Pythonヒストグラムプロット:NumPy、Matplotlib、Pandas&Seaborn
このチュートリアルでは、さまざまな選択肢と機能を備えた、生産品質のプレゼンテーション対応のPythonヒストグラムプロットを作成できます。
Pythonと統計の中間知識の入門書がある場合は、NumPy、Matplotlib、Pandas、Seabornなどの科学スタックのライブラリを使用して、Pythonでヒストグラムを作成およびプロットするためのワンストップショップとしてこの記事を使用できます。
ヒストグラムは、ほとんどすべての対象者が直感的に理解できるprobability distributionをすばやく評価するための優れたツールです。 Pythonは、ヒストグラムを作成およびプロットするためのいくつかの異なるオプションを提供します。 ほとんどの人は、棒グラフに似たグラフィカルな表現でヒストグラムを知っています。
この記事では、上記のようなプロットとより複雑なプロットを作成する方法を説明します。 カバーする内容は次のとおりです。
-
サードパーティのライブラリを使用せずに、純粋なPythonでヒストグラムを作成する
-
NumPyを使用してヒストグラムを作成し、基礎となるデータを要約します
-
Matplotlib、Pandas、およびSeabornを使用して結果のヒストグラムをプロットする
Free Bonus:時間が足りませんか? このチュートリアルで説明されている手法を要約したClick here to get access to a free two-page Python histograms cheat sheet。
Pure Pythonのヒストグラム
ヒストグラムをプロットする準備をしているとき、ビンの観点から考えるのではなく、各値が出現する回数を報告するのが最も簡単です(度数分布表)。 Pythondictionaryは、このタスクに最適です。
>>>
>>> # Need not be sorted, necessarily
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> def count_elements(seq) -> dict:
... """Tally elements from `seq`."""
... hist = {}
... for i in seq:
... hist[i] = hist.get(i, 0) + 1
... return hist
>>> counted = count_elements(a)
>>> counted
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}count_elements()は、シーケンスからの一意の要素をキーとして、それらの頻度(カウント)を値として持つ辞書を返します。 seqのループ内で、hist[i] = hist.get(i, 0) + 1は、「シーケンスの各要素について、histの対応する値を1ずつインクリメントします」と言います。
実際、これはまさにPythonの標準ライブラリのcollections.Counterクラスによって行われることであり、https://github.com/python/cpython/blob/7f1bcda9bc3c04100cb047373732db0eba00e581/Lib/collections/init.py#L466 [subclasses]はPython辞書であり、その.update()をオーバーライドします。 sメソッド:
>>>
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})2つの関数が等しいかどうかをテストすることで、手作りの関数がcollections.Counterと実質的に同じことを行うことを確認できます。
>>>
>>> recounted.items() == counted.items()
TrueTechnical Detail:上記のcount_elements()からのマッピングは、使用可能な場合、デフォルトでより高度に最適化されたC functionになります。 Python関数count_elements()内で行うことができるマイクロ最適化のひとつは、forループの前にget = hist.getを宣言することです。 これにより、メソッドを変数にバインドして、ループ内の呼び出しを高速化できます。
より複雑な機能を理解するための最初のステップとして、簡素化された機能をゼロから作成すると役立ちます。 Pythonのoutput formattingを利用するASCIIヒストグラムを使用して、車輪の再発明を少し進めましょう。
def ascii_histogram(seq) -> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
for k in sorted(counted):
print('{0:5d} {1}'.format(k, '+' * counted[k]))この関数は、カウントがプラス(+)記号の集計として表されるソートされた頻度プロットを作成します。 辞書でsorted()を呼び出すと、そのキーのソートされたリストが返され、counted[k]を使用してそれぞれに対応する値にアクセスします。 これが実際に動作することを確認するには、Pythonのrandomモジュールを使用して少し大きいデータセットを作成できます。
>>>
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++ここでは、freq(agenerator expression)で指定された頻度でvalsからの摘採をシミュレートしています。 結果のサンプルデータは、valsの各値を5から15の間で特定の回数繰り返します。
Note:random.seed()は、randomによって使用される基礎となる疑似乱数ジェネレーター(PRNG)をシードまたは初期化するために使用されます。 矛盾のように聞こえるかもしれませんが、これはランダムなデータを再現可能かつ決定論的にする方法です。 つまり、ここでコードをそのままコピーすると、ジェネレーターをシードした後の最初のrandom.randint()の呼び出しで、Mersenne Twisterを使用して同一の「ランダム」データが生成されるため、まったく同じヒストグラムが得られます。
ベースからの構築:NumPyでのヒストグラム計算
これまでは、「頻度テーブル」と呼ばれるのが最善の方法で作業してきました。しかし数学的には、ヒストグラムはビン(間隔)の頻度へのマッピングです。 より技術的には、基礎となる変数の確率密度関数(PDF)を概算するために使用できます。
上記の「度数分布表」から移動すると、真のヒストグラムはまず値の範囲を「ビン化」し、次に各ビンに入る値の数をカウントします。 これはNumPy’shistogram()関数が行うことであり、MatplotlibやPandasなどのPythonライブラリで後で見る他の関数の基礎です。
Laplace distributionから抽出されたフロートのサンプルを考えてみましょう。 この分布には、正規分布よりも裾が広く、2つの記述パラメーター(位置とスケール)があります。
>>>
>>> import numpy as np
>>> # `numpy.random` uses its own PRNG.
>>> np.random.seed(444)
>>> np.set_printoptions(precision=3)
>>> d = np.random.laplace(loc=15, scale=3, size=500)
>>> d[:5]
array([18.406, 18.087, 16.004, 16.221, 7.358])この場合、連続分布で作業しているため、各フロートを独立して、小数点以下10桁まで集計することはあまり役に立ちません。 代わりに、データをビンまたは「バケット化」し、各ビンに入る観測値をカウントできます。 ヒストグラムは、各ビン内の値の結果カウントです。
>>>
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])この結果はすぐに直観的ではないかもしれません。 np.histogram()は、デフォルトで10個の同じサイズのビンを使用し、頻度カウントと対応するビンエッジのタプルを返します。 これらは、ヒストグラムのメンバーよりもビンエッジが1つ多いという意味でのエッジです。
>>>
>>> hist.size, bin_edges.size
(10, 11)Technical Detail:最後の(右端の)ビンを除くすべてが半分開いています。 つまり、最後のビンを除くすべてのビンが[包括的、排他的]であり、最後のビンが[包括的、包括的]です。
ビンの構築方法の非常に凝縮された内訳by NumPyは、次のようになります。
>>>
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23. ])上記のケースは非常に理にかなっています。23のピークツーピーク範囲で10個の等間隔ビンは、幅2.3の間隔を意味します。
そこから、関数はnp.bincount()またはnp.searchsorted()のいずれかに委任します。 bincount()自体を使用して、ここで開始した「度数分布表」を効果的に作成できます。オカレンスがゼロの値が含まれているという違いがあります。
>>>
>>> bcounts = np.bincount(a)
>>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}Note:ここでのhistは、実際には「離散」カウントではなく、幅1.0のビンを使用しています。 したがって、これは整数のカウントに対してのみ機能し、[3.9, 4.1, 4.15]などの浮動小数点数では機能しません。
MatplotlibとPandasを使用したヒストグラムの視覚化
Pythonでヒストグラムをゼロから作成する方法を確認したので、他のPythonパッケージがどのように機能するかを見てみましょう。 Matplotlibは、NumPyのhistogram()の汎用ラッパーを使用して、Pythonヒストグラムをすぐに視覚化する機能を提供します。
import matplotlib.pyplot as plt
# An "interface" to matplotlib.axes.Axes.hist() method
n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa',
alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('My Very Own Histogram')
plt.text(23, 45, r'$\mu=15, b=3$')
maxfreq = n.max()
# Set a clean upper y-axis limit.
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)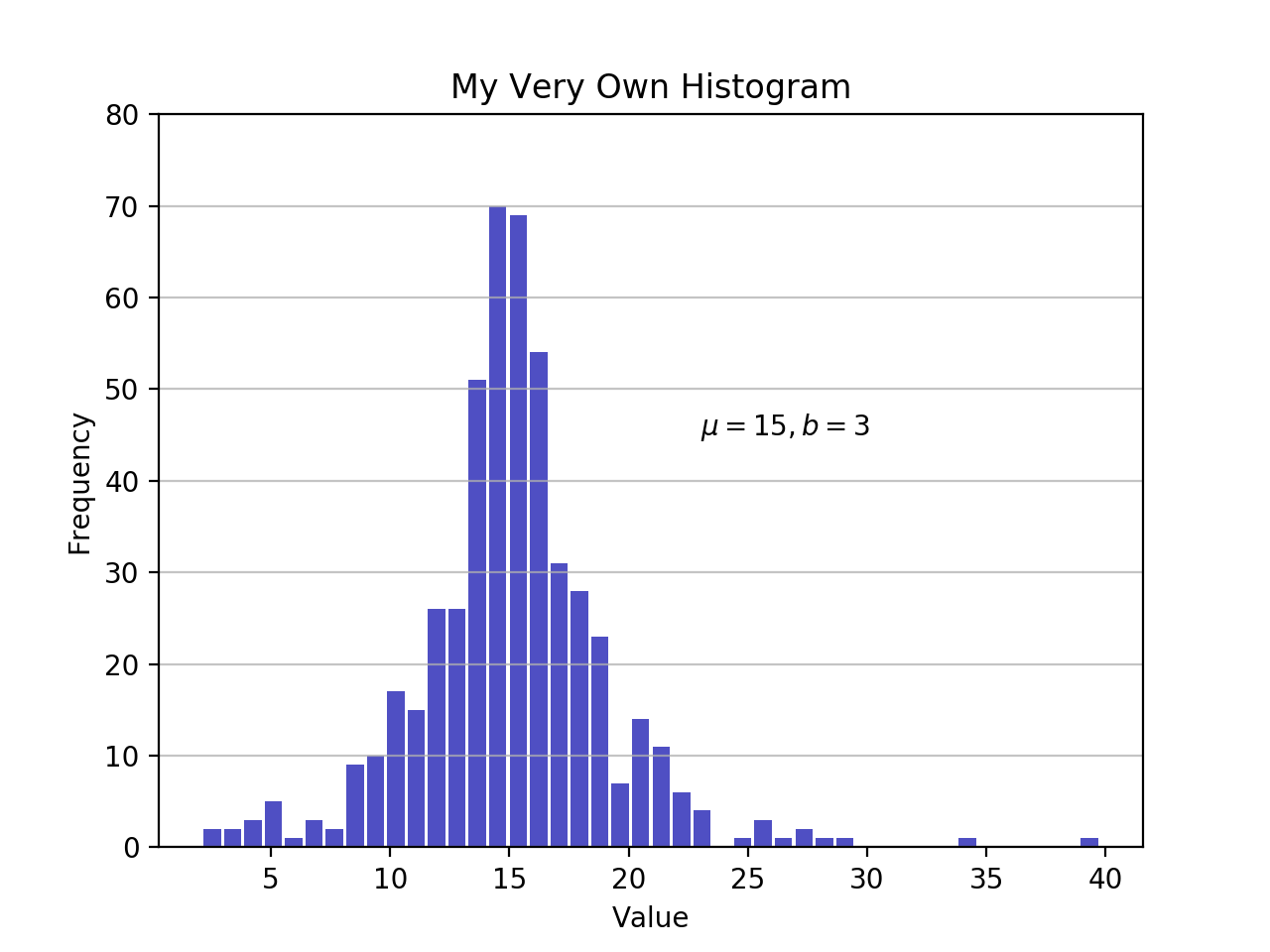
前に定義したように、ヒストグラムのプロットでは、x軸にビンのエッジを使用し、y軸に対応する周波数を使用します。 上のグラフでは、bins='auto'を渡すと、2つのアルゴリズムから選択して、「理想的な」ビンの数を推定します。 高いレベルでのアルゴリズムの目標は、データの最も忠実な表現を生成するビン幅を選択することです。 かなり技術的になる可能性のあるこのテーマの詳細については、AstropyのドキュメントからChoosing Histogram Binsを確認してください。
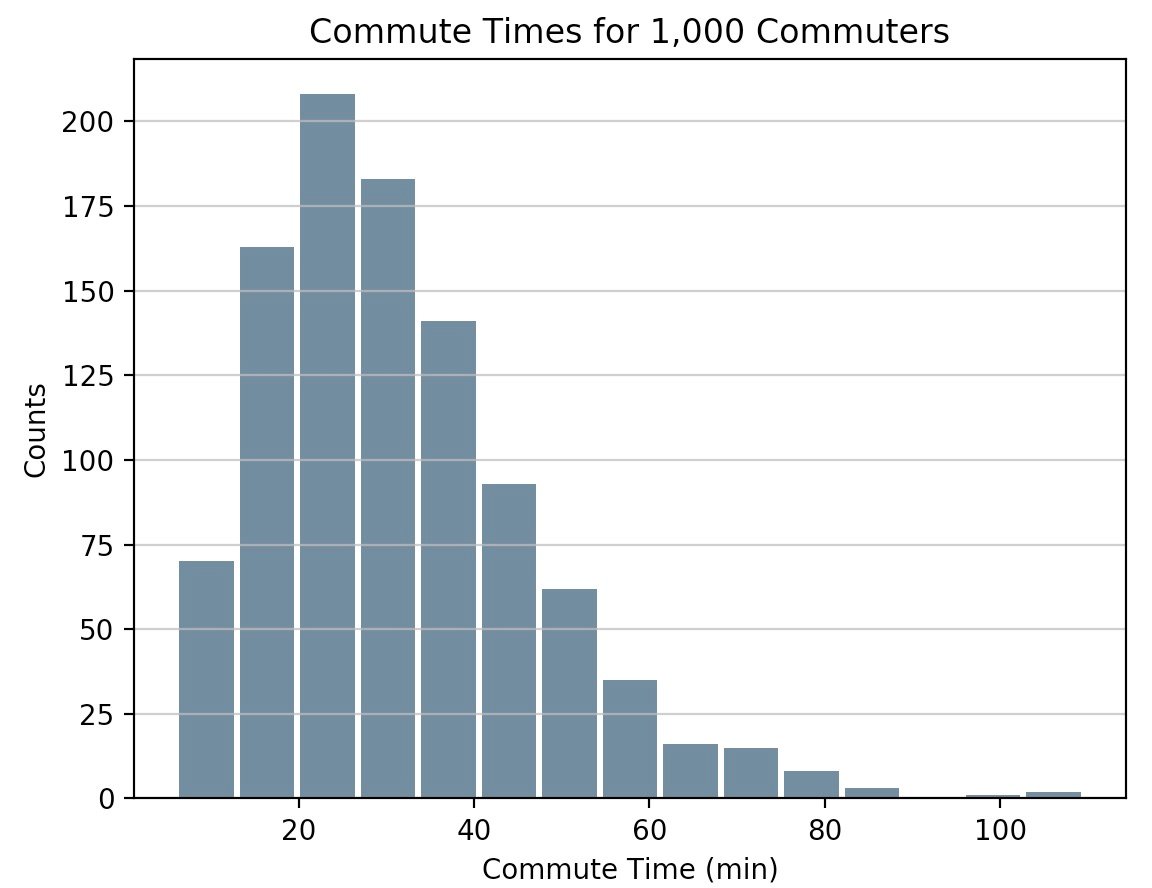
Pythonの科学スタックにとどまり、PandasのSeries.histogram()uses matplotlib.pyplot.hist()を使用して、入力シリーズのMatplotlibヒストグラムを描画します。
import pandas as pd
# Generate data on commute times.
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid=True, bins=20, rwidth=0.9,
color='#607c8e')
plt.title('Commute Times for 1,000 Commuters')
plt.xlabel('Counts')
plt.ylabel('Commute Time')
plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram()も同様ですが、DataFrame内のデータの各列のヒストグラムを生成します。
カーネル密度推定(KDE)のプロット
このチュートリアルでは、統計的に言えば、サンプルを操作しました。 データが離散的であろうと連続的であろうと、ほんの数個のパラメーターで記述された真の正確な分布を持つ母集団から派生したものと想定されます。
カーネル密度推定(KDE)は、サンプルの「基礎となる」確率変数の確率密度関数(PDF)を推定する方法です。 KDEはデータの平滑化の手段です。
Pandasライブラリを使用すると、SeriesオブジェクトとDataFrameオブジェクトの両方で使用できるplot.kde()を使用して密度プロットを作成およびオーバーレイできます。 しかし、最初に、比較のために2つの異なるデータサンプルを生成しましょう。
>>>
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94ここで、同じMatplotlib軸に各ヒストグラムをプロットするには:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')
これらのメソッドはSciPyのgaussian_kde()を活用し、より滑らかなPDFを実現します。
この関数を詳しく見ると、1000個のデータポイントの比較的小さなサンプルで「真の」PDFをどれだけ近似しているかがわかります。 以下では、最初にscipy.stats.norm()を使用して「分析」分布を作成できます。 これは、統計標準正規分布、そのモーメント、および説明関数をカプセル化するクラスインスタンスです。 そのPDFは、norm.pdf(x) = exp(-x**2/2) / sqrt(2*pi)として正確に定義されているという意味で「正確」です。
そこから構築して、この分布から1000データポイントのランダムサンプルを取得し、scipy.stats.gaussian_kde()を使用してPDFの推定に戻ろうとすることができます。
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)
これはコードの大きな塊なので、いくつかの重要な行に触れてみましょう。
-
SciPyの
statssubpackageを使用すると、実際のデータを作成するためにサンプリングできる分析分布を表すPythonオブジェクトを作成できます。 したがって、dist = stats.norm()は通常の連続確率変数を表し、dist.rvs()を使用してそこから乱数を生成します。 -
分析PDFとガウスKDEの両方を評価するには、分位数の配列
xが必要です(正規分布の場合、平均の上下の標準偏差)。stats.gaussian_kde()は、この場合視覚的に意味のあるものを生成するために配列で評価する必要がある推定PDFを表します。 -
最後の行にはいくつかのLaTexが含まれており、Matplotlibとうまく統合されています。
Seabornのファンシーオルタナティブ
もう1つのPythonパッケージを組み合わせてみましょう。 Seabornには、1つのステップで単変量分布のヒストグラムとKDEをプロットするdisplot()関数があります。 ealierのNumPy配列dを使用する:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)
上記の呼び出しはKDEを生成します。 特定の分布をデータに適合させるオプションもあります。 これはKDEとは異なり、汎用データのパラメーター推定と指定された分布名で構成されます。
sns.distplot(d, fit=stats.laplace, kde=False)
繰り返しますが、わずかな違いに注意してください。 最初のケースでは、未知のPDFを推定しています。 2つ目は、既知の分布を取得し、経験的データを考慮して、それを最もよく表すパラメーターを見つけます。
パンダのその他のツール
プロットツールに加えて、Pandasは、非null値のヒストグラムをPandasSeriesに計算する便利な.value_counts()メソッドも提供します。
>>>
>>> import pandas as pd
>>> data = np.random.choice(np.arange(10), size=10000,
... p=np.linspace(1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
9 1831
8 1624
7 1423
6 1323
5 1089
4 888
3 770
2 535
1 347
0 170
dtype: int64
>>> s.value_counts(normalize=True).head()
9 0.1831
8 0.1624
7 0.1423
6 0.1323
5 0.1089
dtype: float64他の場所では、pandas.cut()は値を任意の間隔にビン化する便利な方法です。 個人の年齢に関するいくつかのデータがあり、それらを賢明にバケット化するとします。
>>>
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adultすばらしいのは、これらの操作の両方が最終的にutilize Cython codeであり、柔軟性を維持しながら速度の競争力を高めることです。
さて、どちらを使用する必要がありますか?
この時点で、Pythonヒストグラムをプロットするために選択できる関数とメソッドがいくつかあります。 彼らはどうやって比較しますか? 要するに、「万能」というものはありません。これまでに取り上げた関数とメソッドの要約を以下に示します。これらはすべて、Pythonでの分布の分類と表現に関するものです。
| あなたが持っている/したい | 使用を検討してください | ノート) |
|---|---|---|
リスト、タプル、セットなどのデータ構造に格納されている整数データをクリーンカットし、サードパーティのライブラリをインポートせずにPythonヒストグラムを作成したい。 |
Python標準ライブラリの |
これは度数分布表であるため、「真の」ヒストグラムのようにビニングの概念を使用していません。 |
データの大規模な配列であり、ビンと対応する頻度を表す「数学的な」ヒストグラムを計算する必要があります。 |
NumPyの |
詳細については、 |
Pandasの |
|
インスピレーションを得るためにパンダvisualization docsをチェックしてください。 |
任意のデータ構造から高度にカスタマイズ可能で微調整されたプロットを作成します。 |
|
Matplotlib、特にそのobject-oriented frameworkは、ヒストグラムの詳細を微調整するのに最適です。 このインターフェイスは習得するのに少し時間がかかる場合がありますが、最終的には、視覚化のレイアウトを非常に正確に行うことができます。 |
事前に缶詰にされた設計と統合。 |
Seabornの |
基本的に、Matplotlibヒストグラムを内部で活用する「ラッパーのラッパー」であり、NumPyを利用します。 |
Free Bonus:時間が足りませんか? このチュートリアルで説明されている手法を要約したClick here to get access to a free two-page Python histograms cheat sheet。
この記事のコードスニペットは、Real Pythonマテリアルページの1つのscriptにまとめて見つけることもできます。
それで、幸運にもヒストグラムを作成します。 上記のツールの1つがニーズに合うことを願っています。 何をするにしても、don’t use a pie chartだけです。