PySparkとビッグデータ処理の最初のステップ
1台のマシンで処理するにはデータの量が大きすぎるという状況に直面することが一般的になりつつあります。 幸いなことに、Apache Spark、Hadoopなどの技術は、この正確な問題を解決するために開発されました。 これらのシステムのパワーは、PySparkを使用してPythonから直接利用できます!
ギガバイト以上のデータセットを効率的に処理するのは、データサイエンティスト、Web開発者、またはその中間のいずれであっても、well within the reach of any Python developerです。
このチュートリアルでは、次のことを学びます。
-
Pythonの概念をビッグデータに適用できるもの
-
Apache SparkとPySparkの使用方法
-
基本的なPySparkプログラムの書き方
-
小さなデータセットでローカルにPySparkプログラムを実行する方法
-
PySparkのスキルを分散システムに取り入れるための次のステップ
Free Bonus:Click here to get access to a chapter from Python Tricks: The Bookは、Pythonのベストプラクティスと、より美しい+ Pythonicコードをすぐに適用できる簡単な例を示しています。
Pythonのビッグデータの概念
just、scripting languageとして人気があるにもかかわらず、Pythonはarray-oriented programming、object-oriented programming、asynchronous programmingなどのいくつかのprogramming paradigmsを公開しています。 意欲的なビッグデータの専門家にとって特に興味深いパラダイムの1つは、functional programmingです。
関数型プログラミングは、ビッグデータを扱う際の一般的なパラダイムです。 機能的な方法で書くと、embarrassingly parallelコードになります。 つまり、コードを取得して複数のCPUまたはまったく異なるマシンで実行する方が簡単です。 一度に複数のシステムで実行することにより、単一のワークステーションの物理メモリとCPUの制限を回避できます。
これはPySparkエコシステムの力であり、機能的なコードを取得して、コンピューターのクラスター全体に自動的に配布できます。
Pythonプログラマにとって幸いなことに、関数型プログラミングのコアアイデアの多くは、Pythonの標準ライブラリとビルトインで利用できます。 Pythonの快適さを離れることなく、ビッグデータ処理に必要な多くの概念を学ぶことができます。
関数型プログラミングの核となる考え方は、外部状態を維持せずに関数によってデータを操作する必要があるということです。 これは、コードがグローバル変数を回避し、データをインプレースで操作する代わりに常にnew dataを返すことを意味します。
関数型プログラミングのもう1つの一般的な考え方は、anonymous functionsです。 Pythonは、AWS Lambda functionsと混同しないように、lambdaキーワードを使用して無名関数を公開します。
用語と概念のいくつかを知ったので、これらのアイデアがPythonエコシステムでどのように現れるかを探ることができます。
ラムダ関数
Pythonのlambda functionsはインラインで定義され、単一の式に制限されています。 組み込みのsorted()関数を使用すると、lambda関数を見たことがあるでしょう。
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(sorted(x))
['Python', 'awesome!', 'is', 'programming']
>>> print(sorted(x, key=lambda arg: arg.lower()))
['awesome!', 'is', 'programming', 'Python']sortedへのkeyパラメーターは、iterable内のアイテムごとに呼び出されます。 これにより、すべての文字列を小文字のbeforeに変更することで、並べ替えで大文字と小文字が区別されなくなります。
これは、lambda関数、つまり外部状態を維持しない小さな無名関数の一般的な使用例です。
filter()、map()、reduce()など、他の一般的な関数型プログラミング関数もPythonに存在します。 これらの関数はすべて、同様の方法でlambda関数またはdefで定義された標準関数を利用できます。
filter()、map()、およびreduce()
組み込みのfilter()、map()、およびreduce()関数はすべて、関数型プログラミングでは一般的です。 これらの概念がPySparkプログラムの機能のかなりの部分を占めることがすぐにわかるでしょう。
コアPythonコンテキストでこれらの関数を理解することが重要です。 その後、その知識をPySparkプログラムとSpark APIに翻訳できるようになります。
filter()は、条件に基づいて反復可能アイテムからアイテムをフィルター処理します。通常、lambda関数として表されます。
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(filter(lambda arg: len(arg) < 8, x)))
['Python', 'is']filter()は反復可能を取り、各アイテムでlambda関数を呼び出し、lambdaがTrueを返したアイテムを返します。
Note:filter()も反復可能であるため、list()を呼び出す必要があります。 filter()は、ループするときにのみ値を提供します。 list()は、ループを使用する代わりに、すべてのアイテムを一度にメモリに強制します。
次のように、filter()を使用して一般的なforループパターンを置き換えることを想像できます。
def is_less_than_8_characters(item):
return len(item) < 8
x = ['Python', 'programming', 'is', 'awesome!']
results = []
for item in x:
if is_less_than_8_characters(item):
results.append(item)
print(results)このコードは、8文字未満のすべての文字列を収集します。 コードはfilter()の例よりも冗長ですが、同じ機能を実行して同じ結果をもたらします。
filter()のもう1つのあまり明白でない利点は、反復可能を返すことです。 つまり、filter()では、反復可能オブジェクト内のすべてのアイテムを一度に保持するのに十分なメモリがコンピュータにある必要はありません。 これは、数ギガバイトのサイズに急速に成長する可能性のあるビッグデータセットでますます重要になっています。
map()は、反復可能オブジェクトの各アイテムに関数を適用するという点でfilter()に似ていますが、常に元のアイテムの1対1のマッピングを生成します。 map()が返すnew反復可能オブジェクトは、元の反復可能オブジェクトと常に同じ数の要素を持ちます。これは、filter()の場合とは異なります。
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(map(lambda arg: arg.upper(), x)))
['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']map()は、すべてのアイテムでlambda関数を自動的に呼び出し、次のようにforループを効果的に置き換えます。
results = []
x = ['Python', 'programming', 'is', 'awesome!']
for item in x:
results.append(item.upper())
print(results)forループは、すべての項目を大文字の形式で収集するmap()の例と同じ結果になります。 ただし、filter()の例と同様に、map()は反復可能オブジェクトを返します。これにより、大きすぎてメモリに完全に収まらない大きなデータセットを処理できるようになります。
最後に、Python標準ライブラリの最後の機能トリオはreduce()です。 filter()およびmap()と同様に、 `reduce()`は反復可能要素の要素に関数を適用します。
この場合も、適用される関数は、defキーワードまたはlambda関数で作成された標準のPython関数にすることができます。
ただし、reduce()は新しい反復可能オブジェクトを返しません。 代わりに、reduce()は呼び出された関数を使用して、反復可能オブジェクトを単一の値に減らします。
>>>
>>> from functools import reduce
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(reduce(lambda val1, val2: val1 + val2, x))
Pythonprogrammingisawesome!このコードは、反復可能オブジェクト内のすべてのアイテムを左から右に結合して単一のアイテムにします。 reduce()はすでに単一のアイテムを返すため、ここではlist()の呼び出しはありません。
Note: Python 3.xは、組み込みのreduce()関数をfunctoolsパッケージに移動しました。
lambda、map()、filter()、およびreduce()は、多くの言語に存在し、通常のPythonプログラムで使用できる概念です。 まもなく、これらの概念がPySpark APIに拡張され、大量のデータを処理できるようになるでしょう。
Sets
Setsは、標準のPythonに存在するもう1つの一般的な機能であり、ビッグデータ処理で広く役立ちます。 セットはリストに非常に似ていますが、順序がなく、重複する値を含めることができない点が異なります。 セットは、Python dictのキーに似ていると考えることができます。
PySparkのHello World
他の優れたプログラミングチュートリアルと同様に、Hello Worldの例から始めたいと思うでしょう。 以下はPySparkに相当するものです。
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())まだすべての詳細について心配する必要はありません。 主なアイデアは、PySparkプログラムが通常のPythonプログラムとそれほど変わらないことを念頭に置くことです。
Note: PySparkがまだインストールされていない場合、または指定されたcopyrightファイルがない場合、このプログラムはシステム上でExceptionを発生させる可能性があります。これを行う方法を説明します。後で。
このプログラムの詳細はすぐに学習しますが、よく見てください。 プログラムは、copyrightという名前のファイル内の行の総数と単語pythonを含む行の数をカウントします。
a PySpark program isn’t that much different from a regular Python programを覚えておいてください。ただし、特にクラスターで実行している場合は、通常のPythonプログラムからのexecution model can be very differentを使用してください。
クラスター上にいる場合、複数のノードに処理を分散させる背後で多くのことが発生する可能性があります。 ただし、現時点では、プログラムをPySparkライブラリを使用するPythonプログラムと考えてください。
PythonとシンプルなPySparkプログラムに存在するいくつかの一般的な機能概念を見てきたので、今度はSparkとPySparkについてさらに詳しく見ていきましょう。
Sparkとは
Apache Sparkは複数のコンポーネントで構成されているため、説明が難しい場合があります。 本質的に、Sparkは大量のデータを処理するための汎用engineです。
SparkはScalaで記述され、JVMで実行されます。 Sparkには、ストリーミングデータの処理、機械学習、グラフ処理、さらにSQLを介したデータとのやり取りのためのコンポーネントが組み込まれています。
このガイドでは、ビッグデータを処理するためのコアSparkコンポーネントについてのみ学習します。 ただし、機械学習やSQLなどの他のすべてのコンポーネントはすべて、PySparkを介してPythonプロジェクトでも使用できます。
PySparkとは何ですか?
Sparkは、JVM上で実行される言語であるScalaに実装されていますが、Pythonを介してすべての機能にアクセスするにはどうすればよいですか?
PySparkが答えです。
PySparkの現在のバージョンは2.4.3であり、Python 2.7、3.3以上で動作します。
PySparkは、Scala APIの上にあるPythonベースのラッパーと考えることができます。 これは、参照する2つのドキュメントセットがあることを意味します。
PySpark APIドキュメントには例がありますが、多くの場合、Scalaのドキュメントを参照して、コードをPySparkプログラムのPython構文に変換する必要があります。 幸いなことに、Scalaは非常に読みやすい関数ベースのプログラミング言語です。
PySparkは、Py4J libraryを介してSparkScalaベースのAPIと通信します。 Py4JはPySparkやSparkに固有のものではありません。 Py4Jでは、あらゆるPythonプログラムがJVMベースのコードと通信できます。
PySparkが機能的パラダイムに基づいている理由は2つあります。
-
Sparkのネイティブ言語であるScalaは、機能ベースです。
-
機能的なコードは並列化がはるかに簡単です。
PySparkを考えるもう1つの方法は、単一のマシンまたはマシンのクラスターで大量のデータを処理できるライブラリです。
Pythonのコンテキストでは、PySparkには、threadingまたはmultiprocessingモジュールを必要とせずに並列処理を処理する方法があると考えてください。 スレッド、プロセス、さらにはさまざまなCPU間の複雑な通信と同期はすべて、Sparkによって処理されます。
PySpark APIとデータ構造
PySparkと対話するには、Resilient Distributed Datasets(RDD)と呼ばれる特殊なデータ構造を作成します。
RDDは、クラスターで実行している場合、スケジューラーによってデータを複数のノードに自動的に変換および分散する複雑さをすべて隠します。
PySparkのAPIとデータ構造をよりよく理解するために、前述のHello Worldプログラムを思い出してください。
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())PySparkプログラムのエントリポイントは、SparkContextオブジェクトです。 このオブジェクトを使用すると、Sparkクラスターに接続してRDDを作成できます。 local[*]文字列は、localクラスターを使用していることを示す特別な文字列です。これは、シングルマシンモードで実行していることを示す別の方法です。 *は、マシン上に論理コアと同じ数のワーカースレッドを作成するようにSparkに指示します。
クラスターを使用している場合、SparkContextの作成はより複雑になる可能性があります。 Sparkクラスターに接続するには、認証とクラスターに固有の他のいくつかの情報を処理する必要がある場合があります。 これらの詳細は、次のように設定できます。
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)SparkContextを取得したら、RDDの作成を開始できます。
RDDはさまざまな方法で作成できますが、一般的な方法の1つは、PySparkparallelize()関数です。 parallelize()は、リストやタプルなどの一部のPythonデータ構造をRDDに変換できます。これにより、フォールトトレラントで分散型の機能が提供されます。
RDDをよりよく理解するために、別の例を検討してください。 次のコードは、10,000要素のイテレーターを作成し、parallelize()を使用してそのデータを2つのパーティションに分散します。
>>>
>>> big_list = range(10000)
>>> rdd = sc.parallelize(big_list, 2)
>>> odds = rdd.filter(lambda x: x % 2 != 0)
>>> odds.take(5)
[1, 3, 5, 7, 9]parallelize()は、そのイテレータをdistributedの数値のセットに変換し、Sparkのインフラストラクチャのすべての機能を提供します。
このコードは、前に見たPythonの組み込みfilter()の代わりに、RDDのfilter()メソッドを使用していることに注意してください。 結果は同じですが、舞台裏で起こっていることは大幅に異なります。 RDDfilter()メソッドを使用することにより、その操作は複数のCPUまたはコンピューターに分散して実行されます。
繰り返しますが、これを、Sparkがmultiprocessingを実行し、すべてRDDデータ構造にカプセル化されていると想像してください。
take()は、RDDの内容を確認する方法ですが、小さなサブセットにすぎません。 take()は、データのサブセットを分散システムから単一のマシンにプルします。
take()は、単一のマシンでデータセット全体を検査できない場合があるため、デバッグにとって重要です。 RDDはビッグデータでの使用に最適化されているため、現実のシナリオでは、単一のマシンにデータセット全体を保持するのに十分なRAMがない場合があります。
Note: Sparkは、シェルでこのような例を実行すると、一時的に情報をstdoutに出力します。これについては、すぐに説明します。 stdoutは、一時的に[Stage 0:> (0 + 1) / 1]のようなものを表示する場合があります。
stdoutテキストは、SparkがRDDを分割し、データをさまざまなCPUとマシン間で複数のステージに処理する方法を示しています。
RDDを作成する別の方法は、前の例で見たtextFile()を含むファイルを読み込むことです。 RDDはPySparkを使用するための基本的なデータ構造の1つであるため、APIの多くの関数はRDDを返します。
RDDと他のデータ構造の重要な違いの1つは、結果が要求されるまで処理が遅延することです。 これはPython generatorに似ています。 Pythonエコシステムの開発者は通常、この動作を説明するためにlazy evaluationという用語を使用します。
処理を行わずに、同じRDDに複数の変換を積み重ねることができます。 Sparkは変換のdirected acyclic graphを維持するため、この機能が可能です。 基になるグラフは、最終結果が要求されたときにのみアクティブになります。 前の例では、take()を呼び出して結果を要求するまで、計算は行われませんでした。
RDDから結果を要求する方法は複数あります。 RDDでcollect()を使用して、評価および収集する結果を単一のクラスターノードに明示的に要求できます。 また、さまざまな方法で結果を暗黙的に要求することもできます。その1つは、前に見たようにcount()を使用していました。
Note:これらのメソッドを使用するときは、データセット全体をメモリにプルするので注意してください。データセットが大きすぎて単一のマシンのRAMに収まらない場合は機能しません。
繰り返しになりますが、考えられるすべての機能の詳細については、PySpark API documentationを参照してください。
PySparkのインストール
通常、Hadoop clusterでPySparkプログラムを実行しますが、他のクラスター展開オプションもサポートされています。 詳細については、Spark’s cluster mode overviewを参照してください。
Note:これらのクラスターの1つをセットアップするのは難しい場合があり、このガイドの範囲外です。 理想的には、チームにはそれを機能させるのに役立つウィザードDevOpsのエンジニアがいます。 そうでない場合、Hadoopはa guideを公開して支援します。
このガイドでは、ローカルマシンでPySparkプログラムを実行するいくつかの方法を紹介します。 これはテストや学習に役立ちますが、すぐに新しいプログラムを取得してクラスターで実行し、ビッグデータを真に処理したいと思うでしょう。
必要な依存関係がすべてあるため、PySpark自体をセットアップするのも難しい場合があります。
PySparkはJVMの上で実行され、機能するために多くの基盤となるJavaインフラストラクチャが必要です。 そうは言っても、私たちはDockerの時代に生きているので、PySparkの実験がはるかに簡単になります。
さらに良いことに、Jupyterの背後にいる驚くべき開発者は、あなたのためにすべての面倒な作業を行ってくれました。 それらは、JupyterとともにすべてのPySpark依存関係を含むDockerfileを公開します。 したがって、Jupyterノートブックで直接実験できます。
Note:Jupyterノートブックには多くの機能があります。 ノートブックを効果的に使用する方法の詳細については、Jupyter Notebook: An Introductionを確認してください。
まず、Dockerをインストールする必要があります。 Dockerをまだセットアップしていない場合は、Docker in Action – Fitter, Happier, More Productiveを確認してください。
Note: Dockerイメージは非常に大きくなる可能性があるため、PySparkとJupyterを使用するために約5GBのディスクスペースを使用しても問題がないことを確認してください。
次に、次のコマンドを実行して、事前に構築されたPySparkシングルノードセットアップでDockerコンテナーをダウンロードし、自動的に起動できます。 このコマンドは、Spark、PySpark、およびJupyterのすべての要件とともに、DockerHubから直接画像をダウンロードするため、数分かかる場合があります。
$ docker run -p 8888:8888 jupyter/pyspark-notebookそのコマンドが出力の印刷を停止すると、シングルノード環境でPySparkプログラムをテストするために必要なすべてを備えた実行中のコンテナーができます。
コンテナを停止するには、「+ dockerrun」コマンドを入力したのと同じウィンドウで[.keys]#Ctrl [.kbd .key-c]#C ##と入力します。
いよいよいくつかのプログラムを実行します。
PySparkプログラムの実行
PySparkプログラムを実行するには、コマンドラインを使用するか、より視覚的なインターフェースを使用するかに応じて、いくつかの方法があります。 コマンドラインインターフェイスの場合は、spark-submitコマンド、標準のPythonシェル、または専用のPySparkシェルを使用できます。
最初に、Jupyterノートブックのより視覚的なインターフェースが表示されます。
Jupyterノートブック
Jupyterノートブックでプログラムを実行するには、次のコマンドを実行して、以前にダウンロードしたDockerコンテナーを開始します(まだ実行していない場合)。
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Executing the command: jupyter notebook
[I 08:04:22.869 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[I 08:04:25.022 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 08:04:25.022 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 08:04:25.027 NotebookApp] Serving notebooks from local directory: /home/jovyan
[I 08:04:25.028 NotebookApp] The Jupyter Notebook is running at:
[I 08:04:25.029 NotebookApp] http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
[I 08:04:25.029 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 08:04:25.037 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html
Or copy and paste one of these URLs:
http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437これで、PySparkで実行されているコンテナーができました。 docker runコマンド出力の最後にローカルURLが記載されていることに注意してください。
Note:トークン、コンテナID、およびコンテナ名はすべてランダムに生成されるため、dockerコマンドからの出力はマシンごとにわずかに異なります。
このURLを使用して、WebブラウザーでJupyterを実行しているDockerコンテナーに接続する必要があります。 URLfrom your outputをコピーしてWebブラウザに直接貼り付けます。 表示される可能性が高いURLの例を次に示します。
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437以下のコマンドのURLはマシンによって多少異なる可能性がありますが、ブラウザーでそのURLに接続すると、次のようなJupyterノートブック環境にアクセスできます。
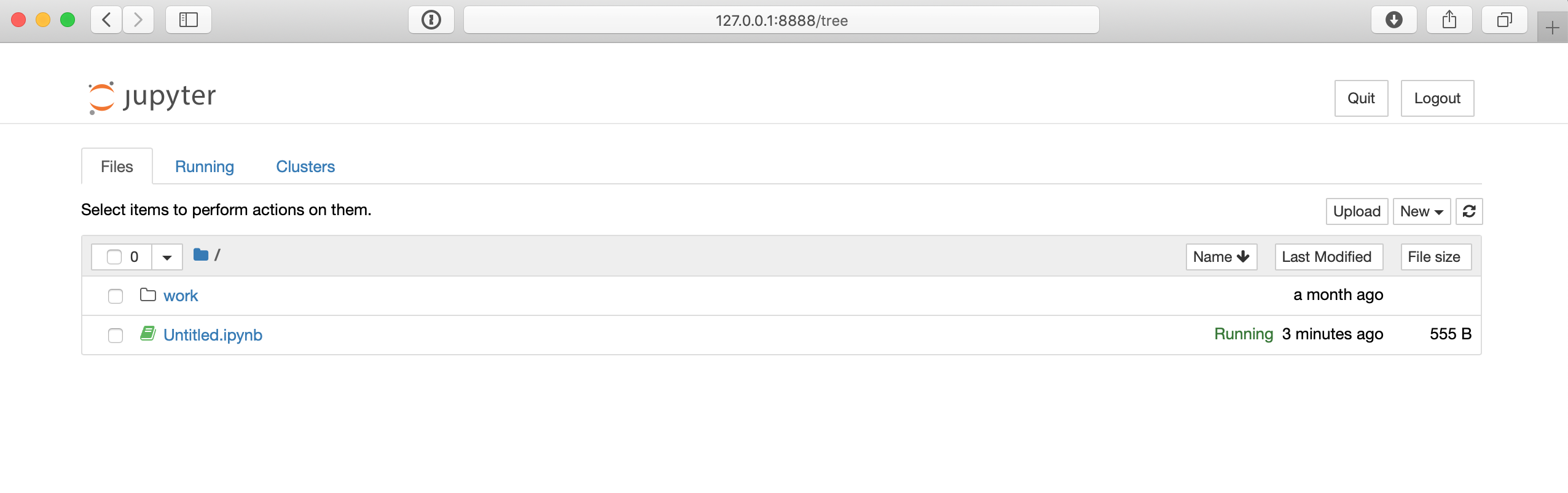
Jupyterノートブックページから、右端のNewボタンを使用して、新しいPython3シェルを作成できます。 次に、前のHello Worldの例のように、いくつかのコードをテストできます。
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Jupyterノートブックでそのコードを実行すると次のようになります。
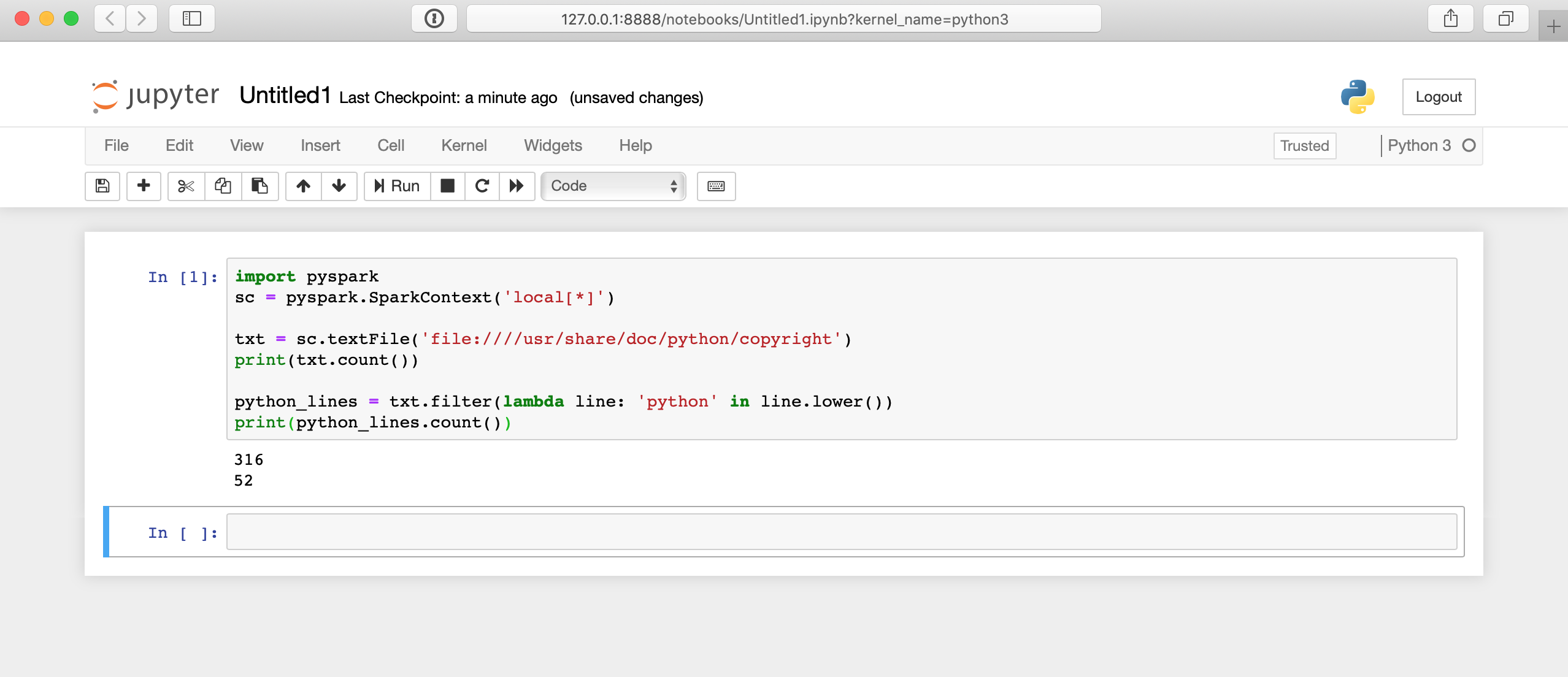
ここでは舞台裏で多くのことが行われているため、結果が表示されるまでに数秒かかる場合があります。 セルをクリックしてもすぐに答えは表示されません。
コマンドラインインターフェース
コマンドラインインターフェイスは、PySparkシェルやspark-submitコマンドなど、PySparkプログラムを送信するためのさまざまな方法を提供します。 これらのCLIアプローチを使用するには、まずPySparkがインストールされているシステムのCLIに接続する必要があります。
DockerセットアップのCLIに接続するには、以前のようにコンテナーを起動してから、そのコンテナーに接続する必要があります。 繰り返しますが、コンテナを起動するには、次のコマンドを実行できます。
$ docker run -p 8888:8888 jupyter/pyspark-notebookDockerコンテナーを実行したら、Jupyterノートブックの代わりにシェル経由で接続する必要があります。 これを行うには、次のコマンドを実行してコンテナ名を見つけます。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d5ab7a93902 jupyter/pyspark-notebook "tini -g -- start-no…" 12 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp kind_edisonこのコマンドは、実行中のすべてのコンテナーを表示します。 jupyter/pyspark-notebookイメージを実行しているコンテナのCONTAINER IDを見つけ、それを使用してコンテナのbashシェルinsideに接続します。
$ docker exec -it 4d5ab7a93902 bash
jovyan@4d5ab7a93902:~$これで、bashプロンプトinside of the containerに接続する必要があります。 シェルのプロンプトがjovyan@4d5ab7a93902に似たものに変更されるため、動作していることを確認できますが、コンテナーの一意のIDを使用します。
Note:4d5ab7a93902をマシンで使用されているCONTAINER IDに置き換えます。
クラスタ
Sparkと一緒にインストールされたspark-submitコマンドを使用して、コマンドラインを使用してPySparkコードをクラスターに送信できます。 このコマンドは、PySparkまたはScalaプログラムを受け取り、クラスターで実行します。 これはおそらく、実際のビッグデータ処理ジョブを実行する方法です。
Note:これらのコマンドへのパスは、Sparkがインストールされた場所によって異なり、参照されたDockerコンテナーを使用する場合にのみ機能する可能性があります。
実行中のDockerコンテナーでHello Worldの例(または任意のPySparkプログラム)を実行するには、最初に上記のようにシェルにアクセスします。 コンテナのシェル環境に入ると、nano text editorを使用してファイルを作成できます。
現在のフォルダにファイルを作成するには、作成するファイルの名前でnanoを起動するだけです。
$ nano hello_world.pyHello Worldの例の内容を入力し、Ctrl+[.kbd .key-x]#X#と入力して、保存プロンプトに従ってファイルを保存します。
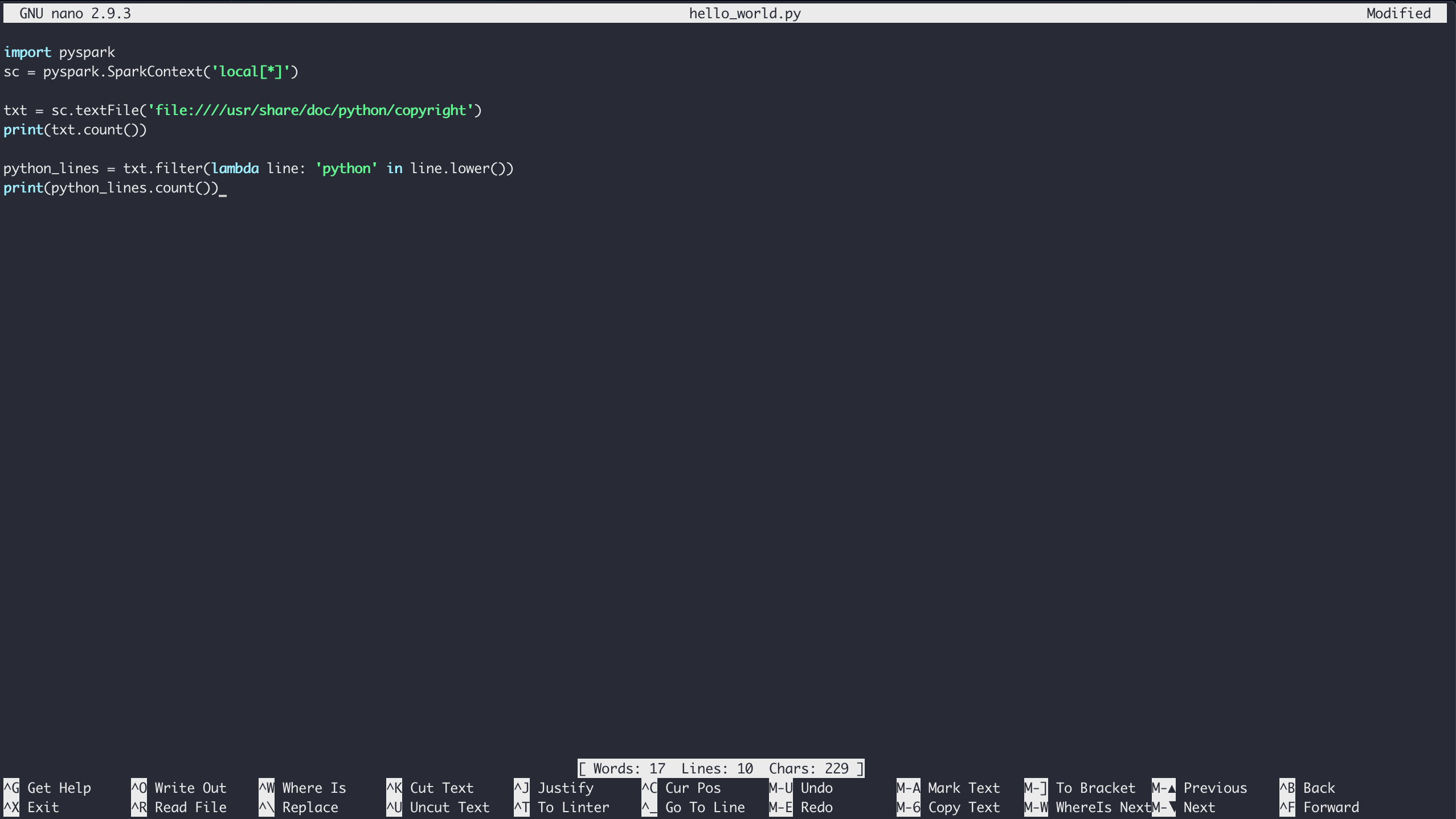
最後に、pyspark-submitコマンドを使用してSparkを介してコードを実行できます。
$ /usr/local/spark/bin/spark-submit hello_world.pyこのコマンドは、デフォルトでa lotの出力になるため、プログラムの出力を確認するのが難しい場合があります。 SparkContext変数のレベルを変更することにより、PySparkプログラム内でログの冗長性をある程度制御できます。 それには、次の行をスクリプトの上部近くに配置します。
sc.setLogLevel('WARN')これにより、spark-submitの出力のsomeが省略されるため、プログラムの出力をより明確に確認できます。 ただし、実際のシナリオでは、後でデバッグしやすくするために、出力をファイル、データベース、またはその他のストレージメカニズムに配置する必要があります。
幸いなことに、PySparkプログラムは引き続きPythonのすべての標準ライブラリにアクセスできるため、結果をファイルに保存することは問題ではありません。
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
python_lines = txt.filter(lambda line: 'python' in line.lower())
with open('results.txt', 'w') as file_obj:
file_obj.write(f'Number of lines: {txt.count()}\n')
file_obj.write(f'Number of lines with python: {python_lines.count()}\n')これで、後で簡単に参照できるように、結果がresults.txtという別のファイルに保存されます。
Note:上記のコードは、Python 3.6で導入されたf-stringsを使用しています。
PySparkシェル
プログラムを実行するPySpark固有のもう1つの方法は、PySpark自体で提供されるシェルを使用することです。 繰り返しますが、Dockerセットアップを使用して、上記のようにコンテナのCLIに接続できます。 次に、次のコマンドで特殊なPythonシェルを実行できます。
$ /usr/local/spark/bin/pyspark
Python 3.7.3 | packaged by conda-forge | (default, Mar 27 2019, 23:01:00)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 23:01:00)
SparkSession available as 'spark'.これで、DockerコンテナのPysparkシェル環境insideに移動し、Jupyterノートブックの例と同様のコードをテストできます。
>>>
>>> txt = sc.textFile('file:////usr/share/doc/python/copyright')
>>> print(txt.count())
316これで、通常のPythonシェルと同じようにPysparkシェルで作業できます。
Note: Pysparkシェルの例では、SparkContext変数を作成する必要はありませんでした。 PySparkシェルは、変数scを自動的に作成して、シングルノードモードでSparkエンジンに接続します。
spark-submitまたはJupyterノートブックを使用して実際のPySparkプログラムを送信する場合は、must create your ownSparkContextを使用します。
PySparkがPython環境にインストールされている限り、標準のPythonシェルを使用してプログラムを実行することもできます。 does notを使用しているDockerコンテナでは、標準のPython環境でPySparkが有効になっています。 そのため、DockerコンテナでPySparkを使用するには、前述のいずれかの方法を使用する必要があります。
PySparkと他のツールの組み合わせ
既に見たように、PySparkには、機械学習やSQLのような大規模なデータセットの操作などを行うための追加のライブラリが付属しています。 ただし、NumPyやPandasなどの他の一般的な科学ライブラリを使用することもできます。
これらを同じ環境on each cluster nodeにインストールする必要があります。そうすれば、プログラムは通常どおりにそれらを使用できます。 そうすれば、すでに知っているおなじみのidiomatic Pandasのトリックをすべて自由に使用できます。
Remember:Pandas DataFramesは熱心に評価されるため、すべてのデータがメモリon a single machineに収まる必要があります。
実際のビッグデータ処理の次のステップ
PySparkの基本を学んだらすぐに、シングルマシンモードを使用していると機能しない可能性が高い膨大な量のデータの分析を確実に開始する必要があります。 Sparkクラスターのインストールとメンテナンスは、このガイドの範囲外であり、それ自体がフルタイムの仕事である可能性があります。
そのため、オフィスのIT部門を訪問するか、ホストされているSparkクラスターソリューションを検討する時間になるかもしれません。 潜在的なホストソリューションの1つは、Databricksです。
Databricksを使用すると、Microsoft AzureまたはAWSでデータをホストでき、free 14-day trialでデータをホストできます。
動作中のSparkクラスターができたら、すべてのデータを分析のためにそのクラスターに取り込みます。 Sparkには、データをインポートする方法がいくつかあります。
Network File Systemから直接データを読み取ることもできます。これは、前の例の仕組みです。
Databricksのようなホスト型ソリューションを使用している場合でも、独自のマシンのクラスターを使用している場合でも、すべてのデータにアクセスする方法が不足することはありません。
結論
PySparkは、ビッグデータ処理への優れたエントリポイントです。
このチュートリアルでは、map()、filter()、basic Pythonなどの関数型プログラミングの概念に精通していれば、事前に多くの時間を費やす必要がないことを学びました。 )s。 実際、NumPyやPandasなどの使い慣れたツールを含め、PySparkプログラムで直接知っているすべてのPythonを使用できます。
次のことができるようになりました。
-
ビッグデータに適用されるUnderstandの組み込みPythonの概念
-
Writeの基本的なPySparkプログラム
-
ローカルマシンを使用した小さなデータセット上のRun PySparkプログラム
-
Sparkクラスターや別のカスタムホストソリューションなどのExploreのより高性能なビッグデータソリューション