Python Lambda関数の使用方法
PythonおよびJava、C#、さらにC ++などの他の言語では、構文にラムダ関数が追加されていますが、LISPやMLファミリの言語、Haskell、OCaml、F#などの言語では、ラムダをコアコンセプトとして使用しています。
Pythonラムダは、小さな匿名関数であり、通常のPython関数よりも制限的ではありますが簡潔な構文に従います。
この記事の終わりまでに、次のことがわかります。
-
Pythonラムダがどのようになったか
-
ラムダと通常の関数オブジェクトとの比較
-
ラムダ関数の書き方
-
Python標準ライブラリのどの関数がラムダを活用しているか
-
Pythonラムダ関数を使用または回避する場合
Notes:Pythonスタイルのベストプラクティスを露骨に無視しているように見えるlambdaを使用したコード例がいくつか表示されます。 これは、ラムダ計算の概念を説明すること、またはPythonlambdaの機能を強調することのみを目的としています。
これらの疑わしい例は、記事を進めるにつれて、より良いアプローチや代替案と対比されます。
このチュートリアルは、主に中級から上級のPythonプログラマーを対象としていますが、プログラミングやラムダ計算に興味がある好奇心to盛な人であれば誰でもアクセスできます。
このチュートリアルに含まれるすべての例は、Python 3.7でテストされています。
__ Take the Quiz:インタラクティブな「PythonLambda関数」クイズで知識をテストします。 完了すると、学習の進捗状況を経時的に追跡できるようにスコアを受け取ります。
Free Bonus:Click here to get access to a chapter from Python Tricks: The Bookは、Pythonのベストプラクティスと、より美しい+ Pythonicコードをすぐに適用できる簡単な例を示しています。
ラムダ計算
Pythonおよび他のプログラミング言語のラムダ式は、Alonzo Churchによって発明された計算モデルであるラムダ計算にルーツがあります。 ラムダ計算が導入された時期と、それがPythonエコシステムで最終的に採用された基本概念である理由を明らかにします。
歴史
Alonzo Churchは、1930年代に、純粋な抽象化に基づく言語であるlambda calculusを形式化しました。 ラムダ関数は、ラムダ抽象化とも呼ばれ、アロンゾ教会の創作の抽象化モデルへの直接の参照です。
ラムダ計算は任意の計算をエンコードできます。 これはTuring completeですが、Turing machineの概念に反して、純粋であり、状態を保持しません。
関数型言語は数学的論理とラムダ計算に起源を持ち、命令型プログラミング言語はアランチューリングが発明した状態ベースの計算モデルを採用しています。 ラムダ計算とTuring machinesの2つの計算モデルは、相互に変換できます。 この同等性は、Church-Turing hypothesisとして知られています。
関数型言語は、ラムダ計算の哲学を直接継承し、抽象化、データ変換、構成、および純度(状態および副作用なし)を重視する宣言型のプログラミングアプローチを採用しています。 関数型言語の例には、Haskell、Lisp、またはErlangが含まれます。
命令型スタイルは、ステートメントを使用したプログラミングで構成され、プログラムのフローを詳細な手順で段階的に駆動します。 このアプローチは突然変異を促進し、状態を管理する必要があります。
一部の関数型言語にはOCamlなどの命令型機能が組み込まれているのに対し、関数型言語は特にJavaにラムダ関数が導入されているため、命令型言語ファミリーに浸透しているため、両方のファミリーの分離には微妙な違いがあります。またはPython。
Pythonは本質的に関数型言語ではありませんが、早い段階でいくつかの関数型の概念を採用しました。 1994年1月に、map()、filter()、reduce()、およびlambda演算子が言語に追加されました。
最初の例
ここに、Pythonコードの機能的なスタイルに対する欲求を与えるいくつかの例を示します。
引数を返す関数であるidentity functionは、次のようにキーワードdefを使用して標準のPython関数定義で表されます。
>>>
>>> def identity(x):
... return xidentity()は引数xを取り、呼び出し時にそれを返します。
対照的に、Pythonラムダ構造を使用すると、次の結果が得られます。
>>>
>>> lambda x: x上記の例では、式は次のもので構成されています。
-
キーワード:
lambda -
束縛変数:
x -
体:
x
Note:この記事のコンテキストでは、bound variableはラムダ関数の引数です。
対照的に、free variableはバインドされておらず、式の本体で参照される場合があります。 自由変数は、定数または関数の囲みスコープで定義された変数です。
次のように、もう少し手の込んだ例、引数に1を追加する関数を書くことができます。
>>>
>>> lambda x: x + 1関数とその引数を括弧で囲むことにより、上記の関数を引数に適用できます。
>>>
>>> (lambda x: x + 1)(2)
3Reductionは、式の値を計算するためのラムダ計算戦略です。 これは、引数2をxに置き換えることで構成されます。
(lambda x: x + 1)(2) = lambda 2: 2 + 1
= 2 + 1
= 3ラムダ関数は式であるため、名前を付けることができます。 したがって、次のように以前のコードを書くことができます。
>>>
>>> add_one = lambda x: x + 1
>>> add_one(2)
3上記のラムダ関数は、これを書くのと同等です。
def add_one(x):
return x + 1これらの関数はすべて単一の引数を取ります。 お気付きかもしれませんが、ラムダの定義では、引数の周りに括弧がありません。 マルチ引数関数(複数の引数を取る関数)は、Pythonラムダで、引数を一覧表示し、コンマ(,)で区切りますが、括弧で囲まないことで表現されます。
>>>
>>> full_name = lambda first, last: f'Full name: {first.title()} {last.title()}'
>>> full_name('guido', 'van rossum')
'Full name: Guido Van Rossum'full_nameに割り当てられたラムダ関数は2つの引数を取り、2つのパラメーターfirstとlastを補間する文字列を返します。 予想どおり、ラムダの定義は括弧なしで引数をリストしますが、関数の呼び出しは通常のPython関数とまったく同じように行われ、引数を括弧で囲みます。
無名関数
次の用語は、プログラミング言語の種類と文化に応じて交換可能に使用される場合があります。
-
無名関数
-
ラムダ関数
-
ラムダ式
-
ラムダ抽象化
-
ラムダ形
-
関数リテラル
このセクションの後のこの記事の残りの部分では、ほとんどの場合、lambda functionという用語が表示されます。
文字通り、匿名関数は名前のない関数です。 Pythonでは、lambdaキーワードを使用して無名関数が作成されます。 さらに大まかに言うと、名前が割り当てられている場合と割り当てられていない場合があります。 lambdaで定義されているが、変数にバインドされていない2引数の無名関数について考えてみます。 ラムダには名前が付けられていません:
>>>
>>> lambda x, y: x + y上記の関数は、2つの引数を取り、それらの合計を返すラムダ式を定義します。
Pythonがこのフォームで完全に問題ないというフィードバックを提供する以外は、実用化にはつながりません。 Pythonインタープリターで関数を呼び出すことができます。
>>>
>>> _(1, 2)
3上記の例では、アンダースコア(_)を介して提供されるインタラクティブなインタープリターのみの機能を利用しています。 詳細については、以下の注を参照してください。
Pythonモジュールで同様のコードを書くことはできませんでした。 インタプリタの_を、利用した副作用と見なしてください。 Pythonモジュールでは、ラムダに名前を割り当てるか、ラムダを関数に渡します。 この2つのアプローチは、この記事の後半で使用します。
Note:対話型インタープリターでは、単一のアンダースコア(_)が最後に評価された式にバインドされます。
上記の例では、_はラムダ関数を指しています。 Pythonでのこの特殊文字の使用法の詳細については、The Meaning of Underscores in Pythonを確認してください。
JavaScriptなどの他の言語で使用される別のパターンは、Pythonラムダ関数をすぐに実行することです。 これはImmediately Invoked Function Expression(IIFE、「iffy」と発音)として知られています。 例を示しましょう。
>>>
>>> (lambda x, y: x + y)(2, 3)
5上記のラムダ関数が定義され、すぐに2つの引数(2と3)で呼び出されます。 引数の合計である値5を返します。
このチュートリアルのいくつかの例では、この形式を使用してラムダ関数の無名の側面を強調し、関数を定義する短い方法としてPythonでlambdaに焦点を当てないようにしています。
Pythonは、すぐに呼び出されるラムダ式の使用を推奨していません。 通常の関数の本体とは異なり、単にラムダ式が呼び出し可能になった結果です。
Lambda関数はhigher-order functionsで頻繁に使用されます。これは、1つ以上の関数を引数として受け取るか、1つ以上の関数を返します。
ラムダ関数は、次の不自然な例のように関数(通常またはラムダ)を引数として使用することにより、高次関数になります。
>>>
>>> high_ord_func = lambda x, func: x + func(x)
>>> high_ord_func(2, lambda x: x * x)
6
>>> high_ord_func(2, lambda x: x + 3)
7Pythonは、高階関数を組み込み関数として、または標準ライブラリで公開します。 例には、map()、filter()、functools.reduce()、およびsort()、sorted()、min()、max()などの主要な関数が含まれます。 。 Appropriate Uses of Lambda Expressionsでは、ラムダ関数をPythonの高階関数と一緒に使用します。
Python Lambdaと通常の関数
Python Design and History FAQからのこの引用は、Pythonでのラムダ関数の使用に関する全体的な期待についてのトーンを設定しているようです。
機能を追加する他の言語のラムダフォームとは異なり、Pythonラムダは、関数を定義するのが面倒な場合の略記法にすぎません。 (Source)
それでも、このステートメントがPythonのlambdaの使用を思いとどまらせないようにしてください。 一見すると、ラムダ関数は、関数を定義または呼び出すためのコードを短縮するいくつかのsyntactic sugarを持つ関数であることがわかります。 次のセクションでは、通常のPython関数とラムダ関数の共通点と微妙な違いを強調します。
関数
この時点で、変数にバインドされたラムダ関数と、単一のreturn行を持つ通常の関数とを根本的に区別するものは何か疑問に思うかもしれません。表面下ではほとんど何もありません。 Pythonが、単一のreturnステートメントで作成された関数と、式(lambda)として作成された関数をどのように認識するかを確認しましょう。
disモジュールは、Pythonコンパイラによって生成されたPythonバイトコードを分析する関数を公開します。
>>>
>>> import dis
>>> add = lambda x, y: x + y
>>> type(add)
>>> dis.dis(add)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUE
>>> add
at 0x7f30c6ce9ea0> dis()は、Pythonバイトコードの読み取り可能なバージョンを公開し、プログラムの実行中にPythonインタープリターが使用する低レベルの命令を検査できることを確認できます。
今、通常の関数オブジェクトでそれを見てください:
>>>
>>> import dis
>>> def add(x, y): return x + y
>>> type(add)
>>> dis.dis(add)
1 0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 RETURN_VALUE
>>> add
Pythonによって解釈されるバイトコードは、両方の関数で同じです。 ただし、名前が異なることに気付くかもしれません。defで定義された関数の関数名はaddですが、Pythonラムダ関数はlambdaと見なされます。
トレースバック
前のセクションで、ラムダ関数のコンテキストでは、Pythonは関数の名前を提供せず、<lambda>のみを提供することを確認しました。 これは、例外が発生したときに考慮する制限になる可能性があり、トレースバックには<lambda>のみが表示されます。
>>>
>>> div_zero = lambda x: x / 0
>>> div_zero(2)
Traceback (most recent call last):
File "", line 1, in
File "", line 1, in
ZeroDivisionError: division by zero ラムダ関数の実行中に発生した例外のトレースバックは、例外の原因となった関数を<lambda>としてのみ識別します。
通常の関数で発生する同じ例外は次のとおりです。
>>>
>>> def div_zero(x): return x / 0
>>> div_zero(2)
Traceback (most recent call last):
File "", line 1, in
File "", line 1, in div_zero
ZeroDivisionError: division by zero 通常の関数でも同様のエラーが発生しますが、関数名div_zeroが与えられるため、より正確なトレースバックが得られます。
構文
前のセクションで見たように、ラムダ形式は通常の関数との構文上の違いを示します。 特に、ラムダ関数には次の特性があります。
-
式のみを含めることができ、本文にステートメントを含めることはできません。
-
1行の実行として記述されます。
-
型注釈はサポートしていません。
-
すぐに呼び出すことができます(IIFE)。
声明なし
ラムダ関数にステートメントを含めることはできません。 ラムダ関数では、return、pass、assert、またはraiseなどのステートメントでSyntaxError例外が発生します。 ラムダの本体にassertを追加する例を次に示します。
>>>
>>> (lambda x: assert x == 2)(2)
File "", line 1
(lambda x: assert x == 2)(2)
^
SyntaxError: invalid syntaxこの不自然な例は、パラメータxの値が2であることをassertに意図したものです。 ただし、インタープリターは、lambdaの本体にあるステートメントassertを含むコードを解析するときに、SyntaxErrorを識別します。
単一式
通常の関数とは対照的に、Pythonラムダ関数は単一の式です。 lambdaの本体では、括弧または複数行の文字列を使用して式を複数の行に広げることができますが、それは単一の式のままです。
>>>
>>> (lambda x:
... (x % 2 and 'odd' or 'even'))(3)
'odd'上記の例では、ラムダ引数が奇数の場合は文字列'odd'が返され、引数が偶数の場合は'even'が返されます。 括弧のセットに含まれているため、2行に広がりますが、単一の式のままです。
タイプ注釈
Pythonで利用できるようになったタイプヒンティングの採用を開始した場合、Pythonラムダ関数よりも通常の関数を好むもう1つの理由があります。 Pythonの型ヒントと型チェックの詳細については、Python Type Checking (Guide)を確認してください。 ラムダ関数では、次のものに相当するものはありません。
def full_name(first: str, last: str) -> str:
return f'{first.title()} {last.title()}'>>>
>>> lambda first: str, last: str: first.title() + " " + last.title() -> str
File "", line 1
lambda first: str, last: str: first.title() + " " + last.title() -> str
SyntaxError: invalid syntax ラムダにステートメントを含めようとするのと同様に、型アノテーションを追加すると、実行時にすぐにSyntaxErrorになります。
IIFE
immediately invoked function executionのいくつかの例をすでに見てきました。
>>>
>>> (lambda x: x * x)(3)
9Pythonインタープリター以外では、この機能はおそらく実際には使用されません。 定義されたとおりにラムダ関数が呼び出し可能であることの直接的な結果です。 たとえば、これにより、Pythonラムダ式の定義をmap()、filter()、functools.reduce()などの高階関数またはキー関数に渡すことができます。
引数
defで定義された通常の関数オブジェクトと同様に、Pythonラムダ式は引数を渡すさまざまな方法をすべてサポートしています。 これも:
-
位置引数
-
名前付き引数(キーワード引数とも呼ばれます)
-
引数の変数リスト(多くの場合、varargsと呼ばれます)
-
キーワード引数の変数リスト
-
キーワードのみの引数
次の例は、ラムダ式に引数を渡すために利用できるオプションを示しています。
>>>
>>> (lambda x, y, z: x + y + z)(1, 2, 3)
6
>>> (lambda x, y, z=3: x + y + z)(1, 2)
6
>>> (lambda x, y, z=3: x + y + z)(1, y=2)
6
>>> (lambda *args: sum(args))(1,2,3)
6
>>> (lambda **kwargs: sum(kwargs.values()))(one=1, two=2, three=3)
6
>>> (lambda x, *, y=0, z=0: x + y + z)(1, y=2, z=3)
6デコレータ
Pythonでは、decoratorは、関数またはクラスに動作を追加できるようにするパターンの実装です。 これは通常、関数の前に@decorator構文を付けて表現されます。 これが不自然な例です。
def some_decorator(f):
def wraps(*args):
print(f"Calling function '{f.__name__}'")
return f(args)
return wraps
@some_decorator
def decorated_function(x):
print(f"With argument '{x}'")上記の例では、some_decorator()はdecorated_function()に動作を追加する関数であるため、decorated_function("Python")を呼び出すと次の出力になります。
Calling function 'decorated_function'
With argument 'Python'decorated_function()はWith argument 'Python'のみを出力しますが、デコレータはCalling function 'decorated_function'も出力する追加の動作を追加します。
デコレータはラムダに適用できます。 @decorator構文でラムダをデコレートすることはできませんが、デコレータは単なる関数であるため、ラムダ関数を呼び出すことができます。
1 # Defining a decorator
2 def trace(f):
3 def wrap(*args, **kwargs):
4 print(f"[TRACE] func: {f.__name__}, args: {args}, kwargs: {kwargs}")
5 return f(*args, **kwargs)
6
7 return wrap
8
9 # Applying decorator to a function
10 @trace
11 def add_two(x):
12 return x + 2
13
14 # Calling the decorated function
15 add_two(3)
16
17 # Applying decorator to a lambda
18 print((trace(lambda x: x ** 2))(3))11行目で@traceで装飾されたadd_two()は、15行目で引数3を使用して呼び出されます。 対照的に、18行目では、ラムダ関数がすぐに含まれ、デコレータであるtrace()の呼び出しに埋め込まれています。 上記のコードを実行すると、次のものが得られます。
[TRACE] func: add_two, args: (3,), kwargs: {}
[TRACE] func: , args: (3,), kwargs: {}
9 すでに見てきたように、ラムダ関数の名前が<lambda>として表示されるのに対し、通常の関数ではadd_twoが明確に識別されていることを確認してください。
ラムダ関数をこのように装飾することは、デバッグの目的で、おそらく高階関数またはキー関数のコンテキストで使用されるラムダ関数の動作をデバッグするのに役立ちます。 map()の例を見てみましょう。
list(map(trace(lambda x: x*2), range(3)))map()の最初の引数は、その引数に2を掛けるラムダです。 このラムダはtrace()で装飾されています。 実行すると、上記の例は次を出力します。
[TRACE] Calling with args (0,) and kwargs {}
[TRACE] Calling with args (1,) and kwargs {}
[TRACE] Calling with args (2,) and kwargs {}
[0, 2, 4] 結果の[0, 2, 4]は、range(3)の各要素を乗算して得られたリストです。 今のところ、リスト[0, 1, 2]と同等のrange(3)を検討してください。
Mapで詳細にmap()にさらされます。
ラムダもデコレータにすることができますが、推奨されません。 これを行う必要がある場合は、PEP 8, Programming Recommendationsを参照してください。
Pythonデコレータの詳細については、Primer on Python Decoratorsを確認してください。
閉鎖
closureは、その関数で使用されるすべての自由変数(パラメーターを除くすべて)が、その関数の包含スコープで定義された特定の値にバインドされる関数です。 実際には、クロージャーは実行する環境を定義するため、どこからでも呼び出すことができます。
ラムダ関数とクロージャーの概念は必ずしも関連しているわけではありませんが、ラムダ関数は通常の関数もクロージャーと同じようにクロージャーにすることができます。 一部の言語には、クロージャーまたはラムダ(クロージャーオブジェクトとしてコードの匿名ブロックを使用するGroovyなど)、またはラムダ式(クロージャーのオプションが制限されているJava Lambda式など)の特別な構造があります。
通常のPython関数で構築されたクロージャーは次のとおりです。
1 def outer_func(x):
2 y = 4
3 def inner_func(z):
4 print(f"x = {x}, y = {y}, z = {z}")
5 return x + y + z
6 return inner_func
7
8 for i in range(3):
9 closure = outer_func(i)
10 print(f"closure({i+5}) = {closure(i+5)}")outer_func()は、3つの引数の合計を計算する入れ子関数であるinner_func()を返します。
-
xは引数としてouter_func()に渡されます。 -
yは、outer_func()にローカルな変数です。 -
zは、inner_func()に渡される引数です。
outer_func()およびinner_func()の動作をテストするために、outer_func()がforループで3回呼び出され、以下が出力されます。
x = 0, y = 4, z = 5
closure(5) = 9
x = 1, y = 4, z = 6
closure(6) = 11
x = 2, y = 4, z = 7
closure(7) = 13コードの9行目では、outer_func()の呼び出しによって返されるinner_func()は、名前closureにバインドされています。 5行目では、inner_func()はxとyをキャプチャします。これは、埋め込み環境にアクセスできるため、クロージャの呼び出し時に2つの自由変数xおよびy。
同様に、lambdaもクロージャにすることができます。 Pythonラムダ関数を使用した同じ例:
1 def outer_func(x):
2 y = 4
3 return lambda z: x + y + z
4
5 for i in range(3):
6 closure = outer_func(i)
7 print(f"closure({i+5}) = {closure(i+5)}")上記のコードを実行すると、次の出力が得られます。
closure(5) = 9
closure(6) = 11
closure(7) = 136行目で、outer_func()はラムダを返し、それを変数closureに割り当てます。 3行目では、ラムダ関数の本体がxとyを参照しています。 変数yは定義時に使用可能ですが、xは実行時にouter_func()が呼び出されたときに定義されます。
この状況では、通常の関数とラムダの両方が同様に動作します。 次のセクションでは、ラムダの動作が評価時間(定義時間と実行時間)により誤解を招く可能性がある状況を確認します。
評価時間
loopsが関係する状況では、クロージャとしてのPythonラムダ関数の動作が直感に反する場合があります。 ラムダのコンテキストで自由変数がバインドされるタイミングを理解する必要があります。 次の例は、通常の関数を使用する場合とPythonラムダを使用する場合の違いを示しています。
通常の機能を使用して最初にシナリオをテストします。
>>>
1 >>> def wrap(n):
2 ... def f():
3 ... print(n)
4 ... return f
5 ...
6 >>> numbers = 'one', 'two', 'three'
7 >>> funcs = []
8 >>> for n in numbers:
9 ... funcs.append(wrap(n))
10 ...
11 >>> for f in funcs:
12 ... f()
13 ...
14 one
15 two
16 three通常の関数では、nは、関数がリストに追加された9行目の定義時にfuncs.append(wrap(n))で評価されます。
次に、ラムダ関数を使用した同じロジックの実装で、予期しない動作を観察します。
>>>
1 >>> numbers = 'one', 'two', 'three'
2 >>> funcs = []
3 >>> for n in numbers:
4 ... funcs.append(lambda: print(n))
5 ...
6 >>> for f in funcs:
7 ... f()
8 ...
9 three
10 three
11 three実装されている自由変数nがラムダ式の実行時にバインドされるため、予期しない結果が発生します。 4行目のPythonラムダ関数は、実行時にバインドされた自由変数であるnをキャプチャするクロージャです。 実行時に、7行目で関数fを呼び出している間、nの値はthreeです。
この問題を克服するために、定義時に次のように自由変数を割り当てることができます。
>>>
1 >>> numbers = 'one', 'two', 'three'
2 >>> funcs = []
3 >>> for n in numbers:
4 ... funcs.append(lambda n=n: print(n))
5 ...
6 >>> for f in funcs:
7 ... f()
8 ...
9 one
10 two
11 threePythonラムダ関数は、引数に関して通常の関数のように動作します。 したがって、ラムダパラメーターはデフォルト値で初期化できます。パラメーターnは、外側のnをデフォルト値として使用します。 Pythonラムダ関数はlambda x=n: print(x)として記述され、同じ結果になる可能性があります。
Pythonラムダ関数は7行目で引数なしで呼び出され、定義時に設定されたデフォルト値nを使用します。
ラムダのテスト
Pythonラムダは、通常の関数と同様にテストできます。 unittestとdoctestの両方を使用できます。
unittest
unittestモジュールは、通常の関数と同様にPythonラムダ関数を処理します。
import unittest
addtwo = lambda x: x + 2
class LambdaTest(unittest.TestCase):
def test_add_two(self):
self.assertEqual(addtwo(2), 4)
def test_add_two_point_two(self):
self.assertEqual(addtwo(2.2), 4.2)
def test_add_three(self):
# Should fail
self.assertEqual(addtwo(3), 6)
if __name__ == '__main__':
unittest.main(verbosity=2)LambdaTestは、3つのテストメソッドを使用してテストケースを定義します。各メソッドは、ラムダ関数として実装されたaddtwo()のテストシナリオを実行します。 LambdaTestを含むPythonファイルlambda_unittest.pyを実行すると、次のようになります。
$ python lambda_unittest.py
test_add_three (__main__.LambdaTest) ... FAIL
test_add_two (__main__.LambdaTest) ... ok
test_add_two_point_two (__main__.LambdaTest) ... ok
======================================================================
FAIL: test_add_three (__main__.LambdaTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "lambda_unittest.py", line 18, in test_add_three
self.assertEqual(addtwo(3), 6)
AssertionError: 5 != 6
----------------------------------------------------------------------
Ran 3 tests in 0.001s
FAILED (failures=1)予想どおり、test_add_threeのテストケースは2つ成功し、1つは失敗しました。結果は5ですが、期待される結果は6でした。 この失敗は、テストケースの意図的な誤りによるものです。 期待される結果を6から5に変更すると、LambdaTestのすべてのテストが満たされます。
doctest
doctestモジュールは、docstringからインタラクティブなPythonコードを抽出して、テストを実行します。 Pythonラムダ関数の構文は一般的なdocstringをサポートしていませんが、名前付きラムダの__doc__要素に文字列を割り当てることは可能です。
addtwo = lambda x: x + 2
addtwo.__doc__ = """Add 2 to a number.
>>> addtwo(2)
4
>>> addtwo(2.2)
4.2
>>> addtwo(3) # Should fail
6
"""
if __name__ == '__main__':
import doctest
doctest.testmod(verbose=True)ラムダaddtwo()のドキュメントコメントのdoctestは、前のセクションと同じテストケースを説明しています。
doctest.testmod()を介してテストを実行すると、次のようになります。
$ python lambda_doctest.py
Trying:
addtwo(2)
Expecting:
4
ok
Trying:
addtwo(2.2)
Expecting:
4.2
ok
Trying:
addtwo(3) # Should fail
Expecting:
6
**********************************************************************
File "lambda_doctest.py", line 16, in __main__.addtwo
Failed example:
addtwo(3) # Should fail
Expected:
6
Got:
5
1 items had no tests:
__main__
**********************************************************************
1 items had failures:
1 of 3 in __main__.addtwo
3 tests in 2 items.
2 passed and 1 failed.
***Test Failed*** 1 failures.失敗したテストの結果は、前のセクションのユニットテストの実行で説明したものと同じ失敗です。
__doc__への割り当てを介してdocstringをPythonラムダに追加し、ラムダ関数を文書化できます。 可能ではありますが、Python構文は、ラムダ関数よりも通常の関数のdocstringにうまく対応します。
Pythonでの単体テストの包括的な概要については、Getting Started With Testing in Pythonを参照することをお勧めします。
ラムダ式乱用
この記事のいくつかの例は、プロのPythonコードのコンテキストで記述されている場合、悪用と見なされます。
ラムダ式がサポートしていないものを克服しようとしていることに気付いた場合、これはおそらく通常の関数の方が適していることを示しています。 前のセクションのラムダ式のdocstringは良い例です。 Pythonラムダ関数がステートメントをサポートしていないという事実を克服しようとすることは、もう1つの危険です。
次のセクションでは、回避すべきラムダの使用例をいくつか示します。 これらの例は、Pythonラムダのコンテキストで、コードが次のパターンを示す状況です。
-
Pythonスタイルガイドに準拠していません(PEP 8)
-
面倒で読みにくいです。
-
読みにくいという犠牲を払って不必要に巧妙です。
例外を発生させる
Pythonラムダで例外を発生させようとすると、考え直す必要があります。 そうするためのいくつかの賢い方法がありますが、次のようなものでさえも避けるべきです:
>>>
>>> def throw(ex): raise ex
>>> (lambda: throw(Exception('Something bad happened')))()
Traceback (most recent call last):
File "", line 1, in
File "", line 1, in
File "", line 1, in throw
Exception: Something bad happened Pythonラムダ本体ではステートメントが構文的に正しくないため、上記の例の回避策は、専用関数throw()を使用してステートメント呼び出しを抽象化することで構成されます。 このタイプの回避策の使用は避けてください。 このタイプのコードに遭遇した場合、通常の関数を使用するようにコードをリファクタリングすることを検討する必要があります。
不可解なスタイル
すべてのプログラミング言語と同様に、使用されているスタイルのために読みにくいPythonコードがあります。 Lambda関数は簡潔であるため、読みにくいコードの記述に役立ちます。
次のラムダの例には、いくつかの不適切なスタイルの選択肢が含まれています。
>>>
>>> (lambda _: list(map(lambda _: _ // 2, _)))([1,2,3,4,5,6,7,8,9,10])
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]アンダースコア(_)は、明示的に参照する必要のない変数を示します。 ただし、この例では、3つの_が異なる変数を参照しています。 このラムダコードへの最初のアップグレードは、変数に名前を付けることです。
>>>
>>> (lambda some_list: list(map(lambda n: n // 2,
some_list)))([1,2,3,4,5,6,7,8,9,10])
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]確かに、それはまだ読みにくいです。 lambdaを引き続き利用することにより、通常の関数はこのコードを読みやすくするために大いに役立ち、ロジックを数行と関数呼び出しに分散させます。
>>>
>>> def div_items(some_list):
div_by_two = lambda n: n // 2
return map(div_by_two, some_list)
>>> list(div_items([1,2,3,4,5,6,7,8,9,10])))
[0, 1, 1, 2, 2, 3, 3, 4, 4, 5]これはまだ最適ではありませんが、コード、特にPythonラムダ関数をより読みやすくするための可能なパスを示しています。 Alternatives to Lambdasでは、map()とlambdaをリスト内包表記またはジェネレータ式に置き換える方法を学習します。 これにより、コードの可読性が大幅に向上します。
Pythonクラス
クラスメソッドをPythonラムダ関数として記述することはできますが、すべきではありません。 次の例は完全に合法的なPythonコードですが、lambdaに依存する型破りなPythonコードを示しています。 たとえば、__str__を通常の関数として実装する代わりに、lambdaを使用します。 同様に、brandとyearもpropertiesであり、通常の関数やデコレータではなく、ラムダ関数で実装されています。
class Car:
"""Car with methods as lambda functions."""
def __init__(self, brand, year):
self.brand = brand
self.year = year
brand = property(lambda self: getattr(self, '_brand'),
lambda self, value: setattr(self, '_brand', value))
year = property(lambda self: getattr(self, '_year'),
lambda self, value: setattr(self, '_year', value))
__str__ = lambda self: f'{self.brand} {self.year}' # 1: error E731
honk = lambda self: print('Honk!') # 2: error E731スタイルガイド施行ツールであるflake8のようなツールを実行すると、__str__とhonkに対して次のエラーが表示されます。
E731 do not assign a lambda expression, use a defflake8は、プロパティでのPythonラムダ関数の使用に関する問題を指摘していませんが、'_brand'や%()のような複数の文字列を使用しているため、読みにくく、エラーが発生しやすくなっています。 t2)s。
__str__の適切な実装は、次のようになります。
def __str__(self):
return f'{self.brand} {self.year}'brandは次のように記述されます。
@property
def brand(self):
return self._brand
@brand.setter
def brand(self, value):
self._brand = value一般的なルールとして、Pythonで記述されたコードのコンテキストでは、ラムダ式よりも通常の関数を優先します。 それにもかかわらず、次のセクションで見るように、ラムダ構文の恩恵を受ける場合があります。
ラムダ式の適切な使用
Pythonのラムダは論争の対象になる傾向があります。 Pythonのラムダに対するいくつかの引数は次のとおりです。
-
読みやすさの問題
-
機能的な考え方の賦課
-
lambdaキーワードを使用した重い構文
Pythonでのこの機能の単なる存在を疑問視する激しい議論にもかかわらず、ラムダ関数には、Python言語および開発者に価値を提供するプロパティがあります。
次の例は、ラムダ関数の使用が適切であるだけでなく、Pythonコードで推奨されるシナリオを示しています。
古典的な機能構築物
Lambda関数は、モジュールfunctoolsで公開されている組み込み関数map()とfilter()、およびfunctools.reduce()で定期的に使用されます。 次の3つの例は、ラムダ式をコンパニオンとして使用してこれらの関数を使用するそれぞれの例です。
>>>
>>> list(map(lambda x: x.upper(), ['cat', 'dog', 'cow']))
['CAT', 'DOG', 'COW']
>>> list(filter(lambda x: 'o' in x, ['cat', 'dog', 'cow']))
['dog', 'cow']
>>> from functools import reduce
>>> reduce(lambda acc, x: f'{acc} | {x}', ['cat', 'dog', 'cow'])
'cat | dog | cow'より関連性の高いデータがありますが、上記の例に似たコードを読む必要があります。 そのため、これらの構成要素を認識することが重要です。 それにもかかわらず、これらの構成には、よりPythonicと見なされる同等の代替があります。 Alternatives to Lambdasでは、高階関数とそれに付随するラムダを他のより慣用的な形式に変換する方法を学習します。
主な機能
Pythonの主要な関数は、名前付き引数としてパラメーターkeyを受け取る高階関数です。 keyは、lambdaになることができる関数を受け取ります。 この関数は、キー関数自体によって駆動されるアルゴリズムに直接影響します。 主な機能は次のとおりです。
-
sort():リストメソッド -
sorted(),min(),max():の組み込み関数 -
ヒープキューアルゴリズムモジュールの
nlargest()andnsmallest():heapq
文字列として表されるIDのリストをソートしたいと想像してください。 各IDは、文字列idのconcatenationと数字です。 組み込み関数sorted()を使用してこのリストを並べ替えると、デフォルトでは、リスト内の要素が文字列であるため、辞書式順序が使用されます。
並べ替えの実行に影響を与えるために、名前付き引数keyにラムダを割り当てて、並べ替えがIDに関連付けられた番号を使用するようにすることができます。
>>>
>>> ids = ['id1', 'id2', 'id30', 'id3', 'id22', 'id100']
>>> print(sorted(ids)) # Lexicographic sort
['id1', 'id2', 'id30', 'id3', 'id22', 'id100']
>>> sorted_ids = sorted(ids, key=lambda x: int(x[2:])) # Integer sort
>>> print(sorted_ids)
['id1', 'id2', 'id3', 'id22', 'id30', 'id100']UIフレームワーク
Tkinter、wxPython、または.NET WindowsフォームとIronPythonなどのUIフレームワークは、UIイベントに応答してアクションをマッピングするためにラムダ関数を利用します。
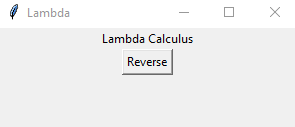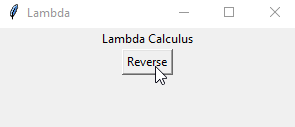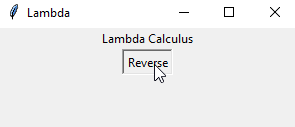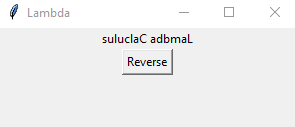
以下の素朴なTkinterプログラムは、Reverseボタンのコマンドに割り当てられたlambdaの使用法を示しています。
import tkinter as tk
import sys
window = tk.Tk()
window.grid_columnconfigure(0, weight=1)
window.title("Lambda")
window.geometry("300x100")
label = tk.Label(window, text="Lambda Calculus")
label.grid(column=0, row=0)
button = tk.Button(
window,
text="Reverse",
command=lambda: label.configure(text=label.cget("text")[::-1]),
)
button.grid(column=0, row=1)
window.mainloop()ボタンReverseをクリックすると、ラムダ関数をトリガーするイベントが発生し、ラベルがLambda CalculusからsuluclaC adbmaL *に変更されます。
.NETプラットフォーム上のwxPythonとIronPythonは、イベントを処理するための同様のアプローチを共有しています。 lambdaは起動イベントを処理する1つの方法ですが、関数を同じ目的で使用できることに注意してください。 必要なコードの量が非常に少ない場合にlambdaを使用すると、自己完結型になり、冗長性が低下します。
wxPythonを調べるには、How to Build a Python GUI Application With wxPythonを確認してください。
Pythonインタプリタ
インタラクティブインタープリターでPythonコードを使用している場合、Pythonラムダ関数は多くの場合祝福です。 簡単なワンライナー関数を簡単に作成して、インタープリターの外では日の目を見ることのないコードの一部を調べることができます。 インタプリタで記述されたラムダは、迅速な発見のために、使用後に捨てることができるスクラップペーパーのようなものです。
timeit
Pythonインタープリターでの実験と同じ精神で、モジュールtimeitは、小さなコードフラグメントの時間を計測する関数を提供します。 特にtimeit.timeit()は直接呼び出すことができ、Pythonコードを文字列で渡します。 例を示しましょう。
>>>
>>> from timeit import timeit
>>> timeit("factorial(999)", "from math import factorial", number=10)
0.0013087529951008037ステートメントが文字列として渡される場合、timeit()には完全なコンテキストが必要です。 上記の例では、これは、タイミングをとるメイン関数に必要な環境を設定する2番目の引数によって提供されます。 そうしないと、NameError例外が発生します。
別のアプローチは、lambdaを使用することです。
>>>
>>> from math import factorial
>>> timeit(lambda: factorial(999), number=10)
0.0012704220062005334このソリューションは、より簡潔で読みやすく、インタープリターにすばやく入力できます。 lambdaバージョンの実行時間はわずかに短くなりましたが、関数を再度実行すると、stringバージョンのわずかな利点が示される場合があります。 setupの実行時間は全体の実行時間から除外されており、結果に影響を与えることはありません。
モンキーパッチング
テストでは、特定のソフトウェアの通常の実行中に対応する結果が異なるか、完全にランダムであることが予想される場合でも、繰り返し可能な結果に依存することが必要になる場合があります。
実行時にランダムな値を処理する関数をテストするとします。 ただし、テストの実行中は、予測可能な値に対して繰り返し可能な方法でアサートする必要があります。 次の例は、lambda関数を使用して、モンキーパッチがどのように役立つかを示しています。
from contextlib import contextmanager
import secrets
def gen_token():
"""Generate a random token."""
return f'TOKEN_{secrets.token_hex(8)}'
@contextmanager
def mock_token():
"""Context manager to monkey patch the secrets.token_hex
function during testing.
"""
default_token_hex = secrets.token_hex
secrets.token_hex = lambda _: 'feedfacecafebeef'
yield
secrets.token_hex = default_token_hex
def test_gen_key():
"""Test the random token."""
with mock_token():
assert gen_token() == f"TOKEN_{'feedfacecafebeef'}"
test_gen_key()コンテキストマネージャーは、モンキーパッチを適用する関数の操作を標準ライブラリ(この例ではsecrets)から分離するのに役立ちます。 secrets.token_hex()に割り当てられたラムダ関数は、静的な値を返すことでデフォルトの動作を置き換えます。
これにより、token_hex()に依存する任意の関数を予測可能な方法でテストできます。 コンテキストマネージャーを終了する前に、token_hex()のデフォルトの動作が再確立され、token_hex()のデフォルトの動作に依存する可能性のあるテストの他の領域に影響を与える予期しない副作用が排除されます。
unittestやpytestのような単体テストフレームワークは、この概念をより高度なレベルに引き上げます。
pytestを使用し、lambda関数を使用すると、同じ例がよりエレガントで簡潔になります。
import secrets
def gen_token():
return f'TOKEN_{secrets.token_hex(8)}'
def test_gen_key(monkeypatch):
monkeypatch.setattr('secrets.token_hex', lambda _: 'feedfacecafebeef')
assert gen_token() == f"TOKEN_{'feedfacecafebeef'}"pytest monkeypatch fixtureを使用すると、secrets.token_hex()はラムダで上書きされ、決定論的な値feedfacecafebeefが返され、テストの検証が可能になります。 pytestmonkeypatchフィクスチャを使用すると、オーバーライドのスコープを制御できます。 上記の例では、モンキーパッチを使用せずに後続のテストでsecrets.token_hex()を呼び出すと、この関数の通常の実装が実行されます。
pytestテストを実行すると、次の結果が得られます。
$ pytest test_token.py -v
============================= test session starts ==============================
platform linux -- Python 3.7.2, pytest-4.3.0, py-1.8.0, pluggy-0.9.0
cachedir: .pytest_cache
rootdir: /home/andre/AB/tools/bpython, inifile:
collected 1 item
test_token.py::test_gen_key PASSED [100%]
=========================== 1 passed in 0.01 seconds ===========================gen_token()が実行されたことを検証したため、テストは合格し、結果はテストのコンテキストで期待されたものでした。
ラムダの代替品
lambdaを使用する大きな理由がありますが、その使用が嫌われる場合があります。 それでは、代替手段は何ですか?
map()、filter()、functools.reduce()などの高階関数は、特にリスト内包表記やジェネレーター式を使用して、創造性を少しひねった、よりエレガントな形式に変換できます。
リスト内包表記の詳細については、Using List Comprehensions Effectivelyをご覧ください。
Map
組み込み関数map()は、関数を最初の引数として受け取り、それを2番目の引数iterableの各要素に適用します。 イテラブルの例は、文字列、リスト、およびタプルです。 イテレータとイテレータの詳細については、Iterables and Iteratorsを確認してください。
map()は、変換されたコレクションに対応するイテレータを返します。 例として、文字列のリストを、各文字列を大文字にした新しいリストに変換する場合は、次のようにmap()を使用できます。
>>>
>>> list(map(lambda x: x.capitalize(), ['cat', 'dog', 'cow']))
['Cat', 'Dog', 'Cow']map()によって返されるイテレータをPythonシェルインタプリタで表示できる拡張リストに変換するには、list()を呼び出す必要があります。
リスト内包表記を使用すると、ラムダ関数を定義して呼び出す必要がなくなります。
>>>
>>> [x.capitalize() for x in ['cat', 'dog', 'cow']]
['Cat', 'Dog', 'Cow']フィルタ
別の古典的な関数構造である組み込み関数filter()は、リスト内包に変換できます。 最初の引数としてpredicateを取り、2番目の引数としてiterableを取ります。 述語関数を満たす初期コレクションのすべての要素を含む反復子を作成します。 整数のリスト内のすべての偶数をフィルタリングする例を次に示します。
>>>
>>> even = lambda x: x%2 == 0
>>> list(filter(even, range(11)))
[0, 2, 4, 6, 8, 10]filter()はイテレータを返すため、イテレータを指定してリストを作成する組み込み型listを呼び出す必要があることに注意してください。
リスト内包構造を活用する実装は、以下を提供します:
>>>
>>> [x for x in range(11) if x%2 == 0]
[0, 2, 4, 6, 8, 10]減らす
Python 3以降、reduce()は組み込み関数からfunctoolsモジュール関数になりました。 map()およびfilter()として、その最初の2つの引数はそれぞれ関数および反復可能です。 また、結果のアキュムレータの初期値として使用される3番目の引数として初期化子を取る場合があります。 iterableの各要素について、reduce()は関数を適用し、iterableが使い果たされたときに返される結果を累積します。
ペアのリストにreduce()を適用し、各ペアの最初の項目の合計を計算するには、次のように記述します。
>>>
>>> import functools
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> functools.reduce(lambda acc, pair: acc + pair[0], pairs, 0)
6例のsum()の引数として、generator expressionを使用するより慣用的なアプローチは、次のとおりです。
>>>
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> sum(x[0] for x in pairs)
6わずかに異なる、おそらくよりクリーンなソリューションにより、ペアの最初の要素に明示的にアクセスし、代わりにアンパックを使用する必要がなくなります。
>>>
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
>>> sum(x for x, _ in pairs)
6アンダースコア(_)の使用は、ペアの2番目の値を無視できることを示すPythonの規則です。
sum()は一意の引数を取るため、ジェネレータ式を括弧で囲む必要はありません。
LambdasはPythonicですか?
PythonコードのスタイルガイドであるPEP 8は、次のように読みます。
ラムダ式を直接識別子にバインドする割り当てステートメントの代わりに、常にdefステートメントを使用します。 (Source)
これは、主に関数を使用する必要があり、より多くの利点がある場合、識別子にバインドされたラムダを使用することを強く推奨します。 PEP 8は、lambdaの他の使用法については言及していません。 前のセクションで見たように、ラムダ関数には制限がありますが、確かに良い使用法があります。
質問に答える可能な方法は、利用可能なPythonicが他にない場合、ラムダ関数は完全にPythonicであるということです。 「Pythonic」の意味を定義せずに、自分の考え方に最適な定義と、個人またはチームのコーディングスタイルを残します。
Pythonlambdaの狭い範囲を超えて、How to Write Beautiful Python Code With PEP 8は、Pythonのコードスタイルに関してチェックしたい素晴らしいリソースです。
結論
これで、Pythonlambda関数の使用方法がわかり、次のことができるようになりました。
-
Pythonラムダを作成し、匿名関数を使用する
-
ラムダまたは通常のPython関数の間で賢明に選択する
-
ラムダの過度の使用を避ける
-
高次関数またはPythonキー関数でラムダを使用する
数学が好きな人は、lambda calculusの魅力的な世界を探索するのも楽しいかもしれません。
Pythonラムダは塩のようなものです。 スパム、ハム、卵にピンチすると風味が向上しますが、多すぎると料理が損なわれます。
__ Take the Quiz:インタラクティブな「PythonLambda関数」クイズで知識をテストします。 完了すると、学習の進捗状況を経時的に追跡できるようにスコアを受け取ります。
Note: Monty Pythonにちなんで名付けられたPythonプログラミング言語は、従来のfooではなく、spam、ham、およびeggsをメタ構文変数として使用することを好みます。 bar、およびbaz。