前書き
クラウドサーバー環境でアプリケーションを起動して実行すると、サーバー環境をどのように改善して「機能する」から本格的な本番環境に飛躍できるのか疑問に思うかもしれません。 この記事は、クラウドサーバー環境のWebアプリケーションのコンテキストで「運用」の大まかな定義を作成し、既存のサーバーに追加できるコンポーネントをいくつか示すことで、運用環境の計画と実装を開始するのに役立ちます。移行を行うためのアーキテクチャ。
このデモンストレーションの目的のために、5 Common Server Setupsで説明されているものと同様のセットアップから始めていると仮定しましょう。たとえば、Webアプリケーションを提供するだけの2サーバー環境です。

実際のセットアップはより単純またはより複雑な場合がありますが、ここで説明する一般的なアイデアとコンポーネントは、サーバー環境にある程度適用されるはずです。
「本番環境」と言うときの意味を定義することから始めましょう。
実稼働環境とは何ですか?
一般的な意味でのWebアプリケーションのサーバー環境は、ハードウェア、ソフトウェア、データ、運用計画、およびアプリケーションの動作を維持するために必要な人員で構成されます。 通常、実稼働環境とは、これらの要素の許容レベルを最大限に考慮して設計および実装されたサーバー環境を指します。
-
Availability:アドバタイズされた時間中に対象のユーザーがアプリケーションを使用できるようにする機能。 可用性は、重要なコンポーネントに重大な影響を与える障害(たとえば、 バグが原因でアプリケーションがクラッシュしたり、データベースストレージデバイスに障害が発生したり、システム管理者が誤ってアプリケーションサーバーの電源を切ったりします。
可用性を促進する1つの方法は、環境内のsingle points of failureの数を減らすことです。 たとえば、静的IPと監視フェイルオーバーサービスを使用すると、ユーザーは正常なロードバランサーにのみアクセスできます。詳細については、this section of How To Use Floating IPsとこのarticle on load balancingを参照してください。
-
Recoverability:システム障害またはデータ損失が発生した場合にアプリケーション環境を回復する機能。 重要なコンポーネントに障害が発生し、回復できない場合、可用性は存在しなくなります。 関連する概念であるmaintainabilityを改善すると、障害が発生した場合に特定の回復プロセスを実行するために必要な時間が短縮されるため、障害が発生した場合の可用性を向上させることができます。
-
Performance:アプリケーションは、平均負荷またはピーク負荷で期待どおりに動作します(例: 適度に反応します)。 ユーザーにとって非常に重要ですが、パフォーマンスはアプリケーションが利用可能な場合にのみ重要です
アプリケーションのコンテキストで、上記の各項目の許容レベルを定義するのに時間をかけます。 これは、問題のアプリケーションの重要性と性質によって異なります。 たとえば、ブログを回復できる限り、時折ダウンタイムやパフォーマンスの低下に苦しむ訪問者がほとんどいない個人のブログでもおそらく受け入れられますが、企業のオンラインストアは全面的に非常に高い評価を得なければなりません。 もちろん、すべてのアプリケーションについて、すべてのカテゴリで100%を達成するのは良いことですが、時間とお金の制約のために実行できない場合がよくあります。
(a)ハードウェアの信頼性、特定のハードウェアコンポーネントが障害が発生する前に指定された時間の間適切に機能する確率、または(b)要因としてのセキュリティについては言及していません。 これは、(a)使用しているクラウドサーバーは一般に信頼性が高いが(物理サーバー上で実行されるため)障害が発生する可能性があること、および(b)セキュリティのベストプラクティスに従って最大限の能力を発揮しているためです。簡単に言えば、これらはこの記事の範囲外です。 ただし、信頼性とセキュリティは可用性に直接影響する要因であり、どちらも回復性の必要性に寄与する可能性があることに注意してください。
すべてのアプリケーションのさまざまなニーズと性質のために不可能な実稼働環境を作成するための段階的な手順を示す代わりに、既存のセットアップを実稼働環境に変換するために利用できるいくつかの具体的なコンポーネントを紹介します。
コンポーネントを見てみましょう!
1. バックアップシステム
バックアップシステムを使用すると、データの定期的なバックアップを作成し、バックアップからデータを復元することができます。 また、バックアップは、人為的ミスを含むさまざまな理由で発生する可能性のある偶発的な削除または望ましくない変更が発生した場合に、データを以前の状態にロールバックすることもできます。 すべてのコンピューターハードウェアには、ある時点で障害が発生する可能性があり、データ損失を引き起こす可能性があります。 これを念頭に置いて、すべての重要なデータの最新のバックアップを維持する必要があります。
Required for Production?はい。 バックアップシステムは、リカバリ可能性を実現するために必要なデータ損失の影響を軽減できるため、データ損失が発生した場合の可用性を向上させます。ただし、バックアップシステムは、次のセクション。 DigitalOceanのスナップショットベースのバックアップは、すべてのバックアップニーズに十分ではない可能性があることに注意してください。アクティブなデータベースや、ディスク書き込みI / Oが高い他のアプリケーションのバックアップには適していません。または、より柔軟なバックアップスケジューリングが必要な場合は、Baculaなどの別のバックアップシステムを使用してください。
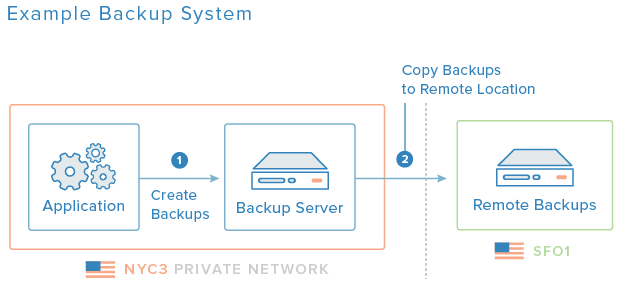
上の図は、基本的なバックアップシステムの例です。 バックアップサーバーは、最初のバックアップが作成されるアプリケーションサーバーと同じデータセンターにあります。 後で、バックアップのオフサイトコピーが別のデータセンターのサーバーに作成され、自然災害などの場合にデータが保持されるようにします。
検討事項
-
Backup Selection:バックアップするデータ。 最低限、代替ソースから確実に再現できないデータをバックアップします
-
Backup Schedule:完全バックアップまたは増分バックアップを実行するタイミングと頻度。 アクティブなデータベースなど、特定の種類のデータのバックアップには特別な考慮が必要です。バックアップスケジュールに影響する可能性があります
-
Data Retention Period:バックアップを削除する前に保持する期間
-
Disk Space for Backups:前の3つの項目の組み合わせは、バックアップシステムに必要なディスク容量に影響します。 圧縮および増分バックアップを活用して、バックアップに必要なディスク容量を削減します
-
Off-site Backups:特定のデータセンター内で、ローカルの災害からバックアップを保護するために、地理的に離れた場所にバックアップのコピーを保持することをお勧めします。 上の図では、NYC3のバックアップがこの目的のためにSFO1にコピーされます
-
Backup Restoration Tests:バックアップの復元プロセスを定期的にテストして、バックアップが正しく機能することを確認します
2. 復旧計画
復旧計画は、実稼働環境内の潜在的な障害または管理エラーから復旧するために文書化された一連の手順です。 少なくとも、サーバーハードウェアの障害や偶発的なデータ削除など、必然的に発生すると思われる障害のあるシナリオごとに回復計画が必要になります。 たとえば、サーバー障害の非常に基本的な回復計画は、最初のサーバー展開を実行するために実行した手順のリストと、バックアップからアプリケーションデータを復元するための追加手順で構成できます。 優れたドキュメントに加えて、より良い復旧計画では、Ansible、Chef、Puppetなどの展開スクリプトと構成管理ツールを活用して、復旧プロセスを自動化および迅速化することができます。
Required for Production?はい。 復旧計画はサーバー環境にソフトウェアとして存在しませんが、本番環境のセットアップに必要なコンポーネントです。 これらを使用すると、バックアップを効果的に使用でき、環境が再構築されたり、必要に応じて目的の状態にロールバックしたりするための青写真が提供されます。

上の図は、障害が発生したデータベースサーバーの復旧計画の概要です。 この場合、データベースサーバーは同じソフトウェアがインストールされた新しいサーバーに置き換えられ、最後の正常なバックアップがサーバー構成とデータの復元に使用されます。 最後に、アプリサーバーは新しいデータベースサーバーを使用するように構成されます。
検討事項
-
Procedure Documentation:障害イベントで従う必要のあるドキュメントのセット。 出発点として適切なのは、障害が発生したサーバーを再構築するための手順を追ったドキュメントを作成し、さまざまなアプリケーションデータと構成をバックアップから復元する手順を追加することです。
-
Automation Tools:スクリプトと構成管理ソフトウェアは自動化を提供し、展開と回復のプロセスを改善できます。 ステップバイステップガイドは、多くの場合、単に障害から回復するのに適切ですが、人が実行する必要があるため、自動化されたプロセスほど高速または一貫性がありません
-
Critical Components:アプリケーションが正しく機能するために必要なコンポーネント。 上記の例では、アプリケーションサーバーとデータベースサーバーの両方が重要なコンポーネントです。どちらかが失敗すると、アプリケーションが利用できなくなるためです。
-
Single Points of Failure:自動フェイルオーバーメカニズムを備えていない重要なコンポーネントは、単一障害点と見なされます。 可用性を向上させるために、可能な限り単一障害点の除去を試みる必要があります
-
Revisions:展開と回復のプロセスが改善されたら、ドキュメントを更新します
3. 負荷分散
負荷分散をサーバー環境に追加して、複数のサーバーにワークロードを分散することでパフォーマンスと可用性を改善できます。 負荷分散されたサーバーの1つに障害が発生した場合、他のサーバーは、障害が発生したサーバーが再び正常になるまで着信トラフィックを処理します。 クラウドサーバー環境では、通常、アプリケーションの特定のコンポーネントを実行する複数のサーバーの前に、ロードバランサー(リバースプロキシ)ソフトウェアを実行するロードバランサーサーバーを追加することにより、ロードバランシングを実装できます。
Required for Production?必ずしもそうとは限りません。 負荷分散は、実稼働環境では必ずしも必要ではありませんが、正しく実装されていれば、システムの単一障害点の数を減らす効果的な方法になる可能性があります。 また、水平スケーリングにより容量を追加することにより、パフォーマンスを改善できます。

上の図では、負荷を共有するための追加のアプリサーバーと、両方のアプリサーバーにユーザーリクエストを分散するロードバランサーが追加されています。 この設定は、単一のアプリサーバーがトラフィックに追いつくのに苦労している場合のパフォーマンスに役立ちます。また、アプリケーションサーバーの1つに障害が発生した場合にアプリケーションを使用可能に保つのに役立ちます。 ただし、データベースサーバーとロードバランサーサーバー自体には2つの単一障害点があります。
[.note]#Note:DigitalOcean Load Balancersは、フルマネージドで可用性の高い負荷分散サービスです。 DigitalOceanでアプリケーションを実行している場合は、ロードバランサーサービスが環境に適している可能性があります。
#
検討事項
-
Load Balanceable Components:環境内のすべてのコンポーネントを簡単に負荷分散できるわけではありません。 データベースやステートフルアプリケーションなどの特定の種類のソフトウェアについては、特別な考慮が必要です。
-
Application Data Replication:負荷分散されたアプリケーションサーバーがアップロードされたファイルなどのアプリケーションデータをローカルに保存する場合、このデータはレプリケーションや共有ファイルシステムなどの方法で他のアプリケーションサーバーが利用できるようにする必要があります。 これは、どのアプリケーションサーバーがユーザーリクエストを処理するために選択されているかに関係なく、アプリケーションデータを確実に使用可能にするために必要です。
-
Performance Bottlenecks:ロードバランサーに十分なリソースがないか、適切に構成されていない場合、実際にはアプリケーションのパフォーマンスが低下する可能性があります
-
Single Points of Failure:負荷分散を使用して単一障害点を排除できますが、計画が不十分な負荷分散では、実際には単一障害点が増える可能性があります。 ロードバランシングは、可用性に応じて一方または他方にトラフィックを送信するペアの前に静的IPを持つ2番目のロードバランサーを含めることで強化されます。
4. モニタリング
監視は、サービスの状態とサーバーリソースの使用率の傾向を追跡することにより、サーバー環境をサポートできるため、環境の優れた可視性を提供します。 監視システムの最大の利点の1つは、スクリプトの実行や通知の送信などのアクションをトリガーするように構成できることです。サービスやサーバーがダウンしたとき、またはCPU、メモリ、ストレージが過剰に使用されます。 これらの通知により、問題が発生するとすぐに対応できるため、アプリケーションのダウンタイムを最小限に抑えるか、防ぐことができます。
Required for Production?必ずしもそうとは限りませんが、実稼働環境のサイズと複雑さが増すにつれて、監視の必要性が高まります。 重要なサービスとサーバーリソースを追跡する簡単な方法を提供します。 同様に、監視により回復性が向上し、セットアップの計画と保守を通知できます。

上記の図は、監視システムの例です。 通常、監視サーバーは、アプリケーションサーバーとデータベースサーバーで実行されているエージェントソフトウェアからステータスデータを要求し、各エージェントはソフトウェアとハードウェアのステータス情報で応答します。 システムの管理者は、監視コンソールを使用してアプリケーションの全体的な状態を確認し、必要に応じてより詳細な情報にドリルダウンできます。
検討事項
-
Services to Monitor:監視するサービスとソフトウェア。 最低限、アプリケーションが正常に機能するために健全な実行状態にある必要があるすべてのサービスの状態を監視する必要があります
-
Resources to Monitor:監視するリソース。 リソースの例には、CPU、メモリ、ストレージ、ネットワーク使用率、およびサーバー全体の状態が含まれます
-
Data Retention:監視データを破棄する前に保持する期間。 これは、監視する項目の選択とともに、監視システムが必要とするディスク容量に影響します
-
Problem Detection Rules:サービスまたはリソースがOK状態にあるかどうかを決定するしきい値とルール。 たとえば、サービスやサーバーは、要求を実行して処理している場合は正常であると見なされることがありますが、ストレージなどのリソースは、一定の時間使用率が特定のしきい値に達すると警告をトリガーする場合があります
-
Notification Rules:通知を送信するかどうかを決定するしきい値とルール。 通知は重要ですが、あまり多く受信しないように通知ルールを調整することも同様に重要です。警告や警告がいっぱいの受信トレイはしばしば無視され、通知がまったくないのと同じくらい役に立たなくなります
5. 集中ログ
集中ログは、ログを表示および検索する簡単な方法を提供することでサーバー環境をサポートできます。ログは通常、環境全体の個々のサーバーにローカルに1か所で保存されます。 ログを読み取るために個々のサーバーにログインする必要がないという便利さの他に、集中ログでは、特定の時間枠でログとメトリックを相関させることにより、複数のサーバーにまたがる問題を簡単に識別できます。 また、ローカルログをアプリケーションサーバーから、独自の独立したストレージを持つ集中ログサーバーにオフロードできるため、ログの保持に関して柔軟性が高まります。
Required for Production?いいえ。ただし、監視と同様に、集中ログは、サーバー環境のサイズと複雑さが増すにつれて、サーバー環境に関する貴重な洞察を提供できます。 従来のログよりも便利であることに加えて、サーバーログを迅速に監査し、可視性を高めることができます。

上の図は、集中ログシステムの簡略化された例です。 ログ配布エージェントは各サーバーにインストールされ、重要なアプリとデータベースのログを集中ログサーバーに送信するように構成されます。 システムの管理者は、1つのコンソールからすべての重要なログを表示、フィルタリング、および検索できます。
検討事項
-
Logs to Gather:サーバーから集中ログサーバーに出荷する特定のログ。 すべてのサーバーから重要なログを収集する必要があります
-
Data Retention:ログを破棄する前にログを保持する期間。 これは、収集するログの選択とともに、集中ログシステムが必要とするディスク容量に影響します
-
Log Filters:プレーンログを構造化ログデータに解析するフィルター。 ログをフィルタリングすることで、データを有意義な方法でクエリ、分析、グラフ化する能力が向上します
-
Server Clocks:サーバーのクロックが同期され、同じタイムゾーンに設定されていることを確認して、環境全体でログのタイムラインが正確になるようにします。
結論
すべてのコンポーネントをまとめると、実稼働環境は次のようになります。

実動サーバーのセットアップをサポートおよび改善するために使用できるコンポーネントに精通したので、独自のサーバー環境をどのように統合できるかを検討する必要があります。 もちろん、すべての可能性を網羅しているわけではありませんが、これはどこから始めればいいのかを理解できるはずです。 利用可能なリソースと独自の生産目標のバランスに基づいて、サーバー環境を設計および実装することを忘れないでください。
上記のような環境のセットアップに興味がある場合は、次のチュートリアルを確認してください:Building for Production: Web Applications。