前書き
以前のチュートリアルでは、how to visualize and manipulate time series dataとhow to leverage the ARIMA method to produce forecasts from time series dataを示しました。 ARIMAモデルの正しいパラメーター化は、一定の時間を要する複雑な手動プロセスになる可能性があることに注意しました。
Rなどの他の統計プログラミング言語はこの問題を解決するためにautomated waysを提供しますが、それらはまだ正式にPythonに移植されていません。 幸い、Facebookのコアデータサイエンスチームは最近、Prophetと呼ばれる新しいメソッドを公開しました。これにより、データアナリストと開発者は、Python3で大規模な予測を実行できます。
前提条件
このガイドでは、ローカルデスクトップまたはリモートサーバーで時系列分析を行う方法について説明します。 大規模なデータセットの操作はメモリを大量に消費する可能性があるため、いずれの場合も、このガイドの計算の一部を実行するには、コンピューターに少なくとも2GB of memoryが必要です。
このチュートリアルでは、Jupyter Notebookを使用してデータを操作します。 まだお持ちでない場合は、tutorial to install and set up Jupyter Notebook for Python 3に従ってください。
[[step-1 -—- pull-dataset-and-install-packages]] ==ステップ1—データセットをプルしてパッケージをインストールする
Prophetで時系列予測のための環境をセットアップするには、まずローカルプログラミング環境またはサーバーベースのプログラミング環境に移りましょう。
cd environments. my_env/bin/activateここから、プロジェクト用の新しいディレクトリを作成しましょう。 これをtimeseriesと呼び、ディレクトリに移動します。 プロジェクトを別の名前で呼ぶ場合は、ガイド全体で必ずtimeseriesの名前に置き換えてください。
mkdir timeseries
cd timeseriesBox and Jenkins(1976)Airline Passengers datasetを使用します。これには、1949年から1960年までの月間航空旅客数に関する時系列データが含まれています。 curlコマンドと-Oフラグを使用してデータを保存し、出力をファイルに書き込んでCSVをダウンロードできます。
curl -O https://assets.digitalocean.com/articles/eng_python/prophet/AirPassengers.csvこのチュートリアルでは、pandas、matplotlib、numpy、cython、およびfbprophetライブラリが必要です。 他のほとんどのPythonパッケージと同様に、pipを使用してpandas、numpy、cython、およびmatplotlibライブラリをインストールできます。
pip install pandas matplotlib numpy cython予測を計算するために、fbprophetライブラリは、数学者Stanislaw Ulamにちなんで名付けられたSTANプログラミング言語に依存しています。 したがって、fbprophetをインストールする前に、STANへのpystanPythonラッパーがインストールされていることを確認する必要があります。
pip install pystanこれが完了したら、pipを使用してProphetをインストールできます。
pip install fbprophetこれですべてのセットアップが完了したので、インストールされたパッケージの操作を開始できます。
[[step-2 -—- import-packages-and-load-data]] ==ステップ2—パッケージのインポートとデータのロード
データの操作を開始するには、Jupyter Notebookを起動します。
jupyter notebook新しいノートブックファイルを作成するには、右上のプルダウンメニューからNew>Python 3を選択します。
これにより、必要なライブラリをロードできるノートブックが開きます。
ベストプラクティスとして、ノートブックの上部に必要なライブラリをインポートすることから始めます(pandas、matplotlib、およびstatsmodelsを参照するために使用される標準の省略形に注意してください)。
%matplotlib inline
import pandas as pd
from fbprophet import Prophet
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')プロットに538matplotlib styleを定義したことに注目してください。
このチュートリアルの各コードブロックの後に、ALT + ENTERと入力してコードを実行し、ノートブック内の新しいコードブロックに移動する必要があります。
時系列データを読み取ることから始めましょう。 次のコマンドを使用して、CSVファイルをロードし、最初の5行を印刷できます。
df = pd.read_csv('AirPassengers.csv')
df.head(5)
DataFrameには、明らかにMonth列とAirPassengers列が含まれています。 Prophetライブラリは、入力として、時間情報を含む1つの列と、予測したいメトリックを含む別の列を持つDataFrameを予期します。 重要なのは、時間列がdatetimeタイプであると予想されるため、列のタイプを確認してみましょう。
df.dtypesOutputMonth object
AirPassengers int64
dtype: objectMonth列はdatetimeタイプではないため、次のように変換する必要があります。
df['Month'] = pd.DatetimeIndex(df['Month'])
df.dtypesOutputMonth datetime64[ns]
AirPassengers int64
dtype: objectこれで、Month列が正しいdatetimeタイプであることがわかります。
Prophetは、入力列の名前をds(時間列)およびy(メトリック列)にするという厳密な条件も課しているため、DataFrameの列の名前を変更しましょう。
df = df.rename(columns={'Month': 'ds',
'AirPassengers': 'y'})
df.head(5)
作業するデータを視覚化することをお勧めします。時系列をプロットしてみましょう。
ax = df.set_index('ds').plot(figsize=(12, 8))
ax.set_ylabel('Monthly Number of Airline Passengers')
ax.set_xlabel('Date')
plt.show()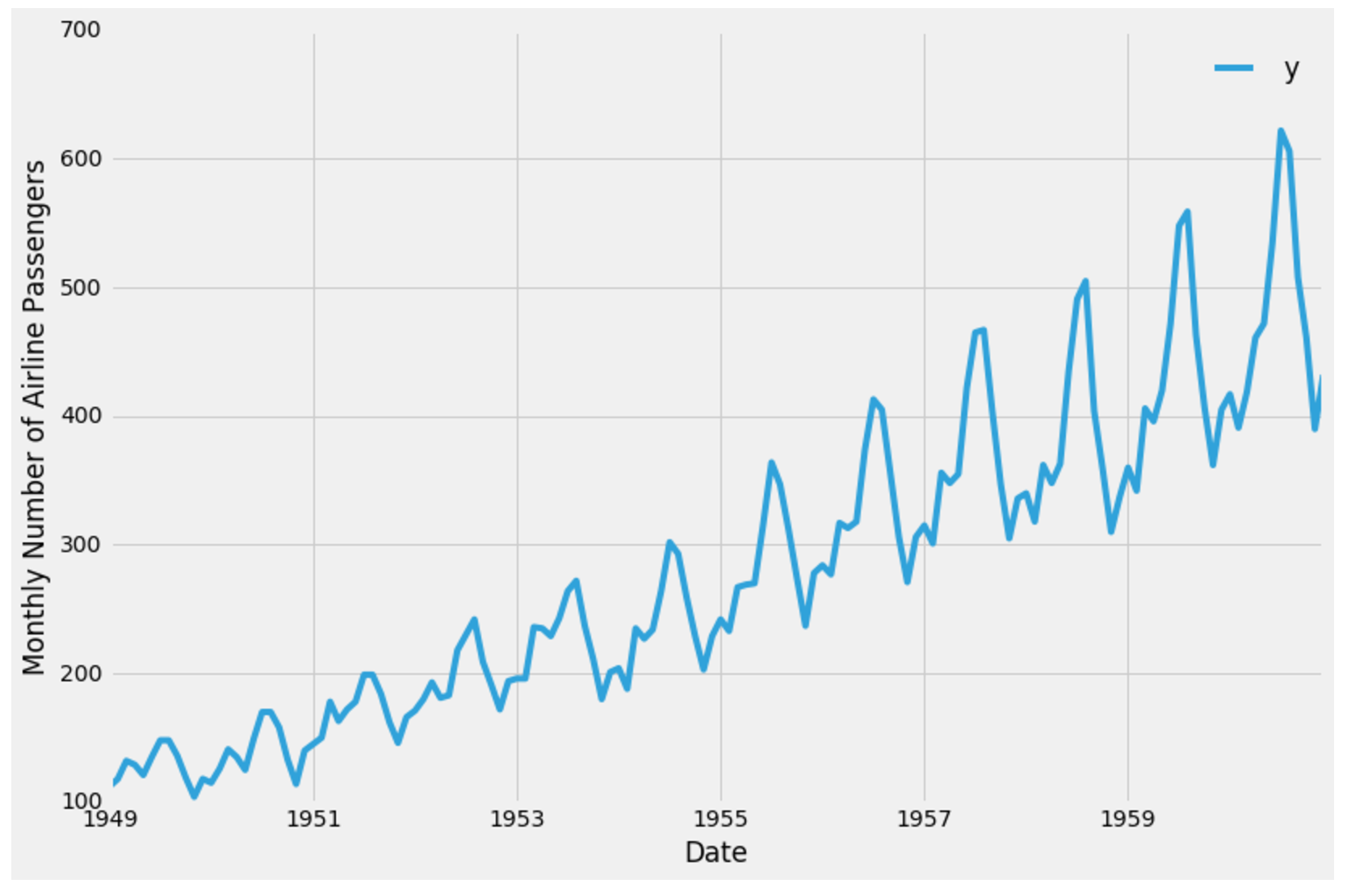
データが準備できたら、Prophetライブラリを使用して時系列の予測を作成する準備ができました。
[[step-3 -—- time-series-forecasting-with-prophet]] ==ステップ3—預言者による時系列予測
このセクションでは、Prophetライブラリを使用して時系列の将来の値を予測する方法を説明します。 Prophetの作成者は、時系列予測の固有の複雑さの多くを抽象化し、アナリストと開発者が時系列データを操作するのをより直感的にしました。
最初に、新しいProphetオブジェクトをインスタンス化する必要があります。 Prophetを使用すると、多くの引数を指定できます。 たとえば、interval_widthパラメータを設定することにより、不確実性区間の目的の範囲を指定できます。
# set the uncertainty interval to 95% (the Prophet default is 80%)
my_model = Prophet(interval_width=0.95)Prophetモデルが初期化されたので、DataFrameを入力としてそのfitメソッドを呼び出すことができます。 モデルのフィッティングには数秒しかかかりません。
my_model.fit(df)次のような出力を受け取るはずです。
Output時系列の予測を取得するには、予測が必要な日付を保持するds列を含む新しいDataFrameをProphetに提供する必要があります。 便利なことに、Prophetはmake_future_dataframeヘルパー関数を提供しているため、このDataFrameを手動で作成する必要はありません。
future_dates = my_model.make_future_dataframe(periods=36, freq='MS')
future_dates.tail()
上記のコードチャンクでは、将来36の日付スタンプを生成するように預言者に指示しました。
Prophetを使用する場合、時系列の頻度を考慮することが重要です。 月次データを処理しているため、タイムスタンプの目的の頻度を明確に指定しました(この場合、MSは月の始まりです)。 したがって、make_future_dataframeは36か月のタイムスタンプを生成しました。 つまり、3年先の時系列の将来価値を予測しようとしています。
次に、将来の日付のDataFrameが、近似モデルのpredictメソッドへの入力として使用されます。
forecast = my_model.predict(future_dates)
forecast[[ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
Prophetは、多くの興味深い列を持つ大きなDataFrameを返しますが、予測に最も関連する列に出力をサブセット化します。
-
ds:予測値の日付スタンプ -
yhat:メトリックの予測値(統計では、yhatは、値yの予測値を表すために従来から使用されている表記法です) -
yhat_lower:予測の下限 -
yhat_upper:予測の上限
Prophetは予測を生成するためにマルコフ連鎖モンテカルロ(MCMC)メソッドに依存しているため、上記の出力からの値の変動が予想されます。 MCMCは確率的なプロセスであるため、値は毎回わずかに異なります。
Prophetは、予測の結果をすばやくプロットする便利な機能も提供します。
my_model.plot(forecast,
uncertainty=True)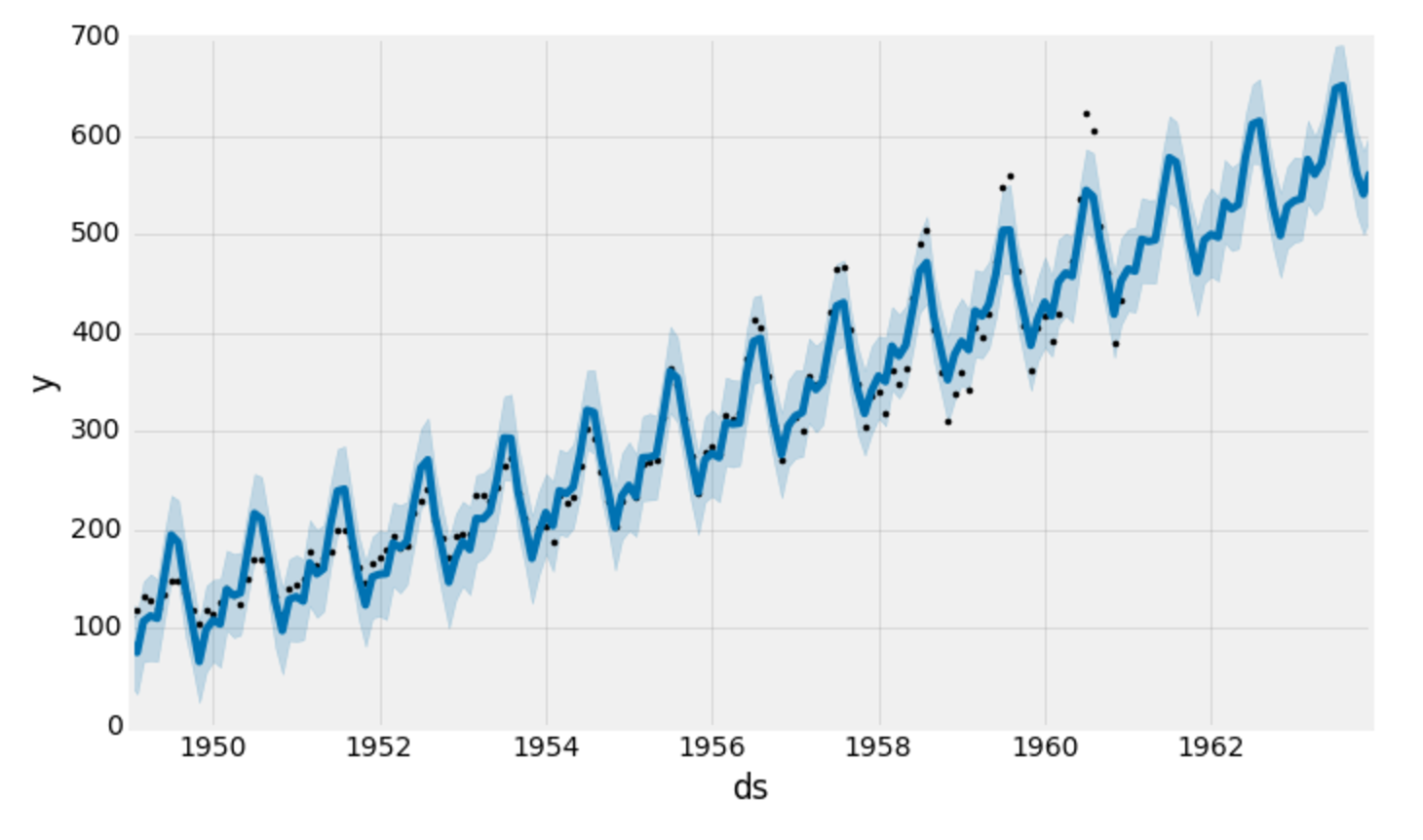
預言者は、時系列の観測値(黒い点)、予測値(青い線)、および予測の不確実性区間(青い網掛け領域)をプロットします。
Prophetのもう1つの特に強力な機能は、予測のコンポーネントを返す機能です。 これは、時系列の日次、週次、および年次のパターンが全体的な予測値にどのように寄与するかを明らかにするのに役立ちます。
my_model.plot_components(forecast)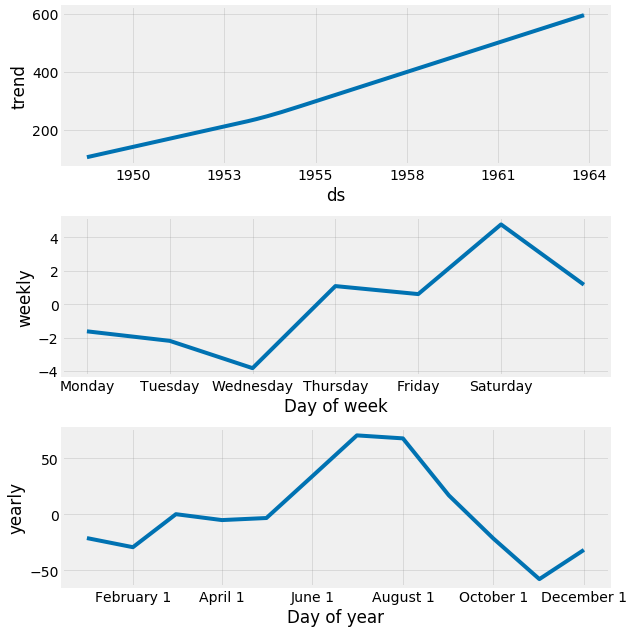
上記のプロットは興味深い洞察を提供します。 最初のプロットは、航空会社の乗客の月間量が時間とともに直線的に増加していることを示しています。 2番目のプロットは、週の終わりと土曜日に乗客の週数がピークに達するという事実を強調し、3番目のプロットは、7月と8月の休日月に最も多くのトラフィックが発生することを示します。
結論
このチュートリアルでは、Prophetライブラリを使用してPythonで時系列予測を実行する方法を説明しました。 既定のパラメーターを使用していましたが、Prophetを使用すると、さらに多くの引数を指定できます。 特に、Prophetは、時系列に関する独自の知識をテーブルにもたらす機能を提供します。
試してみることができるいくつかの追加事項を次に示します。
-
休日の月に関する事前の知識を含めることにより、休日の影響を評価します(たとえば、12月は休日の月であることがわかっています)。 modeling holidaysに関する公式ドキュメントが役立ちます。
-
不確実な間隔の範囲を変更するか、将来の予測を行います。
さらに練習するために、別の時系列データセットを読み込んで、独自の予測を作成することもできます。 全体として、Prophetは、ユーザーの要件に合わせて予測モデルを調整する機会など、多くの魅力的な機能を提供します。