並行処理でPythonプログラムを高速化する
asynciobeing added to Pythonについて多くの話を聞いたが、他の並行性メソッドと比較する方法に興味がある場合、または並行性とは何か、プログラムをどのように高速化できるか疑問に思っている場合は、適切な場所。
この記事では、次のことを学びます。
-
concurrencyとは
-
parallelismとは
-
threading、asyncio、multiprocessingなどのPython’s concurrency methodsの比較 -
プログラム内のWhen to use concurrencyと使用するモジュール
この記事では、Pythonの基本的な知識があり、少なくともバージョン3.6を使用して例を実行していることを前提としています。 Real Python GitHub repoから例をダウンロードできます。
Free Bonus:5 Thoughts On Python Masteryは、Python開発者向けの無料コースで、Pythonスキルを次のレベルに引き上げるために必要なロードマップと考え方を示しています。
__ Take the Quiz:インタラクティブな「Python同時実行」クイズで知識をテストします。 完了すると、学習の進捗状況を経時的に追跡できるようにスコアを受け取ります。
並行性とは
並行性の辞書定義は同時発生です。 Pythonでは、同時に発生しているものは異なる名前(スレッド、タスク、プロセス)で呼び出されますが、高レベルでは、すべてが順番に実行される一連の命令を参照します。
私はそれらを異なる思考の流れと考えるのが好きです。 それぞれを特定のポイントで停止することができ、それらを処理しているCPUまたは脳は別のポイントに切り替えることができます。 それぞれの状態は保存されるため、中断された場所からすぐに再開できます。
Pythonが同じ概念に対して異なる単語を使用する理由を疑問に思うかもしれません。 スレッド、タスク、およびプロセスは、高レベルで表示した場合にのみ同じであることがわかります。 詳細を掘り下げると、それらはすべてわずかに異なるものを表しています。 例が進むにつれて、それらがどのように異なるかがわかります。
それでは、その定義の同時部分について話しましょう。 詳細にたどり着くと、実際にはmultiprocessingだけが文字通り同時にこれらの思考の流れを実行するため、少し注意する必要があります。 Threadingとasyncioはどちらも単一のプロセッサで実行されるため、一度に1つしか実行されません。 彼らは全体的なプロセスをスピードアップするために交代する方法を賢く見つけています。 異なる思考の流れを同時に実行することはありませんが、それでもこの並行性と呼びます。
スレッドまたはタスクが交代する方法は、threadingとasyncioの大きな違いです。 threadingでは、オペレーティングシステムは実際に各スレッドを認識しており、いつでもスレッドを中断して別のスレッドの実行を開始できます。 これは、オペレーティングシステムがスレッドをプリエンプトして切り替えを行うことができるため、pre-emptive multitaskingと呼ばれます。
プリエンプティブマルチタスクは、スレッド内のコードが切り替えを行うために何もする必要がないという点で便利です。 また、「いつでも」というフレーズのために難しいこともあります。 この切り替えは、x = x + 1のような些細なステートメントであっても、単一のPythonステートメントの途中で発生する可能性があります。
一方、Asyncioはcooperative multitaskingを使用します。 タスクは、スイッチアウトの準備ができたときに通知することで協力する必要があります。 つまり、これを実現するには、タスク内のコードをわずかに変更する必要があります。
この追加の作業を事前に行うことの利点は、タスクがどこでスワップアウトされるかを常に知っていることです。 Pythonステートメントがマークされていない限り、Pythonステートメントの途中でスワップアウトされることはありません。 これにより、デザインの一部がどのように簡素化されるかについては、後で説明します。
並列処理とは
これまで、単一のプロセッサで発生する同時実行性について見てきました。 クールで新しいラップトップのCPUコアはどうですか? それらをどのように利用できますか? multiprocessingが答えです。
multiprocessingを使用すると、Pythonは新しいプロセスを作成します。 ここでのプロセスは、ほぼ完全に異なるプログラムと考えることができますが、技術的には、通常、リソースにはメモリ、ファイルハンドルなどが含まれるリソースのコレクションとして定義されます。 それについて考える1つの方法は、各プロセスが独自のPythonインタープリターで実行されることです。
これらは異なるプロセスであるため、マルチプロセッシングプログラムの一連の思考はそれぞれ異なるコアで実行できます。 別のコアで実行すると、実際に同時に実行できることを意味します。これはすばらしいことです。 これを行うことから生じるいくつかの複雑さはありますが、Pythonはほとんどの場合、それらをスムーズにするという非常に良い仕事をします。
並行処理と並列処理の概要がわかったので、それらの違いを確認して、それらがなぜ役立つのかを見てみましょう。
| 並行性タイプ | 切り替えの決定 | プロセッサーの数 |
|---|---|---|
プリエンプティブマルチタスク( |
オペレーティングシステムは、Pythonの外部でタスクを切り替えるタイミングを決定します。 |
1 |
協調マルチタスク( |
タスクは、いつ制御を放棄するかを決定します。 |
1 |
マルチプロセッシング( |
プロセスはすべて、異なるプロセッサで同時に実行されます。 |
Many |
これらのタイプの同時実行性はそれぞれ有用です。 スピードアップに役立つプログラムの種類を見てみましょう。
同時実行性はいつ有用ですか?
並行性は、2種類の問題に対して大きな違いをもたらす可能性があります。 これらは一般にCPUバウンドおよびI / Oバウンドと呼ばれます。
I/O-bound problems cause your program to slow down because it frequently must wait for input/output (I/O) from some external resource. プログラムがCPUよりもかなり遅いもので動作しているときに頻繁に発生します。
CPUよりも遅いものの例は大勢ですが、プログラムはありがたいことにそれらのほとんどと対話しません。 プログラムが最も頻繁にやり取りするのは、ファイルシステムとネットワーク接続です。
それがどのように見えるか見てみましょう:
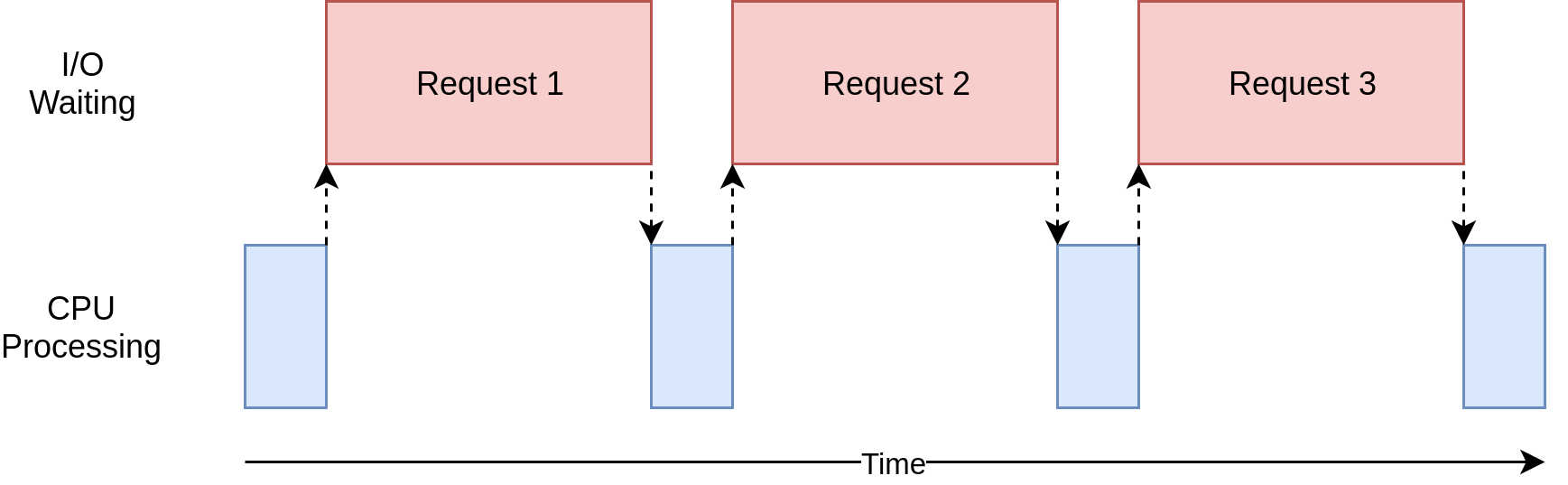
上の図では、青いボックスはプログラムが作業を行っている時間を示し、赤いボックスはI / O操作が完了するまでの時間を示しています。 インターネット上の要求はCPU命令よりも数桁長くかかる可能性があるため、この図は縮尺どおりではありません。そのため、プログラムはほとんどの時間を待機することになります。 これは、ブラウザがほとんどの場合に実行していることです。
一方、ネットワークと対話したりファイルにアクセスしたりせずに重要な計算を行うプログラムのクラスがあります。 プログラムの速度を制限するリソースはCPUであり、ネットワークまたはファイルシステムではないため、これらはCPUにバインドされたプログラムです。
CPUにバインドされたプログラムに対応する図を次に示します。
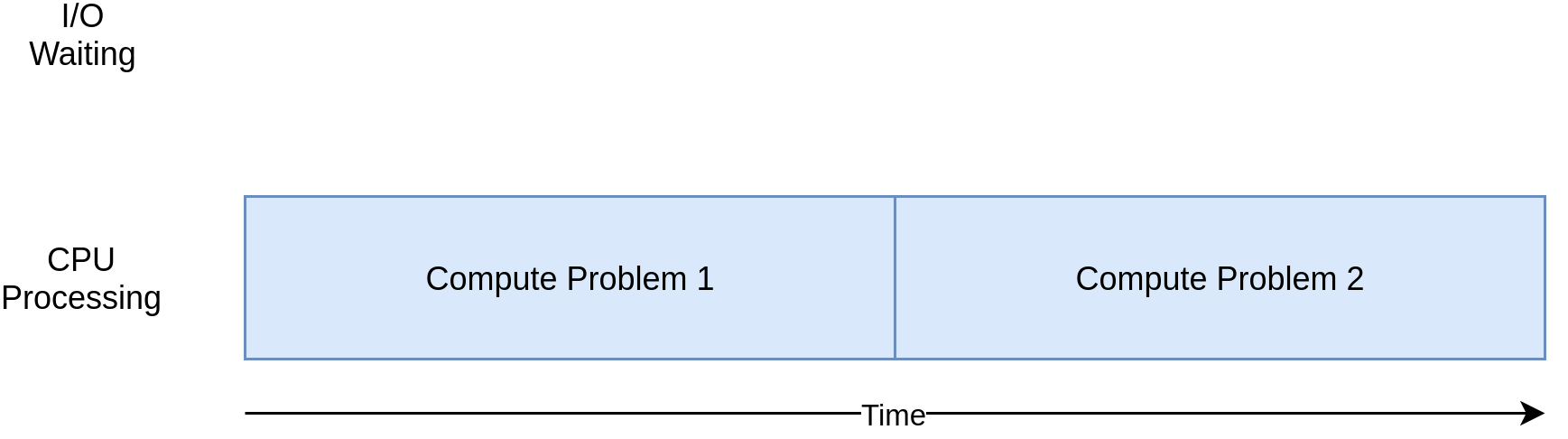
次のセクションの例を見ていくと、CPUにバインドされたプログラムとI / Oにバインドされたプログラムでは、さまざまな形式の同時実行がうまくまたは悪くなることがわかります。 プログラムに並行性を追加すると、余分なコードと複雑さが追加されるため、潜在的な高速化に余分な労力が必要かどうかを判断する必要があります。 この記事の終わりまでに、その決定を開始するのに十分な情報が得られるはずです。
この概念を明確にするための簡単な要約を次に示します。
| I/O-Bound Process | CPUバウンドプロセス |
|---|---|
プログラムは、ほとんどの時間をネットワーク接続、ハードドライブ、プリンターなどの低速デバイスとの通信に費やしています。 |
プログラムは、ほとんどの時間をCPU操作に費やします。 |
それをスピードアップするには、これらのデバイスを待つために費やされる時間を重複させる必要があります。 |
それをスピードアップするには、同じ時間でより多くの計算を行う方法を見つける必要があります。 |
まず、I / Oにバインドされたプログラムを見ていきます。 次に、CPUにバインドされたプログラムを処理するコードを確認します。
I / Oバウンドプログラムを高速化する方法
まず、I / Oにバインドされたプログラムと、ネットワークを介したコンテンツのダウンロードという一般的な問題に焦点を当てます。 この例では、いくつかのサイトからWebページをダウンロードしますが、実際にはネットワークトラフィックである可能性があります。 ウェブページを視覚化して設定する方が簡単です。
同期バージョン
このタスクの非並行バージョンから始めます。 このプログラムにはrequestsモジュールが必要であることに注意してください。 おそらくvirtualenvを使用して、実行する前にpip install requestsを実行する必要があります。 このバージョンでは、並行性はまったく使用されません。
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")ご覧のとおり、これはかなり短いプログラムです。 download_site()は、URLからコンテンツをダウンロードし、サイズを出力するだけです。 指摘すべき小さなことの1つは、requestsのSessionオブジェクトを使用していることです。
requestsからget()を直接使用することは可能ですが、Sessionオブジェクトを作成すると、requestsがいくつかの凝ったネットワークトリックを実行し、実際に処理を高速化できます。
download_all_sites()はSessionを作成し、サイトのリストをウォークスルーして、各サイトを順番にダウンロードします。 最後に、このプロセスにかかった時間を出力するので、次の例でどれだけの並行性が私たちを助けたのかを見ることができます。
このプログラムの処理図は、前のセクションのI / Oバウンド図によく似ています。
Note:ネットワークトラフィックは、秒ごとに異なる可能性のある多くの要因に依存しています。 ネットワークの問題が原因で、これらのテストの時間は実行ごとに2倍になるのを見てきました。
同期バージョンがロックする理由
このバージョンのコードの素晴らしいところは、簡単なことです。 作成とデバッグは比較的簡単でした。 考えるのも簡単です。 思考の流れは1つしかないので、次のステップとその動作を予測できます。
同期バージョンの問題
ここでの大きな問題は、これから提供する他のソリューションに比べて比較的遅いことです。 これが、私のマシンでの最終出力の例です。
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 secondsNote:結果は大幅に異なる場合があります。 このスクリプトを実行すると、時間は14.2秒から21.9秒まで変化することがわかりました。 この記事では、3回の実行のうち最速のものを時間として使用しました。 方法の違いはまだ明らかです。
ただし、遅くなることは必ずしも大きな問題ではありません。 実行中のプログラムが同期バージョンで2秒しかかからず、めったに実行されない場合、同時実行性を追加する価値はおそらくないでしょう。 ここでやめることができます。
プログラムが頻繁に実行されるとどうなりますか? 実行に数時間かかる場合はどうなりますか? threadingを使用してこのプログラムを書き直し、並行性に移りましょう。
threadingバージョン
おそらくご想像のとおり、スレッド化されたプログラムの作成にはより多くの労力が必要です。 ただし、単純な場合に余分な労力がほとんどかからないことに驚くかもしれません。 同じプログラムがthreadingでどのように見えるかを次に示します。
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")threadingを追加すると、全体的な構造は同じになり、いくつかの変更を加えるだけで済みます。 download_all_sites()は、サイトごとに1回関数を呼び出すことから、より複雑な構造に変更されました。
このバージョンでは、ThreadPoolExecutorを作成していますが、これは複雑なことのようです。 それを分解してみましょう:ThreadPoolExecutor =Thread +Pool +Executor。
あなたはすでにThreadの部分について知っています。 これは先ほど述べた一連の考え方に過ぎません。 Poolの部分は、それが面白くなり始めるところです。 このオブジェクトは、それぞれが同時に実行できるスレッドのプールを作成します。 最後に、Executorは、プール内の各スレッドをいつどのように実行するかを制御する部分です。 プールでリクエストを実行します。
便利なことに、標準ライブラリはコンテキストマネージャとしてThreadPoolExecutorを実装しているため、with構文を使用して、Threadsのプールの作成と解放を管理できます。
ThreadPoolExecutorを取得したら、その便利な.map()メソッドを使用できます。 このメソッドは、リスト内の各サイトで渡された関数を実行します。 優れた点は、管理しているスレッドのプールを使用して自動的にそれらを同時に実行することです。
他の言語、またはPython 2から来ている人は、Thread.start()、%など、threadingを処理するときに慣れている詳細を管理する通常のオブジェクトと関数がどこにあるのか疑問に思っているでしょう。 (t2)s、およびQueue。
これらはすべてそこにあり、それらを使用してスレッドの実行方法をきめ細かく制御できます。 ただし、Python 3.2以降、標準ライブラリはExecutorsと呼ばれる高レベルの抽象化を追加しました。これは、きめ細かい制御が必要ない場合に、詳細の多くを管理します。
この例のもう1つの興味深い変更は、各スレッドが独自のrequests.Session()オブジェクトを作成する必要があることです。 requestsのドキュメントを見ると、必ずしも簡単にわかるとは限りませんが、this issueを読むと、スレッドごとに個別のセッションが必要であることは明らかです。
これは、threadingの面白くて難しい問題の1つです。 オペレーティングシステムは、タスクが中断されて別のタスクが開始されるタイミングを制御しているため、スレッド間で共有されるデータは保護するか、スレッドセーフにする必要があります。 残念ながら、requests.Session()はスレッドセーフではありません。
データの内容と使用方法に応じて、データアクセスをスレッドセーフにするための戦略がいくつかあります。 それらの1つは、PythonのqueueモジュールのQueueのようなスレッドセーフなデータ構造を使用することです。
これらのオブジェクトは、threading.Lockのような低レベルのプリミティブを使用して、1つのスレッドのみがコードのブロックまたはメモリのビットに同時にアクセスできるようにします。 この戦略は、ThreadPoolExecutorオブジェクトを介して間接的に使用しています。
ここで使用する別の戦略は、スレッドローカルストレージと呼ばれるものです。 Threading.local()は、グローバルのように見えますが、個々のスレッドに固有のオブジェクトを作成します。 あなたの例では、これはthreadLocalとget_session()で行われます:
threadLocal = threading.local()
def get_session():
if not hasattr(threadLocal, "session"):
threadLocal.session = requests.Session()
return threadLocal.sessionThreadLocalは、この問題を具体的に解決するためにthreadingモジュールにあります。 少し奇妙に見えますが、作成するのはこれらのオブジェクトのうちの1つだけであり、スレッドごとに作成するのではありません。 オブジェクト自体が、異なるスレッドから異なるデータへのアクセスを分離します。
get_session()が呼び出されると、検索されるsessionは、それが実行されている特定のスレッドに固有です。 したがって、各スレッドは、最初にget_session()を呼び出すときに単一のセッションを作成し、その後、その存続期間中、後続の各呼び出しでそのセッションを使用するだけです。
最後に、スレッド数の選択に関する簡単なメモ。 サンプルコードでは5つのスレッドを使用していることがわかります。 この数値を自由に試して、全体の時間がどのように変化するかを確認してください。 あなたはダウンロードごとに1つのスレッドを持っていることが最も速いと期待するかもしれませんが、少なくとも私のシステムではそうではありませんでした。 5〜10スレッドのどこかで最速の結果が見つかりました。 それよりも高くすると、スレッドを作成および破棄するための余分なオーバーヘッドにより、時間を節約できなくなります。
ここで難しい答えは、スレッドの正しい数は、あるタスクから別のタスクへの定数ではないということです。 いくつかの実験が必要です。
threadingバージョンがロックする理由
これは速い! これが私のテストの最速の実行です。 非同時バージョンには14秒以上かかったことを思い出してください。
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 secondsその実行タイミング図は次のとおりです。
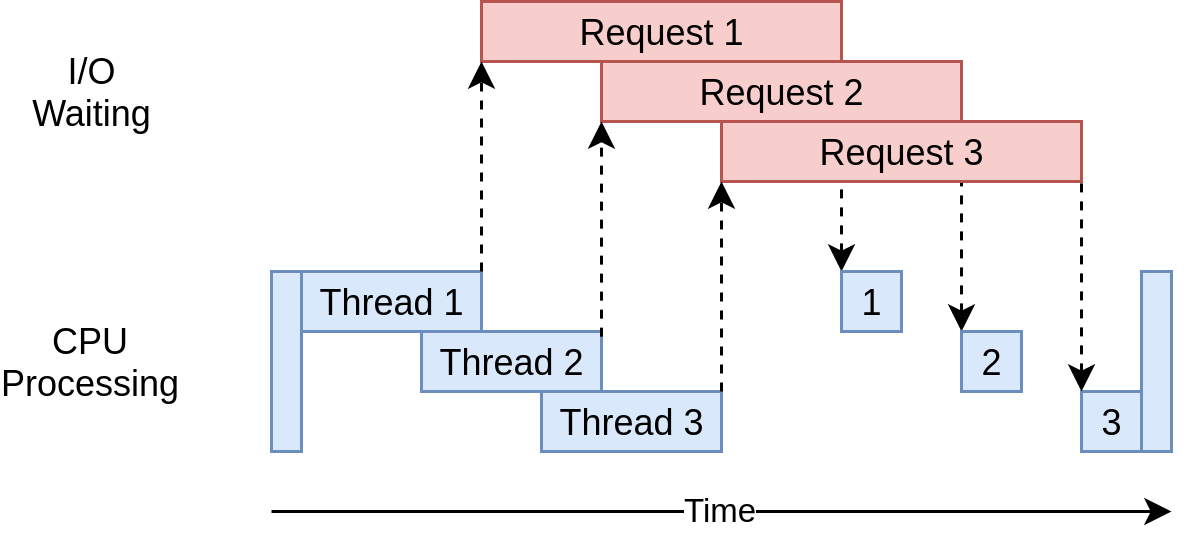
複数のスレッドを使用して、Webサイトに同時に複数のオープンリクエストを送信し、プログラムが待機時間をオーバーラップして、最終結果をより速く取得できるようにします。 イッピー! それが目標でした。
threadingバージョンの問題
さて、例からわかるように、これを実現するにはもう少しコードが必要であり、スレッド間でどのデータが共有されているかを本当に考える必要があります。
スレッドは、微妙で検出が困難な方法で対話できます。 これらの相互作用により、競合状態が発生する可能性があり、その結果、ランダムで断続的なバグが頻繁に発生するため、見つけるのは非常に困難です。 競合状態の概念に不慣れな方は、以下のセクションを拡大して読んでください。
asyncioバージョン
asyncioのサンプルコードを調べる前に、asyncioがどのように機能するかについて詳しく説明しましょう。
asyncioの基本
これは、asycioの簡略化されたバージョンになります。 ここには多くの詳細が記載されていますが、それがどのように機能するかという考えはまだ伝わっています。
asyncioの一般的な概念は、イベントループと呼ばれる単一のPythonオブジェクトが、各タスクをいつどのように実行するかを制御することです。 イベントループは各タスクを認識し、その状態を把握しています。 実際には、タスクが存在する可能性のある状態は多数ありますが、ここでは、2つの状態のみを持つ単純化されたイベントループを考えてみましょう。
準備完了状態は、タスクに実行すべき作業があり、実行準備ができていることを示します。待機状態は、タスクがネットワーク操作などの外部の処理が完了するのを待っていることを意味します。
単純化されたイベントループは、これらの状態ごとに1つずつ、2つのタスクリストを保持します。 実行可能なタスクの1つを選択し、実行を再開します。 このタスクは、イベントループに制御を協調的に戻すまで完全に制御されます。
実行中のタスクがイベントループに制御を戻すと、イベントループはそのタスクを準備完了リストまたは待機リストに配置し、待機リスト内の各タスクを調べて、I / O操作によって準備完了になったかどうかを確認します。完了します。 実行可能リストにあるタスクは、まだ実行されていないことがわかっているため、まだ準備ができていることがわかります。
すべてのタスクが再び正しいリストに分類されると、イベントループは次に実行するタスクを選択し、プロセスが繰り返されます。 単純化されたイベントループは、最も長く待機していたタスクを選択して実行します。 このプロセスは、イベントループが終了するまで繰り返されます。
asyncioの重要な点は、タスクが意図的に制御を放棄しない限り、制御を放棄しないことです。 操作の途中で中断されることはありません。 これにより、threadingよりもasyncioでリソースを少し簡単に共有できます。 コードをスレッドセーフにすることを心配する必要はありません。
これは、asyncioで何が起こっているかについての概要です。 より詳細な情報が必要な場合、さらに深く掘り下げたい場合は、this StackOverflow answerがいくつかの適切な詳細情報を提供します。
asyncおよびawait
次に、Pythonに追加された2つの新しいキーワードasyncとawaitについて説明します。 上記の説明に照らして、awaitは、タスクが制御をイベントループに戻すことを可能にする魔法と見なすことができます。 コードが関数呼び出しを待つとき、それは呼び出しがしばらくかかるものであり、タスクが制御を放棄する可能性が高いことを示すシグナルです。
asyncは、定義しようとしている関数がawaitを使用していることを示すPythonへのフラグと考えるのが最も簡単です。 asynchronous generatorsのように、これが厳密に当てはまらない場合もありますが、多くの場合に当てはまり、開始時に単純なモデルが得られます。
次のコードに表示されるこれに対する1つの例外は、async withステートメントです。これは、通常待機するオブジェクトからコンテキストマネージャーを作成します。 セマンティクスは少し異なりますが、考え方は同じです。このコンテキストマネージャーにスワップアウトできるものとしてフラグを立てることです。
想像できると思いますが、イベントループとタスク間の相互作用の管理には多少の複雑さがあります。 asyncioで始まる開発者にとって、これらの詳細は重要ではありませんが、awaitを呼び出す関数はすべてasyncでマークする必要があることを覚えておく必要があります。 そうしないと、構文エラーが発生します。
コードに戻る
asyncioとは何かについての基本的な理解ができたので、サンプルコードのasyncioバージョンを見ていき、それがどのように機能するかを理解しましょう。 このバージョンではaiohttpが追加されることに注意してください。 実行する前にpip install aiohttpを実行する必要があります。
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")このバージョンは、前の2つよりも少し複雑です。 構造は似ていますが、ThreadPoolExecutorを作成するよりも、タスクを設定する作業が少し多くなります。 例の一番上から始めましょう。
download_site()
上部のdownload_site()は、関数定義行のasyncキーワードと、実際にsession.get()を呼び出すときのasync withキーワードを除いて、threadingバージョンとほぼ同じです。 )s。 スレッドローカルストレージを使用するのではなく、Sessionをここに渡すことができる理由は後でわかります。
download_all_sites()
download_all_sites()は、threadingの例からの最大の変化が見られる場所です。
セッションはすべてのタスクで共有できるため、セッションはコンテキストマネージャーとしてここで作成されます。 すべてのタスクは同じスレッドで実行されているため、タスクはセッションを共有できます。 セッションが悪い状態にある間、あるタスクが別のタスクを中断する方法はありません。
そのコンテキストマネージャー内で、asyncio.ensure_future()を使用してタスクのリストを作成し、タスクの開始も処理します。 すべてのタスクが作成されると、この関数はasyncio.gather()を使用して、すべてのタスクが完了するまでセッションコンテキストを存続させます。
threadingコードはこれと同様のことを行いますが、詳細はThreadPoolExecutorで便利に処理されます。 現在、AsyncioPoolExecutorクラスはありません。
ただし、ここでは詳細に小さな重要な変更が1つあります。 作成するスレッドの数について話したことを覚えていますか? threadingの例では、最適なスレッド数が何であるかは明らかではありませんでした。
asyncioの優れた利点の1つは、threadingよりもはるかに優れたスケーリングを実現することです。 各タスクはスレッドよりもはるかに少ないリソースと作成時間で済むため、より多くのリソースを作成して実行するのが適切です。 この例では、ダウンロードするサイトごとに個別のタスクを作成するだけで、非常にうまく機能します。
__main__
最後に、asyncioの性質は、イベントループを開始し、実行するタスクを指示する必要があることを意味します。 ファイルの下部にある__main__セクションには、get_event_loop()、次にrun_until_complete()のコードが含まれています。 他に何もないとしても、彼らはそれらの関数の命名において素晴らしい仕事をしました。
Python 3.7に更新した場合、Pythonコア開発者はこの構文を簡略化します。 asyncio.get_event_loop().run_until_complete()早口言葉の代わりに、asyncio.run()を使用できます。
asyncioバージョンがロックする理由
本当に速いです! 私のマシンでのテストでは、これは十分なマージンを持ってコードの最速バージョンでした:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 seconds実行タイミング図は、threadingの例で起こっていることと非常によく似ています。 I / Oリクエストはすべて同じスレッドによって実行されるというだけです。
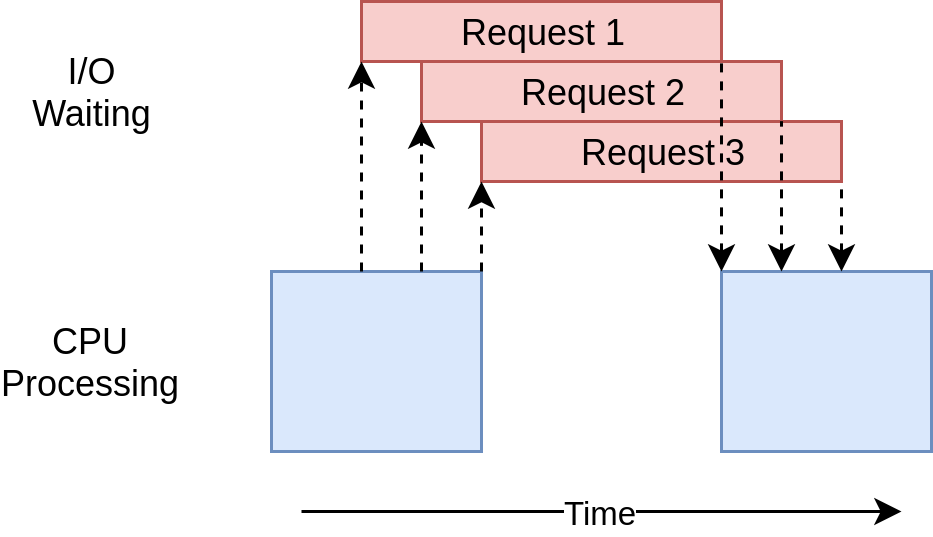
ThreadPoolExecutorのような優れたラッパーがないため、このコードはthreadingの例よりも少し複雑になっています。 これは、パフォーマンスを向上させるために少し余分な作業を行う必要がある場合です。
また、適切な場所にasyncとawaitを追加しなければならないことは、さらに複雑であるという一般的な議論があります。 少しですが、それは事実です。 この議論の裏側は、特定のタスクがいつスワップアウトされるかを考えるように強制することです。これは、より良い、より高速な設計を作成するのに役立ちます。
スケーリングの問題もここで大きく見えます。 上記のthreadingの例を各サイトのスレッドで実行すると、少数のスレッドで実行するよりも著しく遅くなります。 何百ものタスクでasyncioの例を実行しても、速度はまったく低下しませんでした。
asyncioバージョンの問題
この時点で、asyncioにはいくつかの問題があります。 asycioを最大限に活用するには、ライブラリの特別な非同期バージョンが必要です。 サイトのダウンロードにrequestsを使用した場合、requestsはイベントループにブロックされたことを通知するように設計されていないため、はるかに遅くなります。 この問題は、時間が経つにつれてますます小さくなり、より多くのライブラリがasyncioを採用しています。
もう1つのより微妙な問題は、タスクの1つが協調しない場合、協調マルチタスクのすべての利点が失われることです。 コードの軽微なミスにより、タスクが実行されずに長時間プロセッサが停止し、実行が必要な他のタスクが不足する可能性があります。 タスクが制御を渡さない場合、イベントループが割り込む方法はありません。
それを念頭に置いて、並行性に対する根本的に異なるアプローチ、multiprocessingにステップアップしましょう。
multiprocessingバージョン
以前のアプローチとは異なり、コードのmultiprocessingバージョンは、クールで新しいコンピューターが持つ複数のCPUを最大限に活用します。 または、私の場合、私の不器用な古いラップトップが持っていること。 コードから始めましょう:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")これはasyncioの例よりもはるかに短く、実際にはthreadingの例と非常によく似ていますが、コードに入る前に、multiprocessingが何をするのかを簡単に見てみましょう。
一言で言えばmultiprocessing
この時点まで、この記事の同時実行の例はすべて、コンピューターの単一のCPUまたはコアでのみ実行されます。 この理由は、CPythonの現在の設計とグローバルインタープリターロック(GIL)と呼ばれるものに関係しています。
この記事では、GILの方法と理由については詳しく説明しません。 今のところ、この例の同期バージョン、threading、およびasyncioバージョンはすべて単一のCPUで実行されていることを知っていれば十分です。
標準ライブラリのmultiprocessingは、その障壁を打ち破り、複数のCPUでコードを実行するように設計されています。 高レベルでは、Pythonインタープリターの新しいインスタンスを作成して各CPUで実行し、プログラムの一部を実行して実行します。
ご想像のとおり、別のPythonインタープリターを起動するのは、現在のPythonインタープリターで新しいスレッドを開始するほど速くありません。 これは重量のある操作であり、いくつかの制限と困難が伴いますが、正しい問題のためには大きな違いを生む可能性があります。
multiprocessingコード
コードには、同期バージョンからいくつかの小さな変更があります。 最初のものはdownload_all_sites()にあります。 単にdownload_site()を繰り返し呼び出す代わりに、multiprocessing.Poolオブジェクトを作成し、download_siteを反復可能なsitesにマップします。 これは、threadingの例から見覚えがあるはずです。
ここで何が起こるかというと、Poolはいくつかの個別のPythonインタープリタープロセスを作成し、それぞれがイテラブル内のいくつかのアイテム(この場合はサイトのリスト)に対して指定された関数を実行します。 メインプロセスと他のプロセス間の通信は、multiprocessingモジュールによって処理されます。
Poolを作成する行は注目に値します。 まず、Poolに作成するプロセスの数は指定されていませんが、これはオプションのパラメーターです。 デフォルトでは、multiprocessing.Pool()がコンピューター内のCPUの数を決定し、それに一致します。 これはしばしば最良の答えであり、私たちの場合です。
この問題では、プロセスの数を増やしても処理が速くなりませんでした。 これらすべてのプロセスのセットアップと破棄のコストは、I / O要求を並行して行う利点よりも大きいため、実際には速度が低下しました。
次に、その呼び出しのinitializer=set_global_session部分があります。 Poolの各プロセスには、独自のメモリスペースがあることに注意してください。 つまり、Sessionオブジェクトのようなものを共有することはできません。 関数が呼び出されるたびに新しいSessionを作成するのではなく、プロセスごとに作成する必要があります。
initializer関数パラメーターは、この場合のために作成されています。 戻り値をinitializerからプロセスdownload_site()によって呼び出される関数に戻す方法はありませんが、グローバルsession変数を初期化して、それぞれの単一セッションを保持することができます。処理する。 各プロセスには独自のメモリ空間があるため、各プロセスのグローバルは異なります。
それだけです。 コードの残りの部分は、前に見たものと非常に似ています。
multiprocessingバージョンがロックする理由
この例のmultiprocessingバージョンは、セットアップが比較的簡単で、追加のコードがほとんど必要ないため、優れています。 また、コンピューターのCPUパワーを最大限に活用します。 このコードの実行タイミング図は次のようになります。
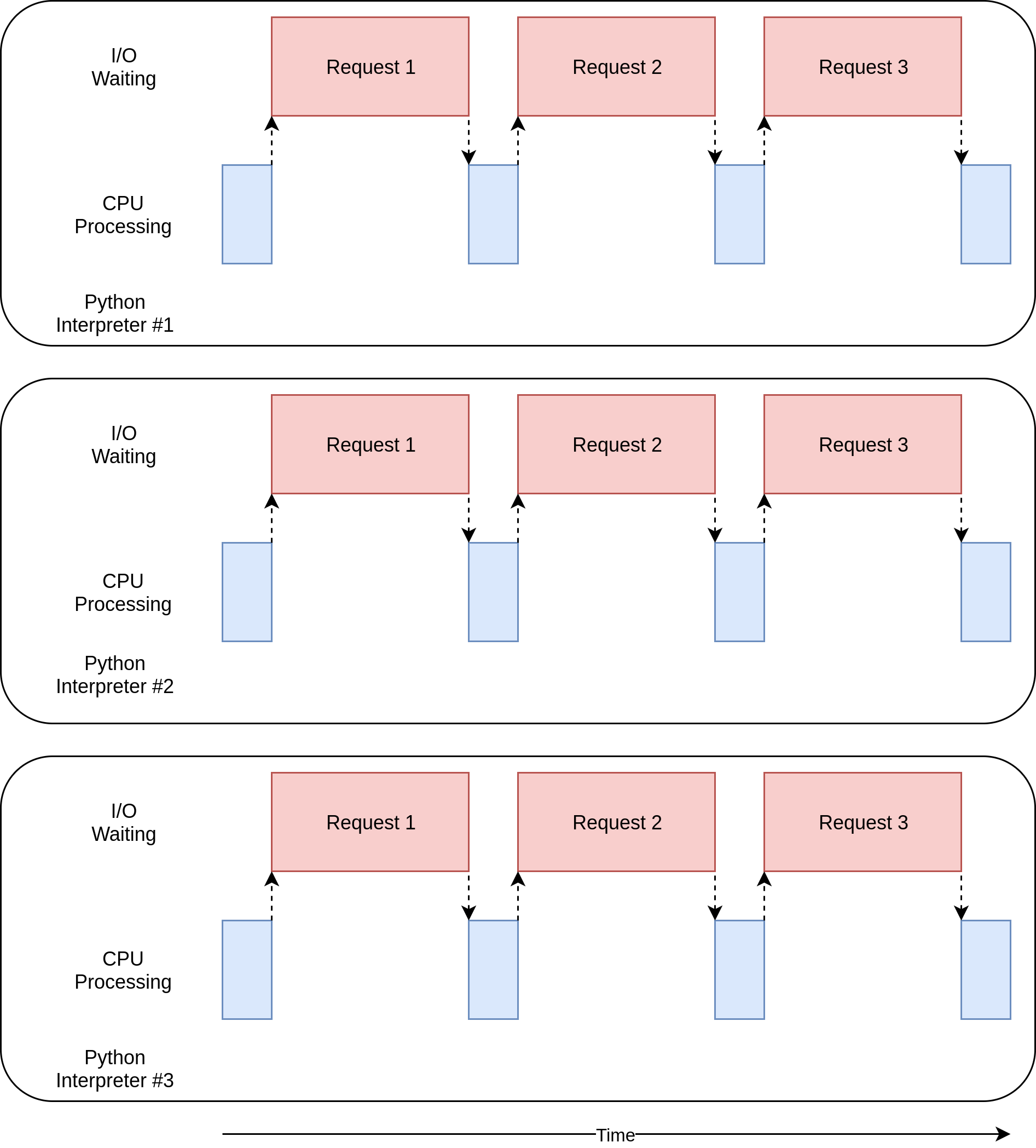
multiprocessingバージョンの問題
このバージョンの例では、追加のセットアップが必要であり、グローバルsessionオブジェクトは奇妙です。 各プロセスでどの変数にアクセスするかを考えるのに時間をかける必要があります。
最後に、この例のasyncioおよびthreadingバージョンよりも明らかに低速です。
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 secondsI / Oバウンドの問題は、multiprocessingが存在する理由ではないため、これは驚くべきことではありません。 次のセクションに進み、CPUバウンドの例を見ると、さらに多くのことがわかります。
CPUバウンドプログラムを高速化する方法
ここで少しギアをシフトしましょう。 これまでの例では、すべてI / Oに関連した問題を扱ってきました。 次に、CPUに関連する問題を調べます。 ご覧のように、I / Oに関連する問題は、ネットワークコールなどの外部操作が完了するのを待つことにほとんどの時間を費やします。 一方、CPUバウンドの問題はI / O操作をほとんど行わず、全体の実行時間は必要なデータを処理できる速度の要因です。
この例の目的のために、CPUでの実行に時間がかかるものを作成するために、やや愚かな関数を使用します。 この関数は、0から渡された値までの各数値の2乗和を計算します。
def cpu_bound(number):
return sum(i * i for i in range(number))多数渡すことになりますので、しばらく時間がかかります。 これは、方程式の根の計算や大規模なデータ構造のソートなど、実際に有用な処理を行い、かなりの処理時間を必要とするコードのプレースホルダーにすぎないことを忘れないでください。
CPUバウンド同期バージョン
次に、非同時バージョンの例を見てみましょう。
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")このコードは、cpu_bound()を20回呼び出し、そのたびに異なる大きな数を呼び出します。 これはすべて、単一CPU上の単一プロセスの単一スレッドで実行されます。 実行タイミング図は次のようになります。
I / Oバウンドの例とは異なり、CPUバウンドの例は通常、実行時間がかなり一貫しています。 これは私のマシンで約7.8秒かかります:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 seconds明らかに、これよりもうまくいくことができます。 これはすべて、同時実行性のない単一のCPUで実行されます。 それを改善するためにできることを見てみましょう。
threadingおよびasyncioバージョン
threadingまたはasyncioを使用してこのコードを書き直すと、これがどれだけ高速化されると思いますか?
「まったくない」と答えた場合は、自分にクッキーを与えます。 「遅くなります」と答えた場合は、2つのCookieを自分に与えます。
その理由は次のとおりです。上記のI / Oバウンドの例では、全体的な時間のほとんどが、遅い操作が完了するのを待つことに費やされました。 threadingとasyncioは、順番に実行するのではなく、待機していた時間をオーバーラップできるようにすることで、これを高速化しました。
ただし、CPUにバインドされた問題では、待機はありません。 CPUは、問題を解決するためにできるだけ速くクランクを切ります。 Pythonでは、スレッドとタスクの両方が同じプロセスの同じCPUで実行されます。 これは、1つのCPUが非並行コードのすべての作業に加えて、スレッドまたはタスクのセットアップという余分な作業を行っていることを意味します。 10秒以上かかります。
$ ./cpu_threading.py
Duration 10.407078266143799 secondsこのコードのthreadingバージョンを作成し、他のサンプルコードと一緒にGitHub repoに配置したので、これを自分でテストできます。 ただし、まだ見ていません。
CPUバウンドmultiprocessingバージョン
これで、multiprocessingが本当に輝くところにようやく到達しました。 他の同時実行ライブラリとは異なり、multiprocessingは、複数のCPU間で重いCPUワークロードを共有するように明示的に設計されています。 その実行タイミング図は次のとおりです。
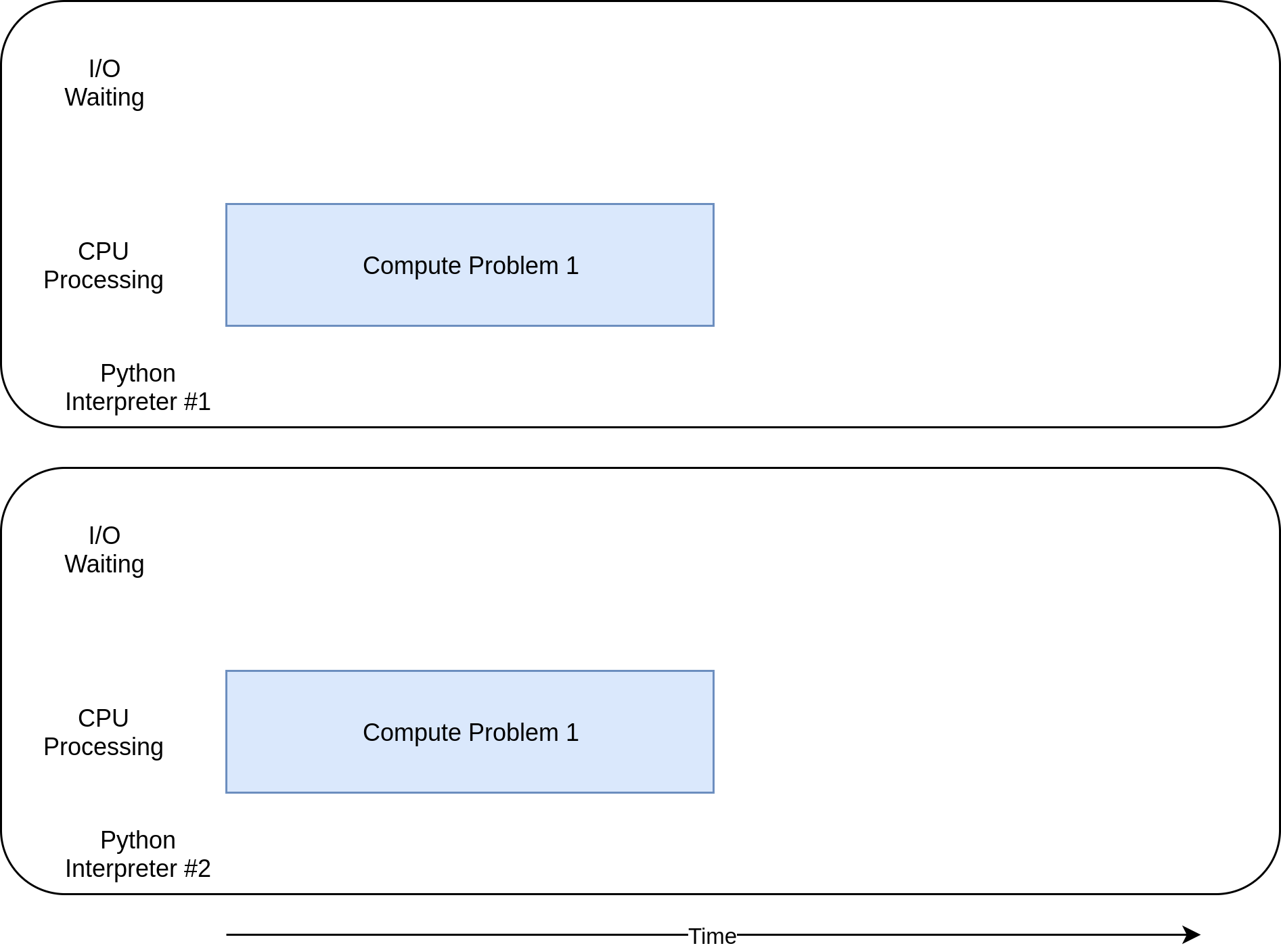
コードは次のようになります。
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")このコードのほとんどは、非並行バージョンから変更する必要がありませんでした。 import multiprocessingを実行してから、数値のループからmultiprocessing.Poolオブジェクトの作成に変更し、その.map()メソッドを使用して、個々の数値が解放されたときにワーカープロセスに送信する必要がありました。
これは、I / Oバウンドのmultiprocessingコードに対して行ったこととまったく同じですが、ここではSessionオブジェクトについて心配する必要はありません。
上記のように、multiprocessing.Pool()コンストラクターのprocessesオプションパラメーターには注意が必要です。 Poolで作成および管理するProcessオブジェクトの数を指定できます。 デフォルトでは、マシンにあるCPUの数を決定し、各CPUのプロセスを作成します。 これは単純な例ではうまく機能しますが、実稼働環境ではもう少し制御したいかもしれません。
また、threadingについて最初のセクションで説明したように、multiprocessing.Poolコードは、QueueやSemaphoreなどのビルディングブロックに基づいて構築されています。他の言語でマルチスレッドおよびマルチプロセッシングコードを実行しました。
multiprocessingバージョンがロックする理由
この例のmultiprocessingバージョンは、セットアップが比較的簡単で、追加のコードがほとんど必要ないため、優れています。 また、コンピューターのCPUパワーを最大限に活用します。
ねえ、それは私たちが最後にmultiprocessingを見たときに私が言ったこととまったく同じです。 大きな違いは、今回が明らかに最適なオプションであることです。 私のマシンでは2.5秒かかります:
$ ./cpu_mp.py
Duration 2.5175397396087646 seconds他のオプションで見たよりもずっと良いです。
multiprocessingバージョンの問題
multiprocessingを使用することにはいくつかの欠点があります。 この単純な例では実際には表示されませんが、問題を分割して各プロセッサが独立して動作できるようにするのは難しい場合があります。
また、多くのソリューションでは、プロセス間のより多くの通信が必要です。 これにより、非並行プログラムで対処する必要のない複雑さがソリューションに追加される可能性があります。
同時実行性を使用する場合
ここまで多くのことを説明してきたので、いくつかの重要なアイデアを確認してから、プロジェクトで使用する同時実行モジュール(ある場合)を決定するのに役立つ決定ポイントについて説明します。
このプロセスの最初のステップは、shouldが並行性モジュールを使用するかどうかを決定することです。 ここの例では、各ライブラリが非常にシンプルに見えますが、同時実行には常に余分な複雑さが伴い、多くの場合、発見が困難なバグが発生する可能性があります。
既知のパフォーマンスの問題が発生し、thenが必要な同時実行のタイプを決定するまで、同時実行の追加を保留します。 Donald Knuthが言っているように、「時期尚早の最適化は、プログラミングにおけるすべての悪(または少なくともそのほとんど)の根源です。」
プログラムを最適化する必要があると判断したら、プログラムがCPUにバインドされているかI / Oにバインドされているかを判断することは、次のステップとして最適です。 I / Oにバインドされたプログラムは、CPUにバインドされたプログラムがデータを処理したり、数字をできるだけ高速に処理するのに時間を費やしている間に、ほとんどの時間を何かが起こるのを待つことに注意してください。
ご覧のとおり、CPUにバインドされた問題は、multiprocessingを使用することによってのみ実際に得られます。 threadingとasyncioは、このタイプの問題をまったく助けませんでした。
I / Oバウンドの問題については、Pythonコミュニティに一般的な経験則があります。「可能な場合はasyncioを使用し、必要な場合はthreadingを使用してください。」 asyncioは、このタイプのプログラムに最高の速度を提供できますが、asyncioを利用するために、移植されていない重要なライブラリが必要になる場合があります。 イベントループへの制御を放棄しないタスクは、他のすべてのタスクをブロックすることに注意してください。
結論
これで、Pythonで利用可能な基本的な並行性のタイプを見てきました。
-
threading -
asyncio -
multiprocessing
特定の問題に対してどの並行性メソッドを使用するか、またはどの並行性メソッドを使用するかを決定するための理解があります。 さらに、同時実行を使用しているときに発生する可能性のある問題のいくつかをよりよく理解することができました。
この記事から多くのことを学び、ご自身のプロジェクトで並行性をうまく活用できることを願っています。 以下にリンクされている「Python Concurrency」クイズを受講して、学習内容を確認してください。
__ Take the Quiz:インタラクティブな「Python同時実行」クイズで知識をテストします。 完了すると、学習の進捗状況を経時的に追跡できるようにスコアを受け取ります。