著者は、Write for DOnationsプログラムの一部として寄付を受け取るためにGirls Who Codeを選択しました。
前書き
コンピュータービジョンは、画像やビデオから高次の理解を引き出すことを目的としたコンピューターサイエンスのサブフィールドです。 このフィールドには、オブジェクト検出、画像復元(マトリックス補完)、オプティカルフローなどのタスクが含まれます。 コンピュータービジョンは、自動運転車のプロトタイプ、従業員のいない食料品店、楽しいSnapchatフィルター、モバイルデバイスの顔認証システムなどのテクノロジーを強化します。
このチュートリアルでは、事前学習済みのモデルを使用してSnapchat風のドッグフィルターを構築する際のコンピュータービジョンについて説明します。 Snapchatに慣れていない人のために、このフィルターはあなたの顔を検出し、犬のマスクを重ねます。 次に、顔の感情分類器をトレーニングして、幸せの場合はコーギー、悲しい場合はパグなど、感情に基づいて犬のマスクを選択できるようにします。 途中で、通常の最小二乗法とコンピュータービジョンの両方で関連する概念を探り、機械学習の基礎を学びます。

チュートリアルを進める際には、コンピュータービジョンライブラリであるOpenCV、線形代数ユーティリティ用のnumpy、およびプロット用のmatplotlibを使用します。 また、コンピュータービジョンアプリケーションを作成するときに、次の概念を適用します。
-
回帰および分類手法としての通常の最小二乗。
-
確率的勾配ニューラルネットワークの基礎。
このチュートリアルを完了する必要はありませんが、これらの数学的概念に精通していれば、より詳細な説明のいくつかを理解しやすくなります。
-
基本的な線形代数の概念:スカラー、ベクトル、および行列。
-
基礎計算:導関数を取る方法。
このチュートリアルの完全なコードはhttps://github.com/do-community/emotion-based-dog-filterにあります。
始めましょう。
前提条件
このチュートリアルを完了するには、次のものが必要です。
-
1 GB以上のRAMを備えたPython 3のローカル開発環境。 How To Install and Set Up a Local Programming Environment for Python 3に従って、必要なすべてを構成できます。
-
リアルタイムの画像検出を行うための機能するウェブカメラ。
[[step-1 -—- creating-the-project-and-installing-dependencies]] ==ステップ1—プロジェクトの作成と依存関係のインストール
このプロジェクトのワークスペースを作成し、必要な依存関係をインストールしましょう。 ワークスペースをDogFilterと呼びます。
mkdir ~/DogFilterDogFilterディレクトリに移動します。
cd ~/DogFilter次に、プロジェクト用の新しいPython仮想環境を作成します。
python3 -m venv dogfilter環境をアクティブにします。
source dogfilter/bin/activateプロンプトが変わり、環境がアクティブであることを示します。 次に、このチュートリアルで使用するPythonのディープラーニングフレームワークであるPyTorchをインストールします。 インストールプロセスは、使用しているオペレーティングシステムによって異なります。
macOSで、次のコマンドを使用してPytorchをインストールします。
python -m pip install torch==0.4.1 torchvision==0.2.1Linuxでは、次のコマンドを使用します。
pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp35-cp35m-linux_x86_64.whl
pip install torchvisionWindowsの場合、次のコマンドを使用してPytorchをインストールします。
pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp35-cp35m-win_amd64.whl
pip install torchvision次に、OpenCVとnumpyのパッケージ済みバイナリをインストールします。これらは、それぞれコンピュータビジョンライブラリと線形代数ライブラリです。 前者は画像回転などのユーティリティを提供し、後者は行列反転などの線形代数ユーティリティを提供します。
python -m pip install opencv-python==3.4.3.18 numpy==1.14.5最後に、このチュートリアルで使用する画像を保持するアセットのディレクトリを作成します。
mkdir assets依存関係がインストールされたら、フィルターの最初のバージョンである顔検出器を作成しましょう。
[[step-2 -—- building-a-face-detector]] ==ステップ2—顔検出器の構築
最初の目的は、画像内のすべての顔を検出することです。 単一の画像を受け入れ、ボックスで輪郭が描かれた注釈付き画像を出力するスクリプトを作成します。
幸い、独自の顔検出ロジックを作成する代わりに、pre-trained modelsを使用できます。 モデルをセットアップしてから、事前に訓練されたパラメーターをロードします。 OpenCVは両方を提供することでこれを簡単にします。
OpenCVは、ソースコードでモデルパラメーターを提供します。 ただし、これらのパラメーターを使用するには、ローカルにインストールされたOpenCVへの絶対パスが必要です。 その絶対パスは異なる可能性があるため、代わりに独自のコピーをダウンロードして、assetsフォルダーに配置します。
wget -O assets/haarcascade_frontalface_default.xml https://github.com/opencv/opencv/raw/master/data/haarcascades/haarcascade_frontalface_default.xml-Oオプションは、宛先をassets/haarcascade_frontalface_default.xmlとして指定します。 2番目の引数はソースURLです。
次の画像では、Pexels(CC0、link to original image)からすべての顔を検出します。

まず、画像をダウンロードします。 次のコマンドは、ダウンロードしたイメージをassetsフォルダーにchildren.pngとして保存します。
wget -O assets/children.png https://assets.digitalocean.com/articles/python3_dogfilter/CfoBWbF.png検出アルゴリズムが機能することを確認するために、個々の画像でそれを実行し、結果の注釈付き画像をディスクに保存します。 これらの注釈付き結果用にoutputsフォルダーを作成します。
mkdir outputs次に、顔検出器用のPythonスクリプトを作成します。 nanoまたはお気に入りのテキストエディタを使用してファイルstep_1_face_detectを作成します。
nano step_2_face_detect.py次のコードをファイルに追加します。 このコードは、画像ユーティリティと顔分類器を含むOpenCVをインポートします。 残りのコードは、典型的なPythonプログラムの定型文です。
step_2_face_detect.py
"""Test for face detection"""
import cv2
def main():
pass
if __name__ == '__main__':
main()次に、main関数のpassを、assetsフォルダーにダウンロードしたOpenCVパラメーターを使用して顔分類子を初期化する次のコードに置き換えます。
step_2_face_detect.py
def main():
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")次に、この行を追加して、イメージchildren.pngをロードします。
step_2_face_detect.py
frame = cv2.imread('assets/children.png')次に、このコードを追加して、画像を白黒に変換します。これは、分類器が白黒画像でトレーニングされたためです。 これを実現するために、グレースケールに変換してからヒストグラムを離散化します。
step_2_face_detect.py
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)次に、OpenCVのdetectMultiScale関数を使用して、画像内のすべての顔を検出します。
step_2_face_detect.py
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)-
scaleFactorは、各次元に沿って画像がどれだけ縮小されるかを指定します。 -
minNeighborsは、候補長方形を保持する必要がある隣接する長方形の数を示します。 -
minSizeは、検出されたオブジェクトの最小許容サイズです。 これより小さいオブジェクトは破棄されます。
戻り値の型はtuplesのリストであり、各タプルには、長方形の最小x、最小y、幅、高さをこの順序で示す4つの数値があります。
検出されたすべてのオブジェクトを反復処理し、cv2.rectangleを使用して画像上に緑色で描画します。
step_2_face_detect.py
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)-
2番目と3番目の引数は、長方形の反対側の角です。
-
4番目の引数は、使用する色です。
(0, 255, 0)は、RGB色空間の緑に対応します。 -
最後の引数は、行の幅を示します。
最後に、バウンディングボックスを含む画像をoutputs/children_detected.pngの新しいファイルに書き込みます。
step_2_face_detect.py
cv2.imwrite('outputs/children_detected.png', frame)完成したスクリプトは次のようになります。
step_2_face_detect.py
"""Tests face detection for a static image."""
import cv2
def main():
# initialize front face classifier
cascade = cv2.CascadeClassifier(
"assets/haarcascade_frontalface_default.xml")
frame = cv2.imread('assets/children.png')
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite('outputs/children_detected.png', frame)
if __name__ == '__main__':
main()ファイルを保存して、エディターを終了します。 次に、スクリプトを実行します。
python step_2_face_detect.pyoutputs/children_detected.pngを開きます。 ボックスで囲まれた顔を示す次の画像が表示されます。

この時点で、作業中の顔検出器があります。 入力として画像を受け入れ、画像内のすべての顔の周りに境界ボックスを描画し、注釈付き画像を出力します。 次に、この同じ検出をライブカメラフィードに適用します。
[[step-3 -—- linking-the-camera-feed]] ==ステップ3—カメラフィードのリンク
次の目的は、コンピューターのカメラを顔検出器にリンクすることです。 静止画像で顔を検出する代わりに、コンピューターのカメラからすべての顔を検出します。 カメラ入力を収集し、すべての顔を検出して注釈を付け、注釈付きの画像をユーザーに表示します。 ステップ2のスクリプトから続行するため、そのスクリプトを複製することから始めます。
cp step_2_face_detect.py step_3_camera_face_detect.py次に、エディターで新しいスクリプトを開きます。
nano step_3_camera_face_detect.py公式のOpenCVドキュメントのこのtest scriptのいくつかの要素を使用して、main関数を更新します。 コンピューターのカメラからライブフィードをキャプチャするように設定されているVideoCaptureオブジェクトを初期化することから始めます。 これをmain関数の先頭、関数内の他のコードの前に配置します。
step_3_camera_face_detect.py
def main():
cap = cv2.VideoCapture(0)
...frameを定義する行から始めて、既存のすべてのコードをインデントし、すべてのコードをwhileループに配置します。
step_3_camera_face_detect.py
while True:
frame = cv2.imread('assets/children.png')
...
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imwrite('outputs/children_detected.png', frame)whileループの開始時にframeを定義する行を置き換えます。 ディスク上の画像から読み取る代わりに、カメラから読み取ります。
step_3_camera_face_detect.py
while True:
# frame = cv2.imread('assets/children.png') # DELETE ME
# Capture frame-by-frame
ret, frame = cap.read()whileループの最後で行cv2.imwrite(...)を置き換えます。 画像をディスクに書き込む代わりに、注釈付きの画像をユーザーの画面に表示します。
step_3_camera_face_detect.py
cv2.imwrite('outputs/children_detected.png', frame) # DELETE ME
# Display the resulting frame
cv2.imshow('frame', frame)また、キーボード入力を監視するコードを追加して、プログラムを停止できるようにします。 ユーザーがq文字をヒットしたかどうかを確認し、ヒットした場合は、アプリケーションを終了します。 cv2.imshow(...)の直後に、以下を追加します。
step_3_camera_face_detect.py
...
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
...行cv2.waitkey(1)は、プログラムを1ミリ秒停止して、キャプチャされた画像をユーザーに表示できるようにします。
最後に、キャプチャをリリースし、すべてのウィンドウを閉じます。 これをwhileループの外側に配置して、main関数を終了します。
step_3_camera_face_detect.py
...
while True:
...
cap.release()
cv2.destroyAllWindows()スクリプトは次のようになります。
step_3_camera_face_detect.py
"""Test for face detection on video camera.
Move your face around and a green box will identify your face.
With the test frame in focus, hit `q` to exit.
Note that typing `q` into your terminal will do nothing.
"""
import cv2
def main():
cap = cv2.VideoCapture(0)
# initialize front face classifier
cascade = cv2.CascadeClassifier(
"assets/haarcascade_frontalface_default.xml")
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
# Detect faces
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# Add all bounding boxes to the image
for x, y, w, h in rects:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()ファイルを保存して、エディターを終了します。
次に、テストスクリプトを実行します。
python step_3_camera_face_detect.pyこれにより、カメラが有効になり、カメラのフィードを表示するウィンドウが開きます。 顔はリアルタイムで緑色の四角で囲まれます:
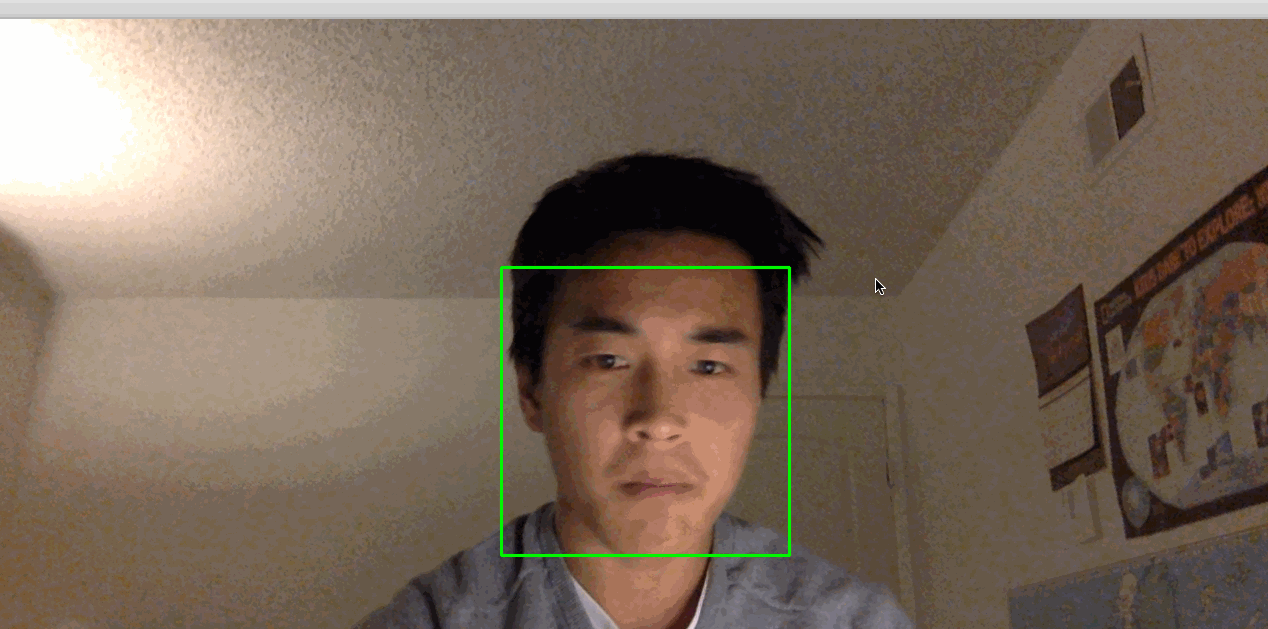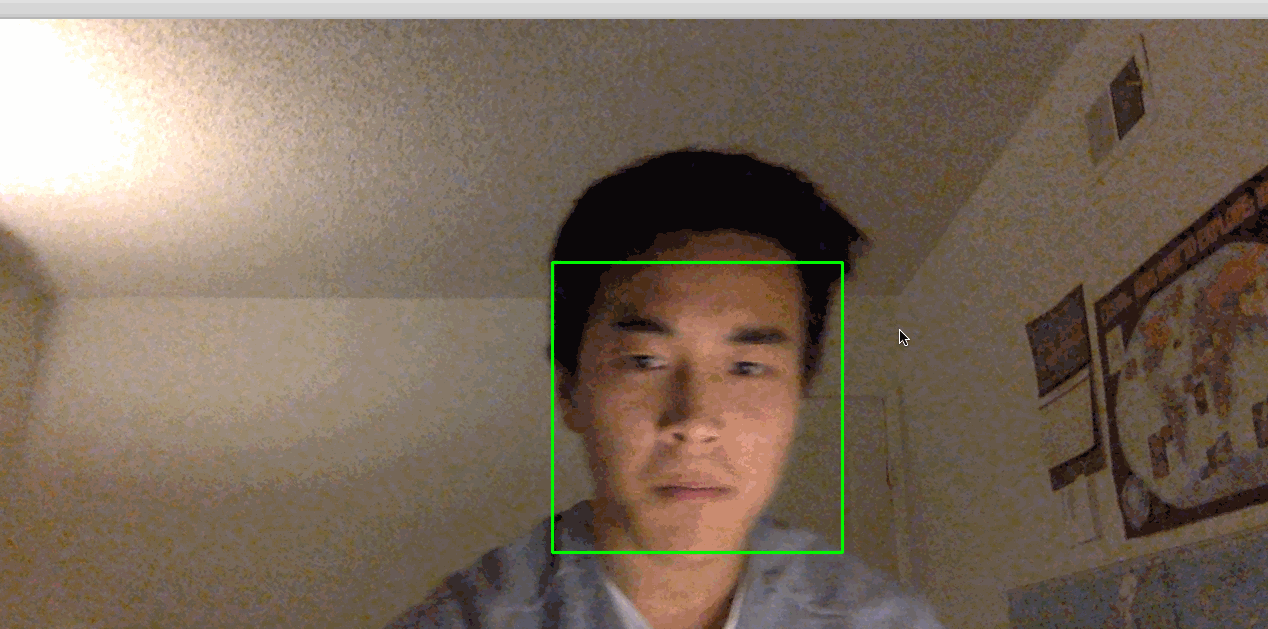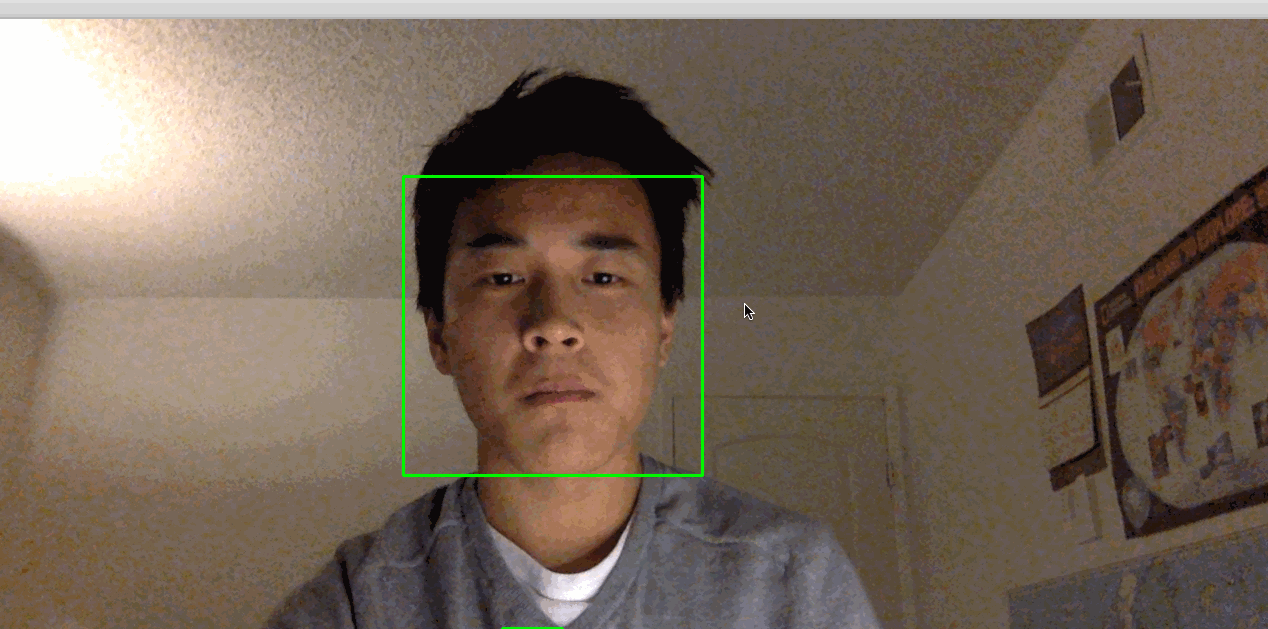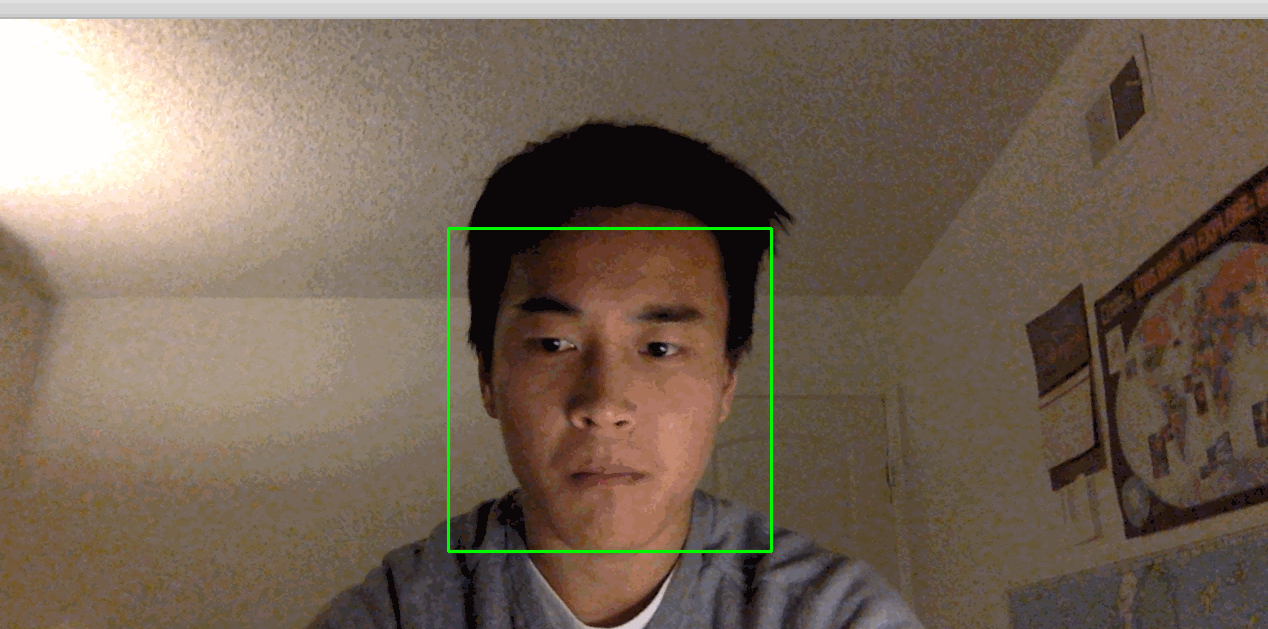
[.note]#Note:物事が機能するために非常に静止しなければならないことがわかった場合、部屋の照明が適切でない可能性があります。 あなたとあなたの背景のコントラストが高い明るい部屋に移動してみてください。 また、頭の近くの明るい光は避けてください。 たとえば、太陽に背を向けている場合、このプロセスはうまく機能しない可能性があります。
#
次の目的は、検出された顔を取得し、それぞれに犬のマスクを重ね合わせることです。
[[step-4 -—- building-the-dog-filter]] ==ステップ4— DogFilterの構築
フィルター自体を作成する前に、画像がどのように数値で表されるかを調べましょう。 これにより、画像を変更し、最終的に犬のフィルターを適用するために必要な背景が得られます。
例を見てみましょう。 数字を使用して白黒画像を作成できます。ここで、0は黒に対応し、1は白に対応します。
1と0の間の境界線に注目してください。 どんな形が見えますか?
0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0
0 0 0 1 1 1 0 0 0
0 0 1 1 1 1 1 0 0
0 0 0 1 1 1 0 0 0
0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0画像はダイヤモンドです。 このmatrixの値を画像として保存する場合。 これにより、次の図が表示されます。

0.1、0.26、0.74391など、0〜1の任意の値を使用できます。 0に近い数字は暗く、1に近い数字は明るくなります。 これにより、白、黒、およびあらゆるグレーの色合いを表現できます。 これは、0、1、およびその間の任意の値を使用して任意のグレースケール画像を構築できるため、私たちにとって素晴らしいニュースです。 たとえば、次のことを考慮してください。 それが何かわかりますか? 繰り返しますが、各数値はピクセルの色に対応しています。
1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 0 0 1 1 1 1
1 1 0 0 .4 .4 .4 .4 0 0 1 1
1 0 .4 .4 .5 .4 .4 .4 .4 .4 0 1
1 0 .4 .5 .5 .5 .4 .4 .4 .4 0 1
0 .4 .4 .4 .5 .4 .4 .4 .4 .4 .4 0
0 .4 .4 .4 .4 0 0 .4 .4 .4 .4 0
0 0 .4 .4 0 1 .7 0 .4 .4 0 0
0 1 0 0 0 .7 .7 0 0 0 1 0
1 0 1 1 1 0 0 .7 .7 .4 0 1
1 0 .7 1 1 1 .7 .7 .7 .7 0 1
1 1 0 0 .7 .7 .7 .7 0 0 1 1
1 1 1 1 0 0 0 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1画像として再レンダリングすると、これは実際にはポケボールであることがわかります。

これで、白黒画像とグレースケール画像がどのように数値で表されるかがわかりました。 色を導入するには、より多くの情報をエンコードする方法が必要です。 画像の高さと幅はh x wで表されます。
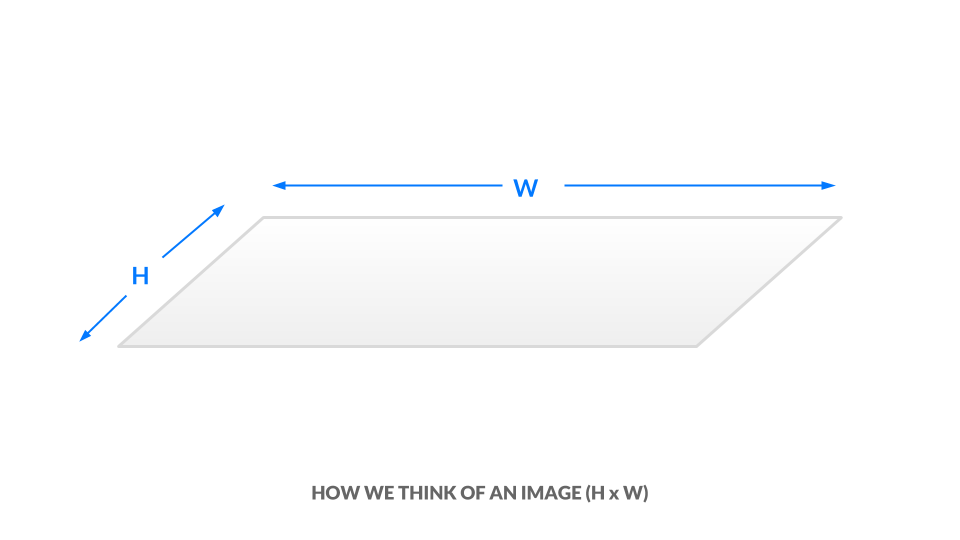
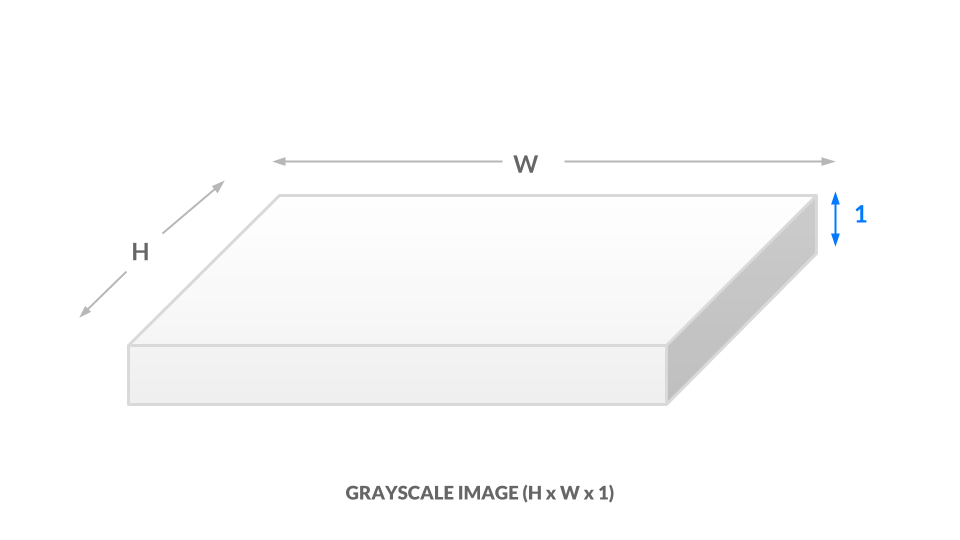
現在のグレースケール表現では、各ピクセルは0と1の間の1つの値です。 同等に、画像のサイズはh x w x 1であると言えます。 つまり、画像内のすべての(x, y)位置には1つの値しかありません。
色表現では、0〜1の3つの値を使用して各ピクセルの色を表します。 1つの数字は「赤の度合い」に対応し、1つは「緑の度合い」に対応し、最後の数字は「青の度合い」に対応します。これをRGB color spaceと呼びます。 これは、画像内のすべての(x, y)位置に対して、3つの値(r, g, b)があることを意味します。 その結果、画像はh x w x 3になります。
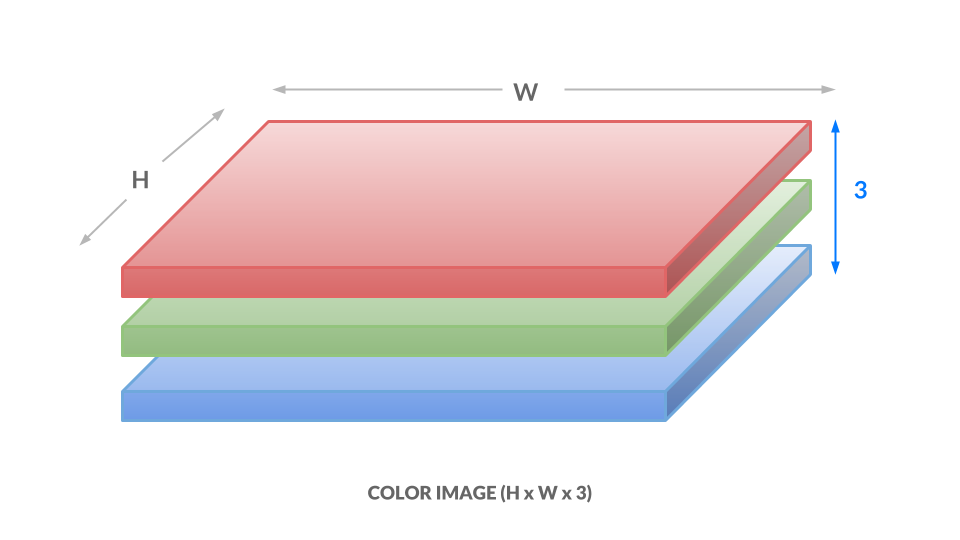
ここでは、各数値の範囲は0〜1ではなく0〜255ですが、考え方は同じです。 数字のさまざまな組み合わせは、濃い紫色の(102, 0, 204)や明るいオレンジ色の(255, 153, 51)などのさまざまな色に対応しています。 要点は次のとおりです。
-
各画像は、高さ、幅、カラーチャネルの3つの次元を持つ数字のボックスとして表されます。 この数字のボックスを直接操作することは、画像を操作することと同じです。
-
このボックスを平らにして、数字のリストにすることもできます。 このようにして、画像はvectorになります。 後で、画像をベクターと呼びます。
これで、画像が数値で表現される方法が理解できたので、顔に犬のマスクを適用する準備が整っています。 犬マスクを適用するには、子画像の値を非白の犬マスクピクセルに置き換えます。 最初に、単一の画像を使用します。 手順2で使用した画像からこの顔の一部をダウンロードします。
wget -O assets/child.png https://assets.digitalocean.com/articles/python3_dogfilter/alXjNK1.png
さらに、次の犬のマスクをダウンロードします。 このチュートリアルで使用される犬のマスクは、私自身の図面であり、現在CC0ライセンスの下でパブリックドメインにリリースされています。

これをwgetでダウンロードします。
wget -O assets/dog.png https://assets.digitalocean.com/articles/python3_dogfilter/ED32BCs.png犬のマスクを顔に適用するスクリプトのコードを保持するstep_4_dog_mask_simple.pyという名前の新しいファイルを作成します。
nano step_4_dog_mask_simple.pyPythonスクリプトに次の定型文を追加し、OpenCVおよびnumpyライブラリをインポートします。
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def main():
pass
if __name__ == '__main__':
main()main関数のpassを、元の画像とドッグマスクをメモリにロードするこれらの2行に置き換えます。
step_4_dog_mask_simple.py
...
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')次に、犬のマスクを子供に合わせます。 ロジックは以前に行ったものよりも複雑なので、コードをモジュール化するためにapply_maskという新しい関数を作成します。 画像をロードする2行の直後に、apply_mask関数を呼び出す次の行を追加します。
step_4_dog_mask_simple.py
...
face_with_mask = apply_mask(face, mask)apply_maskという新しい関数を作成し、main関数の上に配置します。
step_4_dog_mask_simple.py
...
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
pass
def main():
...この時点で、ファイルは次のようになります。
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
pass
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
if __name__ == '__main__':
main()apply_mask関数を作成してみましょう。 私たちの目標は、子供の顔にマスクを適用することです。 ただし、犬のマスクのアスペクト比を維持する必要があります。 そのためには、犬のマスクの最終寸法を明示的に計算する必要があります。 apply_mask関数内で、passを次の2行に置き換えて、両方の画像の高さと幅を抽出します。
step_4_dog_mask_simple.py
...
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape次に、どのディメンションを「さらに縮小」する必要があるかを判断します。正確には、2つの制約のうち、より厳密なものが必要です。 この行をapply_mask関数に追加します。
step_4_dog_mask_simple.py
...
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)次に、このコードを関数に追加して、新しい形状を計算します。
step_4_dog_mask_simple.py
...
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)ここでは、resize関数が整数次元を必要とするため、数値を整数にキャストします。
次のコードを追加して、犬のマスクのサイズを新しい形状に変更します。
step_4_dog_mask_simple.py
...
# Add mask to face - ensure mask is centered
resized_mask = cv2.resize(mask, new_mask_shape)最後に、スクリプトを実行した後、サイズ変更された犬のマスクが正しいことを再確認できるように、イメージをディスクに書き込みます。
step_4_dog_mask_simple.py
cv2.imwrite('outputs/resized_dog.png', resized_mask)完成したスクリプトは次のようになります。
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
# Add mask to face - ensure mask is centered
resized_mask = cv2.resize(mask, new_mask_shape)
cv2.imwrite('outputs/resized_dog.png', resized_mask)
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
if __name__ == '__main__':
main()ファイルを保存して、エディターを終了します。 新しいスクリプトを実行します。
python step_4_dog_mask_simple.pyoutputs/resized_dog.pngで画像を開き、マスクのサイズが正しく変更されていることを再確認します。 このセクションで前述した犬のマスクと一致します。
次に、子供に犬のマスクを追加します。 step_4_dog_mask_simple.pyファイルを再度開き、apply_mask関数に戻ります。
nano step_4_dog_mask_simple.pyまず、サイズ変更されたマスクを書き込むコード行をapply_mask関数から削除します。これは、不要になったためです。
cv2.imwrite('outputs/resized_dog.png', resized_mask) # delete this line
...その代わりに、このセクションの最初から画像表現の知識を適用して、画像を変更します。 子画像のコピーを作成することから始めます。 この行をapply_mask関数に追加します。
step_4_dog_mask_simple.py
...
face_with_mask = face.copy()次に、犬のマスクが白または白に近いすべての位置を見つけます。 これを行うには、すべてのカラーチャネルでピクセル値が250未満であるかどうかを確認します。これは、白に近いピクセルが[255, 255, 255]に近いと予想されるためです。 このコードを追加:
step_4_dog_mask_simple.py
...
non_white_pixels = (resized_mask < 250).all(axis=2)この時点で、犬の画像は、多くても子の画像と同じ大きさです。 犬の画像を顔の中央に配置したいので、次のコードをapply_maskに追加して、犬の画像を中央に配置するために必要なオフセットを計算します。
step_4_dog_mask_simple.py
...
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)犬の画像からすべての非白ピクセルを子の画像にコピーします。 子の画像は犬の画像よりも大きい場合があるため、子の画像のサブセットを取得する必要があります。
step_4_dog_mask_simple.py
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]次に、結果を返します。
step_4_dog_mask_simple.py
return face_with_maskmain関数で、次のコードを追加して、apply_mask関数の結果を出力イメージに書き込み、手動で結果を再確認できるようにします。
step_4_dog_mask_simple.py
...
face_with_mask = apply_mask(face, mask)
cv2.imwrite('outputs/child_with_dog_mask.png', face_with_mask)完成したスクリプトは次のようになります。
step_4_dog_mask_simple.py
"""Test for adding dog mask"""
import cv2
import numpy as np
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
face = cv2.imread('assets/child.png')
mask = cv2.imread('assets/dog.png')
face_with_mask = apply_mask(face, mask)
cv2.imwrite('outputs/child_with_dog_mask.png', face_with_mask)
if __name__ == '__main__':
main()スクリプトを保存して実行します。
python step_4_dog_mask_simple.pyoutputs/child_with_dog_mask.pngに犬のマスクをした子供の次の写真があります。

これで、犬のマスクを顔に適用するユーティリティができました。 作成したものを使用して、犬のマスクをリアルタイムで追加しましょう。
ステップ3で中断したところから再開します。 step_3_camera_face_detect.pyをstep_4_dog_mask.pyにコピーします。
cp step_3_camera_face_detect.py step_4_dog_mask.py新しいスクリプトを開きます。
nano step_4_dog_mask.py最初に、スクリプトの上部にあるNumPyライブラリをインポートします。
step_4_dog_mask.py
import numpy as np
...次に、前の作業のapply_mask関数を、main関数の上にあるこの新しいファイルに追加します。
step_4_dog_mask.py
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
...次に、main関数で次の行を見つけます。
step_4_dog_mask.py
cap = cv2.VideoCapture(0)その行の後に次のコードを追加して、犬のマスクをロードします。
step_4_dog_mask.py
cap = cv2.VideoCapture(0)
# load mask
mask = cv2.imread('assets/dog.png')
...次に、whileループで、次の行を見つけます。
step_4_dog_mask.py
ret, frame = cap.read()次の行を追加して、画像の高さと幅を抽出します。
step_4_dog_mask.py
ret, frame = cap.read()
frame_h, frame_w, _ = frame.shape
...次に、境界ボックスを描画するmainの線を削除します。 この行は、検出された面を反復処理するforループにあります。
step_4_dog_mask.py
for x, y, w, h in rects:
...
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) # DELETE ME
...その代わりに、フレームをトリミングするこのコードを追加します。 審美的な目的のために、顔よりわずかに大きい領域をトリミングします。
step_4_dog_mask.py
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + w検出された顔がエッジに近すぎる場合にチェックを導入します。
step_4_dog_mask.py
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continue最後に、マスク付きの顔を画像に挿入します。
step_4_dog_mask.py
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)スクリプトが次のようになっていることを確認します。
step_4_dog_mask.py
"""Real-time dog filter
Move your face around and a dog filter will be applied to your face if it is not out-of-bounds. With the test frame in focus, hit `q` to exit. Note that typing `q` into your terminal will do nothing.
"""
import numpy as np
import cv2
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
cap = cv2.VideoCapture(0)
# load mask
mask = cv2.imread('assets/dog.png')
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
frame_h, frame_w, _ = frame.shape
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
# Detect faces
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
# Add mask to faces
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + w
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continue
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()ファイルを保存して、エディターを終了します。 その後、スクリプトを実行してください。
python step_4_dog_mask.pyこれで、リアルタイムのドッグフィルターが実行されます。 このスクリプトは、画像内の複数の顔でも機能するため、友だちを集めて自動犬化を行うことができます。

これで、このチュートリアルの最初の主要な目的、つまりSnapchat風のドッグフィルターを作成することが終わりました。 次に、顔の表情を使用して、顔に適用される犬のマスクを決定します。
[[step-5 -—- build-a-basic-face-emotion-classifier-using-least-squares]] ==ステップ5—最小二乗法を使用して基本的な顔の感情分類器を構築します
このセクションでは、感情分類子を作成して、表示された感情に基づいて異なるマスクを適用します。 笑顔の場合、フィルターはコーギーマスクを適用します。 眉をひそめると、パグマスクが適用されます。 その過程で、機械学習の概念を理解して議論するための基本となるleast-squaresフレームワークについて説明します。
データの処理方法と予測の作成方法を理解するために、まず機械学習モデルについて簡単に説明します。
検討するモデルごとに2つの質問をする必要があります。 今のところ、これらの2つの質問は、モデルを区別するのに十分です。
-
入力:モデルにはどのような情報が与えられますか?
-
出力:モデルが予測しようとしているものは何ですか?
大まかに言えば、目標は感情分類のモデルを開発することです。 モデルは以下のとおりです。
-
入力:与えられた顔の画像。
-
出力:対応する感情を予測します。
model: face -> emotion使用するアプローチはleast squaresです。一連のポイントを取得し、最適なラインを見つけます。 次の画像に示されている最適なラインがモデルです。
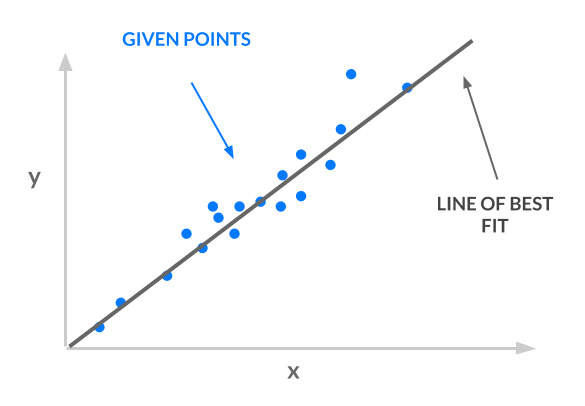
回線の入力と出力を考えてみましょう。
-
入力:指定された
x座標。 -
出力:対応する$ y $座標を予測します。
least squares line: x -> y感情の分類に最小二乗法を使用するには、入力xが顔を表し、出力yが感情を表す必要があります。
-
x -> face:xにone番号を使用する代わりに、xにvectorの値を使用します。 したがって、xは顔の画像を表すことができます。 記事Ordinary Least Squaresは、xに値のベクトルを使用できる理由を説明しています。 -
y -> emotion:各感情は数字に対応します。 たとえば、「angry」は0、「sad」は1、「happy」は2です。 このように、yは感情を表すことができます。 ただし、この行は、yの値0、1、および2を出力するように制約されたnotです。 可能なy値は無限にあり、1.2、3.5、または10003.42の可能性があります。 これらのy値をクラスに対応する整数に変換するにはどうすればよいですか? 詳細と説明については、記事One-Hot Encodingを参照してください。
この背景知識を活用して、ベクトル化された画像とワンホットエンコードラベルを使用して、単純な最小二乗分類器を構築します。 次の3つの手順でこれを達成します。
-
データの前処理:このセクションの冒頭で説明したように、サンプルはベクトルであり、各ベクトルは顔の画像をエンコードします。 ラベルは感情に対応する整数であり、これらのラベルにワンホットエンコーディングを適用します。
-
モデルの指定とトレーニング:閉形式の最小二乗解
w^*を使用します。 -
モデルを使用して予測を実行します。
Xw^*のargmaxを取得して、予測された感情を取得します。
始めましょう。
最初に、データを含むディレクトリを設定します。
mkdir data次に、Pierre-LucCarrierとAaronCourvilleによってキュレーションされたデータを2013年の顔の感情分類competition on Kaggleからダウンロードします。
wget -O data/fer2013.tar https://bitbucket.org/alvinwan/adversarial-examples-in-computer-vision-building-then-fooling/raw/babfe4651f89a398c4b3fdbdd6d7a697c5104cff/fer2013.tardataディレクトリに移動し、データを解凍します。
cd data
tar -xzf fer2013.tar次に、最小二乗モデルを実行するスクリプトを作成します。 プロジェクトのルートに移動します。
cd ~/DogFilterスクリプト用の新しいファイルを作成します。
nano step_5_ls_simple.pyPythonボイラープレートを追加し、必要なパッケージをインポートします。
step_5_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def main():
pass
if __name__ == '__main__':
main()次に、データをメモリにロードします。 main関数のpassを次のコードに置き換えます。
step_5_ls_simple.py
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']ラベルをワンホットエンコードします。 これを行うには、numpyを使用して単位行列を作成し、ラベルのリストを使用してこの行列にインデックスを付けます。
step_5_ls_simple.py
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]ここでは、i番目のエントリを除いて、単位行列のi番目の行がすべてゼロであるという事実を使用します。 したがって、i番目の行はクラスiのラベルのワンホットエンコーディングです。 さらに、numpyの高度なインデックスを使用します。ここで、[a, b, c, d][[b, d]です。
X^TXは400万を超える値を持つ2304x2304行列であるため、(X^TX)^{-1}の計算には時間がかかりすぎるため、最初の100個の機能のみを選択することでこの時間を短縮します。 このコードを追加:
step_5_ls_simple.py
...
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]次に、次のコードを追加して、閉形式の最小二乗解を評価します。
step_5_ls_simple.py
...
# train model
w = np.linalg.inv(A_train.T.dot(A_train)).dot(A_train.T.dot(Y_oh_train))次に、トレーニングおよび検証セットの評価関数を定義します。 これをmain関数の前に配置します。
step_5_ls_simple.py
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]ラベルを推定するために、各サンプルの内積を取得し、np.argmaxを使用して最大値のインデックスを取得します。 次に、正しい分類の平均数を計算します。 この最後の数字はあなたの正確さです。
最後に、このコードをmain関数の最後に追加して、先ほど作成したevaluate関数を使用してトレーニングと検証の精度を計算します。
step_5_ls_simple.py
# evaluate model
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)スクリプトが次と一致することを再確認します。
step_5_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]
def main():
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]
# train model
w = np.linalg.inv(A_train.T.dot(A_train)).dot(A_train.T.dot(Y_oh_train))
# evaluate model
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)
if __name__ == '__main__':
main()ファイルを保存し、エディターを終了して、Pythonスクリプトを実行します。
python step_5_ls_simple.py次の出力が表示されます。
Output(ols) Train Accuracy: 0.4748918316507146
(ols) Test Accuracy: 0.45280545359202934このモデルでは、列車の精度は47.5%です。 45.3%の精度を得るために、検証セットでこれを繰り返します。 3者間分類問題の場合、45.3%が推測をかなり上回っており、33 \%です。 これが感情検出の最初の分類子であり、次のステップでは、この最小二乗モデルから構築して精度を向上させます。 精度が高いほど、感情ベースのドッグフィルターは、検出された各感情に適切なドッグフィルターをより確実に見つけることができます。
[[ステップ-6 ---入力を特徴づけることによって精度を向上させる]] ==ステップ6—入力を特徴づけることによって精度を向上させる
より表現力豊かなモデルを使用して、精度を高めることができます。 これを実現するために、入力をfeaturizeします。
元の画像は、位置(0, 0)が赤、(1, 0)が茶色などであることを示しています。 特徴のある画像は、画像の左上に犬、中央に人などがいることを示しています。 機能化は強力ですが、その正確な定義はこのチュートリアルの範囲外です。
approximation for the radial basis function (RBF) kernel, using a random Gaussian matrixを使用します。 このチュートリアルでは詳しく説明しません。 代わりに、これを高次の特徴を計算するブラックボックスとして扱います。
前のステップで中断したところから続行します。 前のスクリプトをコピーして、適切な開始点を用意します。
cp step_5_ls_simple.py step_6_ls_simple.pyエディターで新しいファイルを開きます。
nano step_6_ls_simple.pyまず、特徴的なランダムマトリックスを作成します。 繰り返しますが、新しい機能スペースでは100個の機能のみを使用します。
A_trainとA_testを定義する次の行を見つけます。
step_6_ls_simple.py
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100]A_trainおよびA_testのこの定義のすぐ上に、ランダムな特徴行列を追加します。
step_6_ls_simple.py
d = 100
W = np.random.normal(size=(X_train.shape[1], d))
# select first 100 dimensions
A_train, A_test = X_train[:, :100], X_test[:, :100] ...次に、A_trainとA_testの定義を置き換えます。 このランダムな特徴を使用して、design行列と呼ばれる行列を再定義します。
step_6_ls_simple.py
A_train, A_test = X_train.dot(W), X_test.dot(W)ファイルを保存して、スクリプトを実行します。
python step_6_ls_simple.py次の出力が表示されます。
Output(ols) Train Accuracy: 0.584174642717
(ols) Test Accuracy: 0.584425799685この機能により、58.4%の列車精度と58.4%の検証精度が実現し、検証結果が13.1%改善されました。 X行列を100 x 100にトリミングしましたが、100の選択は任意でした。 X行列を1000 x 1000または50 x 50にトリミングすることもできます。 xの次元がd x dであるとします。 Xをd x dに再トリミングし、新しいモデルを再計算することで、dのより多くの値をテストできます。
dの値をさらに試してみると、テスト精度がさらに4.3%向上して61.7%になることがわかります。 次の図では、dを変化させたときの、新しい分類器のパフォーマンスを考慮しています。 直感的には、dが増加すると、元のデータをますます使用するため、精度も向上するはずです。 ただし、グラフはバラ色の絵を描くのではなく、負の傾向を示します。
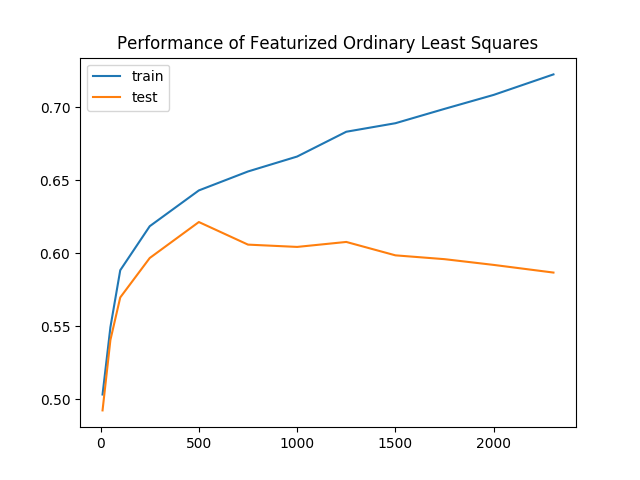
データを保持するにつれて、トレーニングの精度と検証の精度のギャップも大きくなります。 これはoverfittingの明確な証拠であり、モデルはすべてのデータに一般化できなくなった表現を学習しています。 過剰適合と戦うために、複雑なモデルにペナルティを課してモデルをregularizeします。
通常の最小二乗目的関数を正則化項で修正し、新しい目的を与えます。 新しい目的関数はridge regressionと呼ばれ、次のようになります。
min_w |Aw- y|^2 + lambda |w|^2この式では、lambdaは調整可能なハイパーパラメータです。 lambda = 0を方程式に代入すると、リッジ回帰が最小二乗になります。 lambda = infinityを方程式に代入すると、ゼロ以外のwは無限の損失を被るので、最良のwはゼロでなければならないことがわかります。 結局のところ、この目的は閉じた形式のソリューションももたらします:
w^* = (A^TA + lambda I)^{-1}A^Ty引き続き特徴のあるサンプルを使用して、モデルを再度トレーニングし、再評価します。
エディターでstep_6_ls_simple.pyを再度開きます。
nano step_6_ls_simple.py今回は、新しいフィーチャスペースの次元をd=1000に増やします。 次のコードブロックに示すように、dの値を100から1000に変更します。
step_6_ls_simple.py
...
d = 1000
W = np.random.normal(size=(X_train.shape[1], d))
...次に、lambda = 10^{10}の正則化を使用してリッジ回帰を適用します。 wを定義する行を次の2行に置き換えます。
step_6_ls_simple.py
...
# train model
I = np.eye(A_train.shape[1])
w = np.linalg.inv(A_train.T.dot(A_train) + 1e10 * I).dot(A_train.T.dot(Y_oh_train))次に、このブロックを見つけます。
step_6_ls_simple.py
...
ols_train_accuracy = evaluate(A_train, Y_train, w)
print('(ols) Train Accuracy:', ols_train_accuracy)
ols_test_accuracy = evaluate(A_test, Y_test, w)
print('(ols) Test Accuracy:', ols_test_accuracy)次のものに置き換えます。
step_6_ls_simple.py
...
print('(ridge) Train Accuracy:', evaluate(A_train, Y_train, w))
print('(ridge) Test Accuracy:', evaluate(A_test, Y_test, w))完成したスクリプトは次のようになります。
step_6_ls_simple.py
"""Train emotion classifier using least squares."""
import numpy as np
def evaluate(A, Y, w):
Yhat = np.argmax(A.dot(w), axis=1)
return np.sum(Yhat == Y) / Y.shape[0]
def main():
# load data
with np.load('data/fer2013_train.npz') as data:
X_train, Y_train = data['X'], data['Y']
with np.load('data/fer2013_test.npz') as data:
X_test, Y_test = data['X'], data['Y']
# one-hot labels
I = np.eye(6)
Y_oh_train, Y_oh_test = I[Y_train], I[Y_test]
d = 1000
W = np.random.normal(size=(X_train.shape[1], d))
# select first 100 dimensions
A_train, A_test = X_train.dot(W), X_test.dot(W)
# train model
I = np.eye(A_train.shape[1])
w = np.linalg.inv(A_train.T.dot(A_train) + 1e10 * I).dot(A_train.T.dot(Y_oh_train))
# evaluate model
print('(ridge) Train Accuracy:', evaluate(A_train, Y_train, w))
print('(ridge) Test Accuracy:', evaluate(A_test, Y_test, w))
if __name__ == '__main__':
main()ファイルを保存し、エディターを終了して、スクリプトを実行します。
python step_6_ls_simple.py次の出力が表示されます。
Output(ridge) Train Accuracy: 0.651173462698
(ridge) Test Accuracy: 0.622181436812列車の精度が65.1%に低下すると、検証の精度が0.4%から62.2%にさらに改善されます。 いくつかの異なるdで再度評価すると、リッジ回帰のトレーニングと検証の精度のギャップが小さくなっています。 言い換えれば、リッジ回帰はオーバーフィッティングの影響を受けにくいということです。
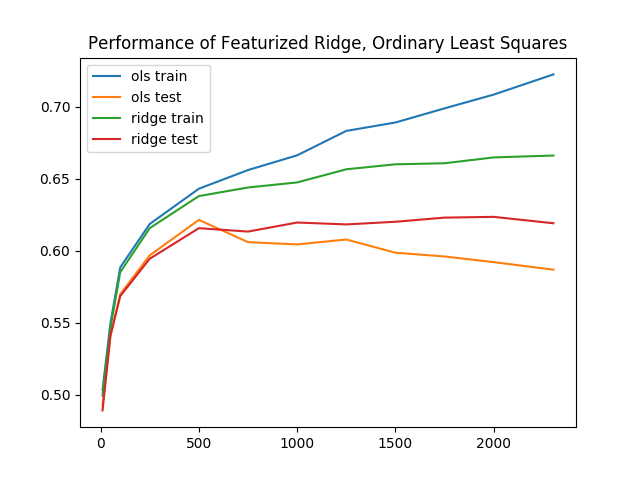
これらの追加の拡張機能を備えた最小二乗法のベースラインパフォーマンスは、かなりよく機能します。 トレーニング時間と推論時間を合わせて、最高の結果を得るために20秒以内で完了します。 次のセクションでは、さらに複雑なモデルについて説明します。
[[step-7 -—- building-the-face-emotion-classifier-using-a-convolutional-neural-network-in-pytorch]] ==ステップ7—畳み込みニューラルネットワークを使用したFace-EmotionClassifierの構築PyTorch
このセクションでは、最小二乗法の代わりにニューラルネットワークを使用して、2番目の感情分類器を構築します。 繰り返しますが、私たちの目標は、入力として顔を受け入れ、感情を出力するモデルを作成することです。 最終的に、この分類子は適用する犬マスクを決定します。
ニューラルネットワークの簡単な視覚化と紹介については、記事Understanding Neural Networksを参照してください。 ここでは、PyTorchと呼ばれる深層学習ライブラリを使用します。 広く使用されている多くのディープラーニングライブラリがあり、それぞれにさまざまな長所と短所があります。 PyTorchは、始めるのに特に適した場所です。 このニューラルネットワーク分類器を実装するには、最小二乗分類器で行ったように、再び3つの手順を実行します。
-
データの前処理:ワンホットエンコーディングを適用してから、PyTorch抽象化を適用します。
-
モデルの指定とトレーニング:PyTorchレイヤーを使用してニューラルネットワークをセットアップします。 最適化ハイパーパラメーターを定義し、確率的勾配降下を実行します。
-
モデルを使用して予測を実行します。ニューラルネットワークを評価します。
step_7_fer_simple.pyという名前の新しいファイルを作成します
nano step_7_fer_simple.py必要なユーティリティをインポートし、データを保持するPythonclassを作成します。 ここでのデータ処理では、トレインデータセットとテストデータセットを作成します。 これらを行うには、PyTorchのDatasetインターフェースを実装します。これにより、顔の感情認識データセット用にPyTorchの組み込みデータパイプラインを読み込んで使用できます。
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
passFer2013Datasetクラスのpassプレースホルダーを削除します。 その代わりに、データホルダーを初期化する関数を追加します。
step_7_fer_simple.py
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
...この機能は、サンプルとラベルをロードすることから始まります。 次に、データをPyTorchデータ構造にラップします。
__init__関数の直後に、__len__関数を追加します。これは、PyTorchが期待するDatasetインターフェイスを実装するために必要です。
step_7_fer_simple.py
...
def __len__(self):
return len(self._labels)最後に、__getitem__メソッドを追加します。このメソッドは、サンプルとラベルを含むdictionaryを返します。
step_7_fer_simple.py
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}ファイルが次のようになっていることを再確認します。
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}次に、Fer2013Datasetデータセットをロードします。 Fer2013Datasetクラスの後のファイルの最後に次のコードを追加します。
step_7_fer_simple.py
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)このコードは、作成したFer2013Datasetクラスを使用してデータセットを初期化します。 次に、トレインセットと検証セットの場合、データセットをDataLoaderでラップします。 これにより、データセットは後で使用できるように反復可能に変換されます。
健全性チェックとして、データセットユーティリティが機能していることを確認します。 DataLoaderを使用してサンプルデータセットローダーを作成し、そのローダーの最初の要素を出力します。 ファイルの最後に次を追加します。
step_7_fer_simple.py
if __name__ == '__main__':
loader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False)
print(next(iter(loader)))完成したスクリプトが次のようになっていることを確認します。
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
if __name__ == '__main__':
loader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False)
print(next(iter(loader)))エディターを終了し、スクリプトを実行します。
python step_7_fer_simple.pyこれにより、次のtensorsのペアが出力されます。 データパイプラインは、2つのサンプルと2つのラベルを出力します。 これは、データパイプラインが起動し、準備ができていることを示しています。
Output{'image':
(0 ,0 ,.,.) =
24 32 36 ... 173 172 173
25 34 29 ... 173 172 173
26 29 25 ... 172 172 174
... ⋱ ...
159 185 157 ... 157 156 153
136 157 187 ... 152 152 150
145 130 161 ... 142 143 142
⋮
(1 ,0 ,.,.) =
20 17 19 ... 187 176 162
22 17 17 ... 195 180 171
17 17 18 ... 203 193 175
... ⋱ ...
1 1 1 ... 106 115 119
2 2 1 ... 103 111 119
2 2 2 ... 99 107 118
[torch.LongTensor of size 2x1x48x48]
, 'label':
1
1
[torch.LongTensor of size 2]
}データパイプラインが機能することを確認したので、step_7_fer_simple.pyに戻ってニューラルネットワークとオプティマイザーを追加します。 step_7_fer_simple.pyを開きます。
nano step_7_fer_simple.py最初に、前の反復で追加した最後の3行を削除します。
step_7_fer_simple.py
# Delete all three lines
if __name__ == '__main__':
loader = torch.utils.data.DataLoader(trainset, batch_size=2, shuffle=False)
print(next(iter(loader)))その代わりに、3つの畳み込み層とそれに続く3つの完全に接続された層を含むPyTorchニューラルネットワークを定義します。 これを既存のスクリプトの最後に追加します。
step_7_fer_simple.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x次に、ニューラルネットワークを初期化し、損失関数を定義し、次のコードをスクリプトの最後に追加して、最適化ハイパーパラメーターを定義します。
step_7_fer_simple.py
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)2つのepochsでトレーニングします。 今のところ、epochは、すべてのトレーニングサンプルが1回だけ使用されたトレーニングの反復であると定義しています。
まず、データセットローダーからimageとlabelを抽出してから、それぞれをPyTorchVariableでラップします。 次に、フォワードパスを実行してから、損失およびニューラルネットワークを逆伝播します。 それを行うには、スクリプトの最後に次のコードを追加します。
step_7_fer_simple.py
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 100 == 0:
print('[%d, %5d] loss: %.3f' % (epoch, i, running_loss / (i + 1)))スクリプトは次のようになります。
step_7_fer_simple.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
trainset = Fer2013Dataset('data/fer2013_train.npz')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
testset = Fer2013Dataset('data/fer2013_test.npz')
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 100 == 0:
print('[%d, %5d] loss: %.3f' % (epoch, i, running_loss / (i + 1)))コードを確認したら、ファイルを保存してエディターを終了します。 次に、この概念実証トレーニングを開始します。
python step_7_fer_simple.pyニューラルネットワークのトレーニングとして、次のような出力が表示されます。
Output[0, 0] loss: 1.094
[0, 100] loss: 1.049
[0, 200] loss: 1.009
[0, 300] loss: 0.963
[0, 400] loss: 0.935
[1, 0] loss: 0.760
[1, 100] loss: 0.768
[1, 200] loss: 0.775
[1, 300] loss: 0.776
[1, 400] loss: 0.767その後、他の多くのPyTorchユーティリティを使用してこのスクリプトを拡張し、モデルの保存と読み込み、トレーニングと検証の精度の出力、学習率のスケジュールの微調整などを行うことができます。 0.01の学習率と0.9の運動量で20エポックのトレーニングを行った後、当社のニューラルネットワークは87.9%の訓練精度と75.5%の検証精度を達成し、これまでで最も成功した最小二乗アプローチに対して6.8%の改善を達成しました。 。 これらの追加機能を新しいスクリプトに含めます。
ライブカメラフィードが使用する最終的な顔の感情検出器を保持する新しいファイルを作成します。 このスクリプトには、上記のコードとコマンドラインインターフェイス、および後で使用するインポートしやすいコードのバージョンが含まれています。 さらに、より正確なモデルのために、事前に調整されたハイパーパラメーターが含まれています。
nano step_7_fer.py次のインポートから始めます。 これは以前のファイルと一致しますが、import cv2.としてOpenCVが追加で含まれています
step_7_fer.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparseこれらのインポートのすぐ下で、step_7_fer_simple.pyのコードを再利用して、ニューラルネットワークを定義します。
step_7_fer.py
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return xここでも、step_7_fer_simple.pyの顔感情認識データセットのコードを再利用して、このファイルに追加します。
step_7_fer.py
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}次に、いくつかのユーティリティを定義して、ニューラルネットワークのパフォーマンスを評価します。 まず、ニューラルネットワークの予測された感情を単一の画像の実際の感情と比較するevaluate関数を追加します。
step_7_fer.py
def evaluate(outputs: Variable, labels: Variable, normalized: bool=True) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.data.numpy()
Yhat = np.argmax(outputs.data.numpy(), axis=1)
denom = Y.shape[0] if normalized else 1
return float(np.sum(Yhat == Y) / denom)次に、最初の関数をすべての画像に適用するbatch_evaluateという関数を追加します。
step_7_fer.py
def batch_evaluate(net: Net, dataset: Dataset, batch_size: int=500) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = 0.0
n = dataset.X.shape[0]
for i in range(0, n, batch_size):
x = dataset.X[i: i + batch_size]
y = dataset.Y[i: i + batch_size]
score += evaluate(net(x), y, False)
return score / n次に、事前にトレーニングされたモデルを使用して、画像を取り込み、予測された感情を出力するget_image_to_emotion_predictorという関数を定義します。
step_7_fer.py
def get_image_to_emotion_predictor(model_path='assets/model_best.pth'):
"""Returns predictor, from image to emotion index."""
net = Net().float()
pretrained_model = torch.load(model_path)
net.load_state_dict(pretrained_model['state_dict'])
def predictor(image: np.array):
"""Translates images into emotion indices."""
if image.shape[2] > 1:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
frame = cv2.resize(image, (48, 48)).reshape((1, 1, 48, 48))
X = Variable(torch.from_numpy(frame)).float()
return np.argmax(net(X).data.numpy(), axis=1)[0]
return predictor最後に、次のコードを追加して、他のユーティリティを活用するためのmain関数を定義します。
step_7_fer.py
def main():
trainset = Fer2013Dataset('data/fer2013_train.npz')
testset = Fer2013Dataset('data/fer2013_test.npz')
net = Net().float()
pretrained_model = torch.load("assets/model_best.pth")
net.load_state_dict(pretrained_model['state_dict'])
train_acc = batch_evaluate(net, trainset, batch_size=500)
print('Training accuracy: %.3f' % train_acc)
test_acc = batch_evaluate(net, testset, batch_size=500)
print('Validation accuracy: %.3f' % test_acc)
if __name__ == '__main__':
main()これにより、事前学習済みのニューラルネットワークが読み込まれ、提供された顔感情認識データセットでのパフォーマンスが評価されます。 具体的には、このスクリプトは、トレーニングに使用した画像の正確性と、テスト目的のために別の画像セットを出力します。
ファイルが次と一致することを再確認します。
step_7_fer.py
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import torch
import cv2
import argparse
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 3)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class Fer2013Dataset(Dataset):
"""Face Emotion Recognition dataset.
Utility for loading FER into PyTorch. Dataset curated by Pierre-Luc Carrier
and Aaron Courville in 2013.
Each sample is 1 x 1 x 48 x 48, and each label is a scalar.
"""
def __init__(self, path: str):
"""
Args:
path: Path to `.np` file containing sample nxd and label nx1
"""
with np.load(path) as data:
self._samples = data['X']
self._labels = data['Y']
self._samples = self._samples.reshape((-1, 1, 48, 48))
self.X = Variable(torch.from_numpy(self._samples)).float()
self.Y = Variable(torch.from_numpy(self._labels)).float()
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
return {'image': self._samples[idx], 'label': self._labels[idx]}
def evaluate(outputs: Variable, labels: Variable, normalized: bool=True) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.data.numpy()
Yhat = np.argmax(outputs.data.numpy(), axis=1)
denom = Y.shape[0] if normalized else 1
return float(np.sum(Yhat == Y) / denom)
def batch_evaluate(net: Net, dataset: Dataset, batch_size: int=500) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = 0.0
n = dataset.X.shape[0]
for i in range(0, n, batch_size):
x = dataset.X[i: i + batch_size]
y = dataset.Y[i: i + batch_size]
score += evaluate(net(x), y, False)
return score / n
def get_image_to_emotion_predictor(model_path='assets/model_best.pth'):
"""Returns predictor, from image to emotion index."""
net = Net().float()
pretrained_model = torch.load(model_path)
net.load_state_dict(pretrained_model['state_dict'])
def predictor(image: np.array):
"""Translates images into emotion indices."""
if image.shape[2] > 1:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
frame = cv2.resize(image, (48, 48)).reshape((1, 1, 48, 48))
X = Variable(torch.from_numpy(frame)).float()
return np.argmax(net(X).data.numpy(), axis=1)[0]
return predictor
def main():
trainset = Fer2013Dataset('data/fer2013_train.npz')
testset = Fer2013Dataset('data/fer2013_test.npz')
net = Net().float()
pretrained_model = torch.load("assets/model_best.pth")
net.load_state_dict(pretrained_model['state_dict'])
train_acc = batch_evaluate(net, trainset, batch_size=500)
print('Training accuracy: %.3f' % train_acc)
test_acc = batch_evaluate(net, testset, batch_size=500)
print('Validation accuracy: %.3f' % test_acc)
if __name__ == '__main__':
main(ファイルを保存して、エディターを終了します。
以前と同様に、顔検出器を使用して、事前にトレーニングされたモデルパラメータをダウンロードし、次のコマンドを使用してassetsフォルダに保存します。
wget -O assets/model_best.pth https://github.com/alvinwan/emotion-based-dog-filter/raw/master/src/assets/model_best.pthスクリプトを実行して、事前学習済みモデルを使用および評価します。
python step_7_fer.pyこれは以下を出力します。
OutputTraining accuracy: 0.879
Validation accuracy: 0.755この時点で、非常に正確な顔感情分類器を作成しました。 本質的に、私たちのモデルは、幸せで、悲しく、驚いた顔の10分の8を正しく明確にすることができます。 これはかなり良いモデルであるため、この顔感情分類器を使用して、どの犬マスクを顔に適用するかを決定できます。
[[step-8 -—- finishing-the-emotion-based-dog-filter]] ==ステップ8— Emotion-Based DogFilterの終了
真新しい顔感情分類器を統合する前に、動物マスクを選択する必要があります。 ダルメーションマスクとシープドッグマスクを使用します。

次のコマンドを実行して、両方のマスクをassetsフォルダーにダウンロードします。
wget -O assets/dalmation.png https://assets.digitalocean.com/articles/python3_dogfilter/E9ax7PI.png # dalmation
wget -O assets/sheepdog.png https://assets.digitalocean.com/articles/python3_dogfilter/HveFdkg.png # sheepdog次に、フィルターでマスクを使用します。 step_4_dog_mask.pyファイルを複製することから始めます。
cp step_4_dog_mask.py step_8_dog_emotion_mask.py新しいPythonスクリプトを開きます。
nano step_8_dog_emotion_mask.pyスクリプトの先頭に新しい行を挿入して、感情予測子をインポートします。
step_8_dog_emotion_mask.py
from step_7_fer import get_image_to_emotion_predictor
...次に、main()関数で、次の行を見つけます。
step_8_dog_emotion_mask.py
mask = cv2.imread('assets/dog.png')以下に置き換えて、新しいマスクをロードし、すべてのマスクをタプルに集約します。
step_8_dog_emotion_mask.py
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)改行を追加してから、このコードを追加して感情予測を作成します。
step_8_dog_emotion_mask.py
# get emotion predictor
predictor = get_image_to_emotion_predictor()これで、main関数は次のように一致するはずです。
step_8_dog_emotion_mask.py
def main():
cap = cv2.VideoCapture(0)
# load mask
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)
# get emotion predictor
predictor = get_image_to_emotion_predictor()
# initialize front face classifier
...次に、次の行を見つけます。
step_8_dog_emotion_mask.py
# apply mask
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)# apply mask行の下に次の行を挿入して、予測子を使用して適切なマスクを選択します。
step_8_dog_emotion_mask.py
# apply mask
mask = masks[predictor(frame[y:y+h, x: x+w])]
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)完成したファイルは次のようになります。
step_8_dog_emotion_mask.py
"""Test for face detection"""
from step_7_fer import get_image_to_emotion_predictor
import numpy as np
import cv2
def apply_mask(face: np.array, mask: np.array) -> np.array:
"""Add the mask to the provided face, and return the face with mask."""
mask_h, mask_w, _ = mask.shape
face_h, face_w, _ = face.shape
# Resize the mask to fit on face
factor = min(face_h / mask_h, face_w / mask_w)
new_mask_w = int(factor * mask_w)
new_mask_h = int(factor * mask_h)
new_mask_shape = (new_mask_w, new_mask_h)
resized_mask = cv2.resize(mask, new_mask_shape)
# Add mask to face - ensure mask is centered
face_with_mask = face.copy()
non_white_pixels = (resized_mask < 250).all(axis=2)
off_h = int((face_h - new_mask_h) / 2)
off_w = int((face_w - new_mask_w) / 2)
face_with_mask[off_h: off_h+new_mask_h, off_w: off_w+new_mask_w][non_white_pixels] = \
resized_mask[non_white_pixels]
return face_with_mask
def main():
cap = cv2.VideoCapture(0)
# load mask
mask0 = cv2.imread('assets/dog.png')
mask1 = cv2.imread('assets/dalmation.png')
mask2 = cv2.imread('assets/sheepdog.png')
masks = (mask0, mask1, mask2)
# get emotion predictor
predictor = get_image_to_emotion_predictor()
# initialize front face classifier
cascade = cv2.CascadeClassifier("assets/haarcascade_frontalface_default.xml")
while True:
# Capture frame-by-frame
ret, frame = cap.read()
frame_h, frame_w, _ = frame.shape
# Convert to black-and-white
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
blackwhite = cv2.equalizeHist(gray)
rects = cascade.detectMultiScale(
blackwhite, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
for x, y, w, h in rects:
# crop a frame slightly larger than the face
y0, y1 = int(y - 0.25*h), int(y + 0.75*h)
x0, x1 = x, x + w
# give up if the cropped frame would be out-of-bounds
if x0 < 0 or y0 < 0 or x1 > frame_w or y1 > frame_h:
continue
# apply mask
mask = masks[predictor(frame[y:y+h, x: x+w])]
frame[y0: y1, x0: x1] = apply_mask(frame[y0: y1, x0: x1], mask)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()エディターを保存して終了します。 スクリプトを起動します。
python step_8_dog_emotion_mask.py今すぐ試してみてください! 笑顔は「幸せ」として登録され、元の犬が表示されます。 中立的な顔または眉をひそめている人は「悲しい」として登録し、ダルメシアンを譲ります。 「驚き」の顔、素敵な大きなあごのドロップは、牧羊犬をもたらします。

これで、感情に基づく犬のフィルターとコンピュータービジョンへの進出が終わりました。
結論
このチュートリアルでは、コンピュータービジョンを使用して顔検出器と犬のフィルターを作成し、機械学習モデルを使用して、検出された感情に基づいてマスクを適用します。
機械学習は広く適用可能です。 ただし、機械学習を適用する際には、各アプリケーションの倫理的意味を考慮するのは開業医次第です。 このチュートリアルで作成したアプリケーションは楽しい練習でしたが、モデルをトレーニングするために独自のデータを提供するのではなく、OpenCVと既存のデータセットに依存して顔を識別したことに注意してください。 使用されるデータとモデルは、プログラムの動作に大きな影響を与えます。
たとえば、候補者に関するデータでモデルがトレーニングされた求人検索エンジンを想像してください。 人種、性別、年齢、文化、第一言語、またはその他の要因など。 そしておそらく開発者は、スパース性を強制するモデルをトレーニングしました。これにより、特徴空間が性差の大部分を説明する部分空間に縮小されます。 その結果、このモデルは、主に性別に基づいて、求職者の求職や企業選択のプロセスにも影響を与えます。 次に、モデルの解釈が難しく、特定の機能が何に対応するかわからない、より複雑な状況を考えてみましょう。 これについては、カリフォルニア大学バークレー校のMoritz Hardt教授によるEquality of Opportunity in Machine Learningで詳しく知ることができます。
機械学習には非常に大きな不確実性が存在する可能性があります。 このランダムさと複雑さを理解するには、数学的直観と確率的思考スキルの両方を開発する必要があります。 実践者として、機械学習の理論的基盤を掘り下げるのはあなた次第です。