Pythonの非同期IO:完全なチュートリアル
非同期IOは、Pythonで専用のサポートを受けた並行プログラミング設計であり、Python 3.4から3.7、およびprobably beyondに急速に進化しています。
「並行性、並列処理、スレッド化、マルチプロセッシング。 すでに把握することはたくさんあります。 非同期IOはどこに収まりますか?」
このチュートリアルは、その質問に答えるのに役立つように構築されており、非同期IOに対するPythonのアプローチをよりしっかりと把握できます。
カバーする内容は次のとおりです。
-
Asynchronous IO (async IO):多数のプログラミング言語に実装されている言語に依存しないパラダイム(モデル)
-
async/await:コルーチンの定義に使用される2つの新しいPythonキーワード -
asyncio:コルーチンを実行および管理するための基盤とAPIを提供するPythonパッケージ
コルーチン(専用のジェネレーター関数)はPythonの非同期IOの中心であり、後で詳しく説明します。
Note:この記事では、async IOという用語を使用して非同期IOの言語に依存しない設計を示し、asyncioはPythonパッケージを指します。
開始する前に、このチュートリアルにあるasyncioおよびその他のライブラリを使用するように設定されていることを確認する必要があります。
Free Bonus:5 Thoughts On Python Masteryは、Python開発者向けの無料コースで、Pythonスキルを次のレベルに引き上げるために必要なロードマップと考え方を示しています。
環境を設定する
この記事全体、およびaiohttpパッケージとaiofilesパッケージをフォローするには、Python3.7以降が必要です。
$ python3.7 -m venv ./py37async
$ source ./py37async/bin/activate # Windows: .\py37async\Scripts\activate.bat
$ pip install --upgrade pip aiohttp aiofiles # Optional: aiodnsPython 3.7のインストールと仮想環境のセットアップについては、Python 3 Installation & Setup GuideまたはVirtual Environments Primerを確認してください。
それでは、飛び込みましょう。
非同期IOの10,000フィートビュー
非同期IOは、実証済みの従兄弟であるマルチプロセッシングとスレッドよりも少し知られていないものです。 このセクションでは、非同期IOとは何か、それが周囲のランドスケープにどのように適合するかについて、より詳細に説明します。
非同期IOはどこに収まりますか?
並行性と並列性は広範に及ぶ主題であり、容易に理解することはできません。 この記事では非同期IOとPythonでの実装に焦点を当てていますが、非同期IOがより大きく、めまいがするパズルにどのように適合するかについてのコンテキストを得るために、非同期IOを対応するものと比較するのに少し時間をかける価値があります。
Parallelismは、複数の操作を同時に実行することで構成されます。 Multiprocessingは並列処理を実行する手段であり、コンピューターの中央処理装置(CPUまたはコア)にタスクを分散させる必要があります。 マルチプロセッシングは、CPUにバインドされたタスクに最適です。厳密にバインドされたforループと数学的計算は、通常、このカテゴリに分類されます。
Concurrencyは、並列処理よりも少し広い用語です。 複数のタスクが重複して実行できることを示しています。 (並行性は並列性を意味しないと言われています。)
Threadingは、複数のthreadsが交代でタスクを実行する同時実行モデルです。 1つのプロセスに複数のスレッドを含めることができます。 Pythonは、そのGILのおかげでスレッド化と複雑な関係にありますが、それはこの記事の範囲を超えています。
スレッド化について知っておくべき重要なことは、IOにバインドされたタスクに適していることです。 CPUにバインドされたタスクは、コンピューターのコアが最初から最後まで継続的に懸命に動作することを特徴としていますが、IOにバインドされたジョブは、入力/出力の完了を待つことが多くなります。
上記を要約すると、並行処理には、マルチプロセッシング(CPUにバインドされたタスクに最適)とスレッド(IOにバインドされたタスクに適した)の両方が含まれます。 マルチプロセッシングは並列処理の一種であり、並列処理は特定のタイプ(サブセット)の並行処理です。 Python標準ライブラリは、そのmultiprocessing、threading、およびconcurrent.futuresパッケージを通じて長年のsupport for both of theseを提供してきました。
次は、新しいメンバーをミックスに追加します。 過去数年にわたって、別の設計がCPythonにさらに包括的に組み込まれました。非同期IOは、標準ライブラリのasyncioパッケージと、新しいasyncおよびawait言語キーワードによって有効になります。 明確にするために、非同期IOは新しく発明された概念ではなく、Go、C#、Scalaなどの他の言語やランタイム環境に存在しているか、組み込まれています。
asyncioパッケージは、Pythonドキュメントによってa library to write concurrent codeとして請求されます。 ただし、非同期IOはスレッドではなく、マルチプロセッシングでもありません。 これらの上に構築されていません。
実際、非同期IOはシングルスレッド、シングルプロセスの設計です。cooperative multitaskingを使用します。これは、このチュートリアルの終わりまでに具体化する用語です。 言い換えれば、非同期IOは、単一プロセスで単一スレッドを使用しているにもかかわらず、並行性の感覚を与えると言われています。 コルーチン(非同期IOの中心機能)は同時にスケジュールできますが、本質的に同時ではありません。
繰り返しますが、非同期IOは並行プログラミングのスタイルですが、並列処理ではありません。 マルチプロセッシングよりもスレッドと密接に連携していますが、これらの両方とはまったく異なり、並行処理の裏技のスタンドアロンメンバーです。
それはもう1つの用語を残します。 何かがasynchronousであるとはどういう意味ですか? これは厳密な定義ではありませんが、ここでの目的のために、2つのプロパティを考えることができます。
-
非同期ルーチンは、最終結果を待機しながら「一時停止」し、その間に他のルーチンを実行できます。
-
非同期コードは、上記のメカニズムにより、同時実行を促進します。 別の言い方をすれば、非同期コードは並行性のルックアンドフィールを提供します。
すべてをまとめた図を次に示します。 白の用語は概念を表し、緑の用語はそれらが実装または実行される方法を表します。
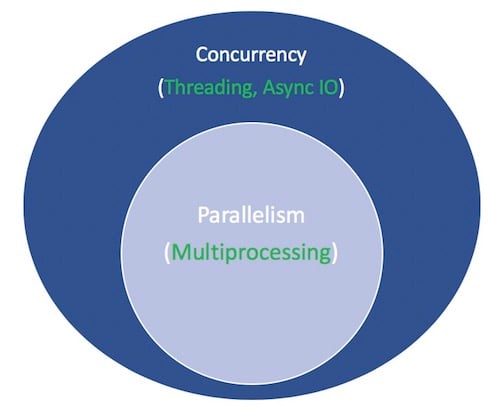
並行プログラミングモデルの比較については、これで終わりです。 このチュートリアルは、非同期IOであるサブコンポーネント、その使用方法、およびその周辺に出現したAPIに焦点を当てています。 スレッド化、マルチプロセッシング、非同期IOの詳細については、ここで一時停止して、Jim Andersonのoverview of concurrency in Pythonを確認してください。 ジムは私よりもずっとおもしろくて、私よりも多くのミーティングに参加してブートしました。
非同期IOの説明
非同期IOは、最初は直感に反し、逆説的に見えるかもしれません。 並行コードを容易にするものは、単一のスレッドと単一のCPUコアをどのように使用しますか? 私は例を思い付くのが得意ではなかったので、ミゲル・グリンバーグの2017年のPyConトークから1つを言い換えたいと思います。
チェスマスターのジュディ・ポルガルは、複数のアマチュア選手を演じるチェスの展示会を主催しています。 彼女には展示を行う方法が2つあります。同期的と非同期的です。
仮定:
24人の対戦相手
Juditは各チェスを5秒で移動させます
相手はそれぞれ55秒で移動します
ゲームは平均30ペア移動(合計60移動)
Synchronous version:Juditは、ゲームが完了するまで、一度に1つのゲームをプレイし、同時に2つのゲームをプレイすることはありません。 各ゲームには(55 + 5) * 30 == 1800秒または30分かかります。 展示全体は24 * 30 == 720分、または12 hoursかかります。
Asynchronous version:Juditはテーブルからテーブルに移動し、各テーブルで1回移動します。 彼女はテーブルを離れ、待機時間中に相手に次の動きをさせます。 24のゲームすべてで1回の移動には、Judit24 * 5 == 120秒、つまり2分かかります。 展示全体が120 * 30 == 3600秒、または1 hourに短縮されました。 (Source)
JuditPolgárは1人しかいません。JuditPolgárは両手のみで、自分で一度に1つだけ移動します。 ただし、非同期で再生すると、展示時間は12時間から1時間に短縮されます。 そのため、協調型マルチタスクは、プログラムのイベントループ(詳細は後述)が複数のタスクと通信して、それぞれが最適なタイミングで順番に実行できるようにするという凝った方法です。
非同期IOは、そうでなければ機能がブロックされる長い待機期間をとり、そのダウンタイム中に他の機能を実行できるようにします。 (ブロックする関数は、他の人が開始してから戻るまで実行することを効果的に禁止します。)
非同期IOは簡単ではありません
「できる限り非同期IOを使用してください。必要なときにスレッドを使用します。」真実は、耐久性のあるマルチスレッドコードの構築は難しく、エラーが発生しやすいということです。 非同期IOを使用すると、スレッド化された設計で発生する可能性のある潜在的なスピードバンプの一部が回避されます。
しかし、それはPythonの非同期IOが簡単だということではありません。 警告:表面レベルより少し下に行くと、非同期プログラミングも難しくなります! Pythonの非同期モデルは、コールバック、イベント、トランスポート、プロトコル、未来などの概念に基づいて構築されています。用語だけでは威圧できません。 そのAPIが絶えず変化しているという事実により、それは容易ではありません。
幸いなことに、asyncioは、その機能のほとんどが暫定的ではなくなるまで成熟しましたが、そのドキュメントは大幅に見直され、この主題に関するいくつかの質の高いリソースも出現し始めています。
asyncioパッケージとasync /await
設計として非同期IOの背景がわかったところで、Pythonの実装を調べてみましょう。 Pythonのasyncioパッケージ(Python 3.4で導入)とその2つのキーワードasyncとawaitは異なる目的を果たしますが、非同期コードの宣言、ビルド、実行、および管理を支援するために一緒になります。
async /await構文とネイティブコルーチン
A Word of Caution:インターネットで何を読んでいるかに注意してください。 Pythonの非同期IO APIは、Python 3.4からPython 3.7に急速に進化しました。 一部の古いパターンは使用されなくなり、最初は禁止されていたものが、新しい紹介を通じて許可されるようになりました。 私が知っているすべてのために、このチュートリアルもすぐに時代遅れのクラブに参加します。
非同期IOの中心にはコルーチンがあります。 コルーチンは、Pythonジェネレーター関数の特殊バージョンです。 ベースライン定義から始めて、ここで進むにつれてそれを構築していきましょう。コルーチンは、returnに達する前に実行を一時停止できる関数であり、しばらくの間、間接的に別のコルーチンに制御を渡すことができます。
後で、従来のジェネレーターがコルーチンにどのように再利用されるかについて、さらに深く掘り下げます。 今のところ、コルーチンの動作を理解する最も簡単な方法は、コルーチンの作成を開始することです。
没入型のアプローチを取り、非同期IOコードを作成しましょう。 この短いプログラムは非同期IOのHello Worldですが、そのコア機能を説明するのに大いに役立ちます。
#!/usr/bin/env python3
# countasync.py
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")このファイルを実行するときは、defとtime.sleep()だけで関数を定義する場合とは異なることに注意してください。
$ python3 countasync.py
One
One
One
Two
Two
Two
countasync.py executed in 1.01 seconds.この出力の順序は、非同期IOの中心です。 count()への各呼び出しとの通信は、単一のイベントループまたはコーディネーターです。 各タスクがawait asyncio.sleep(1)に達すると、関数はイベントループに向かって大声で叫び、「1秒間スリープします。 先に進み、その間に何か意味のあることをさせてください。」
これを同期バージョンと比較してください。
#!/usr/bin/env python3
# countsync.py
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")実行すると、順序と実行時間にわずかではあるが重要な変更があります。
$ python3 countsync.py
One
Two
One
Two
One
Two
countsync.py executed in 3.01 seconds.time.sleep()とasyncio.sleep()を使用することは平凡に思えるかもしれませんが、待機時間を伴う時間のかかるプロセスの代用として使用されます。 (待つことができる最もありふれたことは、基本的に何もしないsleep()呼び出しです。)つまり、time.sleep()は時間のかかるブロッキング関数呼び出しを表すことができますが、asyncio.sleep()はノンブロッキングコールの代わりになります(ただし、完了するまでに時間がかかります)。
次のセクションで説明するように、asyncio.sleep()を含む何かを待つことの利点は、周囲の関数が一時的に別の関数に制御を譲り、すぐに何かを実行しやすくなることです。 対照的に、time.sleep()またはその他のブロッキング呼び出しは、スリープ時間の間、トラック内のすべてを停止するため、非同期Pythonコードと互換性がありません。
非同期IOのルール
この時点で、async、await、およびそれらが作成するコルーチン関数のより正式な定義が順番になっています。 このセクションは少し密度が高いですが、async /awaitを取得することは有益なので、必要に応じてこれに戻ってください。
-
構文
async defは、native coroutineまたはasynchronous generatorのいずれかを導入します。 式async withおよびasync forも有効であり、後で表示されます。 -
キーワード
awaitは、関数制御をイベントループに戻します。 (周囲のコルーチンの実行を一時停止します。)Pythonがg()のスコープ内でawait f()式を検出した場合、これはawaitがイベントループに次のように通知する方法です。 t4)s私が待っているもの(f()の結果)が返されるまで。 それまでの間、何か他のものを実行させてください。」
コードでは、2番目の箇条書きはおおよそ次のようになります。
async def g():
# Pause here and come back to g() when f() is ready
r = await f()
return rまた、async /awaitをいつ、どのように使用できるか、使用できないかについての一連の厳密なルールがあります。 これらは、まだ構文を理解している場合でも、async /awaitの使用にすでに触れている場合でも便利です。
-
async defで導入する関数はコルーチンです。await、return、またはyieldを使用できますが、これらはすべてオプションです。async def noop(): passの宣言は有効です:-
awaitおよび/またはreturnを使用すると、コルーチン関数が作成されます。 コルーチン関数を呼び出すには、結果を取得するためにawaitする必要があります。 -
async defブロックでyieldを使用することはあまり一般的ではありません(そしてPythonでは最近合法です)。 これにより、asynchronous generatorが作成され、async forで繰り返し処理されます。 とりあえず非同期ジェネレーターを忘れて、awaitやreturnを使用するコルーチン関数の構文を理解することに集中してください。 -
async defで定義されたものは、yield fromを使用できません。これにより、SyntaxErrorが発生します。
-
-
def関数の外部でyieldを使用するのはSyntaxErrorであるのと同様に、async defコルーチンの外部でawaitを使用するのはSyntaxErrorです。 。 コルーチンの本体ではawaitのみを使用できます。
上記のいくつかのルールを要約するための簡潔な例を次に示します。
async def f(x):
y = await z(x) # OK - `await` and `return` allowed in coroutines
return y
async def g(x):
yield x # OK - this is an async generator
async def m(x):
yield from gen(x) # No - SyntaxError
def m(x):
y = await z(x) # Still no - SyntaxError (no `async def` here)
return y最後に、await f()を使用する場合、f()はawaitableであるオブジェクトである必要があります。 まあ、それはあまり役に立ちませんよね? 今のところ、待機可能なオブジェクトは、(1)別のコルーチン、または(2)イテレータを返す.__await__()dunderメソッドを定義するオブジェクトのいずれかであることを知っておいてください。 プログラムを作成している場合、大部分の目的のために、ケース1のみを心配する必要があります。
これにより、ポップアップが表示される可能性のあるもう1つの技術的な違いがわかります。関数をコルーチンとしてマークする古い方法は、通常のdef関数を@asyncio.coroutineで装飾することです。 結果はgenerator-based coroutineです。 async /await構文がPython 3.5に導入されて以来、この構造は時代遅れになっています。
これらの2つのコルーチンは本質的に同等です(両方とも待機可能です)が、最初のコルーチンはgenerator-basedであり、2番目のコルーチンはnative coroutineです。
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine, older syntax"""
yield from stuff()
async def py35_coro():
"""Native coroutine, modern syntax"""
await stuff()自分でコードを記述している場合は、暗黙的ではなく明示的であるために、ネイティブコルーチンを好みます。 Python 3.10では、ジェネレーターベースのコルーチンはremovedになります。
このチュートリアルの後半では、説明のためにジェネレータベースのコルーチンに触れます。 async /awaitが導入された理由は、コルーチンをPythonのスタンドアロン機能にし、通常のジェネレーター関数と簡単に区別できるようにして、あいまいさを減らすためです。
deliberately outdated xasync /awaitであるジェネレーターベースのコルーチンに行き詰まらないでください。 それらには独自の小さなルールセットがあり(たとえば、awaitはジェネレーターベースのコルーチンでは使用できません)、async /await構文に固執する場合はほとんど関係ありません。
それ以上苦労することなく、さらにいくつかの複雑な例を取り上げましょう。
非同期IOが待機時間を短縮する方法の一例を次に示します。[0、10]の範囲のランダムな整数を生成し続けるコルーチンmakerandom()が与えられ、そのうちの1つがしきい値を超えるまで、このコルーチンは、互いに連続して完了するのを待つ必要はありません。 上記の2つのスクリプトのパターンは、わずかな変更を加えてほぼ追跡できます。
#!/usr/bin/env python3
# rand.py
import asyncio
import random
# ANSI colors
c = (
"\033[0m", # End of color
"\033[36m", # Cyan
"\033[91m", # Red
"\033[35m", # Magenta
)
async def makerandom(idx: int, threshold: int = 6) -> int:
print(c[idx + 1] + f"Initiated makerandom({idx}).")
i = random.randint(0, 10)
while i <= threshold:
print(c[idx + 1] + f"makerandom({idx}) == {i} too low; retrying.")
await asyncio.sleep(idx + 1)
i = random.randint(0, 10)
print(c[idx + 1] + f"---> Finished: makerandom({idx}) == {i}" + c[0])
return i
async def main():
res = await asyncio.gather(*(makerandom(i, 10 - i - 1) for i in range(3)))
return res
if __name__ == "__main__":
random.seed(444)
r1, r2, r3 = asyncio.run(main())
print()
print(f"r1: {r1}, r2: {r2}, r3: {r3}")色付けされた出力は、私ができる以上のことを言っており、このスクリプトがどのように実行されるかについての感覚を与えます:
このプログラムは、1つのメインコルーチンmakerandom()を使用し、3つの異なる入力で同時に実行します。 ほとんどのプログラムには、小さなモジュール式コルーチンと、小さなコルーチンのそれぞれを連結するのに役立つ1つのラッパー関数が含まれます。 次に、main()を使用して、反復可能またはプール全体に中央コルーチンをマッピングすることにより、タスク(将来)を収集します。
このミニチュアの例では、プールはrange(3)です。 後で説明するより完全な例では、要求、解析、および同時処理が必要なURLのセットであり、main()は各URLのルーチン全体をカプセル化します。
「ランダムな整数を作成する」(何よりもCPUバウンドである)は、asyncioの候補としては最良の選択ではないかもしれませんが、例ではasyncio.sleep()が存在することを模倣するように設計されています。待機時間が不確実なIOバウンドプロセス。 たとえば、asyncio.sleep()呼び出しは、メッセージアプリケーション内の2つのクライアント間でそれほどランダムではない整数を送受信することを表す場合があります。
非同期IOデザインパターン
非同期IOには、独自の可能なスクリプトデザインのセットが付属しています。これについては、このセクションで紹介します。
コルーチンの連鎖
コルーチンの重要な特徴は、それらを一緒に連鎖できることです。 (コルーチンオブジェクトが待機しているため、別のコルーチンがawaitできることを忘れないでください。)これにより、プログラムをより小さく、管理しやすく、リサイクル可能なコルーチンに分割できます。
#!/usr/bin/env python3
# chained.py
import asyncio
import random
import time
async def part1(n: int) -> str:
i = random.randint(0, 10)
print(f"part1({n}) sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-1"
print(f"Returning part1({n}) == {result}.")
return result
async def part2(n: int, arg: str) -> str:
i = random.randint(0, 10)
print(f"part2{n, arg} sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-2 derived from {arg}"
print(f"Returning part2{n, arg} == {result}.")
return result
async def chain(n: int) -> None:
start = time.perf_counter()
p1 = await part1(n)
p2 = await part2(n, p1)
end = time.perf_counter() - start
print(f"-->Chained result{n} => {p2} (took {end:0.2f} seconds).")
async def main(*args):
await asyncio.gather(*(chain(n) for n in args))
if __name__ == "__main__":
import sys
random.seed(444)
args = [1, 2, 3] if len(sys.argv) == 1 else map(int, sys.argv[1:])
start = time.perf_counter()
asyncio.run(main(*args))
end = time.perf_counter() - start
print(f"Program finished in {end:0.2f} seconds.")出力に注意してください。part1()は可変時間スリープし、part2()は結果が利用可能になると作業を開始します。
$ python3 chained.py 9 6 3
part1(9) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(3) sleeping for 0 seconds.
Returning part1(3) == result3-1.
part2(3, 'result3-1') sleeping for 4 seconds.
Returning part1(9) == result9-1.
part2(9, 'result9-1') sleeping for 7 seconds.
Returning part1(6) == result6-1.
part2(6, 'result6-1') sleeping for 4 seconds.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
Program finished in 11.01 seconds.この設定では、main()の実行時間は、一緒に収集してスケジュールするタスクの最大実行時間と等しくなります。
キューを使用する
asyncioパッケージは、queueモジュールのクラスと同様に設計されたqueue classesを提供します。 これまでの例では、実際にはキュー構造は必要ありませんでした。 chained.pyでは、各タスク(future)は、明示的に相互に待機し、チェーンごとに1つの入力を通過するコルーチンのセットで構成されます。
非同期IOでも機能する代替構造があります。相互に関連付けられていない多数のプロデューサーが、アイテムをキューに追加します。 各プロデューサーは、時間をずらしてランダムに予告なしに複数のアイテムをキューに追加できます。 消費者のグループは、他の信号を待たずに、欲張りにキューからアイテムを引き出します。
この設計では、個々の消費者から生産者への連鎖はありません。 消費者は、生産者の数や、キューに追加されるアイテムの累積数さえも事前に知りません。
個々の生産者または消費者は、それぞれキューにアイテムを入れたり抽出したりするのにさまざまな時間がかかります。 キューは、生産者と消費者が直接対話せずに生産者と消費者と通信できるスループットとして機能します。
Note:queue.Queue()のスレッドセーフのため、キューはスレッドプログラムでよく使用されますが、非同期IOに関してはスレッドセーフについて心配する必要はありません。 (例外は2つを組み合わせる場合ですが、このチュートリアルでは行いません。)
キューの使用例の1つは(この場合のように)、キューがプロデューサーとコンシューマーのトランスミッタとして機能することです。
このプログラムの同期バージョンは非常に悲惨に見えます。ブロッキングプロデューサーのグループは、一度に1つのプロデューサーをキューにアイテムを順次追加します。 すべてのプロデューサーが完了して初めて、アイテムごとに1人のコンシューマーが一度に処理し、キューを処理できます。 この設計には膨大な遅延があります。 アイテムはすぐに取り出されて処理されるのではなく、キューに放置される場合があります。
非同期バージョンasyncq.pyは以下のとおりです。 このワークフローの難しい部分は、生産が行われたことを消費者に知らせる必要があるということです。 そうしないと、キューが完全に処理されるため、await q.get()が無期限にハングしますが、消費者は本番環境が完了したことを認識できません。
(main()をまっすぐにするのを手伝ってくれたStackOverflowuserからの助けに大いに感謝します:キーはawait q.join()であり、キュー内のすべてのアイテムが受信されて処理されるまでブロックします。次に、コンシューマータスクをキャンセルします。そうしないと、ハングアップして、追加のキューアイテムが表示されるのを際限なく待ちます。)
これが完全なスクリプトです。
#!/usr/bin/env python3
# asyncq.py
import asyncio
import itertools as it
import os
import random
import time
async def makeitem(size: int = 5) -> str:
return os.urandom(size).hex()
async def randsleep(a: int = 1, b: int = 5, caller=None) -> None:
i = random.randint(0, 10)
if caller:
print(f"{caller} sleeping for {i} seconds.")
await asyncio.sleep(i)
async def produce(name: int, q: asyncio.Queue) -> None:
n = random.randint(0, 10)
for _ in it.repeat(None, n): # Synchronous loop for each single producer
await randsleep(caller=f"Producer {name}")
i = await makeitem()
t = time.perf_counter()
await q.put((i, t))
print(f"Producer {name} added <{i}> to queue.")
async def consume(name: int, q: asyncio.Queue) -> None:
while True:
await randsleep(caller=f"Consumer {name}")
i, t = await q.get()
now = time.perf_counter()
print(f"Consumer {name} got element <{i}>"
f" in {now-t:0.5f} seconds.")
q.task_done()
async def main(nprod: int, ncon: int):
q = asyncio.Queue()
producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)]
consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)]
await asyncio.gather(*producers)
await q.join() # Implicitly awaits consumers, too
for c in consumers:
c.cancel()
if __name__ == "__main__":
import argparse
random.seed(444)
parser = argparse.ArgumentParser()
parser.add_argument("-p", "--nprod", type=int, default=5)
parser.add_argument("-c", "--ncon", type=int, default=10)
ns = parser.parse_args()
start = time.perf_counter()
asyncio.run(main(**ns.__dict__))
elapsed = time.perf_counter() - start
print(f"Program completed in {elapsed:0.5f} seconds.")最初のいくつかのコルーチンは、ランダムな文字列、小数秒のパフォーマンスカウンター、およびランダムな整数を返すヘルパー関数です。 プロデューサーは1〜5個のアイテムをキューに入れます。 各アイテムは(i, t)のタプルです。ここで、iはランダムな文字列であり、tはプロデューサーがタプルをキューに入れようとする時刻です。
消費者がアイテムを引き出すとき、アイテムが入れられたタイムスタンプを使用して、アイテムがキューに座っている経過時間を単に計算します。
asyncio.sleep()は、他のより複雑なコルーチンを模倣するために使用され、通常のブロック関数である場合、時間を浪費し、他のすべての実行をブロックすることに注意してください。
これは、2つのプロデューサーと5つのコンシューマーによるテスト実行です。
$ python3 asyncq.py -p 2 -c 5
Producer 0 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 4 sleeping for 4 seconds.
Producer 0 added <377b1e8f82> to queue.
Producer 0 sleeping for 5 seconds.
Producer 1 added <413b8802f8> to queue.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 sleeping for 4 seconds.
Producer 0 added <06c055b3ab> to queue.
Producer 0 sleeping for 1 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 sleeping for 4 seconds.
Producer 0 added <17a8613276> to queue.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 sleeping for 5 seconds.
Program completed in 9.00954 seconds.この場合、アイテムはほんの一瞬で処理されます。 遅延の原因は2つあります。
-
標準で、ほとんど回避できないオーバーヘッド
-
アイテムがキューに表示されたときにすべての消費者が眠っている状況
幸いなことに、2番目の理由に関しては、数百または数千の消費者に対応することは完全に正常です。 python3 asyncq.py -p 5 -c 100で問題はないはずです。 ここでのポイントは、理論的には、異なるシステムの異なるユーザーがプロデューサーとコンシューマーの管理を制御し、キューが中央スループットとして機能することです。
これまでのところ、あなたは火の中に投げ込まれ、asyncとawaitで定義されたコルーチンを呼び出すasyncioの3つの関連する例を見てきました。 Pythonで現代のコルーチンがどのようになったのかを完全にフォローしていない場合、または単に深く掘り下げたい場合は、次のセクションから正方形から始めます。
ジェネレーターの非同期IOのルーツ
前に、より明確なネイティブコルーチンによって時代遅れにされた古いスタイルのジェネレータベースのコルーチンの例を見てきました。 この例は、少し調整して再表示する価値があります。
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine"""
# No need to build these yourself, but be aware of what they are
s = yield from stuff()
return s
async def py35_coro():
"""Native coroutine, modern syntax"""
s = await stuff()
return s
async def stuff():
return 0x10, 0x20, 0x30実験として、py34_coro()またはpy35_coro()を単独で、awaitなしで、またはasyncio.run()または他のasyncio「磁器」への呼び出しなしで呼び出すとどうなりますか" 機能? コルーチンを単独で呼び出すと、コルーチンオブジェクトが返されます。
>>>
>>> py35_coro()
これは表面上はあまり面白くないです。 コルーチンを単独で呼び出した結果は、待機可能なcoroutine objectです。
クイズの時間:Pythonの他の機能は次のようになりますか? (Pythonのどの機能が、それ自体で呼び出されたときに実際に「多くのことをしない」のですか?)
コルーチンは内部で強化されたジェネレーターであるため、この質問への回答としてgeneratorsを考えていることを願っています。 この点で動作は似ています:
>>>
>>> def gen():
... yield 0x10, 0x20, 0x30
...
>>> g = gen()
>>> g # Nothing much happens - need to iterate with `.__next__()`
>>> next(g)
(16, 32, 48) ジェネレーター関数は、たまたま非同期IOの基盤です(古い@asyncio.coroutineラッパーではなくasync defでコルーチンを宣言するかどうかに関係なく)。 技術的には、awaitはyieldよりもyield fromに類似しています。 (ただし、yield from x()はfor i in x(): yield iを置き換える単なる構文糖衣であることを忘れないでください。)
非同期IOに関連するジェネレータの重要な機能の1つは、ジェネレータを自由に効果的に停止および再起動できることです。 たとえば、ジェネレータオブジェクトの反復をbreakで実行し、後で残りの値の反復を再開できます。 ジェネレーター関数がyieldに達すると、その値を生成しますが、その後の値を生成するように指示されるまでアイドル状態になります。
これは例を通して具体化できます:
>>>
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)awaitキーワードも同様に動作し、コルーチンがそれ自体を一時停止し、他のコルーチンが機能するようにするブレークポイントをマークします。 この場合、「一時停止」とは、一時的に制御権を放棄したが、完全に終了または終了していないコルーチンを意味します。 yield、さらにはyield fromとawaitは、ジェネレーターの実行のブレークポイントをマークすることに注意してください。
これは、関数とジェネレーターの根本的な違いです。 関数はオールオアナッシングです。 開始すると、returnに達するまで停止せず、その値を呼び出し元(呼び出し元の関数)にプッシュします。 一方、ジェネレーターは、yieldに達するたびに一時停止し、それ以上進みません。 この値を呼び出しスタックにプッシュできるだけでなく、next()を呼び出して再開するときに、ローカル変数を保持できます。
ジェネレータの2番目のあまり知られていない機能も重要です。 .send()メソッドを使用して、ジェネレーターに値を送信することもできます。 これにより、ジェネレーター(およびコルーチン)は、ブロックせずに(await)を相互に呼び出すことができます。 これは主に舞台裏でコルーチンを実装するために重要であるため、この機能の詳細は説明しませんが、実際に直接使用する必要はありません。
さらに探索することに興味がある場合は、コルーチンが正式に導入されたPEP 342から始めることができます。 Brett CannonのHow the Heck Does Async-Await Work in Pythonも、PYMOTW writeup on asyncioと同様に読みやすいです。 最後に、David BeazleyのCurious Course on Coroutines and Concurrencyがあります。これは、コルーチンが実行されるメカニズムを深く掘り下げています。
上記のすべての記事をいくつかの文章にまとめてみましょう。これらのコルーチンが実際に実行される特に型破りなメカニズムがあります。 それらの結果は、.send()メソッドが呼び出されたときにスローされる例外オブジェクトの属性です。 これらのすべてにはさらに奇妙な詳細がありますが、おそらく実際に言語のこの部分を使用するのに役立つことはないので、今から先に進みましょう。
物事をまとめるために、ジェネレーターとしてのコルーチンのトピックに関する重要なポイントを以下に示します。
-
コルーチンは、ジェネレーターメソッドの特性を利用するrepurposed generatorsです。
-
古いジェネレータベースのコルーチンは、
yield fromを使用してコルーチンの結果を待ちます。 ネイティブコルーチンの最新のPython構文は、コルーチンの結果を待機する手段として、yield fromをawaitに置き換えるだけです。awaitはyield fromに類似しており、多くの場合、そのように考えると役立ちます。 -
awaitの使用は、ブレークポイントをマークするシグナルです。 これにより、コルーチンは一時的に実行を一時停止し、プログラムが後でそれに戻ることを許可します。
その他の機能:async forおよび非同期ジェネレーター+内包表記
Pythonは、プレーンなasync /awaitに加えて、async forがasynchronous iteratorを反復処理できるようにします。 非同期イテレーターの目的は、反復されるときに各段階で非同期コードを呼び出すことができるようにすることです。
この概念の自然な拡張はasynchronous generatorです。 ネイティブコルーチンでawait、return、またはyieldを使用できることを思い出してください。 コルーチン内でのyieldの使用は、Python 3.6で(PEP 525を介して)可能になりました。これにより、awaitとyieldを同じコルーチン関数本体で使用できるようにする目的で非同期ジェネレーターが導入されました。
>>>
>>> async def mygen(u: int = 10):
... """Yield powers of 2."""
... i = 0
... while i < u:
... yield 2 ** i
... i += 1
... await asyncio.sleep(0.1)大事なことを言い忘れましたが、Pythonはasync forでasynchronous comprehensionを有効にします。 同期のいとこと同様、これは大部分が構文糖です:
>>>
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]これは重要な違いです:neither asynchronous generators nor comprehensions make the iteration concurrent。 それらが行うことは、同期の対応物のルックアンドフィールを提供することですが、問題のループが他のコルーチンを実行するためにイベントループに制御を放棄する機能を備えています。
つまり、非同期イテレーターと非同期ジェネレーターは、シーケンスまたはイテレーターを介して一部の関数を同時にマップするようには設計されていません。 単にコルーチンを囲むことで、他のタスクが順番を回せるように設計されています。 async forおよびasync withステートメントは、プレーンなforまたはwithを使用すると、コルーチンのawaitの性質が「壊れる」場合にのみ必要です。 非同期性と同時実行性のこの区別は、把握すべき重要なものです。
イベントループとasyncio.run()
イベントループは、コルーチンを監視し、何がアイドル状態であるかについてフィードバックを受け取り、その間に実行できるものを探すwhile Trueループのようなものと考えることができます。 コルーチンが待機しているものが利用可能になったときに、アイドルコルーチンを起動することができます。
これまで、イベントループの管理全体は、1つの関数呼び出しによって暗黙的に処理されてきました。
asyncio.run(main()) # Python 3.7+Python 3.7で導入されたasyncio.run()は、イベントループを取得し、タスクが完了としてマークされるまでタスクを実行してから、イベントループを閉じる役割を果たします。
get_event_loop()を使用して、asyncioイベントループを管理するためのより長い方法があります。 典型的なパターンは次のようになります。
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()古い例ではおそらくloop.get_event_loop()が浮かんでいますが、イベントループ管理を微調整する特別な必要がない限り、ほとんどのプログラムではasyncio.run()で十分です。
Pythonプログラム内でイベントループを操作する必要がある場合、loopは、loop.is_running()およびloop.is_closed()のイントロスペクションをサポートする古き良きPythonオブジェクトです。 ループを引数として渡すことにより、scheduling a callbackのように、より微調整された制御を取得する必要がある場合は、これを操作できます。
さらに重要なのは、イベントループの仕組みについて少し表面的に理解することです。 イベントループについて強調する価値があるいくつかのポイントを次に示します。
#1:コルーチンは、イベントループに関連付けられるまで、それ自体ではあまり機能しません。
前に発電機の説明でこの点を見ましたが、もう一度説明する価値があります。 他の人を待つメインコルーチンがある場合、それを単独で呼び出すだけではほとんど効果がありません。
>>>
>>> import asyncio
>>> async def main():
... print("Hello ...")
... await asyncio.sleep(1)
... print("World!")
>>> routine = main()
>>> routine
main()コルーチン(将来のオブジェクト)をイベントループで実行するようにスケジュールすることにより、asyncio.run()を使用して実際に実行を強制することを忘れないでください。
>>>
>>> asyncio.run(routine)
Hello ...
World!(他のコルーチンはawaitで実行できます。 main()だけをasyncio.run()でラップするのが一般的であり、awaitでチェーンされたコルーチンがそこから呼び出されます。)
#2:デフォルトでは、非同期IOイベントループは単一のスレッドと単一のCPUコアで実行されます。 通常、1つのCPUコアで1つのシングルスレッドイベントループを実行するだけで十分です。 複数のコアでイベントループを実行することもできます。 詳細については、このtalk by John Reeseを確認してください。また、ラップトップが自然発火する可能性があることに注意してください。
#3.イベントループはプラグ可能です。 つまり、本当に必要な場合は、独自のイベントループ実装を記述し、タスクをまったく同じように実行させることができます。 これは、Cythonのイベントループの実装であるuvloopパッケージで見事に示されています。
それが「プラグ可能なイベントループ」という用語の意味です。コルーチン自体の構造とは関係なく、イベントループの実装を使用できます。 asyncioパッケージ自体はtwo different event loop implementationsに同梱されており、デフォルトはselectorsモジュールに基づいています。 (2番目の実装はWindows専用に構築されています。)
完全なプログラム:非同期リクエスト
ここまでで、これで楽しさと痛みのない部分の時間です。 このセクションでは、非常に高速な非同期HTTPクライアント/サーバーフレームワークであるaiohttpを使用して、WebスクレイピングURLコレクターareq.pyを構築します。 (クライアント部分だけが必要です。)このようなツールを使用して、サイトのクラスター間の接続をマップし、リンクをdirected graphで形成することができます。
Note:Pythonのrequestsパッケージが非同期IOと互換性がないのはなぜか疑問に思われるかもしれません。 requestsはurllib3の上に構築され、urllib3はPythonのhttpおよびsocketモジュールを使用します。
デフォルトでは、ソケット操作はブロックされています。 これは、.get()が待機できないため、Pythonがawait requests.get(url)を好まないことを意味します。 対照的に、aiohttpのほとんどすべては、session.request()やresponse.text()などの待機可能なコルーチンです。 それ以外の点では優れたパッケージですが、非同期コードでrequestsを使用することで、自分自身に不利益をもたらしています。
高レベルのプログラム構造は次のようになります。
-
ローカルファイル
urls.txtから一連のURLを読み取ります。 -
URLのGETリクエストを送信し、結果のコンテンツをデコードします。 これが失敗した場合、URLのためにそこで停止します。
-
応答のHTMLで
hrefタグ内のURLを検索します。 -
結果を
foundurls.txtに書き込みます。 -
上記のすべてを可能な限り非同期で同時に実行します。 (要求には
aiohttpを使用し、ファイル追加にはaiofilesを使用します。 これらは、非同期IOモデルに適したIOの2つの主要な例です。
urls.txtの内容は次のとおりです。 巨大ではなく、ほとんどがトラフィックの多いサイトが含まれています。
$ cat urls.txt
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txtリストの2番目のURLは404応答を返す必要があります。これは適切に処理する必要があります。 このプログラムの拡張バージョンを実行している場合は、おそらくサーバーの切断や無限のリダイレクトなど、これよりもはるかに難しい問題に対処する必要があります。
リクエスト自体は、セッションの内部接続プールの再利用を活用するために、単一のセッションを使用して作成する必要があります。
完全なプログラムを見てみましょう。 以下の手順を順を追って説明します。
#!/usr/bin/env python3
# areq.py
"""Asynchronously get links embedded in multiple pages' HMTL."""
import asyncio
import logging
import re
import sys
from typing import IO
import urllib.error
import urllib.parse
import aiofiles
import aiohttp
from aiohttp import ClientSession
logging.basicConfig(
format="%(asctime)s %(levelname)s:%(name)s: %(message)s",
level=logging.DEBUG,
datefmt="%H:%M:%S",
stream=sys.stderr,
)
logger = logging.getLogger("areq")
logging.getLogger("chardet.charsetprober").disabled = True
HREF_RE = re.compile(r'href="(.*?)"')
async def fetch_html(url: str, session: ClientSession, **kwargs) -> str:
"""GET request wrapper to fetch page HTML.
kwargs are passed to `session.request()`.
"""
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
logger.info("Got response [%s] for URL: %s", resp.status, url)
html = await resp.text()
return html
async def parse(url: str, session: ClientSession, **kwargs) -> set:
"""Find HREFs in the HTML of `url`."""
found = set()
try:
html = await fetch_html(url=url, session=session, **kwargs)
except (
aiohttp.ClientError,
aiohttp.http_exceptions.HttpProcessingError,
) as e:
logger.error(
"aiohttp exception for %s [%s]: %s",
url,
getattr(e, "status", None),
getattr(e, "message", None),
)
return found
except Exception as e:
logger.exception(
"Non-aiohttp exception occured: %s", getattr(e, "__dict__", {})
)
return found
else:
for link in HREF_RE.findall(html):
try:
abslink = urllib.parse.urljoin(url, link)
except (urllib.error.URLError, ValueError):
logger.exception("Error parsing URL: %s", link)
pass
else:
found.add(abslink)
logger.info("Found %d links for %s", len(found), url)
return found
async def write_one(file: IO, url: str, **kwargs) -> None:
"""Write the found HREFs from `url` to `file`."""
res = await parse(url=url, **kwargs)
if not res:
return None
async with aiofiles.open(file, "a") as f:
for p in res:
await f.write(f"{url}\t{p}\n")
logger.info("Wrote results for source URL: %s", url)
async def bulk_crawl_and_write(file: IO, urls: set, **kwargs) -> None:
"""Crawl & write concurrently to `file` for multiple `urls`."""
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
write_one(file=file, url=url, session=session, **kwargs)
)
await asyncio.gather(*tasks)
if __name__ == "__main__":
import pathlib
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
here = pathlib.Path(__file__).parent
with open(here.joinpath("urls.txt")) as infile:
urls = set(map(str.strip, infile))
outpath = here.joinpath("foundurls.txt")
with open(outpath, "w") as outfile:
outfile.write("source_url\tparsed_url\n")
asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls))このスクリプトは、最初のおもちゃプログラムよりも長いので、分解してみましょう。
定数HREF_REは、最終的に検索するものを抽出するための正規表現であり、HTML内のhrefタグです。
>>>
>>> HREF_RE.search('Go to Real Python')
コルーチンfetch_html()は、GETリクエストのラッパーであり、リクエストを作成し、結果のページHTMLをデコードします。 200以外のステータスの場合、リクエストを作成し、レスポンスを待機し、すぐに発生します。
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()ステータスに問題がない場合、fetch_html()はページのHTML(str)を返します。 特に、この関数では例外処理は行われません。 ロジックは、その例外を呼び出し元に伝播し、そこで処理できるようにすることです。
html = await resp.text()awaitsession.request()とresp.text()は、待機可能なコルーチンであるためです。 それ以外の場合、要求/応答サイクルはアプリケーションの時間のかかる長い部分になりますが、非同期IOを使用すると、fetch_html()を使用すると、すでにURLの解析や書き込みなど、すぐに利用できる他のジョブでイベントループを機能させることができます。フェッチされました。
コルーチンのチェーンの次はparse()です。これは、指定されたURLをfetch_html()で待機し、そのページのHTMLからすべてのhrefタグを抽出して、それぞれが有効であることを確認します。絶対パスとしてフォーマットします。
確かに、parse()の2番目の部分はブロックされていますが、これは迅速な正規表現の一致と、検出されたリンクが絶対パスになるようにすることで構成されています。
この特定のケースでは、この同期コードは迅速かつ目立たないはずです。 ただし、その行がyield、await、またはreturnを使用しない限り、特定のコルーチン内の行は他のコルーチンをブロックすることに注意してください。 解析がより集中的なプロセスであった場合は、この部分をloop.run_in_executor()を使用して独自のプロセスで実行することを検討してください。
次に、コルーチンwrite()はファイルオブジェクトと単一のURLを受け取り、parse()が解析されたURLのsetを返すのを待ち、それぞれをソースURLとともに非同期でファイルに書き込みます。非同期ファイルIOのパッケージであるaiofilesを使用します。
最後に、bulk_crawl_and_write()は、スクリプトのコルーチンチェーンへの主要なエントリポイントとして機能します。 単一のセッションを使用し、最終的にurls.txtから読み取られるURLごとにタスクが作成されます。
言及するに値するいくつかの追加ポイントを次に示します。
-
デフォルトの
ClientSessionには、最大100の接続が開いているadapterがあります。 これを変更するには、asyncio.connector.TCPConnectorのインスタンスをClientSessionに渡します。 ホストごとに制限を指定することもできます。 -
セッション全体と個々のリクエストの両方に最大timeoutsを指定できます。
-
このスクリプトは、asynchronous context managerで機能する
async withも使用します。 同期から非同期のコンテキストマネージャーへの移行は非常に簡単なので、この概念にセクション全体を費やしたことはありません。 後者は、.__exit__()と.__enter__()ではなく、.__aenter__()と.__aexit__()を定義する必要があります。 ご想像のとおり、async withは、async defで宣言されたコルーチン関数内でのみ使用できます。
もう少し詳しく調べたい場合は、GitHubにあるこのチュートリアルのcompanion filesにも、コメントとdocstringが添付されています。
areq.pyが1秒以内に9つのURLの結果を取得、解析、保存するときの、すべての栄光の実行は次のとおりです。
$ python3 areq.py
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/それは粗末ではありません! 健全性チェックとして、出力の行数を確認できます。 私の場合、626ですが、これは変動する可能性があることに注意してください。
$ wc -l foundurls.txt
626 foundurls.txt
$ head -n 3 foundurls.txt
source_url parsed_url
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/feedback
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/notices/tosNext Steps:アンティを上げたい場合は、このWebCrawlerを再帰的にしてください。 aio-redisを使用して、ツリー内でクロールされたURLを追跡し、それらを2回要求しないようにし、リンクをPythonのnetworkxライブラリに接続できます。
素敵であることを忘れないでください。 小規模で疑いのないWebサイトに1000件の同時要求を送信するのは、悪い、悪い、悪いです。 asyncioのsempahoreオブジェクトを使用したり、パターンlike this oneを使用したりするなど、1つのバッチで行う同時リクエストの数を制限する方法があります。 この警告に注意しないと、TimeoutError例外が大量に発生し、自分のプログラムを傷つけるだけになる可能性があります。
コンテキスト内の非同期IO
正常な量のコードを見てきたので、少し戻って、非同期IOが理想的なオプションである場合と、その結論に到達するために比較を行う方法、または別の並行モデルを選択する方法を考えてみましょう。
非同期IOが正しい選択である理由と理由
このチュートリアルは、非同期IO、スレッド化、マルチプロセッシングに関する拡張された論文には適していません。 ただし、非同期IOがおそらく3つのうちの最良の候補である時期を把握しておくと便利です。
非同期IOとマルチプロセッシングをめぐる戦いは、実際にはまったく戦いではありません。 実際、それらはused in concertである可能性があります。 複数のかなり均一なCPUバウンドタスクがある場合(良い例はscikit-learnやkerasなどのライブラリ内のgrid searchです)、マルチプロセッシングは当然の選択です。
すべての関数がブロッキング呼び出しを使用する場合、すべての関数の前にasyncを置くことは悪い考えです。 (これにより、実際にコードの速度が低下する可能性があります。)ただし、前述のように、非同期IOとマルチプロセッシングがlive in harmonyできる場所があります。
非同期IOとスレッド化のコンテストは、もう少し直接的です。 はじめに、「スレッド化は難しい」と述べました。完全な話は、スレッド化を実装するのが簡単だと思われる場合でも、とりわけ、競合状態やメモリ使用量のために、悪名高いトレース不可能なバグにつながる可能性があるということです。
スレッドは有限の可用性を備えたシステムリソースであるため、スレッドは非同期IOよりもエレガントにスケーリングする傾向があります。 多くのマシンで数千のスレッドを作成すると失敗します。そもそも試してみることはお勧めしません。 数千の非同期IOタスクの作成は完全に実行可能です。
非同期IOは、複数のIOにバインドされたタスクがあり、タスクがそうでなければIOにバインドされた待機時間をブロックすることによってタスクが支配される場合に光ります。
-
プログラムがサーバー側かクライアント側かに関係なく、ネットワークIO
-
グループチャットルームのようなピアツーピアのマルチユーザーネットワークなどのサーバーレス設計
-
Read/write operations where you want to mimic a “fire-and-forget” style but worry less about holding a lock on whatever you’re reading and writing to
これを使用しない最大の理由は、awaitが特定のメソッドセットを定義する特定のオブジェクトセットのみをサポートすることです。 特定のDBMSで非同期読み取り操作を実行する場合は、そのDBMSのPythonラッパーだけでなく、async /await構文をサポートするラッパーを見つける必要があります。 同期呼び出しを含むコルーチンは、他のコルーチンおよびタスクの実行をブロックします。
async /awaitで動作するライブラリの候補リストについては、このチュートリアルの最後にあるlistを参照してください。
非同期IOですが、どれですか?
このチュートリアルでは、非同期IO、async /await構文、およびイベントループ管理とタスクの指定にasyncioを使用することに焦点を当てています。 確かに、asyncioだけが非同期IOライブラリではありません。 ナサニエルJからのこの観察 スミスはたくさん言います:
[In]数年後、
asyncioは、urllib2のように、知識のある開発者が避けているstdlibライブラリの1つになることに追いやられる可能性があります。…
私が主張しているのは、事実上、
asyncioはそれ自体の成功の犠牲者であるということです。設計時には、可能な限り最善のアプローチを使用していました。しかし、それ以来、async/awaitの追加など、asyncioに触発された作業により、状況が変化し、さらに改善できるようになりました。現在、asyncioは行き詰まっています。その以前のコミットメントによって。 (Source)
そのために、asyncioが行うことを実行するいくつかの有名な代替手段は、異なるAPIと異なるアプローチを使用しますが、curioとtrioです。 個人的には、適度なサイズの単純なプログラムを構築している場合は、asyncioを使用するだけで十分で理解しやすく、Pythonの標準ライブラリの外部にさらに大きな依存関係を追加することを回避できると思います。
ただし、必ずcurioとtrioを確認してください。そうすれば、ユーザーにとってより直感的な方法で同じことが行われることに気付くかもしれません。 ここで紹介するパッケージに依存しない概念の多くは、代替の非同期IOパッケージにも浸透するはずです。
オッズと終了
これらの次のいくつかのセクションでは、asyncioとasync /awaitのいくつかの雑多な部分について説明します。これらは、これまでのチュートリアルにうまく適合していませんが、構築と完全なプログラムを理解する。
その他のトップレベルのasyncio関数
asyncio.run()に加えて、asyncio.create_task()やasyncio.gather()などの他のパッケージレベルの関数をいくつか見てきました。
create_task()を使用してコルーチンオブジェクトの実行をスケジュールし、その後にasyncio.run()を使用できます。
>>>
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type
t done: True このパターンには微妙な点があります。main()内にawait tがない場合、main()自体が完了を通知する前に終了する可能性があります。 asyncio.run(main())calls loop.run_until_complete(main())であるため、イベントループは(await tが存在しない場合)main()が実行されることのみに関係し、main()内で作成されるタスクは関係しません。完了しました。 await tがない場合、ループの他のタスクwill be cancelledは、おそらく完了する前に実行されます。 現在保留中のタスクのリストを取得する必要がある場合は、asyncio.Task.all_tasks()を使用できます。
Note:asyncio.create_task()はPython3.7で導入されました。 Python 3.6以下では、create_task()の代わりにasyncio.ensure_future()を使用します。
これとは別に、asyncio.gather()があります。 それほど特別なことは何もしませんが、gather()は、コルーチン(未来)のコレクションを1つの未来にきちんと配置することを目的としています。 その結果、単一のfutureオブジェクトが返され、await asyncio.gather()を使用して複数のタスクまたはコルーチンを指定すると、それらがすべて完了するのを待つことになります。 (これは、前の例のqueue.join()と多少似ています。)gather()の結果は、入力全体の結果のリストになります。
>>>
>>> import time
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+
... print('Start:', time.strftime('%X'))
... a = await asyncio.gather(t, t2)
... print('End:', time.strftime('%X')) # Should be 10 seconds
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
... return a
...
>>> a = asyncio.run(main())
Start: 16:20:11
End: 16:20:21
Both tasks done: True
>>> agather()は、渡した先物またはコルーチンの結果セット全体を待機していることに気付いたと思います。 または、asyncio.as_completed()をループして、完了したタスクを完了順に取得することもできます。 この関数は、タスクが終了するとタスクを生成するイテレーターを返します。 以下では、coro([3, 2, 1])の結果は、coro([10, 5, 0])が完了する前に利用可能になりますが、gather()の場合はそうではありません。
>>>
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: True最後に、asyncio.ensure_future()も表示される場合があります。 これは低レベルの配管APIであり、後で導入されたcreate_task()に大部分が置き換えられているため、ほとんど必要ありません。
awaitの優先順位
動作は多少似ていますが、awaitキーワードの優先順位はyieldよりも大幅に高くなっています。 これは、より緊密にバインドされているため、類似のawaitステートメントでは必要のないyield fromステートメントで括弧が必要になる場合がいくつかあることを意味します。 詳細については、PEP 492のexamples of await expressionsを参照してください。
結論
これで、async /awaitとそれから構築されたライブラリを使用できるようになりました。 これがあなたがカバーしたことの要約です:
-
言語に依存しないモデルとしての非同期IOと、コルーチンが相互に間接的に通信できるようにすることで並行性を実現する方法
-
コルーチンのマーク付けと定義に使用されるPythonの新しい
asyncおよびawaitキーワードの詳細 -
asyncio、コルーチンを実行および管理するためのAPIを提供するPythonパッケージ
リソース
Pythonバージョンの詳細
Pythonの非同期IOは急速に進化しており、何がいつ発生したかを追跡するのは難しい場合があります。 asyncioに関連するPythonのマイナーバージョンの変更と導入のリストは次のとおりです。
-
3.3: The
yield fromexpression allows for generator delegation. -
3.4:
asynciowas introduced in the Python standard library with provisional API status. -
3.5:
asyncandawaitbecame a part of the Python grammar, used to signify and wait on coroutines. それらはまだ予約されたキーワードではありませんでした。 (asyncおよびawaitという名前の関数または変数を定義することもできます。) -
3.6: Asynchronous generators and asynchronous comprehensions were introduced.
asyncioのAPIは、暫定的ではなく安定していると宣言されました。 -
3.7:
asyncandawaitbecame reserved keywords. (識別子として使用することはできません。)これらは、asyncio.coroutine()デコレータを置き換えることを目的としています。asyncio.run()は、a bunch of other featuresの中でasyncioパッケージに導入されました。
安全を確保したい(そしてasyncio.run()を使用できるようにしたい)場合は、Python3.7以降を使用してすべての機能を入手してください。
記事
追加リソースの厳選されたリストは次のとおりです。
-
CPython:
asyncioパッケージsource -
Pythonドキュメント:Data model > Coroutines
-
TalkPython:Async Techniques and Examples in Pythonhttps://github.com/talkpython/async-techniques-python-course
-
PYMOTW:
asyncio -
A. ジェシー・ジリュウ・デイビスとグイド・ヴァン・ロッサム:A Web Crawler With asyncio Coroutines
-
Andy Pearce:The State of Python Coroutines:
yield from -
ナサニエルJ。 スミス:Some Thoughts on Asynchronous API Design in a Post-
async/awaitWorld -
アーミン・ロンチャー:I don’t understand Python’s Asyncio
-
Andy Balaam:series on
asyncio(4件の投稿) -
スタックオーバーフロー:Python
asyncio.semaphoreinasync-awaitfunction -
Yeray Diaz:
いくつかのPythonWhat’s Newのセクションでは、言語変更の背後にある動機について詳しく説明しています。
-
What’s New in Python 3.3(
yield fromおよびPEP 380) -
What’s New in Python 3.6(PEP 525&530)
デビッドビーズリーから:
YouTubeの講演:
関連するPEP
| PEP | 作成日 |
|---|---|
2005-05 |
|
2009-02 |
|
2011-05 |
|
2012-12 |
|
2015-04 |
|
2016-07 |
|
2016-09 |
async /awaitで動作するライブラリ
aio-libsから:
magicstackから:
他のホストから:
-
trio:よりフレンドリーなasyncioは、根本的にシンプルなデザインを紹介することを目的としています -
aiofiles:非同期ファイルIO -
asks:非同期リクエスト-httpライブラリのように -
asyncio-redis:非同期IORedisのサポート -
aioprocessing:multiprocessingモジュールをasyncioと統合します -
umongo:非同期IOMongoDBクライアント -
unsync:asyncioの同期を解除します -
aiostream:itertoolsと同様ですが、非同期です