Первые шаги с PySpark и обработка больших данных
Все чаще встречаются ситуации, когда объем данных слишком велик для обработки на одной машине. К счастью, такие технологии, как Apache Spark, Hadoop и другие, были разработаны для решения именно этой проблемы. Сила этих систем может быть использована непосредственно из Python с помощью PySpark!
Эффективная обработка наборов данных размером в гигабайты и более составляетwell within the reach of any Python developer, независимо от того, являетесь ли вы специалистом по обработке данных, веб-разработчиком или кем-то еще.
В этом руководстве вы узнаете:
-
Какие концепции Python могут быть применены к большим данным
-
Как использовать Apache Spark и PySpark
-
Как писать базовые программы PySpark
-
Как запускать программы PySpark для небольших наборов данных локально
-
Куда пойти дальше, чтобы перенести свои навыки PySpark в распределенную систему
Free Bonus:Click here to get access to a chapter from Python Tricks: The Book, который демонстрирует вам лучшие практики Python на простых примерах, которые вы можете мгновенно применить для написания более красивого кода Pythonic.
Концепции больших данных в Python
Несмотря на свою популярность какjust ascripting language, Python предоставляет несколькоprogramming paradigms, напримерarray-oriented programming,object-oriented programming,asynchronous programming и многие другие. Одна из парадигм, которая представляет особый интерес для начинающих профессионалов в области больших данных, - этоfunctional programming.
Функциональное программирование является распространенной парадигмой, когда вы имеете дело с большими данными. Функциональная запись составляет кодembarrassingly parallel. Это означает, что легче взять ваш код и запустить его на нескольких процессорах или даже на совершенно разных компьютерах. Вы можете обойти ограничения физической памяти и ЦП одной рабочей станции, запустив несколько систем одновременно.
Это сила экосистемы PySpark, позволяющая вам брать функциональный код и автоматически распределять его по всему кластеру компьютеров.
К счастью для программистов Python, многие из основных идей функционального программирования доступны в стандартной библиотеке и встроенных программах Python. Вы можете изучить многие концепции, необходимые для обработки больших данных, не выходя из комфорта Python.
Основная идея функционального программирования заключается в том, что данными должны манипулировать функции без сохранения какого-либо внешнего состояния. Это означает, что ваш код избегает глобальных переменных и всегда возвращаетnew data вместо того, чтобы манипулировать данными на месте.
Еще одна распространенная идея в функциональном программировании -anonymous functions. Python предоставляет анонимные функции с использованием ключевого словаlambda, не путать сAWS Lambda functions.
Теперь, когда вы знаете некоторые термины и понятия, вы можете исследовать, как эти идеи проявляются в экосистеме Python.
Лямбда-функции
lambda functions в Python определены встроенными и ограничены одним выражением. Вероятно, вы видели функцииlambda при использовании встроенной функцииsorted():
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(sorted(x))
['Python', 'awesome!', 'is', 'programming']
>>> print(sorted(x, key=lambda arg: arg.lower()))
['awesome!', 'is', 'programming', 'Python']Параметрkey дляsorted вызывается для каждого элемента вiterable. Это делает сортировку нечувствительной к регистру, изменяя все строки на строчныеbefore, в которых выполняется сортировка.
Это общий вариант использования функцийlambda, небольших анонимных функций, не поддерживающих внешнее состояние.
В Python также существуют другие распространенные функции функционального программирования, такие какfilter(),map() иreduce(). Все эти функции могут использовать функцииlambda или стандартные функции, определенные с помощьюdef аналогичным образом.
filter(),map() иreduce()
Встроенные функцииfilter(),map() иreduce() являются общими для функционального программирования. Вскоре вы увидите, что эти концепции могут составлять значительную часть функциональности программы PySpark.
Важно понимать эти функции в основном контексте Python. Затем вы сможете преобразовать эти знания в программы PySpark и API Spark.
filter() фильтрует элементы из итерации на основе условия, обычно выражаемого функциейlambda:
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(filter(lambda arg: len(arg) < 8, x)))
['Python', 'is']filter() принимает итерацию, вызывает функциюlambda для каждого элемента и возвращает элементы, для которыхlambda вернулTrue.
Note: Вызовlist() необходим, потому чтоfilter() также является итеративным. filter() дает вам значения, только когда вы их перебираете. list() помещает все элементы в память одновременно, вместо того, чтобы использовать цикл.
Вы можете представить себе использованиеfilter() для замены стандартного шаблона циклаfor следующим образом:
def is_less_than_8_characters(item):
return len(item) < 8
x = ['Python', 'programming', 'is', 'awesome!']
results = []
for item in x:
if is_less_than_8_characters(item):
results.append(item)
print(results)Этот код собирает все строки длиной менее 8 символов. Код более подробный, чем примерfilter(), но он выполняет ту же функцию с теми же результатами.
Еще одно менее очевидное преимуществоfilter() заключается в том, что он возвращает итерацию. Это означает, чтоfilter() не требует, чтобы на вашем компьютере было достаточно памяти для одновременного хранения всех элементов в итерации. Это становится все более важным для больших наборов данных, размер которых может быстро увеличиться до нескольких гигабайт.
map() похож наfilter() в том, что он применяет функцию к каждому элементу в итерации, но всегда производит сопоставление исходных элементов 1 к 1. Итерацияnew, которую возвращаетmap(), всегда будет иметь то же количество элементов, что и исходная итерация, чего не было сfilter():
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(map(lambda arg: arg.upper(), x)))
['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']map() автоматически вызывает функциюlambda для всех элементов, эффективно заменяя циклfor следующим образом:
results = []
x = ['Python', 'programming', 'is', 'awesome!']
for item in x:
results.append(item.upper())
print(results)Циклfor имеет тот же результат, что и примерmap(), который собирает все элементы в их верхнем регистре. Однако, как и в примереfilter(),map() возвращает итерацию, что снова позволяет обрабатывать большие наборы данных, которые слишком велики, чтобы полностью уместиться в памяти.
Наконец, последний из функционального трио в стандартной библиотеке Python -reduce(). Как и в случае сfilter() иmap(), `reduce ()` применяет функцию к элементам в итерации.
Опять же, применяемая функция может быть стандартной функцией Python, созданной с помощью ключевого словаdef или функциейlambda.
Однакоreduce() не возвращает новую итерацию. Вместо этогоreduce() использует функцию, вызываемую, чтобы уменьшить итерацию до одного значения:
>>>
>>> from functools import reduce
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(reduce(lambda val1, val2: val1 + val2, x))
Pythonprogrammingisawesome!Этот код объединяет все элементы итерируемого слева направо в один элемент. Здесь нет вызоваlist(), потому чтоreduce() уже возвращает один элемент.
Note: Python 3.x переместил встроенную функциюreduce() в пакетfunctools.
lambda,map(),filter() иreduce() - это концепции, которые существуют во многих языках и могут использоваться в обычных программах Python. Вскоре вы увидите, что эти концепции распространяются на PySpark API для обработки больших объемов данных.
Sets
Sets - еще одна распространенная функция, которая существует в стандартном Python и широко используется при обработке больших данных. Наборы очень похожи на списки, за исключением того, что они не имеют никакого порядка и не могут содержать повторяющиеся значения. Вы можете думать о наборе как о ключах в Python dict.
Hello World в PySpark
Как и в любом хорошем руководстве по программированию, вам нужно начать с примераHello World. Ниже приведен эквивалент PySpark:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Пока не беспокойтесь обо всех деталях. Основная идея заключается в том, чтобы иметь в виду, что программа PySpark не сильно отличается от обычной программы Python.
Note: Эта программа, скорее всего, вызоветException в вашей системе, если у вас еще не установлен PySpark или нет указанного файлаcopyright, что вы увидите, как это сделать. позже.
Вы скоро узнаете все детали этой программы, но внимательно посмотрите. Программа подсчитывает общее количество строк и количество строк, содержащих словоpython в файле с именемcopyright.
Помните,a PySpark program isn’t that much different from a regular Python program, ноexecution model can be very different из обычной программы Python, особенно если вы работаете в кластере.
За кулисами может происходить много вещей, которые распределяют обработку по нескольким узлам, если вы находитесь в кластере. Однако пока что представьте программу как программу Python, использующую библиотеку PySpark.
Теперь, когда вы увидели некоторые общие функциональные концепции, существующие в Python, а также простую программу PySpark, пришло время углубиться в Spark и PySpark.
Что такое искра?
Apache Spark состоит из нескольких компонентов, поэтому его описание может быть затруднительным. По своей сути Spark - это общийengine для обработки больших объемов данных.
Spark записывается вScala и работает наJVM. Spark имеет встроенные компоненты для обработки потоковых данных, машинного обучения, обработки графиков и даже взаимодействия с данными через SQL.
В этом руководстве вы узнаете только об основных компонентах Spark для обработки больших данных. Однако все остальные компоненты, такие как машинное обучение, SQL и т. Д., Также доступны для проектов Python через PySpark.
Что такое PySpark?
Spark реализован в Scala, языке, который работает на JVM, так как вы можете получить доступ ко всем этим функциям через Python?
PySpark является ответом.
Текущая версия PySpark - 2.4.3 и работает с Python 2.7, 3.3 и выше.
Вы можете думать о PySpark как обертке на основе Python поверх Scala API. Это означает, что у вас есть два набора документации для ссылки:
Документы PySpark API имеют примеры, но часто вам нужно обратиться к документации по Scala и перевести код в синтаксис Python для своих программ PySpark. К счастью, Scala - очень читаемый язык программирования на основе функций.
PySpark взаимодействует с API на основе Spark Scala черезPy4J library. Py4J не является специфичным для PySpark или Spark. Py4J позволяет любой программе на Python общаться с кодом на основе JVM.
Существует две причины, по которым PySpark основан на функциональной парадигме:
-
Scala, родной язык Spark, основан на функциональности.
-
Функциональный код гораздо проще распараллелить.
Еще один способ представить PySpark - это библиотека, которая позволяет обрабатывать большие объемы данных на одном компьютере или кластере компьютеров.
В контексте Python подумайте о том, что PySpark может обрабатывать параллельную обработку без необходимости в модуляхthreading илиmultiprocessing. Все сложные коммуникации и синхронизация между потоками, процессами и даже разными процессорами выполняются Spark.
PySpark API и структуры данных
Для взаимодействия с PySpark вы создаете специализированные структуры данных, называемыеResilient Distributed Datasets (RDD).
RDD скрывают всю сложность преобразования и автоматического распределения ваших данных по нескольким узлам с помощью планировщика, если вы работаете в кластере.
Чтобы лучше понять API PySpark и структуры данных, вспомните упомянутую ранее программуHello World:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Точкой входа любой программы PySpark является объектSparkContext. Этот объект позволяет вам подключаться к кластеру Spark и создавать RDD. Строкаlocal[*] - это специальная строка, обозначающая, что вы используете кластерlocal, что является еще одним способом сказать, что вы работаете в одномашинном режиме. * указывает Spark создать столько рабочих потоков, сколько логических ядер на вашем компьютере.
СозданиеSparkContext может быть более сложным, если вы используете кластер. Чтобы подключиться к кластеру Spark, вам может потребоваться обработать аутентификацию и некоторые другие сведения, относящиеся к вашему кластеру. Вы можете настроить эти детали аналогично следующему:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)Вы можете приступить к созданию RDD, когда у вас будетSparkContext.
Вы можете создавать RDD несколькими способами, но одним из распространенных способов является функция PySparkparallelize(). parallelize() может преобразовывать некоторые структуры данных Python, такие как списки и кортежи, в RDD, что дает вам функциональность, которая делает их отказоустойчивыми и распределенными.
Чтобы лучше понять СДР, рассмотрим другой пример. Следующий код создает итератор из 10 000 элементов, а затем используетparallelize() для распределения этих данных на 2 раздела:
>>>
>>> big_list = range(10000)
>>> rdd = sc.parallelize(big_list, 2)
>>> odds = rdd.filter(lambda x: x % 2 != 0)
>>> odds.take(5)
[1, 3, 5, 7, 9]parallelize() превращает этот итератор в набор чиселdistributed и предоставляет вам все возможности инфраструктуры Spark.
Обратите внимание, что этот код использует методfilter() RDD вместо встроенного в Pythonfilter(), который вы видели ранее. Результат тот же, но то, что происходит за кулисами, радикально отличается. При использовании метода RDDfilter() эта операция выполняется распределенным образом между несколькими процессорами или компьютерами.
Опять же, представьте, что Spark выполняет за вас работуmultiprocessing, и все это инкапсулировано в структуре данных RDD.
take() - это способ увидеть содержимое вашего RDD, но только небольшую часть. take() переносит это подмножество данных из распределенной системы на одну машину.
take() важен для отладки, поскольку проверка всего набора данных на одном компьютере может быть невозможна. СДР оптимизированы для использования с большими данными, поэтому в реальных условиях на одной машине может не хватить ОЗУ для хранения всего вашего набора данных.
Note: Spark временно выводит информацию вstdout при запуске подобных примеров в оболочке, и вы скоро увидите, как это сделать. Вашstdout может временно отображать что-то вроде[Stage 0:> (0 + 1) / 1].
Текстstdout демонстрирует, как Spark разделяет RDD и обрабатывает ваши данные на несколько этапов на разных процессорах и машинах.
Другой способ создания RDD - это чтение файла сtextFile(), который вы видели в предыдущих примерах. СДР являются одной из основополагающих структур данных для использования PySpark, поэтому многие функции API возвращают СДР.
Одно из ключевых отличий между СДР и другими структурами данных заключается в том, что обработка задерживается до тех пор, пока не будет запрошен результат. Это похоже на aPython generator. Разработчики в экосистеме Python обычно используют терминlazy evaluation для объяснения этого поведения.
Вы можете объединить несколько преобразований в одном RDD без какой-либо обработки. Эта функция возможна, потому что Spark поддерживаетdirected acyclic graphпреобразований. Базовый график активируется только тогда, когда запрашиваются окончательные результаты. В предыдущем примере вычисления не производились, пока вы не запросили результаты, вызвавtake().
Есть несколько способов запросить результаты от RDD. Вы можете явно запросить результаты для оценки и сбора на одном узле кластера, используяcollect() в RDD. Вы также можете неявно запросить результаты различными способами, одним из которых, как вы видели ранее, было использованиеcount().
Note: Будьте осторожны при использовании этих методов, потому что они извлекают весь набор данных в память, что не будет работать, если набор данных слишком велик, чтобы поместиться в RAM одной машины.
Опять же, обратитесь кPySpark API documentation для получения более подробной информации обо всех возможных функциях.
Установка PySpark
Как правило, вы запускаете программы PySpark наHadoop cluster, но поддерживаются и другие варианты развертывания кластера. Вы можете прочитатьSpark’s cluster mode overview для более подробной информации.
Note: Настройка одного из этих кластеров может быть сложной задачей и выходит за рамки данного руководства. В идеале у вашей команды есть несколько инженеров-волшебниковDevOps, которые помогут наладить это. Если нет, Hadoop публикуетa guide, чтобы помочь вам.
В этом руководстве вы увидите несколько способов запуска программ PySpark на локальном компьютере. Это полезно для тестирования и обучения, но вы быстро захотите взять свои новые программы и запустить их в кластере, чтобы действительно обрабатывать большие данные.
Иногда настройка PySpark сама по себе может быть сложной задачей из-за всех необходимых зависимостей.
PySpark работает поверх JVM и требует много базовой инфраструктуры Java для работы. При этом мы живем в эпохуDocker, что значительно упрощает эксперименты с PySpark.
Более того, замечательные разработчикиJupyter сделали за вас всю тяжелую работу. Они публикуютDockerfile, который включает все зависимости PySpark вместе с Jupyter. Таким образом, вы можете экспериментировать прямо в блокноте Jupyter!
Note: Ноутбуки Jupyter обладают множеством функций. ПосмотритеJupyter Notebook: An Introduction, чтобы узнать больше о том, как эффективно использовать записные книжки.
Во-первых, вам нужно установить Docker. Взгляните наDocker in Action – Fitter, Happier, More Productive, если у вас еще нет настройки Docker.
Note: Образы Docker могут быть довольно большими, поэтому убедитесь, что вы используете около 5 ГБ дискового пространства для использования PySpark и Jupyter.
Затем вы можете запустить следующую команду, чтобы загрузить и автоматически запустить Docker-контейнер с предварительно созданной установкой PySpark для одного узла. Эта команда может занять несколько минут, поскольку она загружает изображения непосредственно изDockerHub вместе со всеми требованиями для Spark, PySpark и Jupyter:
$ docker run -p 8888:8888 jupyter/pyspark-notebookКак только эта команда прекращает печатать вывод, у вас есть работающий контейнер, в котором есть все необходимое для тестирования ваших программ PySpark в среде с одним узлом.
Чтобы остановить ваш контейнер, введите [.keys] #Ctrl [.kbd .key-c] # C ## в том же окне, в котором вы ввели команду `+ docker run`.
Теперь пришло время, наконец, запустить некоторые программы!
Запуск программ PySpark
Существует несколько способов выполнения программ PySpark, в зависимости от того, предпочитаете ли вы командную строку или более визуальный интерфейс. Для интерфейса командной строки вы можете использовать командуspark-submit, стандартную оболочку Python или специализированную оболочку PySpark.
Во-первых, вы увидите более визуальный интерфейс с ноутбуком Jupyter.
Блокнот Jupyter
Вы можете запустить свою программу в блокноте Jupyter, выполнив следующую команду, чтобы запустить ранее загруженный контейнер Docker (если он еще не запущен):
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Executing the command: jupyter notebook
[I 08:04:22.869 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[I 08:04:25.022 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 08:04:25.022 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 08:04:25.027 NotebookApp] Serving notebooks from local directory: /home/jovyan
[I 08:04:25.028 NotebookApp] The Jupyter Notebook is running at:
[I 08:04:25.029 NotebookApp] http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
[I 08:04:25.029 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 08:04:25.037 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html
Or copy and paste one of these URLs:
http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437Теперь у вас есть контейнер, работающий с PySpark. Обратите внимание, что в конце вывода командыdocker run упоминается локальный URL.
Note: Вывод командdocker будет немного отличаться на каждом компьютере, потому что токены, идентификаторы контейнеров и имена контейнеров генерируются случайным образом.
Вам необходимо использовать этот URL для подключения к контейнеру Docker, на котором запущен Jupyter, в веб-браузере. Скопируйте и вставьте URLfrom your output прямо в свой веб-браузер. Вот пример URL, который вы, вероятно, увидите:
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437URL в приведенной ниже команде, вероятно, будет немного отличаться на вашем компьютере, но как только вы подключитесь к этому URL в вашем браузере, вы сможете получить доступ к среде ноутбука Jupyter, которая должна выглядеть примерно так:
На странице записной книжки Jupyter вы можете использовать кнопкуNew справа, чтобы создать новую оболочку Python 3. Затем вы можете протестировать некоторый код, например, примерHello World из предыдущего:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Вот как будет работать этот код в записной книжке Jupyter:
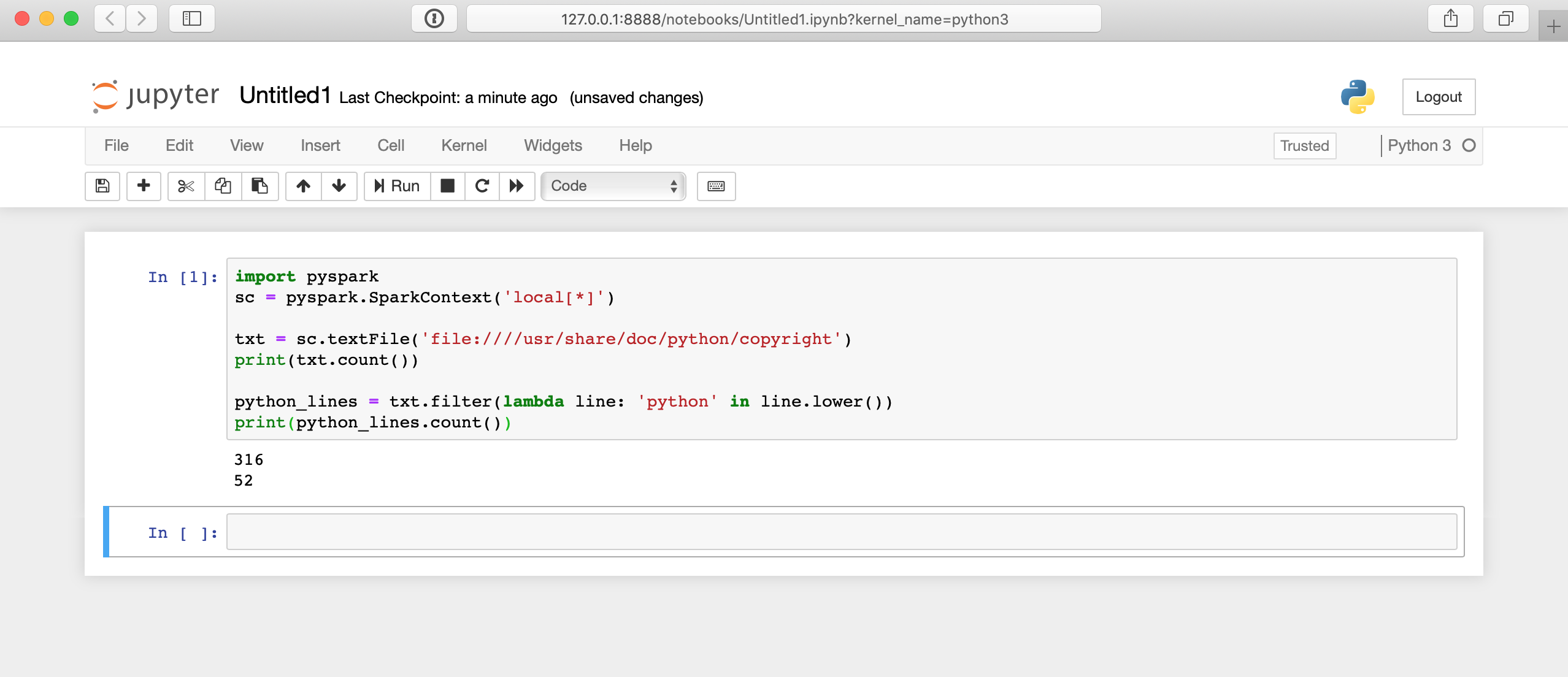
Здесь много чего происходит за кулисами, поэтому отображение результатов может занять несколько секунд. Ответ не появится сразу после нажатия на ячейку.
Интерфейс командной строки
Интерфейс командной строки предлагает множество способов отправки программ PySpark, включая оболочку PySpark и командуspark-submit. Чтобы использовать эти подходы к CLI, вам сначала необходимо подключиться к CLI системы, в которой установлен PySpark.
Чтобы подключиться к CLI настройки Docker, вам нужно запустить контейнер, как и раньше, а затем подключить к этому контейнеру. Опять же, чтобы запустить контейнер, вы можете запустить следующую команду:
$ docker run -p 8888:8888 jupyter/pyspark-notebookПосле запуска контейнера Docker вам необходимо подключиться к нему через оболочку вместо ноутбука Jupyter. Для этого выполните следующую команду, чтобы найти имя контейнера:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d5ab7a93902 jupyter/pyspark-notebook "tini -g -- start-no…" 12 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp kind_edisonЭта команда покажет вам все запущенные контейнеры. НайдитеCONTAINER ID контейнера, в котором запущено изображениеjupyter/pyspark-notebook, и используйте его для подключения к оболочкеbashinside контейнера:
$ docker exec -it 4d5ab7a93902 bash
jovyan@4d5ab7a93902:~$Теперь вы должны быть подключены к приглашениюbashinside of the container. Вы можете проверить, что все работает, потому что приглашение вашей оболочки изменится на что-то похожее наjovyan@4d5ab7a93902, но с использованием уникального идентификатора вашего контейнера.
Note: Замените4d5ab7a93902 наCONTAINER ID, используемое на вашем компьютере.
кластер
Вы можете использовать командуspark-submit, установленную вместе со Spark, для отправки кода PySpark в кластер с помощью командной строки. Эта команда берет программу PySpark или Scala и выполняет ее в кластере. Вероятно, именно так вы будете выполнять свои настоящие задания по обработке больших данных.
Note: Путь к этим командам зависит от того, где был установлен Spark, и, вероятно, будет работать только при использовании указанного контейнера Docker.
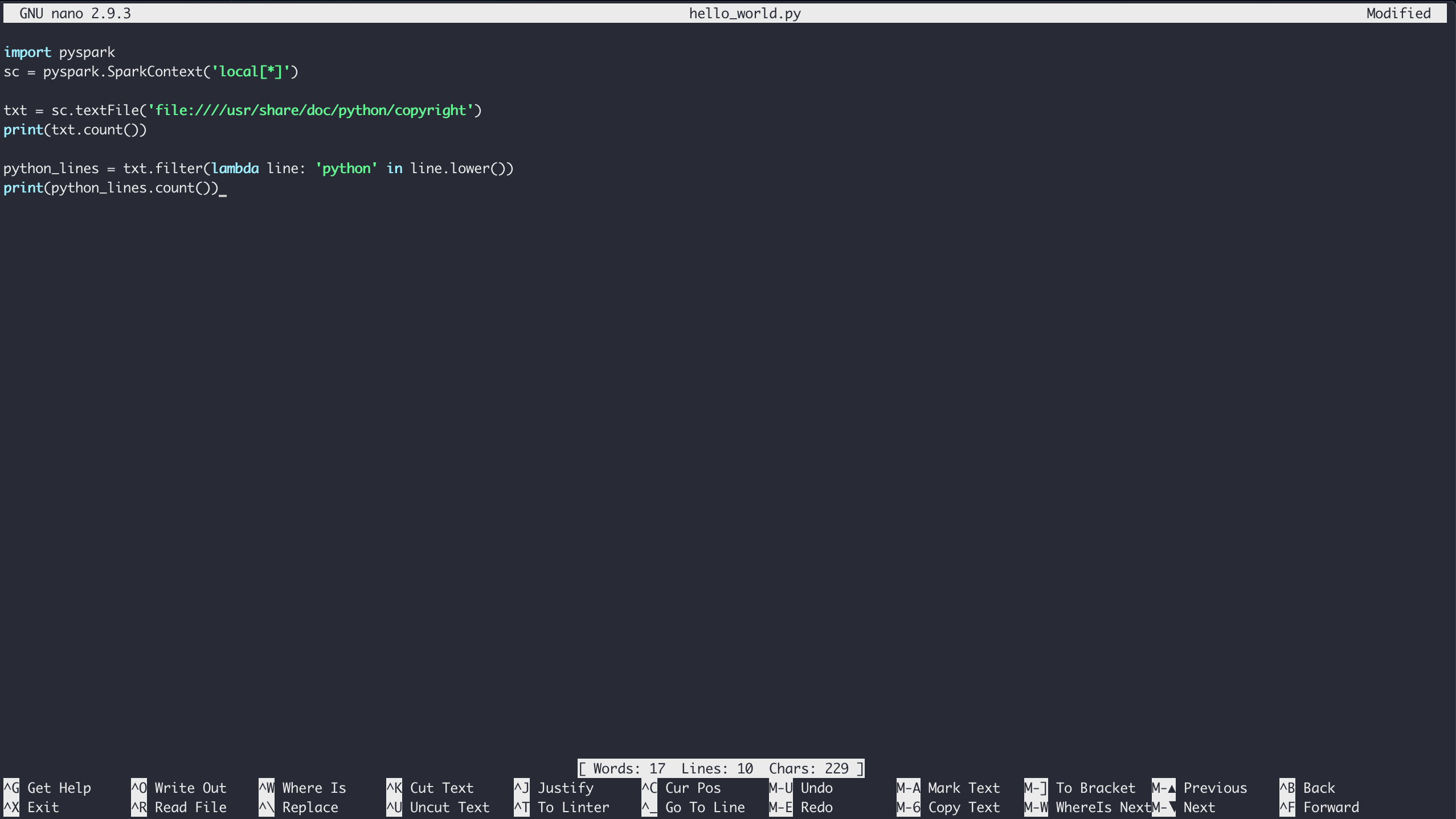
Чтобы запустить примерHello World (или любую программу PySpark) с работающим контейнером Docker, сначала войдите в оболочку, как описано выше. Находясь в среде оболочки контейнера, вы можете создавать файлы с помощьюnano text editor.
Чтобы создать файл в текущей папке, просто запуститеnano с именем файла, который вы хотите создать:
$ nano hello_world.pyВведите содержимое примераHello World и сохраните файл, набравCtrl+[.kbd .key-x]#X # и следуя подсказкам для сохранения:
Наконец, вы можете запустить код через Spark с помощью командыpyspark-submit:
$ /usr/local/spark/bin/spark-submit hello_world.pyЭта команда по умолчанию даетa lot вывода, поэтому может быть трудно увидеть вывод вашей программы. Вы можете отчасти контролировать уровень детализации журнала внутри вашей программы PySpark, изменив уровень вашей переменнойSparkContext. Для этого поместите эту строку в верхнюю часть вашего скрипта:
sc.setLogLevel('WARN')При этом будет пропущенsome выводаspark-submit, чтобы вы могли более четко увидеть вывод своей программы. Однако в реальном сценарии вы захотите поместить любой вывод в файл, базу данных или какой-либо другой механизм хранения для упрощения отладки позже.
К счастью, программа PySpark по-прежнему имеет доступ ко всей стандартной библиотеке Python, поэтому сохранение результатов в файл не представляет проблемы:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
python_lines = txt.filter(lambda line: 'python' in line.lower())
with open('results.txt', 'w') as file_obj:
file_obj.write(f'Number of lines: {txt.count()}\n')
file_obj.write(f'Number of lines with python: {python_lines.count()}\n')Теперь ваши результаты находятся в отдельном файле под названиемresults.txt для более удобного использования позже.
Note: В приведенном выше коде используетсяf-strings, которое было введено в Python 3.6.
PySpark Shell
Еще один специфичный для PySpark способ запуска ваших программ - это использование оболочки, поставляемой вместе с самим PySpark. Опять же, используя настройку Docker, вы можете подключиться к CLI контейнера, как описано выше. Затем вы можете запустить специализированную оболочку Python с помощью следующей команды:
$ /usr/local/spark/bin/pyspark
Python 3.7.3 | packaged by conda-forge | (default, Mar 27 2019, 23:01:00)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 23:01:00)
SparkSession available as 'spark'.Теперь вы находитесь в среде оболочки Pysparkinside вашего контейнера Docker, и вы можете протестировать код, аналогичный примеру с записной книжкой Jupyter:
>>>
>>> txt = sc.textFile('file:////usr/share/doc/python/copyright')
>>> print(txt.count())
316Теперь вы можете работать в оболочке Pyspark так же, как и в обычной оболочке Python.
Note: Вам не нужно было создавать переменнуюSparkContext в примере оболочки Pyspark. Оболочка PySpark автоматически создает переменнуюsc, чтобы связать вас с механизмом Spark в одноузловом режиме.
Выmust create your ownSparkContext при отправке реальных программ PySpark сspark-submit или записной книжкой Jupyter.
Вы также можете использовать стандартную оболочку Python для выполнения ваших программ, если PySpark установлен в эту среду Python. В контейнере Docker, который вы использовалиdoes not, включен PySpark для стандартной среды Python. Итак, вы должны использовать один из предыдущих методов, чтобы использовать PySpark в контейнере Docker.
Объединение PySpark с другими инструментами
Как вы уже видели, PySpark поставляется с дополнительными библиотеками для таких вещей, как машинное обучение и SQL-подобные манипуляции с большими наборами данных. Однако вы также можете использовать другие общие научные библиотеки, такие какNumPy иPandas.
Вы должны установить их в той же средеon each cluster node, и тогда ваша программа сможет использовать их как обычно. Затем вы можете использовать все уже знакомые вам приемыidiomatic Pandas.
Remember:Pandas DataFrames быстро оцениваются, поэтому все данные должны поместиться в памятиon a single machine.
Следующие шаги для обработки больших данных
Вскоре после изучения основ PySpark вы наверняка захотите приступить к анализу огромных объемов данных, которые, вероятно, не будут работать, когда вы используете режим с одним компьютером. Установка и обслуживание кластера Spark выходят за рамки данного руководства и, скорее всего, являются работой на полный рабочий день.
Так что, возможно, пришло время посетить ИТ-отдел в вашем офисе или изучить размещенное кластерное решение Spark. Одно из возможных размещенных решений -Databricks.
Databricks позволяет размещать ваши данные с помощьюMicrosoft Azure илиAWS и имеетfree 14-day trial.
После того, как у вас есть работающий кластер Spark, вы захотите поместить все свои данные в этот кластер для анализа. У Spark есть несколько способов импорта данных:
Вы даже можете читать данные напрямую из сетевой файловой системы, как работали предыдущие примеры.
Нет недостатка в способах получить доступ ко всем вашим данным, независимо от того, используете ли вы размещенное решение, такое как Databricks, или свой кластер машин.
Заключение
PySpark является хорошей отправной точкой в обработке больших данных.
Из этого руководства вы узнали, что вам не нужно тратить много времени на предварительное обучение, если вы знакомы с несколькими концепциями функционального программирования, такими какmap(),filter() иbasic Python. ) с. Фактически, вы можете использовать весь Python, который вы уже знаете, включая знакомые инструменты, такие как NumPy и Pandas, непосредственно в своих программах PySpark.
Теперь вы можете:
-
Встроенные концепции PythonUnderstand, применимые к большим данным
-
Write базовые программы PySpark
-
Run программы PySpark для небольших наборов данных на вашем локальном компьютере
-
Explore более эффективные решения для больших данных, такие как кластер Spark или другое настраиваемое размещенное решение