Вступление
Пакет Pythonpandas используется для обработки и анализа данных, он разработан, чтобы позволить вам работать с помеченными или реляционными данными интуитивно понятным способом.
Пакетpandas предлагает функции электронных таблиц, но, поскольку вы работаете с Python, он намного быстрее и эффективнее, чем традиционная программа для работы с электронными таблицами.
В этом руководстве мы рассмотрим настройку большого набора данных для работы с функциямиgroupby() иpivot_table() дляpandas и, наконец, как визуализировать данные.
Чтобы получить некоторое представление о пакетеpandas, вы можете прочитать наше руководствоAn Introduction to the pandas Package and its Data Structures in Python 3.
Предпосылки
Это руководство расскажет, как работать с данными вpandas на локальном рабочем столе или на удаленном сервере. Работа с большими наборами данных может потребовать много памяти, поэтому в любом случае компьютеру потребуется не менее2GB of memory для выполнения некоторых вычислений в этом руководстве.
В этом руководстве мы будем использоватьJupyter Notebook для работы с данными. Если у вас его еще нет, следуйте нашимtutorial to install and set up Jupyter Notebook for Python 3.
Настройка данных
В этом руководстве мы будем работать с данными социального обеспечения США об именах детей, которые доступны изSocial Security website в виде zip-файла размером 8 МБ.
Давайте активируем нашу среду программирования Python 3 на нашемlocal machine или на нашемserver из правильного каталога:
cd environments. my_env/bin/activateТеперь давайте создадим новый каталог для нашего проекта. Мы можем назвать егоnames, а затем перейти в каталог:
mkdir names
cd namesВ этом каталоге мы можем извлечь zip-файл с веб-сайта Социального обеспечения с помощью командыcurl:
curl -O https://www.ssa.gov/oact/babynames/names.zipКак только файл будет загружен, давайте проверим, что у нас установлены все пакеты, которые мы будем использовать:
-
numpyдля поддержки многомерных массивов -
matplotlibдля визуализации данных -
pandasдля нашего анализа данных -
seaborn, чтобы сделать статистическую графику matplotlib более эстетичной
Если у вас еще нет установленных пакетов, установите их с помощьюpip, как в:
pip install pandas
pip install matplotlib
pip install seabornПакетnumpy также будет установлен, если у вас его еще нет.
Теперь мы можем запустить Jupyter Notebook:
jupyter notebookКогда вы войдете в веб-интерфейс Jupyter Notebook, вы увидите там файлnames.zip.
Чтобы создать новый файл записной книжки, выберитеNew>Python 3 в правом верхнем раскрывающемся меню:
Это откроет блокнот.
Начнем сimporting пакетов, которые мы будем использовать. В верхней части нашей записной книжки мы должны написать следующее:
import numpy as np
import matplotlib.pyplot as pp
import pandas as pd
import seabornМы можем запустить этот код и перейти к новому блоку кода, набравALT + ENTER.
Давайте также скажем Python Notebook, чтобы наши графики были встроенными:
matplotlib inlineДавайте запустим код и продолжим, набравALT + ENTER.
С этого момента мы перейдем к распаковке zip-архива, загрузим набор данных CSV вpandas, а затем объединимpandasDataFrames.
Распаковка Zip-архива
Чтобы распаковать zip-архив в текущий каталог, мы импортируем модульzipfile, а затем вызовем функциюZipFile с именем файла (в нашем случаеnames.zip):
import zipfile
zipfile.ZipFile('names.zip').extractall('.')Мы можем запустить код и продолжить, набравALT + ENTER.
Теперь, если вы вернетесь в свой каталогnames, у вас будут файлы данных имен.txt в формате CSV. Эти файлы будут соответствовать годам данных в файле, с 1881 по 2015 год. Каждый из этих файлов соответствует похожему соглашению об именах. Например, файл 2015 года называетсяyob2015.txt, а файл 1927 года -yob1927.txt.
Чтобы взглянуть на формат одного из этих файлов, давайте используем Python, чтобы открыть его и отобразить 5 верхних строк:
open('yob2015.txt','r').readlines()[:5]Запустите код и продолжайте сALT + ENTER.
Output['Emma,F,20355\n',
'Olivia,F,19553\n',
'Sophia,F,17327\n',
'Ava,F,16286\n',
'Isabella,F,15504\n']Форматирование данных: сначала имя (как вEmma илиOlivia), затем пол (как вF для женского имени иM для мужского имени), а затем количество младенцев, родившихся в этом году с этим именем (в 2015 году родилось 20 355 младенцев по имени Эмма).
Имея эту информацию, мы можем загрузить данные вpandas.
Загрузить данные CSV вpandas
Чтобы загрузить данные значений, разделенных запятыми, вpandas, мы будем использовать функциюpd.read_csv(), передавая имя текстового файла, а также имена столбцов, которые мы выберем. Мы присвоим это переменной, в данном случаеnames2015, поскольку мы используем данные из файла за 2015 год рождения.
names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])ВведитеALT + ENTER, чтобы запустить код и продолжить.
Чтобы убедиться, что это сработало, давайте отобразим верхнюю часть таблицы:
names2015.head()Когда мы запустим код и продолжим сALT + ENTER, мы увидим следующий результат:

Наша таблица теперь содержит информацию об именах, поле и количестве детей, рожденных с каждым именем, упорядоченным по столбцам.
Объединить объектыpandas
Объединение объектовpandas позволит нам работать со всеми отдельными текстовыми файлами в каталогеnames.
Чтобы объединить их, нам сначала нужно инициализировать список, назначив переменную незаполненномуlist data type:
all_years = []Как только мы это сделаем, мы будем использоватьfor loop для перебора всех файлов по годам, которые варьируются от 1880 до 2015. Мы добавим+1 к концу 2015 года, чтобы 2015 год был включен в цикл.
all_years = []
for year in range(1880, 2015+1):Внутри цикла мы добавим в список каждое из значений текстового файла, используяstring formatter для обработки различных имен каждого из этих файлов. Мы передадим эти значения переменнойyear. Опять же, мы укажем столбцы дляName,Sex и количестваBabies:
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))Кроме того, мы создадим столбец для каждого года, чтобы сохранить упорядоченность. Это можно сделать после каждой итерации, используя индекс-1, чтобы указывать на них по ходу цикла.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = yearНаконец, мы добавим его к объектуpandas конкатенацией с помощью функцииpd.concat(). Мы будем использовать переменнуюall_names для хранения этой информации.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
all_names = pd.concat(all_years)Теперь мы можем запустить цикл сALT + ENTER, а затем проверить вывод, вызвав хвост (самые нижние строки) результирующей таблицы:
all_names.tail()
Теперь наш набор данных готов и готов к дополнительной работе с ним вpandas.
Группировка данных
С помощьюpandas вы можете группировать данные по столбцам с помощью функции.groupby(). Используя нашу переменнуюall_names для нашего полного набора данных, мы можем использоватьgroupby() для разделения данных на разные сегменты.
Давайте сгруппируем набор данных по полу и году. Мы можем настроить это так:
group_name = all_names.groupby(['Sex', 'Year'])Мы можем запустить код и продолжить сALT + ENTER.
На этом этапе, если мы просто вызовем переменнуюgroup_name, мы получим следующий результат:
OutputЭто показывает нам, что это объектDataFrameGroupBy. Этот объект содержит инструкции о том, как группировать данные, но не дает инструкций о том, как отображать значения.
Для отображения значений нам нужно будет дать инструкции. Мы можем вычислить.size(),.mean() и.sum(), например, чтобы вернуть таблицу.
Начнем с.size():
group_name.size()Когда мы запустим код и продолжим сALT + ENTER, наш результат будет выглядеть так:
OutputSex Year
F 1880 942
1881 938
1882 1028
1883 1054
1884 1172
...Эти данные выглядят хорошо, но они могут быть более читабельными. Мы можем сделать его более читабельным, добавив функцию.unstack:
group_name.size().unstack()Теперь, когда мы запускаем код и продолжаем вводитьALT + ENTER, результат будет выглядеть следующим образом:

Эти данные говорят нам о том, сколько женских и мужских имен было за каждый год. Например, в 1889 году было 1479 женских и 1111 мужских имен. В 2015 году насчитывалось 18 993 женских и 13 959 мужских имен. Это показывает, что с течением времени происходит большее разнообразие имен.
Если мы хотим получить общее количество рожденных младенцев, мы можем использовать функцию.sum(). Давайте применим это к меньшему набору данных,names2015, установленному из единственного файлаyob2015.txt, который мы создали ранее:
names2015.groupby(['Sex']).sum()Давайте наберемALT + ENTER, чтобы запустить код и продолжить:
 ) .sum () output]
) .sum () output]
Это показывает нам общее количество младенцев мужского и женского пола, родившихся в 2015 году, хотя в набор данных включаются только те дети, чье имя использовалось не менее 5 раз в этом году.
Функцияpandas.groupby() позволяет нам сегментировать наши данные на значимые группы.
Сводная таблица
Сводные таблицы полезны для обобщения данных. Они могут автоматически сортировать, подсчитывать, суммировать или усреднять данные, хранящиеся в одной таблице. Затем они могут показать результаты этих действий в новой таблице этих обобщенных данных.
Вpandas функцияpivot_table() используется для создания сводных таблиц.
Чтобы построить сводную таблицу, мы сначала вызовем DataFrame, с которым мы хотим работать, затем данные, которые мы хотим показать, и то, как они сгруппированы.
В этом примере мы будем работать с даннымиall_names и покажем данные о младенцах, сгруппированные по имени в одном измерении и году - в другом:
pd.pivot_table(all_names, 'Babies', 'Name', 'Year')Когда мы набираемALT + ENTER, чтобы запустить код и продолжить, мы увидим следующий результат:
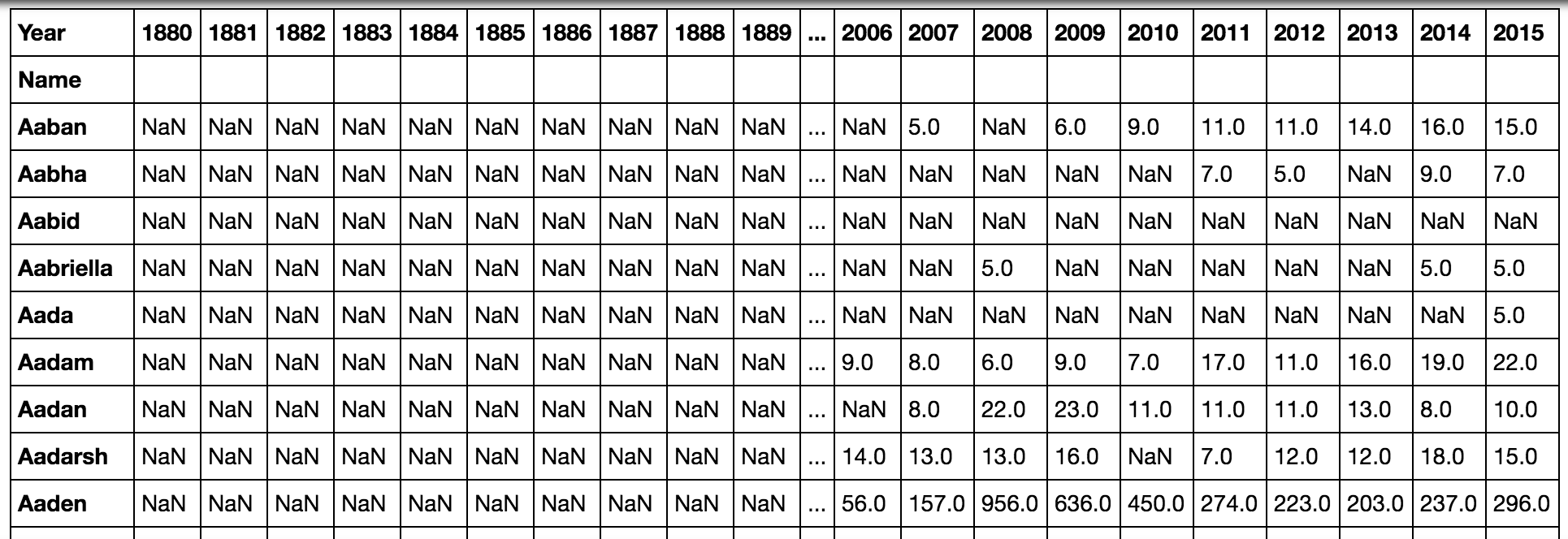
Поскольку это показывает много пустых значений, мы можем захотеть сохранить Имя и Год как столбцы, а не как строки в одном случае и столбцы в другом. Мы можем сделать это, сгруппировав данные в квадратных скобках:
pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])После того, как мы введемALT + ENTER, чтобы запустить код и продолжить, в этой таблице теперь будут отображаться данные только за те годы, которые зарегистрированы для каждого имени:
OutputName Year
Aaban 2007 5.0
2009 6.0
2010 9.0
2011 11.0
2012 11.0
2013 14.0
2014 16.0
2015 15.0
Aabha 2011 7.0
2012 5.0
2014 9.0
2015 7.0
Aabid 2003 5.0
Aabriella 2008 5.0
2014 5.0
2015 5.0Кроме того, мы можем сгруппировать данные так, чтобы имя и пол были в одном измерении, а год - в другом:
pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')Когда мы запустим код и продолжим сALT + ENTER, мы увидим следующую таблицу:
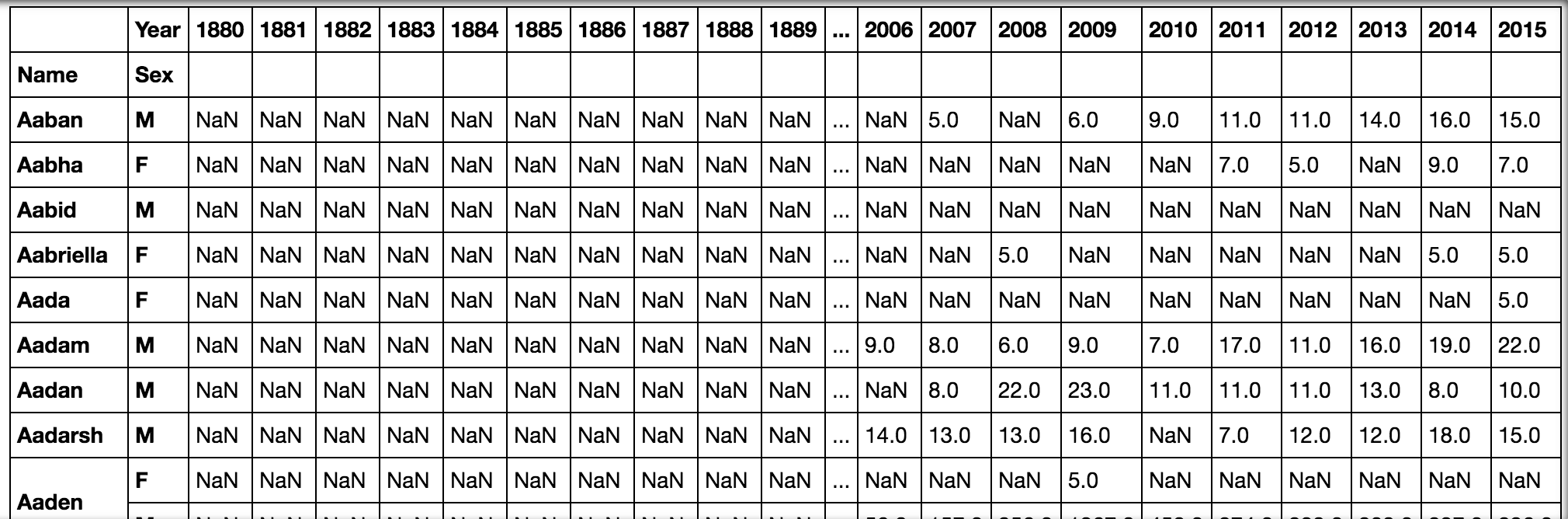 , 'Year') output]
, 'Year') output]
Сводные таблицы позволяют нам создавать новые таблицы из существующих таблиц, что позволяет нам решать, как мы хотим, чтобы эти данные группировались.
Визуализируйте данные
Используяpandas с другими пакетами, такими какmatplotlib, мы можем визуализировать данные в нашей записной книжке.
Мы будем визуализировать данные о популярности данного имени на протяжении многих лет. Для этого нам нужно установить и отсортировать индексы для обработки данных, которые позволят нам увидеть изменение популярности конкретного имени.
Пакетpandas позволяет нам выполнять иерархическое или многоуровневое индексирование, которое позволяет нам хранить и манипулировать данными с произвольным количеством измерений.
Мы собираемся проиндексировать наши данные с информацией о пол, затем имя, год. Мы также хотим отсортировать индекс:
all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()ВведитеALT + ENTER для запуска и перейдите к следующей строке, где в записной книжке будет отображаться новый проиндексированный фрейм данных:
all_names_indexЗапустите код и продолжайте сALT + ENTER, и результат будет выглядеть так:

Далее мы хотим написать функцию, которая будет отображать популярность имени с течением времени. Мы вызовем функциюname_plot и передадим ейsex иname в качестве параметров, которые мы будем вызывать при запуске функции.
def name_plot(sex, name):Теперь мы настроим переменную с именемdata для хранения созданной таблицы. Мы также будем использоватьpandas DataFrameloc, чтобы выбирать нашу строку по значению индекса. В нашем случае мы хотим, чтобыloc основывался на комбинации полей в MultiIndex, ссылаясь как на данныеsex, так и наname.
Давайте запишем эту конструкцию в нашу функцию:
def name_plot(sex, name):
data = all_names_index.loc[sex, name]Наконец, нам нужно отобразить значения сmatplotlib.pyplot, которые мы импортировали какpp. Затем мы сопоставим значения данных пола и имени с индексом, который для наших целей равен годам.
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
pp.plot(data.index, data.values)ВведитеALT + ENTER, чтобы запустить и перейти в следующую ячейку. Теперь мы можем вызвать функцию с указанием пола и имени по нашему выбору, напримерF для женского имени с заданным именемDanica.
name_plot('F', 'Danica')Когда вы сейчас наберетеALT + ENTER, вы получите следующий результат:
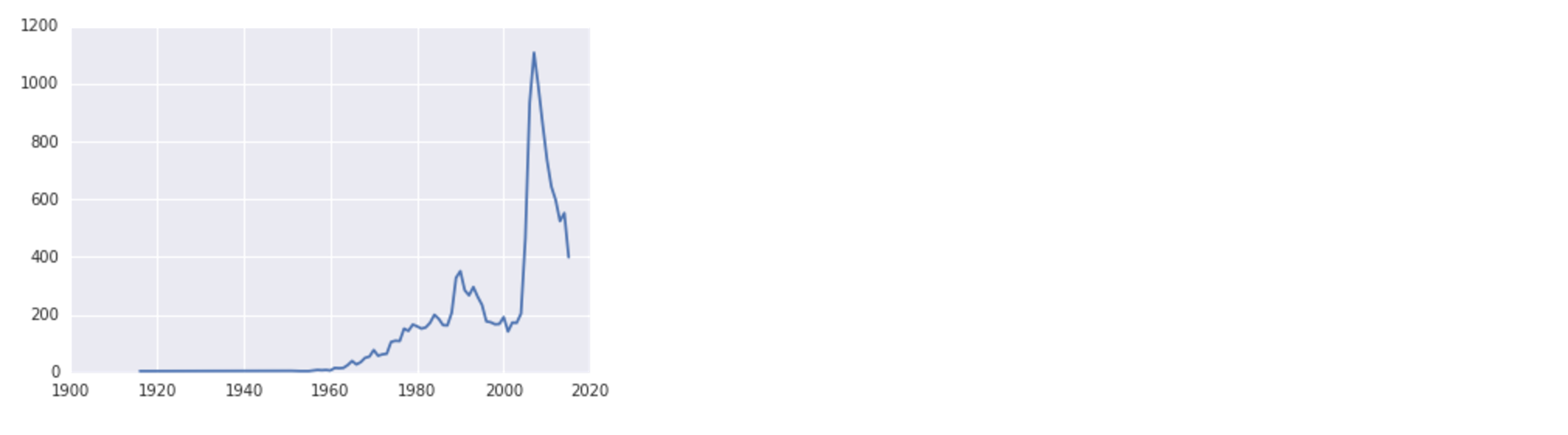
Обратите внимание, что в зависимости от того, какую систему вы используете, вы можете получить предупреждение о замене шрифта, но данные все равно будут отображаться правильно.
Глядя на визуализацию, мы видим, что женское имя Даника немного выросло в 1990 году и достигло максимума как раз перед 2010 годом.
Созданную нами функцию можно использовать для отображения данных из нескольких имен, чтобы мы могли видеть тенденции во времени для разных имен.
Давайте начнем с того, что сделаем наш сюжет немного больше:
pp.figure(figsize = (18, 8))Далее, давайте создадим список со всеми именами, которые мы хотели бы построить:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']Теперь мы можем перебирать список с помощью циклаfor и отображать данные для каждого имени. Во-первых, мы попробуем эти гендерно-нейтральные имена как женские имена:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)Чтобы облегчить понимание этих данных, давайте добавим легенду:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
pp.legend(names)Мы наберемALT + ENTER, чтобы запустить код и продолжить, а затем мы получим следующий результат:
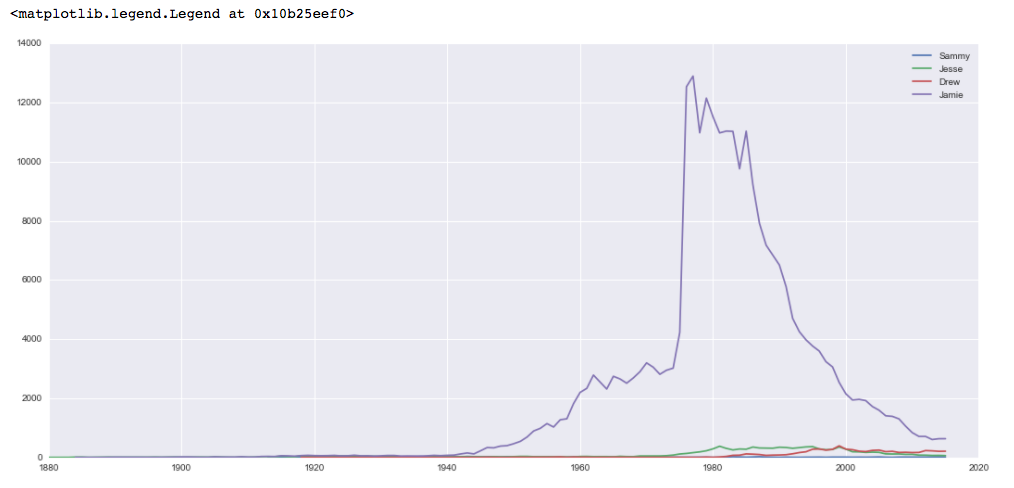
В то время как каждое из имен постепенно завоевывало популярность как женские имена, имя, которое Джейми был чрезвычайно популярен как женское имя в 1980 году.
Давайте назовем те же имена, но на этот раз как мужские имена:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('M', name)
pp.legend(names)Снова введитеALT + ENTER, чтобы запустить код и продолжить. График будет выглядеть так:
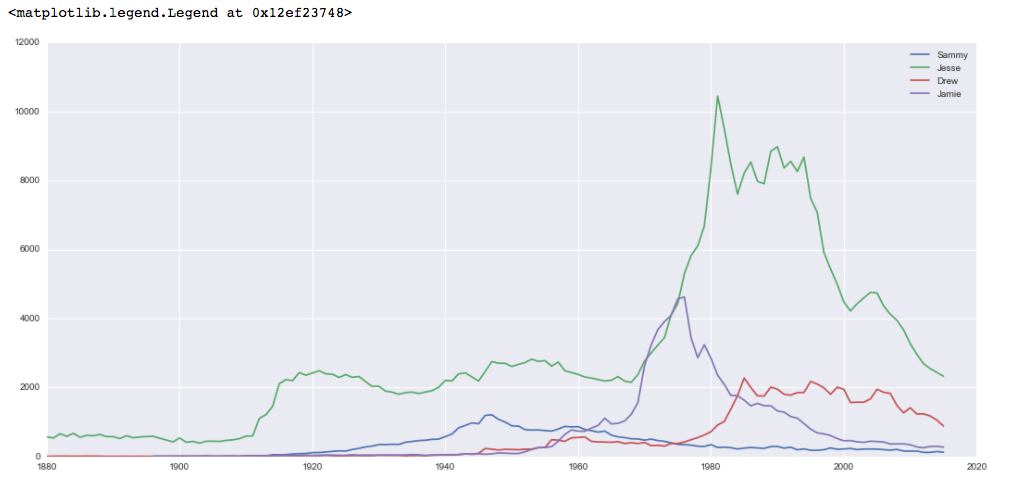
Эти данные показывают большую популярность среди имен, причем Джесси, как правило, является самым популярным выбором и особенно популярным в 1980-х и 1990-х годах.
Отсюда вы можете продолжать играть с данными имен, создавать визуализации различных имен и их популярности, а также создавать другие сценарии для просмотра различных данных для визуализации.
Заключение
В этом руководстве вы познакомились со способами работы с большими наборами данных от настройки данных до группировки данных с помощьюgroupby() иpivot_table(), индексации данных с помощью MultiIndex и визуализации данныхpandas. используя пакетmatplotlib.
Многие организации и учреждения предоставляют наборы данных, с которыми вы можете работать, чтобы продолжать изучатьpandas и визуализацию данных. Правительство США предоставляет данные, например, черезdata.gov.
Вы можете узнать больше о визуализации данных с помощьюmatplotlib, следуя нашим руководствам поHow to Plot Data in Python 3 Using matplotlib иHow To Graph Word Frequency Using matplotlib with Python 3.