introduction
Toute application ou site Web qui connaît une croissance significative devra éventuellement évoluer pour s'adapter à l'augmentation du trafic. Pour les applications et les sites Web basés sur les données, il est essentiel que la mise à l’échelle soit effectuée de manière à garantir la sécurité et l’intégrité de leurs données. Il peut être difficile de prévoir la popularité ou la durée d'un site Web ou d'une application, ce qui explique pourquoi certaines entreprises choisissent une architecture de base de données leur permettant de redimensionner leurs bases de manière dynamique.
Dans cet article conceptuel, nous allons discuter d'une telle architecture de base de données:sharded databases. Sharding a fait l’objet de beaucoup d’attention au cours des dernières années, mais beaucoup n’ont pas une idée précise de ce qu’il en est ni des scénarios dans lesquels il pourrait être judicieux de partager une base de données. Nous allons passer en revue ce qu'est le sharding, certains de ses principaux avantages et inconvénients, ainsi que quelques méthodes de sharding courantes.
Qu'est-ce que l'éclatement?
Le partage est un modèle d'architecture de base de données lié àhorizontal partitioning - la pratique consistant à séparer les lignes d'une table en plusieurs tables différentes, appelées partitions. Chaque partition a le même schéma et les mêmes colonnes, mais également des lignes totalement différentes. De même, les données détenues dans chacune sont uniques et indépendantes des données détenues dans les autres partitions.
Il peut être utile de penser au partitionnement horizontal en termes de rapport avecvertical partitioning. Dans une table partitionnée verticalement, des colonnes entières sont séparées et placées dans de nouvelles tables distinctes. Les données contenues dans une partition verticale sont indépendantes des données de toutes les autres et chacune contient des lignes et des colonnes distinctes. Le diagramme suivant illustre comment un tableau peut être partitionné à la fois horizontalement et verticalement:
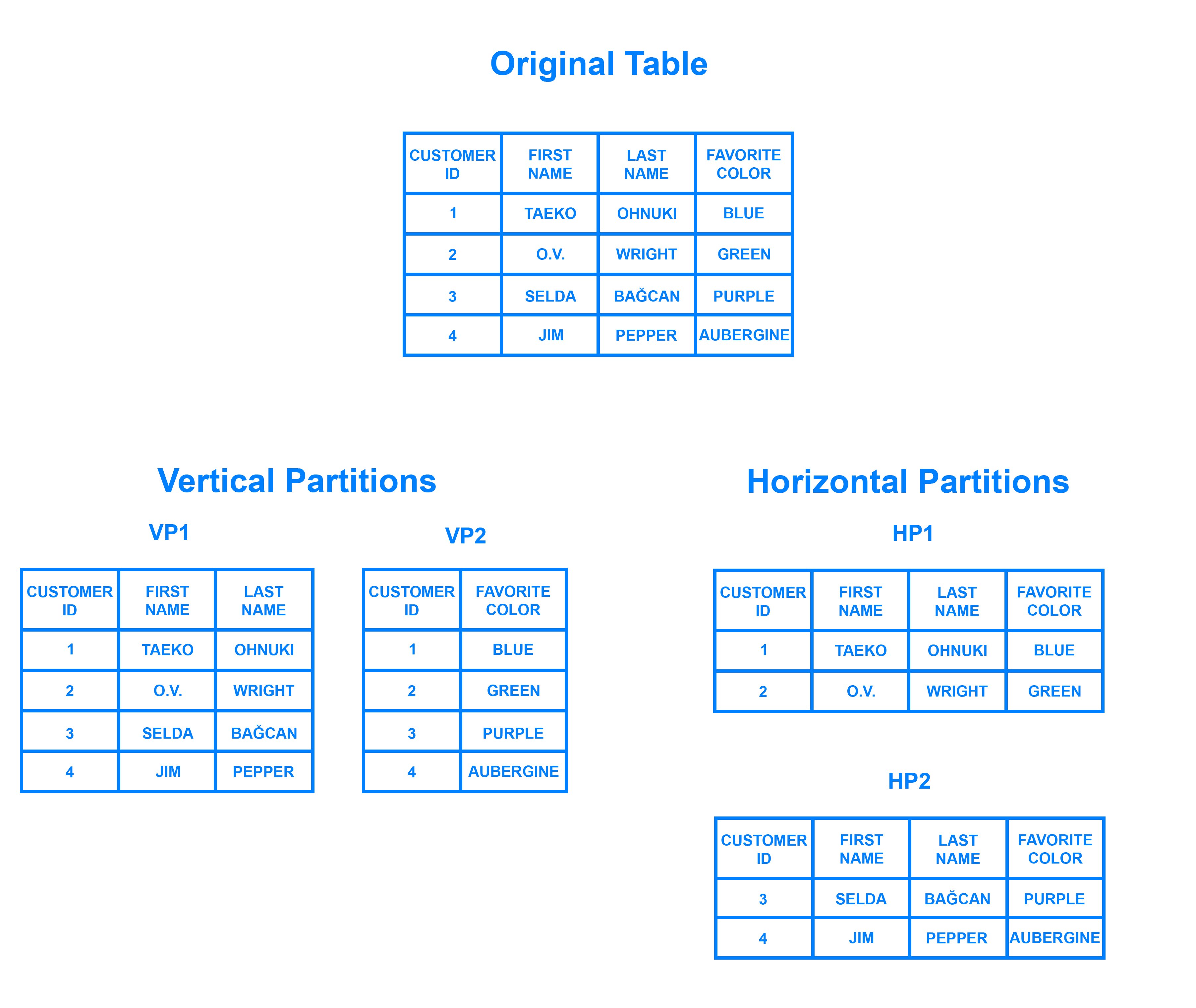
Le partage consiste à diviser ses données en deux ou plusieurs petits morceaux, appeléslogical shards. Les fragments logiques sont ensuite répartis sur des nœuds de base de données séparés, appelésphysical shards, qui peuvent contenir plusieurs fragments logiques. Malgré cela, les données détenues dans tous les fragments représentent collectivement un ensemble de données logique complet.
Les fragments de base de données illustrent unshared-nothing architecture. Cela signifie que les fragments sont autonomes; ils ne partagent aucune des mêmes données ou ressources informatiques. Dans certains cas, cependant, il peut être judicieux de répliquer certaines tables dans chaque fragment pour servir de tables de référence. Par exemple, supposons qu’il existe une base de données pour une application qui dépend de taux de conversion fixes pour les mesures de poids. En répliquant une table contenant les données de taux de conversion nécessaires dans chaque fragment, cela contribuerait à garantir que toutes les données requises pour les requêtes sont conservées dans chaque fragment.
Souvent, le partage est mis en œuvre au niveau de l'application, ce qui signifie que l'application inclut un code qui définit le fragment à transmettre, à lire et à écrire. Cependant, certains systèmes de gestion de base de données intègrent des fonctionnalités de partage permettant de le mettre en œuvre directement au niveau de la base de données.
Compte tenu de cet aperçu général du partage, passons en revue certains des aspects positifs et négatifs associés à cette architecture de base de données.
Avantages de l'écaillage
Le principal attrait du partitionnement d'une base de données est qu'il peut aider à faciliterhorizontal scaling, également connu sous le nom descaling out. La mise à l'échelle horizontale consiste à ajouter davantage de machines à une pile existante afin de répartir la charge, de générer davantage de trafic et de traiter plus rapidement. Ceci est souvent comparé àvertical scaling, autrement connu sous le nom descaling up, qui implique la mise à niveau du matériel d'un serveur existant, généralement en ajoutant plus de RAM ou de CPU.
Il est relativement simple d’exploiter une base de données relationnelle sur une seule machine et de l’adapter au besoin en mettant à niveau ses ressources informatiques. En fin de compte, toutefois, toute base de données non distribuée sera limitée en termes de stockage et de puissance de calcul. Par conséquent, la liberté de faire évoluer la structure horizontalement rend votre configuration beaucoup plus flexible.
Une autre raison pour laquelle certains pourraient choisir une architecture de base de données fragmentée est d’accélérer les temps de réponse aux requêtes. Lorsque vous soumettez une requête sur une base de données qui n'a pas été fragmentée, il peut être nécessaire de rechercher chaque ligne de la table que vous interrogez avant de pouvoir trouver le jeu de résultats que vous recherchez. Pour une application avec une grande base de données monolithique, les requêtes peuvent devenir extrêmement lentes. Toutefois, en partageant une table en plusieurs, les requêtes doivent parcourir moins de lignes et leurs jeux de résultats sont renvoyés beaucoup plus rapidement.
La fragmentation peut également aider à fiabiliser une application en atténuant les conséquences des pannes. Si votre application ou votre site Web repose sur une base de données non sécurisée, une panne peut rendre la totalité de l'application indisponible. Avec une base de données fragmentée, cependant, une panne ne devrait affecter qu'un seul fragment. Même si cela peut rendre certaines parties de l'application ou du site Web indisponibles pour certains utilisateurs, l'impact global serait quand même moindre que si la base de données entière s'effondrait.
Inconvénients de Sharding
Le partage d'une base de données peut faciliter la mise à l'échelle et améliorer les performances, mais il peut aussi imposer certaines limitations. Ici, nous allons discuter de certaines d’entre elles et de la raison pour laquelle elles pourraient être des raisons d’éviter tout tranchant.
La première difficulté que rencontrent les utilisateurs avec le sharding est la complexité inhérente à la mise en œuvre correcte d'une architecture de base de données fragmentée. Si cela est fait incorrectement, il existe un risque important que le processus de sharding conduise à la perte de données ou à la corruption de tables. Même une fois correctement effectué, le partage peut avoir un impact majeur sur les flux de travail de votre équipe. Plutôt que d’accéder à des données et de les gérer à partir d’un seul point d’entrée, les utilisateurs doivent gérer les données sur plusieurs emplacements de fragments, ce qui pourrait potentiellement perturber certaines équipes.
Un problème que rencontrent parfois les utilisateurs après avoir fragmenté une base de données est que les fragments deviennent éventuellement déséquilibrés. À titre d’exemple, supposons que vous disposiez d’une base de données avec deux fragments séparés, l’un pour les clients dont le nom de famille commence par les lettres A à M et l’autre pour ceux dont le nom commence par les lettres N à Z. Cependant, votre application sert un nombre excessif de personnes dont le nom commence par la lettre G. En conséquence, le fragment A-M génère progressivement plus de données que le composant N-Z, ce qui ralentit et ralentit l'application pour une partie importante de vos utilisateurs. Le fragment A-M est devenu ce que l'on appelle undatabase hotspot. Dans ce cas, les avantages du partage de la base de données sont annulés par les ralentissements et les pannes. La base de données devrait probablement être réparée et rééchelonnée pour permettre une distribution plus uniforme des données.
Un autre inconvénient majeur est qu’une fois qu’une base de données a été fragmentée, il peut être très difficile de la replacer dans une architecture non durcie. Les sauvegardes de la base de données effectuées avant le partage ne comprennent pas les données écrites depuis le partitionnement. Par conséquent, la reconstruction de l'architecture non durcie d'origine nécessiterait la fusion des nouvelles données partitionnées avec les anciennes sauvegardes ou, alternativement, la transformation de la base de données partitionnée en une seule base de données, ce qui serait coûteux et prendrait beaucoup de temps.
Un dernier inconvénient à prendre en compte est que le sharding n’est pas supporté de manière native par tous les moteurs de base de données. Par exemple, PostgreSQL n'inclut pas le partage automatique en tant que fonctionnalité, bien qu'il soit possible de partager manuellement une base de données PostgreSQL. Un certain nombre de fourches Postgres incluent le sharding automatique, mais elles sont souvent en retard sur la dernière version de PostgreSQL et manquent de certaines autres fonctionnalités. Certaines technologies de base de données spécialisées - comme MySQL Cluster ou certains produits de base de données en tant que service comme MongoDB Atlas - incluent le partage automatique en tant que fonctionnalité, mais pas les versions vanille de ces systèmes de gestion de base de données. Pour cette raison, le sharding nécessite souvent une approche «roll your own». Cela signifie que la documentation pour le sharding ou les astuces pour résoudre les problèmes sont souvent difficiles à trouver.
Ce ne sont bien sûr que quelques problèmes généraux à prendre en compte avant le sharding. Découper une base de données peut présenter de nombreux autres inconvénients potentiels, en fonction de son cas d'utilisation.
Maintenant que nous avons couvert quelques-uns des inconvénients et des avantages du partage, nous allons passer en revue quelques architectures différentes pour les bases de données fragmentées.
Architectures d'écaillage
Une fois que vous avez décidé de partager votre base de données, vous devez déterminer comment vous allez le faire. Lorsque vous exécutez des requêtes ou que vous distribuez des données entrantes à des tables ou à des bases de données fragmentées, il est primordial qu’elles soient transmises au bon fragment. Sinon, cela pourrait entraîner une perte de données ou des requêtes extrêmement lentes. Dans cette section, nous allons passer en revue quelques architectures de partage courantes, chacune utilisant un processus légèrement différent pour répartir les données entre des fragments.
Éclatement à base de clé
Key based sharding, également appeléhash based sharding, implique l'utilisation d'une valeur extraite de données nouvellement écrites, comme le numéro d'identification d'un client, l'adresse IP d'une application cliente, un code postal, etc. - et en le branchant dans unhash function pour déterminer à quelle partition les données doivent aller. Une fonction de hachage est une fonction qui prend en entrée un élément de données (par exemple, un e-mail client) et génère une valeur discrète, appeléehash value. Dans le cas du partage, la valeur de hachage est un ID de fragment utilisé pour déterminer le fragment sur lequel les données entrantes seront stockées. Au total, le processus ressemble à ceci:

Pour que les entrées soient placées dans les fragments corrects et de manière cohérente, les valeurs entrées dans la fonction de hachage doivent toutes provenir de la même colonne. Cette colonne est connue sous le nom deshard key. En termes simples, les clés de partition sont similaires àprimary keys en ce que les deux sont des colonnes qui sont utilisées pour établir un identifiant unique pour des lignes individuelles. De manière générale, une clé de partition doit être statique, ce qui signifie qu’elle ne doit pas contenir de valeurs susceptibles de changer avec le temps. Sinon, cela augmenterait la quantité de travail nécessaire aux opérations de mise à jour et pourrait ralentir les performances.
Bien que le sharding basé sur des clés soit une architecture de sharding assez courante, cela peut rendre les choses plus difficiles lorsque vous essayez d'ajouter ou de supprimer dynamiquement des serveurs supplémentaires à une base de données. Au fur et à mesure que vous ajoutez des serveurs, chacun d'entre eux aura besoin d'une valeur de hachage correspondante et bon nombre de vos entrées existantes, si ce n'est toutes, devront être remappées sur leur nouvelle valeur de hachage correcte, puis migrées vers le serveur approprié. Lorsque vous commencez à rééquilibrer les données, ni les nouvelles fonctions ni les anciennes fonctions de hachage ne seront valides. Par conséquent, votre serveur ne pourra pas écrire de nouvelles données pendant la migration et votre application pourrait être soumise à des temps morts.
Le principal intérêt de cette stratégie réside dans le fait qu’elle peut être utilisée pour distribuer de manière uniforme les données afin d’éviter les points chauds. De plus, comme elle distribue les données de façon algorithmique, il n’est pas nécessaire de conserver une carte indiquant l’emplacement de toutes les données, contrairement à d’autres stratégies telles que le sharding basé sur les plages ou les répertoires.
Éclatement basé sur la portée
Range based sharding implique des données de partitionnement basées sur des plages d'une valeur donnée. Imaginons, par exemple, que vous disposiez d’une base de données contenant des informations sur tous les produits du catalogue d’un détaillant. Vous pouvez créer quelques fragments différents et diviser les informations de chaque produit en fonction de la fourchette de prix correspondant, comme ceci:

Le principal avantage du partage basé sur la plage est qu’il est relativement simple à mettre en œuvre. Chaque fragment contient un ensemble de données différent, mais tous ont un schéma identique, ainsi que la base de données d'origine. Le code de l'application lit simplement la plage dans laquelle les données se trouvent et l'écrit dans le fragment correspondant.
Par contre, le partage basé sur les plages ne protège pas les données contre une distribution inégale, ce qui conduit aux points chauds de base de données susmentionnés. Si vous examinez l'exemple de diagramme, même si chaque fragment contient une quantité égale de données, il y a de fortes chances que des produits spécifiques reçoivent plus d'attention que d'autres. Leurs fragments respectifs recevront à leur tour un nombre disproportionné de lectures.
Eclatement basé sur un répertoire
Pour implémenterdirectory based sharding, il faut créer et maintenir unlookup table qui utilise une clé de partition pour garder une trace de quelle partition contient quelles données. En un mot, une table de recherche est une table contenant un ensemble statique d’informations sur les endroits où trouver des données spécifiques. Le diagramme suivant montre un exemple simpliste de partage basé sur un répertoire:
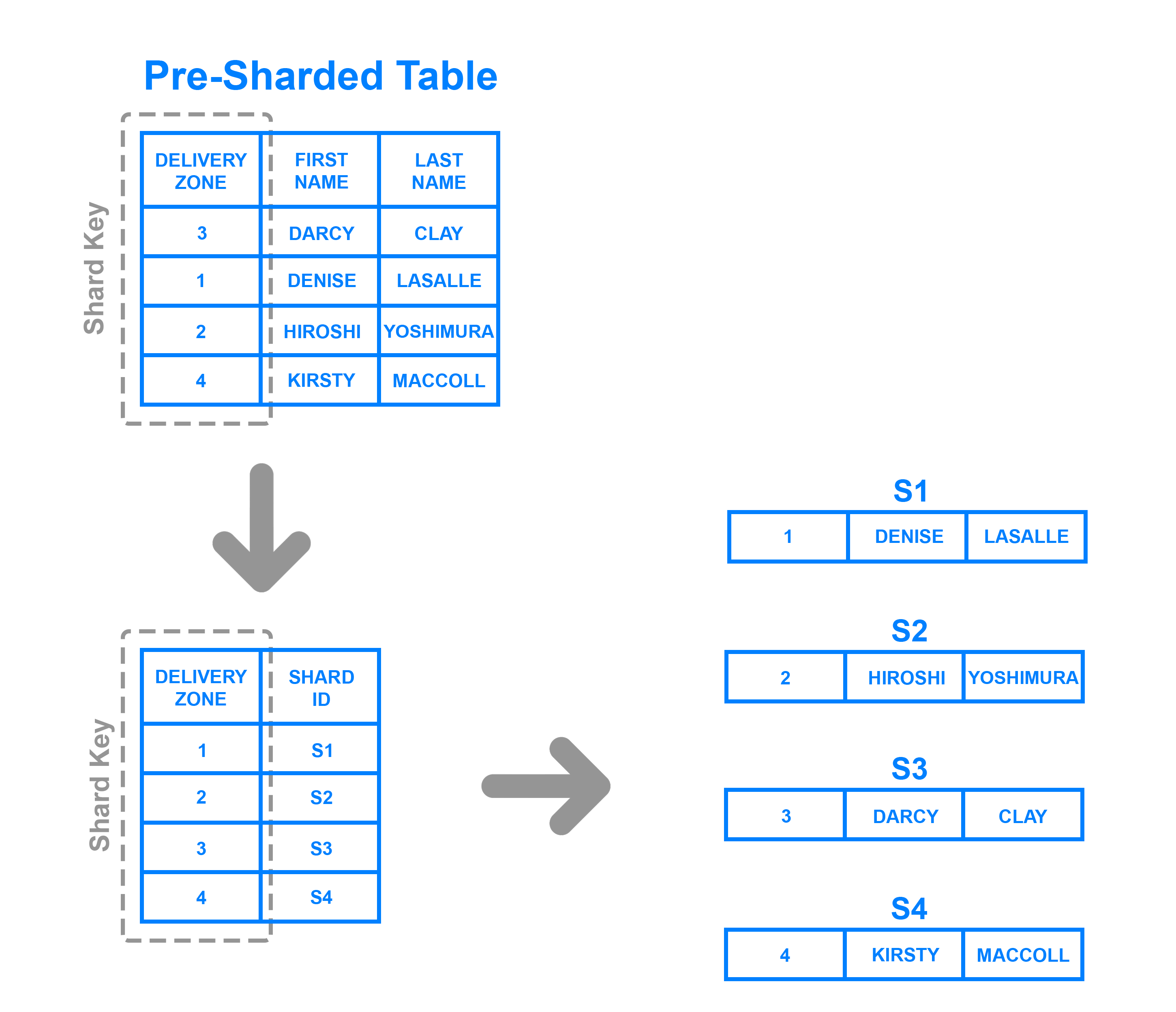
Ici, la colonneDelivery Zone est définie comme une clé de partition. Les données de la clé de fragment sont écrites dans la table de recherche avec le fragment dans lequel chaque ligne respective doit être écrite. Cette opération est similaire au partage basé sur une plage, mais au lieu de déterminer la plage dans laquelle se trouvent les données de la clé de partition, chaque clé est liée à sa propre partition spécifique. Le découpage par répertoire est un bon choix par rapport au découpage par plage dans les cas où la clé de fragment a une faible cardinalité et qu’il n’est pas logique pour un fragment de stocker une plage de clés. Notez qu’elle se distingue également du partage basé sur des clés en ce sens qu’elle ne traite pas la clé de partage via une fonction de hachage; il vérifie simplement la clé par rapport à une table de recherche pour voir où les données doivent être écrites.
L'attrait principal du partage basé sur l'annuaire est sa flexibilité. Les architectures de partage basées sur des plages vous limitent à la spécification de plages de valeurs, tandis que celles basées sur des clés vous limitent à l'utilisation d'une fonction de hachage fixe qui, comme mentionné précédemment, peut être extrêmement difficile à modifier ultérieurement. Le partage basé sur un répertoire, quant à lui, vous permet d'utiliser le système ou l'algorithme auquel vous souhaitez affecter des entrées de données, et il est relativement facile d'ajouter dynamiquement des fragments à l'aide de cette approche.
Bien que le partage basé sur l'annuaire soit la plus souple des méthodes de partage décrites ici, la nécessité de se connecter à la table de recherche avant chaque requête ou écriture peut avoir un impact négatif sur les performances d'une application. De plus, la table de consultation peut devenir un point d’échec unique: si elle est corrompue ou tombe en panne, elle peut avoir une incidence sur la capacité de la personne d’écrire de nouvelles données ou d’accéder à leurs données existantes.
Dois-je éclater?
Qu'il soit ou non nécessaire de mettre en œuvre une architecture de base de données fragmentée est presque toujours un sujet de débat. Certains voient dans le sharding un résultat inévitable pour les bases de données atteignant une certaine taille, tandis que d’autres le considèrent comme un casse-tête à éviter sauf si cela est absolument nécessaire, en raison de la complexité opérationnelle ajoutée par le sharding.
En raison de cette complexité accrue, le partage n'est généralement effectué que lorsque vous traitez de très grandes quantités de données. Voici quelques scénarios courants dans lesquels il peut être avantageux de partager une base de données:
-
La quantité de données d'application augmente pour dépasser la capacité de stockage d'un seul nœud de base de données.
-
Le volume d'écritures ou de lectures dans la base de données dépasse ce qu'un seul nœud ou ses répliques en lecture peuvent gérer, ce qui ralentit les délais de réponse ou les délais d'attente.
-
La bande passante réseau requise par l'application dépasse la bande passante disponible pour un seul nœud de base de données et tous les réplicas en lecture, ce qui ralentit les délais de réponse ou les délais d'attente.
Avant le partage, vous devez épuiser toutes les autres options pour optimiser votre base de données. Parmi les optimisations à envisager, citons:
-
Setting up a remote database. Si vous travaillez avec une application monolithique dans laquelle tous ses composants résident sur le même serveur, vous pouvez améliorer les performances de votre base de données en la déplaçant sur sa propre machine. Cela n’ajoute pas autant de complexité que le sharding puisque les tables de la base de données restent intactes. Cependant, cela vous permet toujours de mettre à l'échelle verticalement votre base de données en dehors du reste de votre infrastructure.
-
Implementing caching. Si les performances de lecture de votre application sont la cause de vos problèmes, la mise en cache est une stratégie qui peut aider à l’améliorer. La mise en cache implique le stockage temporaire dans la mémoire des données déjà demandées, ce qui vous permet d'y accéder beaucoup plus rapidement par la suite.
-
Creating one or more read replicas. Une autre stratégie qui peut aider à améliorer les performances de lecture consiste à copier les données d'un serveur de base de données (lesprimary server) vers un ou plusieurssecondary servers. Ensuite, chaque nouvelle écriture va au primaire avant d’être copiée sur les secondaires, alors que les lectures sont faites exclusivement sur les serveurs secondaires. La distribution de lectures et d'écritures de cette manière empêche toute machine d'assumer une charge excessive, ce qui permet d'éviter les ralentissements et les pannes. Notez que la création de répliques en lecture implique davantage de ressources informatiques et coûte donc plus cher, ce qui pourrait constituer une contrainte importante pour certains.
-
Upgrading to a larger server. Dans la plupart des cas, la mise à l’échelle d’un serveur de base de données sur une machine disposant de plus de ressources nécessite moins d’efforts que le sharding. Comme pour la création de répliques en lecture, un serveur mis à niveau avec plus de ressources coûtera probablement plus cher. Par conséquent, vous ne devriez procéder au redimensionnement que s'il s'avère vraiment être votre meilleure option.
N'oubliez pas que si votre application ou votre site Web dépasse un certain seuil, aucune de ces stratégies ne suffira à améliorer les performances. Dans de tels cas, le sharding peut en effet être la meilleure option pour vous.
Conclusion
Sharding peut être une excellente solution pour ceux qui cherchent à redimensionner leur base de données horizontalement. Cependant, cela ajoute également beaucoup de complexité et crée plus de points de défaillance potentiels pour votre application. L'éclatement peut être nécessaire pour certains, mais le temps et les ressources nécessaires pour créer et gérer une architecture fragmentée pourraient l'emporter sur les avantages pour les autres.
En lisant cet article conceptuel, vous devriez avoir une compréhension plus claire des avantages et des inconvénients du sharding. À l'avenir, vous pouvez utiliser cette information pour prendre une décision plus éclairée quant à savoir si une architecture de base de données fragmentée convient ou non à votre application.