Python Pandas:知らないトリックと機能
パンダは、分析、データ処理、およびデータサイエンスのための基礎ライブラリです。 膨大なオプションと深さを持つ巨大なプロジェクトです。
このチュートリアルでは、コードの可読性、汎用性、速度を向上させる、あまり使用されていないが慣用的なPandas機能について説明します。à laはBuzzfeedリストです。
PythonのPandasライブラリのコアコンセプトに慣れている場合は、この記事でこれまでに出会ったことのない秘orを見つけていただければ幸いです。 (ライブラリを使い始めたばかりの場合は、10 Minutes to Pandasから始めるのがよいでしょう。)
Note:この記事の例は、Pandasバージョン0.23.2およびPython3.6.6でテストされています。 ただし、古いバージョンでも有効である必要があります。
1. 通訳者の起動時にオプションと設定を構成する
以前にパンダの豊富なoptions and settingsシステムに出くわしたことがあるかもしれません。
特にスクリプト環境で作業している場合、インタープリターの起動時にカスタマイズされたPandasオプションを設定することは、生産性を大幅に節約します。 pd.set_option()を使用して、PythonまたはIPythonスタートアップファイルを使用して心ゆくまで設定できます。
オプションは、pd.set_option('display.max_colwidth', 25)などのドット表記を使用します。これは、ネストされたオプションの辞書に適しています。
import pandas as pd
def start():
options = {
'display': {
'max_columns': None,
'max_colwidth': 25,
'expand_frame_repr': False, # Don't wrap to multiple pages
'max_rows': 14,
'max_seq_items': 50, # Max length of printed sequence
'precision': 4,
'show_dimensions': False
},
'mode': {
'chained_assignment': None # Controls SettingWithCopyWarning
}
}
for category, option in options.items():
for op, value in option.items():
pd.set_option(f'{category}.{op}', value) # Python 3.6+
if __name__ == '__main__':
start()
del start # Clean up namespace in the interpreterインタープリターセッションを起動すると、起動スクリプトのすべてが実行され、オプションのスイートとともにPandasが自動的にインポートされていることがわかります。
>>>
>>> pd.__name__
'pandas'
>>> pd.get_option('display.max_rows')
14UCI Machine Learning Repositoryによってホストされているabaloneのデータを使用して、スタートアップファイルに設定されたフォーマットを示しましょう。 データは、浮動小数点数の4桁の精度で14行で切り捨てられます。
>>>
>>> url = ('https://archive.ics.uci.edu/ml/'
... 'machine-learning-databases/abalone/abalone.data')
>>> cols = ['sex', 'length', 'diam', 'height', 'weight', 'rings']
>>> abalone = pd.read_csv(url, usecols=[0, 1, 2, 3, 4, 8], names=cols)
>>> abalone
sex length diam height weight rings
0 M 0.455 0.365 0.095 0.5140 15
1 M 0.350 0.265 0.090 0.2255 7
2 F 0.530 0.420 0.135 0.6770 9
3 M 0.440 0.365 0.125 0.5160 10
4 I 0.330 0.255 0.080 0.2050 7
5 I 0.425 0.300 0.095 0.3515 8
6 F 0.530 0.415 0.150 0.7775 20
# ...
4170 M 0.550 0.430 0.130 0.8395 10
4171 M 0.560 0.430 0.155 0.8675 8
4172 F 0.565 0.450 0.165 0.8870 11
4173 M 0.590 0.440 0.135 0.9660 10
4174 M 0.600 0.475 0.205 1.1760 9
4175 F 0.625 0.485 0.150 1.0945 10
4176 M 0.710 0.555 0.195 1.9485 12このデータセットは、他の例でも後で表示されます。
2. Pandasのテストモジュールでおもちゃのデータ構造を作成する
Pandasのtestingモジュールの奥に隠されているのは、準現実的なシリーズとデータフレームをすばやく構築するための便利な関数です。
>>>
>>> import pandas.util.testing as tm
>>> tm.N, tm.K = 15, 3 # Module-level default rows/columns
>>> import numpy as np
>>> np.random.seed(444)
>>> tm.makeTimeDataFrame(freq='M').head()
A B C
2000-01-31 0.3574 -0.8804 0.2669
2000-02-29 0.3775 0.1526 -0.4803
2000-03-31 1.3823 0.2503 0.3008
2000-04-30 1.1755 0.0785 -0.1791
2000-05-31 -0.9393 -0.9039 1.1837
>>> tm.makeDataFrame().head()
A B C
nTLGGTiRHF -0.6228 0.6459 0.1251
WPBRn9jtsR -0.3187 -0.8091 1.1501
7B3wWfvuDA -1.9872 -1.0795 0.2987
yJ0BTjehH1 0.8802 0.7403 -1.2154
0luaYUYvy1 -0.9320 1.2912 -0.2907これらは約30個あり、モジュールオブジェクトでdir()を呼び出すと、完全なリストを表示できます。 ここにいくつかあります:
>>>
>>> [i for i in dir(tm) if i.startswith('make')]
['makeBoolIndex',
'makeCategoricalIndex',
'makeCustomDataframe',
'makeCustomIndex',
# ...,
'makeTimeSeries',
'makeTimedeltaIndex',
'makeUIntIndex',
'makeUnicodeIndex']これらは、ベンチマーク、アサーションのテスト、およびあまり馴染みのないPandasメソッドの実験に役立ちます。
3. アクセサメソッドを活用する
おそらく、accessorという用語を聞いたことがあるでしょう。これは、ゲッターに似ています(ただし、Pythonではゲッターとセッターはあまり使用されません)。 ここでの目的のために、Pandasアクセサーは、追加のメソッドへのインターフェイスとして機能するプロパティと考えることができます。
パンダシリーズには次の3つがあります。
>>>
>>> pd.Series._accessors
{'cat', 'str', 'dt'}はい、上記の定義は一口ですので、内部について説明する前にいくつかの例を見てみましょう。
.catはカテゴリデータ用、.strは文字列(オブジェクト)データ用、.dtは日時のようなデータ用です。 .strから始めましょう。パンダシリーズ内の単一のフィールドとして、生の都市/州/郵便番号データがあると想像してください。
パンダの文字列メソッドはvectorizedです。つまり、明示的なforループなしで配列全体を操作します。
>>>
>>> addr = pd.Series([
... 'Washington, D.C. 20003',
... 'Brooklyn, NY 11211-1755',
... 'Omaha, NE 68154',
... 'Pittsburgh, PA 15211'
... ])
>>> addr.str.upper()
0 WASHINGTON, D.C. 20003
1 BROOKLYN, NY 11211-1755
2 OMAHA, NE 68154
3 PITTSBURGH, PA 15211
dtype: object
>>> addr.str.count(r'\d') # 5 or 9-digit zip?
0 5
1 9
2 5
3 5
dtype: int64より複雑な例として、3つの都市/州/ ZIPコンポーネントをDataFrameフィールドにきちんと分離したいとします。
regular expressionを.str.extract()に渡して、シリーズの各セルの一部を「抽出」できます。 .str.extract()では、.strはアクセサーであり、.str.extract()はアクセサーメソッドです。
>>>
>>> regex = (r'(?P[A-Za-z ]+), ' # One or more letters
... r'(?P[A-Z]{2}) ' # 2 capital letters
... r'(?P\d{5}(?:-\d{4})?)') # Optional 4-digit extension
...
>>> addr.str.replace('.', '').str.extract(regex)
city state zip
0 Washington DC 20003
1 Brooklyn NY 11211-1755
2 Omaha NE 68154
3 Pittsburgh PA 15211 これは、メソッドチェーンと呼ばれるものも示しています。ここでは、addr.str.replace('.', '')の結果に対して.str.extract(regex)が呼び出され、ピリオドの使用がクリーンアップされて、2文字の状態の省略形が取得されます。
addr.apply(re.findall, ...)のようなものではなく、そもそもこれらのアクセサメソッドを使用する必要がある理由として、これらのアクセサメソッドがどのように機能するかについて少し知っておくと役に立ちます。
各アクセサーはそれ自体が真正なPythonクラスです。
-
.strはStringMethodsにマップされます。 -
.dtはCombinedDatetimelikePropertiesにマップされます。 -
.catはCategoricalAccessorにルーティングします。
これらのスタンドアロンクラスは、CachedAccessorを使用してSeriesクラスに「アタッチ」されます。 クラスがCachedAccessorでラップされているときに、ちょっとした魔法が起こります。
CachedAccessorは、「キャッシュされたプロパティ」の設計に着想を得ています。プロパティは、インスタンスごとに1回だけ計算され、通常の属性に置き換えられます。 これは、Pythonの記述子プロトコルの一部であるhttps://docs.python.org/reference/datamodel.html#object。get [.__get__()メソッド]をオーバーロードすることによって行われます。
Note:これがどのように機能するかの内部について詳しく知りたい場合は、キャッシュされたプロパティデザインのPython Descriptor HOWTOとthis postを参照してください。 Python 3では、同様の機能を提供するfunctools.lru_cache()も導入されました。 aiohttpパッケージなど、このパターンのいたるところに例があります。
2番目のアクセサー.dtは、日時のようなデータ用です。 技術的にはパンダのDatetimeIndexに属しており、シリーズで呼び出されると、最初にDatetimeIndexに変換されます。
>>>
>>> daterng = pd.Series(pd.date_range('2017', periods=9, freq='Q'))
>>> daterng
0 2017-03-31
1 2017-06-30
2 2017-09-30
3 2017-12-31
4 2018-03-31
5 2018-06-30
6 2018-09-30
7 2018-12-31
8 2019-03-31
dtype: datetime64[ns]
>>> daterng.dt.day_name()
0 Friday
1 Friday
2 Saturday
3 Sunday
4 Saturday
5 Saturday
6 Sunday
7 Monday
8 Sunday
dtype: object
>>> # Second-half of year only
>>> daterng[daterng.dt.quarter > 2]
2 2017-09-30
3 2017-12-31
6 2018-09-30
7 2018-12-31
dtype: datetime64[ns]
>>> daterng[daterng.dt.is_year_end]
3 2017-12-31
7 2018-12-31
dtype: datetime64[ns]3番目のアクセサである.catは、カテゴリデータ専用であり、すぐにそのown sectionに表示されます。
4. コンポーネント列からDatetimeIndexを作成する
上記のdaterngのように、日時のようなデータについて言えば、日付または日時を形成する複数のコンポーネント列からパンダDatetimeIndexを作成することができます。
>>>
>>> from itertools import product
>>> datecols = ['year', 'month', 'day']
>>> df = pd.DataFrame(list(product([2017, 2016], [1, 2], [1, 2, 3])),
... columns=datecols)
>>> df['data'] = np.random.randn(len(df))
>>> df
year month day data
0 2017 1 1 -0.0767
1 2017 1 2 -1.2798
2 2017 1 3 0.4032
3 2017 2 1 1.2377
4 2017 2 2 -0.2060
5 2017 2 3 0.6187
6 2016 1 1 2.3786
7 2016 1 2 -0.4730
8 2016 1 3 -2.1505
9 2016 2 1 -0.6340
10 2016 2 2 0.7964
11 2016 2 3 0.0005
>>> df.index = pd.to_datetime(df[datecols])
>>> df.head()
year month day data
2017-01-01 2017 1 1 -0.0767
2017-01-02 2017 1 2 -1.2798
2017-01-03 2017 1 3 0.4032
2017-02-01 2017 2 1 1.2377
2017-02-02 2017 2 2 -0.2060最後に、古い個々の列をドロップして、シリーズに変換できます。
>>>
>>> df = df.drop(datecols, axis=1).squeeze()
>>> df.head()
2017-01-01 -0.0767
2017-01-02 -1.2798
2017-01-03 0.4032
2017-02-01 1.2377
2017-02-02 -0.2060
Name: data, dtype: float64
>>> df.index.dtype_str
'datetime64[ns]DataFrameを渡すことの背後にある直感は、DataFrameは列名がキーであり、個々の列(シリーズ)が辞書の値であるPython辞書に似ているということです。 この場合、pd.to_datetime(df[datecols].to_dict(orient='list'))も機能するのはそのためです。 これは、datetime.datetime(year=2000, month=1, day=15, hour=10)などのキーワード引数を渡すPythonのdatetime.datetimeの構築を反映しています。
5. カテゴリデータを使用して時間とスペースを節約する
パンダの強力な機能の1つは、そのCategoricaldtypeです。
RAM内のギガバイトのデータを常に操作しているわけではない場合でも、大規模なDataFrameでの簡単な操作が数秒以上ハングアップする場合があります。
Pandasobject dtypeは、多くの場合、カテゴリデータへの変換に最適な候補です。 (objectは、Pythonstr、異種データ型、または「その他」の型のコンテナーです。)文字列はメモリ内でかなりの量のスペースを占有します。
>>>
>>> colors = pd.Series([
... 'periwinkle',
... 'mint green',
... 'burnt orange',
... 'periwinkle',
... 'burnt orange',
... 'rose',
... 'rose',
... 'mint green',
... 'rose',
... 'navy'
... ])
...
>>> import sys
>>> colors.apply(sys.getsizeof)
0 59
1 59
2 61
3 59
4 61
5 53
6 53
7 59
8 53
9 53
dtype: int64Note:sys.getsizeof()を使用して、シリーズの個々の値が占めるメモリを示しました。 これらは、最初はオーバーヘッドがあるPythonオブジェクトであることに注意してください。 (sys.getsizeof('')は49バイトを返します。)
colors.memory_usage()もあります。これは、メモリ使用量を合計し、基になるNumPy配列の.nbytes属性に依存します。 これらの詳細に行き詰まりすぎないようにしてください。重要なのは、次に示すように、型変換から生じる相対的なメモリ使用量です。
さて、上記のユニークな色を使用して、それぞれをより少ないスペース占有整数にマッピングできたらどうでしょうか? 以下はその単純な実装です。
>>>
>>> mapper = {v: k for k, v in enumerate(colors.unique())}
>>> mapper
{'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
>>> as_int = colors.map(mapper)
>>> as_int
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int64
>>> as_int.apply(sys.getsizeof)
0 24
1 28
2 28
3 24
4 28
5 28
6 28
7 28
8 28
9 28
dtype: int64Note:これと同じことを行う別の方法は、パンダのpd.factorize(colors)を使用することです。
>>>
>>> pd.factorize(colors)[0]
array([0, 1, 2, 0, 2, 3, 3, 1, 3, 4])いずれにせよ、オブジェクトを列挙型(カテゴリ変数)としてエンコードしています。
完全な文字列がobject dtypeで使用される場合と比較して、メモリ使用量がほぼ半分に削減されることにすぐに気付くでしょう。
accessorsのセクションの前半で、.cat(カテゴリ)アクセサについて説明しました。 上記のmapperは、PandasのCategoricaldtypeで内部的に何が起こっているかを大まかに示しています。
「
Categoricalのメモリ使用量は、カテゴリの数とデータの長さに比例します。 対照的に、objectdtypeは、データの長さの定数倍です。」 (Source)
上記のcolorsでは、一意の値(カテゴリ)ごとに2つの値の比率があります。
>>>
>>> len(colors) / colors.nunique()
2.0その結果、Categoricalへの変換によるメモリの節約は良好ですが、それほど大きくはありません。
>>>
>>> # Not a huge space-saver to encode as Categorical
>>> colors.memory_usage(index=False, deep=True)
650
>>> colors.astype('category').memory_usage(index=False, deep=True)
495ただし、多くのデータと少数の一意の値(人口統計またはアルファベットのテストスコアのデータを考える)で上記の割合を吹き飛ばすと、必要なメモリの削減は10倍以上になります。
>>>
>>> manycolors = colors.repeat(10)
>>> len(manycolors) / manycolors.nunique() # Much greater than 2.0x
20.0
>>> manycolors.memory_usage(index=False, deep=True)
6500
>>> manycolors.astype('category').memory_usage(index=False, deep=True)
585ボーナスは、計算効率も向上することです。カテゴリのSeriesの場合、Seriesの元の各要素ではなく、文字列操作are performed on the .cat.categories attributeが使用されます。
つまり、操作は一意のカテゴリごとに1回実行され、結果は値にマップされます。 カテゴリデータには、カテゴリを操作するための属性とメソッドへのウィンドウである.catアクセサがあります。
>>>
>>> ccolors = colors.astype('category')
>>> ccolors.cat.categories
Index(['burnt orange', 'mint green', 'navy', 'periwinkle', 'rose'], dtype='object')実際、手動で行った上記の例に似たものを再現できます。
>>>
>>> ccolors.cat.codes
0 3
1 1
2 0
3 3
4 0
5 4
6 4
7 1
8 4
9 2
dtype: int8以前の手動出力を正確に模倣するために必要なことは、コードを並べ替えることだけです。
>>>
>>> ccolors.cat.reorder_categories(mapper).cat.codes
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int8dtypeがNumPyのint8であり、-127から128までの値を取ることができる8-bit signed integerであることに注意してください。 (メモリ内の値を表すために必要なのは1バイトだけです。 64ビットの符号付きintsは、メモリ使用量の点でやり過ぎです。)荒削りな例では、デフォルトでint64データが生成されましたが、Pandasは、カテゴリデータを可能な限り最小の数値dtypeにダウンキャストするのに十分スマートです。 。
.catの属性のほとんどは、基になるカテゴリ自体の表示と操作に関連しています。
>>>
>>> [i for i in dir(ccolors.cat) if not i.startswith('_')]
['add_categories',
'as_ordered',
'as_unordered',
'categories',
'codes',
'ordered',
'remove_categories',
'remove_unused_categories',
'rename_categories',
'reorder_categories',
'set_categories']ただし、いくつかの注意事項があります。 カテゴリデータは一般に柔軟性が低くなります。 たとえば、以前に表示されなかった値を挿入する場合は、最初にこの値を.categoriesコンテナに追加する必要があります。
>>>
>>> ccolors.iloc[5] = 'a new color'
# ...
ValueError: Cannot setitem on a Categorical with a new category,
set the categories first
>>> ccolors = ccolors.cat.add_categories(['a new color'])
>>> ccolors.iloc[5] = 'a new color' # No more ValueError新しい計算を導出するのではなく、値を設定したりデータを再形成したりすることを計画している場合、Categoricalタイプは機敏性が低い可能性があります。
6. 反復によるGroupbyオブジェクトのイントロスペクト
df.groupby('x')を呼び出すと、結果のPandasgroupbyオブジェクトは少し不透明になる可能性があります。 このオブジェクトは遅延的にインスタンス化され、それ自体に意味のある表現はありません。
example 1のアワビデータセットでデモンストレーションできます。
>>>
>>> abalone['ring_quartile'] = pd.qcut(abalone.rings, q=4, labels=range(1, 5))
>>> grouped = abalone.groupby('ring_quartile')
>>> grouped
さて、これでgroupbyオブジェクトができましたが、これは何で、どのように表示されますか?
grouped.apply(func)のようなものを呼び出す前に、groupbyオブジェクトが反復可能であるという事実を利用できます。
>>>
>>> help(grouped.__iter__)
Groupby iterator
Returns
-------
Generator yielding sequence of (name, subsetted object)
for each groupgrouped.__iter__()によって生成される各「もの」は、(name, subsetted object)のタプルです。ここで、nameはグループ化する列の値であり、subsetted objectは次のようなDataFrameです。指定したグループ化条件に基づく元のDataFrameのサブセットです。 つまり、データはグループごとに分割されます。
>>>
>>> for idx, frame in grouped:
... print(f'Ring quartile: {idx}')
... print('-' * 16)
... print(frame.nlargest(3, 'weight'), end='\n\n')
...
Ring quartile: 1
----------------
sex length diam height weight rings ring_quartile
2619 M 0.690 0.540 0.185 1.7100 8 1
1044 M 0.690 0.525 0.175 1.7005 8 1
1026 M 0.645 0.520 0.175 1.5610 8 1
Ring quartile: 2
----------------
sex length diam height weight rings ring_quartile
2811 M 0.725 0.57 0.190 2.3305 9 2
1426 F 0.745 0.57 0.215 2.2500 9 2
1821 F 0.720 0.55 0.195 2.0730 9 2
Ring quartile: 3
----------------
sex length diam height weight rings ring_quartile
1209 F 0.780 0.63 0.215 2.657 11 3
1051 F 0.735 0.60 0.220 2.555 11 3
3715 M 0.780 0.60 0.210 2.548 11 3
Ring quartile: 4
----------------
sex length diam height weight rings ring_quartile
891 M 0.730 0.595 0.23 2.8255 17 4
1763 M 0.775 0.630 0.25 2.7795 12 4
165 M 0.725 0.570 0.19 2.5500 14 4関連して、groupbyオブジェクトには.groupsとグループゲッター.get_group()もあります。
>>>
>>> grouped.groups.keys()
dict_keys([1, 2, 3, 4])
>>> grouped.get_group(2).head()
sex length diam height weight rings ring_quartile
2 F 0.530 0.420 0.135 0.6770 9 2
8 M 0.475 0.370 0.125 0.5095 9 2
19 M 0.450 0.320 0.100 0.3810 9 2
23 F 0.550 0.415 0.135 0.7635 9 2
39 M 0.355 0.290 0.090 0.3275 9 2これにより、実行している操作が目的の操作であることをもう少し確信できるようになります。
>>>
>>> grouped['height', 'weight'].agg(['mean', 'median'])
height weight
mean median mean median
ring_quartile
1 0.1066 0.105 0.4324 0.3685
2 0.1427 0.145 0.8520 0.8440
3 0.1572 0.155 1.0669 1.0645
4 0.1648 0.165 1.1149 1.0655groupedで実行する計算に関係なく、単一のPandasメソッドであろうとカスタムビルド関数であろうと、これらの「サブフレーム」のそれぞれは、その呼び出し可能オブジェクトへの引数として1つずつ渡されます。 これが、「分割適用結合」という用語の由来です。グループごとにデータを分割し、グループごとの計算を実行し、集約された方法で再結合します。
グループが実際にどのように見えるかを正確に視覚化できない場合は、単にグループを繰り返していくつかを印刷するだけで非常に便利です。
7. メンバーシップビニングにこのマッピングトリックを使用する
たとえば、シリーズと対応する「マッピングテーブル」があり、各値がマルチメンバーグループに属しているか、グループがまったくないとします。
>>>
>>> countries = pd.Series([
... 'United States',
... 'Canada',
... 'Mexico',
... 'Belgium',
... 'United Kingdom',
... 'Thailand'
... ])
...
>>> groups = {
... 'North America': ('United States', 'Canada', 'Mexico', 'Greenland'),
... 'Europe': ('France', 'Germany', 'United Kingdom', 'Belgium')
... }つまり、countriesを次の結果にマップする必要があります。
>>>
0 North America
1 North America
2 North America
3 Europe
4 Europe
5 other
dtype: objectここで必要なのは、Pandasのpd.cut()に似た関数ですが、カテゴリメンバーシップに基づいてビニングするためのものです。 これを模倣するために、example #5ですでに見たpd.Series.map()を使用できます。
from typing import Any
def membership_map(s: pd.Series, groups: dict,
fillvalue: Any=-1) -> pd.Series:
# Reverse & expand the dictionary key-value pairs
groups = {x: k for k, v in groups.items() for x in v}
return s.map(groups).fillna(fillvalue)これは、countries内の国ごとにgroupsを介してネストされたPythonループよりも大幅に高速である必要があります。
これがテストドライブです。
>>>
>>> membership_map(countries, groups, fillvalue='other')
0 North America
1 North America
2 North America
3 Europe
4 Europe
5 other
dtype: objectここで何が起こっているのかを分析しましょう。 (補足:これは、Pythonのデバッガーpdbを使用して関数のスコープにステップインし、関数に対してローカルな変数を調べるのに最適な場所です。)
目的は、groupsの各グループを整数にマップすることです。 ただし、Series.map()は'ab'を認識しません。各グループの各文字が整数にマップされた、分割されたバージョンが必要です。 これはdictionary comprehensionが行っていることです:
>>>
>>> groups = dict(enumerate(('ab', 'cd', 'xyz')))
>>> {x: k for k, v in groups.items() for x in v}
{'a': 0, 'b': 0, 'c': 1, 'd': 1, 'x': 2, 'y': 2, 'z': 2}このディクショナリをs.map()に渡して、その値を対応するグループインデックスにマッピングまたは「変換」できます。
8. パンダがブール演算子を使用する方法を理解する
Pythonのoperator precedenceに精通しているかもしれません。ここで、and、not、およびorは、<、<=などの算術演算子よりも優先順位が低くなります。 、>、>=、!=、および==。 以下の2つのステートメントについて考えてみます。ここで、<と>はand演算子よりも優先されます。
>>>
>>> # Evaluates to "False and True"
>>> 4 < 3 and 5 > 4
False
>>> # Evaluates to 4 < 5 > 4
>>> 4 < (3 and 5) > 4
TrueNote:特にパンダ関連ではありませんが、短絡評価のため、3 and 5は5と評価されます。
「短絡演算子の戻り値は、最後に評価された引数です。」 (Source)
Pandas(およびPandasが構築されているNumPy)は、and、or、またはnotを使用しません。 代わりに、&、|、および~をそれぞれ使用します。これらは、通常の、正真正銘のPythonビット演算子です。
これらの演算子は、パンダによって「発明された」ものではありません。 むしろ、&、|、および~は、算術演算子よりも(低いというよりも)高い優先順位を持つ有効なPython組み込み演算子です。 (Pandasは、|演算子にマップされる.__ror__()のようなdunderメソッドをオーバーライドします。)詳細をいくらか犠牲にするために、PandasとNumPyに関連するため、「ビット単位」を「要素単位」と考えることができます。
>>>
>>> pd.Series([True, True, False]) & pd.Series([True, False, False])
0 True
1 False
2 False
dtype: boolこの概念を完全に理解することは有益です。 範囲のようなシリーズがあるとしましょう:
>>>
>>> s = pd.Series(range(10))ある時点でこの例外が発生したのを見たことがあると思います。
>>>
>>> s % 2 == 0 & s > 3
ValueError: The truth value of a Series is ambiguous.
Use a.empty, a.bool(), a.item(), a.any() or a.all().ここで何が起こっていますか? 式を括弧で段階的にバインドして、Pythonがこの式を段階的に展開する方法を説明すると便利です。
s % 2 == 0 & s > 3 # Same as above, original expression
(s % 2) == 0 & s > 3 # Modulo is most tightly binding here
(s % 2) == (0 & s) > 3 # Bitwise-and is second-most-binding
(s % 2) == (0 & s) and (0 & s) > 3 # Expand the statement
((s % 2) == (0 & s)) and ((0 & s) > 3) # The `and` operator is least-binding式s % 2 == 0 & s > 3は、((s % 2) == (0 & s)) and ((0 & s) > 3)と同等です(または((s % 2) == (0 & s)) and ((0 & s) > 3)として扱われます)。 これはexpansionと呼ばれます。x < y <= zはx < y and y <= zと同等です。
さて、そこで停止し、これをパンダ語に戻しましょう。 leftとrightと呼ぶ2つのパンダシリーズがあります。
>>>
>>> left = (s % 2) == (0 & s)
>>> right = (0 & s) > 3
>>> left and right # This will raise the same ValueError次のように、left and right形式のステートメントがleftとrightの両方をテストする真理値であることを知っています。
>>>
>>> bool(left) and bool(right)問題は、パンダの開発者がシリーズ全体の真理値(真実性)を意図的に確立していないことです。 シリーズは真ですか、それとも偽ですか? 知るか? 結果はあいまいです:
>>>
>>> bool(s)
ValueError: The truth value of a Series is ambiguous.
Use a.empty, a.bool(), a.item(), a.any() or a.all().意味のある唯一の比較は、要素ごとの比較です。 そのため、算術演算子が含まれている場合、you’ll need parentheses:
>>>
>>> (s % 2 == 0) & (s > 3)
0 False
1 False
2 False
3 False
4 True
5 False
6 True
7 False
8 True
9 False
dtype: bool要するに、上記のValueErrorがブールインデックスでポップアップするのを見る場合、おそらく最初にすべきことは、いくつかの必要な括弧を振りかけることです。
9. クリップボードからデータを読み込む
ExcelやSublime Textなどの場所からPandasデータ構造にデータを転送する必要があるのは一般的な状況です。 理想的には、データをファイルに保存し、その後ファイルをPandasに読み込むという中間ステップを実行せずに、これを実行する必要があります。
pd.read_clipboard()を使用して、コンピューターのクリップボードデータバッファーからDataFrameを読み込むことができます。 そのキーワード引数はpd.read_table()に渡されます。
これにより、構造化テキストを直接DataFrameまたはSeriesにコピーできます。 Excelでは、データは次のようになります。
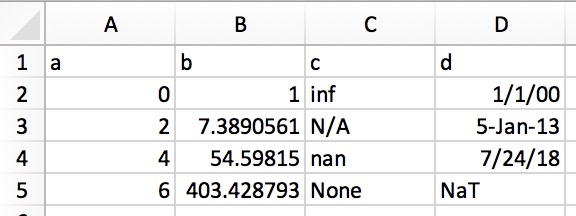
そのプレーンテキスト表現(たとえば、テキストエディター)は次のようになります。
a b c d 0 1 inf 1/1/00 2 7.389056099 N/A 5-Jan-13 4 54.59815003 nan 7/24/18 6 403.4287935 None NaT
上記のプレーンテキストを強調表示してコピーし、pd.read_clipboard()を呼び出すだけです。
>>>
>>> df = pd.read_clipboard(na_values=[None], parse_dates=['d'])
>>> df
a b c d
0 0 1.0000 inf 2000-01-01
1 2 7.3891 NaN 2013-01-05
2 4 54.5982 NaN 2018-07-24
3 6 403.4288 NaN NaT
>>> df.dtypes
a int64
b float64
c float64
d datetime64[ns]
dtype: object10. Pandasオブジェクトを圧縮形式に直接書き込む
これはリストを締めくくるのに短くて甘いです。 Pandasバージョン0.21.0では、非圧縮ファイルをメモリに隠して変換するのではなく、Pandasオブジェクトをgzip、bz2、zip、またはxz圧縮に直接書き込むことができます。 trick #1のabaloneデータを使用した例を次に示します。
abalone.to_json('df.json.gz', orient='records',
lines=True, compression='gzip')この場合、サイズの違いは11.6xです。
>>>
>>> import os.path
>>> abalone.to_json('df.json', orient='records', lines=True)
>>> os.path.getsize('df.json') / os.path.getsize('df.json.gz')
11.603035760226396このリストに追加しますか? 私たちに知らせて
うまくいけば、このリストからいくつかの便利なトリックを選んで、Pandasコードの読みやすさ、汎用性、パフォーマンスを向上させることができました。
ここでカバーされていない何かがあなたの袖にある場合は、コメントに、またはGitHub Gistとして提案を残してください。 このリストに喜んで追加し、期限が来たらクレジットを提供します。