Python、Boto3、AWS S3:分かりやすい説明
Amazon Web Services(AWS)はクラウドコンピューティングのリーダーになりました。 そのコアコンポーネントの1つは、AWSが提供するオブジェクトストレージサービスであるS3です。 その優れた可用性と耐久性により、ビデオ、画像、データを保存する標準的な方法になりました。 S3を他のサービスと組み合わせて、無限にスケーラブルなアプリケーションを構築できます。
Boto3は、Python SDK forAWSの名前です。 PythonスクリプトからAWSリソースを直接作成、更新、削除できます。
以前にAWSを使用した経験があり、独自のAWSアカウントを持ち、Pythonコード内からAWSサービスの使用を開始してスキルを次のレベルに引き上げたい場合は、読み続けてください。
このチュートリアルの終わりまでに、次のことを行います。
-
Pythonスクリプトから直接バケットとオブジェクトを使用して自信を持って作業する
-
Boto3およびS3を使用するときによくある落とし穴を避ける方法を知っている
-
後でパフォーマンスの問題を回避するために、最初からデータを設定する方法を理解する
-
S3の最高の機能を活用するためにオブジェクトを構成する方法を学びます
Boto3の特性を調べる前に、まず、マシンでSDKを構成する方法を確認します。 このステップでは、チュートリアルの残りの部分を設定します。
Free Bonus:5 Thoughts On Python Masteryは、Python開発者向けの無料コースで、Pythonスキルを次のレベルに引き上げるために必要なロードマップと考え方を示しています。
インストール
コンピューターにBoto3をインストールするには、ターミナルに移動して次を実行します。
$ pip install boto3SDKを入手しました。 ただし、どのAWSアカウントに接続する必要があるかがわからないため、すぐに使用することはできません。
AWSアカウントに対して実行するには、いくつかの有効な認証情報を提供する必要があります。 S3に対する完全なアクセス許可を持つIAMユーザーが既に存在する場合、新しいユーザーを作成する必要なく、それらのユーザーの資格情報(アクセスキーとシークレットアクセスキー)を使用できます。 それ以外の場合、これを行う最も簡単な方法は、新しいAWSユーザーを作成してから、新しい認証情報を保存することです。
新しいユーザーを作成するには、AWSアカウントに移動し、次にServicesに移動してIAMを選択します。 次に、Usersを選択し、Add userをクリックします。
ユーザーに名前を付けます(たとえば、boto3user)。 programmatic accessを有効にします。 これにより、このユーザーは、AWSがサポートするSDKを使用したり、個別のAPI呼び出しを実行したりできるようになります。
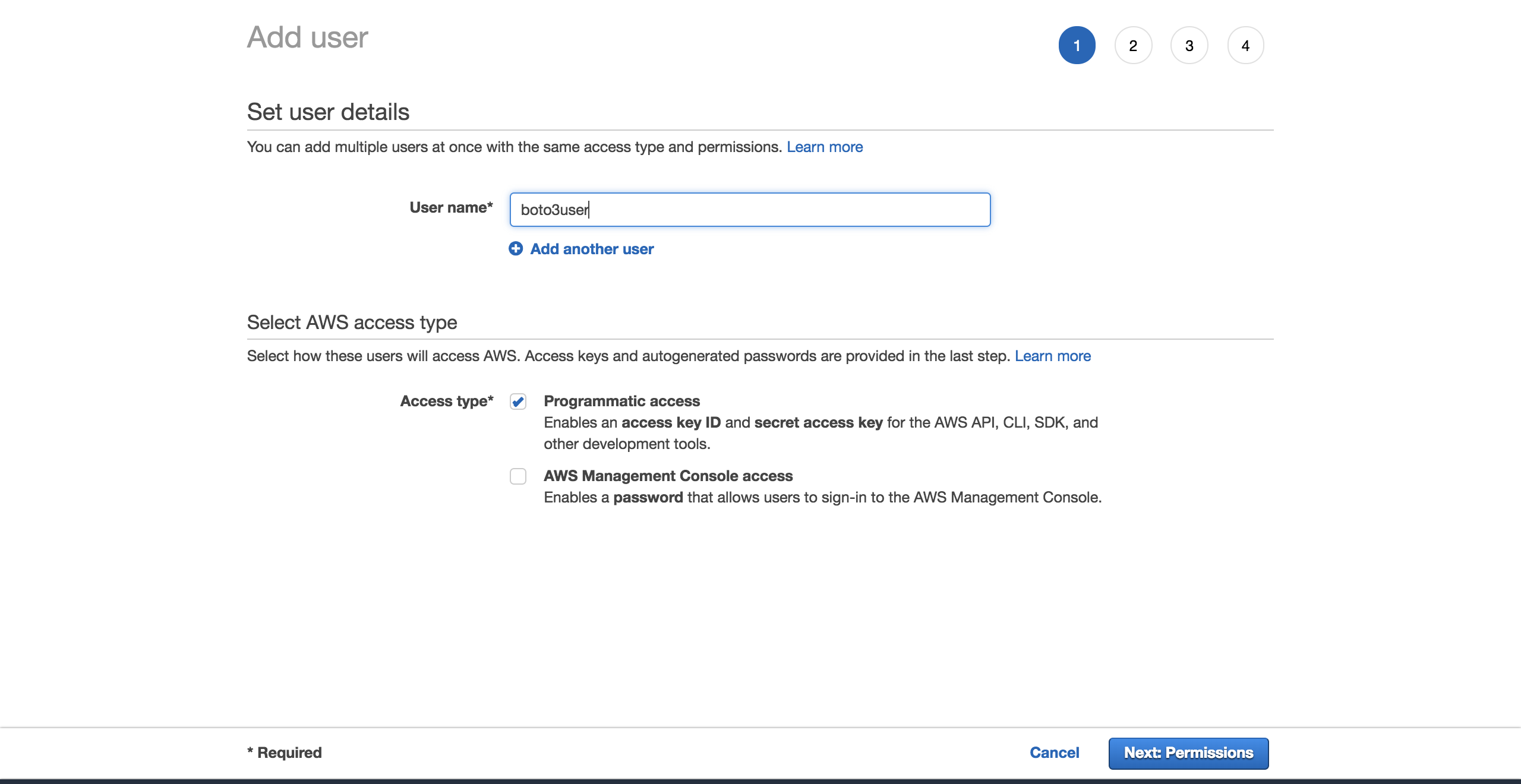
物事を単純にするために、事前設定されたAmazonS3FullAccessポリシーを選択します。 このポリシーを使用すると、新しいユーザーはS3を完全に制御できます。 Next: Reviewをクリックします。
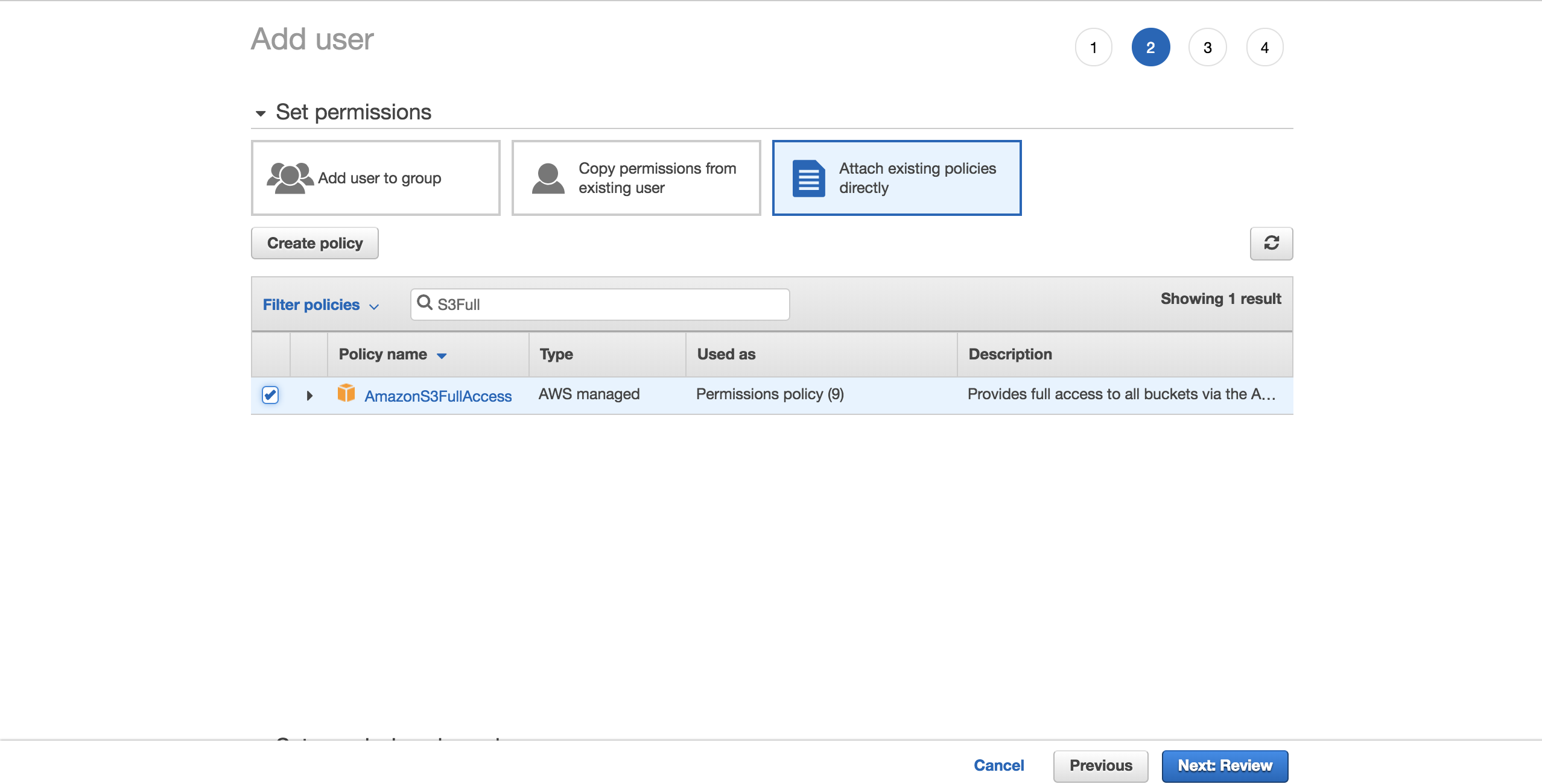
Create userを選択します。
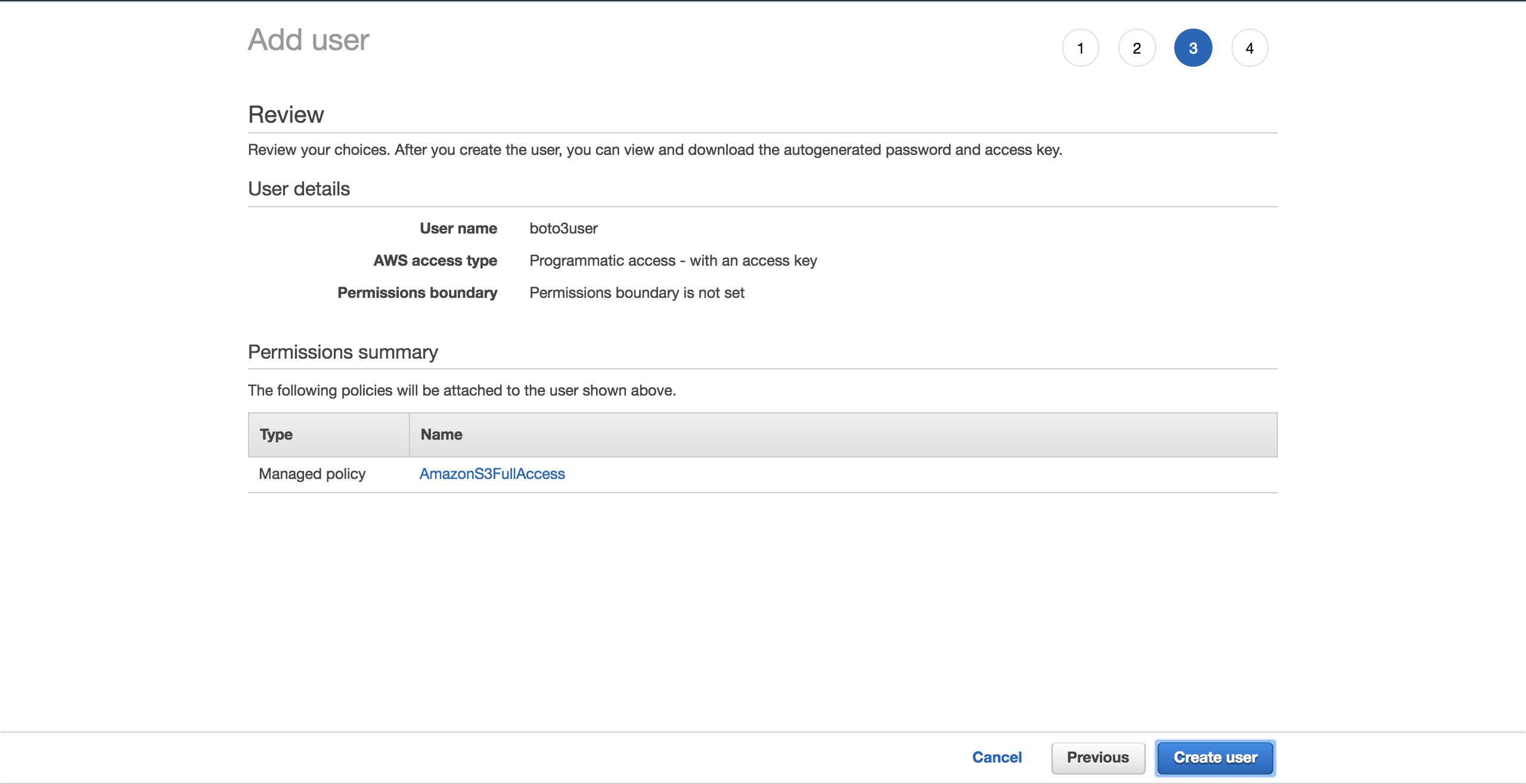
新しい画面に、ユーザーが生成した資格情報が表示されます。 Download .csvボタンをクリックして、資格情報のコピーを作成します。 セットアップを完了するにはそれらが必要になります。
新しいユーザーができたので、新しいファイル~/.aws/credentialsを作成します。
$ touch ~/.aws/credentialsファイルを開き、以下の構造を貼り付けます。 ダウンロードした新しいユーザー資格情報をプレースホルダーに入力します。
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEYファイルを保存してください。
これらの認証情報を設定したので、defaultプロファイルが作成されました。これは、Boto3がAWSアカウントとやり取りするために使用します。
もう1つ設定する設定があります。Boto3が対話するデフォルトの領域です。 complete table of the supported AWS regionsをチェックアウトできます。 あなたに最も近い地域を選択してください。 Region列から希望の地域をコピーします。 私の場合、eu-west-1(アイルランド)を使用しています。
新しいファイル~/.aws/configを作成します。
$ touch ~/.aws/config以下を追加し、プレースホルダーをコピーしたregionに置き換えます。
[default]
region = YOUR_PREFERRED_REGIONファイルを保存してください。
これで、チュートリアルの残りの部分の正式なセットアップが完了しました。
次に、Boto3がS3および他のAWSサービスに接続するために提供するさまざまなオプションが表示されます。
クライアントとリソース
基本的に、Boto3が行うことは、ユーザーに代わってAWS APIを呼び出すことだけです。 大部分のAWSサービスについて、Boto3はこれらの抽象化されたAPIにアクセスする2つの異なる方法を提供します。
-
Client:の低レベルのサービスアクセス
-
Resource:の高レベルのオブジェクト指向サービスアクセス
いずれかを使用して、S3と対話できます。
低レベルのクライアントインターフェイスに接続するには、Boto3のclient()を使用する必要があります。 次に、接続するサービスの名前(この場合はs3)を渡します。
import boto3
s3_client = boto3.client('s3')高レベルのインターフェースに接続するには、同様のアプローチに従いますが、resource()を使用します。
import boto3
s3_resource = boto3.resource('s3')両方のバージョンに正常に接続できましたが、「どちらを使用する必要がありますか?」
クライアントでは、プログラムによる作業をさらに行う必要があります。 クライアント操作の大部分は、dictionary応答を返します。 必要な正確な情報を取得するには、その辞書を自分で解析する必要があります。 リソースメソッドを使用すると、SDKがそれを実行します。
クライアントを使用すると、パフォーマンスが若干向上する場合があります。 欠点は、リソースを使用している場合よりもコードが読みにくくなることです。 リソースはより優れた抽象化を提供し、コードは理解しやすくなります。
クライアントとリソースの生成方法を理解することは、どちらを選択するかを検討する際にも重要です。
-
Boto3は、JSONサービス定義ファイルからクライアントを生成します。 クライアントのメソッドは、ターゲットAWSサービスとのあらゆる種類の対話をサポートします。
-
一方、リソースはJSONリソース定義ファイルから生成されます。
Boto3は、異なる定義からクライアントとリソースを生成します。 その結果、クライアントがサポートする操作がリソースによって提供されない場合があります。 ここで興味深いのは、どこでもクライアントを使用するためにコードを変更する必要がないということです。 その操作では、s3_resource.meta.clientのようにリソースを介してクライアントに直接アクセスできます。
そのようなclient操作の1つが.generate_presigned_url()です。これにより、ユーザーはAWS認証情報を必要とせずに、バケット内のオブジェクトに一定期間アクセスできます。
一般的な操作
クライアントとリソースの違いがわかったので、それらを使用していくつかの新しいS3コンポーネントを構築しましょう。
バケットを作成する
開始するには、S3bucketが必要です。 プログラムでプログラムを作成するには、まずバケットの名前を選択する必要があります。 バケット名はDNSに準拠しているため、この名前はAWSプラットフォーム全体で一意でなければならないことに注意してください。 バケットを作成しようとしたが、別のユーザーが目的のバケット名を既に要求している場合、コードは失敗します。 成功する代わりに、次のエラーが表示されます:botocore.errorfactory.BucketAlreadyExists。
ランダムな名前を選ぶことで、バケットを作成するときに成功する可能性を高めることができます。 それを行う独自の関数を生成できます。 この実装では、uuidモジュールを使用するとそれを実現するのにどのように役立つかがわかります。 UUID4の文字列表現は36文字(ハイフンを含む)で、プレフィックスを追加して各バケットの目的を指定できます。
これを実現する方法は次のとおりです。
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])バケット名を取得しましたが、もう1つ注意する必要があります。お住まいの地域が米国でない限り、バケットを作成するときに地域を明示的に定義する必要があります。 それ以外の場合は、IllegalLocationConstraintExceptionを取得します。
米国以外の地域でS3バケットを作成するときにこれが何を意味するかを例証するには、以下のコードをご覧ください。
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})リージョン(私の場合はeu-west-1)を指定する必要があるバケット名とバケット構成の両方を指定する必要があります。
これは理想的ではありません。 コードを取得してクラウドにデプロイするとします。 リージョンをハードコーディングしたため、タスクはますます難しくなります。 リージョンをリファクタリングして環境変数に変換できますが、もう1つ管理する必要があります。
幸い、sessionオブジェクトを利用して、プログラムで領域を取得するためのより良い方法があります。 Boto3は、資格情報からsessionを作成します。 リージョンを取得して、LocationConstraint構成としてcreate_bucket()に渡す必要があります。 その方法は次のとおりです。
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_response良い点は、このコードがどこにデプロイしても機能することです:local / EC2 / Lambda。 さらに、地域をハードコーディングする必要はありません。
クライアントとリソースの両方が同じ方法でバケットを作成するため、どちらかをs3_connectionパラメータとして渡すことができます。
2つのバケットを作成します。 まず、クライアントを使用して作成します。これにより、bucket_responseが辞書として返されます。
>>>
>>> first_bucket_name, first_response = create_bucket(
... bucket_prefix='firstpythonbucket',
... s3_connection=s3_resource.meta.client)
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1
>>> first_response
{'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}次に、リソースを使用して2番目のバケットを作成します。これにより、Bucketインスタンスがbucket_responseとして返されます。
>>>
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')バケツがあります。 次に、ファイルの追加を開始します。
ファイルに名前を付ける
標準のファイル命名規則を使用して、オブジェクトに名前を付けることができます。 任意の有効な名前を使用できます。 この記事では、S3が内部でどのように機能するかを理解するのに役立つ、より具体的なケースを見ていきます。
S3バケットに多数のファイルをホストすることを計画している場合は、留意すべきことがあります。 すべてのファイル名に、「YYYY-MM-DDThh:mm:ss」のようなタイムスタンプ形式など、ファイルごとに繰り返される確定的なプレフィックスがある場合、すぐにperformance issuesが発生していることがわかります。バケットを操作しようとしているとき。
これは、S3がファイルのプレフィックスを取得してパーティションにマップするために発生します。 ファイルを追加すると、同じパーティションに割り当てられるファイルの数が増え、そのパーティションは非常に重くなり、応答性が低下します。
それが起こらないようにするために何ができますか?
最も簡単な解決策は、ファイル名をランダム化することです。 さまざまな実装を想像できますが、この場合は、信頼できるuuidモジュールを使用してそれを支援します。 このチュートリアルでファイル名を読みやすくするために、生成された数値のhex表現の最初の6文字を取得し、それをベースファイル名と連結します。
以下のヘルパー関数を使用すると、ファイルに必要なバイト数、ファイル名、およびファイルのサンプルコンテンツを渡して、目的のファイルサイズを構成できます。
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_nameすぐに使用する最初のファイルを作成します。
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')ファイル名にランダム性を追加することにより、S3バケット内でデータを効率的に配布できます。
BucketおよびObjectインスタンスの作成
ファイルを作成した後の次のステップは、ファイルをS3ワークフローに統合する方法を確認することです。
これらの抽象化によりS3での作業が容易になるため、リソースのクラスが重要な役割を果たします。
リソースを使用することで、高レベルのクラス(BucketおよびObject)にアクセスできます。 これは、それぞれの1つを作成する方法です。
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)first_object変数の作成でエラーが発生しなかった理由は、Boto3が参照を作成するためにAWSを呼び出さないためです。 bucket_nameとkeyは識別子と呼ばれ、Objectを作成するために必要なパラメーターです。 サイズなど、Objectの他の属性はすべて遅延ロードされます。 つまり、Boto3が要求された属性を取得するには、AWSを呼び出す必要があります。
サブリソースを理解する
BucketとObjectは、相互のサブリソースです。 サブリソースは、子リソースの新しいインスタンスを作成するメソッドです。 親の識別子は子リソースに渡されます。
Bucket変数がある場合は、Objectを直接作成できます。
first_object_again = first_bucket.Object(first_file_name)または、Object変数がある場合は、Bucketを取得できます。
first_bucket_again = first_object.Bucket()これで、BucketとObjectを生成する方法を理解できました。 次に、これらの構成要素を使用して、新しく生成されたファイルをS3にアップロードします。
ファイルをアップロードする
ファイルをアップロードするには、次の3つの方法があります。
-
Objectインスタンスから -
Bucketインスタンスから -
clientから
いずれの場合も、アップロードするファイルのパスであるFilenameを指定する必要があります。 次に、3つの代替案を検討します。 first_file_nameをS3にアップロードするために、最も好きなものを自由に選択してください。
オブジェクトインスタンスバージョン
Objectインスタンスを使用してアップロードできます。
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)または、first_objectインスタンスを使用できます。
first_object.upload_file(first_file_name)バケットインスタンスバージョン
Bucketインスタンスを使用してアップロードする方法は次のとおりです。
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)クライアントバージョン
clientを使用してアップロードすることもできます。
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)3つの使用可能な方法のいずれかを使用して、ファイルをS3に正常にアップロードしました。 次のセクションでは、操作がclientバージョンとBucketバージョンの間で非常に似ているため、主にObjectクラスを使用します。
ファイルをダウンロードする
S3からローカルにファイルをダウンロードするには、アップロード時と同様の手順に従います。 ただし、この場合、Filenameパラメーターは目的のローカルパスにマップされます。 今回は、ファイルをtmpディレクトリにダウンロードします。
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+S3からファイルを正常にダウンロードしました。 次に、単一のAPI呼び出しを使用して、S3バケット間で同じファイルをコピーする方法を確認します。
バケット間でオブジェクトをコピーする
あるバケットから別のバケットにファイルをコピーする必要がある場合、Boto3はその可能性を提供します。 この例では、.copy()を使用して、最初のバケットから2番目のバケットにファイルをコピーします。
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)Note: S3オブジェクトを別のリージョンのバケットに複製することを目的としている場合は、Cross Region Replicationを確認してください。
オブジェクトを削除する
同等のObjectインスタンスで.delete()を呼び出して、2番目のバケットから新しいファイルを削除しましょう。
s3_resource.Object(second_bucket_name, first_file_name).delete()これで、S3のコア操作の使用方法がわかりました。 次のセクションで、より複雑な特性を使用して、知識を次のレベルに引き上げる準備ができました。
高度な構成
このセクションでは、より精巧なS3機能について説明します。 それらの使用方法の例と、それらがアプリケーションにもたらす利点が表示されます。
ACL(アクセス制御リスト)
アクセス制御リスト(ACL)は、バケットとバケット内のオブジェクトへのアクセスを管理するのに役立ちます。 これらは、S3へのアクセス許可を管理する従来の方法と見なされます。 なぜあなたはそれらについて知る必要がありますか? 個々のオブジェクトへのアクセスを管理する必要がある場合は、オブジェクトACLを使用します。
デフォルトでは、オブジェクトをS3にアップロードすると、そのオブジェクトはプライベートになります。 このオブジェクトを他の人が利用できるようにする場合は、作成時にオブジェクトのACLをパブリックに設定できます。 新しいファイルをバケットにアップロードし、誰でもアクセスできるようにする方法は次のとおりです。
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})Objectは、そのサブリソースクラスの1つであるため、Objectから取得できます。
second_object_acl = second_object.Acl()オブジェクトにアクセスできるユーザーを確認するには、grants属性を使用します。
>>>
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]オブジェクトを再アップロードすることなく、再びプライベートにできます。
>>>
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]ACLを使用して個々のオブジェクトへのアクセスを管理する方法を見てきました。 次に、暗号化を使用してオブジェクトにセキュリティのレイヤーを追加する方法を確認します。
Note:データを複数のカテゴリに分割する場合は、tagsをご覧ください。 タグに基づいてオブジェクトへのアクセスを許可できます。
暗号化
S3では、暗号化を使用してデータを保護できます。 AWSが暗号化とキーの両方を管理するAES-256アルゴリズムを使用して、サーバー側の暗号化を調べます。
新しいファイルを作成し、ServerSideEncryptionを使用してアップロードします。
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})ファイルの暗号化に使用されたアルゴリズム(この場合はAES256)を確認できます。
>>>
>>> third_object.server_side_encryption
'AES256'これで、AWSが提供するAES-256サーバー側の暗号化アルゴリズムを使用して、オブジェクトに追加の保護レイヤーを追加する方法を理解できました。
ストレージ
S3バケットに追加するすべてのオブジェクトは、storage classに関連付けられています。 利用可能なすべてのストレージクラスは、高い耐久性を提供します。 アプリケーションのパフォーマンスアクセス要件に基づいて、オブジェクトの保存方法を選択します。
現在、S3では次のストレージクラスを使用できます。
-
STANDARD:頻繁にアクセスされるデータのデフォルト
-
STANDARD_IA:要求されたときに迅速に取得する必要がある、使用頻度の低いデータの場合
-
ONEZONE_IA:STANDARD_IAと同じユースケースですが、データを3つではなく1つのアベイラビリティーゾーンに格納します
-
REDUCED_REDUNDANCY:簡単に再現できる頻繁に使用される重要でないデータの場合
既存のオブジェクトのストレージクラスを変更する場合は、オブジェクトを再作成する必要があります。
たとえば、third_objectを再アップロードし、そのストレージクラスをStandard_IAに設定します。
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256',
'StorageClass': 'STANDARD_IA'})Note:オブジェクトに変更を加えると、ローカルインスタンスにそれらが表示されない場合があります。 その時点で行う必要があるのは、.reload()を呼び出して、オブジェクトの最新バージョンをフェッチすることです。
オブジェクトをリロードすると、新しいストレージクラスが表示されます。
>>>
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'Note:LifeCycle Configurationsを使用して、必要に応じてオブジェクトをさまざまなクラスに移行します。 これらは自動的にこれらのオブジェクトを移行します。
バージョニング
時間の経過とともにオブジェクトの完全な記録を保持するには、バージョニングを使用する必要があります。 また、オブジェクトの偶発的な削除に対する保護メカニズムとしても機能します。 バージョン付きオブジェクトをリクエストすると、Boto3は最新バージョンを取得します。
オブジェクトの新しいバージョンを追加すると、オブジェクトが合計で使用するストレージは、バージョンのサイズの合計になります。 そのため、1 GBのオブジェクトを保存していて、10個のバージョンを作成する場合、10 GBのストレージの料金を支払う必要があります。
最初のバケットのバージョン管理を有効にします。 これを行うには、BucketVersioningクラスを使用する必要があります。
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)>>>
>>> enable_bucket_versioning(first_bucket_name)
Enabled次に、最初のファイルObjectに2つの新しいバージョンを作成します。1つは元のファイルの内容で、もう1つは3番目のファイルの内容です。
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
first_file_name)
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
third_file_name)次に、2番目のファイルを再アップロードして、新しいバージョンを作成します。
s3_resource.Object(first_bucket_name, second_file_name).upload_file(
second_file_name)次のように、オブジェクトの利用可能な最新バージョンを取得できます。
>>>
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'このセクションでは、最も重要なS3属性のいくつかを操作してオブジェクトに追加する方法を説明しました。 次に、バケットとオブジェクトを簡単に移動する方法を確認します。
トラバーサル
すべてのS3リソースから情報を取得したり、すべてのS3リソースに操作を適用したりする必要がある場合、Boto3はバケットとオブジェクトを反復的にトラバースするいくつかの方法を提供します。 作成したすべてのバケットをトラバースすることから始めます。
バケットトラバーサル
アカウント内のすべてのバケットをトラバースするには、リソースのbuckets属性を.all()と一緒に使用できます。これにより、Bucketインスタンスの完全なリストが得られます。
>>>
>>> for bucket in s3_resource.buckets.all():
... print(bucket.name)
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644clientを使用してバケット情報を取得することもできますが、clientが返す辞書から情報を抽出する必要があるため、コードはより複雑です。
>>>
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644アカウントにあるバケットを反復処理する方法を見てきました。 次のセクションでは、バケットの1つを選択し、バケットに含まれるオブジェクトを繰り返し表示します。
オブジェクトトラバーサル
バケットからすべてのオブジェクトをリストする場合、次のコードはイテレータを生成します:
>>>
>>> for obj in first_bucket.objects.all():
... print(obj.key)
...
127367firstfile.txt
616abesecondfile.txt
fb937cthirdfile.txtobj変数はObjectSummaryです。 これは、Objectの軽量表現です。 要約バージョンは、Objectが持つすべての属性をサポートしているわけではありません。 それらにアクセスする必要がある場合は、Object()サブリソースを使用して、基になる格納されたキーへの新しい参照を作成します。 次に、不足している属性を抽出できます。
>>>
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}バケットとオブジェクトに対して操作を繰り返し実行できるようになりました。 ほぼ終わりです。 この段階でもう1つ知っておくべきことがあります。このチュートリアルで作成したすべてのリソースを削除する方法です。
バケットとオブジェクトの削除
作成したすべてのバケットとオブジェクトを削除するには、まずバケットにオブジェクトが含まれていないことを確認する必要があります。
空でないバケットを削除する
バケットを削除できるようにするには、最初にバケット内のすべてのオブジェクトを削除する必要があります。そうしないと、BucketNotEmpty例外が発生します。 バージョン管理されたバケットがある場合、すべてのオブジェクトとそのすべてのバージョンを削除する必要があります。
これを自動的に行うLifeCycleルールがニーズに適さない場合は、次の方法でオブジェクトをプログラムで削除できます。
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})上記のコードは、バケットでバージョン管理を有効にしているかどうかにかかわらず機能します。 そうでない場合、オブジェクトのバージョンはnullになります。 Bucketインスタンスで.delete_objects()を使用すると、1回のAPI呼び出しで最大1000の削除をバッチ処理できます。これは、各オブジェクトを個別に削除するよりも費用効果が高くなります。
最初のバケットに対して新しい関数を実行して、すべてのバージョン付きオブジェクトを削除します。
>>>
>>> delete_all_objects(first_bucket_name)
[{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]最終テストとして、ファイルを2番目のバケットにアップロードできます。 このバケットではバージョン管理が有効になっていないため、バージョンはnullになります。 同じ機能を適用して内容を削除します。
>>>
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]両方のバケットからすべてのオブジェクトを正常に削除しました。 これで、バケットを削除する準備ができました。
バケットを削除する
最後に、Bucketインスタンスで.delete()を使用して、最初のバケットを削除します。
s3_resource.Bucket(first_bucket_name).delete()必要に応じて、clientバージョンを使用して2番目のバケットを削除できます。
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)各バケットを削除する前に空にしたため、両方の操作が成功しました。
これで、S3およびBoto3で実行できる最も重要な操作のいくつかを実行できました。 ここまでおめでとうございます! おまけとして、Infrastructure as CodeでS3リソースを管理する利点のいくつかを見てみましょう。
PythonコードまたはInfrastructure as Code(IaC)?
これまで見てきたように、このチュートリアルでS3とやり取りしたほとんどの操作はオブジェクトに関係していました。 バケットにポリシーを追加する、ストレージクラスを介してオブジェクトを移行するライフサイクルルールを追加する、Glacierにアーカイブする、またはそれらを完全に削除する、バケットを構成することによりすべてのオブジェクトを暗号化するなど、バケット関連の操作はあまり見られませんでした暗号化。
Boto3のクライアントまたはリソースを介してバケットの状態を手動で管理することは、アプリケーションが他のサービスの追加を開始し、より複雑になるにつれてますます困難になります。 Boto3と連携してインフラストラクチャを監視するには、CloudFormationやTerraformなどのコードとしてのインフラストラクチャ(IaC)ツールを使用してアプリケーションのインフラストラクチャを管理することを検討してください。 これらのツールのいずれかは、インフラストラクチャの状態を維持し、適用した変更を通知します。
このルートを下る場合は、次のことに注意してください。
-
何らかの方法でバケットを変更するすべてのバケット関連操作は、IaCを介して実行する必要があります。
-
すべてのオブジェクトを同じ方法(すべて暗号化、またはすべてパブリックなど)で動作させたい場合、通常、バケットポリシーまたは特定のバケットプロパティを追加することにより、IaCを使用してこれを直接行う方法があります。
-
バケットのコンテンツを反復処理するなど、バケットの読み取り操作は、Boto3を使用して実行する必要があります。
-
個々のオブジェクトレベルでのオブジェクト関連の操作は、Boto3を使用して実行する必要があります。
結論
このチュートリアルの最後までおめでとうございます!
S3を使用してプログラムで作業を開始する準備が整いました。 これで、オブジェクトの作成、S3へのアップロード、コンテンツのダウンロード、およびスクリプトからの属性の直接変更を行う方法を理解し、Boto3での一般的な落とし穴を回避できます。
このチュートリアルが、AWSを使用してすばらしいものを構築するための旅の足掛かりになることを願っています!
参考文献
詳細を知りたい場合は、次を確認してください。