 2.48Это в 630 раз меньше используемой памяти, чемnaive.py менее чем за четверть времени!
Теперь, когда вы узнали, что такоеitertools («алгебра итераторов») и почему вы должны его использовать (улучшенная эффективность памяти и более быстрое время выполнения), давайте посмотрим, как взятьbetter_grouper() в следующий уровень сitertools.
Рецептgrouper
Проблема сbetter_grouper() заключается в том, что он не обрабатывает ситуации, когда значение, переданное второму аргументу, не является фактором длины итерации в первом аргументе:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(better_grouper(nums, 4))
[(1, 2, 3, 4), (5, 6, 7, 8)]Элементы 9 и 10 отсутствуют в сгруппированном выводе. Это происходит потому, чтоzip() прекращает агрегирование элементов после того, как переданная ему самая короткая итерация исчерпана. Имеет смысл вернуть третью группу, содержащую 9 и 10.
Для этого вы можете использоватьitertools.zip_longest(). Эта функция принимает любое количество итераций в качестве аргументов и аргумент ключевого словаfillvalue, который по умолчанию равенNone. Самый простой способ понять разницу междуzip() иzip_longest() - это посмотреть на пример вывода:
>>>
>>> import itertools as it
>>> x = [1, 2, 3, 4, 5]
>>> y = ['a', 'b', 'c']
>>> list(zip(x, y))
[(1, 'a'), (2, 'b'), (3, 'c')]
>>> list(it.zip_longest(x, y))
[(1, 'a'), (2, 'b'), (3, 'c'), (4, None), (5, None)]Имея это в виду, заменитеzip() вbetter_grouper() наzip_longest():
import itertools as it
def grouper(inputs, n, fillvalue=None):
iters = [iter(inputs)] * n
return it.zip_longest(*iters, fillvalue=fillvalue)Теперь вы получите лучший результат:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> print(list(grouper(nums, 4)))
[(1, 2, 3, 4), (5, 6, 7, 8), (9, 10, None, None)]Функциюgrouper() можно найти вRecipes section документацииitertools. Рецепты - отличный источник вдохновения для способов использованияitertools в ваших интересах.
Note: С этого момента строкаimport itertools as it не будет добавляться в начало примеров. Все методыitertools в примерах кода начинаются сit.. Импорт модуля подразумевается.
Если вы получаете исключениеNameError: name 'itertools' is not defined илиNameError: name 'it' is not defined при запуске одного из примеров в этом руководстве, вам нужно сначала импортировать модульitertools.
Эт ту, грубой силы?
Вот типичная проблема в стиле интервью:
У вас есть три купюры по 20 долларов, пять купюр по 10 долларов, две купюры по 5 долларов и пять купюр по 1 доллару. Сколько способов вы можете внести изменения для 100-долларовой банкноты?
Чтобы“brute force” эта проблема, вы просто начинаете перечислять способы выбора одной банкноты из вашего кошелька, проверяете, вносит ли какой-либо из них изменение на 100 долларов, затем перечисляете способы выбрать две банкноты из вашего кошелька, проверяйте еще раз , и так далее и тому подобное.
Но вы программист, поэтому, естественно, вы хотите автоматизировать этот процесс.
Сначала создайте список счетов, которые есть в вашем кошельке:
bills = [20, 20, 20, 10, 10, 10, 10, 10, 5, 5, 1, 1, 1, 1, 1]Выборk вещей из набораn называетсяcombination, иitertools здесь за спиной. Функцияitertools.combinations() принимает два аргумента - итерируемыйinputs и положительное целое числоn - и создает итератор по кортежам всех комбинаций элементовn вinputs. .
Например, чтобы перечислить комбинации трех счетов в своем кошельке, просто выполните:
>>>
>>> list(it.combinations(bills, 3))
[(20, 20, 20), (20, 20, 10), (20, 20, 10), ... ]Чтобы решить эту проблему, вы можете перебрать положительные целые числа от 1 доlen(bills), а затем проверить, какие комбинации каждого размера составляют до 100 долларов:
>>>
>>> makes_100 = []
>>> for n in range(1, len(bills) + 1):
... for combination in it.combinations(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)Если вы распечатаетеmakes_100, вы заметите, что есть много повторяющихся комбинаций. Это имеет смысл, потому что вы можете внести сдачу на 100 долларов с помощью трех банкнот по 20 долларов и четырех банкнот по 10 долларов, ноcombinations() делает это с первыми четырьмя банкнотами по 10 долларов в вашем кошельке; первая, третья, четвертая и пятая купюры по 10 долларов; первая, вторая, четвертая и пятая купюры по 10 долларов; и так далее.
Чтобы удалить дубликаты изmakes_100, вы можете преобразовать его вset:
>>>
>>> set(makes_100)
{(20, 20, 10, 10, 10, 10, 10, 5, 1, 1, 1, 1, 1),
(20, 20, 10, 10, 10, 10, 10, 5, 5),
(20, 20, 20, 10, 10, 10, 5, 1, 1, 1, 1, 1),
(20, 20, 20, 10, 10, 10, 5, 5),
(20, 20, 20, 10, 10, 10, 10)}Таким образом, существует пять способов внести изменения в счет на 100 долларов, используя счета, которые есть в вашем кошельке.
Вот вариант той же проблемы:
Сколько существует способов внести изменения в купюру на 100 долларов, используя любое количество купюр на 50, 20, 10, 5 и 1 доллар?
В этом случае у вас нет заранее установленного набора счетов, поэтому вам нужен способ генерировать все возможные комбинации, используя любое количество счетов. Для этого вам понадобится функцияitertools.combinations_with_replacement().
Он работает так же, какcombinations(), принимая итерируемоеinputs и положительное целое числоn, и возвращает итератор поn-кортежам элементов изinputs. Разница в том, чтоcombinations_with_replacement() позволяет повторять элементы в возвращаемых им кортежах.
Например:
>>>
>>> list(it.combinations_with_replacement([1, 2], 2))
[(1, 1), (1, 2), (2, 2)]Сравните это сcombinations():
>>>
>>> list(it.combinations([1, 2], 2))
[(1, 2)]Вот как выглядит решение пересмотренной проблемы:
>>>
>>> bills = [50, 20, 10, 5, 1]
>>> make_100 = []
>>> for n in range(1, 101):
... for combination in it.combinations_with_replacement(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)В этом случае вам не нужно удалять какие-либо дубликаты, посколькуcombinations_with_replacement() не будет производить их:
>>>
>>> len(makes_100)
343Если вы запустите вышеупомянутое решение, вы можете заметить, что вывод на экран займет некоторое время. Это потому, что он должен обработать 96 560 645 комбинаций!
Другая функция «грубой силы»itertools -permutations(), которая принимает одну итерацию и производит все возможные перестановки (перестановки) ее элементов:
>>>
>>> list(it.permutations(['a', 'b', 'c']))
[('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'),
('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')]Любая итерируемая из трех элементов будет иметь шесть перестановок, и число перестановок более длинных итераций растет чрезвычайно быстро. Фактически, итерация длиныn имеетn! перестановок, где
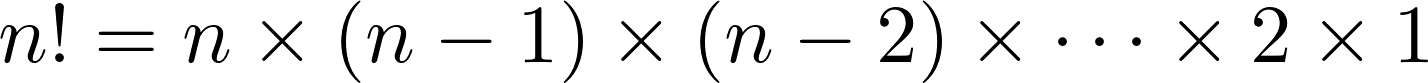
Чтобы представить себе это в перспективе, вот таблица этих чисел отn = 1 доn = 10:
| n | n! |
|---|---|
2 |
2 |
3 |
6 |
4 |
24 |
5 |
120 |
6 |
720 |
7 |
5 040 |
8 |
40 320 |
9 |
362 880 |
10 |
3 628 800 |
Феномен, когда всего несколько входов дают большое количество результатов, называетсяcombinatorial explosion, и его следует иметь в виду при работе сcombinations(),combinations_with_replacement() иpermutations().
Обычно лучше избегать алгоритмов грубой силы, хотя иногда вам может потребоваться их использовать (например, если правильность алгоритма критична или учитываются все возможные исходыmust). В этом случаеitertools вас прикрывает.
Раздел Резюме
В этом разделе вы познакомились с тремя функциямиitertools:combinations(),combinations_with_replacement() иpermutations().
Давайте рассмотрим эти функции, прежде чем двигаться дальше:
itertools.combinations Пример
combinations(iterable, n)Возврат последовательных n-длинных комбинаций элементов в итерируемом.
>>>
>>> combinations([1, 2, 3], 2)
(1, 2), (1, 3), (2, 3)itertools.combinations_with_replacement Пример
combinations_with_replacement(iterable, n)Возврат последовательных n-длинных комбинаций элементов в итерации, позволяющий отдельным элементам иметь последовательные повторы.
>>>
>>> combinations_with_replacement([1, 2], 2)
(1, 1), (1, 2), (2, 2)itertools.permutations Пример
permutations(iterable, n=None)Вернуть последовательные перестановки n-длины элементов в итерации.
>>>
>>> permutations('abc')
('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'),
('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')Последовательности чисел
С помощьюitertools вы можете легко создавать итераторы для бесконечных последовательностей. В этом разделе вы изучите числовые последовательности, но инструменты и методы, которые здесь рассматриваются, ни в коем случае не ограничиваются числами.
Четные и шансы
В первом примере вы создадите пару итераторов для четных и нечетных целых чиселwithout explicitly doing any arithmetic.. Прежде чем углубляться в детали, давайте посмотрим на арифметическое решение с использованием генераторов:
>>>
>>> def evens():
... """Generate even integers, starting with 0."""
... n = 0
... while True:
... yield n
... n += 2
...
>>> evens = evens()
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> def odds():
... """Generate odd integers, starting with 1."""
... n = 1
... while True:
... yield n
... n += 2
...
>>> odds = odds()
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]Это довольно просто, но сitertools вы можете сделать это намного компактнее. Вам нужна функцияitertools.count(), которая делает именно то, что звучит: она считает, начиная по умолчанию с числа 0.
>>>
>>> counter = it.count()
>>> list(next(counter) for _ in range(5))
[0, 1, 2, 3, 4]Вы можете начать отсчет с любого числа, которое вам нравится, установив аргумент ключевого словаstart, который по умолчанию равен 0. Вы даже можете установить аргумент ключевого словаstep, чтобы определить интервал между числами, возвращаемыми изcount() - по умолчанию это 1.
Сcount() итераторы по четным и нечетным целым числам становятся буквальными однострочными:
>>>
>>> evens = it.count(step=2)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = it.count(start=1, step=2)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]Ever since Python 3.1, функцияcount() также принимает нецелочисленные аргументы:
>>>
>>> count_with_floats = it.count(start=0.5, step=0.75)
>>> list(next(count_with_floats) for _ in range(5))
[0.5, 1.25, 2.0, 2.75, 3.5]Вы можете даже передать ему отрицательные числа:
>>>
>>> negative_count = it.count(start=-1, step=-0.5)
>>> list(next(negative_count) for _ in range(5))
[-1, -1.5, -2.0, -2.5, -3.0]В некотором смыслеcount() похож на встроенную функциюrange(), ноcount() всегда возвращает бесконечную последовательность. Вы можете задаться вопросом, что хорошего в бесконечной последовательности, поскольку невозможно выполнить итерацию полностью. Это правильный вопрос, и я признаю, что когда я впервые познакомился с бесконечными итераторами, я тоже не совсем понял суть.
Пример, который заставил меня осознать мощь бесконечного итератора, заключался в следующем, который имитирует поведениеbuilt-in enumerate() function:
>>>
>>> list(zip(it.count(), ['a', 'b', 'c']))
[(0, 'a'), (1, 'b'), (2, 'c')]Это простой пример, но подумайте: вы только что перечислили список без циклаfor и заранее не зная длину списка.
Рекуррентные отношения
Arecurrence relation - это способ описания последовательности чисел с помощью рекурсивной формулы. Одно из самых известных рекуррентных соотношений - это то, которое описываетFibonacci sequence.
Последовательность Фибоначчи - это последовательность0, 1, 1, 2, 3, 5, 8, 13, .... Он начинается с 0 и 1, и каждое последующее число в последовательности является суммой двух предыдущих. Числа в этой последовательности называются числами Фибоначчи. В математических обозначениях рекуррентное соотношение, описывающееn-е число Фибоначчи, выглядит так:
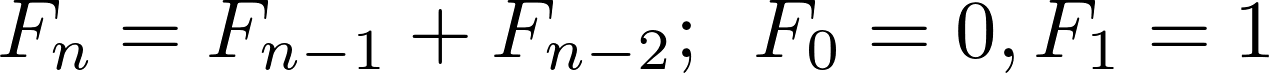
Note: Если вы выполните поиск в Google, вы найдете множество реализаций этих чисел на Python. Вы можете найти рекурсивную функцию, которая их производит, в статьеThinking Recursively in Python здесь, на Real Python.
Обычно можно увидеть последовательность Фибоначчи, созданную с помощью генератора:
def fibs():
a, b = 0, 1
while True:
yield a
a, b = b, a + bОтношение рекуррентности, описывающее числа Фибоначчи, называетсяsecond order recurrence relation, потому что для вычисления следующего числа в последовательности вам нужно оглянуться на два числа позади него.
В общем случае рекуррентные отношения второго порядка имеют вид:
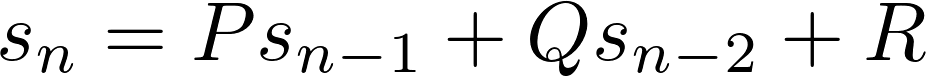
ЗдесьP,Q иR - константы. Чтобы сгенерировать последовательность, вам нужно два начальных значения. Для чисел ФибоначчиP =Q = 1,R = 0, а начальные значения - 0 и 1.
Как вы могли догадаться,first order recurrence relation имеет следующий вид:
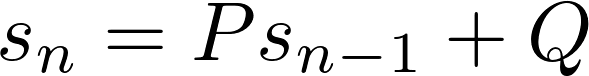
Существует бесчисленное множество последовательностей чисел, которые можно описать рекуррентными соотношениями первого и второго порядка. Например, положительные целые числа могут быть описаны как рекуррентное отношение первого порядка сP =Q = 1 и начальным значением 1. Для четных целых чисел возьмитеP = 1 иQ = 2 с начальным значением 0.
В этом разделе вы построите функции для создания последовательностиany, значения которой могут быть описаны с помощью отношения рекуррентности первого или второго порядка.
Первый порядок рекуррентных отношений
Вы уже видели, какcount() может генерировать последовательность неотрицательных целых чисел, четных целых и нечетных целых чисел. Вы также можете использовать его для генерации последовательности3n = 0, 3, 6, 9, 12, … и4n = 0, 4, 8, 12, 16, ….
count_by_three = it.count(step=3)
count_by_four = it.count(step=4)Фактически,count() может создавать последовательности, кратные любому числу, которое вы хотите. Эти последовательности могут быть описаны с помощью рекуррентных отношений первого порядка. Например, чтобы сгенерировать последовательность кратных некоторого числаn, просто возьмитеP = 1,Q =n и начальное значение 0.
Еще один простой пример рекуррентного отношения первого порядка - постоянная последовательностьn, n, n, n, n…, гдеn - любое значение, которое вы хотите. Для этой последовательности установитеP = 1 иQ = 0 с начальным значениемn. itertools также предоставляет простой способ реализовать эту последовательность с помощью функцииrepeat():
all_ones = it.repeat(1) # 1, 1, 1, 1, ...
all_twos = it.repeat(2) # 2, 2, 2, 2, ...Если вам нужна конечная последовательность повторяющихся значений, вы можете установить точку остановки, передавая положительное целое число в качестве второго аргумента:
five_ones = it.repeat(1, 5) # 1, 1, 1, 1, 1
three_fours = it.repeat(4, 3) # 4, 4, 4Что может быть не так очевидно, так это то, что последовательность1, -1, 1, -1, 1, -1, ... чередующихся единиц и -1 также может быть описана рекуррентным соотношением первого порядка. Просто возьмитеP = -1,Q = 0 и начальное значение 1.
Есть простой способ создать эту последовательность с помощью функцииitertools.cycle(). Эта функция принимает итерируемыйinputs в качестве аргумента и возвращает бесконечный итератор по значениям вinputs, который возвращается в начало после достижения концаinputs. Итак, чтобы создать чередующуюся последовательность 1 и -1, вы можете сделать это:
alternating_ones = it.cycle([1, -1]) # 1, -1, 1, -1, 1, -1, ...Однако цель этого раздела - создать единую функцию, которая может генерировать рекуррентное отношение первого порядкаany - просто передайте ейP,Q и начальное значение. Один из способов сделать это - использоватьitertools.accumulate().
Функцияaccumulate() принимает два аргумента - итерируемыйinputs иbinary functionfunc (то есть функцию с ровно двумя входами) - и возвращает итератор по накопленным результатам применяяfunc к элементамinputs. Это примерно эквивалентно следующему генератору:
def accumulate(inputs, func):
itr = iter(inputs)
prev = next(itr)
for cur in itr:
yield prev
prev = func(prev, cur)Например:
>>>
>>> import operator
>>> list(it.accumulate([1, 2, 3, 4, 5], operator.add))
[1, 3, 6, 10, 15]Первое значение в итераторе, возвращаемоеaccumulate(), всегда является первым значением во входной последовательности. В приведенном выше примере это 1 - первое значение в[1, 2, 3, 4, 5].
Следующее значение в итераторе вывода - это сумма первых двух элементов входной последовательности:add(1, 2) = 3. Чтобы создать следующее значение,accumulate() берет результатadd(1, 2) и добавляет его к третьему значению во входной последовательности:
add(3, 3) = add(add(1, 2), 3) = 6
Четвертое значение, создаваемоеaccumulate(), -add(add(add(1, 2), 3), 4) = 10 и так далее.
Второй аргументaccumulate() по умолчанию равенoperator.add(), поэтому предыдущий пример можно упростить до:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5]))
[1, 3, 6, 10, 15]Передача встроенногоmin() вaccumulate() будет отслеживать текущий минимум:
>>>
>>> list(it.accumulate([9, 21, 17, 5, 11, 12, 2, 6], min))
[9, 9, 9, 5, 5, 5, 2, 2]Более сложные функции могут быть переданыaccumulate() с помощью выраженийlambda:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: (x + y) / 2))
[1, 1.5, 2.25, 3.125, 4.0625]Порядок аргументов в двоичной функции, переданной вaccumulate(), важен. Первый аргумент всегда является ранее накопленным результатом, а второй аргумент всегда является следующим элементом итерируемого ввода. Например, рассмотрим разницу в выводе следующих выражений:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: x - y))
[1, -1, -4, -8, -13]
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: y - x))
[1, 1, 2, 2, 3]Чтобы смоделировать рекуррентное отношение, вы можете просто проигнорировать второй аргумент двоичной функции, переданной вaccumulate(). То есть, при заданных значенияхp,q иs,lambda x, _: p*s + q вернет значение, следующее заx в рекуррентном отношении, определяемомsᵢ =Psᵢ₋₁ +Q.
Чтобыaccumulate() перебирал результирующее рекуррентное отношение, вам необходимо передать ему бесконечную последовательность с правильным начальным значением. Неважно, каковы остальные значения в последовательности, если начальное значение является начальным значением отношения повторения. Вы можете сделать это с помощьюrepeat():
def first_order(p, q, initial_val):
"""Return sequence defined by s(n) = p * s(n-1) + q."""
return it.accumulate(it.repeat(initial_val), lambda s, _: p*s + q)Используяfirst_order(), вы можете построить последовательности сверху следующим образом:
>>> evens = first_order(p=1, q=2, initial_val=0)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = first_order(p=1, q=2, initial_val=1)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]
>>> count_by_threes = first_order(p=1, q=3, initial_val=0)
>>> list(next(count_by_threes) for _ in range(5))
[0, 3, 6, 9, 12]
>>> count_by_fours = first_order(p=1, q=4, initial_val=0)
>>> list(next(count_by_fours) for _ in range(5))
[0, 4, 8, 12, 16]
>>> all_ones = first_order(p=1, q=0, initial_val=1)
>>> list(next(all_ones) for _ in range(5))
[1, 1, 1, 1, 1]
>>> all_twos = first_order(p=1, q=0, initial_val=2)
>>> list(next(all_twos) for _ in range(5))
[2, 2, 2, 2, 2]
>>> alternating_ones = first_order(p=-1, 0, initial_val=1)
>>> list(next(alternating_ones) for _ in range(5))
[1, -1, 1, -1, 1]Отношения повторения второго порядка
Генерирование последовательностей, описываемых рекуррентными отношениями второго порядка, таких как последовательность Фибоначчи, может быть выполнено с использованием метода, аналогичного тому, который используется для рекуррентных отношений первого порядка.
Разница здесь в том, что вам нужно создать промежуточную последовательность кортежей, которая отслеживает два предыдущих элемента последовательности, а затемmap() каждого из этих кортежей до их первого компонента, чтобы получить окончательную последовательность.
Вот как это выглядит:
def second_order(p, q, r, initial_values):
"""Return sequence defined by s(n) = p * s(n-1) + q * s(n-2) + r."""
intermediate = it.accumulate(
it.repeat(initial_values),
lambda s, _: (s[1], p*s[1] + q*s[0] + r)
)
return map(lambda x: x[0], intermediate)Используяsecond_order(), вы можете сгенерировать последовательность Фибоначчи следующим образом:
>>> fibs = second_order(p=1, q=1, r=0, initial_values=(0, 1))
>>> list(next(fibs) for _ in range(8))
[0, 1, 1, 2, 3, 5, 8, 13]Другие последовательности можно легко сгенерировать, изменив значенияp,q иr. Например,Pell numbers иLucas numbers могут быть сгенерированы следующим образом:
pell = second_order(p=2, q=1, r=0, initial_values=(0, 1))
>>> list(next(pell) for _ in range(6))
[0, 1, 2, 5, 12, 29]
>>> lucas = second_order(p=1, q=1, r=0, initial_values=(2, 1))
>>> list(next(lucas) for _ in range(6))
[2, 1, 3, 4, 7, 11]Вы даже можете генерировать чередующиеся числа Фибоначчи:
>>> alt_fibs = second_order(p=-1, q=1, r=0, initial_values=(-1, 1))
>>> list(next(alt_fibs) for _ in range(6))
[-1, 1, -2, 3, -5, 8]Все это действительно круто, если вы такой же гигантский математический ботаник, как я, но отступите на секунду и сравнитеsecond_order() с генераторомfibs() из начала этого раздела. Какой из них легче понять?
Это ценный урок. Функцияaccumulate() - мощный инструмент, который стоит включить в ваш набор инструментов, но бывают случаи, когда ее использование может означать жертву ясностью и удобочитаемостью.
Раздел Резюме
В этом разделе вы видели несколько функцийitertools. Давайте рассмотрим их сейчас.
itertools.count Пример
count(start=0, step=1)Вернуть объект счетчика, чей метод.
__next__()возвращает последовательные значения.
>>>
>>> count()
0, 1, 2, 3, 4, ...
>>> count(start=1, step=2)
1, 3, 5, 7, 9, ...itertools.repeat Пример
repeat(object, times=1)Создайте итератор, который возвращает объект указанное количество раз. Если не указан, возвращает объект бесконечно.
>>>
>>> repeat(2)
2, 2, 2, 2, 2 ...
>>> repeat(2, 5) # Stops after 5 repititions.
2, 2, 2, 2, 2itertools.cycle Пример
cycle(iterable)Вернуть элементы из итерируемого до тех пор, пока он не будет исчерпан. Затем повторите последовательность до бесконечности.
>>>
>>> cycle(['a', 'b', 'c'])
a, b, c, a, b, c, a, ...itertools accumulate Пример
accumulate(iterable, func=operator.add)Возврат ряда накопленных сумм (или других результатов двоичной функции).
>>>
>>> accumulate([1, 2, 3])
1, 3, 6Хорошо, давайте отдохнем от математики и повеселимся с картами.
Раздача колоды карт
Предположим, вы создаете приложение для покера. Вам понадобится колода карт. Вы можете начать с определения списка рангов (туз, король, королева, валет, 10, 9 и т. Д.) И списка мастей (червы, алмазы, булавы и пики):
ranks = ['A', 'K', 'Q', 'J', '10', '9', '8', '7', '6', '5', '4', '3', '2']
suits = ['H', 'D', 'C', 'S']Вы можете представить карту как кортеж, первый элемент которого является рангом, а второй элемент - мастью. Колода карт была бы коллекцией таких кортежей. Колода должна действовать как настоящая вещь, поэтому имеет смысл определить генератор, который выдает карты по одной за раз и становится исчерпанным, когда все карты раздаются.
Один из способов добиться этого - написать генератор с вложенным цикломfor надranks иsuits:
def cards():
"""Return a generator that yields playing cards."""
for rank in ranks:
for suit in suits:
yield rank, suitВы могли бы написать это более компактно с помощью выражения генератора:
cards = ((rank, suit) for rank in ranks for suit in suits)Однако некоторые могут возразить, что это на самом деле труднее понять, чем более явный вложенный циклfor.
Это помогает рассматривать вложенные циклыfor с математической точки зрения, то есть какCartesian product из двух или более итераций. В математике декартово произведение двух наборовA иB - это набор всех кортежей вида(a, b), гдеa является элементомA и b является элементомB.
Вот пример с итерациями Python: декартово произведениеA = [1, 2] иB = ['a', 'b'] равно[(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')].
Функцияitertools.product() предназначена именно для этой ситуации. Он принимает любое количество итераций в качестве аргументов и возвращает итератор для кортежей в декартовом произведении:
it.product([1, 2], ['a', 'b']) # (1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')Функцияproduct() никоим образом не ограничивается двумя итерациями. Вы можете передать его столько, сколько захотите - они даже не обязательно должны быть одинакового размера! Посмотрите, сможете ли вы предсказать, что такоеproduct([1, 2, 3], ['a', 'b'], ['c']), а затем проверьте свою работу, запустив ее в интерпретаторе.
Warning: Функция
product()- это еще одна функция «грубой силы», которая может привести к комбинаторному взрыву, если вы не будете осторожны.
Используяproduct(), вы можете переписатьcards в одной строке:
cards = it.product(ranks, suits)Это все прекрасно, но любое покерное приложение стоит начинать с перемешанной колоды:
import random
def shuffle(deck):
"""Return iterator over shuffled deck."""
deck = list(deck)
random.shuffle(deck)
return iter(tuple(deck))
cards = shuffle(cards)Note: Функция
random.shuffle()используетFisher-Yates shuffle для перемешивания списка (или любой изменяемой последовательности) на местоin O(n) time. Этот алгоритм хорошо подходит для перетасовкиcards, потому что он производит несмещенную перестановку, то есть все перестановки итерируемого с одинаковой вероятностью будут возвращеныrandom.shuffle().Тем не менее, вы, вероятно, заметили, что
shuffle()создает копию своего вводаdeckв памяти, вызываяlist(deck). Хотя это, по-видимому, противоречит духу этой статьи, этот автор не знает о хорошем способе перемешать итератор без создания копии.
В качестве вежливости к вашим пользователям, вы хотели бы дать им возможность сократить колоду. Если вы представляете, как карты аккуратно сложены на столе, вы предлагаете пользователю выбрать числоn, а затем удалить первые картыn из верхней части стопки и переместить их вниз.
Если вы знаете кое-что оslicing, вы можете сделать это так:
def cut(deck, n):
"""Return an iterator over a deck of cards cut at index `n`."""
if n < 0:
raise ValueError('`n` must be a non-negative integer')
deck = list(deck)
return iter(deck[n:] + deck[:n])
cards = cut(cards, 26) # Cut the deck in half.Функцияcut() сначала преобразуетdeck в список, чтобы вы могли разрезать его на части. Чтобы гарантировать, что ваши срезы будут вести себя должным образом, вы должны проверить, чтоn неотрицательно. Если это не так, вам лучше выбросить исключение, чтобы ничего не происходило.
Разделить колоду довольно просто: верхняя часть вырезанной колоды - это всего лишьdeck[:n], а нижняя - это оставшиеся карты илиdeck[n:]. Чтобы построить новую колоду с верхней «половиной», перемещенной вниз, вы просто добавляете ее внизу:deck[n:] + deck[:n].
Функцияcut() довольно проста, но у нее есть несколько проблем. Когда вы разрезаете список, вы делаете копию исходного списка и возвращаете новый список с выбранными элементами. С колодой всего из 52 карт это увеличение сложности пространства тривиально, но вы можете уменьшить накладные расходы на память, используяitertools. Для этого вам понадобятся три функции:itertools.tee(),itertools.islice() иitertools.chain().
Давайте посмотрим, как работают эти функции.
Функциюtee() можно использовать для создания любого количества независимых итераторов из одной итерации. Он принимает два аргумента: первый - это итеративныйinputs, а второй - это количествоn независимых итераторов надinputs, которые нужно вернуть (по умолчаниюn имеет значение 2). Итераторы возвращаются в виде кортежа длинойn.
>>>
>>> iterator1, iterator2 = it.tee([1, 2, 3, 4, 5], 2)
>>> list(iterator1)
[1, 2, 3, 4, 5]
>>> list(iterator1) # iterator1 is now exhausted.
[]
>>> list(iterator2) # iterator2 works independently of iterator1
[1, 2, 3, 4, 5].Хотяtee() полезен для создания независимых итераторов, важно немного понять, как он работает под капотом. Когда вы вызываетеtee() для создания независимых итераторовn, каждый итератор по существу работает со своей собственной очередью FIFO.
Когда значение извлекается из одного итератора, это значение добавляется в очереди для других итераторов. Таким образом, если один итератор исчерпан раньше других, каждый оставшийся итератор будет хранить копию всей итерации в памяти. (Вы можете найти функцию Python, которая эмулируетtee() вitertoolsdocs.)
По этой причинеtee() следует использовать с осторожностью. Если вы исчерпываете большие части итератора перед работой с другими, возвращаемымиtee(), вам может быть лучше преобразовать итератор ввода вlist илиtuple.
Функцияislice() работает почти так же, как нарезка списка или кортежа. Вы передаете его итерируемой, начальной и конечной точкам, и, подобно разрезанию списка, возвращаемый срез останавливается на индексе непосредственно перед точкой остановки. При желании вы также можете включить значение шага. Самая большая разница здесь, конечно, в том, чтоislice() возвращает итератор.
>>>
>>> # Slice from index 2 to 4
>>> list(it.islice('ABCDEFG', 2, 5)))
['C' 'D' 'E']
>>> # Slice from beginning to index 4, in steps of 2
>>> list(it.islice([1, 2, 3, 4, 5], 0, 5, 2))
[1, 3, 5]
>>> # Slice from index 3 to the end
>>> list(it.islice(range(10), 3, None))
[3, 4, 5, 6, 7, 8, 9]
>>> # Slice from beginning to index 3
>>> list(it.islice('ABCDE', 4))
['A', 'B', 'C', 'D']Последние два примера выше полезны для усечения итераций. Вы можете использовать это, чтобы заменить нарезку списка, используемую вcut(), чтобы выбрать «верх» и «низ» колоды. В качестве дополнительного бонусаislice() не принимает отрицательные индексы для позиций начала / конца и значения шага, поэтому вам не нужно создавать исключение, еслиn отрицательное.
Последняя функция, которая вам понадобится, -chain(). Эта функция принимает любое количество итераций в качестве аргументов и объединяет их в цепочку. Например:
>>>
>>> list(it.chain('ABC', 'DEF'))
['A' 'B' 'C' 'D' 'E' 'F']
>>> list(it.chain([1, 2], [3, 4, 5, 6], [7, 8, 9]))
[1, 2, 3, 4, 5, 6, 7, 8, 9]Теперь, когда в вашем арсенале есть дополнительная огневая мощь, вы можете переписать функциюcut(), чтобы разрезать колоду карт, не делая полную копиюcards в памяти:
def cut(deck, n):
"""Return an iterator over a deck of cards cut at index `n`."""
deck1, deck2 = it.tee(deck, 2)
top = it.islice(deck1, n)
bottom = it.islice(deck2, n, None)
return it.chain(bottom, top)
cards = cut(cards, 26)Теперь, когда вы перетасовали и разрешили карты, пришло время сдать несколько рук. Вы можете написать функциюdeal(), которая принимает в качестве аргументов колоду, количество рук и размер руки и возвращает кортеж, содержащий указанное количество рук.
Для написания этой функции вам не нужны новые функцииitertools. Посмотрите, что вы можете придумать самостоятельно, прежде чем читать дальше.
Вот одно из решений:
def deal(deck, num_hands=1, hand_size=5):
iters = [iter(deck)] * hand_size
return tuple(zip(*(tuple(it.islice(itr, num_hands)) for itr in iters)))Вы начинаете с создания списка ссылокhand_size на итератор вdeck. Затем вы перебираете этот список, удаляя карточкиnum_hands на каждом шаге и сохраняя их в кортежах.
Затем выzip() этих кортежей, чтобы имитировать раздачу одной карты каждому игроку. Это производитnum_hands кортежей, каждый из которых содержитhand_size карточек. Наконец, вы упаковываете руки в кортеж, чтобы вернуть их сразу.
Эта реализация устанавливает значения по умолчанию дляnum_hands на1 иhand_size на5 - возможно, вы делаете приложение «Пятикарточный розыгрыш». Вот как вы могли бы использовать эту функцию с некоторыми примерами вывода:
>>>
>>> p1_hand, p2_hand, p3_hand = deal(cards, num_hands=3)
>>> p1_hand
(('A', 'S'), ('5', 'S'), ('7', 'H'), ('9', 'H'), ('5', 'H'))
>>> p2_hand
(('10', 'H'), ('2', 'D'), ('2', 'S'), ('J', 'C'), ('9', 'C'))
>>> p3_hand
(('2', 'C'), ('Q', 'S'), ('6', 'C'), ('Q', 'H'), ('A', 'C'))Как вы думаете, в каком состоянии сейчасcards, когда вы раздали три руки по пять карт?
>>>
>>> len(tuple(cards))
37Пятнадцать розданных карт потребляются из итератораcards, что именно то, что вам нужно. Таким образом, по мере продолжения игры состояние итератораcards отражает состояние колоды в игре.
Раздел Резюме
Давайте рассмотрим функцииitertools, которые вы видели в этом разделе.
itertools.product Пример
product(*iterables, repeat=1)Декартово произведение входных итераций. Эквивалент вложенных циклов for.
>>>
>>> product([1, 2], ['a', 'b'])
(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')itertools.tee Пример
tee(iterable, n=2)Создайте любое количество независимых итераторов из одного входного итератора.
>>>
>>> iter1, iter2 = it.tee(['a', 'b', 'c'], 2)
>>> list(iter1)
['a', 'b', 'c']
>>> list(iter2)
['a', 'b', 'c']itertools.islice Пример
islice(iterable, stop)islice(iterable, start, stop, step=1)Вернуть итератор, чей метод
__next__()возвращает выбранные значения из итерируемого объекта. Работает какslice()в списке, но возвращает итератор.
>>>
>>> islice([1, 2, 3, 4], 3)
1, 2, 3
>>> islice([1, 2, 3, 4], 1, 2)
2, 3itertools.chain Пример
chain(*iterables)Вернуть объект цепочки, чей метод
__next__()возвращает элементы из первой итерации, пока она не будет исчерпана, затем элементы из следующей итерации, пока не будут исчерпаны все итерации.
>>>
>>> chain('abc', [1, 2, 3])
'a', 'b', 'c', 1, 2, 3Интервью: Сведение списка списков
В предыдущем примере вы использовалиchain(), чтобы прикрепить один итератор к концу другого. Функцияchain() имеет метод класса.from_iterable(), который принимает в качестве аргумента одну итерацию. Элементы итерации сами должны быть итерируемыми, поэтому в итогеchain.from_iterable() сглаживает свой аргумент:
>>>
>>> list(it.chain.from_iterable([[There’s no reason the argument of `+chain.from_iterable()+` needs to be finite. You could emulate the behavior of `+cycle()+`, for example:>>> cycle = it.chain.from_iterable(it.repeat('abc'))
>>> list(it.islice(cycle, 8))
['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b']Функцияchain.from_iterable() полезна, когда вам нужно построить итератор для данных, которые были «разбиты на части».
В следующем разделе вы увидите, как использоватьitertools для анализа данных большого набора данных. Но вы заслуживаете перерыва за то, что застряли в нем так долго. Почему бы не увлажнить себя и не расслабиться? Может даже немного поигратьStar Trek: The Nth Iteration.
Назад? Большой! Давайте проведем анализ данных.
Анализируем S & P500
В этом примере вы впервые почувствуете, как использоватьitertools для управления большим набором данных, в частности, историческими данными о дневных ценах индекса S & P500. CSV-файлSP500.csv с этими данными можно найтиhere (источник:Yahoo Finance). Вы должны решить следующую проблему:
Определите максимальную дневную прибыль, дневную потерю (в процентном изменении) и самую длинную полосу роста в истории индекса S & P500.
Чтобы понять, с чем вы имеете дело, вот первые десять строкSP500.csv:
$ head -n 10 SP500.csv
Date,Open,High,Low,Close,Adj Close,Volume
1950-01-03,16.660000,16.660000,16.660000,16.660000,16.660000,1260000
1950-01-04,16.850000,16.850000,16.850000,16.850000,16.850000,1890000
1950-01-05,16.930000,16.930000,16.930000,16.930000,16.930000,2550000
1950-01-06,16.980000,16.980000,16.980000,16.980000,16.980000,2010000
1950-01-09,17.080000,17.080000,17.080000,17.080000,17.080000,2520000
1950-01-10,17.030001,17.030001,17.030001,17.030001,17.030001,2160000
1950-01-11,17.090000,17.090000,17.090000,17.090000,17.090000,2630000
1950-01-12,16.760000,16.760000,16.760000,16.760000,16.760000,2970000
1950-01-13,16.670000,16.670000,16.670000,16.670000,16.670000,3330000Как видите, ранние данные ограничены. Данные улучшаются для более поздних дат, и в целом их достаточно для этого примера.
Стратегия решения этой проблемы следующая:
-
Считайте данные из файла CSV и преобразуйте их в последовательность
gainsежедневных процентных изменений, используя столбец «Adj Close». -
Найдите максимальное и минимальное значения последовательности
gainsи дату, когда они происходят. (Обратите внимание, что эти значения могут быть достигнуты более чем на дату; в этом случае будет достаточно самой последней даты.) -
Преобразуйте
gainsв последовательностьgrowth_streaksкортежей последовательных положительных значений вgains. Затем определите длину самого длинного кортежа вgrowth_streaks, а также даты начала и окончания полосы. (Возможно, что максимальная длина достигается более чем одним кортежем вgrowth_streaks; в этом случае будет достаточно кортежа с самыми последними датами начала и окончания.)
percent change между двумя значениямиx иy определяется по следующей формуле:
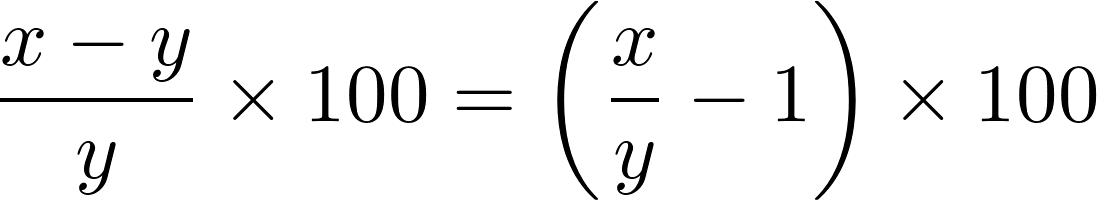
Для каждого шага анализа необходимо сравнивать значения, связанные с датами. Чтобы облегчить эти сравнения, вы можете создать подклассnamedtuple object отcollections module:
from collections import namedtuple
class DataPoint(namedtuple('DataPoint', ['date', 'value'])):
__slots__ = ()
def __le__(self, other):
return self.value <= other.value
def __lt__(self, other):
return self.value < other.value
def __gt__(self, other):
return self.value > other.valueКлассDataPoint имеет два атрибута:date (экземплярdatetime.datetime) иvalue. https://docs.python.org/3/reference/datamodel.html#object.le [.__le__()],https://docs.python.org/3/reference/datamodel.html#object.lt [.__lt__()] иhttps://docs.python.org/3/reference/datamodel.html#object.gt [.__gt__()]dunder methods реализованы таким образом, что логические компараторы<=,< и> могут использоваться для сравнения значений двухDataPoint объекты. Это также позволяет вызывать встроенные функцииmax() иmin() с аргументамиDataPoint.
Note: Если вы не знакомы с
namedtuple, посмотритеthis excellent resource. РеализацияnamedtupleдляDataPoint- лишь один из многих способов построения этой структуры данных. Например, в Python 3.7 вы можете реализоватьDataPointкак класс данных. Посетите нашUltimate Guide to Data Classes для получения дополнительной информации.
Следующее читает данные изSP500.csv в кортеж объектовDataPoint:
import csv
from datetime import datetime
def read_prices(csvfile, _strptime=datetime.strptime):
with open(csvfile) as infile:
reader = csv.DictReader(infile)
for row in reader:
yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(),
value=float(row['Adj Close']))
prices = tuple(read_prices('SP500.csv'))Генераторread_prices() открываетSP500.csv и читает каждую строку с объектомcsv.DictReader(). DictReader() возвращает каждую строку какOrderedDict, ключи которого являются именами столбцов из строки заголовка файла CSV.
Для каждой строкиread_prices() дает объектDataPoint, содержащий значения в столбцах «Дата» и «Adj Close». Наконец, полная последовательность точек данных сохраняется в памяти какtuple и сохраняется в переменнойprices.
Затемprices необходимо преобразовать в последовательность ежедневных процентных изменений:
gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.))
for day, prev_day in zip(prices[1:], prices))Выбор хранения данных вtuple является преднамеренным. Хотя вы можете указатьgains на итератор, вам нужно будет дважды перебрать данные, чтобы найти минимальное и максимальное значения.
Если вы используетеtee() для создания двух независимых итераторов, использование одного итератора для нахождения максимума создаст копию всех данных в памяти для второго итератора. Создавtuple заранее, вы ничего не потеряете с точки зрения сложности пространства по сравнению сtee(), и вы даже можете немного увеличить скорость.
Note: В этом примере основное внимание уделяется использованию
itertoolsдля анализа данных S & P500. Те, кто намеревается работать с большим количеством финансовых данных временных рядов, могут также захотеть проверить библиотекуPandas, которая хорошо подходит для таких задач.
Максимальный выигрыш и убыток
Чтобы определить максимальный прирост в любой день, вы можете сделать что-то вроде этого:
max_gain = DataPoint(None, 0)
for data_point in gains:
max_gain = max(data_point, max_gain)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)Вы можете упростить циклfor, используяfunctools.reduce() function. Эта функция принимает двоичную функциюfunc и итерациюinputs в качестве аргументов и «уменьшает»inputs до единственного значения, применяяfunc кумулятивно к парам объектов в итеративном .
Например,functools.reduce(operator.add, [1, 2, 3, 4, 5]) вернет сумму1 + 2 + 3 + 4 + 5 = 15. Вы можете думать, чтоreduce() работает так же, какaccumulate(), за исключением того, что он возвращает только последнее значение в новой последовательности.
Используяreduce(), вы можете полностью избавиться от циклаfor в приведенном выше примере:
import functools as ft
max_gain = ft.reduce(max, gains)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)Приведенное выше решение работает, но не эквивалентно циклуfor, который у вас был раньше. Вы понимаете почему? Предположим, что данные в вашем CSV-файле записывают убыток каждый день. Каким будет значениеmax_gain?
В циклеfor вы сначала устанавливаетеmax_gain = DataPoint(None, 0), поэтому, если нет усиления, окончательным значениемmax_gain будет этот пустой объектDataPoint. Однако решениеreduce() возвращает наименьшие потери. Это не то, что вам нужно, и это может привести к трудной для поиска ошибке.
Здесьitertools может вам помочь. Функцияitertools.filterfalse() принимает два аргумента: функцию, возвращающуюTrue илиFalse (называемуюpredicate), и повторяемыйinputs. Он возвращает итератор по элементам вinputs, для которых предикат возвращаетFalse.
Вот простой пример:
>>> only_positives = it.filterfalse(lambda x: x <= 0, [0, 1, -1, 2, -2])
>>> list(only_positives)
[1, 2]Вы можете использоватьfilterfalse() для фильтрации отрицательных или нулевых значений вgains, чтобыreduce() работал только с положительными значениями:
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, gains))Что произойдет, если нет прибыли? Учтите следующее:
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]))
Traceback (most recent call last):
File "", line 1, in
TypeError: reduce() of empty sequence with no initial value Что ж, это не то, что вам нужно! Но это имеет смысл, потому что итератор, возвращаемыйfilterflase(), пуст. Вы можете обработатьTypeError, заключив вызовreduce() вtry...except, но есть способ лучше.
Функцияreduce() принимает необязательный третий аргумент в качестве начального значения. Передав0 этому третьему аргументу, вы получите ожидаемое поведение:
>>>
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]), 0)
0Применяя это к примеру S & P500:
zdp = DataPoint(None, 0) # zero DataPoint
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, diffs), zdp)Большой! Все работает так, как должно! Теперь найти максимальную потерю легко:
max_loss = ft.reduce(min, it.filterfalse(lambda p: p > 0, gains), zdp)
print(max_loss) # DataPoint(date='2018-02-08', value=-20.47)Самая длинная полоса роста
Поиск самой длинной полосы роста в истории S & P500 эквивалентен поиску наибольшего количества последовательных положительных точек данных в последовательностиgains. Функцииitertools.takewhile() иitertools.dropwhile() идеально подходят для этой ситуации.
Функцияtakewhile() принимает в качестве аргументов предикат и повторяемыйinputs и возвращает итератор поinputs, который останавливается на первом экземпляре элемента, для которого предикат возвращаетFalse:
it.takewhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 0, 1, 2Функцияdropwhile() делает прямо противоположное. Он возвращает итератор, начинающийся с первого элемента, для которого предикат возвращаетFalse:
it.dropwhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 3, 4В следующей функции генератораtakewhile() иdropwhile() составлены для получения кортежей последовательных положительных элементов последовательности:
def consecutive_positives(sequence, zero=0):
def _consecutives():
for itr in it.repeat(iter(sequence)):
yield tuple(it.takewhile(lambda p: p > zero,
it.dropwhile(lambda p: p <= zero, itr)))
return it.takewhile(lambda t: len(t), _consecutives())Функцияconsecutive_positives() работает, потому чтоrepeat() продолжает возвращать указатель на итератор по аргументуsequence, который частично потребляется на каждой итерации вызовомtuple() вyield заявление.
Вы можете использоватьconsecutive_positives(), чтобы получить генератор, который производит кортежи последовательных положительных точек данных вgains:
growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0))Теперь вы можете использоватьreduce() для извлечения самой длинной полосы роста:
longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y,
growth_streaks)Собирая все вместе, вот полный скрипт, который будет читать данные из файлаSP500.csv и распечатывать максимальное усиление / убыток и самую длинную полосу роста:
from collections import namedtuple
import csv
from datetime import datetime
import itertools as it
import functools as ft
class DataPoint(namedtuple('DataPoint', ['date', 'value'])):
__slots__ = ()
def __le__(self, other):
return self.value <= other.value
def __lt__(self, other):
return self.value < other.value
def __gt__(self, other):
return self.value > other.value
def consecutive_positives(sequence, zero=0):
def _consecutives():
for itr in it.repeat(iter(sequence)):
yield tuple(it.takewhile(lambda p: p > zero,
it.dropwhile(lambda p: p <= zero, itr)))
return it.takewhile(lambda t: len(t), _consecutives())
def read_prices(csvfile, _strptime=datetime.strptime):
with open(csvfile) as infile:
reader = csv.DictReader(infile)
for row in reader:
yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(),
value=float(row['Adj Close']))
# Read prices and calculate daily percent change.
prices = tuple(read_prices('SP500.csv'))
gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.))
for day, prev_day in zip(prices[1:], prices))
# Find maximum daily gain/loss.
zdp = DataPoint(None, 0) # zero DataPoint
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= zdp, gains))
max_loss = ft.reduce(min, it.filterfalse(lambda p: p > zdp, gains), zdp)
# Find longest growth streak.
growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0))
longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y,
growth_streaks)
# Display results.
print('Max gain: {1:.2f}% on {0}'.format(*max_gain))
print('Max loss: {1:.2f}% on {0}'.format(*max_loss))
print('Longest growth streak: {num_days} days ({first} to {last})'.format(
num_days=len(longest_streak),
first=longest_streak[0].date,
last=longest_streak[-1].date
))Выполнение приведенного выше сценария дает следующий результат:
Max gain: 11.58% on 2008-10-13
Max loss: -20.47% on 1987-10-19
Longest growth streak: 14 days (1971-03-26 to 1971-04-15)Раздел Резюме
В этом разделе вы рассмотрели много вопросов, но увидели только несколько функций изitertools. Давайте рассмотрим их сейчас.
itertools.filterfalse Пример
filterfalse(pred, iterable)Вернуть те элементы последовательности, для которых
pred(item)ложно. ЕслиpredравноNone, вернуть элементы, которые являются ложными.
>>>
>>> filterfalse(bool, [1, 0, 1, 0, 0])
0, 0, 0itertools.takewhile Пример
takewhile(pred, iterable)Возвращать последовательные записи из итерации, пока
predоценивается как истина для каждой записи.
>>>
>>> takewhile(bool, [1, 1, 1, 0, 0])
1, 1, 1itertools.dropwhile Пример
dropwhile(pred, iterable)Удалять элементы из итерации, пока
pred(item)истинно. После этого возвращайте каждый элемент, пока итерабельность не будет исчерпана.
>>>
>>> dropwhile(bool, [1, 1, 1, 0, 0, 1, 1, 0])
0, 0, 1, 1, 0Вы действительно начинаете осваивать все этоitertools! Команда сообщества по плаванию хотела бы поручить вам выполнение небольшого проекта.
Создание эстафетных команд на основе данных пловцов
В этом примере вы будете читать данные из файла CSV, содержащего время плавания для общественной команды по плаванию со всех соревнований по плаванию в течение сезона. Цель - определить, какие пловцы должны быть в эстафетных командах для каждого гребка в следующем сезоне.
В каждом гребке должна участвовать эстафетная команда «А» и «В» по четыре пловца в каждой. Команда «А» должна включать четырех пловцов с лучшими показателями гребка, а команда «В» - пловцов с последующими четырьмя лучшими результатами.
Данные для этого примера можно найтиhere. Если вы хотите продолжить, загрузите его в свой текущий рабочий каталог и сохраните какswimmers.csv.
Вот первые 10 строкswimmers.csv:
$ head -n 10 swimmers.csv
Event,Name,Stroke,Time1,Time2,Time3
0,Emma,freestyle,00:50:313667,00:50:875398,00:50:646837
0,Emma,backstroke,00:56:720191,00:56:431243,00:56:941068
0,Emma,butterfly,00:41:927947,00:42:062812,00:42:007531
0,Emma,breaststroke,00:59:825463,00:59:397469,00:59:385919
0,Olivia,freestyle,00:45:566228,00:46:066985,00:46:044389
0,Olivia,backstroke,00:53:984872,00:54:575110,00:54:932723
0,Olivia,butterfly,01:12:548582,01:12:722369,01:13:105429
0,Olivia,breaststroke,00:49:230921,00:49:604561,00:49:120964
0,Sophia,freestyle,00:55:209625,00:54:790225,00:55:351528Три момента в каждой строке представляют время, записанное тремя разными секундомерами, и даны в форматеMM:SS:mmmmmm (минуты, секунды, микросекунды). Принятое время для события - этоmedian этих трех времен,not - среднее значение.
Начнем с создания подклассаEvent объектаnamedtuple, как мы это сделали вSP500 example:
from collections import namedtuple
class Event(namedtuple('Event', ['stroke', 'name', 'time'])):
__slots__ = ()
def __lt__(self, other):
return self.time < other.timeСвойство.stroke сохраняет название гребка в событии,.name сохраняет имя пловца, а.time записывает допустимое время для события. Метод dunder.__lt__() позволяет вызыватьmin() для последовательности объектовEvent.
Чтобы прочитать данные из CSV в кортеж объектовEvent, вы можете использовать объектcsv.DictReader:
import csv
import datetime
import statistics
def read_events(csvfile, _strptime=datetime.datetime.strptime):
def _median(times):
return statistics.median((_strptime(time, '%M:%S:%f').time()
for time in row['Times']))
fieldnames = ['Event', 'Name', 'Stroke']
with open(csvfile) as infile:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
next(reader) # skip header
for row in reader:
yield Event(row['Stroke'], row['Name'], _median(row['Times']))
events = tuple(read_events('swimmers.csv'))Генераторread_events() считывает каждую строку файлаswimmers.csv в объектOrderedDict в следующей строке:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')При назначении поля'Times' дляrestkey столбцы «Time1», «Time2» и «Time3» каждой строки в файле CSV будут сохранены в списке на'Times'. ключOrderedDict, возвращенныйcsv.DictReader.
Например, первая строка файла (исключая строку заголовка) считывается в следующий объект:
OrderedDict([('Event', '0'),
('Name', 'Emma'),
('Stroke', 'freestyle'),
('Times', ['00:50:313667', '00:50:875398', '00:50:646837'])])Затемread_events() возвращает объектEvent с гребком, именем пловца и средним временем (какdatetime.time object), возвращаемым функцией_median(), которая вызываетstatistics.median() в списке раз подряд.
Поскольку каждый элемент в списке значений времени считываетсяcsv.DictReader() как строка,_median() используетdatetime.datetime.strptime() classmethod для создания экземпляра объекта времени из каждой строки.
Наконец, создается кортеж из объектовEvent:
events = tuple(read_events('swimmers.csv'))Первые пять элементовevents выглядят так:
>>>
>>> events[:5]
(Event(stroke='freestyle', name='Emma', time=datetime.time(0, 0, 50, 646837)),
Event(stroke='backstroke', name='Emma', time=datetime.time(0, 0, 56, 720191)),
Event(stroke='butterfly', name='Emma', time=datetime.time(0, 0, 42, 7531)),
Event(stroke='breaststroke', name='Emma', time=datetime.time(0, 0, 59, 397469)),
Event(stroke='freestyle', name='Olivia', time=datetime.time(0, 0, 46, 44389)))Теперь, когда у вас есть данные в памяти, что вы с ними делаете? Вот план атаки:
-
Сгруппируйте события по штриху.
-
Для каждого удара:
-
Сгруппируйте свои соревнования по имени пловца и определите лучшее время для каждого пловца.
-
Закажите пловцов на лучшее время.
-
Первые четыре пловца составляют команду «А» за гребок, а следующие четыре пловца составляют команду «Б».
-
Функцияitertools.groupby() позволяет легко группировать объекты в итеративном режиме. Требуется итерацияinputs иkey для группировки, и возвращается объект, содержащий итераторы по элементамinputs, сгруппированным по ключу.
Вот простой примерgroupby():
>>>
>>> data = [{'name': 'Alan', 'age': 34},
... {'name': 'Catherine', 'age': 34},
... {'name': 'Betsy', 'age': 29},
... {'name': 'David', 'age': 33}]
...
>>> grouped_data = it.groupby(data, key=lambda x: x['age'])
>>> for key, grp in grouped_data:
... print('{}: {}'.format(key, list(grp)))
...
34: [{'name': 'Alan', 'age': 34}, {'name': 'Betsy', 'age': 34}]
29: [{'name': 'Catherine', 'age': 29}]
33: [{'name': 'David', 'age': 33}]Если ключ не указан,groupby() по умолчанию группирует по «идентичности», то есть объединяет идентичные элементы в итерируемом элементе:
>>>
>>> for key, grp in it.groupby([1, 1, 2, 2, 2, 3]:
... print('{}: {}'.format(key, list(grp)))
...
1: [1, 1]
2: [2, 2, 2]
3: [3]Объект, возвращаемыйgroupby(), похож на словарь в том смысле, что возвращаемые итераторы связаны с ключом. Однако, в отличие от словаря, он не позволит вам получить доступ к своим значениям по имени ключа:
>>> grouped_data[1]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'itertools.groupby' object is not subscriptable Фактически,groupby() returns an iterator over tuples whose first components are keys and second components are iterators over the grouped data:
>>>
>>> grouped_data = it.groupby([1, 1, 2, 2, 2, 3])
>>> list(grouped_data)
[(1, ),
(2, ),
(3, )] При использованииgroupby() следует иметь в виду, что он не такой умный, как вам хотелось бы. По мере того, какgroupby() просматривает данные, он агрегирует элементы до тех пор, пока не встретится элемент с другим ключом, после чего он запускает новую группу:
>>>
>>> grouped_data = it.groupby([1, 2, 1, 2, 3, 2])
>>> for key, grp in grouped_data:
... print('{}: {}'.format(key, list(grp)))
...
1: [1]
2: [2]
1: [1]
2: [2]
3: [3]
2: [2]Сравните это, скажем, с командой SQLGROUP BY, которая группирует элементы независимо от их порядка появления.
При работе сgroupby() вам необходимо отсортировать данные по тому же ключу, по которому вы хотите сгруппировать. В противном случае вы можете получить неожиданный результат. Это настолько распространено, что помогает написать служебную функцию, которая позаботится об этом за вас:
def sort_and_group(iterable, key=None):
"""Group sorted `iterable` on `key`."""
return it.groupby(sorted(iterable, key=key), key=key)Возвращаясь к примеру с пловцами, первое, что вам нужно сделать, это создать цикл for, который перебирает данные в кортежеevents, сгруппированные по штриху:
for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke):Затем вам нужно сгруппировать итераторevts по имени пловца внутри указанного выше циклаfor:
events_by_name = sort_and_group(evts, key=lambda evt: evt.name)Чтобы вычислить лучшее время для каждого пловца вevents_by_name, вы можете вызватьmin() для событий в этой группе пловцов. (Это работает, потому что вы реализовали dunder-метод.__lt__() в классеEvents.)
best_times = (min(evt) for _, evt in events_by_name)Обратите внимание, что генераторbest_times выдает объектыEvent, содержащие лучшее время гребка для каждого пловца. Чтобы создать эстафетные команды, вам нужно отсортироватьbest_times по времени и объединить результат в группы по четыре. Чтобы агрегировать результаты, вы можете использовать функциюgrouper() из разделаThe grouper() recipe и использоватьislice() для захвата первых двух групп.
sorted_by_time = sorted(best_times, key=lambda evt: evt.time)
teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2))Теперьteams является итератором ровно по двум кортежам, представляющим команды «A» и «B» для штриха. Первый компонент каждого кортежа - это буква «A» или «B», а второй компонент - это итератор по объектамEvent, содержащим пловцов в команде. Теперь вы можете распечатать результаты:
for team, swimmers in teams:
print('{stroke} {team}: {names}'.format(
stroke=stroke.capitalize(),
team=team,
names=', '.join(swimmer.name for swimmer in swimmers)
))Вот полный сценарий:
from collections import namedtuple
import csv
import datetime
import itertools as it
import statistics
class Event(namedtuple('Event', ['stroke', 'name', 'time'])):
__slots__ = ()
def __lt__(self, other):
return self.time < other.time
def sort_and_group(iterable, key=None):
return it.groupby(sorted(iterable, key=key), key=key)
def grouper(iterable, n, fillvalue=None):
iters = [iter(iterable)] * n
return it.zip_longest(*iters, fillvalue=fillvalue)
def read_events(csvfile, _strptime=datetime.datetime.strptime):
def _median(times):
return statistics.median((_strptime(time, '%M:%S:%f').time()
for time in row['Times']))
fieldnames = ['Event', 'Name', 'Stroke']
with open(csvfile) as infile:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
next(reader) # Skip header.
for row in reader:
yield Event(row['Stroke'], row['Name'], _median(row['Times']))
events = tuple(read_events('swimmers.csv'))
for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke):
events_by_name = sort_and_group(evts, key=lambda evt: evt.name)
best_times = (min(evt) for _, evt in events_by_name)
sorted_by_time = sorted(best_times, key=lambda evt: evt.time)
teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2))
for team, swimmers in teams:
print('{stroke} {team}: {names}'.format(
stroke=stroke.capitalize(),
team=team,
names=', '.join(swimmer.name for swimmer in swimmers)
))Если вы запустите приведенный выше код, вы получите следующий результат:
Backstroke A: Sophia, Grace, Penelope, Addison
Backstroke B: Elizabeth, Audrey, Emily, Aria
Breaststroke A: Samantha, Avery, Layla, Zoe
Breaststroke B: Lillian, Aria, Ava, Alexa
Butterfly A: Audrey, Leah, Layla, Samantha
Butterfly B: Alexa, Zoey, Emma, Madison
Freestyle A: Aubrey, Emma, Olivia, Evelyn
Freestyle B: Elizabeth, Zoe, Addison, MadisonКуда пойти отсюда
Если вы зашли так далеко, поздравляем! Надеюсь, вам понравилось путешествие.
itertools - мощный модуль в стандартной библиотеке Python и важный инструмент в вашем наборе инструментов. С его помощью вы можете писать более быстрый и эффективный с точки зрения памяти код, который часто проще и легче читать (хотя это не всегда так, как вы видели в разделе оsecond order recurrence relations).
Во всяком случае,itertools является свидетельством мощи итераторов иlazy evaluation. Несмотря на то, что вы видели много техник, эта статья лишь поверхностно.
Думаю, это означает, что ваше путешествие только начинается.
Free Bonus:Click here to get our itertools cheat sheet, в котором резюмируются методы, продемонстрированные в этом руководстве.
Фактически, в этой статье пропущены две функцииitertools:starmap() иcompress(). По моему опыту, это две менее используемые функцииitertools, но я настоятельно рекомендую вам прочитать их документацию и поэкспериментировать с вашими собственными вариантами использования!
Вот несколько мест, где вы можете найти больше примеровitertools в действии (спасибо Брэду Соломону за эти прекрасные предложения):
Наконец, для получения дополнительных инструментов для построения итераторов взгляните наmore-itertools.
Есть ли у вас какие-нибудь любимые рецепты / варианты использованияitertools? Мы будем рады услышать о них в комментариях!
Мы хотели бы поблагодарить наших читателей Путчер и Самир Агаев за указание на пару ошибок в оригинальной версии этой статьи.