Python, Boto3 и AWS S3: демистифицированы
Amazon Web Services (AWS) стал лидером в облачных вычислениях. Одним из его основных компонентов является S3, сервис хранения объектов, предлагаемый AWS. Благодаря впечатляющей доступности и долговечности он стал стандартным способом хранения видео, изображений и данных. Вы можете комбинировать S3 с другими сервисами для создания бесконечно масштабируемых приложений.
Boto3 - это имя Python SDK для AWS. Он позволяет вам напрямую создавать, обновлять и удалять ресурсы AWS из ваших скриптов Python.
Если у вас уже был опыт работы с AWS, у вас есть собственный аккаунт AWS и вы хотите поднять свои навыки на новый уровень, начав использовать сервисы AWS из кода Python, а затем продолжайте читать.
К концу этого руководства вы:
-
Будьте уверены, работая с корзинами и объектами прямо из ваших скриптов Python
-
Знать, как избежать распространенных ошибок при использовании Boto3 и S3
-
Поймите, как настроить ваши данные с самого начала, чтобы избежать проблем с производительностью позже
-
Узнайте, как настроить ваши объекты, чтобы использовать лучшие возможности S3
Прежде чем исследовать характеристики Boto3, вы сначала узнаете, как настроить SDK на вашем компьютере. Этот шаг настроит вас на оставшуюся часть урока.
Free Bonus:5 Thoughts On Python Mastery, бесплатный курс для разработчиков Python, который показывает вам план действий и образ мышления, который вам понадобится, чтобы вывести свои навыки Python на новый уровень.
Монтаж
Чтобы установить Boto3 на свой компьютер, перейдите к терминалу и выполните следующее:
$ pip install boto3У вас есть SDK. Но вы не сможете использовать его прямо сейчас, потому что он не знает, к какой учетной записи AWS он должен подключиться.
Чтобы он работал с вашей учетной записью AWS, вам необходимо предоставить некоторые действительные учетные данные. Если у вас уже есть пользователь IAM, у которого есть полные права доступа к S3, вы можете использовать учетные данные этого пользователя (его ключ доступа и секретный ключ доступа) без необходимости создания нового пользователя. В противном случае самый простой способ сделать это - создать нового пользователя AWS, а затем сохранить новые учетные данные.
Чтобы создать нового пользователя, перейдите в свою учетную запись AWS, затем перейдите вServices и выберитеIAM. Затем выберитеUsers и нажмитеAdd user.
Дайте пользователю имя (например,boto3user). Включитеprogrammatic access. Это гарантирует, что этот пользователь сможет работать с любым SDK, поддерживаемым AWS, или совершать отдельные вызовы API:
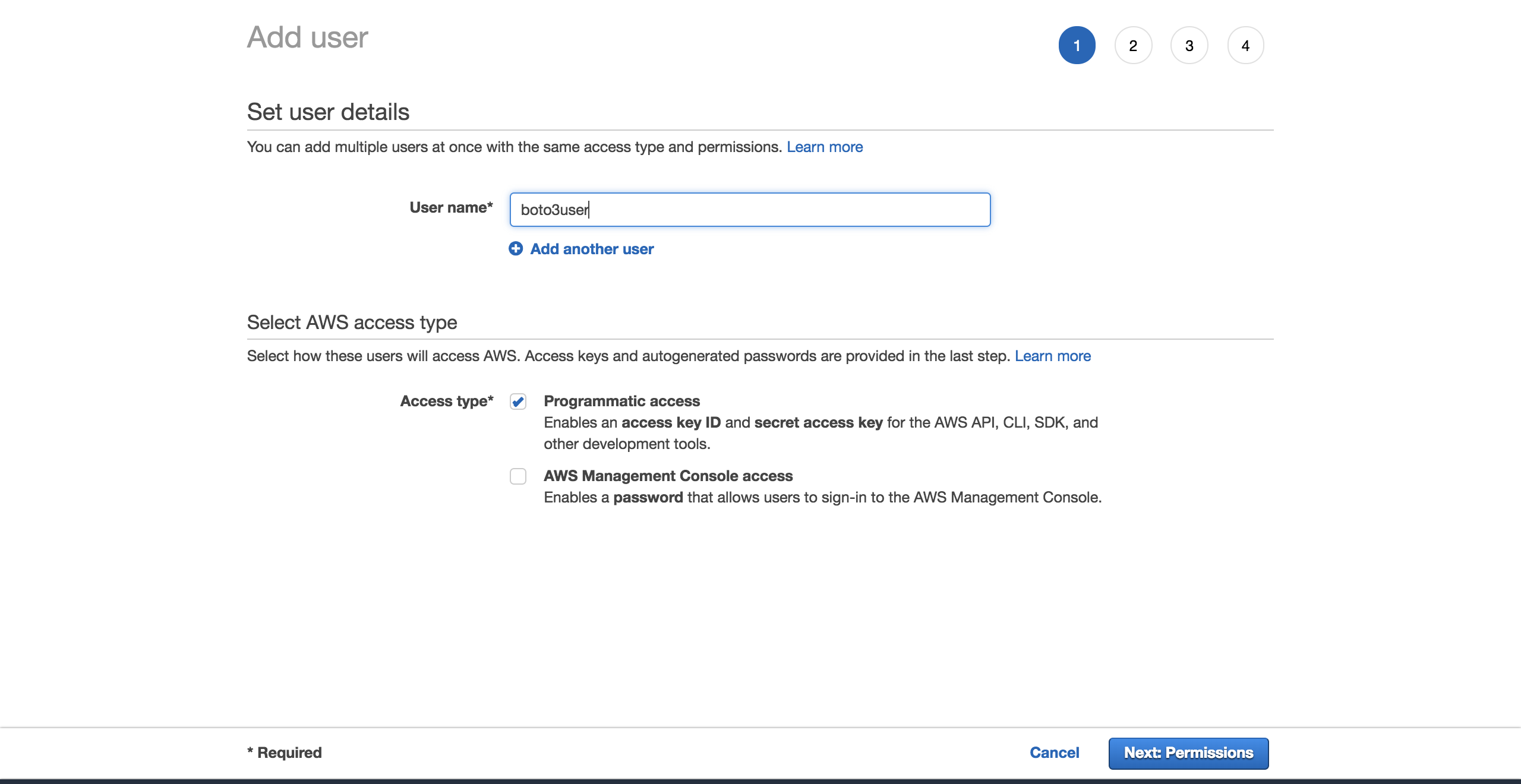
Для простоты выберите предварительно настроенную политикуAmazonS3FullAccess. С этой политикой новый пользователь сможет иметь полный контроль над S3. НажмитеNext: Review:
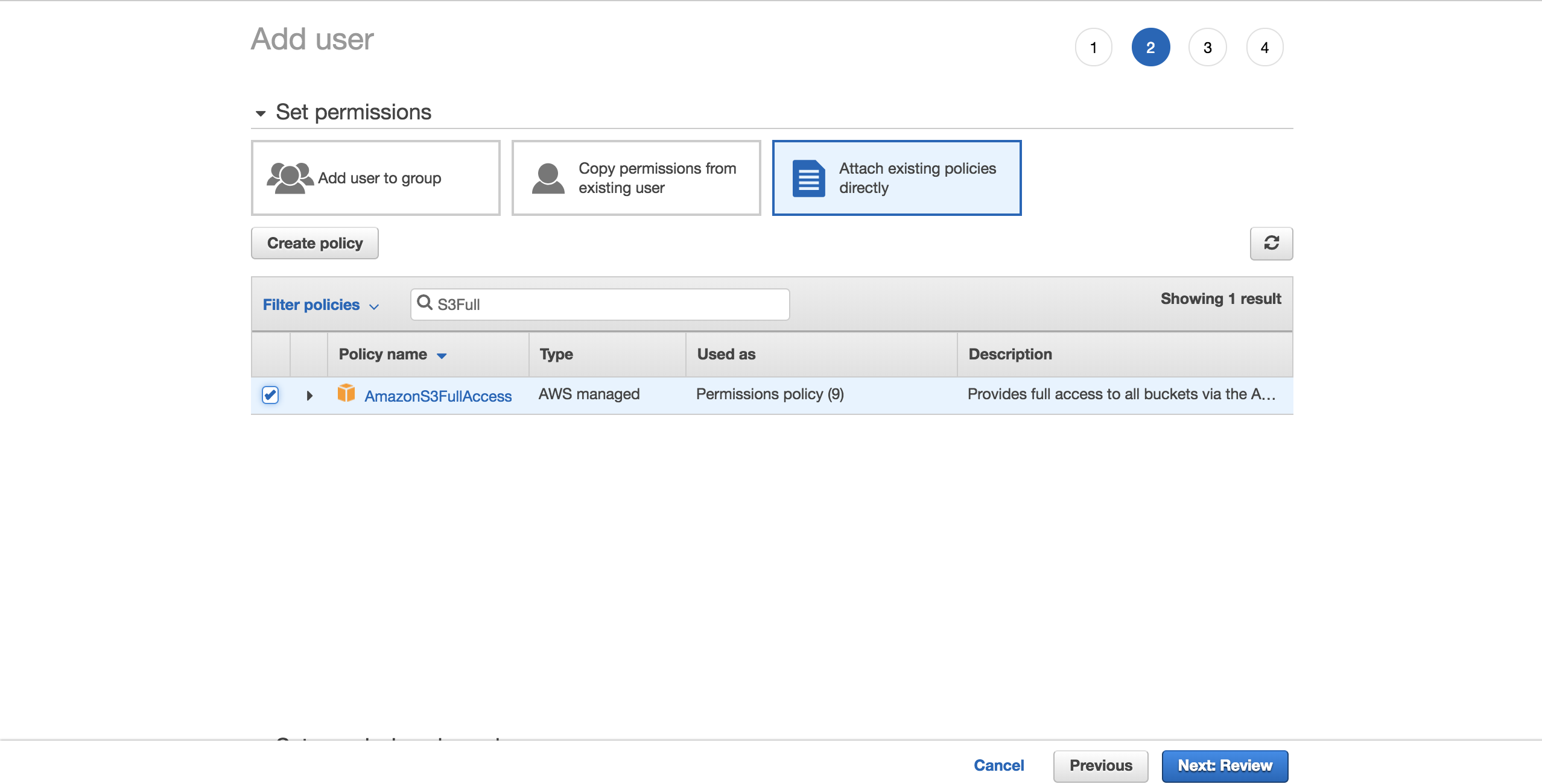
ВыберитеCreate user:
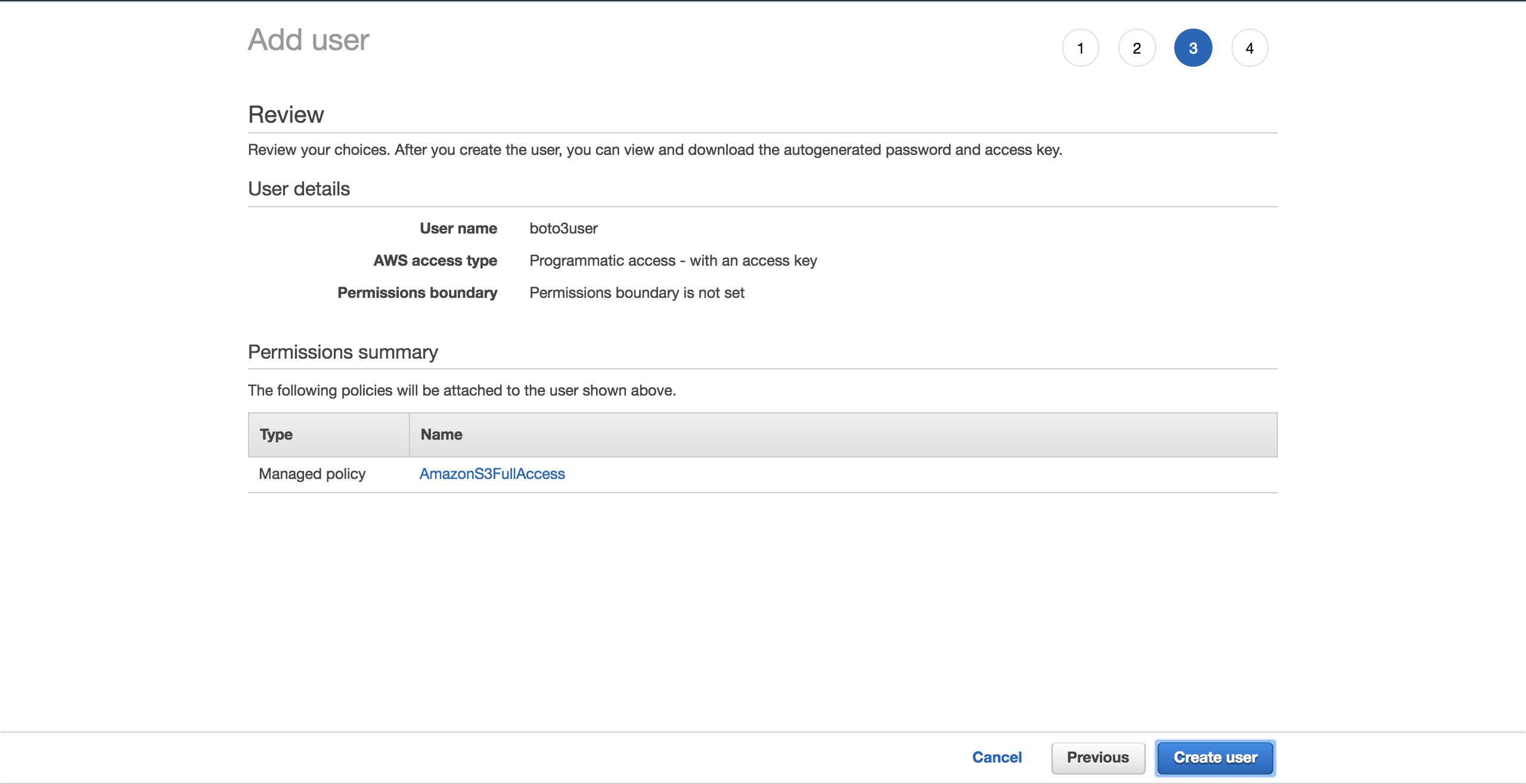
Новый экран покажет вам сгенерированные учетные данные пользователя. Нажмите кнопкуDownload .csv, чтобы сделать копию учетных данных. Они понадобятся вам для завершения настройки.
Теперь, когда у вас есть новый пользователь, создайте новый файл~/.aws/credentials:
$ touch ~/.aws/credentialsОткройте файл и вставьте структуру ниже. Заполните заполнители новыми учетными данными пользователя, которые вы загрузили:
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEYСохраните файл.
Теперь, когда вы настроили эти учетные данные, у вас есть профильdefault, который будет использоваться Boto3 для взаимодействия с вашей учетной записью AWS.
Есть еще одна конфигурация: регион по умолчанию, с которым Boto3 должен взаимодействовать. Вы можете проверитьcomplete table of the supported AWS regions. Выберите регион, который ближе всего к вам. Скопируйте желаемый регион из столбцаRegion. В моем случае я используюeu-west-1 (Ирландия).
Создайте новый файл~/.aws/config:
$ touch ~/.aws/configДобавьте следующее и замените заполнитель скопированнымregion:
[default]
region = YOUR_PREFERRED_REGIONСохраните свой файл.
Теперь вы официально настроены на оставшуюся часть урока.
Далее вы увидите различные опции, которые Boto3 предоставляет вам для подключения к S3 и другим сервисам AWS.
Клиент против ресурсов
По сути, все, что делает Boto3, это вызывает API AWS от вашего имени. Для большинства сервисов AWS Boto3 предлагает два разных способа доступа к этим абстрактным API:
-
Client: доступ к сервису низкого уровня
-
Resource: доступ к объектно-ориентированным службам более высокого уровня
Вы можете использовать любой из них для взаимодействия с S3.
Чтобы подключиться к низкоуровневому клиентскому интерфейсу, вы должны использоватьclient() Boto3. Затем вы передаете имя службы, к которой хотите подключиться, в данном случаеs3:
import boto3
s3_client = boto3.client('s3')Чтобы подключиться к высокоуровневому интерфейсу, вы будете следовать аналогичному подходу, но использоватьresource():
import boto3
s3_resource = boto3.resource('s3')Вы успешно подключились к обеим версиям, но теперь у вас может возникнуть вопрос: «Какую из них использовать?»
С клиентами требуется больше программной работы. Большинство клиентских операций дают ответdictionary. Чтобы получить точную информацию, которая вам нужна, вам придется проанализировать этот словарь самостоятельно. С помощью методов ресурсов SDK делает это для вас.
С клиентом вы можете увидеть небольшие улучшения производительности. Недостатком является то, что ваш код становится менее читабельным, чем если бы вы использовали ресурс. Ресурсы предлагают лучшую абстракцию, и ваш код будет легче понять.
Понимание того, как создается клиент и ресурс, также важно, когда вы выбираете, какой из них выбрать:
-
Boto3 генерирует клиента из файла определения сервиса JSON. Методы клиента поддерживают каждый тип взаимодействия с целевым сервисом AWS.
-
Ресурсы, с другой стороны, генерируются из файлов определения ресурсов JSON.
Boto3 генерирует клиента и ресурс из разных определений. В результате вы можете обнаружить случаи, когда ресурс, поддерживаемый клиентом, не предлагается ресурсом. Вот интересная часть: вам не нужно менять свой код, чтобы использовать клиент везде. Для этой операции вы можете получить доступ к клиенту напрямую через ресурс, например:s3_resource.meta.client.
Одной из таких операцийclient является.generate_presigned_url(), которая позволяет вам предоставлять пользователям доступ к объекту в вашей корзине на определенный период времени, не требуя от них наличия учетных данных AWS.
Общие операции
Теперь, когда вы знаете о различиях между клиентами и ресурсами, давайте начнем использовать их для создания некоторых новых компонентов S3.
Создание ведра
Для начала вам понадобится S3bucket. Чтобы создать один программно, вы должны сначала выбрать имя для вашего ведра. Помните, что это имя должно быть уникальным для всей платформы AWS, так как имена сегментов соответствуют DNS. Если вы попытаетесь создать сегмент, но другой пользователь уже указал желаемое имя блока, ваш код не будет выполнен. Вместо успеха вы увидите следующую ошибку:botocore.errorfactory.BucketAlreadyExists.
Вы можете увеличить свои шансы на успех при создании своего ведра, выбрав случайное имя. Вы можете создать свою собственную функцию, которая сделает это за вас. В этой реализации вы увидите, как использование модуляuuid поможет вам в этом. Строковое представление UUID4 имеет длину 36 символов (включая дефисы), и вы можете добавить префикс, чтобы указать, для чего предназначен каждый сегмент.
Вот способ, которым вы можете достичь этого:
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])У вас есть имя группы, но теперь есть еще одна вещь, о которой вам нужно знать: если ваш регион не находится в Соединенных Штатах, вам нужно будет явно указать регион при создании группы. В противном случае вы получитеIllegalLocationConstraintException.
Чтобы проиллюстрировать, что это означает, когда вы создаете свою корзину S3 в неамериканском регионе, взгляните на код ниже:
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})Вам необходимо указать как имя корзины, так и конфигурацию корзины, в которой вы должны указать регион, которым в моем случае являетсяeu-west-1.
Это не идеально. Представьте, что вы хотите взять свой код и развернуть его в облаке. Ваша задача будет становиться все труднее, потому что вы жестко закодировали регион. Вы можете реорганизовать регион и преобразовать его в переменную окружения, но тогда вам придется управлять еще одной вещью.
К счастью, есть лучший способ получить область программно, используя объектsession. Boto3 создастsession из ваших учетных данных. Вам просто нужно взять регион и передать егоcreate_bucket() в качестве конфигурацииLocationConstraint. Вот как это сделать:
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_responseПриятно то, что этот код работает независимо от того, где вы хотите его развернуть: локально / EC2 / Lambda. Более того, вам не нужно жестко кодировать свой регион.
Поскольку и клиент, и ресурс создают сегменты одинаково, вы можете передать любую из них в качестве параметраs3_connection.
Теперь вы создадите два ведра. Сначала создайте его с помощью клиента, который вернет вамbucket_response в качестве словаря:
>>>
>>> first_bucket_name, first_response = create_bucket(
... bucket_prefix='firstpythonbucket',
... s3_connection=s3_resource.meta.client)
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1
>>> first_response
{'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}Затем создайте вторую корзину, используя ресурс, который вернет вам экземплярBucket какbucket_response:
>>>
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')Вы получили свои ведра. Далее вы захотите начать добавлять к ним несколько файлов.
Называя ваши файлы
Вы можете называть свои объекты, используя стандартные соглашения об именах файлов. Вы можете использовать любое действительное имя. В этой статье вы познакомитесь с более конкретным случаем, который поможет вам понять, как работает S3.
Если вы планируете разместить большое количество файлов в своей корзине S3, есть кое-что, что вы должны иметь в виду. Если все имена ваших файлов имеют детерминированный префикс, который повторяется для каждого файла, например формат метки времени, например «ГГГГ-ММ-ДДTчч: мм: сс», то вскоре вы обнаружите, что сталкиваетесь сperformance issues когда вы пытаетесь взаимодействовать со своим ведром.
Это произойдет, потому что S3 берет префикс файла и сопоставляет его с разделом. Чем больше файлов вы добавите, тем больше будет назначено одному разделу, и этот раздел будет очень тяжелым и менее отзывчивым.
Что вы можете сделать, чтобы этого не случилось?
Самое простое решение - рандомизировать имя файла. Вы можете представить себе множество различных реализаций, но в этом случае вы воспользуетесь доверенным модулемuuid, чтобы помочь с этим. Чтобы упростить чтение имен файлов в этом руководстве, вы возьмете первые шесть символов представления сгенерированного числаhex и объедините их с вашим базовым именем файла.
Приведенная ниже вспомогательная функция позволяет вам передавать количество байтов, которое вы хотите иметь в файле, имя файла и пример содержимого для повторяемого файла, чтобы получить желаемый размер файла:
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_nameСоздайте свой первый файл, который вы скоро будете использовать:
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')Добавляя случайность к именам файлов, вы можете эффективно распределять свои данные в своем сегменте S3.
Создание экземпляровBucket иObject
Следующий шаг после создания вашего файла - посмотреть, как его интегрировать в рабочий процесс S3.
Именно здесь классы ресурса играют важную роль, поскольку эти абстракции облегчают работу с S3.
Используя ресурс, вы получаете доступ к классам высокого уровня (Bucket иObject). Вот как вы можете создать один из них:
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)Причина, по которой вы не заметили ошибок при создании переменнойfirst_object, заключается в том, что Boto3 не обращается к AWS для создания ссылки. bucket_name иkey называются идентификаторами, и они являются необходимыми параметрами для созданияObject. Любой другой атрибутObject, например его размер, загружается лениво. Это означает, что для того, чтобы Boto3 получил запрошенные атрибуты, он должен сделать вызовы в AWS.
Понимание подресурсов
Bucket иObject являются подресурсами друг друга. Подресурсы - это методы, которые создают новый экземпляр дочернего ресурса. Идентификаторы родителя передаются дочернему ресурсу.
Если у вас есть переменнаяBucket, вы можете создатьObject напрямую:
first_object_again = first_bucket.Object(first_file_name)Или, если у вас есть переменнаяObject, вы можете получитьBucket:
first_bucket_again = first_object.Bucket()Отлично, теперь вы понимаете, как генерироватьBucket иObject. Затем вы получите возможность загрузить свой новый файл в S3, используя эти конструкции.
Загрузка файла
Вы можете загрузить файл тремя способами:
-
Из экземпляра
Object -
Из экземпляра
Bucket -
Из
client
В каждом случае вы должны указатьFilename, то есть путь к файлу, который вы хотите загрузить. Теперь вы исследуете три альтернативы. Не стесняйтесь выбирать то, что вам больше всего нравится, чтобы загрузитьfirst_file_name в S3.
Версия экземпляра объекта
Вы можете загрузить, используя экземплярObject:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)Или вы можете использовать экземплярfirst_object:
first_object.upload_file(first_file_name)Версия экземпляра сегмента
Вот как можно загрузить с помощью экземпляраBucket:
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)Версия клиента
Вы также можете загрузить с помощьюclient:
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)Вы успешно загрузили свой файл на S3 одним из трех доступных способов. В следующих разделах вы в основном будете работать с классомObject, поскольку операции в версияхclient иBucket очень похожи.
Скачивание файла
Чтобы загрузить файл с S3 локально, вы будете следовать тем же шагам, что и при загрузке. Но в этом случае параметрFilename будет отображаться на желаемый локальный путь. На этот раз он загрузит файл в каталогtmp:
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+Вы успешно загрузили свой файл с S3. Далее вы увидите, как скопировать один и тот же файл между корзинами S3, используя один вызов API.
Копирование объекта между корзинами
Если вам нужно скопировать файлы из одной корзины в другую, Boto3 предлагает вам такую возможность. В этом примере вы скопируете файл из первой корзины во вторую, используя.copy():
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)Note: Если вы хотите реплицировать свои объекты S3 в сегмент в другом регионе, обратите внимание наCross Region Replication.
Удаление объекта
Давайте удалим новый файл из второй корзины, вызвав.delete() в эквивалентном экземпляреObject:
s3_resource.Object(second_bucket_name, first_file_name).delete()Теперь вы видели, как использовать основные операции S3. Вы готовы поднять свои знания на следующий уровень с более сложными характеристиками в следующих разделах.
Расширенные настройки
В этом разделе вы познакомитесь с более сложными функциями S3. Вы увидите примеры их использования и преимущества, которые они могут принести вашим приложениям.
ACL (списки контроля доступа)
Списки контроля доступа (ACL) помогают вам управлять доступом к вашим корзинам и объектам внутри них. Они считаются устаревшим способом администрирования разрешений для S3. Почему вы должны знать о них? Если вам нужно управлять доступом к отдельным объектам, вы должны использовать объект ACL.
По умолчанию, когда вы загружаете объект в S3, этот объект является частным. Если вы хотите сделать этот объект доступным для кого-то другого, вы можете установить ACL объекта как общедоступный во время создания. Вот как вы загружаете новый файл в корзину и делаете его доступным для всех:
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})Вы можете получить экземплярObjectAcl изObject, так как это один из его подклассов ресурсов:
second_object_acl = second_object.Acl()Чтобы узнать, у кого есть доступ к вашему объекту, используйте атрибутgrants:
>>>
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]Вы можете снова сделать свой объект приватным, не загружая его повторно:
>>>
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]Вы видели, как вы можете использовать ACL для управления доступом к отдельным объектам. Далее вы увидите, как вы можете добавить дополнительный уровень безопасности для ваших объектов с помощью шифрования.
Note: Если вы хотите разделить данные на несколько категорий, обратите внимание наtags. Вы можете предоставить доступ к объектам на основе их тегов.
шифрование
С S3 вы можете защитить свои данные с помощью шифрования. Вы изучите шифрование на стороне сервера с использованием алгоритма AES-256, где AWS управляет как шифрованием, так и ключами.
Создайте новый файл и загрузите его, используяServerSideEncryption:
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})Вы можете проверить алгоритм, который использовался для шифрования файла, в данном случаеAES256:
>>>
>>> third_object.server_side_encryption
'AES256'Теперь вы понимаете, как добавить дополнительный уровень защиты к вашим объектам, используя алгоритм шифрования на стороне сервера AES-256, предлагаемый AWS.
Место хранения
Каждый объект, который вы добавляете в корзину S3, связан сstorage class. Все доступные классы хранения предлагают высокую долговечность. Вы выбираете способ хранения своих объектов в зависимости от требований к производительности вашего приложения.
В настоящее время вы можете использовать следующие классы хранения с S3:
-
STANDARD: по умолчанию для часто используемых данных
-
STANDARD_IA: для редко используемых данных, которые необходимо быстро получить по запросу
-
ONEZONE_IA: для того же варианта использования, что и STANDARD_IA, но хранит данные в одной зоне доступности вместо трех.
-
REDUCED_REDUNDANCY: для часто используемых некритичных данных, которые легко воспроизводятся
Если вы хотите изменить класс хранения существующего объекта, вам необходимо воссоздать объект.
Например, повторно загрузитеthird_object и установите его класс хранения наStandard_IA:
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256',
'StorageClass': 'STANDARD_IA'})Note: Если вы внесете изменения в свой объект, вы можете обнаружить, что ваш локальный экземпляр их не отображает. Что вам нужно сделать в этот момент, так это вызвать.reload(), чтобы получить самую новую версию вашего объекта.
Перезагрузите объект, и вы увидите его новый класс хранения:
>>>
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'Note: ИспользуйтеLifeCycle Configurations для перехода объектов между разными классами по мере необходимости. Они автоматически переведут эти объекты для вас.
Versioning
Вы должны использовать управление версиями, чтобы вести полный учет ваших объектов с течением времени. Он также действует как защитный механизм от случайного удаления ваших объектов. Когда вы запрашиваете версионный объект, Boto3 получит последнюю версию.
Когда вы добавляете новую версию объекта, хранилище, которое занимает этот объект, является суммой размера его версий. Поэтому, если вы храните объект объемом 1 ГБ и создаете 10 версий, вам придется заплатить за 10 ГБ хранилища.
Включить управление версиями для первого сегмента. Для этого вам нужно использовать классBucketVersioning:
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)>>>
>>> enable_bucket_versioning(first_bucket_name)
EnabledЗатем создайте две новые версии для первого файлаObject, одну с содержимым исходного файла и одну с содержимым третьего файла:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
first_file_name)
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
third_file_name)Теперь перезагрузите второй файл, который создаст новую версию:
s3_resource.Object(first_bucket_name, second_file_name).upload_file(
second_file_name)Вы можете получить последнюю доступную версию ваших объектов следующим образом:
>>>
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'В этом разделе вы узнали, как работать с некоторыми из наиболее важных атрибутов S3 и добавлять их в свои объекты. Далее вы увидите, как легко перемещаться по вашим корзинам и объектам.
обходов
Если вам нужно извлечь информацию или применить операцию ко всем вашим ресурсам S3, Boto3 предоставляет вам несколько способов итеративного обхода ваших корзин и ваших объектов. Вы начнете с обхода всех созданных вами групп.
Обход ковша
Чтобы просмотреть все сегменты в вашей учетной записи, вы можете использовать атрибут ресурсаbuckets вместе с.all(), который дает вам полный список экземпляровBucket:
>>>
>>> for bucket in s3_resource.buckets.all():
... print(bucket.name)
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Вы также можете использоватьclient для получения информации о сегменте, но код более сложный, так как вам нужно извлечь его из словаря, который возвращаетclient:
>>>
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Вы видели, как перебирать корзины, которые есть в вашем аккаунте. В следующем разделе вы выберете один из блоков и итеративно просмотрите объекты, которые в нем содержатся.
Обход объекта
Если вы хотите перечислить все объекты из корзины, следующий код сгенерирует для вас итератор:
>>>
>>> for obj in first_bucket.objects.all():
... print(obj.key)
...
127367firstfile.txt
616abesecondfile.txt
fb937cthirdfile.txtПеременнаяobj - этоObjectSummary. Это упрощенное представлениеObject. Сводная версия не поддерживает все атрибуты, которые имеетObject. Если вам нужно получить к ним доступ, используйте подресурсObject(), чтобы создать новую ссылку на базовый сохраненный ключ. Тогда вы сможете извлечь недостающие атрибуты:
>>>
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}Теперь вы можете итеративно выполнять операции с вашими контейнерами и объектами. Вы почти закончили. На этом этапе вы должны знать еще одну вещь: как удалить все ресурсы, которые вы создали в этом руководстве.
Удаление ведер и объектов
Чтобы удалить все группы и объекты, которые вы создали, вы должны сначала убедиться, что в ваших группах нет объектов.
Удаление непустого ведра
Чтобы иметь возможность удалить сегмент, вы должны сначала удалить каждый отдельный объект в контейнере, иначе возникнет исключениеBucketNotEmpty. Если у вас есть версионное хранилище, вам нужно удалить каждый объект и все его версии.
Если вы обнаружите, что правило LifeCycle, которое будет делать это автоматически для вас, не соответствует вашим потребностям, вот как вы можете программно удалять объекты:
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})Приведенный выше код работает независимо от того, включили ли вы управление версиями в вашем ведре. Если вы этого не сделаете, версия объектов будет нулевой. Вы можете выполнить пакетное удаление до 1000 удалений за один вызов API, используя.delete_objects() в экземпляреBucket, что более рентабельно, чем удаление каждого объекта по отдельности.
Запустите новую функцию для первого сегмента, чтобы удалить все версионные объекты:
>>>
>>> delete_all_objects(first_bucket_name)
[{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]В качестве финального теста вы можете загрузить файл во второе ведро. В этом сегменте не включена поддержка версий, поэтому версия будет нулевой. Примените ту же функцию, чтобы удалить содержимое:
>>>
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]Вы успешно удалили все объекты из обеих корзин. Теперь вы готовы удалить ведра.
Удаление ковшей
В завершение вы будете использовать.delete() в экземпляреBucket, чтобы удалить первую корзину:
s3_resource.Bucket(first_bucket_name).delete()Если хотите, вы можете использовать версиюclient для удаления второй корзины:
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)Обе операции были успешными, потому что вы опустошили каждое ведро, прежде чем пытаться удалить его.
Теперь вы выполнили некоторые из наиболее важных операций, которые вы можете выполнять с S3 и Boto3. Поздравляю с этим! В качестве бонуса давайте рассмотрим некоторые преимущества управления ресурсами S3 с помощью инфраструктуры в виде кода.
Код Python или инфраструктура как код (IaC)?
Как вы уже видели, большинство взаимодействий с S3, которые вы имели в этом руководстве, были связаны с объектами. Вы не видели много операций, связанных с корзиной, таких как добавление политик в корзину, добавление правила LifeCycle для перемещения ваших объектов через классы хранения, архивирования их в Glacier или их полного удаления или принудительного шифрования всех объектов путем настройки Bucket Шифрование.
Вручную управлять состоянием ваших сегментов с помощью клиентов или ресурсов Boto3 становится все труднее, поскольку ваше приложение начинает добавлять другие сервисы и становится все более сложным. Чтобы контролировать свою инфраструктуру совместно с Boto3, рассмотрите возможность использования инструмента «Инфраструктура как код» (IaC), такого как CloudFormation или Terraform, для управления инфраструктурой вашего приложения. Любой из этих инструментов будет поддерживать состояние вашей инфраструктуры и сообщать вам об изменениях, которые вы применили.
Если вы решили пойти по этому пути, имейте в виду следующее:
-
Любая связанная с корзиной операция, которая каким-либо образом модифицирует эту группу, должна выполняться через IaC.
-
Если вы хотите, чтобы все ваши объекты работали одинаково (например, все зашифрованные или все общедоступные), обычно есть способ сделать это напрямую с помощью IaC, добавив политику Bucket или определенное свойство Bucket.
-
Операции чтения группы, такие как итерация содержимого корзины, должны выполняться с использованием Boto3.
-
Операции с объектами на уровне отдельных объектов должны выполняться с использованием Boto3.
Заключение
Поздравляем с окончанием этого урока!
Теперь вы готовы программно работать с S3. Теперь вы знаете, как создавать объекты, загружать их в S3, загружать их содержимое и изменять их атрибуты непосредственно из вашего скрипта, избегая при этом общих ошибок с Boto3.
Пусть этот учебник станет ступенькой на пути к созданию чего-то великого с помощью AWS!
Дальнейшее чтение
Если вы хотите узнать больше, проверьте следующее: