前書き
ニューラルネットワークは、人工知能の多くのサブフィールドの1つであるディープラーニングの方法として使用されます。 これらは、はるかに単純化された形式ではありますが、人間の脳の動作をシミュレートする試みとして約70年前に最初に提案されました。 個々の「ニューロン」は層に接続され、ネットワークを介して信号が伝搬されるときにニューロンがどのように応答するかを決定するために重みが割り当てられます。 以前は、ニューラルネットワークはシミュレートできるニューロンの数が制限されていたため、達成できる学習の複雑さが制限されていました。 しかし、近年では、ハードウェア開発の進歩により、非常に深いネットワークを構築し、膨大なデータセットでトレーニングして、マシンインテリジェンスのブレークスルーを達成することができました。
これらのブレークスルーにより、マシンは特定のタスクを実行する人間の能力に匹敵し、それを超えることができました。 そのようなタスクの1つがオブジェクト認識です。 機械は歴史的に人間の視覚に匹敵することができませんでしたが、ディープラーニングの最近の進歩により、オブジェクト、顔、テキスト、さらには感情を認識することができるニューラルネットワークを構築することが可能になりました。
このチュートリアルでは、オブジェクト認識の小さなサブセクションである数字認識を実装します。 ディープラーニング研究のためにGoogleBrainラボによって開発されたオープンソースのPythonライブラリであるTensorFlowを使用して、0〜9の数字の手描き画像を取得し、ニューラルネットワークを構築してトレーニングし、正しいものを認識して予測します表示される数字のラベル。
このチュートリアルに沿って実践的なディープラーニングやTensorFlowの経験は必要ありませんが、トレーニングとテスト、機能とラベル、最適化、評価などの機械学習の用語と概念にある程度精通していることを前提としています。 これらの概念の詳細については、An Introduction to Machine Learningを参照してください。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
Pythonパッケージをインストールするためのツールであるpip、および仮想環境を作成するためのvenvを含むローカルPython 3 development environment。
[[step-1 -—- configuring-the-project]] ==ステップ1—プロジェクトの構成
認識プログラムを開発する前に、いくつかの依存関係をインストールし、ファイルを保持するワークスペースを作成する必要があります。
Python 3仮想環境を使用して、プロジェクトの依存関係を管理します。 プロジェクトの新しいディレクトリを作成し、新しいディレクトリに移動します。
mkdir tensorflow-demo
cd tensorflow-demo次のコマンドを実行して、このチュートリアルの仮想環境をセットアップします。
python3 -m venv tensorflow-demo
source tensorflow-demo/bin/activate次に、このチュートリアルで使用するライブラリをインストールします。 これらのライブラリの特定のバージョンを使用するには、プロジェクトディレクトリにrequirements.txtファイルを作成して、要件と必要なバージョンを指定します。 requirements.txtファイルを作成します。
touch requirements.txtテキストエディタでファイルを開き、次の行を追加して、Image、NumPy、TensorFlowライブラリとそれらのバージョンを指定します。
requirements.txt
image==1.5.20
numpy==1.14.3
tensorflow==1.4.0ファイルを保存し、エディターを終了します。 次に、次のコマンドでこれらのライブラリをインストールします。
pip install -r requirements.txt依存関係がインストールされたら、プロジェクトの作業を開始できます。
[[step-2 -—- importing-the-mnist-dataset]] ==ステップ2—MNISTデータセットのインポート
このチュートリアルで使用するデータセットはMNISTデータセットと呼ばれ、機械学習コミュニティでは古典的です。 このデータセットは、28x28ピクセルのサイズの手書き数字の画像で構成されています。 データセットに含まれる数字の例を次に示します。
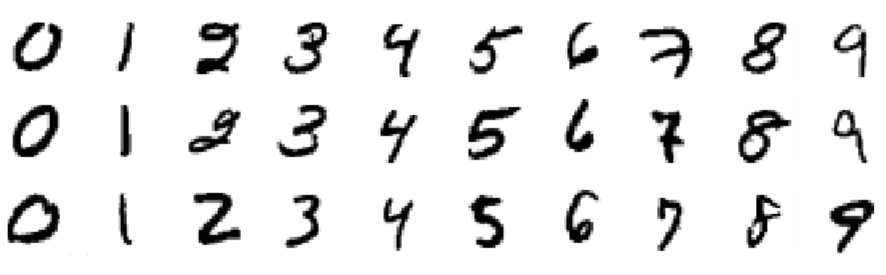
このデータセットを操作するPythonプログラムを作成しましょう。 このチュートリアルでは、すべての作業に1つのファイルを使用します。 main.pyという名前の新しいファイルを作成します。
touch main.py選択したテキストエディタでこのファイルを開き、次のコード行をファイルに追加して、TensorFlowライブラリをインポートします。
main.py
import tensorflow as tf次のコード行をファイルに追加して、MNISTデータセットをインポートし、画像データを変数mnistに格納します。
main.py
...
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # y labels are oh-encodedデータを読み込むときは、one-hot-encodingを使用してラベル(実際に描画された数字など)を表します。 「3」)の画像。 ワンホットエンコーディングでは、バイナリ値のベクトルを使用して数値またはカテゴリ値を表します。 ラベルは0〜9の数字に対応しているため、ベクトルには10の値が含まれており、それぞれの数字が1つに対応しています。 これらの値の1つは1に設定され、ベクトルのそのインデックスの桁を表し、残りは0に設定されます。 たとえば、数字3は、ベクトル[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]を使用して表されます。 インデックス3の値は1として格納されるため、ベクトルは数字3を表します。
実際の画像自体を表すために、28x28ピクセルはサイズが784ピクセルの1Dベクトルに平坦化されます。 画像を構成する784ピクセルのそれぞれは、0〜255の値として保存されます。 画像は白黒のみで表示されるため、これによりピクセルのグレースケールが決まります。 したがって、黒いピクセルは255で、白いピクセルは0で表され、中間のどこかにさまざまなグレーの陰影があります。
mnist変数を使用して、インポートしたばかりのデータセットのサイズを見つけることができます。 3つのサブセットのそれぞれのnum_examplesを見ると、データセットがトレーニング用に55,000画像、検証用に5000画像、テスト用に10,000画像に分割されていることがわかります。 ファイルに次の行を追加します。
main.py
...
n_train = mnist.train.num_examples # 55,000
n_validation = mnist.validation.num_examples # 5000
n_test = mnist.test.num_examples # 10,000データがインポートされたので、次はニューラルネットワークについて考えます。
[[step-3 -—- defining-the-neural-network-architecture]] ==ステップ3—ニューラルネットワークアーキテクチャの定義
ニューラルネットワークのアーキテクチャは、ネットワーク内のレイヤー数、各レイヤー内のユニット数、ユニットがレイヤー間でどのように接続されているかなどの要素を指します。 ニューラルネットワークは人間の脳の働きに大まかに触発されているため、ここではユニットという用語を使用して、生物学的にニューロンと考えるものを表します。 ニューロンが脳の周りに信号を渡すように、ユニットは以前のユニットからいくつかの値を入力として受け取り、計算を実行してから、新しい値を出力として他のユニットに渡します。 これらのユニットは、値を入力するための1つのレイヤーと値を出力するための1つのレイヤーから開始して、ネットワークを形成するために階層化されます。 hidden layerという用語は、入力レイヤーと出力レイヤーの間のすべてのレイヤーに使用されます。 現実の世界から「隠された」もの。
パフォーマンスは、パラメーター、データ、トレーニング期間などのアーキテクチャの関数として考えることができるため、アーキテクチャが異なると劇的に異なる結果が得られます。
次のコード行をファイルに追加して、レイヤーごとのユニット数をグローバル変数に保存します。 これにより、ネットワークアーキテクチャを1か所で変更できます。チュートリアルの最後で、レイヤーとユニットの数がモデルの結果にどのように影響するかを自分でテストできます。
main.py
...
n_input = 784 # input layer (28x28 pixels)
n_hidden1 = 512 # 1st hidden layer
n_hidden2 = 256 # 2nd hidden layer
n_hidden3 = 128 # 3rd hidden layer
n_output = 10 # output layer (0-9 digits)次の図は、設計したアーキテクチャの視覚化を示しています。各レイヤーは周囲のレイヤーに完全に接続されています。
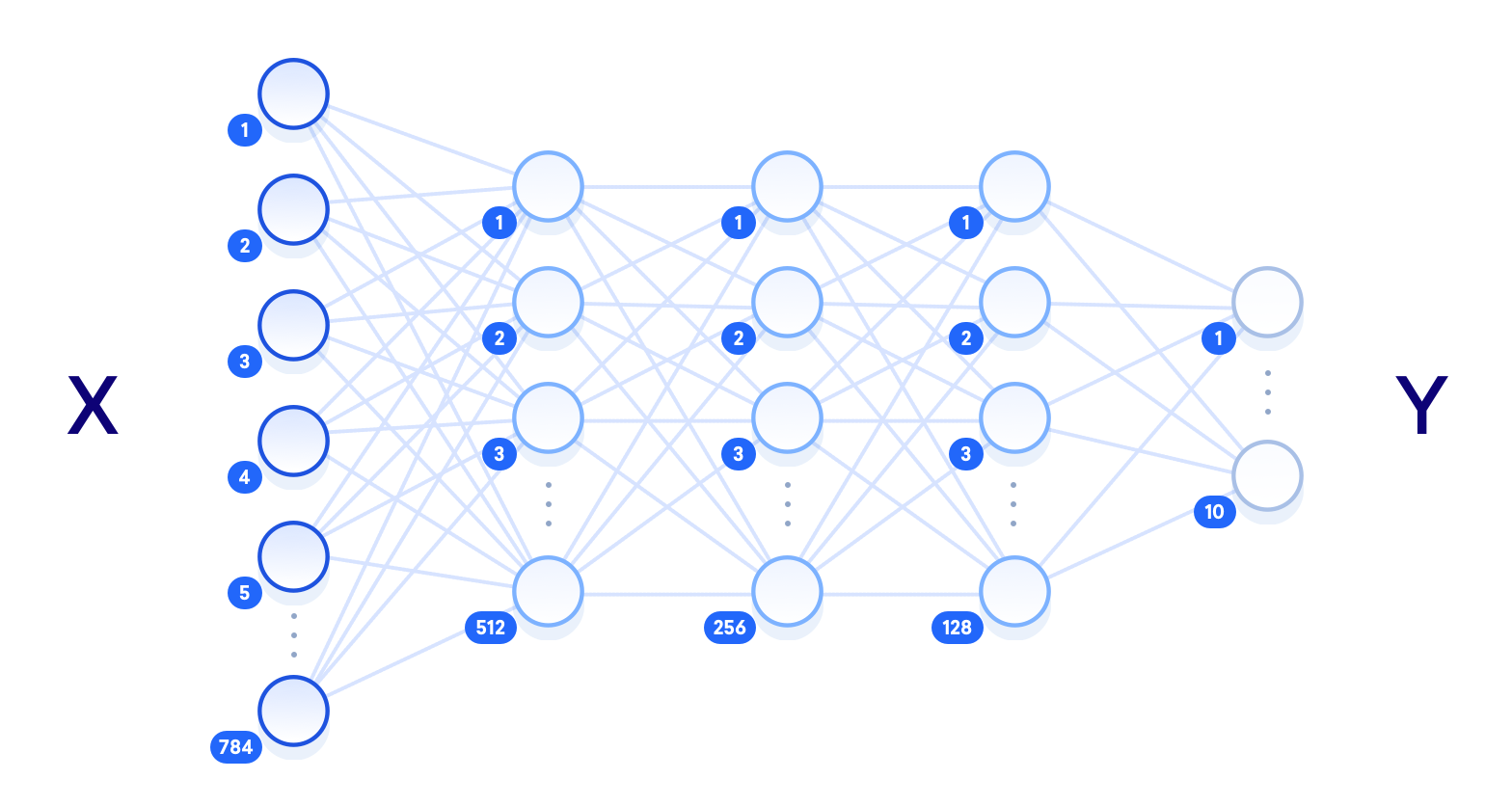
「ディープニューラルネットワーク」という用語は隠れ層の数に関連し、「浅い」は通常1つの隠れ層を意味し、「深い」は複数の隠れ層を指します。 十分なトレーニングデータが与えられた場合、十分な数のユニットを備えた浅いニューラルネットワークは、理論的には、ディープニューラルネットワークが可能なあらゆる機能を表すことができるはずです。 しかし、より深いディープニューラルネットワークを使用して、指数関数的により隠れたユニットを持つ浅いネットワークを必要とする同じタスクを達成する方が、多くの場合、計算効率が高くなります。 また、浅いニューラルネットワークは、しばしば過剰適合に遭遇します。この場合、ネットワークは、見たトレーニングデータを基本的に記憶し、知識を新しいデータに一般化することはできません。 これが、ディープニューラルネットワークがより一般的に使用される理由です。生の入力データと出力ラベルの間の複数のレイヤーにより、ネットワークはさまざまな抽象化レベルで機能を学習でき、ネットワーク自体をより一般化できるようになります。
ここで定義する必要があるニューラルネットワークの他の要素は、ハイパーパラメーターです。 トレーニング中に更新されるパラメーターとは異なり、これらの値は最初に設定され、プロセス全体を通して一定のままです。 ファイルで、次の変数と値を設定します。
main.py
...
learning_rate = 1e-4
n_iterations = 1000
batch_size = 128
dropout = 0.5学習率は、学習プロセスの各ステップでパラメーターが調整される度合いを表します。 これらの調整は、トレーニングの重要な要素です。ネットワークを通過するたびに、損失を減らすために重みをわずかに調整します。 ラーニングレートを大きくすると、収束が速くなりますが、最適値が更新されるとオーバーシュートする可能性もあります。 反復回数とは、トレーニングステップを何回行うかを指し、バッチサイズとは、各ステップで使用するトレーニングサンプルの数を指します。 dropout変数は、いくつかのユニットをランダムに削除するしきい値を表します。 最終的な隠れ層でdropoutを使用して、各ユニットがすべてのトレーニングステップで排除される可能性を50%にします。 これは、過剰適合の防止に役立ちます。
これで、ニューラルネットワークのアーキテクチャと、学習プロセスに影響を与えるハイパーパラメーターを定義しました。 次のステップは、ネットワークをTensorFlowグラフとして構築することです。
[[step-4 -—- building-the-tensorflow-graph]] ==ステップ4—TensorFlowグラフの構築
ネットワークを構築するには、ネットワークをTensorFlowが実行する計算グラフとして設定します。 TensorFlowのコアコンセプトは、配列またはリストに似たデータ構造であるtensorです。 初期化され、グラフを通過するときに操作され、学習プロセスを通じて更新されます。
まず、3つのテンソルをplaceholdersとして定義します。これは、後で値をフィードするテンソルです。 以下をファイルに追加します。
main.py
...
X = tf.placeholder("float", [None, n_input])
Y = tf.placeholder("float", [None, n_output])
keep_prob = tf.placeholder(tf.float32)宣言時に指定する必要がある唯一のパラメーターは、フィードするデータのサイズです。 Xの場合、[None, 784]の形状を使用します。ここで、Noneは任意の量を表します。これは、未定義の数の784ピクセルの画像をフィードするためです。 Yの形状は[None, 10]です。これは、10の可能なクラスを使用して、未定義の数のラベル出力に使用するためです。 keep_probテンソルはドロップアウト率を制御するために使用され、トレーニングに両方とも同じテンソルを使用するため(dropoutが%(に設定されている場合)、不変変数ではなくプレースホルダーとして初期化します。 t7)s)およびテスト(dropoutが1.0に設定されている場合)。
ネットワークがトレーニングプロセスで更新するパラメーターはweightとbiasの値であるため、これらの場合、空のプレースホルダーではなく初期値を設定する必要があります。 これらの値は、ユニットの接続の強さを表すニューロンの活性化関数で使用されるため、基本的にネットワークが学習を行う場所です。
値はトレーニング中に最適化されるため、今のところはゼロに設定できます。 ただし、実際には初期値はモデルの最終的な精度に大きな影響を与えます。 切り捨てられた正規分布のランダムな値を重みに使用します。 それらをゼロに近づけて、正または負の方向に調整でき、わずかに異なるようにして、異なるエラーを生成します。 これにより、モデルが有用なものを学習することが保証されます。 以下の行を追加してください。
main.py
...
weights = {
'w1': tf.Variable(tf.truncated_normal([n_input, n_hidden1], stddev=0.1)),
'w2': tf.Variable(tf.truncated_normal([n_hidden1, n_hidden2], stddev=0.1)),
'w3': tf.Variable(tf.truncated_normal([n_hidden2, n_hidden3], stddev=0.1)),
'out': tf.Variable(tf.truncated_normal([n_hidden3, n_output], stddev=0.1)),
}バイアスについては、小さな定数値を使用して、テンソルが初期段階でアクティブになり、伝播に寄与することを保証します。 重みとバイアステンソルは、アクセスしやすいように辞書オブジェクトに保存されます。 このコードをファイルに追加して、バイアスを定義します。
main.py
...
biases = {
'b1': tf.Variable(tf.constant(0.1, shape=[n_hidden1])),
'b2': tf.Variable(tf.constant(0.1, shape=[n_hidden2])),
'b3': tf.Variable(tf.constant(0.1, shape=[n_hidden3])),
'out': tf.Variable(tf.constant(0.1, shape=[n_output]))
}次に、テンソルを操作する操作を定義して、ネットワークのレイヤーをセットアップします。 これらの行をファイルに追加します。
main.py
...
layer_1 = tf.add(tf.matmul(X, weights['w1']), biases['b1'])
layer_2 = tf.add(tf.matmul(layer_1, weights['w2']), biases['b2'])
layer_3 = tf.add(tf.matmul(layer_2, weights['w3']), biases['b3'])
layer_drop = tf.nn.dropout(layer_3, keep_prob)
output_layer = tf.matmul(layer_3, weights['out']) + biases['out']各非表示レイヤーは、前のレイヤーの出力と現在のレイヤーの重みで行列乗算を実行し、これらの値にバイアスを追加します。 最後の隠れ層で、keep_prob値0.5を使用してドロップアウト操作を適用します。
グラフ作成の最後のステップは、最適化する損失関数を定義することです。 TensorFlowプログラムでよく使用される損失関数はcross-entropyで、log-lossとも呼ばれ、2つの確率分布(予測とラベル)の差を定量化します。 完全な分類では、クロスエントロピーが0になり、損失が完全に最小化されます。
また、損失関数を最小化するために使用される最適化アルゴリズムを選択する必要があります。 gradient descent optimizationという名前のプロセスは、負の(降順)方向の勾配に沿って反復ステップを実行することにより、関数の(極)最小値を見つけるための一般的な方法です。 TensorFlowにすでに実装されている勾配降下最適化アルゴリズムにはいくつかの選択肢があります。このチュートリアルでは、Adam optimizerを使用します。 これは、勾配の指数関数的に加重平均を計算し、それを調整に使用することにより、運動量を使用してプロセスを高速化することにより、勾配降下の最適化を拡張します。 ファイルに次のコードを追加します。
main.py
...
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
labels=Y, logits=output_layer
))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)ネットワークを定義し、TensorFlowで構築しました。 次のステップでは、グラフを介してデータをフィードしてトレーニングし、実際に何かを学んだことをテストします。
[[ステップ-5 ---トレーニングとテスト]] ==ステップ5—トレーニングとテスト
トレーニングプロセスには、グラフを通してトレーニングデータセットを供給し、損失関数を最適化することが含まれます。 ネットワークがさらに多くのトレーニングイメージを反復処理するたびに、パラメータを更新して損失を減らし、表示される数字をより正確に予測します。 テストプロセスでは、トレーニング済みのグラフを介してテストデータセットを実行し、正確に予測される画像の数を追跡して、精度を計算できるようにします。
トレーニングプロセスを開始する前に、精度を評価する方法を定義して、トレーニング中にデータのミニバッチに印刷できるようにします。 これらの印刷されたステートメントにより、最初の反復から最後の反復まで、損失が減少し、精度が向上することを確認できます。また、一貫性のある最適な結果に到達するのに十分な反復を実行したかどうかを追跡できます。
main.py
...
correct_pred = tf.equal(tf.argmax(output_layer, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))correct_predでは、arg_max関数を使用して、output_layer(予測)とY(ラベル)を見て、どの画像が正しく予測されているかを比較します。これをBooleansのリストとして返すequal関数。 次に、このリストを浮動小数点数にキャストし、平均を計算して合計精度スコアを取得できます。
これで、グラフを実行するためのセッションを初期化する準備が整いました。 このセッションでは、トレーニングサンプルをネットワークにフィードし、トレーニング後、同じグラフに新しいテストサンプルをフィードして、モデルの精度を決定します。 次のコード行をファイルに追加します。
main.py
...
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)ディープラーニングのトレーニングプロセスの本質は、損失関数を最適化することです。 ここでは、画像の予測ラベルと画像の真のラベルとの差を最小限に抑えることを目指しています。 このプロセスには、設定された反復回数だけ繰り返される4つのステップが含まれます。
-
ネットワークを介して値を転送する
-
損失を計算する
-
ネットワークを通じて後方に値を伝播する
-
パラメーターを更新する
各トレーニングステップで、次のステップの損失を減らすために、パラメータがわずかに調整されます。 学習が進むにつれて、損失が減少するはずです。最終的に、トレーニングを停止し、新しいデータをテストするためのモデルとしてネットワークを使用できます。
このコードをファイルに追加します。
main.py
...
# train on mini batches
for i in range(n_iterations):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={
X: batch_x, Y: batch_y, keep_prob: dropout
})
# print loss and accuracy (per minibatch)
if i % 100 == 0:
minibatch_loss, minibatch_accuracy = sess.run(
[cross_entropy, accuracy],
feed_dict={X: batch_x, Y: batch_y, keep_prob: 1.0}
)
print(
"Iteration",
str(i),
"\t| Loss =",
str(minibatch_loss),
"\t| Accuracy =",
str(minibatch_accuracy)
)ネットワークを介して画像のミニバッチをフィードする各トレーニングステップを100回繰り返した後、そのバッチの損失と精度を出力します。 値はモデル全体ではなくバッチごとであるため、ここでは損失の減少と精度の向上を期待しないでください。 個別にフィードするのではなく、画像のミニバッチを使用して、トレーニングプロセスを高速化し、ネットワークがパラメーターを更新する前にさまざまな例を確認できるようにします。
トレーニングが完了すると、テストイメージでセッションを実行できます。 今回は、1.0のkeep_probドロップアウト率を使用して、すべてのユニットがテストプロセスでアクティブであることを確認します。
このコードをファイルに追加します。
main.py
...
test_accuracy = sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1.0})
print("\nAccuracy on test set:", test_accuracy)プログラムを実行し、ニューラルネットワークがこれらの手書き数字をどれだけ正確に認識できるかを確認します。 main.pyファイルを保存し、ターミナルで次のコマンドを実行してスクリプトを実行します。
python main.py次のような出力が表示されますが、個々の損失と精度の結果はわずかに異なる場合があります。
OutputIteration 0 | Loss = 3.67079 | Accuracy = 0.140625
Iteration 100 | Loss = 0.492122 | Accuracy = 0.84375
Iteration 200 | Loss = 0.421595 | Accuracy = 0.882812
Iteration 300 | Loss = 0.307726 | Accuracy = 0.921875
Iteration 400 | Loss = 0.392948 | Accuracy = 0.882812
Iteration 500 | Loss = 0.371461 | Accuracy = 0.90625
Iteration 600 | Loss = 0.378425 | Accuracy = 0.882812
Iteration 700 | Loss = 0.338605 | Accuracy = 0.914062
Iteration 800 | Loss = 0.379697 | Accuracy = 0.875
Iteration 900 | Loss = 0.444303 | Accuracy = 0.90625
Accuracy on test set: 0.9206モデルの精度を向上させるため、またはハイパーパラメーターの調整の影響についてさらに学習するために、学習率、ドロップアウトしきい値、バッチサイズ、および反復回数の変更の効果をテストできます。 また、隠れ層のユニット数を変更し、隠れ層自体の量を変更して、異なるアーキテクチャがモデルの精度をどのように増減させるかを確認できます。
ネットワークが実際に手描きの画像を認識していることを示すために、独自の単一の画像でテストしてみましょう。
ローカルマシンを使用していて、独自の手書き番号を使用したい場合は、グラフィックエディタを使用して、28x28ピクセルの数字の独自の画像を作成できます。 それ以外の場合は、curlを使用して、次のサンプルテストイメージをサーバーまたはコンピューターにダウンロードできます。
curl -O https://raw.githubusercontent.com/do-community/tensorflow-digit-recognition/master/test_img.pngエディターでmain.pyファイルを開き、ファイルの先頭に次のコード行を追加して、画像操作に必要な2つのライブラリをインポートします。
main.py
import numpy as np
from PIL import Image
...次に、ファイルの最後に、次のコード行を追加して、手書き数字のテストイメージを読み込みます。
main.py
...
img = np.invert(Image.open("test_img.png").convert('L')).ravel()Imageライブラリのopen関数は、3つのRGBカラーチャネルとアルファ透明度を含む4D配列としてテスト画像をロードします。 これは、TensorFlowを使用してデータセットを読み込むときに以前に使用した表現とは異なるため、形式に合わせて追加の作業を行う必要があります。
まず、convert関数とLパラメータを使用して、4DRGBA表現を1つのグレースケールカラーチャネルに縮小します。 これをnumpy配列として格納し、np.invertを使用して反転します。これは、現在の行列が黒を0、白を255として表すのに対し、逆が必要なためです。 最後に、ravelを呼び出して配列をフラット化します。
画像データが正しく構成されたので、以前と同じ方法でセッションを実行できますが、今回はテスト用に単一の画像のみをフィードします。
次のコードをファイルに追加して、画像をテストし、出力されたラベルを印刷します。
main.py
...
prediction = sess.run(tf.argmax(output_layer, 1), feed_dict={X: [img]})
print ("Prediction for test image:", np.squeeze(prediction))np.squeeze関数は、配列から単一の整数を返すために予測で呼び出されます(つまり、 [2]から2)に移動します。 結果の出力は、ネットワークがこの画像を数字2として認識したことを示しています。
OutputPrediction for test image: 2より複雑な画像(たとえば、他の数字のように見える数字、または不十分にまたは誤って描かれた数字)を使用してネットワークをテストして、運命を確認できます。
結論
このチュートリアルでは、MNISTデータセットを約92%の精度で分類するためにニューラルネットワークを正常にトレーニングし、独自の画像でテストしました。 現在の最先端の研究では、畳み込み層を含むより複雑なネットワークアーキテクチャを使用して、この同じ問題について約99%を達成しています。 これらは、すべてのピクセルを784ユニットの1つのベクトルにフラット化する方法とは異なり、イメージの2D構造を使用してコンテンツをより適切に表現します。 このトピックの詳細については、TensorFlow websiteを参照してください。また、MNIST websiteで最も正確な結果を詳述している研究論文を参照してください。
ニューラルネットワークを構築してトレーニングする方法がわかったので、この実装を自分のデータで試して使用したり、Google StreetView House NumbersやCIFAR-10データセットなどの他の一般的なデータセットでテストしたりできます。より一般的な画像認識。