Ускорьте вашу программу на Python с параллелизмом
Если вы слышали много разговоров о + asyncio + being, добавленных в Python, но вам интересно, как он сравнивается с другими методами параллелизма, или вам интересно, что такое параллелизм и Как это может ускорить вашу программу, вы пришли в нужное место.
*В этой статье вы узнаете следующее:*
-
Что такое параллелизм?
-
Что такое параллелизм Как сравниваются некоторые из методов параллелизма Python, включая
+ threading +,+ asyncio +и+ multiprocessing + -
Когда использовать параллелизм в вашей программе и какой модуль использовать
В этой статье предполагается, что у вас есть базовые знания Python и вы используете как минимум версию 3.6 для запуска примеров. Вы можете скачать примеры из Real Python репозитория GitHub.
*Бесплатный бонус:* ссылка: [5 Thinkts On Python Mastery], бесплатный курс для разработчиков Python, который показывает вам план и мышление, необходимые для перехода на новый уровень Python.
*__ Пройдите тест:* Проверьте свои знания с помощью нашего интерактивного теста «Python Concurrency». По окончании вы получите оценку, чтобы вы могли отслеживать прогресс в обучении с течением времени:
ссылка:/викторины/Python-параллелизм/[пройти тест »]
Что такое параллелизм?
Словарное определение параллелизма - одновременное вхождение. В Python вещи, которые происходят одновременно, называются разными именами (поток, задача, процесс), но на высоком уровне все они относятся к последовательности инструкций, которые выполняются по порядку.
Мне нравится думать о них как о разных направлениях мысли. Каждый может быть остановлен в определенных точках, и процессор или мозг, который их обрабатывает, может переключиться на другой. Состояние каждого из них сохраняется, поэтому его можно перезапустить с того места, где оно было прервано.
Вы можете удивиться, почему Python использует разные слова для одного и того же понятия. Оказывается, что потоки, задачи и процессы одинаковы, если вы просматриваете их с высокого уровня. Как только вы начинаете копаться в деталях, все они представляют немного разные вещи. По мере продвижения по примерам вы увидите, как они различаются.
Теперь давайте поговорим об одновременной части этого определения. Вы должны быть немного осторожнее, потому что, когда вы переходите к деталям, только + multiprocessing + 'фактически запускает эти последовательности мыслей буквально в одно и то же время. `+ Threading + и + asyncio + работают на одном процессоре и поэтому запускаются только по одному за раз. Они просто ловко находят способы по очереди ускорить весь процесс. Несмотря на то, что они не управляют разными направлениями мысли одновременно, мы все равно называем это параллелизмом.
То, как потоки или задачи сменяются, является большой разницей между + threading + и + asyncio +. В + threading + операционная система фактически знает о каждом потоке и может в любой момент прервать его, чтобы запустить другой поток. Это называется pre-emptive многозадачность, так как операционная система может заблокировать ваш поток для переключения.
Упреждающая многозадачность удобна тем, что коду в потоке не нужно ничего делать для переключения. Это также может быть сложно из-за этой фразы «в любое время». Это переключение может произойти в середине одного оператора Python, даже тривиального, такого как + x = x + 1 +.
+ Asyncio +, с другой стороны, использует cooperative многозадачность. Задачи должны сотрудничать, объявляя, когда они готовы быть выключенными. Это означает, что код в задаче должен немного измениться, чтобы это произошло.
Преимущество этой дополнительной работы заключается в том, что вы всегда знаете, где ваша задача будет заменена. Он не будет заменен в середине оператора Python, если этот оператор не помечен. Позже вы увидите, как это может упростить части вашего дизайна.
Что такое параллелизм?
До сих пор вы рассматривали параллелизм, который происходит на одном процессоре. Как насчет всех этих процессорных ядер, которые есть в вашем новом ноутбуке? Как вы можете их использовать? + multiprocessing + - это ответ.
С + multiprocessing +, Python создает новые процессы. Процесс здесь можно рассматривать как почти совершенно другую программу, хотя технически они обычно определяются как набор ресурсов, в которые входят память, файловые дескрипторы и тому подобное. Один из способов думать об этом заключается в том, что каждый процесс выполняется в своем собственном интерпретаторе Python.
Поскольку они представляют собой разные процессы, каждый ваш ход мыслей в многопроцессорной программе может работать на разных ядрах. Работа на другом ядре означает, что они на самом деле могут работать одновременно, что невероятно. Есть некоторые сложности, которые возникают из-за этого, но Python довольно хорошо справляется с их сглаживанием в большинстве случаев.
Теперь, когда у вас есть представление о том, что такое параллелизм и параллелизм, давайте рассмотрим их различия, а затем посмотрим, почему они могут быть полезны:
| Concurrency Type | Switching Decision | Number of Processors |
|---|---|---|
Pre-emptive multitasking ( |
The operating system decides when to switch tasks external to Python. |
1 |
Cooperative multitasking ( |
The tasks decide when to give up control. |
1 |
Multiprocessing ( |
The processes all run at the same time on different processors. |
Many |
Каждый из этих типов параллелизма может быть полезным. Давайте посмотрим, какие типы программ могут помочь вам ускорить работу.
Когда полезен параллелизм?
Параллельность может иметь большое значение для двух типов проблем. Они обычно называются привязанными к процессору и связанными с вводом/выводом.
Связанные с вводом/выводом проблемы приводят к замедлению работы вашей программы, поскольку она часто должна ожидать ввода/вывода (I/O) от какого-либо внешнего ресурса. Они часто возникают, когда ваша программа работает с вещами, которые намного медленнее, чем ваш процессор.
Примеры вещей, которые медленнее вашего процессора, легион, но, к счастью, ваша программа не взаимодействует с большинством из них. Медленные вещи, с которыми ваша программа будет взаимодействовать чаще всего, - это файловая система и сетевые подключения.
Давайте посмотрим, как это выглядит:
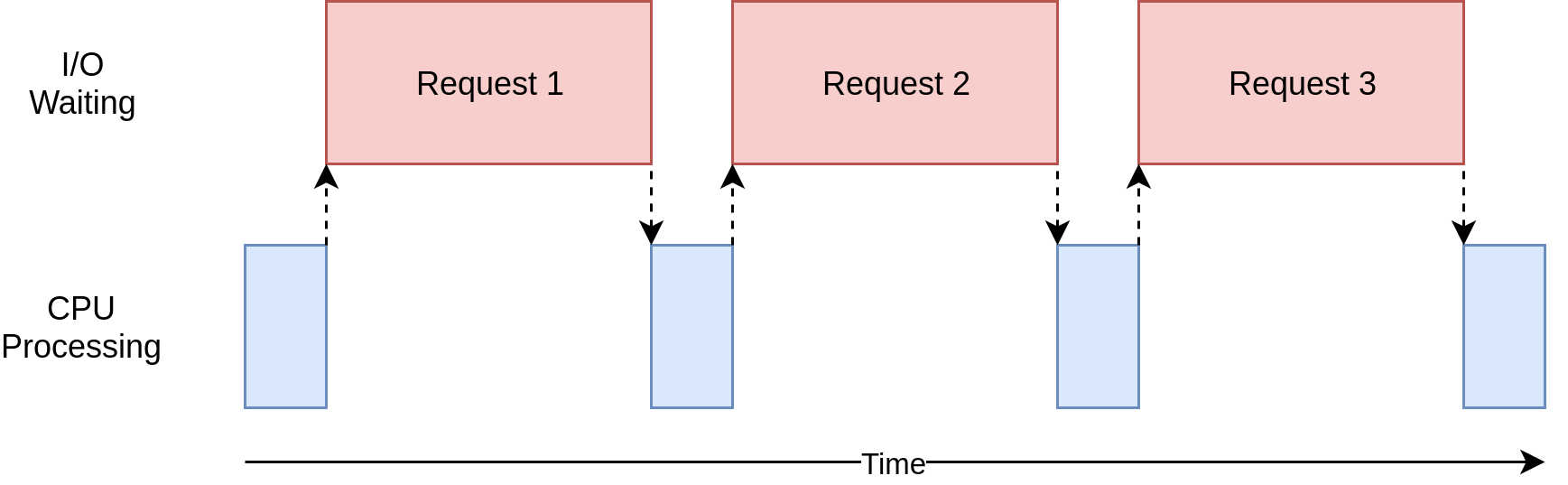
На диаграмме выше синие прямоугольники показывают время, когда ваша программа выполняет работу, а красные - время ожидания завершения операции ввода-вывода. Эта диаграмма не масштабируется, потому что запросы в Интернете могут занимать на несколько порядков больше времени, чем инструкции процессора, поэтому ваша программа может в итоге тратить большую часть времени на ожидание. Это то, что ваш браузер делает большую часть времени.
С другой стороны, есть классы программ, которые выполняют значительные вычисления, не обращаясь к сети и не обращаясь к файлу. Это программы, связанные с ЦП, поскольку ресурсом, ограничивающим скорость вашей программы, является ЦП, а не сеть или файловая система.
Вот соответствующая диаграмма для программы, связанной с процессором:
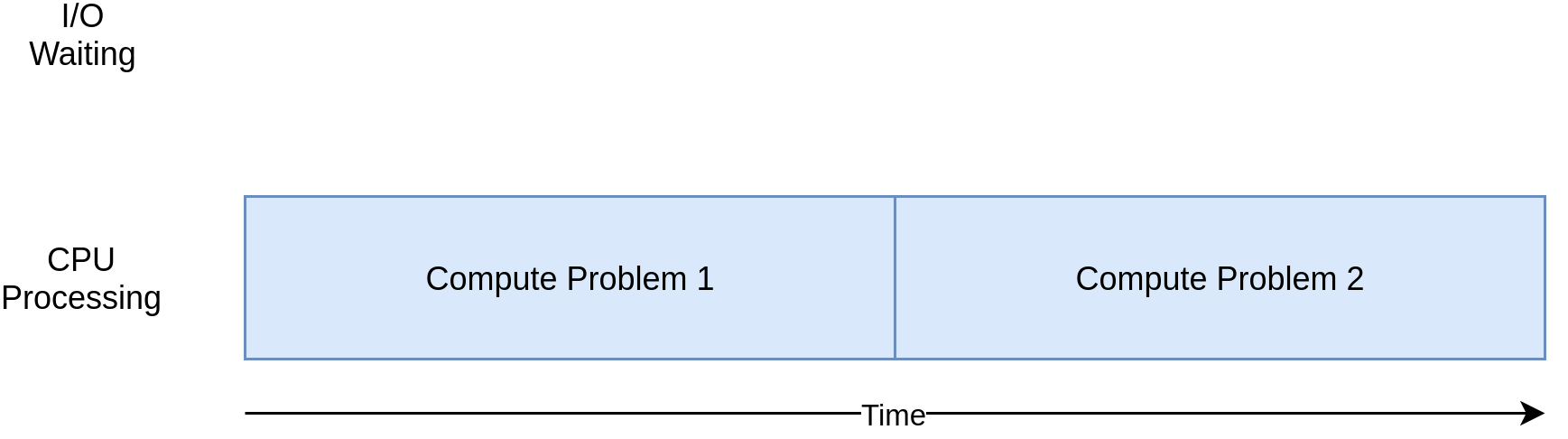
При работе с примерами в следующем разделе вы увидите, что разные формы параллелизма работают лучше или хуже с программами с привязкой к процессору и с вводом/выводом. Добавление параллелизма в вашу программу добавляет дополнительный код и усложняет задачу, поэтому вам нужно решить, стоит ли потенциальное ускорение дополнительных усилий. К концу этой статьи у вас должно быть достаточно информации, чтобы начать принимать это решение.
Вот краткое резюме, чтобы прояснить эту концепцию:
| I/O-Bound Process | CPU-Bound Process |
|---|---|
Your program spends most of its time talking to a slow device, like a network connection, a hard drive, or a printer. |
You program spends most of its time doing CPU operations. |
Speeding it up involves overlapping the times spent waiting for these devices. |
Speeding it up involves finding ways to do more computations in the same amount of time. |
Сначала вы посмотрите на программы, связанные с вводом/выводом. Затем вы увидите код, связанный с программами, связанными с процессором.
Как ускорить программу ввода-вывода
Давайте начнем с того, что сосредоточимся на программах, связанных с вводом-выводом, и на общей проблеме: загрузка контента по сети. В нашем примере вы будете загружать веб-страницы с нескольких сайтов, но это может быть любой сетевой трафик. Его проще визуализировать и настраивать с помощью веб-страниц.
Синхронная версия
Начнем с не параллельной версии этой задачи. Обратите внимание, что для этой программы требуется модуль + запросы +. Вы должны выполнить + pip install request + перед его запуском, вероятно, используя virtualenv. Эта версия вообще не использует параллелизм:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Как видите, это довольно короткая программа. + download_site () + просто загружает содержимое из URL и печатает размер. Следует отметить одну небольшую вещь: мы используем http://docs.python-requests.org/en/master/user/advanced/#session-objects [+ Session +] объект из + запросы +.
Можно просто использовать + get () + из + запросы + напрямую, но создание объекта + Session + позволяет + запросам + выполнять некоторые хитрые сетевые трюки и реально ускорить процесс.
+ download_all_sites () + создает + Session + и затем просматривает список сайтов, загружая каждый из них по очереди. Наконец, он выводит, сколько времени занял этот процесс, чтобы вы могли с удовлетворением увидеть, насколько параллелизм помог нам в следующих примерах.
Диаграмма обработки для этой программы будет очень похожа на диаграмму ввода-вывода в последнем разделе.
*Примечание:* Сетевой трафик зависит от многих факторов, которые могут варьироваться от секунды к секунде. Я видел, как время этих тестов удваивалось от одного запуска к другому из-за проблем с сетью.
*Почему синхронная версия качается*
Самое замечательное в этой версии кода в том, что это легко. Это было сравнительно легко написать и отладить. Это также более простой способ думать. Через него проходит только один ход мыслей, поэтому вы можете предсказать, каким будет следующий шаг и как он будет себя вести.
*Проблемы с синхронной версией*
Большая проблема здесь в том, что он относительно медленный по сравнению с другими решениями, которые мы предлагаем. Вот пример того, что окончательный вывод дал на моей машине:
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 seconds*Примечание:* Ваши результаты могут значительно отличаться. При запуске этого сценария я видел, как время варьируется от 14,2 до 21,9 секунд. В этой статье я выбрал самый быстрый из трех заездов. Различия между методами все еще будут очевидны.
Однако медлительность не всегда является большой проблемой. Если запущенная программа занимает всего 2 секунды с синхронной версией и запускается редко, вероятно, не стоит добавлять параллелизм. Вы можете остановиться здесь.
Что если ваша программа часто запускается? Что делать, если для запуска требуются часы? Давайте перейдем к параллелизму, переписав эту программу с помощью + threading +.
+ Threading + Версия
Как вы, наверное, догадались, написание многопоточной программы требует больше усилий. Вы можете быть удивлены тем, как мало дополнительных усилий требуется для простых случаев. Вот как выглядит та же программа с + threading +:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Когда вы добавляете + threading +, общая структура остается той же, и вам нужно всего лишь внести несколько изменений. + download_all_sites () + изменен с вызова функции один раз для каждого сайта на более сложную структуру.
В этой версии вы создаете + ThreadPoolExecutor +, что кажется сложной задачей. Давайте разберемся с этим: + ThreadPoolExecutor + = + Thread + + + Pool + + + Executor +.
Вы уже знаете о части + Thread +. Это просто ход мыслей, о которых мы упоминали ранее. В части + Pool + она начинает становиться интересной. Этот объект собирается создать пул потоков, каждый из которых может работать одновременно. Наконец, + Executor + - это часть, которая будет контролировать, как и когда будет работать каждый из потоков в пуле. Он выполнит запрос в пуле.
Полезно, что стандартная библиотека реализует + ThreadPoolExecutor + в качестве диспетчера контекста, поэтому вы можете использовать синтаксис + with + для управления созданием и освобождением пула + Threads +.
Если у вас есть + ThreadPoolExecutor +, вы можете использовать его удобный метод + .map () +. Этот метод запускает переданную функцию на каждом из сайтов в списке. Самое замечательное то, что он автоматически запускает их одновременно, используя пул потоков, которыми он управляет.
Те из вас, кто работает с другими языками или даже с Python 2, вероятно, задаются вопросом, где обычные объекты и функции, которые управляют деталями, к которым вы привыкли при работе с + threading +, такими вещами, как + Thread.start () + `, + Thread.join () + и + Queue + `.
Они все еще там, и вы можете использовать их, чтобы получить детальный контроль над тем, как работают ваши потоки. Но, начиная с Python 3.2, в стандартную библиотеку добавлена абстракция более высокого уровня под названием + Executors +, которая управляет многими деталями, если вам не нужен этот детальный элемент управления.
Другое интересное изменение в нашем примере заключается в том, что каждый поток должен создать свой собственный объект + reports.Session () +. Когда вы просматриваете документацию по + query +, это не всегда легко сказать, но, читая this проблема, кажется довольно ясным, что вам нужно отдельный сеанс для каждого потока.
Это одна из интересных и сложных проблем с + threading +. Поскольку операционная система контролирует, когда ваша задача прерывается и запускается другая задача, любые данные, которые совместно используются потоками, должны быть защищены или поточно-ориентированы. К сожалению, + reports.Session () + не является поточно-ориентированным.
Существует несколько стратегий обеспечения доступа к данным для многопоточных приложений в зависимости от того, что это за данные и как вы их используете. Одним из них является использование поточно-ориентированных структур данных, таких как + Queue + из модуля Python + queue +.
Эти объекты используют низкоуровневые примитивы, такие как https://docs.python.org/2/library/threading.html#lock-objects [+ threading.Lock +], чтобы гарантировать, что только один поток может получить доступ к блоку кода или немного памяти в то же время. Вы используете эту стратегию косвенно через объект + ThreadPoolExecutor +.
Еще одна стратегия, используемая здесь - это локальное хранилище потоков + Threading.local () + создает объект, который выглядит как глобальный, но специфичен для каждого отдельного потока. В вашем примере это делается с помощью + threadLocal + и + get_session () +:
threadLocal = threading.local()
def get_session():
if not hasattr(threadLocal, "session"):
threadLocal.session = requests.Session()
return threadLocal.session+ ThreadLocal + находится в модуле + threading +, чтобы конкретно решить эту проблему. Это выглядит немного странно, но вы хотите создать только один из этих объектов, а не один для каждого потока. Сам объект заботится о разделении доступа из разных потоков к разным данным.
Когда вызывается + get_session () +, + session +, который он ищет, специфичен для конкретного потока, в котором он выполняется. Таким образом, каждый поток создаст один сеанс в первый раз, когда он вызывает + get_session () +, а затем будет просто использовать этот сеанс при каждом последующем вызове на протяжении всей своей жизни.
Наконец, быстрое примечание о выборе количества потоков. Вы можете видеть, что пример кода использует 5 потоков. Не стесняйтесь поиграть с этим номером и посмотреть, как меняется общее время. Вы можете ожидать, что один поток будет загружен быстрее, но, по крайней мере, в моей системе это не так. Я нашел самые быстрые результаты где-то между 5 и 10 нитями. Если вы идете выше этого уровня, то дополнительные затраты на создание и уничтожение потоков стирают любую экономию времени.
Трудный ответ здесь заключается в том, что правильное количество потоков не является постоянной величиной от одной задачи к другой. Некоторые эксперименты не требуется.
*Почему `+ threading +` Version Rocks*
Это быстро! Вот самый быстрый из моих тестов. Помните, что не одновременная версия заняла более 14 секунд:
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 secondsВот как выглядит временная диаграмма его выполнения:
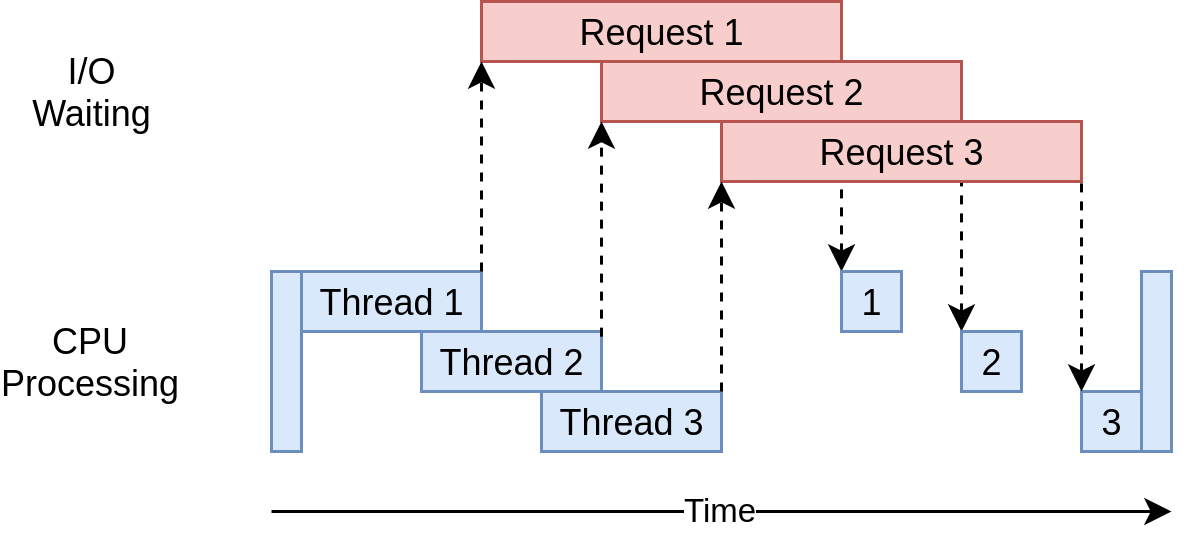
Он использует несколько потоков для одновременной отправки нескольких открытых запросов на веб-сайты, что позволяет вашей программе перекрывать время ожидания и быстрее получать конечный результат! Yippee! Это была цель.
*Проблемы с `+ threading +` Version*
Ну, как вы можете видеть из примера, требуется немного больше кода, чтобы это произошло, и вам действительно нужно задуматься о том, какие данные распределяются между потоками.
Потоки могут взаимодействовать способами, которые являются тонкими и трудными для обнаружения. Эти взаимодействия могут вызывать условия гонки, которые часто приводят к случайным, прерывистым ошибкам, которые может быть довольно трудно найти. Те из вас, кто не знаком с понятием условий гонки, возможно, захотят расширить и прочитать раздел ниже.
+ asyncio + Версия
Прежде чем приступить к рассмотрению примера кода + asyncio +, давайте подробнее поговорим о том, как работает + asyncio +.
*`+ asyncio +` Основы*
Это будет упрощенная версия + asycio +. Здесь есть много деталей, но они все еще передают идею о том, как это работает.
Общая концепция + asyncio + заключается в том, что один объект Python, называемый циклом событий, контролирует, как и когда запускается каждая задача. Цикл событий знает о каждой задаче и знает, в каком она состоянии. В действительности существует много состояний, в которых могут находиться задачи, но сейчас давайте представим упрощенный цикл обработки событий, в котором только два состояния.
Состояние готовности будет указывать на то, что задача выполняет свою работу и готова к выполнению, а состояние ожидания означает, что задача ожидает завершения какой-то внешней операции, например сетевой операции.
Ваш упрощенный цикл обработки событий поддерживает два списка задач, по одному для каждого из этих состояний. Он выбирает одну из готовых задач и снова запускает ее. Эта задача находится под полным контролем, пока она совместно не вернет управление обратно в цикл обработки событий.
Когда запущенная задача возвращает управление циклу событий, цикл событий помещает эту задачу либо в список готовности, либо в список ожидания, а затем просматривает каждую задачу в списке ожидания, чтобы увидеть, стала ли она готовой к операции ввода-вывода. комплектующие. Он знает, что задачи в списке готовности все еще готовы, потому что знает, что они еще не запущены.
После того, как все задачи будут снова отсортированы в правильный список, цикл обработки событий выбирает следующую задачу для запуска, и процесс повторяется. Ваш упрощенный цикл обработки событий выбирает задачу, которая ожидала дольше всего, и запускает ее. Этот процесс повторяется до завершения цикла обработки событий.
Важным моментом + asyncio + является то, что задачи никогда не сдают контроль без намеренного выполнения. Они никогда не прерываются во время операции. Это позволяет нам легче распределять ресурсы в + asyncio +, чем в + threading +. Вам не нужно беспокоиться о том, чтобы сделать свой код поточно-ориентированным.
Это общий взгляд на то, что происходит с + asyncio +. Если вам нужна более подробная информация, this StackOverflow answer предоставит несколько полезных деталей, если вы хотите копать глубже.
*`+ async +` и `+ await +`*
Теперь давайте поговорим о двух новых ключевых словах, которые были добавлены в Python: + async + и + await +. В свете вышеприведенного обсуждения вы можете рассматривать + await + как магию, которая позволяет задаче передать управление обратно в цикл обработки событий. Когда ваш код ожидает вызова функции, это сигнал о том, что вызов, вероятно, будет чем-то, что займет некоторое время, и что задача должна отказаться от контроля.
Про + async + проще всего представить как флаг для Python, сообщающий, что функция, которая должна быть определена, использует + await +. В некоторых случаях это не совсем верно, например, asynchronous Generators, но это справедливо для многих случаев и дает вам простую модель, пока вы ' начинаем.
Единственным исключением из этого, которое вы увидите в следующем коде, является оператор + async with +, который создает менеджер контекста из объекта, который вы обычно ожидаете. Хотя семантика немного отличается, идея та же: пометить этот менеджер контекста как нечто, что может быть заменено.
Как я уверен, вы можете себе представить, что есть некоторая сложность в управлении взаимодействием между циклом событий и задачами. Для разработчиков, начинающих с + asyncio +, эти детали не важны, но вы должны помнить, что любая функция, которая вызывает + await +, должна быть помечена + async +. В противном случае вы получите синтаксическую ошибку.
*Вернуться к коду*
Теперь, когда вы получили общее представление о том, что такое «+ asyncio », давайте пройдемся по версии « asyncio » примера кода и выясним, как он работает. Обратите внимание, что эта версия добавляет https://aiohttp.readthedocs.io/en/stable/[` aiohttp `]. Вы должны запустить ` pip install aiohttp +` перед запуском:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")Эта версия немного сложнее, чем две предыдущие. Он имеет похожую структуру, но для настройки задач требуется немного больше, чем для создания + ThreadPoolExecutor +. Давайте начнем с верхней части примера.
-
`+ Download_site () + '*
+ download_site () + вверху практически идентична версии + threading +, за исключением ключевого слова + async + в строке определения функции и ключевых слов + async с +, когда вы на самом деле вызываете + session .get () + `. Позже вы поймете, почему `+ Session + может быть передан сюда вместо использования локального хранилища потока.
*`+ download_all_sites () +`*
В + download_all_sites () + вы увидите самое большое изменение из примера + threading +.
Вы можете совместно использовать сеанс для всех задач, поэтому сеанс создается здесь как менеджер контекста. Задачи могут совместно использовать сеанс, поскольку все они выполняются в одном потоке. Невозможно, чтобы одна задача могла прервать другую, когда сеанс находится в плохом состоянии.
Внутри этого диспетчера контекста он создает список задач, используя + asyncio.ensure_future () +, который также заботится о их запуске. После того как все задачи созданы, эта функция использует + asyncio.gather () + для поддержания контекста сеанса до тех пор, пока все задачи не будут выполнены.
Код + threading + делает нечто похожее на это, но детали удобно обрабатываются в + ThreadPoolExecutor +. Там в настоящее время нет класса + AsyncioPoolExecutor +.
Однако здесь есть одно небольшое, но важное изменение, скрытое в деталях. Помните, как мы говорили о количестве создаваемых потоков? В примере + threading + не было очевидно, какое было оптимальное количество потоков.
Одним из замечательных преимуществ + asyncio + является то, что он масштабируется намного лучше, чем + threading +. Каждая задача занимает гораздо меньше ресурсов и меньше времени для создания, чем поток, поэтому создание и запуск большего количества из них работает хорошо. Этот пример просто создает отдельную задачу для каждого сайта для загрузки, которая работает довольно хорошо.
*`+ __ __ главный +`*
Наконец, природа + asyncio + означает, что вы должны запустить цикл обработки событий и сообщить ему, какие задачи нужно запустить. Раздел + main + внизу файла содержит код для + get_event_loop () + и затем + run_until_complete () +. Если ничего другого, они проделали отличную работу по названию этих функций.
Если вы обновились до Python 3.7, разработчики ядра Python упростили этот синтаксис для вас. Вместо + asyncio.get_event_loop (). Run_until_complete () + tongue-twister вы можете просто использовать + asyncio.run () +.
*Почему `+ asyncio + 'Версия Rocks*
Это действительно быстро! В тестах на моей машине это была самая быстрая версия кода с хорошим запасом:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 secondsДиаграмма времени выполнения выглядит очень похоже на то, что происходит в примере + threading +. Просто запросы ввода-вывода выполняются одним потоком:
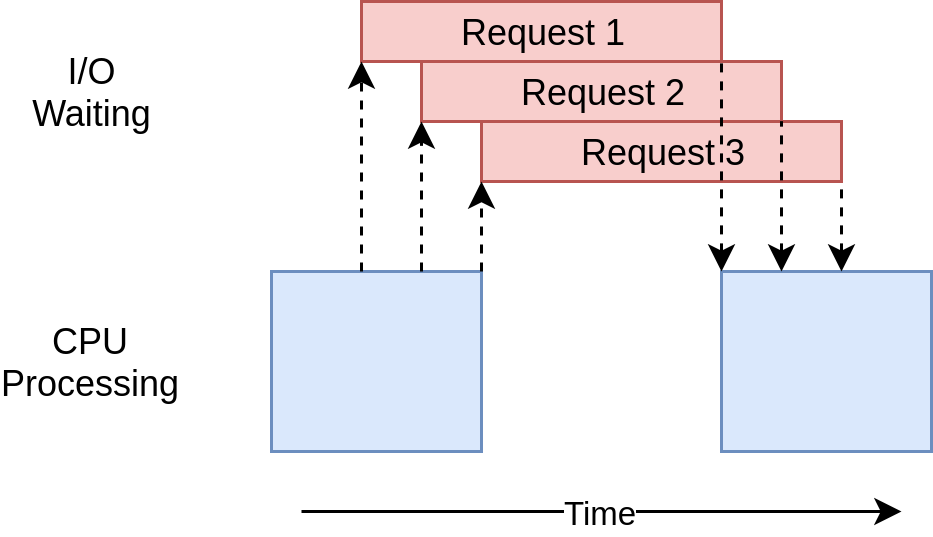
Отсутствие красивой оболочки, такой как + ThreadPoolExecutor +, делает этот код немного более сложным, чем пример + threading +. Это тот случай, когда вам нужно проделать небольшую дополнительную работу, чтобы получить гораздо лучшую производительность.
Также существует распространенный аргумент, что добавление + async + и + await + в соответствующих местах является дополнительным осложнением. В небольшой степени это правда. Обратная сторона этого аргумента заключается в том, что он заставляет вас задуматься о том, когда конкретная задача будет заменена, что может помочь вам создать лучший, более быстрый дизайн.
Проблема масштабирования также вырисовывается здесь. Запуск приведенного выше примера + threading + с потоком для каждого сайта заметно медленнее, чем запуск с несколькими потоками. Запуск примера + asyncio + с сотнями задач не замедлил его вообще.
*Проблемы с версией `+ asyncio +`*
На данный момент есть несколько проблем с + asyncio +. Вам нужны специальные асинхронные версии библиотек, чтобы получить полное преимущество + asycio +. Если бы вы просто использовали + запросы + для загрузки сайтов, это было бы намного медленнее, потому что + запросы + не предназначены для уведомления цикла событий о том, что он заблокирован. Эта проблема становится все меньше и меньше с течением времени, и все больше библиотек охватывают + asyncio +.
Другая, более тонкая проблема заключается в том, что все преимущества совместной многозадачности теряются, если одна из задач не взаимодействует. Незначительная ошибка в коде может привести к тому, что задача будет запущена и будет долго удерживать процессор, что приведет к истощению других задач, которые необходимо запустить. Цикл событий не может быть прерван, если задача не передает управление обратно к нему.
Имея это в виду, давайте перейдем к принципиально иному подходу к параллелизму, + multiprocessing +.
+ многопроцессорная + версия
В отличие от предыдущих подходов, версия кода «+ multiprocessing +» в полной мере использует преимущества множества процессоров, которые есть у вашего крутого нового компьютера. Или, в моем случае, это мой неуклюжий старый ноутбук. Давайте начнем с кода:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Это намного короче, чем пример + asyncio + и на самом деле выглядит очень похоже на пример + threading +, но прежде чем мы углубимся в код, давайте кратко рассмотрим, что + multiprocessing + делает для вас.
*`+ многопроцессорная обработка +` в двух словах*
До этого момента все примеры параллелизма в этой статье выполнялись только на одном процессоре или ядре вашего компьютера. Причины этого связаны с текущим дизайном CPython и тем, что называется Global Interpreter Lock, или GIL.
Эта статья не будет рассказывать о том, как и почему GIL. Сейчас достаточно знать, что синхронные версии + threading + и + asyncio + этого примера все работают на одном процессоре.
+ multiprocessing + в стандартной библиотеке был разработан для преодоления этого барьера и запуска вашего кода на нескольких процессорах. На высоком уровне это достигается путем создания нового экземпляра интерпретатора Python для запуска на каждом процессоре и последующей обработки части вашей программы для его запуска.
Как вы можете себе представить, создание отдельного интерпретатора Python не так быстро, как запуск нового потока в текущем интерпретаторе Python. Это тяжеловесная операция с некоторыми ограничениями и трудностями, но для правильной проблемы она может иметь огромное значение.
*`+ многопроцессорность +` код*
Код имеет несколько небольших изменений по сравнению с нашей синхронной версией. Первый находится в + download_all_sites () +. Вместо того, чтобы просто вызывать + download_site () + несколько раз, он создает объект + multiprocessing.Pool + и отображает + download_site + в итерируемые + sites +. Это должно выглядеть знакомо из примера + threading +.
Здесь происходит то, что + Pool + создает несколько отдельных процессов интерпретатора Python и каждый из них запускает указанную функцию для некоторых элементов итерируемого, который в нашем случае является списком сайтов. Связь между основным процессом и другими процессами обрабатывается модулем + multiprocessing +.
Строка, которая создает + Pool +, заслуживает вашего внимания. Во-первых, он не указывает, сколько процессов нужно создать в + Pool +, хотя это необязательный параметр. По умолчанию + multiprocessing.Pool () + будет определять количество процессоров в вашем компьютере и совпадать с ним. Это часто лучший ответ, и это в нашем случае.
Для этой проблемы увеличение числа процессов не делает вещи быстрее. Это на самом деле замедлило процесс, потому что затраты на настройку и отключение всех этих процессов были больше, чем выгода от параллельного выполнения запросов ввода-вывода.
Далее у нас есть часть этого вызова + initializer = set_global_session +. Помните, что каждый процесс в нашем + Pool + имеет свое собственное пространство памяти. Это означает, что они не могут делиться такими вещами, как объект + Session +. Вы не хотите создавать новый + Session + каждый раз, когда вызывается функция, вы хотите создать один для каждого процесса.
Функциональный параметр + initializer + построен именно для этого случая. Невозможно передать возвращаемое значение из + initializer + в функцию, вызываемую процессом + download_site () +, но вы можете инициализировать глобальную переменную + session + для хранения одного сеанса для каждого процесс. Поскольку каждый процесс имеет свое собственное пространство памяти, глобальный для каждого будет отличаться.
Это действительно все, что нужно сделать. Остальная часть кода очень похожа на то, что вы видели раньше.
*Почему `+ multiprocessing +` Version Rocks*
Версия + multiprocessing + этого примера хороша тем, что ее относительно легко настроить и она требует небольшого дополнительного кода. Это также в полной мере использует мощность процессора в вашем компьютере. Диаграмма времени выполнения для этого кода выглядит следующим образом:
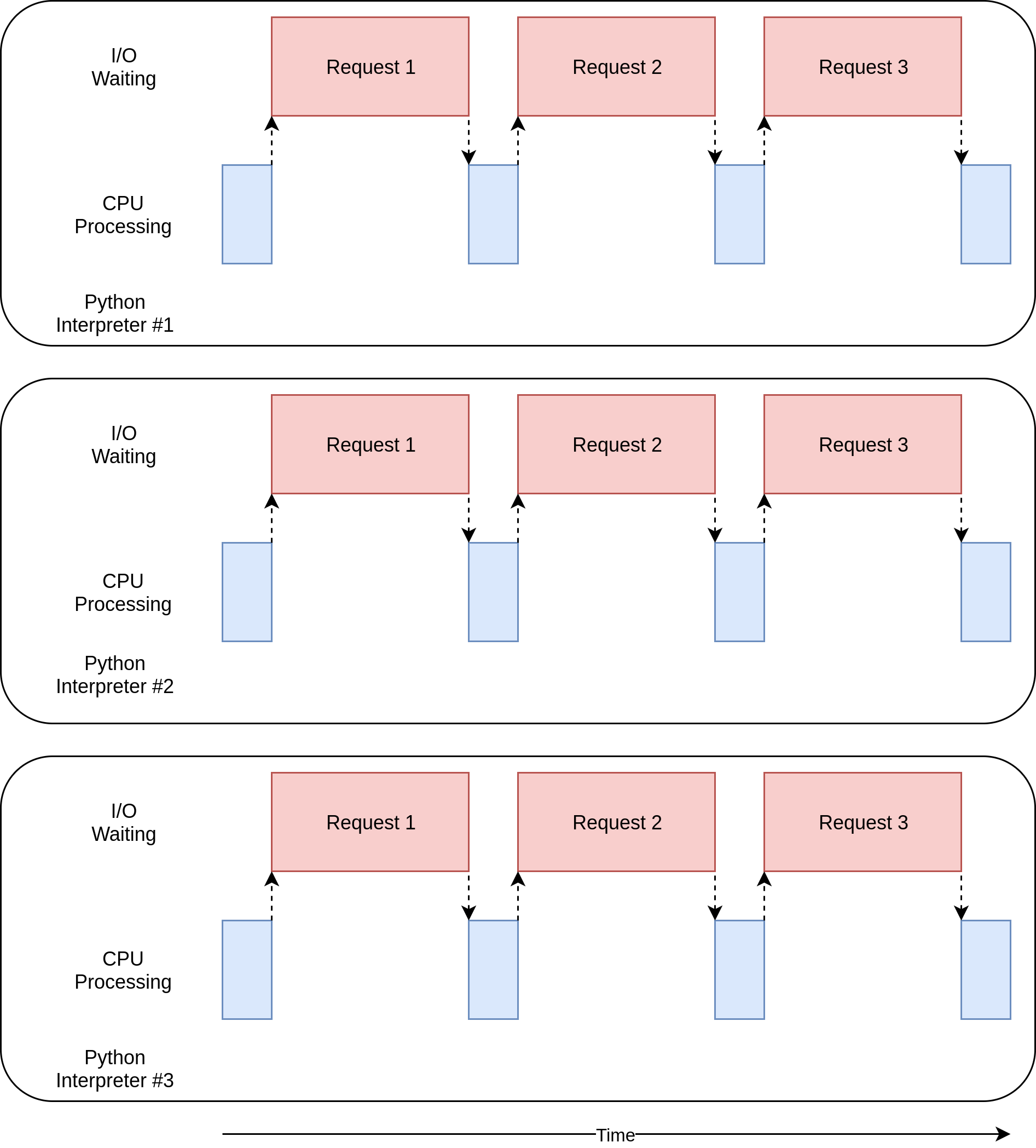
*Проблемы с версией `+ multiprocessing +`*
Эта версия примера требует дополнительной настройки, и глобальный объект + session + является странным. Вы должны потратить некоторое время на размышления о том, какие переменные будут доступны в каждом процессе.
Наконец, он явно медленнее, чем версии + asyncio + и + threading + в этом примере:
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 secondsЭто неудивительно, поскольку проблемы с вводом/выводом не являются причиной того, почему существует + multiprocessing +. Вы увидите больше, когда перейдете к следующему разделу и посмотрите на примеры, связанные с процессором.
Как ускорить программу с привязкой к процессору
Давайте немного переключимся здесь. Все примеры до сих пор имели дело с проблемой ввода/вывода. Теперь вы посмотрите на проблему с процессором. Как вы видели, проблема, связанная с вводом-выводом, тратит большую часть своего времени на ожидание завершения внешних операций, таких как сетевой вызов. С другой стороны, связанная с процессором проблема делает мало операций ввода-вывода, и его общее время выполнения является фактором того, насколько быстро он может обрабатывать требуемые данные.
Для целей нашего примера мы будем использовать несколько глупую функцию для создания чего-то, что требует много времени для запуска на процессоре. Эта функция вычисляет сумму квадратов каждого числа от 0 до переданного значения:
def cpu_bound(number):
return sum(i *i for i in range(number))Вы будете проходить в большом количестве, так что это займет некоторое время. Помните, что это просто заполнитель для вашего кода, который на самом деле делает что-то полезное и требует значительного времени обработки, например, вычисления корней уравнений или сортировки большой структуры данных.
Синхронная версия с привязкой к процессору
Теперь давайте посмотрим на несовпадающую версию примера:
import time
def cpu_bound(number):
return sum(i* i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Этот код вызывает + cpu_bound () + 20 раз с различным большим числом каждый раз. Он делает все это в одном потоке в одном процессе на одном процессоре. Диаграмма времени выполнения выглядит следующим образом:
В отличие от примеров, связанных с вводом/выводом, примеры, связанные с ЦП, обычно достаточно согласованы по времени выполнения. Это занимает около 7,8 секунд на моей машине:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 secondsОчевидно, мы можем добиться большего успеха, чем это. Это все работает на одном процессоре без параллелизма. Давайте посмотрим, что мы можем сделать, чтобы сделать это лучше.
Версии + threading + и + asyncio +
Как вы думаете, сколько переписать этот код с помощью + threading + или + asyncio + ускорит это?
Если вы ответили «Вовсе нет», дайте себе печенье. Если вы ответили: «Это замедлит это», дайте себе два печенья.
И вот почему: в приведенном выше примере с вводом/выводом большая часть общего времени была потрачена на ожидание медленных операций до завершения. + threading + и + asyncio + ускорили это, позволив вам перекрывать время ожидания вместо того, чтобы выполнять их последовательно.
Однако при проблемах, связанных с процессором, ждать не приходится. Процессор запускается так быстро, как только может, чтобы закончить проблему. В Python потоки и задачи выполняются на одном и том же процессоре в одном и том же процессе. Это означает, что один ЦП выполняет всю работу с непараллельным кодом, а также дополнительную работу по настройке потоков или задач. Это займет более 10 секунд:
$ ./cpu_threading.py
Duration 10.407078266143799 secondsЯ написал + threading + версию этого кода и поместил его с другим примером кода в GitHub хранилище, чтобы вы могли иди проверь это сам. Однако пока не будем на это смотреть.
CPU-Bound + многопроцессорная + версия
Теперь вы, наконец, достигли, где + multiprocessing + действительно сияет. В отличие от других библиотек параллелизма, + multiprocessing + явно предназначен для разделения тяжелых рабочих нагрузок ЦП между несколькими ЦП. Вот как выглядит временная диаграмма его выполнения:
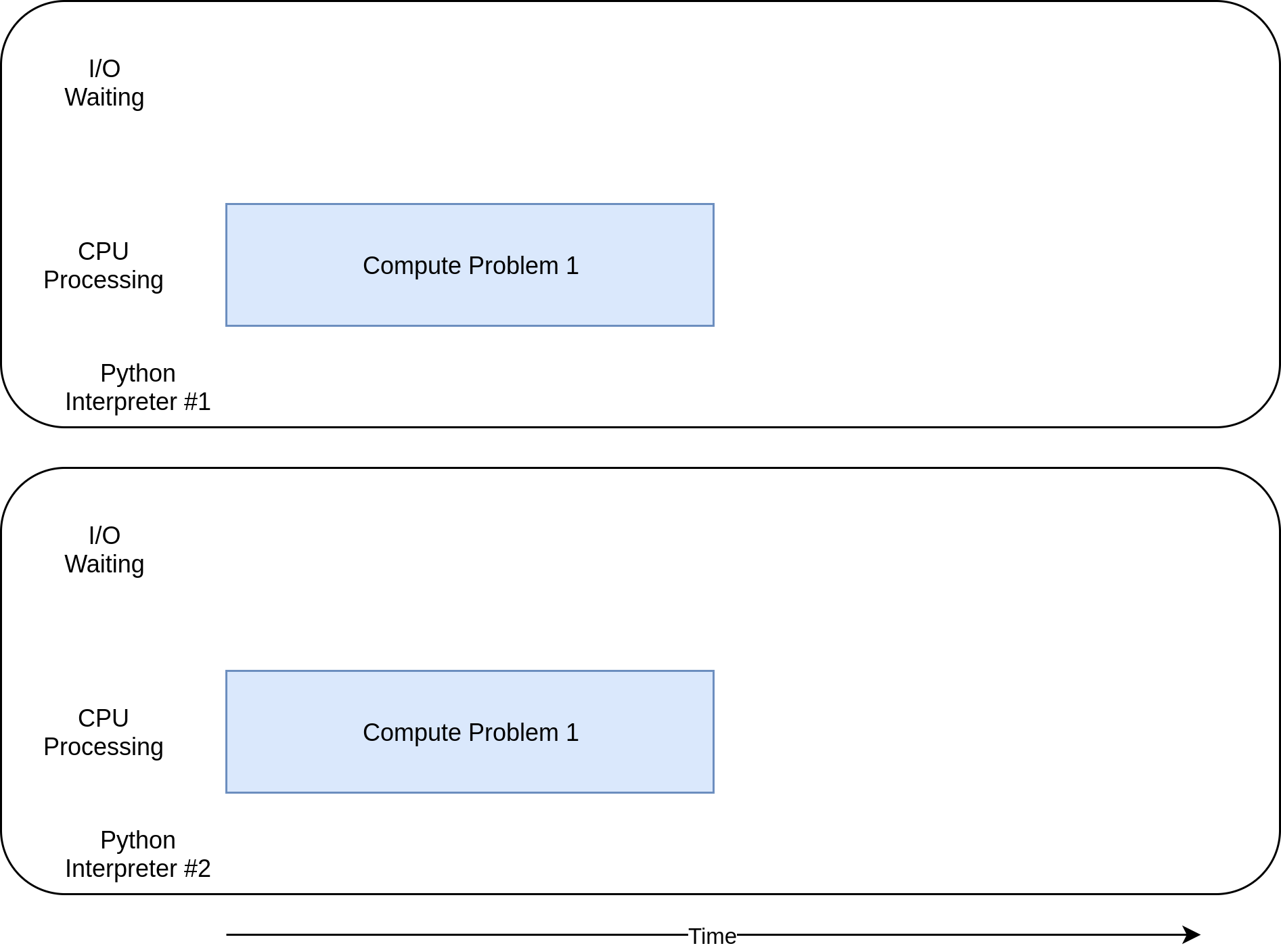
Вот как выглядит код:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Мало что из этого кода пришлось менять по сравнению с не параллельной версией. Вам пришлось + импортировать multiprocessing + и затем просто перейти от циклического перебора чисел к созданию объекта + multiprocessing.Pool + и использованию его метода + .map () + для отправки отдельных чисел рабочим процессам по мере их появления. свободно.
Это было именно то, что вы сделали для кода + multiprocessing +, связанного с вводом/выводом, но здесь вам не нужно беспокоиться об объекте + Session +.
Как упомянуто выше, необязательный параметр + projects + для конструктора + multiprocessing.Pool () + заслуживает некоторого внимания. Вы можете указать, сколько объектов + Process + вы хотите создать и управлять в + Pool +. По умолчанию он определяет количество процессоров на вашем компьютере и создает процесс для каждого из них. Хотя это прекрасно работает для нашего простого примера, вам может потребоваться немного больше контроля в производственной среде.
Кроме того, как мы упоминали в первом разделе о + threading +, код + multiprocessing.Pool + построен на строительных блоках, таких как + Queue + и + Semaphore +, которые будут знакомы тем из вас, кто делал многопоточные и многопроцессорный код на других языках.
*Почему `+ multiprocessing +` Version Rocks*
Версия + multiprocessing + этого примера хороша тем, что ее относительно легко настроить и она требует небольшого дополнительного кода. Это также в полной мере использует мощность процессора в вашем компьютере.
Эй, это именно то, что я сказал в прошлый раз, когда мы смотрели на "+ мультипроцессор +". Большая разница в том, что на этот раз это явно лучший вариант. На моей машине это займет 2,5 секунды:
$ ./cpu_mp.py
Duration 2.5175397396087646 secondsЭто намного лучше, чем мы видели с другими вариантами.
*Проблемы с версией `+ multiprocessing +`*
Есть некоторые недостатки использования + multiprocessing +. На самом деле они не отображаются в этом простом примере, но разделить вашу проблему так, чтобы каждый процессор мог работать независимо, иногда бывает сложно.
Кроме того, многие решения требуют большего взаимодействия между процессами. Это может добавить некоторую сложность вашему решению, с которым не нужно одновременно работать несовместимой программе.
Когда использовать параллелизм
Вы рассмотрели здесь много вопросов, поэтому давайте рассмотрим некоторые ключевые идеи, а затем обсудим некоторые моменты принятия решения, которые помогут вам определить, какой модуль параллелизма, если таковой имеется, вы хотите использовать в своем проекте.
Первым шагом этого процесса является принятие решения о том, следует ли вам использовать модуль параллелизма. Хотя приведенные здесь примеры делают каждую библиотеку довольно простой, параллелизм всегда сопряжен с дополнительной сложностью и часто может привести к ошибкам, которые трудно найти.
Удерживайте добавление параллелизма до тех пор, пока у вас не возникнет известная проблема с производительностью, и затем определите, какой тип параллелизма вам необходим. Как сказал Donald Knuth, «преждевременная оптимизация - корень всего зла (или, по крайней мере, большинства из этого) в программировании».
После того, как вы решили, что вам следует оптимизировать свою программу, выяснить, является ли ваша программа привязанной к процессору или связанной с вводом/выводом, - это отличный следующий шаг. Помните, что программы, связанные с вводом/выводом, - это те, которые проводят большую часть своего времени в ожидании того, что произойдет, в то время как программы, связанные с процессором, тратят свое время на обработку данных или обработку чисел так быстро, как только могут.
Как вы видели, связанные с процессором проблемы действительно выигрывают от использования + multiprocessing +. + threading + и + asyncio + вообще не помогли решить проблему такого типа.
Для проблем, связанных с вводом/выводом, в сообществе Python есть общее правило: «Используйте` + asyncio + , когда можете, + threading + , когда вам нужно». `+ asyncio + может обеспечить наилучшее ускорение для программ такого типа, но иногда вам потребуются критические библиотеки, которые не были портированы, чтобы воспользоваться преимуществами + asyncio +. Помните, что любая задача, которая не уступает управление циклу событий, блокирует все другие задачи.
Заключение
Теперь вы видите основные типы параллелизма, доступные в Python:
-
+ +Резьбонарезной -
+ +Asyncio -
+ +Многопроцессорная
У вас есть понимание, чтобы решить, какой метод параллелизма вам следует использовать для данной проблемы, или вам вообще следует его использовать! Кроме того, вы лучше понимаете некоторые проблемы, которые могут возникнуть при использовании параллелизма.
Я надеюсь, что вы многому научились из этой статьи и нашли большое применение для параллелизма в ваших собственных проектах! Обязательно пройдите тест «Python Concurrency», связанный ниже, чтобы проверить свое обучение:
*__ Пройдите тест:* Проверьте свои знания с помощью нашего интерактивного теста «Python Concurrency». По окончании вы получите оценку, чтобы вы могли отслеживать прогресс в обучении с течением времени:
ссылка:/викторины/Python-параллелизм/[пройти тест »]