Введение в HikariCP
1. обзор
В этой вводной статье мы узнаем о проекте пула соединенийHikariCP JDBC. This is a very lightweight (at roughly 130Kb) and lightning fast JDBC connection pooling framework разработанBrett Wooldridge примерно в 2012 году.
2. Вступление
Доступно несколько результатов тестов для сравнения производительности HikariCP с другими фреймворками пула соединений, такими какc3p0,dbcp2,tomcat иvibur. Например, команда HikariCP опубликовала следующие тесты (доступны исходные результатыhere):
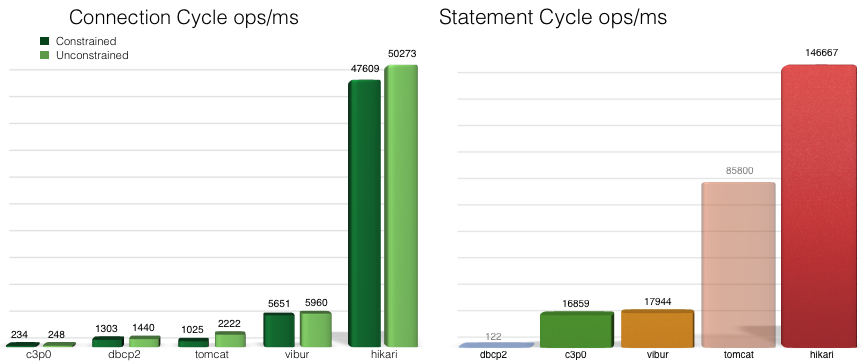
Фреймворк настолько быстр, потому что были применены следующие методы:
-
Bytecode-level engineering – была проделана некоторая экстремальная инженерия на уровне байт-кода (включая собственное кодирование на уровне сборки)
-
Micro-optimizations –, хотя их трудно измерить, в совокупности эти оптимизации повышают общую производительность.
-
Intelligent use of the Collections framework –ArrayList<Statement> был заменен настраиваемым классомFastList, который исключает проверку диапазона и выполняет сканирование удаления от хвоста к голове
3. Maven Dependency
Давайте создадим образец приложения, чтобы осветить его использование. HikariCP поставляется с поддержкой всех основных версий JVM. Каждая версия требует своей зависимости; для Java 9 имеем:
com.zaxxer
HikariCP-java9ea
2.6.1
И для Java 8:
com.zaxxer
HikariCP
2.6.1
Более старые версии JDK, такие как 6 и 7, также поддерживаются. Соответствующие версии можно найтиhere иhere. Также мы можем проверить последние версии вCentral Maven Repository.
4. использование
Давайте теперь создадим демонстрационное приложение. Обратите внимание, что нам нужно включить подходящую зависимость класса драйвера JDBC вpom.xml. Если зависимости не указаны, приложение выдастClassNotFoundException.
4.1. СозданиеDataSource
Мы будем использоватьDataSource HikariCP для создания единственного экземпляра источника данных для нашего приложения:
public class DataSource {
private static HikariConfig config = new HikariConfig();
private static HikariDataSource ds;
static {
config.setJdbcUrl( "jdbc_url" );
config.setUsername( "database_username" );
config.setPassword( "database_password" );
config.addDataSourceProperty( "cachePrepStmts" , "true" );
config.addDataSourceProperty( "prepStmtCacheSize" , "250" );
config.addDataSourceProperty( "prepStmtCacheSqlLimit" , "2048" );
ds = new HikariDataSource( config );
}
private DataSource() {}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
}Здесь следует отметить инициализацию в блокеstatic.
HikariConfig - это класс конфигурации, используемый для инициализации источника данных. Он поставляется с четырьмя хорошо известными обязательными параметрами:username,password,jdbcUrl,dataSourceClassName.
ИзjdbcUrl иdataSourceClassName каждый должен использоваться одновременно. Однако при использовании этого свойства со старыми драйверами нам может потребоваться установить оба свойства.
В дополнение к этим свойствам, есть несколько других доступных свойств, которые могут не все быть предложены другими платформами объединения:
-
autoCommit
-
время соединения вышло
-
idleTimeout
-
maxLifetime
-
connectionTestQuery
-
connectionInitSql
-
validationTimeout
-
maximumPoolSize
-
poolName
-
allowPoolSuspension
-
доступен только для чтения
-
транзакция
-
утечкаDetectionThreshold
HikariCP выделяется из-за этих свойств базы данных. Он достаточно продвинут, чтобы самостоятельно обнаруживать утечки соединения!
Подробное описание этих свойств можно найти вhere.
Мы также можем инициализироватьHikariConfig файлом свойств, помещенным в каталогresources:
private static HikariConfig config = new HikariConfig(
"datasource.properties" );Файл свойств должен выглядеть примерно так:
dataSourceClassName= //TBD
dataSource.user= //TBD
//other properties name should start with dataSource as shown aboveМы также можем использовать конфигурацию на основеjava.util.Properties-:
Properties props = new Properties();
props.setProperty( "dataSourceClassName" , //TBD );
props.setProperty( "dataSource.user" , //TBD );
//setter for other required properties
private static HikariConfig config = new HikariConfig( props );В качестве альтернативы, мы можем инициализировать источник данных напрямую:
ds.setJdbcUrl( //TBD );
ds.setUsername( //TBD );
ds.setPassword( //TBD );4.2. Использование источника данных
Теперь, когда мы определили источник данных, мы можем использовать его для получения соединения из настроенного пула соединений и выполнения действий, связанных с JDBC.
Предположим, у нас есть две таблицы с именамиdept иemp, чтобы смоделировать вариант использования «сотрудник-отдел». Мы напишем класс для извлечения этих данных из базы данных, используя HikariCP.
Ниже приведен список операторов SQL, необходимых для создания примера данных:
create table dept(
deptno numeric,
dname varchar(14),
loc varchar(13),
constraint pk_dept primary key ( deptno )
);
create table emp(
empno numeric,
ename varchar(10),
job varchar(9),
mgr numeric,
hiredate date,
sal numeric,
comm numeric,
deptno numeric,
constraint pk_emp primary key ( empno ),
constraint fk_deptno foreign key ( deptno ) references dept ( deptno )
);
insert into dept values( 10, 'ACCOUNTING', 'NEW YORK' );
insert into dept values( 20, 'RESEARCH', 'DALLAS' );
insert into dept values( 30, 'SALES', 'CHICAGO' );
insert into dept values( 40, 'OPERATIONS', 'BOSTON' );
insert into emp values(
7839, 'KING', 'PRESIDENT', null,
to_date( '17-11-1981' , 'dd-mm-yyyy' ),
7698, null, 10
);
insert into emp values(
7698, 'BLAKE', 'MANAGER', 7839,
to_date( '1-5-1981' , 'dd-mm-yyyy' ),
7782, null, 20
);
insert into emp values(
7782, 'CLARK', 'MANAGER', 7839,
to_date( '9-6-1981' , 'dd-mm-yyyy' ),
7566, null, 30
);
insert into emp values(
7566, 'JONES', 'MANAGER', 7839,
to_date( '2-4-1981' , 'dd-mm-yyyy' ),
7839, null, 40
);Обратите внимание, что если мы используем какую-либо базу данных в памяти, такую как H2, нам нужно автоматически загрузить скрипт базы данных перед запуском фактического кода для извлечения данных. К счастью, H2 поставляется с параметромINIT, который может загружать сценарий базы данных из пути к классам во время выполнения. URL JDBC должен выглядеть следующим образом:
jdbc:h2:mem:test;DB_CLOSE_DELAY=-1;INIT=runscript from 'classpath:/db.sql'Нам нужно создать метод для извлечения этих данных из базы данных:
public static List fetchData() throws SQLException {
String SQL_QUERY = "select * from emp";
List employees = null;
try (Connection con = DataSource.getConnection();
PreparedStatement pst = con.prepareStatement( SQL_QUERY );
ResultSet rs = pst.executeQuery();) {
employees = new ArrayList<>();
Employee employee;
while ( rs.next() ) {
employee = new Employee();
employee.setEmpNo( rs.getInt( "empno" ) );
employee.setEname( rs.getString( "ename" ) );
employee.setJob( rs.getString( "job" ) );
employee.setMgr( rs.getInt( "mgr" ) );
employee.setHiredate( rs.getDate( "hiredate" ) );
employee.setSal( rs.getInt( "sal" ) );
employee.setComm( rs.getInt( "comm" ) );
employee.setDeptno( rs.getInt( "deptno" ) );
employees.add( employee );
}
}
return employees;
} Теперь нам нужно создать метод JUnit для его проверки. Поскольку мы знаем количество строк в таблицеemp, мы можем ожидать, что размер возвращаемого списка должен быть равен количеству строк:
@Test
public void givenConnection_thenFetchDbData() throws SQLException {
HikariCPDemo.fetchData();
assertEquals( 4, employees.size() );
}5. Заключение
В этом кратком руководстве мы узнали о преимуществах использования HikariCP и его конфигурации.
Как всегда, доступен полный исходный кодover on GitHub.