前書き
Pythonpandasパッケージは、データの操作と分析に使用され、ラベル付きデータまたはリレーショナルデータを直感的に操作できるように設計されています。
pandasパッケージはスプレッドシート機能を提供しますが、Pythonを使用しているため、従来のグラフィカルなスプレッドシートプログラムよりもはるかに高速で効率的です。
このチュートリアルでは、使用する大規模なデータセットの設定、pandasのgroupby()関数とpivot_table()関数、そして最後にデータを視覚化する方法について説明します。
pandasパッケージについてある程度理解するには、チュートリアルAn Introduction to the pandas Package and its Data Structures in Python 3を読むことができます。
前提条件
このガイドでは、ローカルデスクトップまたはリモートサーバーでpandasのデータを操作する方法について説明します。 大規模なデータセットの操作はメモリを大量に消費する可能性があるため、いずれの場合も、このガイドの計算の一部を実行するには、コンピューターに少なくとも2GB of memoryが必要です。
このチュートリアルでは、Jupyter Notebookを使用してデータを操作します。 まだお持ちでない場合は、tutorial to install and set up Jupyter Notebook for Python 3に従ってください。
データを設定する
このチュートリアルでは、Social Security websiteから8MBのzipファイルとして入手できる赤ちゃんの名前に関する米国の社会保障データを使用します。
正しいディレクトリからlocal machineまたはserverでPython3プログラミング環境をアクティブ化しましょう。
cd environments. my_env/bin/activateそれでは、プロジェクト用の新しいディレクトリを作成しましょう。 これをnamesと呼び、ディレクトリに移動できます。
mkdir names
cd namesこのディレクトリ内で、curlコマンドを使用して社会保障Webサイトからzipファイルをプルできます。
curl -O https://www.ssa.gov/oact/babynames/names.zipファイルをダウンロードしたら、使用するすべてのパッケージがインストールされていることを確認しましょう。
-
多次元配列をサポートする
numpy -
データを視覚化するための
matplotlib -
データ分析の
pandas -
matplotlib統計グラフィックをより美しくするための
seaborn
パッケージがまだインストールされていない場合は、次のようにpipを使用してインストールします。
pip install pandas
pip install matplotlib
pip install seabornnumpyパッケージがまだインストールされていない場合は、インストールされます。
これでJupyter Notebookを起動できます。
jupyter notebookJupyter Notebookのウェブインターフェースにアクセスすると、そこにnames.zipファイルが表示されます。
新しいノートブックファイルを作成するには、右上のプルダウンメニューからNew>Python 3を選択します。
これにより、ノートブックが開きます。
使用するパッケージのimportingから始めましょう。 ノートブックの上部に、次のように書く必要があります。
import numpy as np
import matplotlib.pyplot as pp
import pandas as pd
import seabornこのコードを実行し、ALT + ENTERと入力して新しいコードブロックに移動できます。
また、Python Notebookにグラフをインラインに保つように指示しましょう。
matplotlib inlineコードを実行して、ALT + ENTERと入力して続行します。
ここから、zipアーカイブを解凍し、CSVデータセットをpandasにロードしてから、pandasDataFramesを連結します。
Zipアーカイブの圧縮解除
zipアーカイブを現在のディレクトリに解凍するには、zipfileモジュールをインポートしてから、ファイルの名前(この場合はnames.zip)を使用してZipFile関数を呼び出します。
import zipfile
zipfile.ZipFile('names.zip').extractall('.')コードを実行して、ALT + ENTERと入力して続行できます。
ここで、namesディレクトリを振り返ると、CSV形式の名前データの.txtファイルがあります。 これらのファイルは、1881年から2015年までのファイル上のデータの年に対応します。 これらの各ファイルは、同様の命名規則に従います。 たとえば、2015年のファイルはyob2015.txtと呼ばれ、1927年のファイルはyob1927.txtと呼ばれます。
これらのファイルのいずれかの形式を確認するには、Pythonを使用してファイルを開き、上位5行を表示します。
open('yob2015.txt','r').readlines()[:5]コードを実行し、ALT + ENTERを続行します。
Output['Emma,F,20355\n',
'Olivia,F,19553\n',
'Sophia,F,17327\n',
'Ava,F,16286\n',
'Isabella,F,15504\n']データのフォーマット方法は、最初に名前(EmmaまたはOliviaなど)、次に性別(女性の名前の場合はF、男性の名前の場合はM)です。そして、その年にその名前で生まれた赤ちゃんの数(2015年に生まれたEmmaという名前の赤ちゃんは20,355人でした)。
この情報を使用して、データをpandasにロードできます。
CSVデータをpandasにロード
カンマ区切り値のデータをpandasに読み込むには、pd.read_csv()関数を使用して、テキストファイルの名前と決定した列名を渡します。 2015年の誕生ファイルのデータを使用しているため、これを変数(この場合はnames2015)に割り当てます。
names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])ALT + ENTERと入力してコードを実行し、続行します。
これが確実に機能するように、表の上部を表示しましょう。
names2015.head()コードを実行してALT + ENTERを続行すると、次のような出力が表示されます。

テーブルには、各名前で生まれた赤ちゃんの名前、性別、および数の情報が列ごとに整理されています。
pandasオブジェクトを連結します
pandasオブジェクトを連結すると、namesディレクトリ内のすべての個別のテキストファイルを操作できるようになります。
これらを連結するには、最初に、入力されていないlist data typeに変数を割り当てて、リストを初期化する必要があります。
all_years = []それが完了したら、for loopを使用して、1880〜2015年の範囲のすべてのファイルを年ごとに繰り返し処理します。 2015年がループに含まれるように、2015年の終わりに+1を追加します。
all_years = []
for year in range(1880, 2015+1):ループ内で、string formatterを使用してこれらの各ファイルの異なる名前を処理し、各テキストファイルの値をリストに追加します。 これらの値をyear変数に渡します。 ここでも、Name、Sex、およびBabiesの数の列を指定します。
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))さらに、年ごとに列を作成して、それらを順番に保ちます。 これは、ループの進行中に-1のインデックスを使用してそれらを指すことにより、各反復後に実行できます。
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year最後に、pd.concat()関数を使用して、連結してpandasオブジェクトに追加します。 この情報を格納するために変数all_namesを使用します。
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
all_names = pd.concat(all_years)ALT + ENTERを使用してループを実行し、結果のテーブルの末尾(最下部の行)を呼び出して出力を検査できます。
all_names.tail()
これでデータセットが完成し、pandasで追加の作業を行う準備が整いました。
データのグループ化
pandasを使用すると、.groupby()関数を使用してデータを列ごとにグループ化できます。 完全なデータセットにall_names変数を使用すると、groupby()を使用してデータをさまざまなバケットに分割できます。
データセットを性別と年別にグループ化します。 次のように設定できます。
group_name = all_names.groupby(['Sex', 'Year'])コードを実行して、ALT + ENTERを続行できます。
この時点で、group_name変数を呼び出すだけで、次の出力が得られます。
Outputこれは、それがDataFrameGroupByオブジェクトであることを示しています。 このオブジェクトには、データをグループ化する方法についての指示がありますが、値を表示する方法については指示しません。
値を表示するには、指示を与える必要があります。 たとえば、.size()、.mean()、および.sum()を計算して、テーブルを返すことができます。
.size()から始めましょう:
group_name.size()コードを実行してALT + ENTERを続行すると、出力は次のようになります。
OutputSex Year
F 1880 942
1881 938
1882 1028
1883 1054
1884 1172
...このデータは適切に見えますが、より読みやすくなる可能性があります。 .unstack関数を追加することで、読みやすくすることができます。
group_name.size().unstack()コードを実行してALT + ENTERと入力し続けると、出力は次のようになります。

このデータが示すことは、各年に女性と男性の名前がいくつあったかということです。 たとえば、1889年には、1,479人の女性の名前と1,111人の男性の名前がありました。 2015年には、18,993人の女性の名前と13,959人の男性の名前がありました。 これは、時間の経過とともに名前の多様性が大きくなることを示しています。
生まれた赤ちゃんの総数を取得したい場合は、.sum()関数を使用できます。 これを、以前に作成した単一のyob2015.txtファイルから設定されたnames2015という小さなデータセットに適用してみましょう。
names2015.groupby(['Sex']).sum()ALT + ENTERと入力してコードを実行し、続行します。
 ).sum()出力]
).sum()出力]
これは、2015年に生まれた男性と女性の赤ちゃんの総数を示しています。ただし、その年に5回以上名前が使用された赤ちゃんのみがデータセットにカウントされます。
pandas.groupby()関数を使用すると、データを意味のあるグループにセグメント化できます。
ピボットテーブル
ピボットテーブルは、データの要約に役立ちます。 1つのテーブルに保存されたデータを自動的にソート、カウント、合計、または平均化できます。 次に、それらのアクションの結果を、その要約データの新しいテーブルに表示できます。
pandasでは、pivot_table()関数を使用してピボットテーブルを作成します。
ピボットテーブルを作成するには、まず、操作するDataFrameを呼び出し、次に表示するデータ、およびそれらのグループ化方法を呼び出します。
この例では、all_namesデータを使用して、一方のディメンションでは名前、もう一方のディメンションでは年でグループ化された赤ちゃんのデータを表示します。
pd.pivot_table(all_names, 'Babies', 'Name', 'Year')ALT + ENTERと入力してコードを実行して続行すると、次の出力が表示されます。
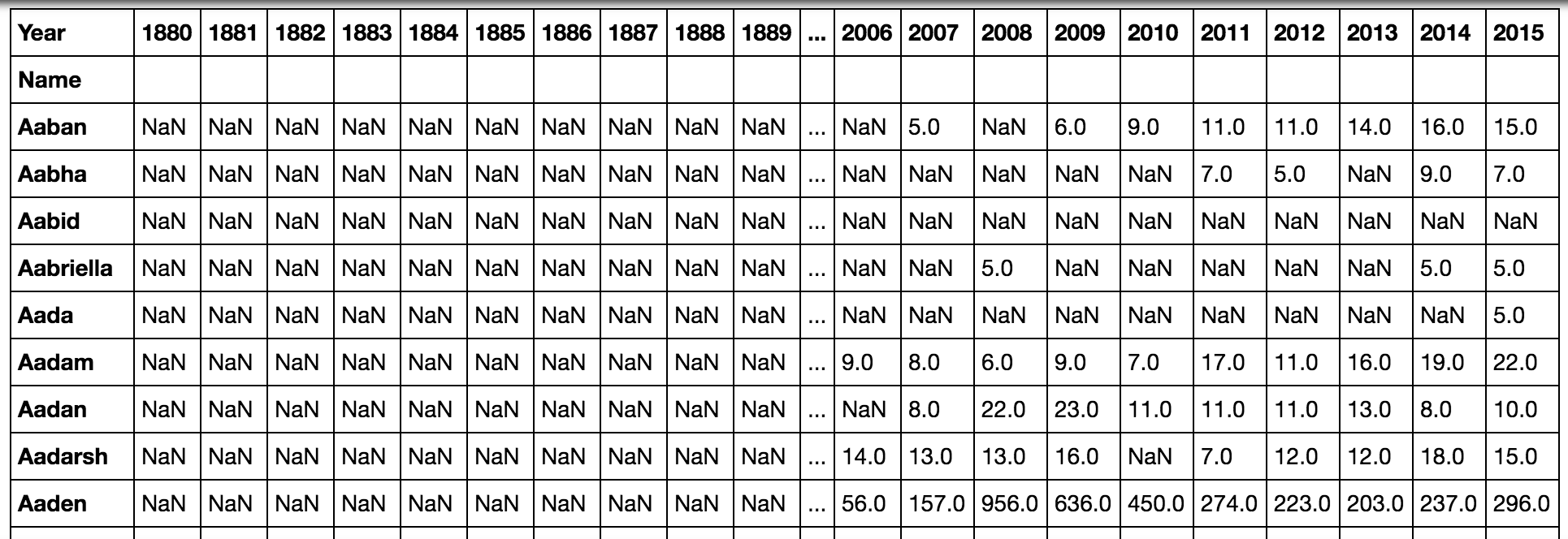
これは多くの空の値を示しているため、NameとYearを1つのケースでは行として、もう1つのケースでは列としてではなく、列として保持することができます。 これを行うには、データを角かっこでグループ化します。
pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])ALT + ENTERと入力してコードを実行して続行すると、このテーブルには、各名前の記録にある年のデータのみが表示されます。
OutputName Year
Aaban 2007 5.0
2009 6.0
2010 9.0
2011 11.0
2012 11.0
2013 14.0
2014 16.0
2015 15.0
Aabha 2011 7.0
2012 5.0
2014 9.0
2015 7.0
Aabid 2003 5.0
Aabriella 2008 5.0
2014 5.0
2015 5.0さらに、次のように、データをグループ化して、名前と性別を一方の次元として、年をもう一方の次元として持つことができます。
pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')コードを実行してALT + ENTERを続行すると、次の表が表示されます。
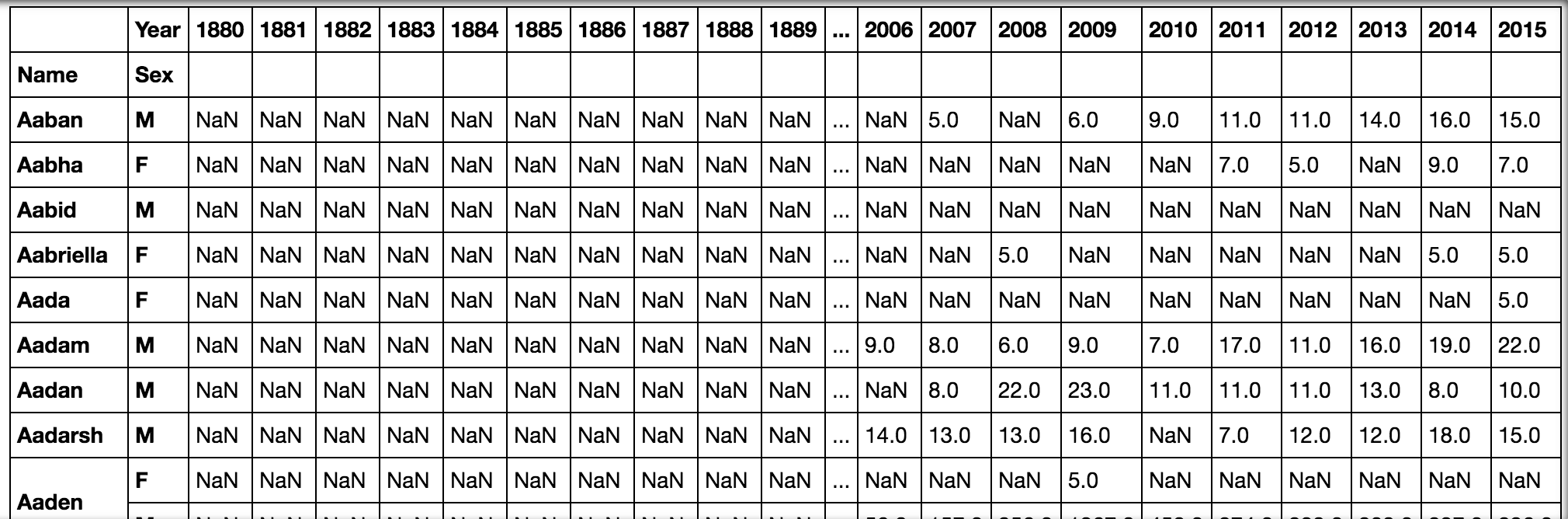 、 '年')出力]
、 '年')出力]
ピボットテーブルを使用すると、既存のテーブルから新しいテーブルを作成できるため、そのデータをどのようにグループ化するかを決定できます。
データを視覚化する
matplotlibなどの他のパッケージでpandasを使用することにより、ノートブック内のデータを視覚化できます。
長年にわたる特定の名前の人気に関するデータを視覚化します。 そのためには、インデックスを設定および並べ替えて、特定の名前の人気の変化を確認できるデータを再加工する必要があります。
pandasパッケージを使用すると、階層的またはマルチレベルのインデックス作成を実行できます。これにより、任意の数の次元でデータを格納および操作できます。
性別、名前、年の情報を使用してデータのインデックスを作成します。 また、インデックスを並べ替えます。
all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()ALT + ENTERと入力して実行し、次の行に進みます。ここで、ノートブックに新しいインデックス付きDataFrameが表示されます。
all_names_indexコードを実行してALT + ENTERを続行すると、出力は次のようになります。

次に、名前の人気度を経時的にプロットする関数を作成します。 関数name_plotを呼び出し、関数の実行時に呼び出すパラメーターとしてsexとnameを渡します。
def name_plot(sex, name):次に、作成したテーブルを保持するためにdataという変数を設定します。 また、インデックスの値で行を選択するために、pandas DataFramelocを使用します。 この場合、locは、sexとnameの両方のデータを参照して、MultiIndexのフィールドの組み合わせに基づく必要があります。
この構造を関数に書きましょう:
def name_plot(sex, name):
data = all_names_index.loc[sex, name]最後に、ppとしてインポートしたmatplotlib.pyplotを使用して値をプロットします。 次に、性別と名前のデータの値をインデックスに対してプロットします。これは、ここでは年です。
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
pp.plot(data.index, data.values)ALT + ENTERと入力して実行し、次のセルに移動します。 これで、選択した性別と名前で関数を呼び出すことができます。たとえば、名前がDanicaの女性の名前の場合はFです。
name_plot('F', 'Danica')ここでALT + ENTERと入力すると、次の出力が表示されます。
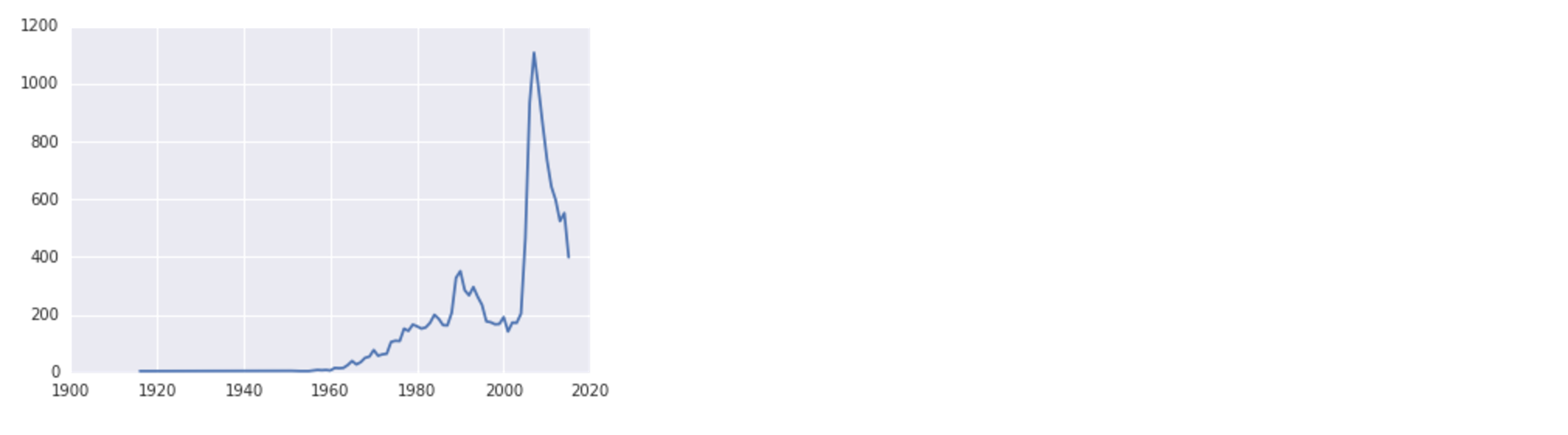
使用しているシステムによっては、フォントの置換に関する警告が表示される場合がありますが、データは引き続き正しくプロットされることに注意してください。
視覚化を見ると、女性の名前であるダニカの人気は1990年頃にわずかに上昇し、2010年の直前にピークに達したことがわかります。
作成した関数を使用して、複数の名前のデータをプロットすることができます。これにより、さまざまな名前の経時的な傾向を確認できます。
まず、プロットを少し大きくすることから始めましょう。
pp.figure(figsize = (18, 8))次に、プロットするすべての名前のリストを作成しましょう。
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']これで、forループを使用してリストを反復処理し、各名前のデータをプロットできます。 最初に、これらの性別ニュートラル名を女性名として試します。
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)このデータを理解しやすくするために、凡例を含めましょう。
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
pp.legend(names)ALT + ENTERと入力してコードを実行し、続行すると、次の出力が表示されます。
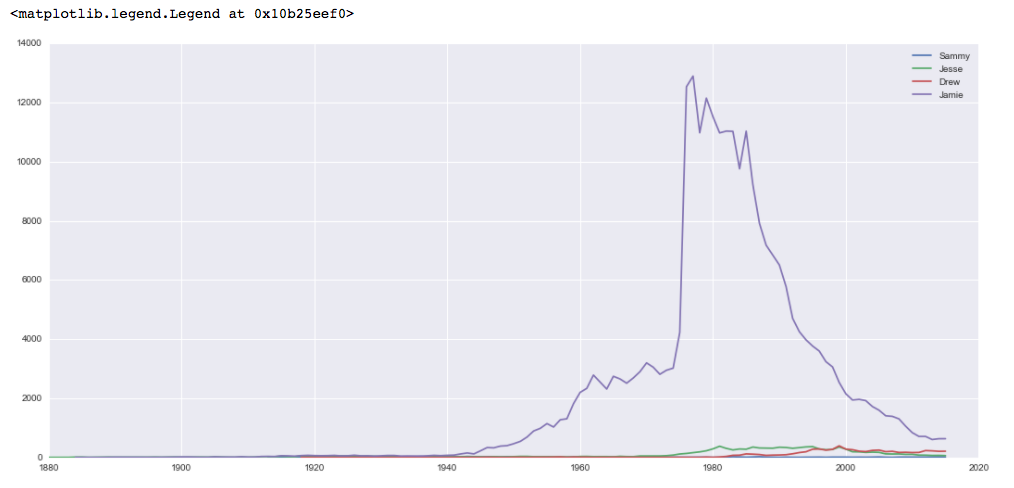
それぞれの名前は女性の名前として徐々に人気を集めていますが、ジェイミーの名前は1980年頃に女性の名前として圧倒的に人気がありました。
同じ名前をプロットしますが、今回は男性の名前としてプロットします。
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('M', name)
pp.legend(names)ここでも、ALT + ENTERと入力してコードを実行し、続行します。 グラフは次のようになります。
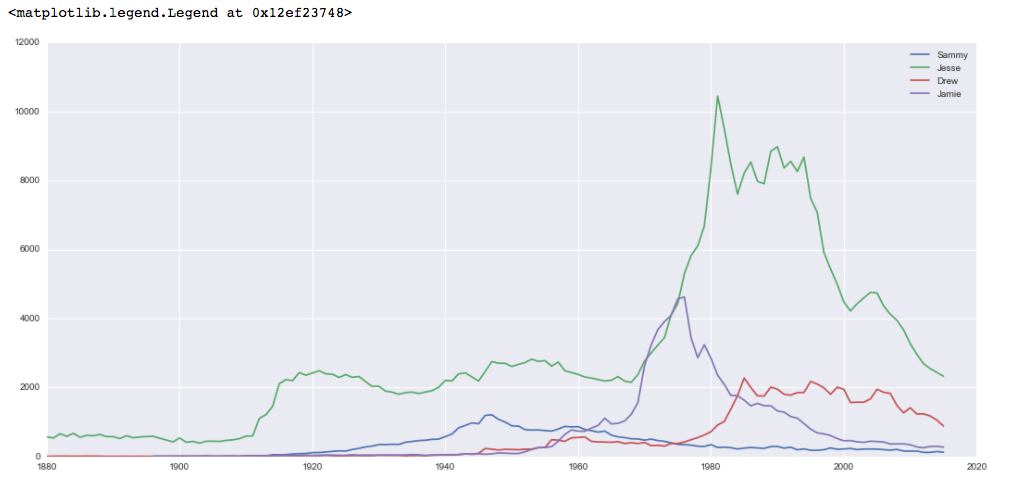
このデータは、Jesseが一般的に最も人気のある選択肢であり、1980年代と1990年代に特に人気があり、名前全体でより人気があります。
ここから、名前データの操作を続け、さまざまな名前とその人気に関する視覚化を作成し、さまざまなデータを参照して視覚化する他のスクリプトを作成できます。
結論
このチュートリアルでは、データの設定から、groupby()とpivot_table()でのデータのグループ化、MultiIndexでのデータのインデックス付け、pandasデータの視覚化まで、大規模なデータセットを操作する方法を紹介しました。 matplotlibパッケージを使用します。
多くの組織や機関は、pandasとデータの視覚化について引き続き学習するために使用できるデータセットを提供しています。 たとえば、米国政府はdata.govを介してデータを提供します。
How to Plot Data in Python 3 Using matplotlibおよびHow To Graph Word Frequency Using matplotlib with Python 3に関するガイドに従うことで、matplotlibを使用したデータの視覚化について詳しく知ることができます。