Introdução ao HikariCP
1. Visão geral
Neste artigo introdutório, aprenderemos sobre o projeto de pool de conexãoHikariCP JDBC. This is a very lightweight (at roughly 130Kb) and lightning fast JDBC connection pooling framework desenvolvido porBrett Wooldridge por volta de 2012.
2. Introdução
Existem vários resultados de benchmark disponíveis para comparar o desempenho do HikariCP com outras estruturas de pool de conexão, comoc3p0,dbcp2,tomcat evibur. Por exemplo, a equipe do HikariCP publicou abaixo dos benchmarks (resultados originais disponíveishere):
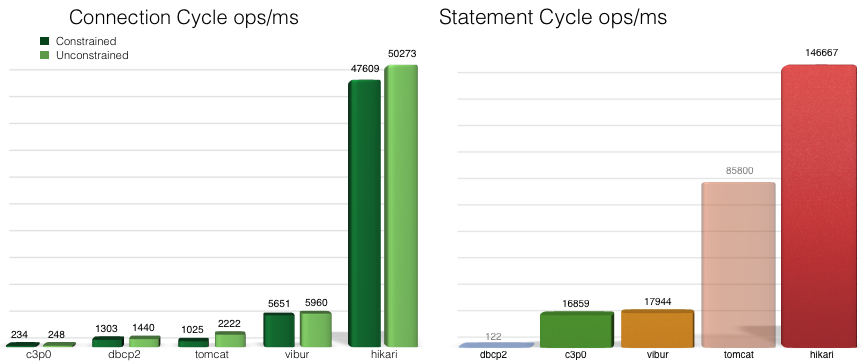
A estrutura é tão rápida porque as seguintes técnicas foram aplicadas:
-
Bytecode-level engineering – alguma engenharia extrema de nível de bytecode (incluindo codificação nativa de nível de montagem) foi feita
-
Micro-optimizations – embora mal mensuráveis, essas otimizações combinadas aumentam o desempenho geral
-
Intelligent use of the Collections framework – oArrayList<Statement> foi substituído por uma classe personalizadaFastList que elimina a verificação de alcance e realiza varreduras de remoção da cauda à cabeça
3. Dependência do Maven
Vamos construir um aplicativo de amostra para destacar seu uso. O HikariCP vem com o suporte para todas as principais versões da JVM. Cada versão requer sua dependência; para Java 9, temos:
com.zaxxer
HikariCP-java9ea
2.6.1
E para Java 8:
com.zaxxer
HikariCP
2.6.1
Versões antigas do JDK, como 6 e 7, também são suportadas. As versões apropriadas podem ser encontradashereehere. Além disso, podemos verificar as versões mais recentes noCentral Maven Repository.
4. Uso
Vamos agora criar um aplicativo de demonstração. Observe que precisamos incluir uma dependência de classe de driver JDBC adequada empom.xml. Se nenhuma dependência for fornecida, o aplicativo lançará umClassNotFoundException.
4.1. Criando umDataSource
UsaremosDataSource do HikariCP para criar uma única instância de uma fonte de dados para nosso aplicativo:
public class DataSource {
private static HikariConfig config = new HikariConfig();
private static HikariDataSource ds;
static {
config.setJdbcUrl( "jdbc_url" );
config.setUsername( "database_username" );
config.setPassword( "database_password" );
config.addDataSourceProperty( "cachePrepStmts" , "true" );
config.addDataSourceProperty( "prepStmtCacheSize" , "250" );
config.addDataSourceProperty( "prepStmtCacheSqlLimit" , "2048" );
ds = new HikariDataSource( config );
}
private DataSource() {}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
}O ponto a notar aqui é a inicialização no blocostatic.
HikariConfig é a classe de configuração usada para inicializar uma fonte de dados. Ele vem com quatro parâmetros bem conhecidos e obrigatóriosusername,password,jdbcUrl,dataSourceClassName.
DejdbcUrledataSourceClassName, qualquer um deve ser usado de cada vez. No entanto, ao usar essa propriedade com drivers mais antigos, talvez seja necessário definir as duas propriedades.
Além dessas propriedades, existem várias outras propriedades disponíveis que nem todas podem ser oferecidas por outras estruturas de pool:
-
autoCommit
-
connectionTimeout
-
idleTimeout
-
maxLifetime
-
connectionTestQuery
-
connectionInitSql
-
validationTimeout
-
maximumPoolSize
-
poolName
-
allowPoolSuspension
-
somente leitura
-
transactionIsolation
-
leaDetectionThreshold
O HikariCP se destaca por causa dessas propriedades do banco de dados. É avançado o suficiente para até mesmo detectar vazamentos de conexão por si só!
Uma descrição detalhada dessas propriedades pode ser encontradahere.
Também podemos inicializarHikariConfig com um arquivo de propriedades colocado no diretórioresources:
private static HikariConfig config = new HikariConfig(
"datasource.properties" );O arquivo de propriedades deve se parecer com isso:
dataSourceClassName= //TBD
dataSource.user= //TBD
//other properties name should start with dataSource as shown abovePodemos usar a configuração baseada emjava.util.Properties- também:
Properties props = new Properties();
props.setProperty( "dataSourceClassName" , //TBD );
props.setProperty( "dataSource.user" , //TBD );
//setter for other required properties
private static HikariConfig config = new HikariConfig( props );Como alternativa, podemos inicializar uma fonte de dados diretamente:
ds.setJdbcUrl( //TBD );
ds.setUsername( //TBD );
ds.setPassword( //TBD );4.2. Usando uma fonte de dados
Agora que definimos a fonte de dados, podemos usá-la para obter uma conexão do conjunto de conexões configurado e executar ações relacionadas ao JDBC.
Suponha que temos duas tabelas chamadasdepteemp para simular um caso de uso funcionário-departamento. Escreveremos uma classe para buscar esses detalhes no banco de dados usando o HikariCP.
Abaixo, listamos as instruções SQL necessárias para criar os dados de amostra:
create table dept(
deptno numeric,
dname varchar(14),
loc varchar(13),
constraint pk_dept primary key ( deptno )
);
create table emp(
empno numeric,
ename varchar(10),
job varchar(9),
mgr numeric,
hiredate date,
sal numeric,
comm numeric,
deptno numeric,
constraint pk_emp primary key ( empno ),
constraint fk_deptno foreign key ( deptno ) references dept ( deptno )
);
insert into dept values( 10, 'ACCOUNTING', 'NEW YORK' );
insert into dept values( 20, 'RESEARCH', 'DALLAS' );
insert into dept values( 30, 'SALES', 'CHICAGO' );
insert into dept values( 40, 'OPERATIONS', 'BOSTON' );
insert into emp values(
7839, 'KING', 'PRESIDENT', null,
to_date( '17-11-1981' , 'dd-mm-yyyy' ),
7698, null, 10
);
insert into emp values(
7698, 'BLAKE', 'MANAGER', 7839,
to_date( '1-5-1981' , 'dd-mm-yyyy' ),
7782, null, 20
);
insert into emp values(
7782, 'CLARK', 'MANAGER', 7839,
to_date( '9-6-1981' , 'dd-mm-yyyy' ),
7566, null, 30
);
insert into emp values(
7566, 'JONES', 'MANAGER', 7839,
to_date( '2-4-1981' , 'dd-mm-yyyy' ),
7839, null, 40
);Observe que se usarmos algum banco de dados na memória, como H2, precisamos carregar automaticamente o script do banco de dados antes de executar o código real para buscar os dados. Felizmente, H2 vem com um parâmetroINIT que pode carregar o script do banco de dados do classpath em tempo de execução. A URL JDBC deve ter a seguinte aparência:
jdbc:h2:mem:test;DB_CLOSE_DELAY=-1;INIT=runscript from 'classpath:/db.sql'Precisamos criar um método para buscar esses dados do banco de dados:
public static List fetchData() throws SQLException {
String SQL_QUERY = "select * from emp";
List employees = null;
try (Connection con = DataSource.getConnection();
PreparedStatement pst = con.prepareStatement( SQL_QUERY );
ResultSet rs = pst.executeQuery();) {
employees = new ArrayList<>();
Employee employee;
while ( rs.next() ) {
employee = new Employee();
employee.setEmpNo( rs.getInt( "empno" ) );
employee.setEname( rs.getString( "ename" ) );
employee.setJob( rs.getString( "job" ) );
employee.setMgr( rs.getInt( "mgr" ) );
employee.setHiredate( rs.getDate( "hiredate" ) );
employee.setSal( rs.getInt( "sal" ) );
employee.setComm( rs.getInt( "comm" ) );
employee.setDeptno( rs.getInt( "deptno" ) );
employees.add( employee );
}
}
return employees;
} Agora, podemos precisar criar um método JUnit para testá-lo. Como sabemos o número de linhas na tabelaemp, podemos esperar que o tamanho da lista retornada seja igual ao número de linhas:
@Test
public void givenConnection_thenFetchDbData() throws SQLException {
HikariCPDemo.fetchData();
assertEquals( 4, employees.size() );
}5. Conclusão
Neste tutorial rápido, aprendemos sobre os benefícios do uso do HikariCP e sua configuração.
Como sempre, o código-fonte completo está disponívelover on GitHub.