前書き
DigitalOcean Managed Databasesでは、いくつかの方法を使用してPostgreSQLデータベースをスケーリングできます。 そのような方法の1つは、多数のクライアント接続を効率的に処理し、これらの開いている接続のCPUとメモリのフットプリントを削減できるビルトイン接続プーラーです。 接続プールを使用し、固定された一連のリサイクル可能な接続を共有することにより、同時クライアント接続を大幅に増やし、PostgreSQLデータベースのパフォーマンスをさらに高めることができます。
このチュートリアルでは、PostgreSQLの組み込みベンチマークツールであるpgbenchを使用して、DigitalOceanマネージドPostgreSQLデータベースで負荷テストを実行します。 接続プールに飛び込み、それらがどのように機能するかを説明し、Cloud Controlパネルを使用して接続プールを作成する方法を示します。 最後に、pgbenchテストの結果を使用して、接続プールを使用することがデータベーススループットを向上させる安価な方法になる方法を示します。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
DigitalOceanマネージPostgreSQLデータベースクラスター。 DigitalOcean PostgreSQLクラスターをプロビジョニングおよび構成する方法については、管理対象データベースproduct documentationを参照してください。
-
PostgreSQLがインストールされたクライアントマシン。 デフォルトでは、PostgreSQLインストールには
pgbenchベンチマークユーティリティとpsqlクライアントが含まれています。どちらもこのガイドで使用します。 PostgreSQLのインストール方法については、How To Install and Use PostgreSQL on Ubuntu 18.04を参照してください。 クライアントマシンでUbuntuを実行していない場合は、バージョンファインダーを使用して適切なチュートリアルを見つけることができます。
DigitalOcean PostgreSQLクラスターを稼働させ、pgbenchがインストールされたクライアントマシンを作成したら、このガイドを開始する準備が整います。
[[step-1 -—- creating-and-initializing-benchmark-database]] ==ステップ1 —benchmarkデータベースの作成と初期化
データベースの接続プールを作成する前に、まずPostgreSQLクラスター上にbenchmarkデータベースを作成し、pgbenchがテストを実行するダミーデータをデータベースに入力します。 pgbenchユーティリティは、複数のスレッドとクライアントを使用して、トランザクションで一連の5つのSQLコマンド(SELECT、UPDATE、およびINSERTクエリで構成される)を繰り返し実行し、計算します。 TransactionsperSecond(TPS)と呼ばれる便利なパフォーマンスメトリック。 TPSはデータベースのスループットの測定値であり、データベースによって1秒間に処理されたアトミックトランザクションの数をカウントします。 pgbenchによって実行される特定のコマンドの詳細については、公式のpgbenchドキュメントからWhat is the “Transaction” Actually Performed in pgbench?を参照してください。
まず、PostgreSQLクラスターに接続し、benchmarkデータベースを作成します。
まず、Databasesに移動し、PostgreSQLクラスターを見つけて、クラスターのConnection Detailsを取得します。 クラスターをクリックします。 次のConnection Detailsボックスを含むクラスターの概要ページが表示されます。

これから、次の構成変数を解析できます。
-
管理者ユーザー:
doadmin -
管理者パスワード:
your_password -
クラスターエンドポイント:
dbaas-test-do-user-3587522-0.db.ondigitalocean.com -
接続ポート:
25060 -
接続するデータベース:
defaultdb -
SSLモード:
require(セキュリティを強化するためにSSL暗号化接続を使用)
psqlクライアントとpgbenchツールの両方を使用するときに必要になるため、これらのパラメーターに注意してください。
このボックスの上にあるドロップダウンをクリックして、Connection Stringを選択します。 この文字列をコピーしてpsqlに渡し、このPostgreSQLノードに接続します。
psqlとコピーした接続文字列を使用してクラスターに接続します。
psql postgresql://doadmin:your_password@your_cluster_endpoint:25060/defaultdb?sslmode=require次のPostgreSQLクライアントプロンプトが表示され、PostgreSQLクラスターに正常に接続されたことを示します。
Outputpsql (10.6 (Ubuntu 10.6-0ubuntu0.18.04.1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
defaultdb=>ここから、benchmarkデータベースを作成します。
CREATE DATABASE benchmark;次のような出力が表示されるはずです。
OutputCREATE DATABASE次に、クラスターから切断します。
\qpgbenchテストを実行する前に、このbenchmarkデータベースに、テストの実行に必要ないくつかのテーブルとダミーデータを入力する必要があります。
これを行うには、次のフラグを指定してpgbenchを実行します。
-
-h:PostgreSQLクラスターエンドポイント -
-p:PostgreSQLクラスター接続ポート -
-U:データベースのユーザー名 -
-i:ベンチマークテーブルとそのダミーデータを使用してbenchmarkデータベースを初期化することを示します。 -
-s:スケール係数を150に設定します。これにより、テーブルサイズに150が乗算されます。 デフォルトのスケール係数1は、次のサイズのテーブルになります。table # of rows --------------------------------- pgbench_branches 1 pgbench_tellers 10 pgbench_accounts 100000 pgbench_history 0150の倍率を使用すると、
pgbench_accountsテーブルには15,000,000行が含まれます。[.note]#Note:過度にブロックされたトランザクションを回避するために、スケール係数を、少なくともテストする同時クライアントの数と同じ大きさの値に設定してください。 このチュートリアルでは、最大150のクライアントでテストするため、ここでは
-sを150に設定します。 詳細については、公式のpgbenchドキュメントからこれらのrecommended practicesを参照してください。
#
完全なpgbenchコマンドを実行します。
pgbench -h your_cluster_endpoint -p 25060 -U doadmin -i -s 150 benchmarkこのコマンドを実行すると、指定したデータベースユーザーのパスワードを入力するよう求められます。 パスワードを入力し、ENTERを押します。
次のような出力が表示されるはずです。
Outputdropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 15000000 tuples (0%) done (elapsed 0.19 s, remaining 27.93 s)
200000 of 15000000 tuples (1%) done (elapsed 0.85 s, remaining 62.62 s)
300000 of 15000000 tuples (2%) done (elapsed 1.21 s, remaining 59.23 s)
400000 of 15000000 tuples (2%) done (elapsed 1.63 s, remaining 59.44 s)
500000 of 15000000 tuples (3%) done (elapsed 2.05 s, remaining 59.51 s)
. . .
14700000 of 15000000 tuples (98%) done (elapsed 70.87 s, remaining 1.45 s)
14800000 of 15000000 tuples (98%) done (elapsed 71.39 s, remaining 0.96 s)
14900000 of 15000000 tuples (99%) done (elapsed 71.91 s, remaining 0.48 s)
15000000 of 15000000 tuples (100%) done (elapsed 72.42 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done.この時点で、pgbenchテストの実行に必要なテーブルとデータが入力されたベンチマークデータベースを作成しました。 接続プーリングを有効にする前後のパフォーマンスを比較するために使用するベースラインテストの実行に進むことができます。
[[step-2 -—- running-a-baseline-pgbench-test]] ==ステップ2—ベースラインpgbenchテストの実行
最初のベンチマークを実行する前に、接続プールで最適化しようとしているものに飛び込む価値があります。
通常、クライアントがPostgreSQLデータベースに接続すると、メインのPostgreSQL OSプロセスは、この新しい接続に対応する子プロセスに分岐します。 少数の接続しかない場合、これにより問題が発生することはほとんどありません。 ただし、クライアントと接続の規模が拡大すると、特に問題のアプリケーションがデータベース接続を効率的に使用していない場合、これらの接続の作成と保守のCPUとメモリのオーバーヘッドが増加し始めます。 さらに、max_connections PostgreSQL設定により、許可されるクライアント接続の数が制限され、追加の接続が拒否またはドロップされる場合があります。

接続プールは、固定数のデータベース接続pool sizeを開いたままにし、それを使用してクライアント要求を配布および実行します。 つまり、はるかに多くの同時接続に対応し、アイドル状態のクライアントまたは停滞しているクライアントを効率的に処理し、トラフィックの急増時にクライアント要求を拒否するのではなくキューに入れることができます。 接続をリサイクルすることにより、接続ボリュームが重い環境でマシンのリソースをより効率的に使用し、データベースから余分なパフォーマンスを引き出すことができます。
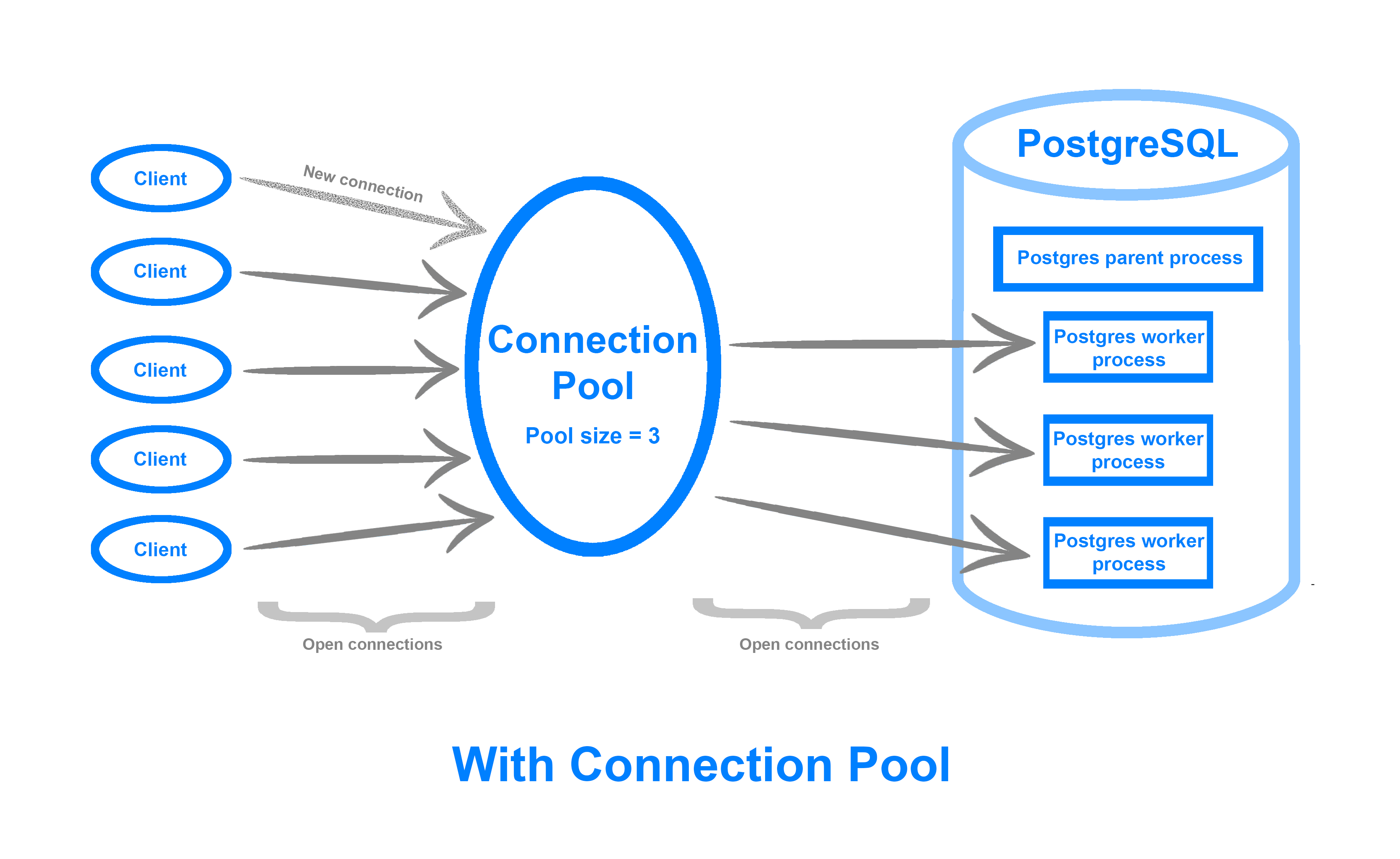
接続プールは、アプリケーション側で、またはデータベースとアプリケーション間のミドルウェアとして実装できます。 Managed Databases接続プールは、PostgreSQL用の軽量のオープンソースミドルウェア接続プールであるpgBouncerの上に構築されています。 そのインターフェイスは、クラウドコントロールパネルUIを介して利用できます。
コントロールパネルのDatabasesに移動し、PostgreSQLクラスターをクリックします。 ここから、Connection Poolsをクリックします。 次に、Create a Connection Poolをクリックします。 次の構成ウィンドウが表示されます。

ここでは、次のフィールドを構成できます。
-
Pool Name:接続プールの一意の名前
-
Database:接続をプールするデータベース
-
User:接続プールが認証するPostgreSQLユーザー
-
Mode:Session、Transaction、またはStatementのいずれか。 このオプションは、プールがクライアントにバックエンド接続を割り当てる時間を制御します。
-
Session:クライアントは、明示的に切断されるまで接続を保持します。
-
Transaction:クライアントは、トランザクションが完了するまで接続を取得します。その後、接続はプールに戻されます。
-
Statement:プールは、各クライアントステートメントの後に接続を積極的にリサイクルします。 ステートメントモードでは、複数ステートメントのトランザクションは許可されません。 詳細については、接続プールproduct documentationを参照してください。
-
-
Pool Size:接続プールがそれ自体とデータベースの間で開いたままにする接続の数。
接続プールを作成する前に、データベースのパフォーマンスと接続プールを比較できるベースラインテストを実行します。
このチュートリアルでは、4 GB RAM、2 vCPU、80 GBディスク、プライマリノードのみの管理されたデータベースのセットアップを使用します。 PostgreSQLクラスターの仕様に従って、このセクションのベンチマークテストパラメーターをスケーリングできます。
DigitalOceanマネージドデータベースクラスターには、PostgreSQLのmax_connectionsパラメーターが1 GBRAMあたり25接続にプリセットされています。 したがって、4 GB RAM PostgreSQLノードではmax_connectionsが100に設定されています。 さらに、すべてのクラスターで、3つの接続がメンテナンス用に予約されています。 したがって、この4 GB RAMのPostgreSQLクラスターでは、97の接続が接続プーリングに使用できます。
これを念頭に置いて、最初のベースラインpgbenchテストを実行してみましょう。
クライアントマシンにログインします。 pgbenchを実行し、通常どおりデータベースエンドポイント、ポート、ユーザーを指定します。 さらに、次のフラグを提供します。
-
-c:シミュレートする同時クライアントまたはデータベースセッションの数。 PostgreSQLクラスターのmax_connectionsパラメーターよりも小さい同時接続の数をシミュレートするために、これを50に設定します。 -
-j:ベンチマークの実行にpgbenchが使用するワーカースレッドの数。 マルチCPUマシンを使用している場合、これを上方に調整して、クライアントをスレッドに分散できます。 2コアマシンでは、これを2に設定します。 -
-P:60秒ごとに進行状況とメトリックを表示します。 -
-T:ベンチマークを600秒(10分)実行します。 一貫性のある再現可能な結果を生成するには、ベンチマークを数分間、または1つのチェックポイントサイクルで実行することが重要です。
また、以前に作成して入力したbenchmarkデータベースに対してベンチマークを実行することも指定します。
次の完全なpgbenchコマンドを実行します。
pgbench -h your_db_endpoint -p 25060 -U doadmin -c 50 -j 2 -P 60 -T 600 benchmarkENTERを押してから、doadminユーザーのパスワードを入力してテストの実行を開始します。 次のような出力が表示されます(結果はPostgreSQLクラスターの仕様によって異なります)。
Outputstarting vacuum...end.
progress: 60.0 s, 157.4 tps, lat 282.988 ms stddev 40.261
progress: 120.0 s, 176.2 tps, lat 283.726 ms stddev 38.722
progress: 180.0 s, 167.4 tps, lat 298.663 ms stddev 238.124
progress: 240.0 s, 178.9 tps, lat 279.564 ms stddev 43.619
progress: 300.0 s, 178.5 tps, lat 280.016 ms stddev 43.235
progress: 360.0 s, 178.8 tps, lat 279.737 ms stddev 43.307
progress: 420.0 s, 179.3 tps, lat 278.837 ms stddev 43.783
progress: 480.0 s, 178.5 tps, lat 280.203 ms stddev 43.921
progress: 540.0 s, 180.0 tps, lat 277.816 ms stddev 43.742
progress: 600.0 s, 178.5 tps, lat 280.044 ms stddev 43.705
transaction type:
scaling factor: 150
query mode: simple
number of clients: 50
number of threads: 2
duration: 600 s
number of transactions actually processed: 105256
latency average = 282.039 ms
latency stddev = 84.244 ms
tps = 175.329321 (including connections establishing)
tps = 175.404174 (excluding connections establishing) ここでは、50の同時セッションで10分間実行すると、105,256のトランザクションを1秒あたり約175のトランザクションのスループットで処理しました。
次に、同じテストを実行してみましょう。今回は、このデータベースのmax_connectionsよりも高い値である150の同時クライアントを使用して、クライアント接続の大量流入を総合的にシミュレートします。
pgbench -h your_db_endpoint -p 25060 -U doadmin -c 150 -j 2 -P 60 -T 600 benchmark次のような出力が表示されます。
Outputstarting vacuum...end.
connection to database "pgbench" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connections
progress: 60.0 s, 182.6 tps, lat 280.069 ms stddev 42.009
progress: 120.0 s, 253.8 tps, lat 295.612 ms stddev 237.448
progress: 180.0 s, 271.3 tps, lat 276.411 ms stddev 40.643
progress: 240.0 s, 273.0 tps, lat 274.653 ms stddev 40.942
progress: 300.0 s, 272.8 tps, lat 274.977 ms stddev 41.660
progress: 360.0 s, 250.0 tps, lat 300.033 ms stddev 282.712
progress: 420.0 s, 272.1 tps, lat 275.614 ms stddev 42.901
progress: 480.0 s, 261.1 tps, lat 287.226 ms stddev 112.499
progress: 540.0 s, 272.5 tps, lat 275.309 ms stddev 41.740
progress: 600.0 s, 271.2 tps, lat 276.585 ms stddev 41.221
transaction type:
scaling factor: 150
query mode: simple
number of clients: 150
number of threads: 2
duration: 600 s
number of transactions actually processed: 154892
latency average = 281.421 ms
latency stddev = 125.929 ms
tps = 257.994941 (including connections establishing)
tps = 258.049251 (excluding connections establishing) FATALエラーに注意してください。これは、pgbenchがmax_connectionsによって設定された100接続制限しきい値に達し、接続が拒否されたことを示します。 テストは約257のTPSでまだ完了できました。
この時点で、接続プールがデータベースのスループットを向上させる可能性がある方法を調査できます。
[[step-3 -—- creating-and-testing-a-connection-pool]] ==ステップ3—接続プールの作成とテスト
このステップでは、接続プールを作成し、前のpgbenchテストを再実行して、データベースのスループットを改善できるかどうかを確認します。
一般に、max_connections設定と接続プールパラメータは、データベースの負荷を最大化するために連携して調整されます。 ただし、max_connectionsはDigitalOceanマネージドデータベースでユーザーから抽象化されているため、ここでの主な手段は接続プールModeとSizeの設定です。
まず、使用可能なすべてのバックエンド接続を開いたままにするTransactionモードの接続プールを作成しましょう。
コントロールパネルのDatabasesに移動し、PostgreSQLクラスターをクリックします。 ここから、Connection Poolsをクリックします。 次に、Create a Connection Poolをクリックします。
表示される構成ウィンドウで、次の値を入力します。

ここでは、接続プールにtest-poolという名前を付け、benchmarkデータベースで使用します。 データベースユーザーはdoadminであり、接続プールをTransactionモードに設定します。 4GBのRAMを備えたマネージドデータベースクラスターには、97の使用可能なデータベース接続があることを思い出してください。 したがって、97個のデータベース接続が開いたままになるようにプールを構成します。
完了したら、Create Poolを押します。
コントロールパネルにこのプールが表示されます。

Connection DetailsをクリックしてURIを取得します。 次のようになります。
postgres://doadmin:password@pool_endpoint:pool_port/test-pool?sslmode=requireここでは、プール名test-poolに対応して、ポートが異なり、エンドポイントとデータベース名が異なる可能性があることに注意してください。
test-pool接続プールを作成したので、上記で実行したpgbenchテストを再実行できます。
pgbenchを再実行します
クライアントマシンから、次のpgbenchコマンドを実行し(150の同時クライアントで)、強調表示された値を接続プールURIの値に置き換えてください。
pgbench -h pool_endpoint -p pool_port -U doadmin -c 150 -j 2 -P 60 -T 600 test-poolここでも、150の同時クライアントを使用し、2つのスレッドでテストを実行し、60秒ごとに進行状況を出力し、600秒間テストを実行します。 データベース名を接続プールの名前であるtest-poolに設定します。
テストが完了すると、次のような出力が表示されます(これらの結果は、データベースノードの仕様によって異なることに注意してください)。
Outputstarting vacuum...end.
progress: 60.0 s, 240.0 tps, lat 425.251 ms stddev 59.773
progress: 120.0 s, 350.0 tps, lat 428.647 ms stddev 57.084
progress: 180.0 s, 340.3 tps, lat 440.680 ms stddev 313.631
progress: 240.0 s, 364.9 tps, lat 411.083 ms stddev 61.106
progress: 300.0 s, 366.5 tps, lat 409.367 ms stddev 60.165
progress: 360.0 s, 362.5 tps, lat 413.750 ms stddev 59.005
progress: 420.0 s, 359.5 tps, lat 417.292 ms stddev 60.395
progress: 480.0 s, 363.8 tps, lat 412.130 ms stddev 60.361
progress: 540.0 s, 351.6 tps, lat 426.661 ms stddev 62.960
progress: 600.0 s, 344.5 tps, lat 435.516 ms stddev 65.182
transaction type:
scaling factor: 150
query mode: simple
number of clients: 150
number of threads: 2
duration: 600 s
number of transactions actually processed: 206768
latency average = 421.719 ms
latency stddev = 114.676 ms
tps = 344.240797 (including connections establishing)
tps = 344.385646 (excluding connections establishing) ここで、150の同時接続でデータベースのスループットを257TPSから344TPSに上げることができ(33%の増加)、接続プールなしで以前にヒットしたmax_connectionsの制限に達していないことに注意してください。 接続プールをデータベースの前に配置することにより、接続のドロップを回避し、同時接続が多数ある環境でデータベースのスループットを大幅に向上させることができます。
これと同じテストを実行しますが、-cの値が50(クライアントの数が少ないことを指定)の場合、接続プールを使用することによるメリットはそれほど明白ではなくなります。
Outputstarting vacuum...end.
progress: 60.0 s, 154.0 tps, lat 290.592 ms stddev 35.530
progress: 120.0 s, 162.7 tps, lat 307.168 ms stddev 241.003
progress: 180.0 s, 172.0 tps, lat 290.678 ms stddev 36.225
progress: 240.0 s, 172.4 tps, lat 290.169 ms stddev 37.603
progress: 300.0 s, 177.8 tps, lat 281.214 ms stddev 35.365
progress: 360.0 s, 177.7 tps, lat 281.402 ms stddev 35.227
progress: 420.0 s, 174.5 tps, lat 286.404 ms stddev 34.797
progress: 480.0 s, 176.1 tps, lat 284.107 ms stddev 36.540
progress: 540.0 s, 173.1 tps, lat 288.771 ms stddev 38.059
progress: 600.0 s, 174.5 tps, lat 286.508 ms stddev 59.941
transaction type:
scaling factor: 150
query mode: simple
number of clients: 50
number of threads: 2
duration: 600 s
number of transactions actually processed: 102938
latency average = 288.509 ms
latency stddev = 83.503 ms
tps = 171.482966 (including connections establishing)
tps = 171.553434 (excluding connections establishing) ここでは、接続プールを使用してスループットを向上させることができなかったことがわかります。 スループットは175 TPSから171 TPSに低下しました。
このガイドでは、組み込みのベンチマークデータセットでpgbenchを使用しますが、接続プールを使用するかどうかを判断するための最良のテストは、本番データに対してデータベースの本番負荷を正確に表すベンチマーク負荷です。 カスタムベンチマークスクリプトとデータの作成はこのガイドの範囲を超えていますが、詳細については、公式のpgbench documentationを参照してください。
[.note]#Note:pool size設定は、ワークロード固有のものです。 このガイドでは、使用可能なすべてのバックエンドデータベース接続を使用するように接続プールを構成しました。 これは、ベンチマーク全体を通じて、データベースが完全に使用されることはめったにないためです(クラウドコントロールパネルの[Metrics]タブからデータベースの負荷を監視できます)。 データベースの負荷によっては、これが最適な設定ではない場合があります。 データベースが常に完全に飽和していることに気付いた場合、接続プールを縮小すると、すでにロードされているサーバーですべてを同時に実行しようとするのではなく、追加の要求をキューに入れることでスループットが向上し、パフォーマンスが向上する可能性があります。
#
結論
DigitalOcean Managed Databases接続プーリングは、データベースから余分なパフォーマンスを迅速に引き出すことができる強力な機能です。 レプリケーション、キャッシング、シャーディングなどの他の手法に加えて、接続プーリングは、データベースレイヤーをスケーリングして、さらに多くのリクエストを処理するのに役立ちます。
このガイドでは、PostgreSQLの組み込みのpgbenchベンチマークツールとそのデフォルトのベンチマークテストを使用した、単純で総合的なテストシナリオに焦点を当てました。 生産シナリオでは、生産負荷をシミュレートしながら、実際の生産データに対してベンチマークを実行する必要があります。 これにより、特定の使用パターンに合わせてデータベースを調整できます。
pgbenchに加えて、データベースのベンチマークとロードを行うための他のツールが存在します。 Perconaによって開発されたそのようなツールの1つは、sysbench-tpccです。 もう1つはApacheのJMeterで、これはWebアプリケーションだけでなくテストデータベースもロードできます。
DigitalOcean管理対象データベースの詳細については、管理対象データベースproduct documentationを参照してください。 もう1つの便利なスケーリング手法であるシャーディングの詳細については、Understanding Database Shardingを参照してください。