Вступление
Временные ряды дают возможность прогнозировать будущие значения. Основываясь на предыдущих значениях, временные ряды могут использоваться для прогнозирования тенденций в экономике, погоде и планировании производственных мощностей, и многие другие. Специфические свойства данных временных рядов означают, что обычно требуются специальные статистические методы.
В этом уроке мы будем стремиться к созданию надежных прогнозов временных рядов. Мы начнем с представления и обсуждения концепций автокорреляции, стационарности и сезонности, а затем перейдем к применению одного из наиболее часто используемых методов прогнозирования временных рядов, известного как ARIMA.
Один из методов, доступных в Python для моделирования и прогнозирования будущих точек временного ряда, известен какSARIMAX, что означаетSeasonal AutoRegressive Integrated Moving Averages with eXogenous regressors. Здесь мы прежде всего сосредоточимся на компоненте ARIMA, который используется для подгонки данных временного ряда для лучшего понимания и прогнозирования будущих точек во временном ряду.
Предпосылки
В этом руководстве будет рассказано, как выполнять анализ временных рядов на локальном компьютере или на удаленном сервере. Работа с большими наборами данных может потребовать много памяти, поэтому в любом случае компьютеру потребуется не менее2GB of memory для выполнения некоторых вычислений в этом руководстве.
Чтобы максимально использовать этот урок, может быть полезно некоторое знакомство с временными рядами и статистикой.
В этом руководстве мы будем использоватьJupyter Notebook для работы с данными. Если у вас его еще нет, следуйте нашимtutorial to install and set up Jupyter Notebook for Python 3.
[[step-1 -—- install-packages]] == Шаг 1. Установка пакетов
Чтобы настроить нашу среду для прогнозирования временных рядов, давайте сначала перейдем к нашимlocal programming environment илиserver-based programming environment:
cd environments. my_env/bin/activateОтсюда давайте создадим новый каталог для нашего проекта. Мы назовем егоARIMA, а затем перейдем в каталог. Если вы назвали проект другим именем, не забудьте заменитьARIMA своим именем на протяжении всего руководства.
mkdir ARIMA
cd ARIMAВ этом руководстве потребуются библиотекиwarnings,itertools,pandas,numpy,matplotlib иstatsmodels. Библиотекиwarnings иitertools входят в стандартный набор библиотек Python, поэтому устанавливать их не нужно.
Как и в случае с другими пакетами Python, мы можем установить эти требования с помощьюpip.
Теперь мы можем установитьpandas,statsmodels и пакет построения графиков данныхmatplotlib. Их зависимости также будут установлены:
pip install pandas numpy statsmodels matplotlibНа данный момент мы настроены на работу с установленными пакетами.
[[step-2 -—- importing-packages-and-loading-data]] == Шаг 2. Импорт пакетов и загрузка данных
Чтобы начать работать с нашими данными, мы запустим Jupyter Notebook:
jupyter notebookЧтобы создать новый файл записной книжки, выберитеNew>Python 3 в правом верхнем раскрывающемся меню:
Это откроет блокнот.
Лучше всего начать сimporting the libraries, которое вам понадобится в верхней части записной книжки:
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')Мы также определили для наших графиковmatplotlib styleот пятидесятых восьмидесяти.
Мы будем работать с набором данных, который называется «Атмосферный CO2 из непрерывных проб воздуха в обсерватории Мауна-Лоа, Гавайи, США», который собирал образцы CO2 с марта 1958 года по декабрь 2001 года. Мы можем внести эти данные следующим образом:
data = sm.datasets.co2.load_pandas()
y = data.dataДавайте немного обработаем наши данные, прежде чем двигаться дальше. С еженедельными данными может быть сложно работать, так как это более короткое время, поэтому давайте вместо этого будем использовать среднемесячные значения. Мы сделаем преобразование с помощью функцииresample. Для простоты мы также можем использоватьfillna() function, чтобы убедиться, что у нас нет пропущенных значений в наших временных рядах.
# The 'MS' string groups the data in buckets by start of the month
y = y['co2'].resample('MS').mean()
# The term bfill means that we use the value before filling in missing values
y = y.fillna(y.bfill())
print(y)Outputco2
1958-03-01 316.100000
1958-04-01 317.200000
1958-05-01 317.433333
...
2001-11-01 369.375000
2001-12-01 371.020000Давайте рассмотрим этот временной ряд e как визуализацию данных:
y.plot(figsize=(15, 6))
plt.show()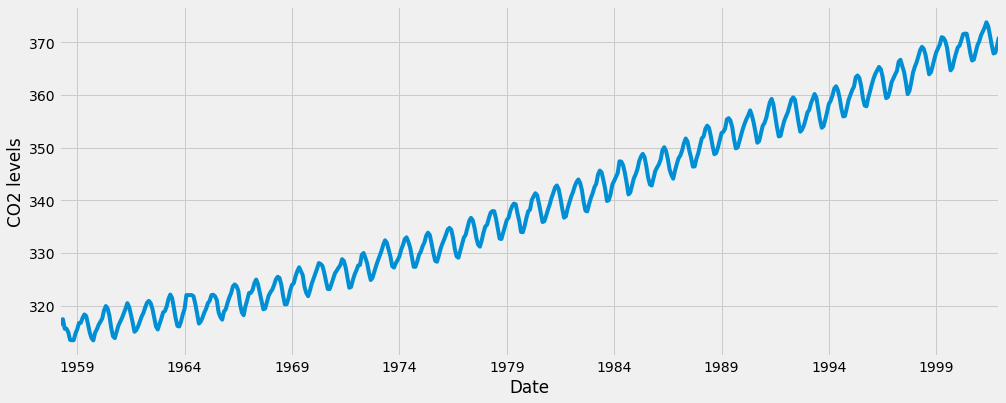
Некоторые различимые шаблоны появляются, когда мы наносим данные. Временной ряд имеет явную модель сезонности, а также общую тенденцию к увеличению.
Чтобы узнать больше о предварительной обработке временных рядов, см. «Https://www.digitalocean.com/community/tutorials/a-guide-to-time-series-visualization-with-python-3[A Guide to Time Серия «Визуализация с Python 3]», где описанные выше шаги описаны гораздо более подробно.
Теперь, когда мы преобразовали и изучили наши данные, давайте перейдем к прогнозированию временных рядов с помощью ARIMA.
[[step-3 -—- the-arima-time-series-model]] == Шаг 3 - Модель временных рядов ARIMA
Один из наиболее распространенных методов, используемых при прогнозировании временных рядов, известен как модель ARIMA, которая обозначает среднюю величинуAutoregRessionsIntegratedMovingA. ARIMA - это модель, которая может быть адаптирована к данным временного ряда, чтобы лучше понять или предсказать будущие точки в ряду.
Есть три различных целых числа (p,d,q), которые используются для параметризации моделей ARIMA. По этой причине модели ARIMA обозначаются символомARIMA(p, d, q). Вместе эти три параметра учитывают сезонность, тренд и шум в наборах данных:
-
p- это часть моделиauto-regressive. Это позволяет нам включить влияние прошлых ценностей в нашу модель. Интуитивно, это было бы похоже на заявление о том, что завтра может быть тепло, если в последние 3 дня было тепло. -
d- это часть моделиintegrated. Это включает в себя термины в модели, которые включают в себя количество различий (т.е. количество прошлых моментов времени, которые необходимо вычесть из текущего значения) для применения к временному ряду. Интуитивно понятно, что это было бы похоже на утверждение, что завтра будет та же температура, если разница в температуре за последние три дня была очень мала. -
q- это часть моделиmoving average. Это позволяет нам установить ошибку нашей модели как линейную комбинацию значений ошибок, наблюдаемых в предыдущие моменты времени в прошлом.
При работе с сезонными эффектами мы используем ARIMAseasonal, который обозначается какARIMA(p,d,q)(P,D,Q)s. Здесь(p, d, q) - это несезонные параметры, описанные выше, а(P, D, Q) следуют тому же определению, но применяются к сезонной составляющей временного ряда. Членs - это периодичность временного ряда (4 для квартальных периодов,12 для годовых периодов и т. Д.).
Сезонный метод ARIMA может показаться пугающим из-за множества параметров настройки. В следующем разделе мы опишем, как автоматизировать процесс определения оптимального набора параметров для сезонной модели временных рядов ARIMA.
[[step-4 -—- parameter-selection-for-the-arima-time-series-model]] == Шаг 4 - Выбор параметра для модели временных рядов ARIMA
При поиске соответствия данных временных рядов сезонной модели ARIMA наша первая цель - найти значенияARIMA(p,d,q)(P,D,Q)s, которые оптимизируют интересующую метрику. Для достижения этой цели существует множество руководств и рекомендаций, однако правильная параметризация моделей ARIMA может быть кропотливым ручным процессом, требующим специальных знаний и времени. Другие языки статистического программирования, такие какR, предоставляютautomated ways to solve this issue, но их еще предстоит перенести на Python. В этом разделе мы решим эту проблему, написав код Python для программного выбора оптимальных значений параметров для нашей модели временных рядовARIMA(p,d,q)(P,D,Q)s.
Мы будем использовать «поиск по сетке», чтобы итеративно исследовать различные комбинации параметров. Для каждой комбинации параметров мы подбираем новую сезонную модель ARIMA с функциейSARIMAX() из модуляstatsmodels и оцениваем ее общее качество. После того, как мы изучим всю совокупность параметров, наш оптимальный набор параметров станет тем, который даст наилучшую производительность по нашим интересующим критериям. Давайте начнем с генерации различных комбинаций параметров, которые мы хотим оценить:
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
# Generate all different combinations of seasonal p, q and q triplets
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))OutputExamples of parameter combinations for Seasonal ARIMA...
SARIMAX: (0, 0, 1) x (0, 0, 1, 12)
SARIMAX: (0, 0, 1) x (0, 1, 0, 12)
SARIMAX: (0, 1, 0) x (0, 1, 1, 12)
SARIMAX: (0, 1, 0) x (1, 0, 0, 12)Теперь мы можем использовать тройки параметров, определенных выше, чтобы автоматизировать процесс обучения и оценки моделей ARIMA для различных комбинаций. В статистике и машинном обучении этот процесс известен как поиск по сетке (или оптимизация гиперпараметров) для выбора модели.
При оценке и сравнении статистических моделей, снабженных различными параметрами, каждая из них может быть ранжирована друг против друга на основе того, насколько хорошо она соответствует данным или ее способности точно прогнозировать будущие точки данных. Мы будем использовать значениеAIC (информационный критерий Акаике), которое удобно возвращается с моделями ARIMA, подобранными с использованиемstatsmodels. AIC измеряет, насколько хорошо модель соответствует данным, принимая во внимание общую сложность модели. Модель, которая очень хорошо соответствует данным при использовании большого количества функций, получит более высокий балл AIC, чем модель, которая использует меньше функций для достижения того же качества соответствия. Следовательно, мы заинтересованы в поиске модели, которая дает наименьшее значениеAIC.
Приведенный ниже фрагмент кода выполняет итерацию по комбинациям параметров и использует функциюSARIMAX изstatsmodels для соответствия соответствующей сезонной модели ARIMA. Здесь аргументorder указывает параметры(p, d, q), а аргументseasonal_order указывает сезонный компонент(P, D, Q, S) модели Seasonal ARIMA. После подбора каждого баллаSARIMAX()+`model, the code prints out its respective `+AIC.
warnings.filterwarnings("ignore") # specify to ignore warning messages
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continueПоскольку некоторые комбинации параметров могут привести к ошибочной числовой спецификации, мы явно отключили предупреждающие сообщения, чтобы избежать перегрузки предупреждающих сообщений. Эти неправильные спецификации могут также привести к ошибкам и вызвать исключение, поэтому мы обязательно перехватим эти исключения и проигнорируем комбинации параметров, которые вызывают эти проблемы.
Код выше должен дать следующие результаты, это может занять некоторое время:
OutputSARIMAX(0, 0, 0)x(0, 0, 1, 12) - AIC:6787.3436240402125
SARIMAX(0, 0, 0)x(0, 1, 1, 12) - AIC:1596.711172764114
SARIMAX(0, 0, 0)x(1, 0, 0, 12) - AIC:1058.9388921320026
SARIMAX(0, 0, 0)x(1, 0, 1, 12) - AIC:1056.2878315690562
SARIMAX(0, 0, 0)x(1, 1, 0, 12) - AIC:1361.6578978064144
SARIMAX(0, 0, 0)x(1, 1, 1, 12) - AIC:1044.7647912940095
...
...
...
SARIMAX(1, 1, 1)x(1, 0, 0, 12) - AIC:576.8647112294245
SARIMAX(1, 1, 1)x(1, 0, 1, 12) - AIC:327.9049123596742
SARIMAX(1, 1, 1)x(1, 1, 0, 12) - AIC:444.12436865161305
SARIMAX(1, 1, 1)x(1, 1, 1, 12) - AIC:277.7801413828764Вывод нашего кода предполагает, чтоSARIMAX(1, 1, 1)x(1, 1, 1, 12) дает наименьшее значениеAIC, равное 277,78. Поэтому мы должны считать это оптимальным вариантом из всех моделей, которые мы рассмотрели.
[[step-5 -—- fit-an-arima-time-series-model]] == Шаг 5. Подгонка модели временных рядов ARIMA
Используя поиск по сетке, мы определили набор параметров, который дает наилучшую модель соответствия нашим данным временных рядов. Мы можем продолжить анализ этой конкретной модели более подробно.
Мы начнем с добавления оптимальных значений параметров в новую модельSARIMAX:
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])Output==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3182 0.092 3.443 0.001 0.137 0.499
ma.L1 -0.6255 0.077 -8.165 0.000 -0.776 -0.475
ar.S.L12 0.0010 0.001 1.732 0.083 -0.000 0.002
ma.S.L12 -0.8769 0.026 -33.811 0.000 -0.928 -0.826
sigma2 0.0972 0.004 22.634 0.000 0.089 0.106
==============================================================================Атрибутsummary, который является результатом выводаSARIMAX, возвращает значительный объем информации, но мы сосредоточим наше внимание на таблице коэффициентов. Столбецcoef показывает вес (т.е. важность) каждой функции и то, как каждая из них влияет на временной ряд. СтолбецP>|z| информирует нас о значимости каждого веса функции. Здесь каждый вес имеет значение p, меньшее или близкое к0.05, поэтому разумно сохранить их все в нашей модели.
При подборе сезонных моделей ARIMA (и любых других моделей по этому вопросу) важно проводить диагностику модели, чтобы убедиться, что ни одно из предположений, сделанных моделью, не было нарушено. Объектplot_diagnostics позволяет нам быстро генерировать диагностику модели и исследовать любое необычное поведение.
results.plot_diagnostics(figsize=(15, 12))
plt.show()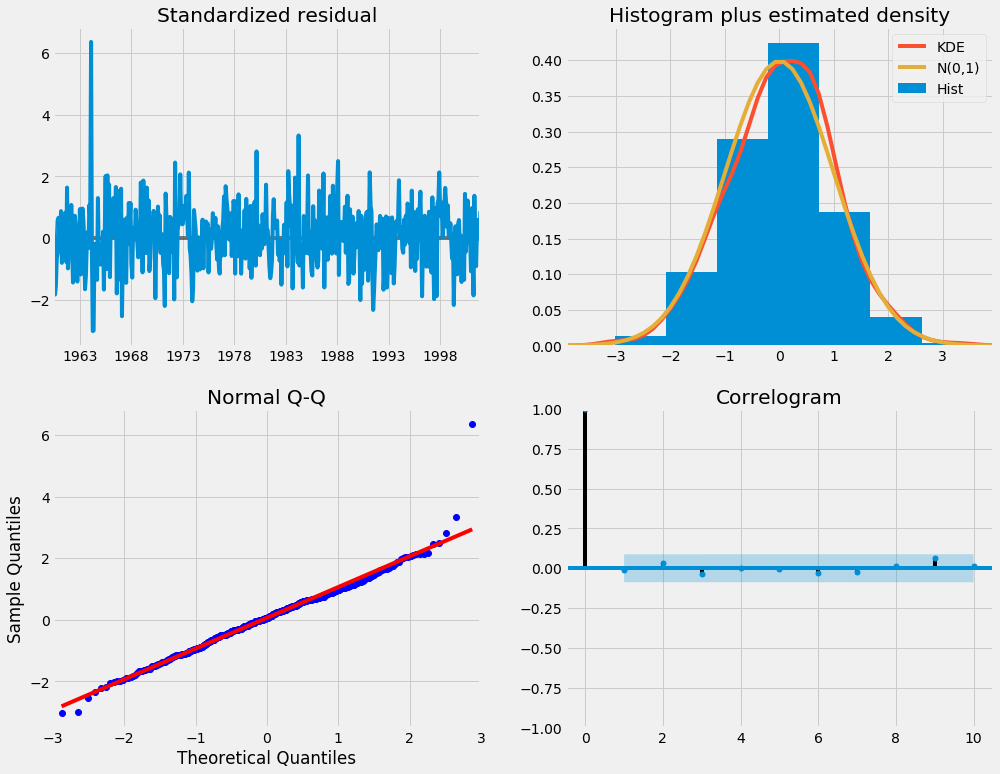
Наша главная задача - обеспечить, чтобы остатки нашей модели были некоррелированными и нормально распределенными с нулевым средним. Если сезонная модель ARIMA не удовлетворяет этим свойствам, это является хорошим показателем того, что ее можно еще улучшить.
В этом случае наша диагностика модели предполагает, что остатки модели обычно распределяются на основе следующего:
-
На верхнем правом графике мы видим, что красная линия
KDEблизко следует за линиейN(0,1)(гдеN(0,1)) - это стандартное обозначение для нормального распределения со средним0и стандартное отклонение1). Это хороший признак того, что остатки обычно распределяются. -
qq-plot в нижнем левом углу показывает, что упорядоченное распределение остатков (синие точки) следует линейному тренду выборок, взятых из стандартного нормального распределения с
N(0, 1). Опять же, это убедительный признак того, что остатки обычно распределяются. -
Остатки во времени (верхний левый график) не проявляют явной сезонности и кажутся белым шумом. Это подтверждается автокорреляцией (т.е. коррелограмма) график в правом нижнем углу, который показывает, что остатки временного ряда имеют низкую корреляцию с запаздывающими версиями самого себя.
Эти наблюдения позволяют нам сделать вывод, что наша модель обеспечивает удовлетворительное соответствие, которое может помочь нам понять данные нашего временного ряда и прогнозировать будущие значения.
Несмотря на то, что у нас удовлетворительная посадка, некоторые параметры нашей сезонной модели ARIMA можно изменить, чтобы улучшить ее посадку. Например, наш поиск по сетке рассматривал только ограниченный набор комбинаций параметров, поэтому мы можем найти лучшие модели, если расширим поиск по сетке.
[[step-6 -—- validating-procasts]] == Шаг 6. Проверка прогнозов
Мы получили модель для нашего временного ряда, которую теперь можно использовать для составления прогнозов. Мы начнем со сравнения прогнозируемых значений с реальными значениями временного ряда, что поможет нам понять точность наших прогнозов. Атрибутыget_prediction() иconf_int() позволяют нам получать значения и соответствующие доверительные интервалы для прогнозов временных рядов.
pred = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=False)
pred_ci = pred.conf_int()Код выше требует, чтобы прогнозы начались в январе 1998 года.
Аргументdynamic=False гарантирует, что мы составляем прогнозы на один шаг вперед, что означает, что прогнозы в каждой точке создаются с использованием полной истории до этого момента.
Мы можем построить реальные и прогнозируемые значения временных рядов CO2, чтобы оценить, насколько хорошо мы справились. Обратите внимание на то, как мы увеличивали конец временного ряда, разрезая индекс даты.
ax = y['1990':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()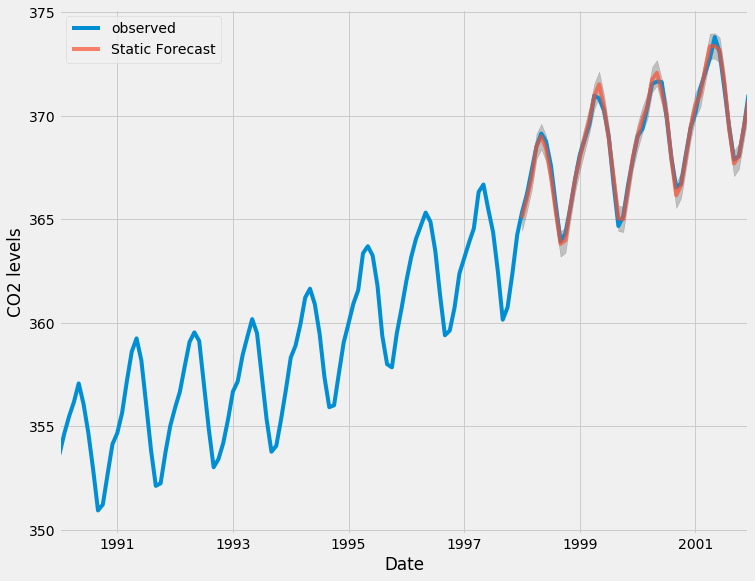
В целом, наши прогнозы очень хорошо соответствуют истинным значениям, показывая общую тенденцию роста.
Также полезно количественно оценить точность наших прогнозов. Мы будем использовать MSE (средняя квадратическая ошибка), которая суммирует среднюю ошибку наших прогнозов. Для каждого прогнозируемого значения мы вычисляем его расстояние до истинного значения и возводим в квадрат результат. Результаты должны быть возведены в квадрат, чтобы положительные / отрицательные различия не компенсировали друг друга, когда мы вычисляем общее среднее значение.
y_forecasted = pred.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))OutputThe Mean Squared Error of our forecasts is 0.07MSE наших прогнозов на один шаг вперед дает значение0.07, что очень мало, так как оно близко к 0. MSE 0 будет означать, что оценщик прогнозирует наблюдения параметра с идеальной точностью, что было бы идеальным сценарием, но это, как правило, невозможно.
Однако лучшее представление о нашей истинной предсказательной силе может быть получено с помощью динамических прогнозов. В этом случае мы используем информацию только из временного ряда до определенной точки, а после этого прогнозы генерируются с использованием значений из предыдущих прогнозируемых моментов времени.
В приведенном ниже фрагменте кода мы указываем начать вычисление динамических прогнозов и доверительных интервалов с января 1998 года.
pred_dynamic = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()Нанося на график наблюдаемые и прогнозируемые значения временного ряда, мы видим, что общие прогнозы точны даже при использовании динамических прогнозов. Все прогнозируемые значения (красная линия) очень близки к истинной точке (синяя линия) и находятся в пределах доверительных интервалов нашего прогноза.
ax = y['1990':].plot(label='observed', figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime('1998-01-01'), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()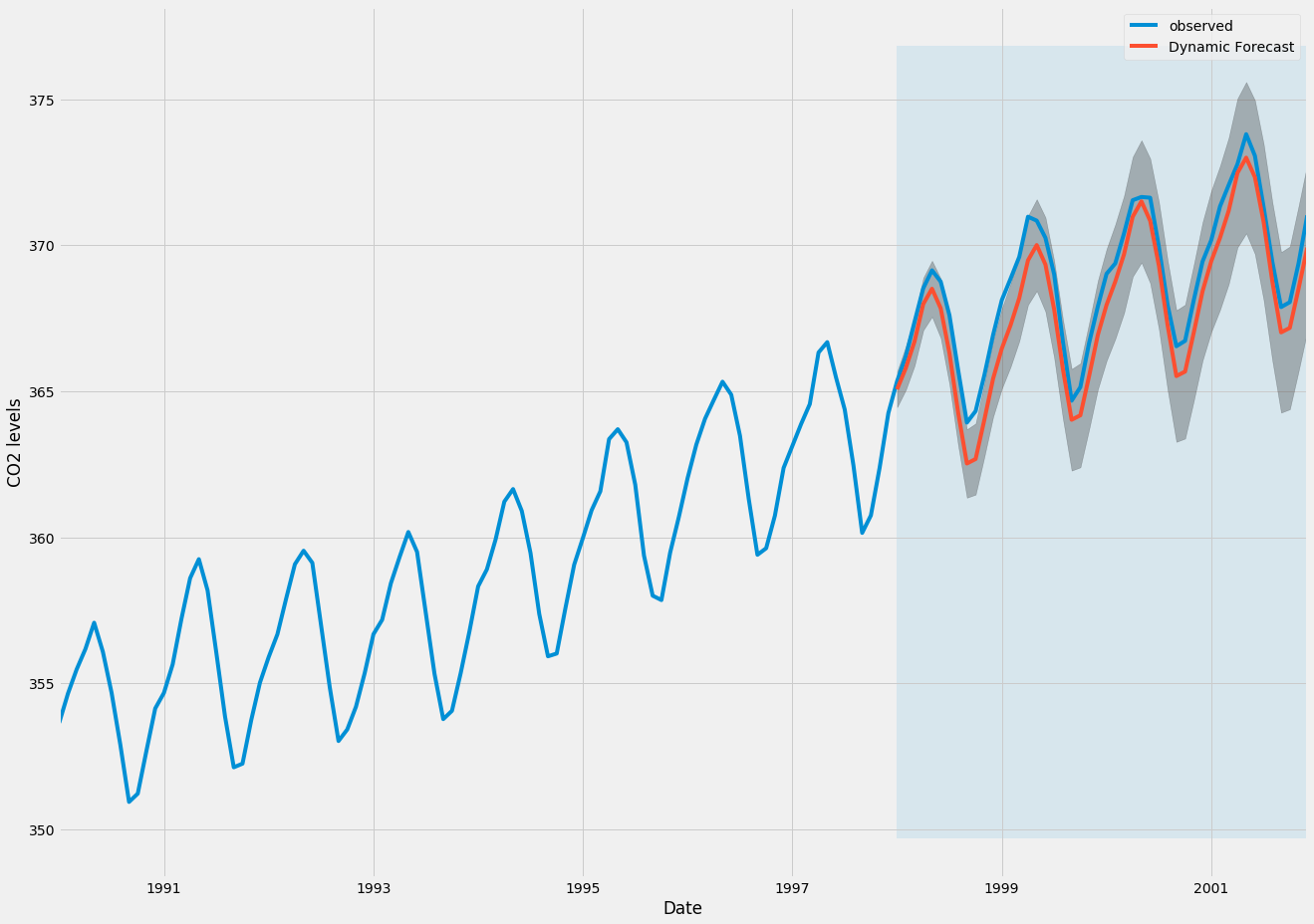
Еще раз, мы количественно оцениваем прогнозную эффективность наших прогнозов, вычисляя MSE
# Extract the predicted and true values of our time series
y_forecasted = pred_dynamic.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))OutputThe Mean Squared Error of our forecasts is 1.01Прогнозируемые значения, полученные из динамических прогнозов, дают MSE 1,01. Это немного выше, чем на шаг вперед, что и следовало ожидать, учитывая, что мы полагаемся на меньшее количество исторических данных из временного ряда.
Оба шага вперед и динамические прогнозы подтверждают, что эта модель временного ряда является действительной. Тем не менее, большой интерес к прогнозированию временных рядов вызывает способность прогнозировать будущие значения заранее во времени.
[[step-7 -—- создание-и-визуализация-прогнозов]] == Шаг 7 - Создание и визуализация прогнозов
На последнем этапе этого руководства мы опишем, как использовать нашу сезонную модель временных рядов ARIMA для прогнозирования будущих значений. Атрибутget_forecast() нашего объекта временного ряда может вычислять прогнозируемые значения на указанное количество шагов вперед.
# Get forecast 500 steps ahead in future
pred_uc = results.get_forecast(steps=500)
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()Мы можем использовать выходные данные этого кода для построения временного ряда и прогнозов его будущих значений.
ax = y.plot(label='observed', figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()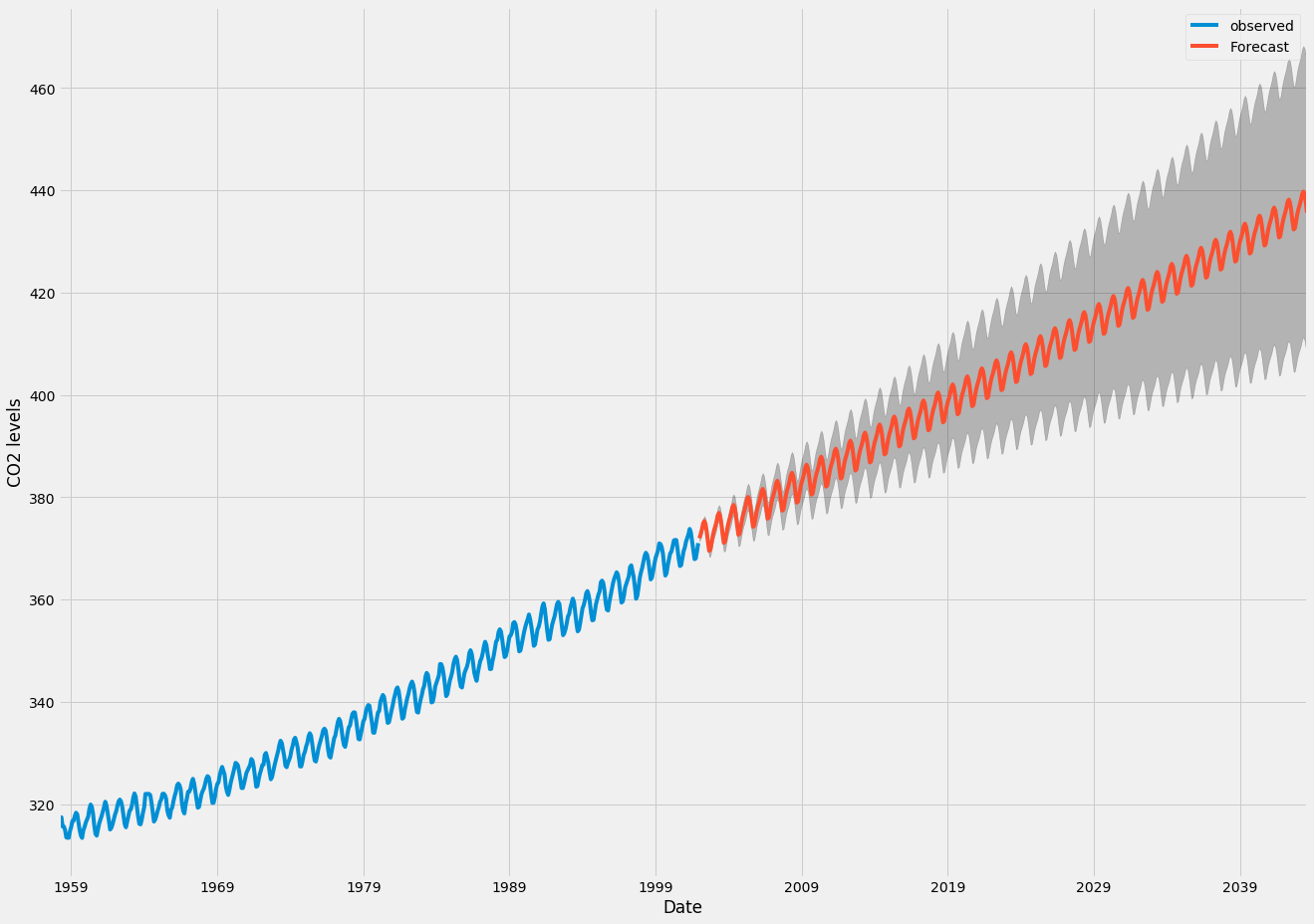
Сгенерированные нами прогнозы и связанный с ними доверительный интервал теперь можно использовать для дальнейшего понимания временных рядов и прогнозирования того, что ожидать. Наши прогнозы показывают, что временные ряды, как ожидается, будут продолжать расти устойчивыми темпами.
По мере того, как мы прогнозируем дальнейшее будущее, для нас естественно стать менее уверенными в наших ценностях. Это отражается в доверительных интервалах, генерируемых нашей моделью, которые увеличиваются по мере того, как мы продвигаемся дальше в будущее.
Заключение
В этом руководстве мы описали, как реализовать сезонную модель ARIMA в Python. Мы широко использовали библиотекиpandas иstatsmodels и показали, как запускать диагностику модели, а также как составлять прогнозы временных рядов CO2.
Вот еще несколько вещей, которые вы можете попробовать:
-
Измените дату начала ваших динамических прогнозов, чтобы увидеть, как это влияет на общее качество ваших прогнозов.
-
Попробуйте больше комбинаций параметров, чтобы увидеть, можете ли вы улучшить качество своей модели.
-
Выберите другую метрику, чтобы выбрать лучшую модель. Например, мы использовали показатель
AIC, чтобы найти лучшую модель, но вместо этого вы можете попытаться оптимизировать среднеквадратическую ошибку вне выборки.
Для большей практики вы можете также попытаться загрузить другой набор данных временных рядов, чтобы получить свои собственные прогнозы.