前書き
Machine learningは、コンピュータサイエンス、人工知能、統計学の研究分野です。 機械学習の焦点は、パターンを学習し、データから予測を行うアルゴリズムを訓練することです。 コンピューターを使用して意思決定プロセスを自動化できるため、機械学習は特に価値があります。
機械学習アプリケーションはどこにでもあります。 NetflixとAmazonは、機械学習を使用して新しい製品の推奨事項を作成します。 銀行は機械学習を使用してクレジットカード取引の不正行為を検出し、医療企業は機械学習を使用して患者を監視、評価、および診断し始めています。
このチュートリアルでは、Pythonの機械学習ツールであるScikit-learnを使用して、Pythonで簡単な機械学習アルゴリズムを実装します。 乳がんの腫瘍情報のデータベースを使用して、腫瘍が悪性か良性かを予測するNaive Bayes (NB)分類子を使用します。
このチュートリアルの終わりまでに、Pythonで独自の機械学習モデルを構築する方法を理解できます。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
Python 3とコンピューターにセットアップされたローカルプログラミング環境。 appropriate installation and set up guide for your operating systemに従って、これを構成できます。
-
Pythonを初めて使用する場合は、How to Code in Python 3を調べて、言語に慣れることができます。
-
-
このチュートリアルでは、virtualenvにJupyter Notebookがインストールされています。 Jupyter Notebookは、機械学習実験を実行する際に非常に役立ちます。 短いコードブロックを実行して結果をすばやく確認できるため、コードのテストとデバッグが簡単になります。
[[step-1 -—- importing-scikit-learn]] ==ステップ1—Scikit-learnのインポート
まず、PythonモジュールScikit-learnをインストールします。これは、Python用の最もよく文書化された機械学習ライブラリの1つです。
コーディングプロジェクトを開始するために、Python 3プログラミング環境をアクティブにしましょう。 環境が存在するディレクトリにいることを確認し、次のコマンドを実行します。
. my_env/bin/activateプログラミング環境をアクティブにして、Scikit-learnモジュールが既にインストールされているかどうかを確認します。
python -c "import sklearn"sklearnがインストールされている場合、このコマンドはエラーなしで完了します。 インストールされていない場合は、次のエラーメッセージが表示されます。
OutputTraceback (most recent call last): File "", line 1, in ImportError: No module named 'sklearn' エラーメッセージは、sklearnがインストールされていないことを示しているため、pipを使用してライブラリをダウンロードします。
pip install scikit-learn[alldeps]インストールが完了したら、Jupyter Notebookを起動します。
jupyter notebookJupyterで、ML Tutorialという新しいPythonノートブックを作成します。 ノートブックの最初のセルで、importはsklearnモジュールです。
MLチュートリアル
import sklearnノートブックは次の図のようになります。

ノートブックにsklearnがインポートされたので、機械学習モデルのデータセットの操作を開始できます。
[[step-2 -—- importing-scikit-learn-39-s-dataset]] ==ステップ2—Scikit-learnのデータセットをインポートする
このチュートリアルで使用するデータセットはBreast Cancer Wisconsin Diagnostic Databaseです。 データセットには、乳がん腫瘍に関するさまざまな情報と、malignantまたはbenignの分類ラベルが含まれています。 データセットには、569の腫瘍に関する569instancesまたはデータがあり、30attributesまたは腫瘍の半径、テクスチャ、滑らかさ、面積などの特徴に関する情報が含まれています。
このデータセットを使用して、機械学習モデルを構築し、腫瘍情報を使用して、腫瘍が悪性か良性かを予測します。
Scikit-learnには、Pythonにロードできるさまざまなデータセットがインストールされており、必要なデータセットが含まれています。 データセットをインポートおよびロードします。
MLチュートリアル
...
from sklearn.datasets import load_breast_cancer
# Load dataset
data = load_breast_cancer()datavariableは、dictionaryのように機能するPythonオブジェクトを表します。 考慮すべき重要な辞書キーは、分類ラベル名(target_names)、実際のラベル(target)、属性/機能名(feature_names)、および属性(data)s)。
属性は、分類子の重要な部分です。 属性は、データの性質に関する重要な特性をキャプチャします。 予測しようとしているラベル(悪性腫瘍と良性腫瘍)を考えると、考えられる有用な属性には、腫瘍のサイズ、半径、テクスチャーが含まれます。
重要な情報セットごとに新しい変数を作成し、データを割り当てます。
MLチュートリアル
...
# Organize our data
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']これで、情報のセットごとにlistsが作成されました。 データセットの理解を深めるために、クラスラベル、最初のデータインスタンスのラベル、フィーチャ名、および最初のデータインスタンスのフィーチャ値を印刷して、データを見てみましょう。
MLチュートリアル
...
# Look at our data
print(label_names)
print(labels[0])
print(feature_names[0])
print(features[0])コードを実行すると、次の結果が表示されます。
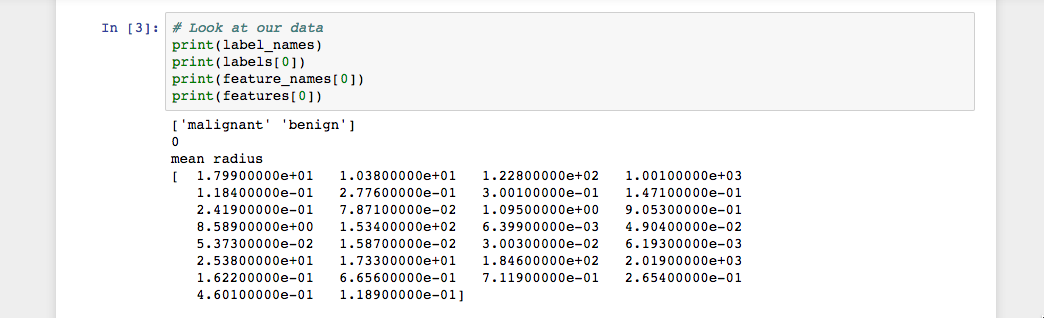
画像が示すように、クラス名はmalignantとbenignであり、これらは0と1のバイナリ値にマップされます。ここで0は悪性腫瘍を表します。 1は良性腫瘍を表します。 したがって、最初のデータインスタンスは、mean radiusが1.79900000e+01である悪性腫瘍です。
データが読み込まれたので、データを操作して機械学習分類器を作成できます。
[[step-3 -—- organizing-data-into-sets]] ==ステップ3—データをセットに整理する
分類器のパフォーマンスを評価するには、不可視データでモデルを常にテストする必要があります。 したがって、モデルを作成する前に、データをtraining setとtest setの2つの部分に分割してください。
トレーニングセットを使用して、開発段階でモデルをトレーニングおよび評価します。 次に、訓練されたモデルを使用して、見えないテストセットの予測を行います。 このアプローチにより、モデルのパフォーマンスと堅牢性を把握できます。
幸い、sklearnにはtrain_test_split()という関数があり、データをこれらのセットに分割します。 関数をインポートし、それを使用してデータを分割します。
MLチュートリアル
...
from sklearn.model_selection import train_test_split
# Split our data
train, test, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=42)この関数は、test_sizeパラメータを使用してデータをランダムに分割します。 この例では、元のデータセットの33%を表すテストセット(test)があります。 残りのデータ(train)は、トレーニングデータを構成します。 また、両方のトレイン/テスト変数のラベルがあります。 train_labelsおよびtest_labels。
これで、最初のモデルのトレーニングに進むことができます。
[[ステップ-4 -—-モデルの構築と評価]] ==ステップ4—モデルの構築と評価
機械学習には多くのモデルがあり、各モデルには長所と短所があります。 このチュートリアルでは、通常は二項分類タスクでうまく機能する単純なアルゴリズム、つまりNaive Bayes (NB)に焦点を当てます。
まず、GaussianNBモジュールをインポートします。 次に、GaussianNB()関数を使用してモデルを初期化し、gnb.fit()を使用してモデルをデータに適合させてモデルをトレーニングします。
MLチュートリアル
...
from sklearn.naive_bayes import GaussianNB
# Initialize our classifier
gnb = GaussianNB()
# Train our classifier
model = gnb.fit(train, train_labels)モデルをトレーニングした後、トレーニングしたモデルを使用して、predict()関数を使用してテストセットの予測を行うことができます。 predict()関数は、テストセット内の各データインスタンスの予測の配列を返します。 その後、予測を印刷して、モデルが決定した内容を把握できます。
testを設定してpredict()関数を使用し、結果を出力します。
MLチュートリアル
...
# Make predictions
preds = gnb.predict(test)
print(preds)コードを実行すると、次の結果が表示されます。
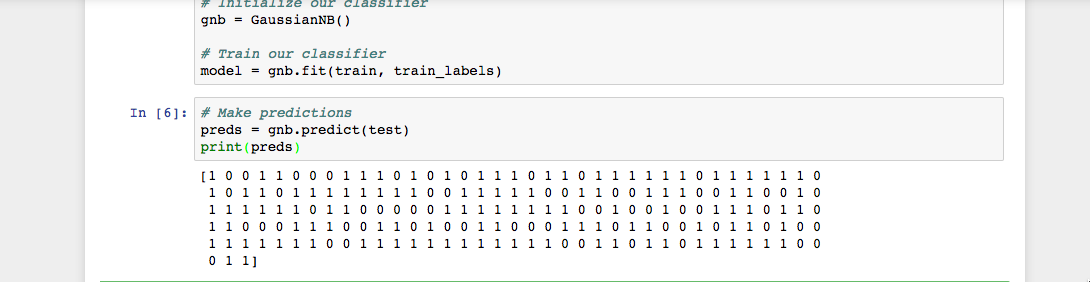
Jupyter Notebookの出力に示されているように、predict()関数は、腫瘍クラスの予測値を表す `0`と` 1`の配列を返しました(悪性対。 良性)。
予測ができたので、分類子のパフォーマンスを評価しましょう。
[[step-5 -—- evaluating-the-model-39-s-accuracy]] ==ステップ5—モデルの精度を評価する
真のクラスラベルの配列を使用して、2つの配列を比較することでモデルの予測値の精度を評価できます(test_labelsと preds)。 sklearn関数accuracy_score()を使用して、機械学習分類器の精度を決定します。
MLチュートリアル
...
from sklearn.metrics import accuracy_score
# Evaluate accuracy
print(accuracy_score(test_labels, preds))次の結果が表示されます。

出力からわかるように、NB分類器の精度は94.15%です。 これは、分類器が腫瘍が悪性または良性であるかどうかについて正しい予測をすることができる時間の94.15パーセントを意味します。 これらの結果は、30の属性の機能セットが腫瘍クラスの良い指標であることを示唆しています。
最初の機械学習分類器を正常に構築しました。 ノートブックまたはスクリプトの先頭にすべてのimportステートメントを配置して、コードを再編成しましょう。 コードの最終バージョンは次のようになります。
MLチュートリアル
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# Load dataset
data = load_breast_cancer()
# Organize our data
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
# Look at our data
print(label_names)
print('Class label = ', labels[0])
print(feature_names)
print(features[0])
# Split our data
train, test, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=42)
# Initialize our classifier
gnb = GaussianNB()
# Train our classifier
model = gnb.fit(train, train_labels)
# Make predictions
preds = gnb.predict(test)
print(preds)
# Evaluate accuracy
print(accuracy_score(test_labels, preds))これで、引き続きコードを操作して、分類器のパフォーマンスをさらに向上できるかどうかを確認できます。 機能のさまざまなサブセットを試してみるか、まったく異なるアルゴリズムを試すこともできます。 機械学習のアイデアについては、Scikit-learn’s websiteを確認してください。
結論
このチュートリアルでは、Pythonで機械学習分類子を作成する方法を学びました。 Scikit-learnを使用して、Pythonでデータの読み込み、データの整理、トレーニング、予測、および機械学習分類子の評価を行うことができます。 このチュートリアルの手順は、Pythonで独自のデータを操作するプロセスを容易にするのに役立ちます。