前書き
大幅な成長が見られるアプリケーションまたはWebサイトは、トラフィックの増加に対応するために、最終的にスケーリングする必要があります。 データ駆動型のアプリケーションやウェブサイトの場合、データのセキュリティと整合性を保証する方法でスケーリングを行うことが重要です。 Webサイトまたはアプリケーションがどのくらい人気になるか、またはその人気を維持する期間を予測するのは困難な場合があります。
この概念的な記事では、そのようなデータベースアーキテクチャの1つであるsharded databasesについて説明します。 シャーディングは近年多くの注目を集めていますが、多くの場合、それが何であるか、またはデータベースをシャードすることが理にかなっているシナリオを明確に理解していません。 シャーディングとは何か、その主な利点と欠点、およびいくつかの一般的なシャーディング方法について説明します。
シャーディングとは何ですか?
シャーディングは、horizontal partitioningに関連するデータベースアーキテクチャパターンです。これは、1つのテーブルの行をパーティションと呼ばれる複数の異なるテーブルに分割する方法です。 各パーティションのスキーマと列は同じですが、行もまったく異なります。 同様に、それぞれに保持されるデータは一意であり、他のパーティションに保持されるデータとは無関係です。
水平分割をvertical partitioningとの関係の観点から考えると役立つ場合があります。 垂直にパーティション化されたテーブルでは、列全体が分離され、新しい個別のテーブルに配置されます。 1つの垂直パーティション内に保持されるデータは、他のすべてのパーティション内のデータから独立しており、それぞれが個別の行と列の両方を保持します。 次の図は、テーブルを水平および垂直の両方にパーティション化する方法を示しています。
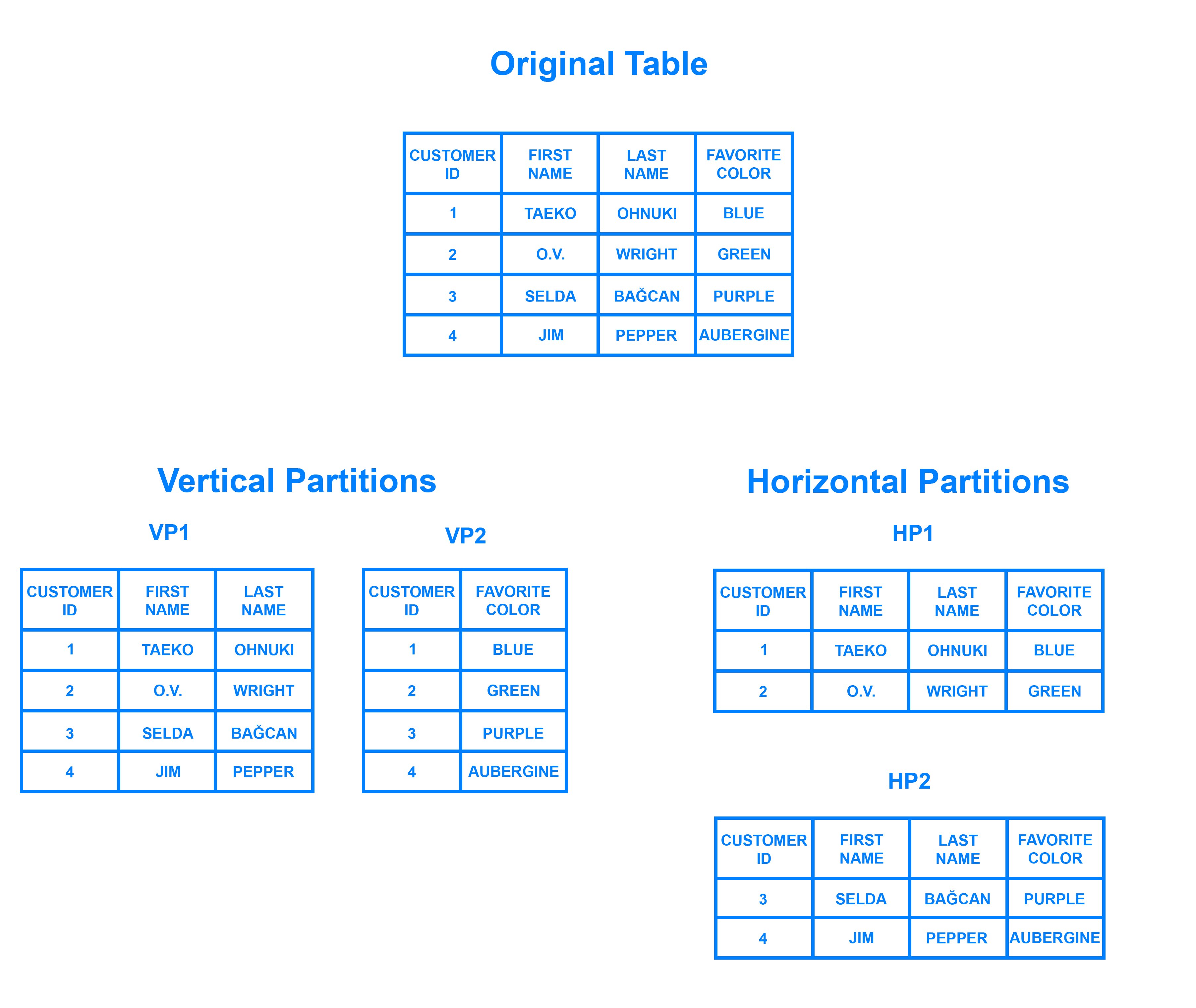
シャーディングでは、データをlogical shardsと呼ばれる2つ以上の小さなチャンクに分割します。 次に、論理シャードは、physical shardsと呼ばれる個別のデータベースノードに分散されます。このノードは、複数の論理シャードを保持できます。 それにもかかわらず、すべてのシャード内に保持されるデータは、論理データセット全体をまとめて表します。
データベースシャードはshared-nothing architectureを例示します。 これは、断片が自律的であることを意味します。同じデータやコンピューティングリソースを共有することはありません。 ただし、場合によっては、特定のテーブルを各シャードに複製して参照テーブルとして機能させることもあります。 たとえば、体重測定の固定変換率に依存するアプリケーションのデータベースがあるとします。 必要な変換率データを含むテーブルを各シャードに複製することにより、クエリに必要なすべてのデータがすべてのシャードに保持されるようになります。
多くの場合、シャーディングはアプリケーションレベルで実装されます。これは、読み取りと書き込みを送信するシャードを定義するコードがアプリケーションに含まれることを意味します。 ただし、一部のデータベース管理システムにはシャーディング機能が組み込まれているため、シャーディングをデータベースレベルで直接実装できます。
シャーディングのこの一般的な概要を踏まえて、このデータベースアーキテクチャに関連するいくつかの長所と短所を見ていきましょう。
シャーディングの利点
データベースのシャーディングの主な魅力は、scaling outとも呼ばれるhorizontal scalingを容易にするのに役立つことです。 水平スケーリングとは、負荷を分散し、より多くのトラフィックとより高速な処理を可能にするために、既存のスタックにさらにマシンを追加することです。 これは、vertical scaling(scaling upとも呼ばれます)とは対照的です。これは、通常、RAMまたはCPUを追加することにより、既存のサーバーのハードウェアをアップグレードすることを含みます。
単一のマシンでリレーショナルデータベースを実行し、コンピューティングリソースをアップグレードして必要に応じてスケールアップするのは比較的簡単です。 ただし、最終的には、非分散データベースはストレージと計算能力の点で制限されるため、水平方向に拡張する自由があると、セットアップがより柔軟になります。
一部がシャードデータベースアーキテクチャを選択するもう1つの理由は、クエリの応答時間を短縮するためです。 シャーディングされていないデータベースでクエリを送信する場合、探している結果セットを見つける前に、クエリしているテーブルのすべての行を検索する必要があります。 大規模なモノリシックデータベースを持つアプリケーションの場合、クエリが非常に遅くなる可能性があります。 ただし、1つのテーブルを複数に分割することにより、クエリの行数を減らす必要があり、結果セットがより迅速に返されます。
シャーディングは、停止の影響を軽減することにより、アプリケーションの信頼性を高めるのにも役立ちます。 アプリケーションまたはWebサイトがシャーディングされていないデータベースに依存している場合、停止によりアプリケーション全体が使用できなくなる可能性があります。 ただし、シャードデータベースでは、停止は単一のシャードのみに影響する可能性があります。 これにより、一部のユーザーがアプリケーションまたはWebサイトの一部を利用できなくなる場合がありますが、全体的な影響はデータベース全体がクラッシュした場合よりも小さくなります。
シャーディングの欠点
データベースをシャーディングすると、スケーリングが容易になり、パフォーマンスが向上しますが、特定の制限が課されることもあります。 ここでは、これらのいくつかと、それらがシャーディングを完全に回避する理由になる理由について説明します。
シャーディングで発生する最初の問題は、シャーディングされたデータベースアーキテクチャを適切に実装することの複雑さです。 正しく行わないと、シャーディングプロセスがデータの損失やテーブルの破損につながる可能性があるという重大なリスクがあります。 ただし、正しく行われた場合でも、シャーディングはチームのワークフローに大きな影響を与える可能性があります。 ユーザーは、単一のエントリポイントから自分のデータにアクセスして管理するのではなく、複数のシャードの場所でデータを管理する必要があります。これは、一部のチームを混乱させる可能性があります。
データベースを分割した後にユーザーが時々遭遇する問題の1つは、断片が最終的に不均衡になることです。 たとえば、姓がA〜Mで始まる顧客用と、名前がN〜Zで始まる顧客用の2つの個別のシャードを持つデータベースがあるとします。 ただし、アプリケーションは、姓が文字Gで始まる多くの人々にサービスを提供します。 したがって、A-MシャードはN-Zシャードよりも多くのデータを徐々に蓄積し、アプリケーションの速度を低下させ、ユーザーの大部分を失速させます。 A-Mシャードは、database hotspotとして知られるものになりました。 この場合、データベースのシャーディングの利点はすべて、スローダウンとクラッシュによってキャンセルされます。 より均等なデータ配布を可能にするには、データベースを修復してリシャーディングする必要がある可能性があります。
もう1つの大きな欠点は、いったんデータベースを分割すると、そのデータベースを非分割アーキテクチャに戻すことが非常に困難になる可能性があることです。 分割される前に作成されたデータベースのバックアップには、パーティション分割以降に書き込まれたデータは含まれません。 その結果、元の非シャーディングアーキテクチャを再構築するには、新しいパーティションデータを古いバックアップとマージするか、パーティションDBを単一のDBに変換し直す必要があり、どちらも費用と時間がかかります。
考慮すべき最後の欠点は、シャーディングがすべてのデータベースエンジンでネイティブにサポートされているわけではないことです。 たとえば、PostgreSQLには自動分割が機能として含まれていませんが、PostgreSQLデータベースを手動で分割することは可能です。 自動シャーディングを含む多くのPostgresフォークがありますが、これらは多くの場合、最新のPostgreSQLリリースに遅れをとっており、特定の他の機能が欠けています。 MySQL ClusterやMongoDB Atlasなどの特定のDatabase-as-a-Service製品など、一部の特殊なデータベーステクノロジーには自動シャーディングが機能として含まれていますが、これらのデータベース管理システムのバニラバージョンには含まれていません。 このため、シャーディングでは「独自のロール」アプローチが必要になることがよくあります。 これは、シャーディングのドキュメントまたは問題のトラブルシューティングのヒントを見つけるのが難しいことが多いことを意味します。
もちろん、これらはシャーディング前に考慮すべき一般的な問題の一部にすぎません。 ユースケースによっては、データベースのシャーディングにはさらに多くの潜在的な欠点があります。
シャーディングのいくつかの欠点と利点について説明したので、シャードデータベースのいくつかの異なるアーキテクチャを検討します。
シャーディングアーキテクチャ
データベースを分割することを決めたら、次に理解する必要があるのは、どのようにそれを行うかです。 クエリを実行したり、受信したデータをシャーディングされたテーブルやデータベースに配布したりするときは、正しいシャードに移動することが重要です。 そうしないと、データが失われたり、クエリが非常に遅くなる可能性があります。 このセクションでは、いくつかの一般的なシャーディングアーキテクチャについて説明します。各アーキテクチャは、わずかに異なるプロセスを使用して、シャード間でデータを分散します。
キーベースのシャーディング
Key based shardingは、hash based shardingとも呼ばれ、顧客のID番号、クライアントアプリケーションのIPアドレス、郵便番号など、新しく書き込まれたデータから取得した値を使用します。 —そしてそれをhash functionに接続して、データがどのシャードに移動するかを決定します。 ハッシュ関数は、データの一部(たとえば、顧客の電子メール)を入力として受け取り、hash valueと呼ばれる離散値を出力する関数です。 シャーディングの場合、ハッシュ値は、着信データを保存するシャードを決定するために使用されるシャードIDです。 全体として、プロセスは次のようになります。

エントリが正しいシャードに一貫した方法で配置されるようにするには、ハッシュ関数に入力される値はすべて同じ列から取得する必要があります。 この列はshard keyとして知られています。 簡単に言うと、シャードキーはprimary keysに似ており、どちらも個々の行の一意の識別子を確立するために使用される列です。 大まかに言って、シャードキーは静的である必要があります。つまり、時間の経過とともに変化する可能性のある値を含めることはできません。 そうしないと、更新操作にかかる作業量が増加し、パフォーマンスが低下する可能性があります。
キーベースのシャーディングはかなり一般的なシャーディングアーキテクチャですが、データベースに追加のサーバーを動的に追加または削除しようとすると、物事が難しくなります。 サーバーを追加すると、それぞれに対応するハッシュ値が必要になり、既存のエントリの多くは、すべてではないにしても、新しい正しいハッシュ値に再マッピングしてから適切なサーバーに移行する必要があります。 データのリバランスを開始すると、新しいハッシュ関数も古いハッシュ関数も無効になります。 そのため、サーバーは移行中に新しいデータを書き込むことができず、アプリケーションがダウンタイムの影響を受ける可能性があります。
この戦略の主な魅力は、ホットスポットを防ぐためにデータを均等に分散するために使用できることです。 また、アルゴリズムを使用してデータを配信するため、範囲やディレクトリベースのシャーディングなどの他の戦略で必要な、すべてのデータが配置されている場所のマップを維持する必要はありません。
範囲ベースのシャーディング
Range based shardingには、指定された値の範囲に基づいてデータをシャーディングすることが含まれます。 例として、小売業者のカタログ内のすべての製品に関する情報を保存するデータベースがあるとします。 次のように、いくつかの異なるシャードを作成し、それぞれの価格範囲に基づいて各製品の情報を分割できます。

範囲ベースのシャーディングの主な利点は、比較的簡単に実装できることです。 各シャードは異なるデータセットを保持しますが、それらはすべて元のデータベースと同様に、互いに同一のスキーマを持っています。 アプリケーションコードは、データがどの範囲に該当するかを読み取り、対応するシャードに書き込みます。
一方、範囲ベースのシャーディングは、データが不均一に分散されることを防ぎ、前述のデータベースホットスポットにつながります。 サンプルの図を見ると、各シャードが同じ量のデータを保持している場合でも、特定の製品が他の製品よりも注目される可能性が高くなります。 それぞれのシャードは、不均衡な数の読み取りを受け取ります。
ディレクトリベースのシャーディング
directory based shardingを実装するには、シャードキーを使用してどのシャードがどのデータを保持しているかを追跡するlookup tableを作成し、維持する必要があります。 簡単に言うと、ルックアップテーブルは、特定のデータがどこにあるかに関する静的な情報のセットを保持するテーブルです。 次の図は、ディレクトリベースのシャーディングの単純な例を示しています。
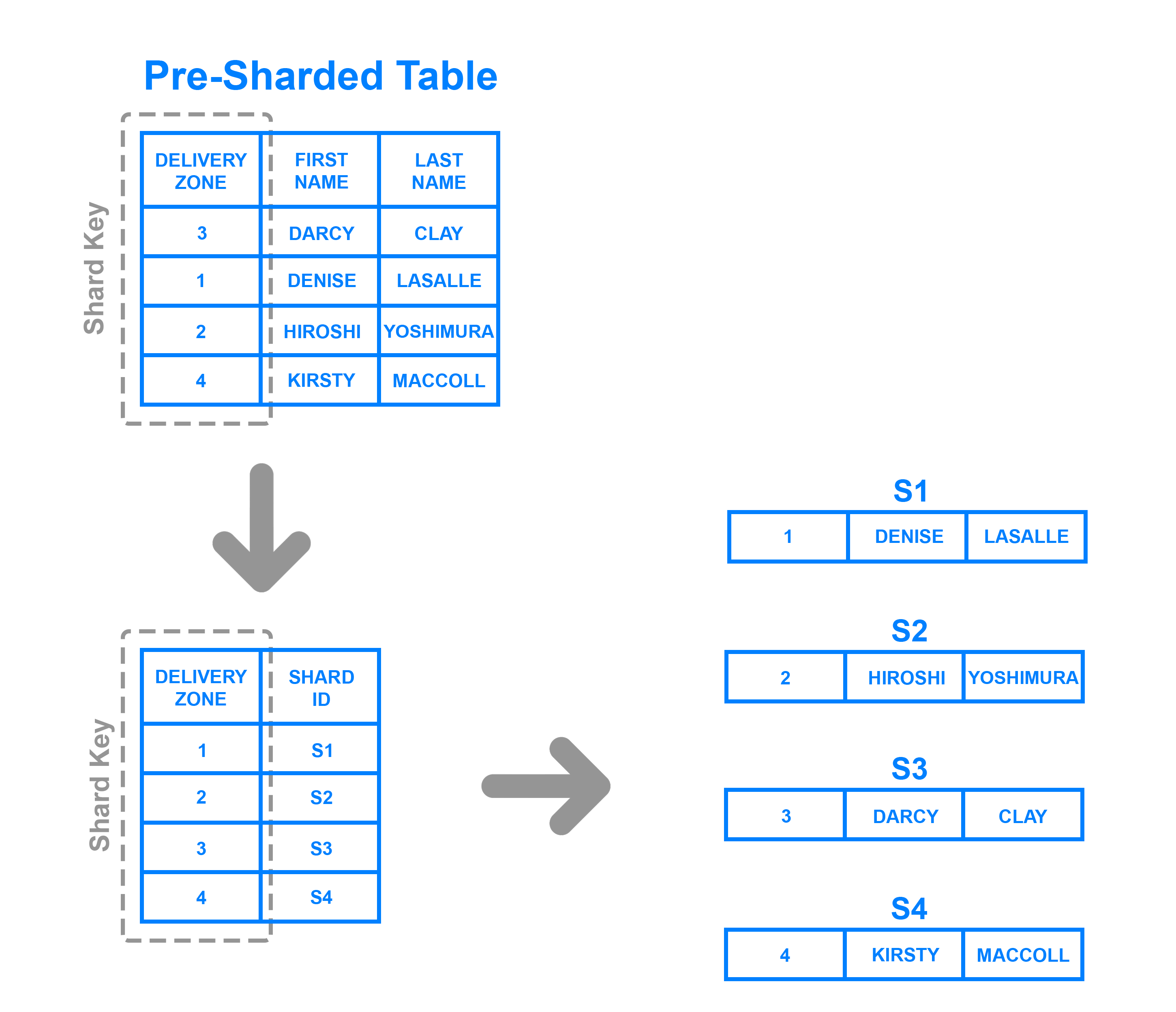
ここで、Delivery Zone列はシャードキーとして定義されています。 シャードキーからのデータは、各行に書き込まれるシャードとともにルックアップテーブルに書き込まれます。 これは範囲ベースのシャーディングに似ていますが、シャードキーのデータがどの範囲に入るかを決定する代わりに、各キーは独自の特定のシャードに関連付けられます。 ディレクトリベースのシャーディングは、シャードキーのカーディナリティが低く、シャードがキーの範囲を格納する意味がない場合に、範囲ベースのシャーディングよりも適切な選択です。 また、ハッシュ関数を介してシャードキーを処理しないという点で、キーベースのシャーディングとは異なります。キーをルックアップテーブルと照合して、データを書き込む必要がある場所を確認するだけです。
ディレクトリベースのシャーディングの主な魅力は、その柔軟性です。 範囲ベースのシャーディングアーキテクチャでは、値の範囲の指定に制限されますが、キーベースのものでは、前述のように、後で変更するのが非常に困難な可能性がある固定ハッシュ関数の使用に制限されます。 一方、ディレクトリベースのシャーディングでは、データエントリをシャードに割り当てる任意のシステムまたはアルゴリズムを使用できます。この方法を使用すると、シャードを動的に比較的簡単に追加できます。
ディレクトリベースのシャーディングは、ここで説明したシャーディング方法の中で最も柔軟性がありますが、すべてのクエリまたは書き込みの前にルックアップテーブルに接続する必要があると、アプリケーションのパフォーマンスに悪影響を与える可能性があります。 さらに、ルックアップテーブルは単一障害点になる可能性があります。破損したり、失敗した場合、新しいデータを書き込んだり、既存のデータにアクセスしたりする能力に影響を与える可能性があります。
シャードする必要がありますか?
シャードデータベースアーキテクチャを実装するかどうかは、ほとんど常に議論の問題です。 シャーディングは、特定のサイズに達するデータベースの避けられない結果であると考える人もいれば、シャーディングによって操作が複雑になるため、絶対に必要でない限り回避すべき頭痛と考える人もいます。
この複雑さが増すため、シャーディングは通常、非常に大量のデータを処理する場合にのみ実行されます。 データベースを分割することが有益な一般的なシナリオを次に示します。
-
アプリケーションデータの量が増加して、単一のデータベースノードのストレージ容量を超えます。
-
データベースへの書き込みまたは読み取りの量は、単一ノードまたはそのリードレプリカが処理できる量を超え、応答時間またはタイムアウトが遅くなります。
-
アプリケーションが必要とするネットワーク帯域幅は、単一のデータベースノードとリードレプリカで使用可能な帯域幅を上回っており、応答時間またはタイムアウトが遅くなります。
シャーディングする前に、データベースを最適化するための他のすべてのオプションを使い果たす必要があります。 検討する必要がある最適化には、次のものがあります。
-
Setting up a remote database。 すべてのコンポーネントが同じサーバー上にあるモノリシックアプリケーションを使用している場合、データベースを独自のマシンに移動することでデータベースのパフォーマンスを向上させることができます。 データベースのテーブルはそのままなので、これはシャーディングほど複雑ではありません。 ただし、インフラストラクチャの他の部分とは別にデータベースを垂直にスケーリングすることはできます。
-
Implementing caching。 アプリケーションの読み取りパフォーマンスが問題の原因である場合、キャッシュはそれを改善するのに役立つ戦略の1つです。 キャッシュには、既に要求されたデータをメモリに一時的に保存することが含まれ、後でより迅速にアクセスできます。
-
Creating one or more read replicas。 読み取りパフォーマンスの向上に役立つもう1つの戦略は、1つのデータベースサーバー(primary server)から1つ以上のsecondary serversにデータをコピーすることです。 これに続いて、すべての新しい書き込みはセカンダリにコピーされる前にプライマリに送られ、読み取りはセカンダリサーバーに対して排他的に行われます。 このように読み取りと書き込みを分散することにより、1台のマシンが負荷をかけすぎないようにし、スローダウンとクラッシュを防ぎます。 リードレプリカの作成には、より多くのコンピューティングリソースが含まれるため、より多くの費用がかかることに注意してください。
-
Upgrading to a larger server。 ほとんどの場合、データベースサーバーをより多くのリソースを持つマシンにスケールアップするには、シャーディングよりも少ない労力で済みます。 リードレプリカの作成と同様に、アップグレードされたサーバーのリソースが増えると、おそらく費用がかかります。 したがって、本当に最適なオプションである場合にのみ、サイズ変更を行う必要があります。
アプリケーションまたはWebサイトが特定のポイントを超えて成長した場合、これらの戦略はどれも単独でパフォーマンスを改善するのに十分ではないことに注意してください。 このような場合、シャーディングが実際に最適なオプションである可能性があります。
結論
シャーディングは、データベースを水平方向に拡張したい場合に最適なソリューションです。 しかし、それはまた、かなりの複雑さを追加し、アプリケーションにとってより多くの潜在的な障害ポイントを作成します。 一部ではシャーディングが必要になる場合がありますが、シャードアーキテクチャの作成と保守に必要な時間とリソースが他の人にとってのメリットを上回る可能性があります。
この概念記事を読むことで、シャーディングの長所と短所をより明確に理解する必要があります。 今後、この洞察を使用して、シャーディングされたデータベースアーキテクチャがアプリケーションに適しているかどうかについて、より情報に基づいた決定を下すことができます。