前書き
重要なシステムに対応するために設計された信頼性の高いパフォーマンスの高いインフラストラクチャに対する需要が高まっているため、スケーラビリティと高可用性という用語はこれほど普及することはありません。 システム負荷の増加に対処することは一般的な懸念事項ですが、ダウンタイムを短縮し、単一障害点を排除することも同様に重要です。 高可用性は、これらの後者の考慮事項に対処する大規模なインフラストラクチャ設計の品質です。
このガイドでは、まさに高可用性の意味と、インフラストラクチャの信頼性を向上させる方法について説明します。
高可用性とは
コンピューティングでは、可用性という用語は、サービスが利用可能な期間、およびユーザーが行った要求にシステムが応答するのに必要な時間を表すために使用されます。 高可用性とは、システムまたはコンポーネントの品質であり、一定期間の高レベルの運用パフォーマンスを保証します。
可用性の測定
可用性は、特定のシステムまたはコンポーネントから特定の期間に予想される稼働時間を示すパーセンテージとして表されることが多く、100%の値はシステムに障害が発生しないことを示します。 たとえば、1年間で99%の可用性を保証するシステムでは、最大3.65日のダウンタイム(1%)が発生する可能性があります。
これらの値は、予定されたメンテナンス期間と予定外のメンテナンス期間の両方、および考えられるシステム障害からの回復時間など、いくつかの要因に基づいて計算されます。
高可用性の仕組み
高可用性は、インフラストラクチャの障害対応メカニズムとして機能します。 動作方法は概念的には非常に単純ですが、通常は特殊なソフトウェアと構成が必要です。
高可用性はいつ重要ですか?
堅牢な本番システムをセットアップする場合、多くの場合、ダウンタイムとサービスの中断を最小限に抑えることが最優先事項です。 システムとソフトウェアの信頼性に関係なく、アプリケーションやサーバーをダウンさせる可能性のある問題が発生する可能性があります。
インフラストラクチャに高可用性を実装することは、これらの影響を軽減するための有用な戦略です。イベントの種類。 高可用性システムは、サーバーまたはコンポーネントの障害から自動的に回復できます。
システムを高可用性にする理由
高可用性の目標の1つは、インフラストラクチャの単一障害点を排除することです。 単一障害点は、利用できなくなった場合にサービスの中断を引き起こすテクノロジースタックのコンポーネントです。 そのため、冗長性を持たないアプリケーションの適切な機能に必要なコンポーネントは、単一障害点と見なされます。
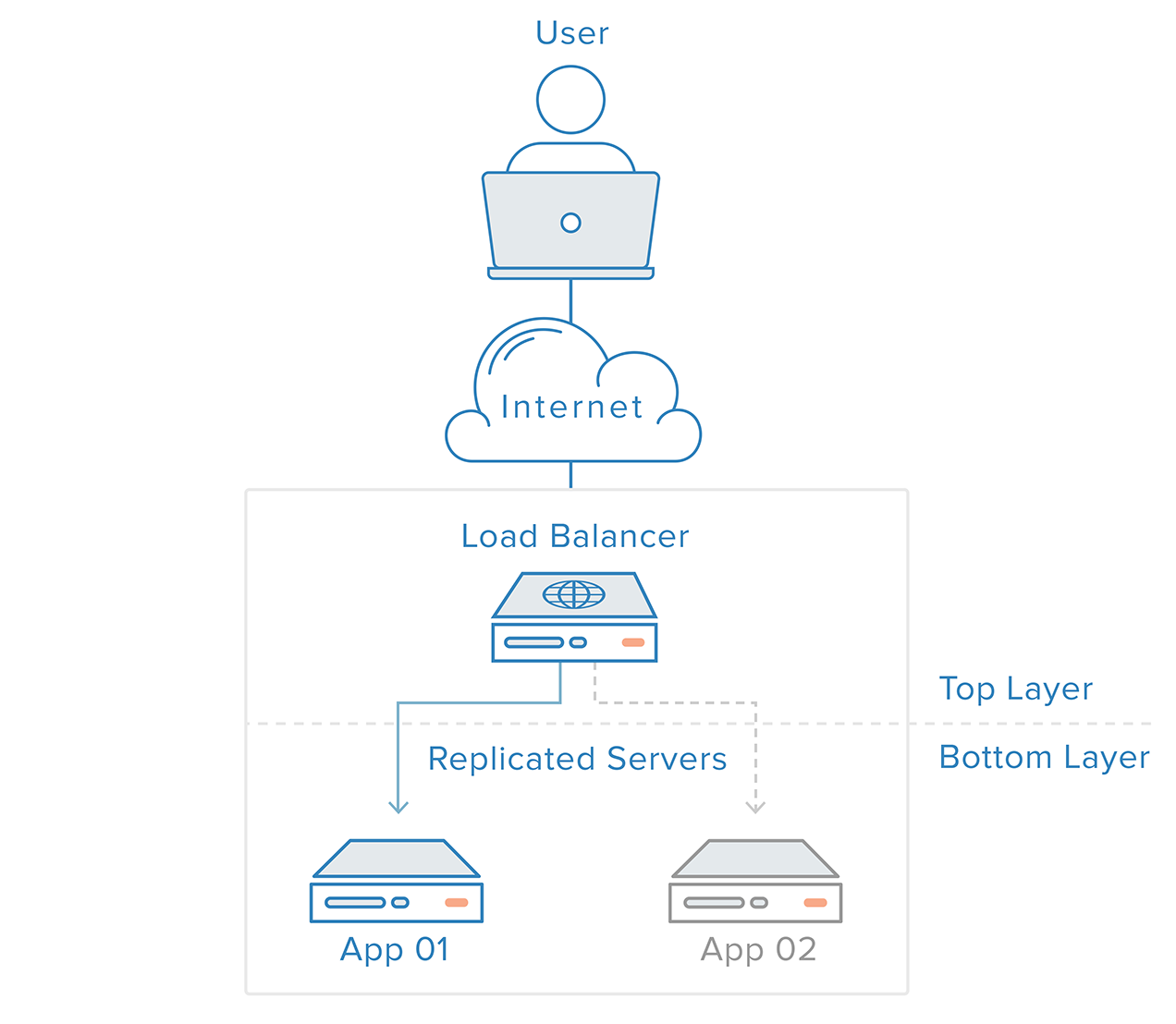
単一障害点を排除するために、それぞれスタックのレイヤーは、冗長性のために準備する必要があります。 たとえば、ロードバランサーの背後にある2つの同一の冗長Webサーバーで構成されるインフラストラクチャがあるとします。 クライアントからのトラフィックはWebサーバー間で均等に分散されますが、サーバーの1つがダウンすると、ロードバランサーはすべてのトラフィックを残りのオンラインサーバーにリダイレクトします。
次の理由により、このシナリオのWebサーバーレイヤーは単一障害点ではありません。
-
同じタスクの冗長コンポーネントが配置されている
-
この層の最上位のメカニズム(ロードバランサー)は、コンポーネントの障害を検出し、その動作をタイムリーな回復に適応させることができます。
しかし、ロードバランサーがオフラインになるとどうなりますか?
説明されているシナリオでは、実際には珍しくありませんが、負荷分散レイヤー自体が単一障害点のままです。 ただし、この残りの単一障害点を排除することは困難な場合があります。追加のロードバランサーを簡単に構成して冗長性を実現できますが、ロードバランサーの上に障害の検出と回復を実装する明確なポイントはありません。
冗長性だけでは高可用性を保証できません。 スタックのコンポーネントの1つが利用できなくなったときに障害を検出し、アクションを実行するためのメカニズムが必要です。
冗長システムの障害検出と復旧は、トップツーボトムのアプローチを使用して実装できます。最上位のレイヤーは、その直下のレイヤーの障害を監視する役割を果たします。 前の例のシナリオでは、ロードバランサーが最上層です。 Webサーバーの1つ(最下層)が使用できなくなると、ロードバランサーはその特定のサーバーへのリクエストのリダイレクトを停止します。
このアプローチはよりシンプルになる傾向がありますが、制限があります。最上層が存在しないか手の届かないところにインフラストラクチャ内のポイントが存在することになります。これはロードバランサー層の場合です。 外部サーバーにロードバランサーの障害検出サービスを作成すると、新しい単一障害点が作成されます。
このようなシナリオでは、分散アプローチが必要です。 複数の冗長ノードをクラスターとして接続し、各ノードで障害の検出と回復を同等に行う必要があります。
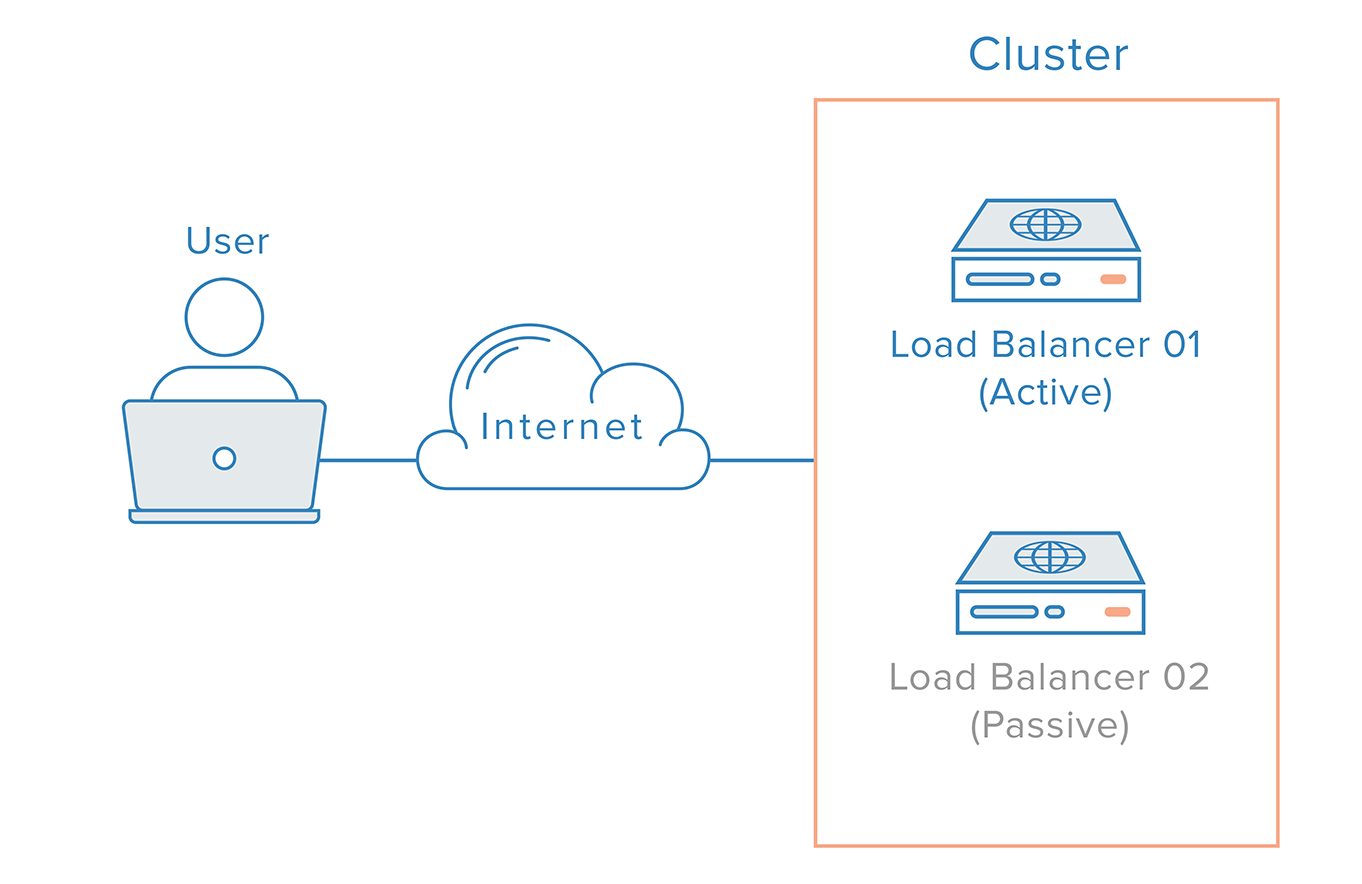
ただし、ロードバランサーの場合、ネームサーバーの動作方法により、さらに複雑になります。 通常、ロードバランサーの障害からの回復とは、冗長ロードバランサーへのフェイルオーバーを意味します。これは、ドメイン名を冗長ロードバランサーのIPアドレスに向けるためにDNSの変更が必要であることを意味します。 このような変更は、インターネットに反映されるまでにかなりの時間がかかり、このシステムに深刻なダウンタイムを引き起こす可能性があります。
考えられる解決策は、DNS round-robin load balancingを使用することです。 ただし、このアプローチはクライアント側アプリケーションのフェイルオーバーを残すため、信頼性がありません。
より堅牢で信頼性の高いソリューションは、floating IPsなどの柔軟なIPアドレスの再マッピングを可能にするシステムを使用することです。 オンデマンドIPアドレスの再マッピングは、必要なときに簡単に再マッピングできる静的IPアドレスを提供することにより、DNSの変更に固有の伝播とキャッシュの問題を排除します。 ドメイン名は同じIPアドレスに関連付けられたままにできますが、IPアドレス自体はサーバー間で移動されます。
これにより、フローティングIPを使用した高可用性インフラストラクチャは次のようになります。

高可用性にはどのシステムコンポーネントが必要ですか?
実際に高可用性を実装するには、いくつかのコンポーネントを慎重に考慮する必要があります。 ソフトウェアの実装以上に、高可用性は次のような要因に依存します。
-
Environment:すべてのサーバーが同じ地理的領域にある場合、地震や洪水などの環境条件によってシステム全体がダウンする可能性があります。 異なるデータセンターおよび地理的領域に冗長サーバーを配置すると、信頼性が向上します。
-
Hardware:の高可用性サーバーは、停電やハードディスクやネットワークインターフェイスなどのハードウェア障害に対して回復力がある必要があります。
-
Software:は、オペレーティングシステムとアプリケーション自体を含むソフトウェアスタック全体を、たとえばシステムの再起動が必要になる可能性のある予期しない障害を処理できるように準備する必要があります。
-
Data:のデータ損失と不整合は、いくつかの要因によって引き起こされる可能性があり、ハードディスクの障害に限定されません。 高可用性システムは、障害発生時のデータの安全性を考慮する必要があります。
-
Network:の計画外のネットワーク停止は、高可用性システムのもう1つの考えられる障害点を表しています。 障害が発生する可能性があるため、冗長ネットワーク戦略を実施することが重要です。
高可用性の構成に使用できるソフトウェアは何ですか?
高可用性システムの各層には、ソフトウェアと構成の点で異なるニーズがあります。 ただし、アプリケーションレベルでは、ロードバランサーは高可用性セットアップを作成するための重要なソフトウェアです。
HAProxy(高可用性プロキシ)は、複数のレイヤーで負荷分散を処理できるため、負荷分散や、database serversを含むさまざまな種類のサーバーで一般的に選択されます。
結論
高可用性は、信頼性エンジニアリングの重要なサブセットであり、システムまたはコンポーネントが一定期間内に高いレベルの運用パフォーマンスを確保することに焦点を当てています。 一見すると、その実装は非常に複雑に見えるかもしれません。ただし、信頼性の向上を必要とするシステムには多大なメリットをもたらします。