Python vs C ++:ジョブに適したツールの選択
あなたはPythonとCを比較するC開発者ですか? Pythonを見て、大騒ぎとは何ですか? Pythonがあなたがすでに知っている概念とどのように比較されるか疑問に思いますか? それとも、C ++とPythonをケージに閉じ込めてバトルさせたら誰が勝つかという賭けがあるのでしょうか? 次に、この記事はあなたのためです!
In this article, you’ll learn about:
-
PythonとC ++を比較する場合の違いと類似点
-
Pythonが問題に対してより良い選択であり、その逆の場合
-
Pythonの学習中に質問がある場合に役立つリソース
この記事は、Pythonを学んでいるC開発者を対象としています。 両方の言語の基本的な知識があることを前提としており、Python3.6以降およびC11以降の概念を使用します。
Python対C ++を見てみましょう。
Free Bonus:Click here to get access to a chapter from Python Tricks: The Bookは、Pythonのベストプラクティスと、より美しい+ Pythonicコードをすぐに適用できる簡単な例を示しています。
言語の比較:PythonとC ++
多くの場合、あるプログラミング言語の長所を別のプログラミング言語よりも称賛する記事があります。 かなり頻繁に、彼らは他の言語を劣化させることにより、ある言語を促進する努力に委ねられます。 これはそのタイプの記事ではありません。
PythonとC ++を比較するときは、両方ともツールであり、両方とも異なる問題に使用できることを忘れないでください。 ハンマーとドライバーを比較することを考えてください。 couldはドライバーを使用して釘を打ち込み、couldはハンマーを使用してねじを押し込みますが、どちらの経験もそれほど効果的ではありません。
ジョブに適切なツールを使用することが重要です。 この記事では、PythonとCの機能について学習します。これらの機能により、特定の種類の問題に対してそれぞれが適切に選択されます。 したがって、PythonとCの「vs」を「反対」を意味するものと見なさないでください。むしろ、それを比較として考えてください。
コンパイルと仮想マシン
PythonとCを比較するときの最大の違いから始めましょう。 Cでは、ソースコードをマシンコードに変換して実行可能ファイルを生成するコンパイラを使用します。 実行可能ファイルは、スタンドアロンプログラムとして実行できる別のファイルです。

このプロセスは、特定のプロセッサとそれが構築されたオペレーティングシステムの実際の機械命令を出力します。 この図では、Windowsプログラムです。 これは、Windows、Mac、およびLinux用にプログラムを個別に再コンパイルする必要があることを意味します。
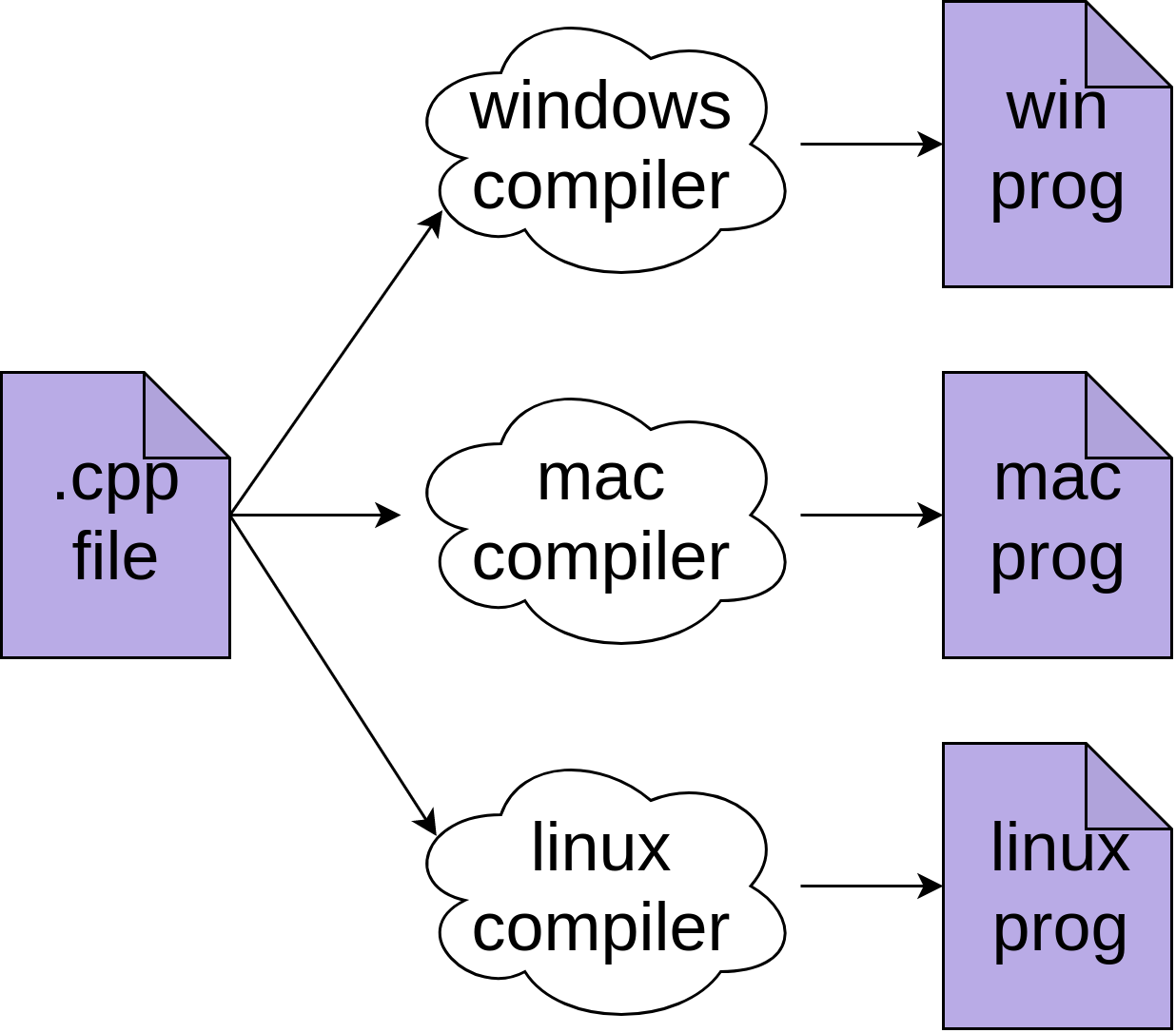
これらの異なるシステムでも実行するには、C ++コードを変更する必要があります。
一方、Pythonは異なるプロセスを使用します。 ここで、言語の標準実装であるCPythonを確認することに注意してください。 特別なことをしているのでなければ、これはあなたが実行しているPythonです。
Pythonは、プログラムを実行するたびに実行されます。 C ++コンパイラと同じようにソースをコンパイルします。 違いは、Pythonがネイティブマシンコードではなくbytecodeにコンパイルされることです。 バイトコードは、Python virtual machineのネイティブ命令コードです。 プログラムの後続の実行を高速化するために、Pythonはバイトコードを.pycファイルに保存します。

Python 2を使用している場合、これらのファイルは.pyファイルの横にあります。 Python 3の場合、それらは__pycache__ディレクトリにあります。
生成されたバイトコードは、プロセッサでネイティブに実行されません。 代わりに、Python仮想マシンによって実行されます。 これは、Java仮想マシンまたは.NET共通ランタイム環境に似ています。 コードを最初に実行すると、コンパイル手順が行われます。 次に、バイトコードは特定のハードウェアで実行されるように解釈されます。

プログラムが変更されていない限り、以降の各実行ではコンパイル手順がスキップされ、以前にコンパイルされたバイトコードを使用して解釈されます。

コードの解釈は、ハードウェアでネイティブコードを直接実行するよりも遅くなります。 では、なぜPythonはそのように機能するのでしょうか? さて、仮想マシンでコードを解釈するということは、特定のプロセッサー上の特定のオペレーティングシステム用に仮想マシンのみをコンパイルする必要があるということです。 Pythonが実行するすべてのPythonコードは、Pythonを搭載したすべてのマシンで実行されます。
Note: CPythonはCで記述されているため、Cコンパイラを備えたほとんどのシステムで実行できます。
このクロスプラットフォームサポートのもう1つの特徴は、Pythonの広範な標準ライブラリがすべてのオペレーティングシステムで動作するように記述されていることです。
たとえば、pathlibを使用すると、Windows、Mac、またはLinuxのいずれを使用している場合でも、パスセパレータが管理されます。 これらのライブラリの開発者は、それを移植可能にするために多くの時間を費やしたので、Pythonプログラムで心配する必要はありません!
先に進む前に、PythonとC ++の比較表の追跡を始めましょう。 新しい比較をカバーすると、斜体で追加されます。
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
PythonとC ++を比較するときに実行時間の違いがわかったので、言語の構文の詳細を調べてみましょう。
構文の違い
PythonとC ++は多くの構文上の類似点を共有していますが、議論する価値のある領域がいくつかあります。
-
空白
-
ブール式
-
変数とポインター
-
理解度
まず最も議論の余地のあるもの、ホワイトスペースから始めましょう。
空白
PythonとCを比較するときにほとんどの開発者が最初に気付くのは、「空白の問題」です。 Pythonは、先頭の空白を使用してスコープをマークします。 これは、「+ if +」ブロックまたは他の同様の構造の本体がインデントのレベルによって示されることを意味します。 Cは、中括弧({})を使用して同じアイデアを示します。
Pythonレクサーは、一貫性がある限り任意の空白を受け入れますが、PEP8(Pythonの場合はofficial style guide)は、インデントのレベルごとに4つのスペースを指定します。 ほとんどのエディターは、これを自動的に行うように構成できます。
Pythonは、;のような字句マーカーに依存して各ステートメントを終了する代わりに、行の終わりを使用します。 ステートメントを1行に拡張する必要がある場合は、円記号(\)を使用してそれを示すことができます。 (括弧内にいる場合は、継続文字は不要です。)
ホワイトスペース問題の両側に不満を抱いている人がいます。 一部のPython開発者は、中括弧とセミコロンを入力する必要がないことを気に入っています。 一部のC ++開発者は、フォーマットへの依存を嫌います。 両方に慣れることを学ぶのが最善策です。
空白の問題を確認したので、もう少し議論の少ない、ブール式に移りましょう。
ブール式
Boolean expressionsの使用方法は、PythonとCでわずかに異なります。 Cでは、組み込み値に加えて、数値を使用してtrueまたはfalseを示すことができます。 0と評価されるものはすべてfalseと見なされ、他のすべての数値はtrueです。
Pythonにも同様の概念がありますが、他のケースを含むように拡張します。 基本は非常に似ています。 Python documentationは、次の項目がFalseに評価されることを示しています。
-
falseとして定義された定数:
-
None -
False
-
-
任意の数値型のゼロ:
-
0 -
0.0 -
0j -
Decimal(0) -
Fraction(0, 1)
-
-
空のシーケンスとコレクション:
-
'' -
() -
[] -
{} -
set() -
range(0)
-
他のすべてのアイテムはTrueです。 これは、空のリスト[]がFalseであるのに対し、ゼロ[0]のみを含むリストはTrueであることを意味します。
オブジェクトにFalseを返す__bool__()または0を返す__len__()がない限り、ほとんどのオブジェクトはTrueに評価されます。 これにより、カスタムクラスを拡張してブール式として機能させることができます。
Pythonには、ブール演算子のCからのわずかな変更もいくつかあります。 手始めに、 `+ if +`および `+ while +`ステートメントは、Cの場合のように周囲の括弧を必要としません。 ただし、括弧は読みやすさを高めるのに役立つため、最善の判断をしてください。
ほとんどのC ++ブール演算子には、Pythonで同様の演算子があります。
| C ++演算子 | Python演算子 |
|---|---|
|
|
`+ |
|
+` |
|
|
|
|
|
`+ |
+` |
`+ |
+` |
ほとんどの演算子はC ++に似ていますが、ブラッシュアップする場合はOperators and Expressions in Pythonを読み取ることができます。
変数とポインター
Cで記述した後、最初にPythonを使い始めるときは、変数についてあまり考えないかもしれません。 それらは一般的にCの場合と同じように機能するようです。 しかし、それらは同じではありません。 C ++では変数を使用して値を参照しますが、Pythonでは名前を使用します。
Note:このセクションでは、PythonとCで変数と名前を確認します。ここでは、Cには*変数*を使用し、Pythonにはnamesを使用します。 他の場所では、両方ともvariablesと呼ばれます。
まず、少しバックアップして、Pythonのobject modelを詳しく見てみましょう。
Pythonでは、everythingはオブジェクトです。 番号はオブジェクトに保持されます。 モジュールはオブジェクトに保持されます。 クラスandの両方のオブジェクトは、クラス自体がオブジェクトです。 関数もオブジェクトです:
>>>
>>> a_list_object = list()
>>> a_list_object
[]
>>> a_class_object = list
>>> a_class_object
>>> def sayHi(name):
... print(f'Hello, {name}')
...
>>> a_function_object = sayHi
>>> a_function_object
list()を呼び出すと、新しいリストオブジェクトが作成され、a_list_objectに割り当てられます。 クラスlistの名前を単独で使用すると、クラスオブジェクトにラベルが付けられます。 関数に新しいラベルを配置することもできます。 これは強力なツールであり、すべての強力なツールと同様に、危険な場合があります。 (私はあなたを見ています、ミスター チェーンソー。)
Note:上記のコードは、「Read、Eval、Print Loop」を表すREPLで実行されていることが示されています。このインタラクティブな環境は、Pythonやその他のインタープリター言語でアイデアを試すために頻繁に使用されます。
コマンドプロンプトでpythonと入力すると、REPLが表示され、コードを入力して自分で試してみることができます。
PythonとCの説明に戻ると、これはCで表示される動作とは異なる動作であることに注意してください。 Pythonとは異なり、C ++にはメモリロケーションに割り当てられる変数があり、その変数が使用するメモリ量を指定する必要があります。
int an_int;
float a_big_array_of_floats[REALLY_BIG_NUMBER];Pythonでは、すべてのオブジェクトがメモリ内に作成され、それらにラベルを適用します。 ラベル自体にはタイプがなく、あらゆるタイプのオブジェクトに付けることができます。
>>>
>>> my_flexible_name = 1
>>> my_flexible_name
1
>>> my_flexible_name = 'This is a string'
>>> my_flexible_name
'This is a string'
>>> my_flexible_name = [3, 'more info', 3.26]
>>> my_flexible_name
[3, 'more info', 3.26]
>>> my_flexible_name = print
>>> my_flexible_name
my_flexible_nameを任意のタイプのオブジェクトに割り当てることができ、Pythonはそれを使用してロールします。
PythonとC ++を比較する場合、変数と名前の違いは少しわかりにくいかもしれませんが、いくつかの優れた利点があります。 1つは、Pythonにはpointersがなく、ヒープとスタックの問題について考える必要がないことです。 この記事の後半で、メモリ管理について詳しく説明します。
理解度
Pythonには、list comprehensionsと呼ばれる言語機能があります。 リストの内包表記をC ++でエミュレートすることは可能ですが、かなり注意が必要です。 Pythonでは、初心者プログラマーに教えられる基本的なツールです。
リストの内包表記について考える1つの方法は、リスト、辞書、またはセットの非常に強力な初期化子のようなものです。 1つの反復可能なオブジェクトを指定すると、リストを作成し、元のフィルターまたはフィルターを変更できます。
>>>
>>> [x**2 for x in range(5)]
[0, 1, 4, 9, 16]このスクリプトは、反復可能なrange(5)で始まり、反復可能な各項目の正方形を含むリストを作成します。
最初のイテラブルの値に条件を追加することができます。
>>>
>>> odd_squares = [x**2 for x in range(5) if x % 2]
>>> odd_squares
[1, 9]この理解の最後にあるif x % 2は、使用される数をrange(5)から奇数に制限します。
この時点で、次の2つの考えがあります。
-
これは、コードの一部を単純化する強力な構文トリックです。
-
C ++でも同じことができます。
C ++で奇数の2乗のvectorを作成できるのは事実ですが、そうすることは通常、もう少しコードを意味します。
std::vector odd_squares;
for (int ii = 0; ii < 10; ++ii) {
if (ii % 2) {
odd_squares.push_back(ii);
}
} Cスタイル言語を使用する開発者にとって、リスト内包表記は、write more Pythonic codeを実行できる最初の注目すべき方法の1つです。 多くの開発者は、C ++構造でPythonの記述を開始します。
odd_squares = []
for ii in range(5):
if (ii % 2):
odd_squares.append(ii)これは完全に有効なPythonです。 ただし、実行はより遅くなる可能性が高く、リストの理解ほど明確で簡潔ではありません。 リスト内包表記の使用を学習すると、コードが高速化されるだけでなく、コードがよりPythonicになり、読みやすくなります。
Note: Pythonについて読んでいると、何かを説明するために使用されるPythonicという単語をよく目にします。 これは、クリーンでエレガントで、Python Jediによって書かれたように見えるコードを記述するためにコミュニティが使用する用語です。
Pythonのstd::algorithms
C ++には、標準ライブラリに組み込まれた豊富なアルゴリズムのセットがあります。 Pythonには、同じ領域をカバーする同様の組み込み関数セットがあります。
これらの最初で最も強力なのはin operatorです。これは、アイテムがlist、set、またはdictionaryに含まれているかどうかを確認するための非常に読みやすいテストを提供します。
>>>
>>> x = [1, 3, 6, 193]
>>> 6 in x
True
>>> 7 in x
False
>>> y = { 'Jim' : 'gray', 'Zoe' : 'blond', 'David' : 'brown' }
>>> 'Jim' in y
True
>>> 'Fred' in y
False
>>> 'gray' in y
Falsein演算子を辞書で使用する場合、値ではなくキーのみをテストすることに注意してください。 これは、最終テスト'gray' in yによって示されます。
inをnotと組み合わせて、非常に読みやすい構文にすることができます。
if name not in y:
print(f"{name} not found")Python組み込み演算子のパレードの次は、anyです。 これは、指定されたiterableのいずれかの要素がTrueと評価された場合に、Trueを返すブール関数です。 リストの理解度を覚えるまで、これは少しばかげているように思えます! これら2つを組み合わせると、多くの状況で強力で明確な構文を生成できます。
>>>
>>> my_big_list = [10, 23, 875]
>>> my_small_list = [1, 2, 8]
>>> any([x < 3 for x in my_big_list])
False
>>> any([x < 3 for x in my_small_list])
True最後に、anyと同様のallがあります。 これは、反復可能要素のallがTrueである場合、Trueonlyを返します。 繰り返しますが、これをリスト内包表記と組み合わせると、強力な言語機能が生成されます。
>>>
>>> list_a = [1, 2, 9]
>>> list_b = [1, 3, 9]
>>> all([x % 2 for x in list_a])
False
>>> all([x % 2 for x in list_b])
Trueanyとallは、C ++開発者がstd::findまたはstd::find_ifを探すのと同じ分野の多くをカバーできます。
Note:上記のanyおよびallの例では、機能を失うことなく角かっこ([])を削除できます。 (例:all(x % 2 for x in list_a))これはgenerator expressionsを利用しますが、これは非常に便利ですが、この記事の範囲を超えています。
変数の入力に進む前に、PythonとC ++の比較表を更新しましょう。
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
|
単一型変数 |
x |
|
複数型変数 |
x |
|
理解度 |
x |
|
組み込みアルゴリズムの豊富なセット |
x |
x |
さて、これで変数とパラメーターの入力を確認する準備ができました。 行こう!
静的タイピングと動的タイピング
PythonとCを比較する際のもう1つの大きなトピックは、データ型の使用です。 Cは静的に型付けされた言語ですが、Pythonは動的に型付けされています。 それが何を意味するのか探りましょう。
静的入力
C ++は静的に型指定されます。つまり、コードで使用する各変数には、int、char、floatなどの特定のデータ型が必要です。 いくつかのフープをジャンプしない限り、変数に正しい型の値のみを割り当てることができます。
これには、開発者とコンパイラの両方にいくつかの利点があります。 開発者は、特定の変数のタイプが事前に何であるか、したがってどの操作が許可されているかを知っているという利点を得ることができます。 コンパイラは、型情報を使用してコードを最適化し、コードをより小さく、より速く、またはその両方にすることができます。
ただし、この事前知識にはコストがかかります。 関数に渡されるパラメーターは、関数が期待する型と一致する必要があります。これにより、コードの柔軟性と潜在的な有用性が低下する可能性があります。
アヒルのタイピング
動的型付けは、しばしばduck typing.と呼ばれます。これは奇妙な名前です。これについては、すぐに詳しく説明します。 しかし、最初に、例から始めましょう。 この関数は、ファイルオブジェクトを受け取り、最初の10行を読み取ります。
def read_ten(file_like_object):
for line_number in range(10):
x = file_like_object.readline()
print(f"{line_number} = {x.strip()}")この関数を使用するには、ファイルオブジェクトを作成して渡します。
with open("types.py") as f:
read_ten(f)これは、関数の基本設計がどのように機能するかを示しています。 この関数は「ファイルオブジェクトから最初の10行を読み取る」と説明されていましたが、Pythonには、file_like_objectbeファイルを必要とするものはありません。 渡されたオブジェクトが.readline()をサポートしている限り、オブジェクトは任意のタイプにすることができます。
class Duck():
def readline(self):
return "quack"
my_duck = Duck()
read_ten(my_duck)Duckオブジェクトを使用してread_ten()を呼び出すと、次のようになります。
0 = quack
1 = quack
2 = quack
3 = quack
4 = quack
5 = quack
6 = quack
7 = quack
8 = quack
9 = quackこれがduck typingの本質です。 「アヒルのように見え、アヒルのように泳ぎ、アヒルのように鳴くなら、おそらくisはアヒルです」ということわざがあります。
つまり、オブジェクトに必要なメソッドがある場合、オブジェクトのタイプに関係なく、オブジェクトを渡すことは許容されます。 ダックまたは動的な型指定により、必要なインターフェイスを満たす任意の型を使用できるため、非常に大きな柔軟性が得られます。
ただし、ここには問題があります。 doesn’tが必要なインターフェイスを満たすオブジェクトを渡すとどうなりますか? たとえば、次のようにread_ten()に数値を渡すとどうなりますか?read_ten(3)?
これにより、例外がスローされます。 例外をキャッチしない限り、プログラムはtracebackで爆発します。
Traceback (most recent call last):
File "", line 1, in
File "duck_test.py", line 4, in read_ten
x = file_like_object.readline()
AttributeError: 'int' object has no attribute 'readline' 動的型付けは非常に強力なツールになる可能性がありますが、ご覧のとおり、使用する際は注意が必要です。
Note: PythonとCは、どちらもhttps://stackoverflow.com/a/11328980 [強く型付けされた]言語と見なされます。 Cはより強力な型システムを持っていますが、これの詳細は一般的にPythonを学ぶ人にとって重要ではありません。
次に、Pythonの動的型付けの利点を生かす機能であるテンプレートに移りましょう。
テンプレート
PythonにはC ++のようなテンプレートはありませんが、通常は必要ありません。 Pythonでは、すべてが単一の基本型のサブクラスです。 これにより、上記のようなカモタイピング関数を作成できます。
C ++のテンプレートシステムを使用すると、複数の異なるタイプで動作する関数またはアルゴリズムを作成できます。 これは非常に強力であり、時間と労力を大幅に節約できます。 ただし、テンプレートのコンパイラエラーにより困惑する可能性があるため、混乱やフラストレーションの原因にもなります。
テンプレートの代わりにアヒルのタイピングを使用できると、いくつかのことがはるかに簡単になります。 しかし、これも検出が困難な問題を引き起こす可能性があります。 すべての複雑な決定と同様に、PythonとC ++を比較する際にはトレードオフがあります。
型チェック
最近のPythonコミュニティでは、Pythonの静的型チェックについて多くの関心と議論がありました。 mypyのようなプロジェクトは、言語の特定の場所に実行前型チェックを追加する可能性を高めました。 これは、大きなパッケージの一部または特定のAPI間のインターフェイスを管理するのに非常に役立ちます。
アヒルのタイピングの欠点の1つに対処するのに役立ちます。 関数を使用する開発者にとって、各パラメーターの必要性を完全に理解できれば役立ちます。 これは、多くの開発者がAPIを介して通信する必要がある大規模なプロジェクトチームで役立ちます。
もう一度、PythonとC ++の比較表を見てみましょう。
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
|
単一型変数 |
x |
|
複数型変数 |
x |
|
理解度 |
x |
|
組み込みアルゴリズムの豊富なセット |
x |
x |
静的入力 |
x |
|
動的な入力 |
x |
これで、オブジェクト指向プログラミングの違いに進む準備ができました。
オブジェクト指向プログラミング
Cと同様に、Pythonはhttps://realpython.com/courses/intro-object-directiond-programming-oop-python/ [オブジェクト指向プログラミングモデル]をサポートしています。 Cで学んだ同じ概念の多くは、Pythonにも引き継がれています。 inheritance, compositionと多重継承については、引き続き決定する必要があります。
類似点
クラス間のInheritanceは、PythonとCで同様に機能します。 新しいクラスは、Cで見たように、1つ以上の基本クラスからメソッドと属性を継承できます。 ただし、詳細の一部は少し異なります。
Pythonの基本クラスには、C ++のように自動的に呼び出されるコンストラクターはありません。 これは、言語を切り替えるときに混乱を招く可能性があります。
Multiple inheritanceはPythonでも機能し、C ++と同じくらい多くの癖や奇妙なルールがあります。
同様に、コンポジションを使用してクラスを構築することもできます。1つのタイプのオブジェクトに他のタイプを保持させることができます。 すべてがPythonのオブジェクトであると考えると、これはクラスが言語の他のすべてを保持できることを意味します。
違い
ただし、PythonとC ++を比較する場合、いくつかの違いがあります。 最初の2つは関連しています。
最初の違いは、Pythonにはクラスのアクセス修飾子の概念がないことです。 クラスオブジェクト内のすべてはパブリックです。 Pythonコミュニティは、単一のアンダースコアで始まるクラスのメンバーはすべてプライベートとして扱われるという規則を開発しました。 これは言語によって強制されるものではありませんが、うまく機能しているようです。
すべてのクラスメンバとメソッドがPythonでパブリックであるという事実は、2番目の違いにつながります。Pythonには、C ++よりもはるかに弱いカプセル化サポートがあります。
前述のように、単一のアンダースコア規則により、実用的なコードベースでは、理論的な意味よりもはるかに問題が少なくなります。 一般に、この規則に違反し、クラスの内部動作に依存しているユーザーは、トラブルを求めています。
演算子のオーバーロードとDunderメソッド
C +では、*演算子のオーバーロード*を追加できます。 これらを使用すると、特定のデータ型に対する特定の構文演算子( `==`など)の動作を定義できます。 通常、これはクラスのより自然な使用法を追加するために使用されます。 `== +`演算子の場合、クラスの2つのオブジェクトが等しいことの意味を正確に定義できます。
一部の開発者が把握するのに長い時間がかかる1つの違いは、Pythonでの演算子のオーバーロードの欠如を回避する方法です。 Pythonのオブジェクトがすべて標準のコンテナで機能するのは素晴らしいことですが、==演算子で新しいクラスの2つのオブジェクトを詳細に比較したい場合はどうでしょうか。 C +では、クラスに `+ operator ==()`を作成し、比較を行います。
Pythonには、言語全体で非常に一貫して使用されている同様の構造があります:dunder methods。 Dunderメソッドの名前は、すべてアンダースコアまたは「d-under」で始まるため、名前が付けられます。
Pythonのオブジェクトを操作する組み込み関数の多くは、そのオブジェクトのdunder methodsの呼び出しによって処理されます。 上記の例では、クラスに__eq__()を追加して、好きなように凝った比較を行うことができます。
class MyFancyComparisonClass():
def __eq__(self, other):
return Trueこれにより、クラスの他のインスタンスと同じ方法で比較するクラスが生成されます。 特に有用ではありませんが、ポイントを示しています。
Pythonには多数のdunderメソッドが使用されており、組み込み関数はそれらを広範囲に利用しています。 たとえば、__lt__()を追加すると、Pythonは2つのオブジェクトの相対的な順序を比較できます。 これは、<演算子が機能するだけでなく、>、<=、および>=も機能することを意味します。
さらに良いことに、リストに新しいクラスのオブジェクトが複数ある場合は、リストでsorted()を使用でき、それらは__lt__()を使用して並べ替えられます。
もう一度、PythonとC ++の比較表を見てみましょう。
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
|
単一型変数 |
x |
|
複数型変数 |
x |
|
理解度 |
x |
|
組み込みアルゴリズムの豊富なセット |
x |
x |
静的入力 |
x |
|
動的な入力 |
x |
|
厳密なカプセル化 |
x |
両方の言語でオブジェクト指向のコーディングを見てきたので、PythonとC ++がメモリ内のオブジェクトを管理する方法を見てみましょう。
メモリ管理
PythonとCを比較する場合の最大の違いの1つは、それらがメモリを処理する方法です。 CとPythonの名前の変数に関するセクションで見たように、Pythonにはポインターがなく、メモリを直接簡単に操作することもできません。 そのレベルの制御が必要な場合もありますが、ほとんどの場合、その必要はありません。
メモリロケーションの直接制御を放棄すると、いくつかの利点があります。 メモリの所有権を心配したり、メモリが割り当てられた後にメモリが一度だけ解放されるようにする必要はありません。 また、オブジェクトがスタックまたはヒープに割り当てられているかどうかを心配する必要もありません。これは、C ++開発者の手始めにトリップする傾向があります。
Pythonはこれらの問題をすべて管理します。 これを行うために、Pythonのすべては、Pythonのobjectから派生したクラスです。 これにより、Pythonインタープリターは、まだ使用中のオブジェクトと解放可能なオブジェクトを追跡する手段として、参照カウントを実装できます。
もちろん、この便利さには代償が伴います。 割り当てられたメモリオブジェクトを解放するために、Pythonは時々garbage collectorと呼ばれるものを実行する必要があります。これは、未使用のメモリオブジェクトを見つけて解放します。
Note: CPythonには複雑なmemory management schemeがあります。つまり、メモリを解放しても、必ずしもメモリがオペレーティングシステムに戻されるとは限りません。
Pythonは2つのツールを使用してメモリを解放します。
-
参照カウントコレクター
-
世代コレクター
これらを個別に見てみましょう。
参照カウントコレクター
参照カウントコレクターは、標準のPythonインタープリターの基本であり、常に実行されています。 これは、プログラムの実行中に、特定のメモリブロック(常にPythonobject)に名前が付けられた回数を追跡することで機能します。 多くのルールは、参照カウントがインクリメントまたはデクリメントされるタイミングを説明しますが、1つのケースの例で明確になる場合があります。
>>>
1 >>> x = 'A long string'
2 >>> y = x
3 >>> del x
4 >>> del y上記の例では、1行目で文字列"A long string"を含む新しいオブジェクトが作成されています。 次に、このオブジェクトに名前xを配置し、オブジェクトの参照カウントを1に増やします。

2行目では、同じオブジェクトに名前を付けるためにyを割り当てます。これにより、参照カウントが2に増加します。
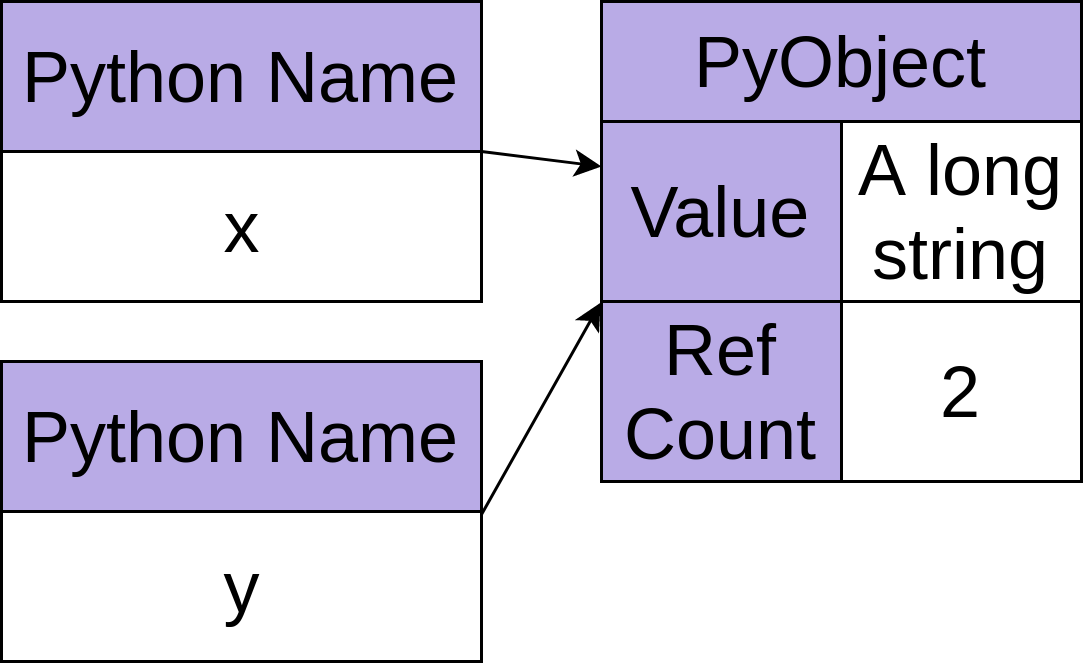
3行目でxを使用してdelを呼び出すと、オブジェクトへの参照の1つが削除され、カウントが1に戻ります。

最後に、オブジェクトへの最後の参照であるyを削除すると、その参照カウントはゼロになり、参照カウントガベージコレクターによって解放できます。 この時点ですぐに解放される場合とされない場合がありますが、通常、開発者にとっては問題ではありません。

これにより、解放する必要があるオブジェクトの多くを見つけて解放しますが、キャッチできない状況がいくつかあります。 そのためには、世代別ガベージコレクタが必要です。
世代別ガベージコレクター
参照カウントスキームの大きな穴の1つは、プログラムが参照のサイクルを構築できることです。ここで、オブジェクトAにはオブジェクトBへの参照があり、オブジェクトAへの参照があります。 s。 この状況に陥ることは完全に可能であり、コード内でいずれのオブジェクトも参照しません。 この場合、どちらのオブジェクトも参照カウントが0になることはありません。
generational garbage collectorには、この記事の範囲を超える複雑なアルゴリズムが含まれていますが、これらの孤立した参照サイクルの一部が検出され、それらが解放されます。 in the documentationで説明されている設定によって制御される場合があります。 これらのパラメーターの1つは、このガベージコレクターを完全に無効にすることです。
ガベージコレクションが不要な場合
PythonとCを比較する場合、2つのツールを比較する場合のように、それぞれの利点にはトレードオフが伴います。 Pythonは明示的なメモリ管理を必要としませんが、ガベージコレクションに予想よりも長い時間がかかる場合があります。 Cの場合は逆になります。プログラムの応答時間は一定ですが、メモリの管理により多くの労力を費やす必要があります。
多くのプログラムでは、時折発生するガーベッジコレクションのヒットは重要ではありません。 10秒間しか実行されないスクリプトを作成している場合、違いに気付くことはほとんどありません。 ただし、状況によっては、一貫した応答時間が必要です。 リアルタイムシステムは優れた例であり、一定の時間内にハードウェアに応答することがシステムの適切な動作に不可欠な場合があります。
ハードリアルタイムの要件を備えたシステムは、Pythonが言語の選択肢として不適切なシステムの一部です。 タイミングが確実である、厳密に制御されたシステムを持つことは、C ++の良い使用法です。 これらは、プロジェクトの言語を決定する際に考慮すべき問題の種類です。
Python対C ++チャートを更新する時間:
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
|
単一型変数 |
x |
|
複数型変数 |
x |
|
理解度 |
x |
|
組み込みアルゴリズムの豊富なセット |
x |
x |
静的入力 |
x |
|
動的な入力 |
x |
|
厳密なカプセル化 |
x |
|
ダイレクトメモリ制御 |
x |
|
ガベージコレクション |
x |
スレッド化、マルチプロセッシング、および非同期IO
C ++とPythonの並行性モデルは似ていますが、結果と利点が異なります。 どちらの言語も、スレッド化、マルチプロセッシング、および非同期IO操作をサポートしています。 これらのそれぞれを見てみましょう。
スレッディング
CとPythonの両方にスレッドが組み込まれていますが、解決する問題によっては、結果が著しく異なる場合があります。 多くの場合、パフォーマンスの問題に対処するためにhttps://realpython.com/intro-to-python-threading/[threading]が使用されます。 Cでは、スレッドはマルチプロセッサシステムのコアを最大限に活用できるため、スレッドは計算上の問題とI / Oバウンドの問題の両方に対して一般的なスピードアップを提供できます。
一方、Pythonは、スレッドの実装を簡素化するために、Global Interpreter LockまたはGILを使用するという設計上のトレードオフを行っています。 GILには多くの利点がありますが、欠点は、複数のコアがある場合でも、一度に1つのスレッドしか実行されないことです。
一度に複数のWebページを取得するなど、問題がI / Oバウンドである場合、この制限はあまり気にしません。 Pythonのより簡単なスレッドモデルとinter-thread communicationsの組み込みメソッドに感謝します。 ただし、問題がCPUバウンドである場合、GILはパフォーマンスをシングルプロセッサのパフォーマンスに制限します。 幸いなことに、Pythonのマルチプロセッシングライブラリには、スレッドライブラリと同様のインターフェースがあります。
マルチプロセッシング
PythonでのMultiprocessingのサポートは、標準ライブラリに組み込まれています。 複数のプロセスを起動し、それらの間で情報を共有できるようにするクリーンなインターフェイスがあります。 プロセスのプールを作成し、いくつかの手法を使用してそれらに作業を分散できます。
Pythonは同様のOSプリミティブを使用して新しいプロセスを作成しますが、低レベルの複雑さの多くは開発者から隠されています。
C ++は、マルチプロセッシングのサポートを提供するためにfork()に依存しています。 これにより、複数のプロセスを作成する際のすべてのコントロールと問題に直接アクセスできますが、はるかに複雑です。
非同期IO
PythonとCはどちらも非同期IOルーチンをサポートしていますが、処理方法は異なります。 Cでは、std::asyncメソッドは、スレッド化を使用して、操作の非同期IOの性質を実現する可能性があります。 Pythonでは、Async IOコードは単一のスレッドでのみ実行されます。
ここにもトレードオフがあります。 個別のスレッドを使用することにより、C ++非同期IOコードは、計算的にバインドされた問題により高速に実行できます。 Async IO実装で使用されるPythonタスクはより軽量であるため、I / Oに関連する問題を処理するために多数のタスクをスピンアップする方が高速です。
このセクションでは、Python対C ++の比較表は変更されていません。 両方の言語は、速度と利便性の間のさまざまなトレードオフで、同時実行オプションの完全な範囲をサポートします。
その他の問題
PythonとC ++を比較し、Pythonをツールベルトに追加することを検討している場合、他にも考慮すべきことがいくつかあります。 現在のエディターまたはIDEは確かにPythonで動作しますが、特定の拡張機能または言語パックを追加することもできます。 Python固有であるため、PyCharmを一見する価値もあります。
embed Python in C++が必要な場合は、Python/C APIを使用できます。
最後に、Cスキルを使用してPythonを拡張して機能を追加したり、Pythonコード内から既存のCライブラリを呼び出したりする方法がいくつかあります。 CTypes、Cython、CFFI、Boost.Python、Swigなどのツールを使用すると、これらの言語を組み合わせて、それぞれを最高の状態で使用できます。
要約:PythonとC ++
PythonとC ++の違いを読んで考えてみました。 Pythonの構文は簡単で、シャープなエッジは少ないですが、すべての問題に完全に適合するわけではありません。 これら2つの言語の構文、メモリ管理、処理、および他のいくつかの側面を見てきました。
PythonとC ++の比較表を最後に見てみましょう。
| 特徴 | Python | C++ |
|---|---|---|
より高速な実行 |
x |
|
クロスプラットフォームの実行 |
x |
|
単一型変数 |
x |
|
複数型変数 |
x |
|
理解度 |
x |
|
組み込みアルゴリズムの豊富なセット |
x |
x |
静的入力 |
x |
|
動的な入力 |
x |
|
厳密なカプセル化 |
x |
|
ダイレクトメモリ制御 |
x |
|
ガベージコレクション |
x |
PythonとC ++を比較している場合、グラフから、一方が他方より優れているわけではないことがわかります。 それらはそれぞれ、さまざまなユースケースに適したツールです。 ネジを打つためにハンマーを使用しないのと同じように、仕事に適切な言語を使用すると、人生が楽になります!
結論
おめでとうございます。 PythonとC ++の両方の長所と短所のいくつかを見てきました。 各言語の機能のいくつかと、それらがどのように似ているかを学びました。
必要なときにC ++が優れていることがわかりました。
-
高速な実行速度(開発速度を犠牲にする可能性があります)
-
メモリの完全な制御
逆に、Pythonは次の場合に最適です。
-
高速な開発速度(潜在的に実行速度を犠牲にして)
-
管理メモリ
次のプロジェクトに関しては、賢い言語を選択する準備が整いました!