Вступление
В предыдущих уроках мы показывалиhow to visualize and manipulate time series data иhow to leverage the ARIMA method to produce forecasts from time series data. Мы отметили, что правильная параметризация моделей ARIMA может быть сложным ручным процессом, который требует определенного времени.
Другие языки статистического программирования, такие какR, предоставляютautomated ways для решения этой проблемы, но они еще не были официально перенесены на Python. К счастью, команда Core Data Science в Facebook недавно опубликовала новый метод под названиемProphet, который позволяет как аналитикам данных, так и разработчикам выполнять масштабное прогнозирование на Python 3.
Предпосылки
В этом руководстве будет рассказано, как выполнять анализ временных рядов на локальном компьютере или на удаленном сервере. Работа с большими наборами данных может потребовать много памяти, поэтому в любом случае компьютеру потребуется не менее2GB of memory для выполнения некоторых вычислений в этом руководстве.
В этом руководстве мы будем использоватьJupyter Notebook для работы с данными. Если у вас его еще нет, следуйте нашимtutorial to install and set up Jupyter Notebook for Python 3.
[[step-1 -—- pull-dataset-and-install-packages]] == Шаг 1. Получение набора данных и установка пакетов
Чтобы настроить нашу среду для прогнозирования временных рядов с помощью Prophet, давайте сначала перейдем в нашу локальную среду программирования или среду программирования на основе сервера:
cd environments. my_env/bin/activateОтсюда давайте создадим новый каталог для нашего проекта. Мы назовем егоtimeseries, а затем перейдем в каталог. Если вы называете проект другим именем, не забудьте заменитьtimeseries своим именем на протяжении всего руководства:
mkdir timeseries
cd timeseriesМы будем работать с Box and Jenkins (1976)Airline Passengers dataset, который содержит временные ряды данных о ежемесячном количестве авиапассажиров в период с 1949 по 1960 год. Вы можете сохранить данные, используя командуcurl с флагом-O для записи вывода в файл и загрузки CSV:
curl -O https://assets.digitalocean.com/articles/eng_python/prophet/AirPassengers.csvВ этом руководстве потребуются библиотекиpandas,matplotlib,numpy,cython иfbprophet. Как и большинство других пакетов Python, мы можем установить библиотекиpandas,numpy,cython иmatplotlib с помощью pip:
pip install pandas matplotlib numpy cythonДля вычисления своих прогнозов библиотекаfbprophet использует язык программированияSTAN, названный в честь математикаStanislaw Ulam. Поэтому перед установкойfbprophet нам необходимо убедиться, что установлена оболочка Pythonpystan дляSTAN:
pip install pystanКак только это будет сделано, мы можем установить Prophet с помощью pip:
pip install fbprophetТеперь, когда мы все настроены, мы можем начать работать с установленными пакетами.
[[step-2 -—- import-packages-and-load-data]] == Шаг 2. Импорт пакетов и загрузка данных
Чтобы начать работать с нашими данными, мы запустим Jupyter Notebook:
jupyter notebookЧтобы создать новый файл записной книжки, выберитеNew>Python 3 в правом верхнем раскрывающемся меню:
Откроется блокнот, который позволит нам загрузить необходимые библиотеки.
Лучше всего начать с импорта необходимых вам библиотек в верхней части записной книжки (обратите внимание на стандартные сокращения, используемые для ссылки наpandas,matplotlib иstatsmodels):
%matplotlib inline
import pandas as pd
from fbprophet import Prophet
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')Обратите внимание, как мы также определили пятьсот тридцать восемьmatplotlib style для наших графиков.
После каждого блока кода в этом руководстве вы должны вводитьALT + ENTER, чтобы запустить код и перейти в новый блок кода в записной книжке.
Давайте начнем с чтения данных нашего временного ряда. Мы можем загрузить файл CSV и распечатать первые 5 строк с помощью следующих команд:
df = pd.read_csv('AirPassengers.csv')
df.head(5)
НашDataFrame явно содержит столбцыMonth иAirPassengers. Библиотека Prophet ожидает в качестве входных данных DataFrame с одним столбцом, содержащим информацию о времени, и другим столбцом, содержащим метрику, которую мы хотим прогнозировать. Важно отметить, что ожидается, что столбец времени будет иметь типdatetime, поэтому давайте проверим тип наших столбцов:
df.dtypesOutputMonth object
AirPassengers int64
dtype: objectПоскольку столбецMonth не относится к типуdatetime, нам необходимо преобразовать его:
df['Month'] = pd.DatetimeIndex(df['Month'])
df.dtypesOutputMonth datetime64[ns]
AirPassengers int64
dtype: objectТеперь мы видим, что наш столбецMonth имеет правильный типdatetime.
Prophet также накладывает строгое условие, согласно которому входные столбцы должны называтьсяds (столбец времени) иy (столбец метрики), поэтому давайте переименуем столбцы в нашем DataFrame:
df = df.rename(columns={'Month': 'ds',
'AirPassengers': 'y'})
df.head(5)
Хорошей практикой является визуализация данных, с которыми мы будем работать, поэтому давайте составим график нашего временного ряда:
ax = df.set_index('ds').plot(figsize=(12, 8))
ax.set_ylabel('Monthly Number of Airline Passengers')
ax.set_xlabel('Date')
plt.show()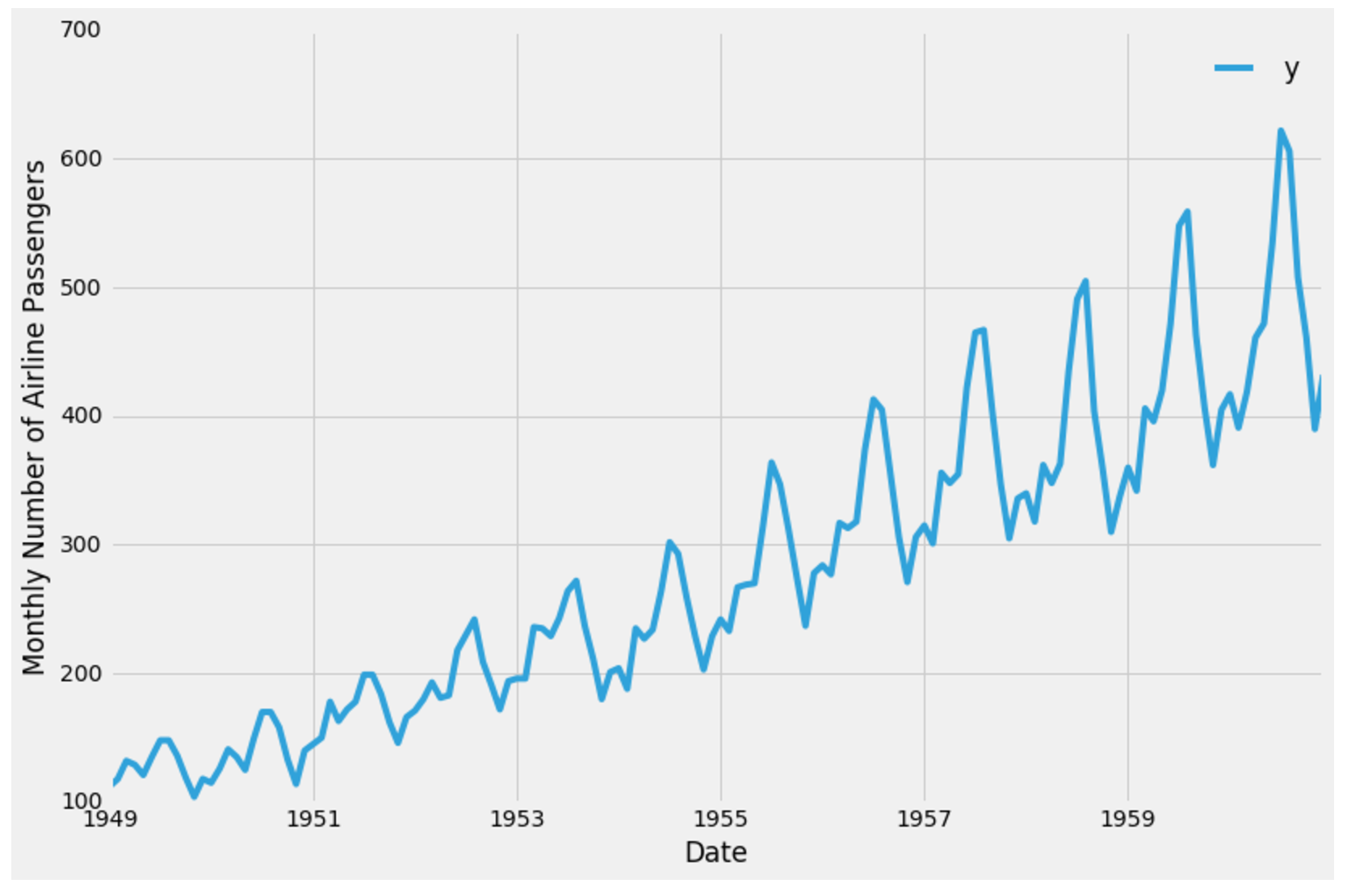
Теперь, когда наши данные подготовлены, мы готовы использовать библиотеку Пророка для составления прогнозов наших временных рядов.
[[шаг-3 -—- прогнозирование-временного-ряда-с-пророком]] == Шаг 3 - Прогнозирование временного ряда с помощью Пророка
В этом разделе мы опишем, как использовать библиотеку Пророка для предсказания будущих значений наших временных рядов. Авторы «Пророка» абстрагировались от многих внутренних сложностей прогнозирования временных рядов и сделали аналитиками и разработчиками более интуитивно понятным работу с данными временных рядов.
Для начала мы должны создать новый объект Пророка. Пророк позволяет нам указать ряд аргументов. Например, мы можем указать желаемый диапазон нашего интервала неопределенности, установив параметрinterval_width.
# set the uncertainty interval to 95% (the Prophet default is 80%)
my_model = Prophet(interval_width=0.95)Теперь, когда наша модель Prophet инициализирована, мы можем вызвать ее методfit с нашим DataFrame в качестве входных данных. Подгонка модели должна занять не более нескольких секунд.
my_model.fit(df)Вы должны получить вывод, похожий на этот:
OutputЧтобы получить прогнозы наших временных рядов, мы должны предоставить Prophet новый DataFrame, содержащий столбецds, содержащий даты, для которых мы хотим получить прогнозы. Для удобства нам не нужно беспокоиться о создании этого DataFrame вручную, поскольку Prophet предоставляет вспомогательную функциюmake_future_dataframe:
future_dates = my_model.make_future_dataframe(periods=36, freq='MS')
future_dates.tail()
В приведенном выше фрагменте кода мы дали указание Пророку создать в будущем 36 меток даты.
При работе с Пророком важно учитывать частоту наших временных рядов. Поскольку мы работаем с ежемесячными данными, мы четко указали желаемую частоту временных меток (в данном случаеMS - это начало месяца). Таким образом,make_future_dataframe сгенерировал для нас 36 ежемесячных отметок времени. Другими словами, мы рассчитываем прогнозировать будущие значения нашего временного ряда на 3 года в будущем.
DataFrame будущих дат затем используется в качестве входных данных для методаpredict нашей подобранной модели.
forecast = my_model.predict(future_dates)
forecast[[ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
Prophet возвращает большой DataFrame со многими интересными столбцами, но мы подразделяем наши выходные данные на столбцы, наиболее релевантные прогнозированию, а именно:
-
ds: отметка даты прогнозируемого значения -
yhat: прогнозируемое значение нашей метрики (в статистикеyhat- это обозначение, традиционно используемое для представления прогнозируемых значений значенияy) -
yhat_lower: нижняя граница наших прогнозов -
yhat_upper: верхняя граница наших прогнозов
Можно ожидать отклонения значений от результатов, представленных выше, так как Пророк использует методы Марковской цепочки Монте-Карло (MCMC) для составления своих прогнозов. MCMC - это случайный процесс, поэтому значения будут немного отличаться каждый раз.
Пророк также предоставляет удобную функцию для быстрого построения результатов наших прогнозов:
my_model.plot(forecast,
uncertainty=True)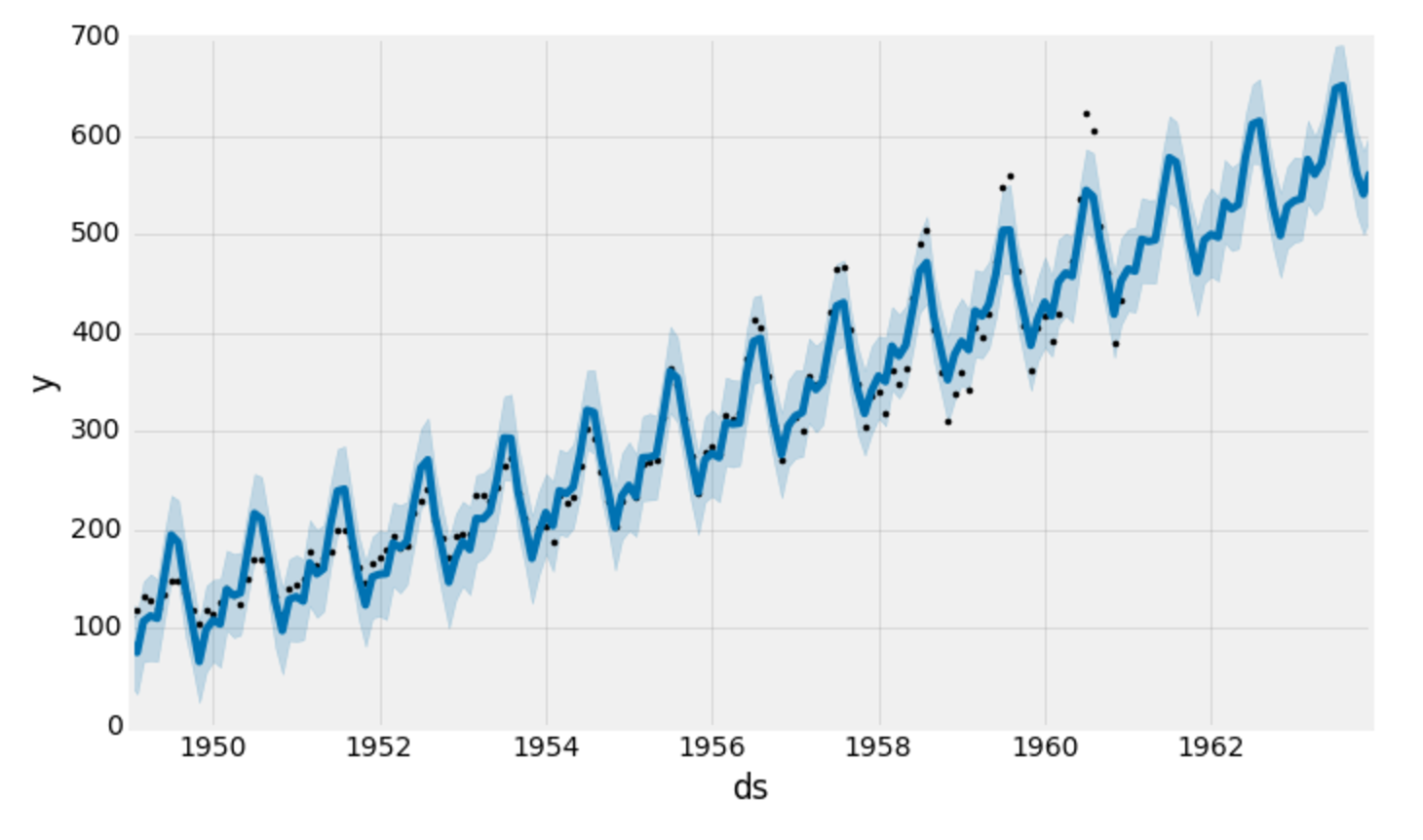
Пророк наносит на график наблюдаемые значения наших временных рядов (черные точки), прогнозируемые значения (синяя линия) и интервалы неопределенности наших прогнозов (синие заштрихованные области).
Еще одна особенно сильная особенность Пророка - его способность возвращать компоненты наших прогнозов. Это может помочь показать, как ежедневные, еженедельные и годовые модели временных рядов влияют на общие прогнозные значения:
my_model.plot_components(forecast)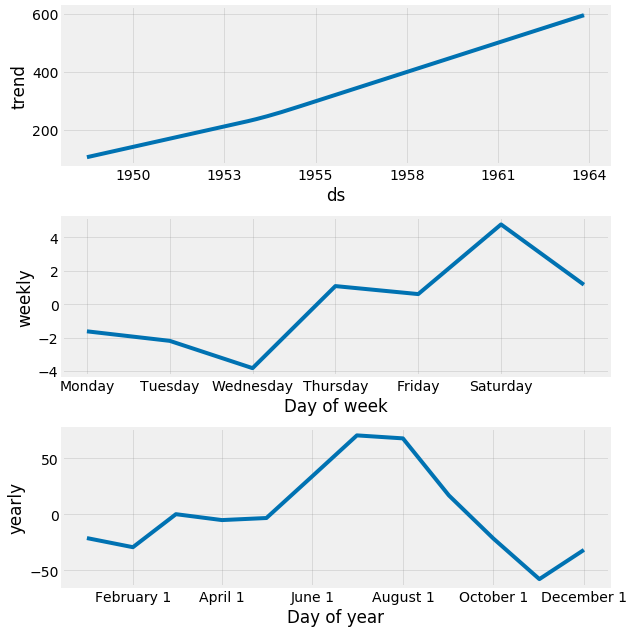
Сюжет выше дает интересные идеи. Первый график показывает, что месячный объем пассажиров авиакомпании со временем линейно увеличивается. На втором графике подчеркивается тот факт, что еженедельный подсчет пассажиров достигает максимума в конце недели и в субботу, а на третьем графике видно, что наибольшее количество трафика происходит в праздничные месяцы июль и август.
Заключение
В этом руководстве мы описали, как использовать библиотеку Prophet для прогнозирования временных рядов в Python. Мы использовали нестандартные параметры, но Prophet позволяет нам указать гораздо больше аргументов. В частности, «Пророк» предоставляет функциональные возможности для представления ваших собственных знаний о временных рядах.
Вот несколько дополнительных вещей, которые вы можете попробовать:
-
Оцените влияние праздников, включив свои предыдущие знания в праздничные месяцы (например, мы знаем, что декабрь является праздничным месяцем). Официальная документация поmodeling holidays будет полезна.
-
Измените диапазон ваших интервалов неопределенности или сделайте прогноз на будущее.
Для большей практики вы можете также попытаться загрузить другой набор данных временных рядов, чтобы получить свои собственные прогнозы. В целом, Prophet предлагает ряд привлекательных функций, в том числе возможность адаптировать модель прогнозирования к требованиям пользователя.