著者は、Write for DOnationsプログラムの一部として寄付を受け取るためにGirls Who Codeを選択しました。
前書き
Reinforcement learningは制御理論内のサブフィールドであり、時間の経過とともに変化する制御システムに関係し、自動運転車、ロボット工学、ゲーム用ボットなどのアプリケーションを幅広く含みます。 このガイドでは、強化学習を使用してAtariビデオゲーム用のボットを構築します。 このボットには、ゲームに関する内部情報へのアクセスは許可されていません。 代わりに、ゲームのレンダリングされたディスプレイへのアクセスとそのディスプレイに対する報酬のみが与えられます。つまり、人間のプレーヤーが見るものしか見ることができません。
機械学習では、ボットは正式にはagentと呼ばれます。 このチュートリアルの場合、エージェントは、policyと呼ばれる意思決定機能に従って動作するシステム内の「プレーヤー」です。 第一の目標は、強力なポリシーで武装して強力なエージェントを開発することです。 言い換えれば、私たちの目的は、強力な意思決定能力を備えたインテリジェントボットを開発することです。
このチュートリアルでは、比較のためのベースラインとなるクラシックなAtariアーケードゲームであるSpace Invadersをプレイするときにランダムアクションを実行する基本的な強化学習エージェントをトレーニングします。 これに続いて、スペースインベーダーとフローズンレイク(Gymに含まれるシンプルなゲーム環境)をプレイするエージェントを構築しながら、Q-learning、deep Q-learning、least squaresなどの他のいくつかのテクニックを探求します。 )s、OpenAIによってリリースされた強化学習ツールキット。 このチュートリアルに従うことにより、機械学習でのモデルの複雑さの選択を支配する基本概念を理解できます。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
1GB以上のRAMを備えたUbuntu 18.04を実行しているサーバー。 このサーバーには、
sudo特権が構成されたroot以外のユーザーと、UFWでセットアップされたファイアウォールが必要です。 このInitial Server Setup Guide for Ubuntu 18.04に従うことで、これを設定できます。 -
ガイド「https://www.digitalocean.com/community/tutorials/how-to-install-python-3-and-set-up-a-programming-environment-」を読むことで実現できるPython 3仮想環境on-an-ubuntu-18-04-server [Ubuntu 18.04サーバーにPython 3をインストールしてプログラミング環境をセットアップする方法]。
または、ローカルマシンを使用している場合は、Python Installation and Setup Seriesを介してオペレーティングシステムに適したチュートリアルを読んで、Python3をインストールしてローカルプログラミング環境をセットアップできます。
[[step-1 -—- creating-the-project-and-installing-dependencies]] ==ステップ1—プロジェクトの作成と依存関係のインストール
ボットの開発環境を設定するには、ゲーム自体と計算に必要なライブラリをダウンロードする必要があります。
AtariBotという名前のこのプロジェクトのワークスペースを作成することから始めます。
mkdir ~/AtariBot新しいAtariBotディレクトリに移動します。
cd ~/AtariBot次に、プロジェクトの新しい仮想環境を作成します。 この仮想環境には、任意の名前を付けることができます。ここでは、ataribotという名前を付けます。
python3 -m venv ataribot環境をアクティブにします。
source ataribot/bin/activateUbuntuでは、バージョン16.04の時点で、OpenCVは機能するためにさらにいくつかのパッケージをインストールする必要があります。 これらには、ソフトウェアビルドプロセスを管理するアプリケーションであるCMake、セッションマネージャー、その他の拡張機能、デジタル画像合成が含まれます。 次のコマンドを実行して、これらのパッケージをインストールします。
sudo apt-get install -y cmake libsm6 libxext6 libxrender-dev libz-dev[。注意]##
NOTE: MacOSを実行しているローカルマシンでこのガイドに従っている場合、インストールする必要がある追加のソフトウェアはCMakeだけです。 Homebrew(prerequisite MacOS tutorialに従った場合にインストールされます)を使用して、次のように入力してインストールします。
brew install cmake次に、pipを使用して、ホイールパッケージング標準のリファレンス実装であるwheelパッケージをインストールします。 Pythonライブラリであるこのパッケージは、ホイールを構築するための拡張機能として機能し、.whlファイルを操作するためのコマンドラインツールが含まれています。
python -m pip install wheelwheelに加えて、次のパッケージをインストールする必要があります。
-
Gym、さまざまなゲームを研究に利用できるようにするPythonライブラリ、およびAtariゲームのすべての依存関係。 OpenAIによって開発されたGymは、さまざまなエージェントとアルゴリズムのパフォーマンスを均一に/評価できるように、各ゲームの公開ベンチマークを提供します。
-
Tensorflow、ディープラーニングライブラリ。 このライブラリにより、計算をより効率的に実行することができます。 具体的には、GPU上で排他的に実行されるTensorflowの抽象化を使用して数学関数を構築することにより、これを行います。
-
OpenCV、前述のコンピュータビジョンライブラリ。
-
SciPy、効率的な最適化アルゴリズムを提供する科学計算ライブラリ。
-
NumPy、線形代数ライブラリ。
次のコマンドを使用して、これらの各パッケージをインストールします。 このコマンドは、インストールする各パッケージのバージョンを指定することに注意してください。
python -m pip install gym==0.9.5 tensorflow==1.5.0 tensorpack==0.8.0 numpy==1.14.0 scipy==1.1.0 opencv-python==3.4.1.15これに続いて、もう一度pipを使用して、スペースインベーダーを含むさまざまなAtariビデオゲームを含むGymのAtari環境をインストールします。
python -m pip install gym[atari]gym[atari]パッケージのインストールが成功した場合、出力は次のように終了します。
OutputInstalling collected packages: atari-py, Pillow, PyOpenGL
Successfully installed Pillow-5.4.1 PyOpenGL-3.1.0 atari-py-0.1.7これらの依存関係がインストールされたら、次に進み、ランダムに再生して比較のベースラインとして機能するエージェントを作成します。
[[step-2 -—- creating-a-baseline-random-agent-with-gym]] ==ステップ2—ジムを使用したベースラインランダムエージェントの作成
必要なソフトウェアがサーバーにあるので、古典的なAtariゲームの単純化されたバージョンであるSpace Invadersをプレイするエージェントをセットアップします。 どの実験でも、モデルのパフォーマンスを理解するのに役立つベースラインを取得する必要があります。 このエージェントは各フレームでランダムなアクションを実行するため、ランダムなベースラインエージェントと呼びます。 この場合、このベースラインエージェントと比較して、後の手順でエージェントのパフォーマンスを確認します。
Gymを使用すると、独自のgame loopを維持できます。 これは、ゲームの実行のすべてのステップを処理することを意味します。すべてのタイムステップで、gymに新しいアクションを与え、gymにgame stateを要求します。 このチュートリアルでは、ゲームの状態は、特定のタイムステップでのゲームの外観であり、ゲームをプレイしている場合に表示されるものです。
お好みのテキストエディタを使用して、bot_2_random.pyという名前のPythonファイルを作成します。 ここでは、nanoを使用します。
nano bot_2_random.py[.note]#Note:このガイド全体を通して、ボットの名前は、表示される順序ではなく、表示されるステップ番号に揃えられています。 したがって、このボットの名前はbot_1_random.pyではなくbot_2_random.pyです。
#
次の強調表示された行を追加して、このスクリプトを開始します。 これらの行には、このスクリプトの機能を説明するコメントブロックと、このスクリプトが機能するために最終的に必要となるパッケージをインポートする2つのimportステートメントが含まれています。
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import randommain関数を追加します。 この関数では、ゲーム環境—SpaceInvaders-v0 —を作成してから、env.resetを使用してゲームを初期化します。
/AtariBot/bot_2_random.py
. . .
import gym
import random
def main():
env = gym.make('SpaceInvaders-v0')
env.reset()次に、env.step関数を追加します。 この関数は、次の種類の値を返すことができます。
-
state:提供されたアクションを適用した後のゲームの新しい状態。 -
reward:状態が被るスコアの増加。 例として、これは、弾丸がエイリアンを破壊し、スコアが50ポイント増加した場合です。 次に、reward = 50。 スコアベースのゲームをプレイする場合、プレーヤーの目標はスコアを最大化することです。 これは、総報酬を最大化することと同義です。 -
done:エピソードが終了したかどうか。これは通常、プレイヤーがすべての命を失ったときに発生します。 -
info:今のところ取っておくことになる無関係な情報。
rewardを使用して合計報酬をカウントします。 また、doneを使用して、プレーヤーがいつ死ぬかを決定します。これは、doneがTrueを返すときです。
次のゲームループを追加します。これは、プレーヤーが死ぬまでループするようにゲームに指示します。
/AtariBot/bot_2_random.py
. . .
def main():
env = gym.make('SpaceInvaders-v0')
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action)
episode_reward += reward
if done:
print('Reward: %s' % episode_reward)
break最後に、main関数を実行します。 __name__チェックを含めて、python bot_2_random.pyを使用して直接呼び出した場合にのみmainが実行されるようにします。 ifチェックを追加しない場合、Pythonファイルeven when you import the fileの実行時にmainが常にトリガーされます。 したがって、コードをmain関数に配置し、__name__ == '__main__'の場合にのみ実行することをお勧めします。
/AtariBot/bot_2_random.py
. . .
def main():
. . .
if done:
print('Reward %s' % episode_reward)
break
if __name__ == '__main__':
main()ファイルを保存し、エディターを終了します。 nanoを使用している場合は、CTRL+X、Y、ENTERの順に押します。 次に、次のように入力してスクリプトを実行します。
python bot_2_random.pyプログラムは、次のような数値を出力します。 ファイルを実行するたびに、異なる結果が得られることに注意してください。
OutputMaking new env: SpaceInvaders-v0
Reward: 210.0これらのランダムな結果には問題があります。 他の研究者や実務家が恩恵を受けることができる仕事を生み出すためには、結果と試験が再現可能でなければなりません。 これを修正するには、スクリプトファイルを再度開きます。
nano bot_2_random.pyimport randomの後に、random.seed(0)を追加します。 env = gym.make('SpaceInvaders-v0')の後に、env.seed(0)を追加します。 これらのラインを組み合わせることで、一貫した開始点で環境を「シード」し、結果が常に再現可能になるようにします。 最終ファイルは、次の内容と完全に一致します。
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import random
random.seed(0)
def main():
env = gym.make('SpaceInvaders-v0')
env.seed(0)
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action)
episode_reward += reward
if done:
print('Reward: %s' % episode_reward)
break
if __name__ == '__main__':
main()ファイルを保存してエディターを閉じ、ターミナルで次のように入力してスクリプトを実行します。
python bot_2_random.pyこれにより、正確に次の報酬が出力されます。
OutputMaking new env: SpaceInvaders-v0
Reward: 555.0これは非常に最初のボットですが、決定を下すときに周囲の環境を考慮していないため、かなりインテリジェントではありません。 ボットのパフォーマンスをより確実に推定するために、エージェントを一度に複数のエピソードで実行し、複数のエピソード全体の平均報酬を報告することができます。 これを設定するには、最初にファイルを再度開きます。
nano bot_2_random.pyrandom.seed(0)の後に、次の強調表示された行を追加して、エージェントに10エピソードのゲームをプレイするように指示します。
/AtariBot/bot_2_random.py
. . .
random.seed(0)
num_episodes = 10
. . .env.seed(0)の直後に、報酬の新しいリストを開始します。
/AtariBot/bot_2_random.py
. . .
env.seed(0)
rewards = []
. . .env.reset()からmain()の終わりまでのすべてのコードをforループにネストし、num_episodes回繰り返します。 各行をenv.reset()からbreakまで4つのスペースでインデントしてください。
/AtariBot/bot_2_random.py
. . .
def main():
env = gym.make('SpaceInvaders-v0')
env.seed(0)
rewards = []
for _ in range(num_episodes):
env.reset()
episode_reward = 0
while True:
...現在メインゲームループの最後の行であるbreakの直前に、現在のエピソードの報酬をすべての報酬のリストに追加します。
/AtariBot/bot_2_random.py
. . .
if done:
print('Reward: %s' % episode_reward)
rewards.append(episode_reward)
break
. . .main関数の最後に、平均報酬を報告します。
/AtariBot/bot_2_random.py
. . .
def main():
...
print('Reward: %s' % episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
. . .ファイルは次のようになります。 次のコードブロックには、スクリプトの重要な部分を明確にするためのコメントがいくつか含まれていることに注意してください。
/AtariBot/bot_2_random.py
"""
Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
"""
import gym
import random
random.seed(0) # make results reproducible
num_episodes = 10
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
for _ in range(num_episodes):
env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
_, reward, done, _ = env.step(action) # random action
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
if __name__ == '__main__':
main()ファイルを保存し、エディターを終了して、スクリプトを実行します。
python bot_2_random.pyこれにより、次の平均報酬が正確に印刷されます。
OutputMaking new env: SpaceInvaders-v0
. . .
Average reward: 163.50ベースラインスコアのより信頼できる推定値が得られました。 ただし、優れたエージェントを作成するには、強化学習のフレームワークを理解する必要があります。 「意思決定」の抽象的な概念をより具体的にするにはどうすればよいですか?
強化学習について
どのゲームでも、プレーヤーの目標はスコアを最大化することです。 このガイドでは、プレーヤーのスコアをrewardと呼びます。 報酬を最大化するには、プレイヤーは意思決定能力を磨くことができなければなりません。 正式には、決定とは、ゲームを見たり、ゲームの状態を観察したり、アクションを選択したりするプロセスです。 私たちの意思決定関数はpolicyと呼ばれます。ポリシーは状態を入力として受け入れ、アクションを「決定」します。
policy: state -> actionこのような関数を作成するために、Q-learning algorithmsと呼ばれる強化学習の特定のアルゴリズムセットから始めます。 これらを説明するために、ゲームの初期状態を考えてみましょう。これをstate0と呼びます。宇宙船とエイリアンは、すべて開始位置にいます。 次に、各アクションが獲得する報酬を示す魔法の「Qテーブル」にアクセスできると仮定します。
| 状態 | アクション | 褒賞 |
|---|---|---|
state0 |
シュート |
10 |
state0 |
右 |
3 |
state0 |
left |
3 |
shootアクションは、最高値10の報酬をもたらすため、報酬を最大化します。 ご覧のとおり、Qテーブルは、観察された状態に基づいて、決定を下す簡単な方法を提供します。
policy: state -> look at Q-table, pick action with greatest rewardただし、ほとんどのゲームには状態が多すぎてテーブルにリストできません。 このような場合、Q学習エージェントはQテーブルではなくQ-functionを学習します。 このQ関数は、以前のQテーブルの使用方法と同様に使用します。 テーブルエントリを関数として書き換えると、次のことがわかります。
Q(state0, shoot) = 10
Q(state0, right) = 3
Q(state0, left) = 3特定の状態を考えると、簡単に判断できます。考えられる各アクションとその報酬を確認し、予想される最高の報酬に対応するアクションを実行するだけです。 以前のポリシーをより正式に再編成すると、次のようになります。
policy: state -> argmax_{action} Q(state, action)これは、意思決定機能の要件を満たします。ゲーム内の状態を考えると、アクションを決定します。 ただし、このソリューションは、すべての状態とアクションのQ(state, action)を知ることに依存しています。 Q(state, action)を見積もるには、次のことを考慮してください。
-
エージェントの状態、アクション、および報酬の多くの観察を考えると、移動平均を取ることにより、すべての状態およびアクションの報酬の推定値を取得できます。
-
Space Invadersは、報酬が遅れるゲームです。プレイヤーは、エイリアンが爆発したときに報酬が与えられます。 ただし、射撃によってアクションをとるプレーヤーは、報酬の真の推進力です。 どういうわけか、Q関数は
(state0, shoot)に正の報酬を割り当てる必要があります。
これらの2つの洞察は、次の方程式で体系化されています。
Q(state, action) = (1 - learning_rate) * Q(state, action) + learning_rate * Q_target
Q_target = reward + discount_factor * max_{action'} Q(state', action')これらの方程式は、次の定義を使用します。
-
state:現在のタイムステップでの状態 -
action:現在のタイムステップで実行されたアクション -
reward:現在のタイムステップに対する報酬 -
state':アクションを実行した場合の次のタイムステップの新しい状態a -
action':考えられるすべてのアクション -
learning_rate:学習率 -
discount_factor:割引係数、それを伝播するときに報酬が「低下」する量
これら2つの方程式の完全な説明については、Understanding Q-Learningに関するこの記事を参照してください。
この強化学習の理解を念頭に置いて、残っているのは、実際にゲームを実行し、新しいポリシーのこれらのQ値の推定値を取得することだけです。
[[step-3 -—- creating-a-simple-q-learning-agent-for-frozen-lake]] ==ステップ3— FrozenLake用の単純なQ学習エージェントの作成
ベースラインエージェントができたので、新しいエージェントの作成を開始し、元のエージェントと比較できます。 このステップでは、Q-learningを使用するエージェントを作成します。これは、特定の状態が与えられたときに実行するアクションをエージェントに教えるために使用される強化学習手法です。 このエージェントは新しいゲームFrozenLakeをプレイします。 このゲームのセットアップは、ジムのWebサイトで次のように説明されています。
冬が来た。 あなたとあなたの友人は、フリスビーを湖の真ん中に置き去りにした野生の投げをしたときに、公園でフリスビーを投げ回していました。 水はほとんど凍っていますが、氷が溶けている穴がいくつかあります。 これらの穴のいずれかに足を踏み入れると、凍った水の中に落ちます。 現時点では、国際的なフリスビー不足が発生しているため、湖を渡ってディスクを回収することが絶対に不可欠です。 ただし、氷は滑りやすいため、常に意図した方向に移動するとは限りません。
表面は、次のようなグリッドを使用して記述されます。
SFFF (S: starting point, safe)
FHFH (F: frozen surface, safe)
FFFH (H: hole, fall to your doom)
HFFG (G: goal, where the frisbee is located)プレーヤーは、Sで示される左上から開始し、Gで示される右下のゴールに向かって進みます。 使用可能なアクションはright、left、up、およびdownであり、目標に到達するとスコアが1になります。 Hで示される多数の穴があり、1つに分類されると、スコアは0になります。
このセクションでは、簡単なQ学習エージェントを実装します。 以前に学んだことを使用して、explorationとexploitationの間でトレードオフするエージェントを作成します。 この文脈では、探索とはエージェントがランダムに行動することを意味し、搾取とはQ値を使用して最適な行動と思われるものを選択することを意味します。 また、Q値を保持するためのテーブルを作成し、エージェントが行動して学習するにつれて、それを段階的に更新します。
手順2のスクリプトのコピーを作成します。
cp bot_2_random.py bot_3_q_table.py次に、編集のためにこの新しいファイルを開きます。
nano bot_3_q_table.pyスクリプトの目的を説明するファイルの上部にあるコメントを更新することから始めます。 これは単なるコメントであるため、この変更はスクリプトが正常に機能するために必要ではありませんが、スクリプトの動作を追跡するのに役立ちます。
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
. . .スクリプトに機能的な変更を加える前に、線形代数ユーティリティのnumpyをインポートする必要があります。 import gymのすぐ下に、強調表示された行を追加します。
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
import gym
import numpy as np
import random
random.seed(0) # make results reproducible
. . .random.seed(0)の下に、numpyのシードを追加します。
/AtariBot/bot_3_q_table.py
. . .
import random
random.seed(0) # make results reproducible
np.random.seed(0)
. . .次に、ゲームの状態にアクセスできるようにします。 env.reset()行を更新して、次のようにします。これにより、ゲームの初期状態が変数stateに格納されます。
/AtariBot/bot_3_q_table.py
. . .
for _ in range(num_episodes):
state = env.reset()
. . .env.step(...)行を更新して、次の状態state2を格納する次のようにします。 Q関数を更新するには、現在のstateと次のstate2の両方が必要になります。
/AtariBot/bot_3_q_table.py
. . .
while True:
action = env.action_space.sample()
state2, reward, done, _ = env.step(action)
. . .episode_reward += rewardの後に、変数stateを更新する行を追加します。 これにより、stateが現在の状態を反映することが期待されるため、変数stateは次の反復のために更新されたままになります。
/AtariBot/bot_3_q_table.py
. . .
while True:
. . .
episode_reward += reward
state = state2
if done:
. . .if doneブロックで、各エピソードの報酬を出力するprintステートメントを削除します。 代わりに、多くのエピソードで平均報酬を出力します。 if doneブロックは次のようになります。
/AtariBot/bot_3_q_table.py
. . .
if done:
rewards.append(episode_reward)
break
. . .これらの変更後、ゲームループは次のように一致します。
/AtariBot/bot_3_q_table.py
. . .
for _ in range(num_episodes):
state = env.reset()
episode_reward = 0
while True:
action = env.action_space.sample()
state2, reward, done, _ = env.step(action)
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward))
break
. . .次に、エージェントが探索と開発の間でトレードオフする機能を追加します。 メインのゲームループ(for...で始まる)の直前に、Q値テーブルを作成します。
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for _ in range(num_episodes):
. . .次に、forループを書き直して、エピソード番号を公開します。
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .while True:の内部ゲームループ内で、noiseを作成します。 Noise、つまり意味のないランダムデータは、モデルのパフォーマンスと精度の両方を向上させることができるため、ディープニューラルネットワークをトレーニングするときに導入されることがあります。 ノイズが高いほど、Q[state, :]の値は重要ではないことに注意してください。 結果として、ノイズが高いほど、エージェントはゲームに関する知識とは無関係に行動する可能性が高くなります。 言い換えると、ノイズが高いと、エージェントはexploreのランダムアクションを実行するようになります。
/AtariBot/bot_3_q_table.py
. . .
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = env.action_space.sample()
. . .episodesが増加すると、ノイズの量は2次関数的に減少することに注意してください。時間が経つにつれて、エージェントはゲームの報酬の独自の評価を信頼し、その知識をexploitし始めることができるため、探索が少なくなります。
action行を更新して、エージェントがQ値テーブルに従ってアクションを選択するようにします。いくつかの調査が組み込まれています。
/AtariBot/bot_3_q_table.py
. . .
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
. . .メインゲームループは次のように一致します。
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
break
. . .次に、Bellman update equationを使用してQ値テーブルを更新します。これは、機械学習で広く使用されている方程式であり、特定の環境内で最適なポリシーを見つけます。
ベルマン方程式には、このプロジェクトに非常に関連性の高い2つのアイデアが組み込まれています。 まず、特定の状態から特定のアクションを何度も実行すると、その状態とアクションに関連付けられたQ値の適切な推定値が得られます。 このため、より強力なQ値の推定値を返すために、このボットが再生する必要があるエピソードの数を増やします。 第二に、元のアクションにゼロ以外の報酬が割り当てられるように、報酬は時間を通じて伝播する必要があります。 このアイデアは、報酬が遅れるゲームで最も明確です。たとえば、スペースインベーダーでは、プレイヤーが撃たれたときではなく、エイリアンが爆発したときにプレイヤーに報酬が与えられます。 ただし、プレーヤーの射撃は報酬の真の推進力です。 同様に、Q関数は(state0、shoot)に正の報酬を割り当てる必要があります。
まず、num_episodesを4000に等しくなるように更新します。
/AtariBot/bot_3_q_table.py
. . .
np.random.seed(0)
num_episodes = 4000
. . .次に、必要なハイパーパラメーターをさらに2つの変数の形式でファイルの先頭に追加します。
/AtariBot/bot_3_q_table.py
. . .
num_episodes = 4000
discount_factor = 0.8
learning_rate = 0.9
. . .env.step(...)を含む行の直後に、新しいターゲットQ値を計算します。
/AtariBot/bot_3_q_table.py
. . .
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
episode_reward += reward
. . .Qtargetの直後の行で、新旧のQ値の加重平均を使用してQ値テーブルを更新します。
/AtariBot/bot_3_q_table.py
. . .
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
. . .メインのゲームループが次と一致することを確認します。
/AtariBot/bot_3_q_table.py
. . .
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
break
. . .エージェントをトレーニングするためのロジックが完成しました。 あとは、レポートメカニズムを追加するだけです。
Pythonは厳密な型チェックを強制していませんが、クリーンにするために関数宣言に型を追加します。 ファイルの先頭で、import gymを読み取る最初の行の前に、Listタイプをインポートします。
/AtariBot/bot_3_q_table.py
. . .
from typing import List
import gym
. . .learning_rate = 0.9の直後、main関数の外で、レポートの間隔と形式を宣言します。
/AtariBot/bot_3_q_table.py
. . .
learning_rate = 0.9
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def main():
. . .main関数の前に、すべての報酬のリストを使用して、このreport文字列を設定する新しい関数を追加します。
/AtariBot/bot_3_q_table.py
. . .
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def print_report(rewards: List, episode: int):
"""Print rewards report for current episode
- Average for last 100 episodes
- Best 100-episode average across all time
- Average for all episodes across time
"""
print(report % (
np.mean(rewards[-100:]),
max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
np.mean(rewards),
episode))
def main():
. . .ゲームをSpaceInvadersではなくFrozenLakeに変更します。
/AtariBot/bot_3_q_table.py
. . .
def main():
env = gym.make('FrozenLake-v0') # create the game
. . .rewards.append(...)の後に、過去100エピソードの平均報酬を印刷し、すべてのエピソードの平均報酬を印刷します。
/AtariBot/bot_3_q_table.py
. . .
if done:
rewards.append(episode_reward)
if episode % report_interval == 0:
print_report(rewards, episode)
. . .main()関数の最後に、両方の平均をもう一度報告します。 これを行うには、print('Average reward: %.2f' % (sum(rewards) / len(rewards)))を読み取る行を次の強調表示された行に置き換えます。
/AtariBot/bot_3_q_table.py
. . .
def main():
...
break
print_report(rewards, -1)
. . .最後に、Q学習エージェントが完成しました。 スクリプトが次と一致することを確認します。
/AtariBot/bot_3_q_table.py
"""
Bot 3 -- Build simple q-learning agent for FrozenLake
"""
from typing import List
import gym
import numpy as np
import random
random.seed(0) # make results reproducible
np.random.seed(0) # make results reproducible
num_episodes = 4000
discount_factor = 0.8
learning_rate = 0.9
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def print_report(rewards: List, episode: int):
"""Print rewards report for current episode
- Average for last 100 episodes
- Best 100-episode average across all time
- Average for all episodes across time
"""
print(report % (
np.mean(rewards[-100:]),
max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
np.mean(rewards),
episode))
def main():
env = gym.make('FrozenLake-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
state = env.reset()
episode_reward = 0
while True:
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
action = np.argmax(Q[state, :] + noise)
state2, reward, done, _ = env.step(action)
Qtarget = reward + discount_factor * np.max(Q[state2, :])
Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
episode_reward += reward
state = state2
if done:
rewards.append(episode_reward)
if episode % report_interval == 0:
print_report(rewards, episode)
break
print_report(rewards, -1)
if __name__ == '__main__':
main()ファイルを保存し、エディターを終了して、スクリプトを実行します。
python bot_3_q_table.py出力は次と一致します。
Output100-ep Average: 0.11 . Best 100-ep Average: 0.12 . Average: 0.03 (Episode 500)
100-ep Average: 0.25 . Best 100-ep Average: 0.24 . Average: 0.09 (Episode 1000)
100-ep Average: 0.39 . Best 100-ep Average: 0.48 . Average: 0.19 (Episode 1500)
100-ep Average: 0.43 . Best 100-ep Average: 0.55 . Average: 0.25 (Episode 2000)
100-ep Average: 0.44 . Best 100-ep Average: 0.55 . Average: 0.29 (Episode 2500)
100-ep Average: 0.64 . Best 100-ep Average: 0.68 . Average: 0.32 (Episode 3000)
100-ep Average: 0.63 . Best 100-ep Average: 0.71 . Average: 0.36 (Episode 3500)
100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode 4000)
100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode -1)これで、ゲーム用の最初の重要なボットができましたが、この平均報酬0.78を考えてみましょう。 Gym FrozenLake pageによると、ゲームを「解決する」とは、100エピソードの平均0.78を達成することを意味します。 非公式には、「解決」とは「ゲームを非常にうまくプレイする」ことを意味します。 記録的な時間ではありませんが、Qテーブルエージェントは4000エピソードでFrozenLakeを解決できます。
ただし、ゲームはより複雑になる場合があります。 ここでは、144個の可能な状態すべてを格納するためにテーブルを使用しましたが、19,683個の可能な状態がある三目並べを考えてみましょう。 同様に、カウントできない状態が多すぎるスペースインベーダーについて検討します。 ゲームがますます複雑になるにつれて、Qテーブルは持続可能ではありません。 このため、Qテーブルを近似する何らかの方法が必要です。 次のステップで実験を続けながら、状態とアクションを入力として受け入れ、Q値を出力できる関数を設計します。
[[step-4 -—- building-a-deep-q-learning-agent-for-frozen-lake]] ==ステップ4— FrozenLake用のディープQ学習エージェントの構築
強化学習では、ニューラルネットワークはstateとactionの入力に基づいて、可能なすべての値を格納するテーブルを使用してQの値を効果的に予測しますが、これは複雑なゲームでは不安定になります。 深層強化学習は、代わりにニューラルネットワークを使用してQ関数を近似します。 詳細については、Understanding Deep Q-Learningを参照してください。
手順1でインストールしたディープラーニングライブラリであるTensorflowに慣れるには、これまでに使用されていたすべてのロジックをTensorflowの抽象化で再実装し、ニューラルネットワークを使用してQ関数を近似します。 ただし、ニューラルネットワークは非常に単純です。出力Q(s)は、行列Wに入力sを掛けたものです。 これは、1つのfully-connected layerを持つニューラルネットワークとして知られています。
Q(s) = Ws繰り返しになりますが、目標は、Tensorflow抽象化を使用して既に構築したボットのすべてのロジックを実装することです。 Tensorflowはすべての計算をGPUで実行できるため、これにより操作がより効率的になります。
まず、ステップ3のQテーブルスクリプトを複製します。
cp bot_3_q_table.py bot_4_q_network.py次に、nanoまたはお好みのテキストエディタで新しいファイルを開きます。
nano bot_4_q_network.pyまず、ファイルの上部にあるコメントを更新します。
/AtariBot/bot_4_q_network.py
"""
Bot 4 -- Use Q-learning network to train bot
"""
. . .次に、import randomのすぐ下にimportディレクティブを追加して、Tensorflowパッケージをインポートします。 さらに、np.random.seed(0)のすぐ下にtf.set_radon_seed(0)を追加します。 これにより、このスクリプトの結果がすべてのセッションで繰り返し可能になります。
/AtariBot/bot_4_q_network.py
. . .
import random
import tensorflow as tf
random.seed(0)
np.random.seed(0)
tf.set_random_seed(0)
. . .ファイルの先頭でハイパーパラメータを再定義して以下に一致させ、exploration_probabilityという関数を追加します。これにより、各ステップでの探索の確率が返されます。 このコンテキストでは、「探索」とは、Q値の推定値で推奨されているアクションを実行するのではなく、ランダムアクションを実行することを意味します。
/AtariBot/bot_4_q_network.py
. . .
num_episodes = 4000
discount_factor = 0.99
learning_rate = 0.15
report_interval = 500
exploration_probability = lambda episode: 50. / (episode + 10)
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
. . .次に、one-hot encoding関数を追加します。 要するに、ワンホットエンコーディングとは、機械学習アルゴリズムがより良い予測を行うのに役立つ形式に変数を変換するプロセスです。 ワンホットエンコーディングについて詳しく知りたい場合は、Adversarial Examples in Computer Vision: How to Build then Fool an Emotion-Based Dog Filterを確認してください。
report = ...のすぐ下に、one_hot関数を追加します。
/AtariBot/bot_4_q_network.py
. . .
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def one_hot(i: int, n: int) -> np.array:
"""Implements one-hot encoding by selecting the ith standard basis vector"""
return np.identity(n)[i].reshape((1, -1))
def print_report(rewards: List, episode: int):
. . .次に、Tensorflowの抽象化を使用してアルゴリズムロジックを書き換えます。 ただし、その前に、まずデータのplaceholdersを作成する必要があります。
main関数のrewards=[]のすぐ下に、次の強調表示されたコンテンツを挿入します。 ここでは、時間t(obs_t_phとして)および時間t+1(obs_tp1_phとして)での観測のプレースホルダーと、アクション、報酬、およびQターゲット:
/AtariBot/bot_4_q_network.py
. . .
def main():
env = gym.make('FrozenLake-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
# 1. Setup placeholders
n_obs, n_actions = env.observation_space.n, env.action_space.n
obs_t_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
obs_tp1_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
act_ph = tf.placeholder(tf.int32, shape=())
rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .q_target_ph =で始まる行のすぐ下に、次の強調表示された行を挿入します。 このコードは、すべてのaのQ(s, a)を計算してq_currentを作成し、すべてのa’のQ(s’, a’)を計算してq_targetを作成することから計算を開始します。
/AtariBot/bot_4_q_network.py
. . .
rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
# 2. Setup computation graph
W = tf.Variable(tf.random_uniform([n_obs, n_actions], 0, 0.01))
q_current = tf.matmul(obs_t_ph, W)
q_target = tf.matmul(obs_tp1_ph, W)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .追加した最後の行のすぐ下に、次の強調表示されたコードを挿入します。 最初の2行は、Qtargetを計算するステップ3で追加された行と同等です。ここで、Qtarget = reward + discount_factor * np.max(Q[state2, :])です。 次の2行は損失を設定し、最後の行はQ値を最大化するアクションを計算します。
/AtariBot/bot_4_q_network.py
. . .
q_current = tf.matmul(obs_t_ph, W)
q_target = tf.matmul(obs_tp1_ph, W)
q_target_max = tf.reduce_max(q_target_ph, axis=1)
q_target_sa = rew_ph + discount_factor * q_target_max
q_current_sa = q_current[0, act_ph]
error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
pred_act_ph = tf.argmax(q_current, 1)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .アルゴリズムと損失関数を設定した後、オプティマイザーを定義します。
/AtariBot/bot_4_q_network.py
. . .
error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
pred_act_ph = tf.argmax(q_current, 1)
# 3. Setup optimization
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
Q = np.zeros((env.observation_space.n, env.action_space.n))
for episode in range(1, num_episodes + 1):
. . .次に、ゲームループの本体を設定します。 これを行うには、Tensorflowプレースホルダーにデータを渡します。Tensorflowの抽象化はGPUで計算を処理し、アルゴリズムの結果を返します。
古いQテーブルとロジックを削除することから始めます。 具体的には、Q(forループの直前)、noise(whileループ内)、action、Qtargetを定義する行を削除します。 s、およびQ[state, action]。 stateの名前をobs_tに、state2の名前をobs_tp1に変更して、前に設定したTensorflowプレースホルダーに合わせます。 終了すると、forループは次のように一致します。
/AtariBot/bot_4_q_network.py
. . .
# 3. Setup optimization
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
for episode in range(1, num_episodes + 1):
obs_t = env.reset()
episode_reward = 0
while True:
obs_tp1, reward, done, _ = env.step(action)
episode_reward += reward
obs_t = obs_tp1
if done:
...forループのすぐ上に、次の2つの強調表示された行を追加します。 これらの行はTensorflowセッションを初期化し、GPUで操作を実行するために必要なリソースを順番に管理します。 2行目は、計算グラフのすべての変数を初期化します。たとえば、更新する前に重みを0に初期化します。 さらに、forループをwithステートメント内にネストするため、forループ全体を4つのスペースでインデントします。
/AtariBot/bot_4_q_network.py
. . .
trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
update_model = trainer.minimize(error)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
for episode in range(1, num_episodes + 1):
obs_t = env.reset()
...obs_tp1, reward, done, _ = env.step(action)を読み取る行の前に、次の行を挿入してactionを計算します。 次のコードは、対応するプレースホルダーを評価し、アクションを何らかの確率でランダムアクションに置き換えます。
/AtariBot/bot_4_q_network.py
. . .
while True:
# 4. Take step using best action or random action
obs_t_oh = one_hot(obs_t, n_obs)
action = session.run(pred_act_ph, feed_dict={obs_t_ph: obs_t_oh})[0]
if np.random.rand(1) < exploration_probability(episode):
action = env.action_space.sample()
. . .env.step(action)を含む行の後に、次を挿入して、Q値関数を推定するニューラルネットワークをトレーニングします。
/AtariBot/bot_4_q_network.py
. . .
obs_tp1, reward, done, _ = env.step(action)
# 5. Train model
obs_tp1_oh = one_hot(obs_tp1, n_obs)
q_target_val = session.run(q_target, feed_dict={obs_tp1_ph: obs_tp1_oh})
session.run(update_model, feed_dict={
obs_t_ph: obs_t_oh,
rew_ph: reward,
q_target_ph: q_target_val,
act_ph: action
})
episode_reward += reward
. . .最終的なファイルはthis file hosted on GitHubと一致します。 ファイルを保存し、エディターを終了して、スクリプトを実行します。
python bot_4_q_network.py出力は、正確には次のようになります。
Output100-ep Average: 0.11 . Best 100-ep Average: 0.11 . Average: 0.05 (Episode 500)
100-ep Average: 0.41 . Best 100-ep Average: 0.54 . Average: 0.19 (Episode 1000)
100-ep Average: 0.56 . Best 100-ep Average: 0.73 . Average: 0.31 (Episode 1500)
100-ep Average: 0.57 . Best 100-ep Average: 0.73 . Average: 0.36 (Episode 2000)
100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.41 (Episode 2500)
100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.43 (Episode 3000)
100-ep Average: 0.69 . Best 100-ep Average: 0.73 . Average: 0.46 (Episode 3500)
100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode 4000)
100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode -1)これで、初めてのディープQラーニングエージェントのトレーニングが完了しました。 FrozenLakeのような単純なゲームの場合、Qディープラーニングエージェントはトレーニングに4000エピソードを必要としました。 ゲームがはるかに複雑だったと想像してください。 トレーニングにはいくつのトレーニングサンプルが必要ですか? 結局のところ、エージェントはmillionsのサンプルを必要とする可能性があります。 必要なサンプルの数はsample complexityと呼ばれ、次のセクションでさらに詳しく説明します。
バイアスと分散のトレードオフを理解する
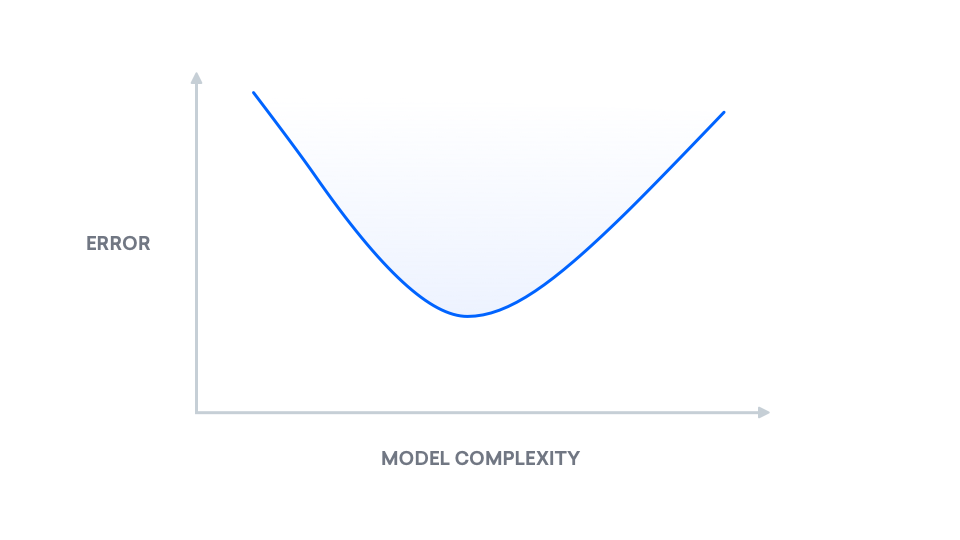
一般的に、サンプルの複雑度は機械学習のモデルの複雑度と対立します。
-
Model complexity:問題を解決するのに十分に複雑なモデルが必要です。 たとえば、線のような単純なモデルは、車の軌道を予測するのに十分複雑ではありません。
-
Sample complexity:多くのサンプルを必要としないモデルが必要です。 これは、ラベル付きデータへのアクセスが制限されている、計算能力が不十分、メモリが限られているなどの理由による可能性があります。
2つのモデルがあるとします。1つは単純なモデルで、もう1つは非常に複雑なモデルです。 両方のモデルが同じパフォーマンスを達成するために、バイアス分散は、非常に複雑なモデルではトレーニングに指数関数的に多くのサンプルが必要になることを示しています。 適切な事例:ニューラルネットワークベースのQ学習エージェントは、FrozenLakeを解決するために4000エピソードを必要としました。 ニューラルネットワークエージェントに2番目のレイヤーを追加すると、必要なトレーニングエピソードの数が4倍になります。 ますます複雑なニューラルネットワークでは、この格差は大きくなります。 同じエラー率を維持するために、モデルの複雑さを増やすと、サンプルの複雑さが指数関数的に増加します。 同様に、サンプルの複雑さを減らすと、モデルの複雑さが減ります。 したがって、モデルの複雑さを最大化することはできず、サンプルの複雑さを最小限に抑えることはできません。
ただし、このトレードオフに関する知識を活用できます。 bias-variance decompositionの背後にある数学の視覚的な解釈については、Understanding the Bias-Variance Tradeoffを参照してください。 高レベルでは、バイアス分散分解は、「真のエラー」を2つのコンポーネント(バイアスと分散)に分解したものです。 「真のエラー」をmean squared error(MSE)と呼びます。これは、予測されたラベルと真のラベルの間の予想される差です。 以下は、モデルの複雑さが増すにつれて「真のエラー」の変化を示すプロットです。
[[step-5 -—- building-a-least-squares-agent-for-frozen-lake]] ==ステップ5— FrozenLakeの最小二乗エージェントを構築する
linear regressionとも呼ばれるleast squaresメソッドは、数学やデータサイエンスの分野で広く使用されている回帰分析の手段です。 機械学習では、2つのパラメーターまたはデータセットの最適な線形モデルを見つけるためによく使用されます。
ステップ4では、Q値を計算するニューラルネットワークを構築しました。 ニューラルネットワークの代わりに、このステップでは、最小二乗の変形であるridge regressionを使用して、このQ値のベクトルを計算します。 希望は、最小二乗として複雑でないモデルで、ゲームを解くのに必要なトレーニングエピソードが少なくなることです。
手順3のスクリプトを複製することから始めます。
cp bot_3_q_table.py bot_5_ls.py新しいファイルを開きます。
nano bot_5_ls.py繰り返しますが、このスクリプトが何をするかを説明するファイルの上部にあるコメントを更新します。
/AtariBot/bot_4_q_network.py
"""
Bot 5 -- Build least squares q-learning agent for FrozenLake
"""
. . .ファイルの上部にあるインポートのブロックの前に、型チェックのためにさらに2つのインポートを追加します。
/AtariBot/bot_5_ls.py
. . .
from typing import Tuple
from typing import Callable
from typing import List
import gym
. . .ハイパーパラメータのリストに、別のハイパーパラメータw_lrを追加して、2番目のQ関数の学習率を制御します。 さらに、エピソード数を5000に更新し、割引係数を0.85に更新します。 num_episodesとdiscount_factorの両方のハイパーパラメータをより大きな値に変更することにより、エージェントはより強力なパフォーマンスを発行できるようになります。
/AtariBot/bot_5_ls.py
. . .
num_episodes = 5000
discount_factor = 0.85
learning_rate = 0.9
w_lr = 0.5
report_interval = 500
. . .print_report関数の前に、次の高階関数を追加します。 モデルを抽象化するラムダ(匿名関数)を返します。
/AtariBot/bot_5_ls.py
. . .
report_interval = 500
report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
'(Episode %d)'
def makeQ(model: np.array) -> Callable[[np.array], np.array]:
"""Returns a Q-function, which takes state -> distribution over actions"""
return lambda X: X.dot(model)
def print_report(rewards: List, episode: int):
. . .makeQの後に、別の関数initializeを追加します。この関数は、正規分布の値を使用してモデルを初期化します。
/AtariBot/bot_5_ls.py
. . .
def makeQ(model: np.array) -> Callable[[np.array], np.array]:
"""Returns a Q-function, which takes state -> distribution over actions"""
return lambda X: X.dot(model)
def initialize(shape: Tuple):
"""Initialize model"""
W = np.random.normal(0.0, 0.1, shape)
Q = makeQ(W)
return W, Q
def print_report(rewards: List, episode: int):
. . .initializeブロックの後に、リッジ回帰の閉形式の解を計算するtrainメソッドを追加し、古いモデルを新しいモデルで重み付けします。 モデルと抽象化されたQ関数の両方を返します。
/AtariBot/bot_5_ls.py
. . .
def initialize(shape: Tuple):
...
return W, Q
def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
"""Train the model, using solution to ridge regression"""
I = np.eye(X.shape[1])
newW = np.linalg.inv(X.T.dot(X) + 10e-4 * I).dot(X.T.dot(y))
W = w_lr * newW + (1 - w_lr) * W
Q = makeQ(W)
return W, Q
def print_report(rewards: List, episode: int):
. . .trainの後に、最後の関数one_hotを追加して、状態とアクションのワンホットエンコーディングを実行します。
/AtariBot/bot_5_ls.py
. . .
def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
...
return W, Q
def one_hot(i: int, n: int) -> np.array:
"""Implements one-hot encoding by selecting the ith standard basis vector"""
return np.identity(n)[i]
def print_report(rewards: List, episode: int):
. . .これに続いて、トレーニングロジックを変更する必要があります。 あなたが書いた前のスクリプトでは、Q-tableは反復ごとに更新されました。 ただし、このスクリプトは、タイムステップごとにサンプルとラベルを収集し、10ステップごとに新しいモデルをトレーニングします。 さらに、Qテーブルまたはニューラルネットワークを保持する代わりに、最小二乗モデルを使用してQ値を予測します。
main関数に移動し、Qテーブル(Q = np.zeros(...))の定義を次のように置き換えます。
/AtariBot/bot_5_ls.py
. . .
def main():
...
rewards = []
n_obs, n_actions = env.observation_space.n, env.action_space.n
W, Q = initialize((n_obs, n_actions))
states, labels = [], []
for episode in range(1, num_episodes + 1):
. . .forループの前に下にスクロールします。 このすぐ下に、保存されている情報が多すぎる場合にstatesリストとlabelsリストをリセットする次の行を追加します。
/AtariBot/bot_5_ls.py
. . .
def main():
...
for episode in range(1, num_episodes + 1):
if len(states) >= 10000:
states, labels = [], []
. . .state = env.reset()を定義するこの行の直後の行を、次のように変更します。 これは、その使用法のすべてがワンホットベクトルを必要とするため、状態をすぐにワンホットエンコードします。
/AtariBot/bot_5_ls.py
. . .
for episode in range(1, num_episodes + 1):
if len(states) >= 10000:
states, labels = [], []
state = one_hot(env.reset(), n_obs)
. . .whileメインゲームループの最初の行の前に、statesのリストを修正します。
/AtariBot/bot_5_ls.py
. . .
for episode in range(1, num_episodes + 1):
...
episode_reward = 0
while True:
states.append(state)
noise = np.random.random((1, env.action_space.n)) / (episode**2.)
. . .actionの計算を更新し、ノイズの確率を減らし、Q関数の評価を変更します。
/AtariBot/bot_5_ls.py
. . .
while True:
states.append(state)
noise = np.random.random((1, n_actions)) / episode
action = np.argmax(Q(state) + noise)
state2, reward, done, _ = env.step(action)
. . .state2のワンホットバージョンを追加し、Qtargetの定義のQ関数呼び出しを次のように修正します。
/AtariBot/bot_5_ls.py
. . .
while True:
...
state2, reward, done, _ = env.step(action)
state2 = one_hot(state2, n_obs)
Qtarget = reward + discount_factor * np.max(Q(state2))
. . .Q[state,action] = ...を更新する行を削除し、次の行に置き換えます。 このコードは、現在のモデルの出力を取得し、現在のアクションに対応するこの出力の値のみを更新します。 その結果、他のアクションのQ値には損失が生じません。
/AtariBot/bot_5_ls.py
. . .
state2 = one_hot(state2, n_obs)
Qtarget = reward + discount_factor * np.max(Q(state2))
label = Q(state)
label[action] = (1 - learning_rate) * label[action] + learning_rate * Qtarget
labels.append(label)
episode_reward += reward
. . .state = state2の直後に、モデルに定期的な更新を追加します。 これにより、10時間ステップごとにモデルがトレーニングされます。
/AtariBot/bot_5_ls.py
. . .
state = state2
if len(states) % 10 == 0:
W, Q = train(np.array(states), np.array(labels), W)
if done:
. . .ファイルがthe source codeと一致することを再確認してください。 次に、ファイルを保存し、エディターを終了して、スクリプトを実行します。
python bot_5_ls.pyこれは以下を出力します。
Output100-ep Average: 0.17 . Best 100-ep Average: 0.17 . Average: 0.09 (Episode 500)
100-ep Average: 0.11 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1000)
100-ep Average: 0.08 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1500)
100-ep Average: 0.24 . Best 100-ep Average: 0.25 . Average: 0.11 (Episode 2000)
100-ep Average: 0.32 . Best 100-ep Average: 0.31 . Average: 0.14 (Episode 2500)
100-ep Average: 0.35 . Best 100-ep Average: 0.38 . Average: 0.16 (Episode 3000)
100-ep Average: 0.59 . Best 100-ep Average: 0.62 . Average: 0.22 (Episode 3500)
100-ep Average: 0.66 . Best 100-ep Average: 0.66 . Average: 0.26 (Episode 4000)
100-ep Average: 0.60 . Best 100-ep Average: 0.72 . Average: 0.30 (Episode 4500)
100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode 5000)
100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode -1)Gym FrozenLake pageによると、ゲームを「解決する」とは、100エピソードの平均である0.78を達成することを意味することを思い出してください。 ここでは、エージェントは平均0.82を達成し、5000エピソードでゲームを解決できたことを意味します。 これは、より少ないエピソードでゲームを解決しませんが、この基本的な最小二乗法は、おおよそ同じ数のトレーニングエピソードを持つ単純なゲームを解決できます。 ニューラルネットワークは複雑になりますが、FrozenLakeには単純なモデルで十分であることを示しました。
これで、3つのQ学習エージェントを探索しました。1つはQテーブルを使用し、もう1つはニューラルネットワークを使用し、3つ目は最小二乗を使用します。 次に、より複雑なゲームのための深層強化学習エージェント、スペースインベーダーを構築します。
[[step-6 -—- creating-a-deep-q-learning-agent-for-space-invaders]] ==ステップ6—スペースインベーダー用のディープQ学習エージェントの作成
ニューラルネットワークを選択したか最小二乗法を選択したかに関係なく、以前のQ学習アルゴリズムのモデルの複雑さとサンプルの複雑さを完全に調整したとします。 結局のところ、この非インテリジェントなQラーニングエージェントは、特に多数のトレーニングエピソードがあっても、より複雑なゲームでは依然として不十分なパフォーマンスを発揮します。 このセクションでは、パフォーマンスを改善できる2つの手法について説明します。次に、これらの手法を使用してトレーニングされたエージェントをテストします。
人間の介入なしでその動作を継続的に適応させることができる最初の汎用エージェントは、DeepMindの研究者によって開発されました。 DeepMind’s original deep Q-learning (DQN) paperは、次の2つの重要な問題を認識しました。
-
Correlated states:時間0でのゲームの状態を取得します。これをs0と呼びます。 以前に導出したルールに従って、Q(s0)を更新するとします。 ここで、s1と呼ばれる時間1の状態を取得し、同じルールに従ってQ(s1)を更新します。 時間0でのゲームの状態は、時間1での状態と非常に似ていることに注意してください。 たとえば、スペースインベーダーでは、エイリアンがそれぞれ1ピクセルずつ移動した可能性があります。 もっと簡潔に言うと、s0とs1は非常に似ています。 同様に、Q(s0)とQ(s1)も非常に類似していると予想されるため、一方を更新すると他方に影響します。 Q(s0)への更新は実際にはQ(s1)への更新に対抗する可能性があるため、これによりQ値が変動します。 より正式には、s0とs1はcorrelatedです。 Q関数は決定論的であるため、Q(s1)はQ(s0)と相関しています。
-
Q-function instability:Q関数は、トレーニングするモデルであり、ラベルのソースでもあることを思い出してください。 ラベルは、distribution、Lを実際に表すランダムに選択された値であるとします。 Qを更新するたびに、Lを変更します。これは、モデルが移動するターゲットを学習しようとしていることを意味します。 使用するモデルは固定分布を前提としているため、これは問題です。
相関状態と不安定なQ関数に対処するには:
-
replay bufferと呼ばれる状態のリストを保持することができます。 タイムステップごとに、観察するゲームの状態をこのリプレイバッファーに追加します。 また、このリストから州のサブセットをランダムにサンプリングし、それらの州で訓練します。
-
DeepMindのチームはQ(s, a)を複製しました。 1つはQ_current(s, a)と呼ばれ、更新するQ関数です。 継承国用の別のQ関数Q_target(s’, a’)が必要ですが、これは更新しません。 Q_target(s’, a’)はラベルの生成に使用されることを思い出してください。 Q_currentをQ_targetから分離し、後者を修正することで、ラベルのサンプリング元の分布を修正します。 その後、ディープラーニングモデルはこの分布を短時間で学習できます。 しばらくすると、Q_currentを新しいQ_targetに再複製します。
これらを自分で実装することはありませんが、これらのソリューションでトレーニングした事前トレーニング済みのモデルをロードします。 これを行うには、これらのモデルのパラメーターを保存する新しいディレクトリを作成します。
mkdir models次に、wgetを使用して、事前にトレーニングされたスペースインベーダーモデルのパラメータをダウンロードします。
wget http://models.tensorpack.com/OpenAIGym/SpaceInvaders-v0.tfmodel -P models次に、ダウンロードしたパラメーターに関連付けられたモデルを指定するPythonスクリプトをダウンロードします。 この事前学習済みモデルには、入力に注意する必要がある2つの制約があることに注意してください。
-
状態は、ダウンサンプリングするか、サイズを84 x 84に縮小する必要があります。
-
入力は、積み重ねられた4つの状態で構成されます。
これらの制約については、後ほど詳しく説明します。 今のところ、次のように入力してスクリプトをダウンロードします。
wget https://github.com/alvinwan/bots-for-atari-games/raw/master/src/bot_6_a3c.pyこの事前トレーニング済みのSpace Invadersエージェントを実行して、パフォーマンスを確認します。 過去に使用したいくつかのボットとは異なり、このスクリプトはゼロから作成します。
新しいスクリプトファイルを作成します。
nano bot_6_dqn.pyこのスクリプトを開始するには、ヘッダーコメントを追加し、必要なユーティリティをインポートして、メインのゲームループを開始します。
/AtariBot/bot_6_dqn.py
"""
Bot 6 - Fully featured deep q-learning network.
"""
import cv2
import gym
import numpy as np
import random
import tensorflow as tf
from bot_6_a3c import a3c_model
def main():
if __name__ == '__main__':
main()インポート直後に、ランダムシードを設定して結果を再現可能にします。 また、エージェントを実行するエピソードの数をスクリプトに指示するハイパーパラメータnum_episodesを定義します。
/AtariBot/bot_6_dqn.py
. . .
import tensorflow as tf
from bot_6_a3c import a3c_model
random.seed(0) # make results reproducible
tf.set_random_seed(0)
num_episodes = 10
def main():
. . .num_episodesを宣言した2行後に、すべての画像を84 x 84のサイズにダウンサンプリングするdownsample関数を定義します。 事前学習済みモデルは84 x 84の画像で学習されているため、すべての画像を事前学習済みのニューラルネットワークに渡す前にダウンサンプリングします。
/AtariBot/bot_6_dqn.py
. . .
num_episodes = 10
def downsample(state):
return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
def main():
. . .main関数の開始時にゲーム環境を作成し、結果が再現可能になるように環境をシードします。
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
. . .環境シードの直後に、空のリストを初期化して報酬を保持します。
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
. . .この手順の最初にダウンロードした事前学習済みモデルパラメーターを使用して、事前学習済みモデルを初期化します。
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
. . .次に、スクリプトにnum_episodes回反復して平均パフォーマンスを計算し、各エピソードの報酬を0に初期化するように指示する行をいくつか追加します。 さらに、環境(env.reset())をリセットする行を追加し、プロセスで新しい初期状態を収集し、この初期状態をdownsample()でダウンサンプリングし、whileループを使用してゲームループを開始します:
/AtariBot/bot_6_dqn.py
. . .
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
for _ in range(num_episodes):
episode_reward = 0
states = [downsample(env.reset())]
while True:
. . .一度に1つの状態を受け入れる代わりに、新しいニューラルネットワークは一度に4つの状態を受け入れます。 その結果、事前トレーニング済みモデルを適用する前に、statesのリストに少なくとも4つの状態が含まれるまで待つ必要があります。 while True:を読み取る行の下に次の行を追加します。 これらは、4つ未満の状態がある場合にランダムアクションを実行するか、状態が連結されて少なくとも4つある場合に事前トレーニングモデルに渡すようにエージェントに指示します。
/AtariBot/bot_6_dqn.py
. . .
while True:
if len(states) < 4:
action = env.action_space.sample()
else:
frames = np.concatenate(states[-4:], axis=3)
action = np.argmax(model([frames]))
. . .次に、アクションを実行し、関連データを更新します。 観測された状態のダウンサンプリングバージョンを追加し、このエピソードの報酬を更新します。
/AtariBot/bot_6_dqn.py
. . .
while True:
...
action = np.argmax(model([frames]))
state, reward, done, _ = env.step(action)
states.append(downsample(state))
episode_reward += reward
. . .次に、エピソードがdoneであるかどうかを確認する次の行を追加し、そうである場合は、エピソードの合計報酬を出力し、すべての結果のリストを修正して、whileループを早期に中断します。
/AtariBot/bot_6_dqn.py
. . .
while True:
...
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
. . .whileおよびforループの外側で、平均報酬を出力します。 これをmain関数の最後に配置します。
/AtariBot/bot_6_dqn.py
def main():
...
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))ファイルが次と一致することを確認します。
/AtariBot/bot_6_dqn.py
"""
Bot 6 - Fully featured deep q-learning network.
"""
import cv2
import gym
import numpy as np
import random
import tensorflow as tf
from bot_6_a3c import a3c_model
random.seed(0) # make results reproducible
tf.set_random_seed(0)
num_episodes = 10
def downsample(state):
return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
def main():
env = gym.make('SpaceInvaders-v0') # create the game
env.seed(0) # make results reproducible
rewards = []
model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
for _ in range(num_episodes):
episode_reward = 0
states = [downsample(env.reset())]
while True:
if len(states) < 4:
action = env.action_space.sample()
else:
frames = np.concatenate(states[-4:], axis=3)
action = np.argmax(model([frames]))
state, reward, done, _ = env.step(action)
states.append(downsample(state))
episode_reward += reward
if done:
print('Reward: %d' % episode_reward)
rewards.append(episode_reward)
break
print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
if __name__ == '__main__':
main()ファイルを保存して、エディターを終了します。 次に、スクリプトを実行します。
python bot_6_dqn.py出力は次で終了します。
Output. . .
Reward: 1230
Reward: 4510
Reward: 1860
Reward: 2555
Reward: 515
Reward: 1830
Reward: 4100
Reward: 4350
Reward: 1705
Reward: 4905
Average reward: 2756.00これを、スペースインベーダーのランダムエージェントを実行した最初のスクリプトの結果と比較します。 その場合の平均報酬はわずか約150でした。つまり、この結果は20倍以上優れています。 ただし、かなり遅いため、コードを実行したのは3つのエピソードだけであり、3つのエピソードの平均は信頼できる指標ではありません。 これを10エピソード以上実行すると、平均は2756です。 100以上のエピソード、平均は約2500です。 これらの平均値を使用した場合にのみ、エージェントが実際に1桁優れたパフォーマンスを発揮し、スペースインベーダーを合理的にうまくプレイできるエージェントがいると快適に結論付けることができます。
ただし、サンプルの複雑さに関して前のセクションで提起された問題を思い出してください。 結局のところ、このSpace Invadersエージェントは何百万ものサンプルを使ってトレーニングします。 実際、このエージェントは、この現在のレベルまでトレーニングするために、4台のTitan X GPUで24時間を必要としました。つまり、適切なトレーニングを行うにはかなりの量の計算が必要でした。 はるかに少ないサンプルで同様に高性能なエージェントをトレーニングできますか? 前の手順で、この質問の調査を開始するのに十分な知識を習得する必要があります。 はるかに単純なモデルとバイアス分散ごとのトレードオフを使用すると、可能性があります。
結論
このチュートリアルでは、ゲーム用のいくつかのボットを構築し、バイアス分散と呼ばれる機械学習の基本概念を探りました。 次の自然な質問は、StarCraft 2などのより複雑なゲームのボットを構築できますか? 結局のところ、これは保留中の研究の質問であり、Google、DeepMind、およびBlizzardの協力者からのオープンソースツールで補完されています。 これらが関心のある問題である場合、現在の問題についてはopen calls for research at OpenAIを参照してください。
このチュートリアルの主なポイントは、バイアスと分散のトレードオフです。 モデルの複雑さの影響を考慮するのは、機械学習の実践者次第です。 非常に複雑なモデルを活用して、過剰な量の計算、サンプル、および時間を重ねることができますが、モデルの複雑さを軽減すると、必要なリソースを大幅に削減できます。