Вступление
MySQL cluster - это программная технология, обеспечивающая высокую доступность и пропускную способность. Если вы уже знакомы с другими кластерными технологиями, вы найдете похожий на них кластер MySQL. Короче говоря, существует один или несколько узлов управления, которые контролируют узлы данных (где хранятся данные). После консультации с узлом управления клиенты (клиенты MySQL, серверы или собственные API) подключаются напрямую к узлам данных.
Вы можете задаться вопросом, как репликация MySQL связана с кластером MySQL. В кластере нет типичной репликации данных, но вместо этого происходит синхронизация узлов данных. Для этого необходимо использовать специальный механизм обработки данных - NDBCluster (NDB). Представьте кластер как единую логическую среду MySQL с избыточными компонентами. Таким образом, кластер MySQL может участвовать в репликации с другими кластерами MySQL.
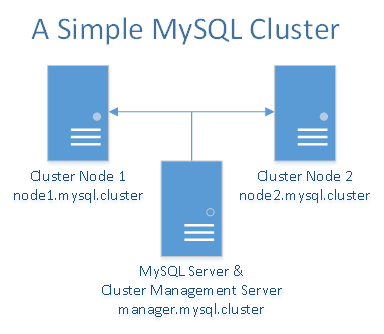
MySQL кластер лучше всего работает в среде без общего доступа. В идеале, два компонента не должны использовать одно и то же оборудование. Для простоты и демонстрации мы ограничимся использованием только трех капель. Там будут две капли, выступающие в качестве узлов данных, которые синхронизируют данные между собой. Третья капля будет использоваться для менеджера кластера и в то же время для сервера / клиента MySQL. Если у вас есть больше Droplets, вы можете добавить больше узлов данных, отделить менеджер кластера от сервера / клиента MySQL и даже добавить больше Droplets в качестве менеджеров кластера и серверов / клиентов MySQL.
Предпосылки
Вам понадобится всего три капли - одна капля для менеджера кластера MySQL и сервер / клиент MySQL и две капли для избыточных узлов данных MySQL.
Вsame DigitalOcean data center создайте следующие капли сprivate networking enabled:
-
Три капли Ubuntu 16.04 с минимум 1 ГБ ОЗУ и включеннымиprivate networking
-
Пользователь без полномочий root с привилегиями sudo для каждой капли (Initial Server Setup with Ubuntu 16.04 объясняет, как это настроить).
MySQL кластер хранит много информации в оперативной памяти. Каждая капля должна иметь как минимум 1 ГБ оперативной памяти.
Как упоминалось вprivate networking tutorial, не забудьте настроить пользовательские записи для 3 капель. Для простоты и удобства мы будем использовать следующие пользовательские записи для каждой капли в файле/etc/hosts:
10.XXX.XX.X node1.mysql.cluster
10.YYY.YY.Y node2.mysql.cluster
10.ZZZ.ZZ.Z manager.mysql.cluster
Пожалуйста, замените выделенные IP-адреса на частные IP-адреса ваших дроплетов соответственно.
Если не указано иное, все команды, которым требуются привилегии root в этом учебном пособии, должны запускаться как пользователь без полномочий root с привилегиями sudo.
[[шаг-1 -—- загрузка-и-установка-mysql-cluster]] == Шаг 1. Загрузка и установка MySQL Cluster
На момент написания этого руководства последняя версия кластера MySQL под GPL была 7.4.11. Продукт построен на основе MySQL 5.6 и включает в себя:
-
Программное обеспечение Cluster Manager
-
Программное обеспечение диспетчера узлов данных
-
MySQL 5.6 сервер и клиентские двоичные файлы
Вы можете скачать бесплатную общедоступную (GA) версию кластера MySQL изofficial MySQL cluster download page. На этой странице выберите пакет платформы Debian Linux, который также подходит для Ubuntu. Также обязательно выберите 32-битную или 64-битную версию в зависимости от архитектуры ваших дроплетов. Загрузите установочный пакет в каждую из ваших капель.
Инструкции по установке будут одинаковыми для всех капель, поэтому выполните эти шаги для всех 3 капель.
Перед тем, как начать установку, необходимо установить пакетlibaio1, так как это зависимость:
sudo apt-get install libaio1После этого установите кластерный пакет MySQL:
sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.debТеперь вы можете найти установку кластера MySQL в каталоге/opt/mysql/server-5.6/. В частности, мы будем работать с каталогом bin (/opt/mysql/server-5.6/bin/), где находятся все двоичные файлы.
Те же самые шаги установки должны быть выполнены для всех трех Капель независимо от того, что каждая из них будет иметь разные функции - менеджер или узел данных.
Далее мы настроим диспетчер кластеров MySQL для каждой капли.
[[step-2 -—- configuring-and-start-the-cluster-manager]] == Шаг 2 - Настройка и запуск Cluster Manager
На этом этапе мы настроим диспетчер кластеров MySQL (manager.mysql.cluster). Его правильная конфигурация обеспечит правильную синхронизацию и распределение нагрузки между узлами данных. Все команды должны выполняться на каплеmanager.mysql.cluster.
Диспетчер кластеров - это первый компонент, который должен запускаться в любом кластере. Ему нужен файл конфигурации, который передается в качестве аргумента в его двоичный файл. Для удобства мы будем использовать файл/var/lib/mysql-cluster/config.ini для его настройки.
В каплеmanager.mysql.cluster сначала создайте каталог, в котором будет находиться этот файл (/var/lib/mysql-cluster):
sudo mkdir /var/lib/mysql-clusterЗатем создайте файл и начните редактировать его с помощью nano:
sudo nano /var/lib/mysql-cluster/config.iniЭтот файл должен содержать следующий код:
/var/lib/mysql-cluster/config.ini
[ndb_mgmd]
# Management process options:
hostname=manager.mysql.cluster # Hostname of the manager
datadir=/var/lib/mysql-cluster # Directory for the log files
[ndbd]
hostname=node1.mysql.cluster # Hostname of the first data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[ndbd]
hostname=node2.mysql.cluster # Hostname of the second data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[mysqld]
# SQL node options:
hostname=manager.mysql.cluster # In our case the MySQL server/client is on the same Droplet as the cluster managerДля каждого из вышеперечисленных компонентов мы определили параметрhostname. Это важная мера безопасности, поскольку только указанному имени хоста будет разрешено подключаться к менеджеру и участвовать в кластере в соответствии с назначенной им ролью.
Кроме того, параметрыhostname указывают, на каком интерфейсе будет работать служба. Это важно и важно для безопасности, потому что в нашем случае указанные выше имена хостов указывают на частные IP-адреса, которые мы указали в файлах/etc/hosts. Таким образом, вы не можете получить доступ к любой из вышеперечисленных услуг за пределами частной сети.
В приведенном выше файле вы можете добавить больше избыточных компонентов, таких как узлы данных (ndbd) или серверы MySQL (mysqld), просто определив дополнительные экземпляры точно таким же образом.
Теперь вы можете запустить менеджер в первый раз, выполнив двоичный файлndb_mgmd и указав файл конфигурации с аргументом-f следующим образом:
sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.iniВы должны увидеть сообщение об успешном запуске, похожее на это:
Output of ndb_mgmdMySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11Вы, вероятно, хотели бы, чтобы служба управления запускалась автоматически с сервера. В выпуске кластера GA нет подходящего сценария запуска, но есть несколько доступных в Интернете. Для начала вы можете просто добавить команду запуска в файл/etc/rc.local, и служба будет автоматически запущена во время загрузки. Однако сначала вам нужно убедиться, что/etc/rc.local выполняется во время запуска сервера. В Ubuntu 16.04 для этого требуется выполнить дополнительную команду:
sudo systemctl enable rc-local.serviceЗатем откройте файл/etc/rc.local для редактирования:
sudo nano /etc/rc.localДобавьте команду запуска перед строкойexit следующим образом:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0Сохраните и выйдите из файла.
Диспетчер кластеров не должен работать все время. Его можно запускать, останавливать и перезапускать без простоев для кластера. Это требуется только во время начального запуска узлов кластера и сервера / клиента MySQL.
[[step-3 -—- configuring-and-start-the-data-nodes]] == Шаг 3 - Настройка и запуск узлов данных
Затем мы настроим узлы данных (node1.mysql.cluster иnode2.mysql.cluster) для хранения файлов данных и правильной поддержки механизма NDB. Все команды должны быть выполнены на обоих узлах. Вы можете начать сначала сnode1.mysql.cluster, а затем повторить те же шаги дляnode2.mysql.cluster.
Узлы данных считывают конфигурацию из стандартного файла конфигурации MySQL/etc/my.cnf, а точнее части после строки[mysql_cluster]. Создайте этот файл с помощью nano и начните редактировать его:
sudo nano /etc/my.cnfУкажите имя хоста менеджера следующим образом:
/etc/my.cnf
[mysql_cluster]
ndb-connectstring=manager.mysql.clusterСохраните и выйдите из файла.
Указание местоположения менеджера является единственной конфигурацией, необходимой для запуска механизма узла. Остальная часть конфигурации будет взята у менеджера напрямую. В нашем примере узел данных обнаружит, что его каталог данных -/usr/local/mysql/data в соответствии с конфигурацией менеджера. Этот каталог должен быть создан на узле. Вы можете сделать это с помощью команды:
sudo mkdir -p /usr/local/mysql/dataПосле этого вы можете запустить узел данных в первый раз с помощью команды:
sudo /opt/mysql/server-5.6/bin/ndbdПосле успешного запуска вы должны увидеть похожий результат:
Output of ndbd2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2У вас должна быть запущена служба ndbd автоматически с сервером. В этом выпуске кластера GA также нет подходящего сценария запуска. Так же, как мы сделали для менеджера кластера, давайте добавим команду запуска в файл/etc/rc.local. Опять же, вам нужно будет убедиться, что/etc/rc.local выполняется во время запуска сервера с помощью команды:
sudo systemctl enable rc-local.serviceЗатем откройте файл/etc/rc.local для редактирования:
sudo nano /etc/rc.localДобавьте команду запуска перед строкойexit следующим образом:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndbd
exit 0Сохраните и выйдите из файла.
Как только вы закончите с первым узлом, повторите точно такие же шаги на другом узле, которым в нашем примере являетсяnode2.mysql.cluster.
[[step-4 -—- configuring-and-start-the-mysql-server-and-client]] == Шаг 4 - Настройка и запуск сервера и клиента MySQL
Стандартный сервер MySQL, такой как тот, который доступен в стандартном репозитории Ubuntu apt, не поддерживает кластерный механизм MySQL NDB. Вот почему вам нужна индивидуальная установка сервера MySQL. Кластерный пакет, который мы уже установили на трех каплях, поставляется с сервером MySQL и клиентом. Как уже упоминалось, мы будем использовать сервер и клиент MySQL на узле управления (manager.mysql.cluster).
Конфигурация снова сохраняется как файл по умолчанию/etc/my.cnf. Наmanager.mysql.cluster откройте файл конфигурации:
sudo nano /etc/my.cnfЗатем добавьте следующее:
/etc/my.cnf
[mysqld]
ndbcluster # run NDB storage engine
...Сохраните и выйдите из файла.
Согласно передовой практике, сервер MySQL должен работать под своим собственным пользователем (mysql), который принадлежит его собственной группе (опять жеmysql). Итак, давайте сначала создадим группу:
sudo groupadd mysqlЗатем создайте пользователяmysql, принадлежащего этой группе, и убедитесь, что он не может использовать оболочку, задав для его пути к оболочке/bin/false следующим образом:
sudo useradd -r -g mysql -s /bin/false mysqlПоследнее требование для пользовательской установки сервера MySQL - это создание базы данных по умолчанию. Вы можете сделать это с помощью команды:
sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysqlДля запуска сервера MySQL мы будем использовать сценарий запуска из/opt/mysql/server-5.6/support-files/mysql.server. Скопируйте его в каталог сценариев инициализации по умолчанию под именемmysqld следующим образом:
sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqldВключите сценарий запуска и добавьте его к уровням запуска по умолчанию с помощью команды:
sudo systemctl enable mysqld.serviceТеперь мы можем запустить сервер MySQL в первый раз вручную с помощью команды:
sudo systemctl start mysqldВ качестве клиента MySQL мы снова будем использовать пользовательский двоичный файл, который поставляется с установкой кластера. Путь к нему следующий:/opt/mysql/server-5.6/bin/mysql. Для удобства создадим на него символическую ссылку в пути по умолчанию/usr/bin:
sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/Теперь вы можете запустить клиент из командной строки, просто набравmysql следующим образом:
mysqlВы должны увидеть вывод, похожий на:
Output of ndb_mgmdWelcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL)Чтобы выйти из командной строки MySQL, просто введитеquit или одновременно нажмитеCTRL-D.
Выше - первая проверка, чтобы показать, что MySQL кластер, сервер и клиент работают. Далее мы пройдем более подробные тесты, чтобы убедиться, что кластер работает правильно.
Тестирование кластера
На этом этапе наш простой кластер MySQL с одним клиентом, одним сервером, одним менеджером и двумя узлами данных должен быть завершен. В диспетчере кластера Droplet (manager.mysql.cluster) откройте консоль управления с помощью команды:
sudo /opt/mysql/server-5.6/bin/ndb_mgmТеперь подсказка должна измениться на консоль управления кластером. Это выглядит так:
Inside the ndb_mgm console-- NDB Cluster -- Management Client --
ndb_mgm>Оказавшись внутри консоли, выполните командуSHOW следующим образом:
SHOWВы должны увидеть вывод, похожий на этот:
Output of ndb_mgmConnected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)Выше показано, что есть два узла данных с идентификаторами 2 и 3. Они активны и связаны. Существует также один узел управления с идентификатором 1 и один сервер MySQL с идентификатором 4. Вы можете найти дополнительную информацию о каждом идентификаторе, набрав его номер с помощью командыSTATUS следующим образом:
2 STATUSПриведенная выше команда покажет вам состояние узла 2 вместе с его версиями MySQL и NDB:
Output of ndb_mgmNode 2: started (mysql-5.6.29 ndb-7.4.11)Чтобы выйти из консоли управления, введитеquit.
Консоль управления очень мощная и предоставляет множество других возможностей для управления кластером и его данными, включая создание оперативной резервной копии. Для получения дополнительной информации проверьтеofficial documentation.
Давайте сейчас попробуем с клиентом MySQL. Из той же капли запустите клиент с помощью командыmysql для пользователя root MySQL. Пожалуйста, помните, что мы создали символическую ссылку на него ранее.
mysql -u root\ Ваша консоль изменится на клиентскую консоль MySQL. Оказавшись внутри клиента MySQL, запустите команду:
SHOW ENGINE NDB STATUS \GТеперь вы должны увидеть всю информацию о ядре кластера NDB, начиная с подробностей соединения:
Output of mysql
*************************** 1. row ***************************
Type: ndbcluster
Name: connection
Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
...Наиболее важной информацией сверху является количество готовых узлов - 2. Эта избыточность позволит вашему кластеру MySQL продолжать работать, даже если один из узлов данных не работает в то время. В то же время ваши SQL-запросы будут сбалансированы по нагрузке для двух узлов.
Вы можете попробовать отключить один из узлов данных, чтобы проверить стабильность кластера. Простейшей вещью было бы просто перезапустить всю Droplet, чтобы провести полную проверку процесса восстановления. Вы увидите, как значениеnumber_of_ready_data_nodes изменится на1 и снова вернется к2 при перезапуске узла.
Работа с двигателем NDB
Чтобы увидеть, как на самом деле работает кластер, давайте создадим новую таблицу с механизмом NDB и вставим в нее некоторые данные. Обратите внимание, что для использования функциональности кластера механизм должен быть NDB. Если вы используете InnoDB (по умолчанию) или любой другой механизм, отличный от NDB, вы не будете использовать кластер.
Во-первых, давайте создадим базу данных под названиемcluster с помощью команды:
CREATE DATABASE cluster;Далее, переключитесь на новую базу данных:
USE cluster;Теперь создайте простую таблицу с именемcluster_test, например:
CREATE TABLE cluster_test (name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster;Выше мы явно указали движокndbcluster, чтобы использовать кластер. Далее мы можем начать вставку данных с помощью запроса:
INSERT INTO cluster_test (name,value) VALUES('some_name','some_value');Чтобы убедиться, что данные были вставлены, выполните запрос на выборку, например так:
SELECT * FROM cluster_test;Когда вы вставляете и выбираете данные, подобные этим, вы распределяете нагрузку между запросами между всеми доступными узлами данных, которых в нашем примере два. При таком масштабировании вы получаете выгоду как с точки зрения стабильности, так и производительности.
Заключение
Как мы видели в этой статье, настройка кластера MySQL может быть простой и легкой. Конечно, есть много более сложных опций и функций, которые стоит освоить, прежде чем кластер перейдет в вашу производственную среду. Как всегда, убедитесь, что у вас есть адекватный процесс тестирования, потому что некоторые проблемы могут быть очень трудно решить позже. Для получения дополнительной информации и дальнейшего чтения перейдите к официальной документации дляMySQL cluster.