Вступление
В этом руководстве рассматривается настройка кластера Hadoop в DigitalOcean. Hadoop software library - это среда Apache, которая позволяет обрабатывать большие наборы данных распределенным образом по кластерам серверов за счет использования базовых моделей программирования. Масштабируемость, предоставляемая Hadoop, позволяет масштабировать от отдельных серверов до тысяч машин. Он также обеспечивает обнаружение сбоев на прикладном уровне, поэтому он может обнаруживать и обрабатывать сбои в качестве службы высокой доступности.
В этом уроке мы рассмотрим 4 важных модуля:
-
Hadoop Common - это набор общих утилит и библиотек, необходимых для поддержки других модулей Hadoop.
-
Hadoop Distributed File System (HDFS), как указано вthe Apache organization, представляет собой распределенную файловую систему с высокой отказоустойчивостью, специально разработанную для работы на стандартном оборудовании для обработки больших наборов данных.
-
Hadoop YARN - это структура, используемая для планирования заданий и управления ресурсами кластера.
-
Hadoop MapReduce - это система на основе YARN для параллельной обработки больших наборов данных.
В этом уроке мы будем настраивать и запускать кластер Hadoop на четырех каплях DigitalOcean.
Предпосылки
Для этого урока потребуется следующее:
-
Четыре Ubuntu 16.04 Droplets с некорневыми пользователями sudo. Если у вас нет этой настройки, выполните шаги 1–4Initial Server Setup with Ubuntu 16.04. В этом руководстве предполагается, что вы используете ключ SSH с локальной машины. В соответствии с языком Hadoop, мы будем называть эти капли следующими именами:
-
hadoop-master -
hadoop-worker-01 -
hadoop-worker-02 -
hadoop-worker-03
-
-
Кроме того, вы можете захотеть использоватьDigitalOcean Snapshots после начальной настройки сервера и завершенияSteps 1 и2 (см. Ниже) вашей первой капли.
Имея эти предварительные условия, вы будете готовы приступить к настройке кластера Hadoop.
[[step-1 -—- installation-setup-for-each-dropt]] == Шаг 1. Настройка установки для каждой капли
Мы собираемся установить Java и Hadoop наeach наших капельfour. Если вы не хотите повторять каждый шаг для каждой капли, вы можете использоватьDigitalOcean Snapshots в концеStep 2, чтобы воспроизвести вашу первоначальную установку и конфигурацию.
Во-первых, мы обновим Ubuntu последними доступными обновлениями программного обеспечения:
sudo apt-get update && sudo apt-get -y dist-upgradeДалее, давайте установим безголовую версию Java для Ubuntu на каждую Droplet. «Безголовый» относится к программному обеспечению, которое может работать на устройстве без графического интерфейса пользователя.
sudo apt-get -y install openjdk-8-jdk-headlessЧтобы установить Hadoop на каждую Droplet, давайте создадим каталог, в который будет установлен Hadoop. Мы можем назвать егоmy-hadoop-install, а затем перейти в этот каталог.
mkdir my-hadoop-install && cd my-hadoop-installПосле того, как мы создали каталог, давайте установим самый последний двоичный файл изHadoop releases list. На момент написания этого руководства самым последним являетсяHadoop 3.0.1.
[.note] #Note: имейте в виду, что эти загрузки распространяются через зеркальные сайты, и рекомендуется сначала проверить их на предмет подделки с помощью GPG или SHA-256.
#
Когда вы удовлетворены выбранной загрузкой, вы можете использовать командуwget с выбранной вами двоичной ссылкой, например:
wget http://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gzПосле завершения загрузки распакуйте содержимое файла с помощьюtar, инструмента архивирования файлов для Ubuntu:
tar xvzf hadoop-3.0.1.tar.gzТеперь мы готовы начать нашу первоначальную настройку.
[[step-2 -—- update-hadoop-environment-configuration]] == Шаг 2. Обновление конфигурации среды Hadoop
Для каждого узла Droplet нам нужно настроитьJAVA_HOME. Откройте следующий файл с помощью nano или другого текстового редактора по вашему выбору, чтобы мы могли его обновить:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shОбновите следующий раздел, где находитсяJAVA_HOME:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Чтобы выглядеть так:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Нам также нужно добавить некоторые переменные окружения для запуска Hadoop и его модулей. Их следует добавить в конец файла, чтобы он выглядел следующим образом, гдеsammy будет вашим именем пользователя sudo без полномочий root.
[.note] #Note: Если вы используете другое имя пользователя в каплях кластера, вам нужно будет отредактировать этот файл, чтобы он отображал правильное имя пользователя для каждой конкретной капли.
#
hadoop-env.sh
...
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
export HDFS_NAMENODE_USER="sammy"
export HDFS_DATANODE_USER="sammy"
export HDFS_SECONDARYNAMENODE_USER="sammy"
export YARN_RESOURCEMANAGER_USER="sammy"
export YARN_NODEMANAGER_USER="sammy"На этом этапе вы можете сохранить и выйти из файла. Затем выполните следующую команду, чтобы применить наш экспорт:
source ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shПосле обновления и источника сценарияhadoop-env.sh нам необходимо создать каталог данных для распределенной файловой системы Hadoop (HDFS) для хранения всех соответствующих файловHDFS.
sudo mkdir -p /usr/local/hadoop/hdfs/dataУстановите разрешения для этого файла с вашим соответствующим пользователем. Помните, что если у вас есть разные имена пользователей в каждой капле, убедитесь, что у вашего соответствующего пользователя sudo есть следующие разрешения:
sudo chown -R sammy:sammy /usr/local/hadoop/hdfs/dataЕсли вы хотите использовать снимок DigitalOcean для репликации этих команд между узлами капель, вы можете создать снимок сейчас и создать новые капли из этого изображения. Чтобы узнать об этом, вы можете прочитатьAn Introduction to DigitalOcean Snapshots.
Когда вы выполнили описанные выше шаги дляall four Ubuntu Droplets, вы можете переходить к завершению этой конфигурации на всех узлах.
[[step-3 -—- complete-initial-configuration-for-each-node]] == Step 3 - Complete Initial Configuration для каждого узла
На этом этапе нам нужно обновить файлcore_site.xml дляall 4 ваших узлов Droplet. Внутри каждой отдельной капли откройте следующий файл:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/core-site.xmlВы должны увидеть следующие строки:
core-site.xml
...
Измените файл, чтобы он выглядел как следующий XML, чтобы мы включилиeach Droplet’s respective IP внутри значения свойства, где у нас записаноserver-ip. Если вы используете брандмауэр, вам нужно открыть порт 9000.
core-site.xml
...
fs.defaultFS
hdfs://server-ip:9000
Повторите вышеуказанное написание в соответствующем IP-адресе капли дляall four ваших серверов.
Теперь все общие настройки Hadoop должны быть обновлены для каждого серверного узла, и мы можем продолжать подключать наши узлы через ключи SSH.
[[step-4 -—- set-up-ssh-for-each-node]] == Шаг 4. Настройте SSH для каждого узла
Для правильной работы Hadoop нам необходимо настроить SSH без пароля между главным узлом и рабочими узлами (языкmaster иworker - это язык Hadoop для обозначенияprimary и secondary серверов).
В этом руководстве главным узлом будетhadoop-master, а рабочие узлы будут в совокупности называтьсяhadoop-worker, но всего у вас их будет три (обозначаемые как-01, -02 и-03). Сначала нам нужно создать пару открытого и закрытого ключей на главном узле, который будет узлом с IP-адресом, принадлежащимhadoop-master.
Находясь в каплеhadoop-master, выполните следующую команду. Нажмитеenter, чтобы использовать значение по умолчанию для местоположения ключа, затем дважды нажмитеenter, чтобы использовать пустую кодовую фразу:
ssh-keygenДля каждого рабочего узла нам нужно взять открытый ключ главного узла и скопировать его в файлauthorized_keys каждого рабочего узла.
Получите открытый ключ от главного узла, запустивcat в файлеid_rsa.pub, расположенном в вашей папке.ssh, для печати на консоли:
cat ~/.ssh/id_rsa.pubТеперь войдите в каждый рабочий узел Droplet и откройте файлauthorized_keys:
nano ~/.ssh/authorized_keysВы скопируете открытый ключ главного узла - результат, сгенерированный командойcat ~/.ssh/id_rsa.pub на главном узле - в соответствующий файл~/.ssh/authorized_keys каждой капли. Обязательно сохраните каждый файл перед закрытием.
Когда вы закончите обновление 3 рабочих узлов, также скопируйте открытый ключ главного узла в его собственный файлauthorized_keys, введя ту же команду:
nano ~/.ssh/authorized_keysНаhadoop-master вы должны настроить конфигурациюssh, чтобы включить каждое из имен хостов связанных узлов. Откройте файл конфигурации для редактирования, используя nano:
nano ~/.ssh/configВам следует изменить файл так, чтобы он выглядел следующим образом, с добавлением соответствующих IP-адресов и имен пользователей.
конфиг
Host hadoop-master-server-ip
HostName hadoop-example-node-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-01-server-ip
HostName hadoop-worker-01-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-02-server-ip
HostName hadoop-worker-02-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-03-server-ip
HostName hadoop-worker-03-server-ip
User sammy
IdentityFile ~/.ssh/id_rsaСохраните и закройте файл.
Изhadoop-master, SSH в каждый узел:
ssh sammy@hadoop-worker-01-server-ipПоскольку вы впервые заходите на каждый узел с настроенной текущей системой, вам будет предложено следующее:
Outputare you sure you want to continue connecting (yes/no)?Ответьте на запросyes. Это будет единственный раз, когда это необходимо сделать, но это требуется для каждого рабочего узла для начального соединения SSH. Наконец, выйдите из каждого рабочего узла, чтобы вернуться кhadoop-master:
logoutНе забудьтеrepeat these steps для оставшихся двух рабочих узлов.
Теперь, когда мы успешно настроили SSH без пароля для каждого рабочего узла, мы можем продолжить настройку главного узла.
[[step-5 -—- configure-the-master-node]] == Шаг 5 - Настройте главный узел
Для нашего кластера Hadoop нам необходимо настроить свойства HDFS на главном узле Droplet.
Находясь на главном узле, отредактируйте следующий файл:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlОтредактируйте разделconfiguration, чтобы он выглядел как XML-код ниже:
hdfs-site.xml
...
dfs.replication
3
dfs.namenode.name.dir
file:///usr/local/hadoop/hdfs/data
Сохраните и закройте файл.
Затем мы настроим свойстваMapReduce на главном узле. Откройтеmapred.site.xml с помощью nano или другого текстового редактора:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mapred-site.xmlЗатем обновите файл так, чтобы он выглядел следующим образом: IP-адрес вашего текущего сервера указан ниже:
mapred-site.xml
...
mapreduce.jobtracker.address
hadoop-master-server-ip:54311
mapreduce.framework.name
yarn
Сохраните и закройте файл. Если вы используете брандмауэр, обязательно откройте порт 54311.
Затем настройте YARN на главном узле. Опять же, мы обновляем раздел конфигурации другого XML-файла, поэтому давайте откроем файл:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/yarn-site.xmlТеперь обновите файл, обязательно введя IP-адрес вашего текущего сервера:
yarn-site.xml
...
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop-master-server-ip
Наконец, давайте настроим точку отсчета Hadoop для того, какими должны быть главный и рабочий узлы. Сначала откройте файлmasters:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mastersВ этот файл вы добавите IP-адрес вашего текущего сервера:
мастера
hadoop-master-server-ipТеперь откройте и отредактируйте файлworkers:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/workersЗдесь вы добавите IP-адреса каждого из ваших рабочих узлов, под тем местом, где написаноlocalhost.
рабочие
localhost
hadoop-worker-01-server-ip
hadoop-worker-02-server-ip
hadoop-worker-03-server-ipПосле завершения настройки свойствMapReduce иYARN мы можем теперь завершить настройку рабочих узлов.
[[step-6 -—- configure-the-worker-nodes]] == Шаг 6. Настройте рабочие узлы
Теперь мы настроим рабочие узлы так, чтобы у каждого из них была правильная ссылка на каталог данных для HDFS.
Наeach worker node отредактируйте этот XML-файл:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlЗамените раздел конфигурации следующим:
hdfs-site.xml
dfs.replication
3
dfs.datanode.data.dir
file:///usr/local/hadoop/hdfs/data
Сохраните и закройте файл. Не забудьте повторить этот шаг наall three ваших рабочих узлов.
На этом этапе капли нашего рабочего узла указывают на каталог данных для HDFS, что позволит нам запустить наш кластер Hadoop.
[[step-7 -—- run-the-hadoop-cluster]] == Шаг 7. Запустите кластер Hadoop
Мы достигли точки, когда мы можем запустить наш кластер Hadoop. Прежде чем мы запустим его, нам нужно отформатировать HDFS на главном узле. Находясь на главном узле Droplet, измените каталоги, где установлен Hadoop:
cd ~/my-hadoop-install/hadoop-3.0.1/Затем выполните следующую команду для форматирования HDFS:
sudo ./bin/hdfs namenode -formatУспешное форматирование namenode приведет к большому количеству результатов, состоящих в основном из операторовINFO. Внизу вы увидите следующее, подтверждающее, что вы успешно отформатировали каталог хранения.
Output...
2018-01-28 17:58:08,323 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/data has been successfully formatted.
2018-01-28 17:58:08,346 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 using no compression
2018-01-28 17:58:08,490 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds.
2018-01-28 17:58:08,505 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-01-28 17:58:08,519 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-example-node/127.0.1.1
************************************************************/Теперь запустите кластер Hadoop, выполнив следующие сценарии (обязательно проверьте сценарии перед запуском с помощью командыless):
sudo ./sbin/start-dfs.shЗатем вы увидите вывод, который содержит следующее:
OutputStarting namenodes on [hadoop-master-server-ip]
Starting datanodes
Starting secondary namenodes [hadoop-master]Затем запустите YARN, используя следующий скрипт:
./sbin/start-yarn.shПоявится следующий вывод:
OutputStarting resourcemanager
Starting nodemanagersПосле запуска этих команд у вас должны быть запущены демоны на главном узле и по одному на каждом из рабочих узлов.
Мы можем проверить демонов, запустив командуjps для проверки процессов Java:
jpsПосле выполнения командыjps вы увидите, чтоNodeManager,SecondaryNameNode,Jps,NameNode,ResourceManager иDataNode бегут. Появится нечто похожее на следующий вывод:
Output9810 NodeManager
9252 SecondaryNameNode
10164 Jps
8920 NameNode
9674 ResourceManager
9051 DataNodeЭто подтверждает, что мы успешно создали кластер, и проверяет, работают ли демоны Hadoop.
В любом веб-браузере вы можете получить обзор состояния вашего кластера, перейдя по ссылке:
http://hadoop-master-server-ip:9870Если у вас есть брандмауэр, обязательно откройте порт 9870. Вы увидите нечто похожее на следующее:
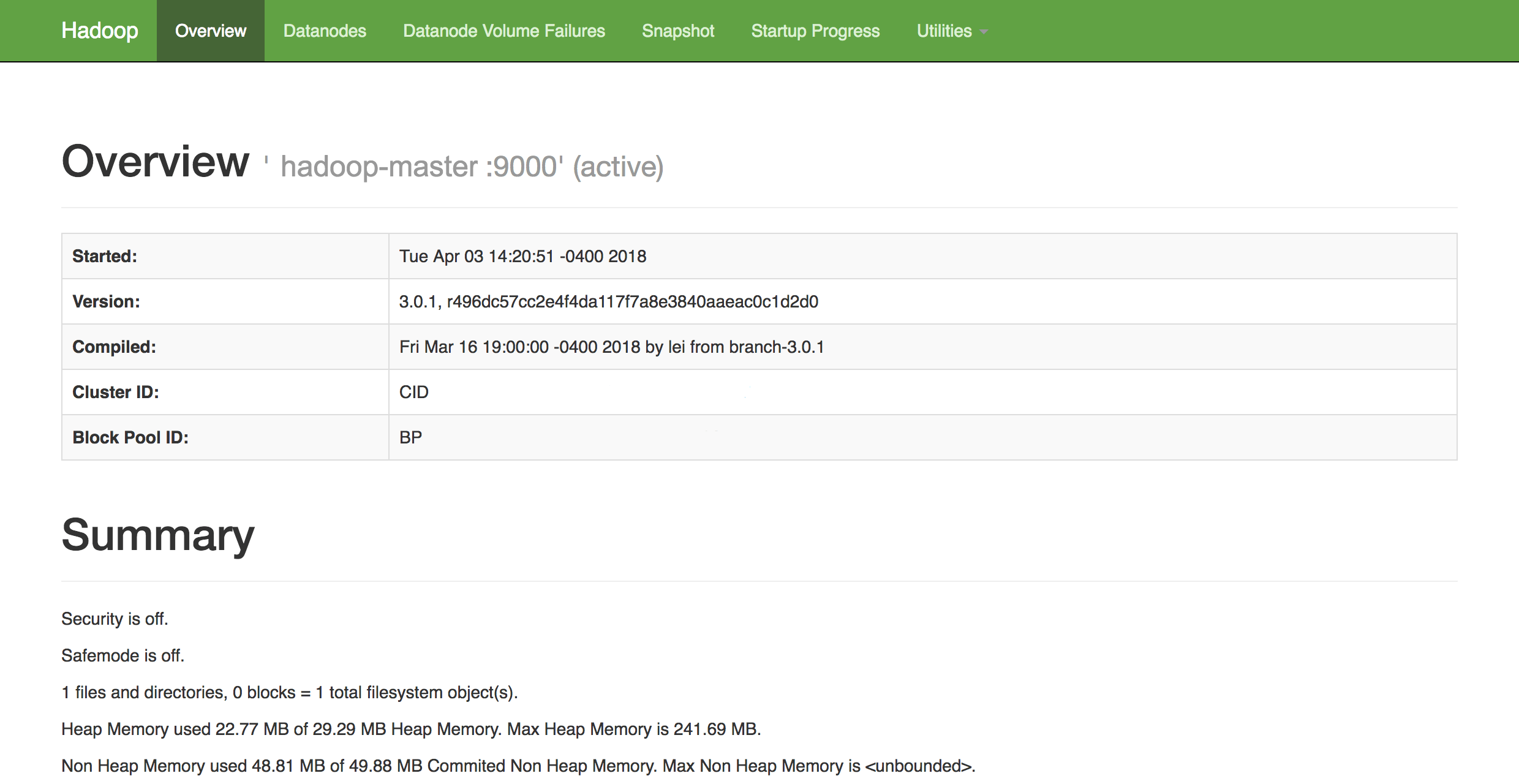
Отсюда вы можете перейти к элементуDatanodes в строке меню, чтобы увидеть активность узла.
Заключение
В этом уроке мы рассмотрели, как настроить и настроить многоузловой кластер Hadoop с использованием DigitalOcean Ubuntu 16.04 Droplets. Теперь вы также можете отслеживать и проверять работоспособность своего кластера с помощью веб-интерфейса Hadoop DFS Health.
Чтобы получить представление о возможных проектах, над которыми вы можете работать, чтобы использовать недавно настроенный кластер, просмотрите длинный список проектов Apachepowered by Hadoop.