Programmation des sockets en Python (Guide)
Les sockets et l’API socket sont utilisés pour envoyer des messages sur un réseau. Ils fournissent une forme de inter-process communication (IPC). Le réseau peut être un réseau local logique vers l’ordinateur, ou un réseau physiquement connecté à un réseau externe, avec ses propres connexions à d’autres réseaux. L’exemple évident est Internet, auquel vous vous connectez via votre FAI.
Ce didacticiel comporte trois itérations différentes de création d’un serveur de socket et d’un client avec Python:
-
Nous allons commencer le didacticiel en examinant un serveur et un client socket simples.
-
Une fois que vous avez vu l’API et comment les choses fonctionnent dans cet exemple initial, nous examinerons une version améliorée qui gère plusieurs connexions simultanément.
-
Enfin, nous allons progresser vers la création d’un exemple de serveur et de client qui fonctionne comme une application socket à part entière, avec son propre en-tête et son contenu personnalisés.
À la fin de ce didacticiel, vous comprendrez comment utiliser les principales fonctions et méthodes du module socket de Python pour écrire vos propres applications client-serveur . Cela vous montre comment utiliser une classe personnalisée pour envoyer des messages et des données entre des points de terminaison sur lesquels vous pouvez vous appuyer et utiliser pour vos propres applications.
Les exemples de ce didacticiel utilisent Python 3.6. Vous pouvez trouver le source code sur GitHub.
La mise en réseau et les sockets sont des sujets importants. Des volumes littéraux ont été écrits à leur sujet. Si vous êtes nouveau dans les sockets ou les réseaux, il est tout à fait normal que vous vous sentiez submergé par tous les termes et éléments. Je sais que je l’ai fait!
Ne vous découragez cependant pas. J’ai écrit ce tutoriel pour vous. Comme nous le faisons avec Python, nous pouvons apprendre un peu à la fois. Utilisez la fonction de signet de votre navigateur et revenez lorsque vous serez prêt pour la section suivante.
Commençons!
Contexte
Les sockets ont une longue histoire. Leur utilisation originated avec ARPANET en 1971 et est devenu plus tard une API dans le système d’exploitation Berkeley Software Distribution (BSD) sorti en 1983 appelé https://en.wikipedia .org/wiki/Berkeley_sockets [sockets Berkeley].
Lorsque Internet a pris son envol dans les années 1990 avec le World Wide Web, la programmation réseau a fait de même. Les serveurs Web et les navigateurs n’étaient pas les seules applications à profiter des nouveaux réseaux connectés et à utiliser des sockets. Les applications client-serveur de tous types et de toutes tailles sont devenues très répandues.
Aujourd’hui, bien que les protocoles sous-jacents utilisés par l’API socket aient évolué au fil des ans, et nous en avons vu de nouveaux, l’API de bas niveau est restée la même.
Le type le plus courant d’applications socket sont les applications client-serveur, où un côté agit comme serveur et attend les connexions des clients. C’est le type d’application que je vais couvrir dans ce tutoriel. Plus précisément, nous examinerons l’API socket pour Internet sockets, parfois appelée sockets Berkeley ou BSD. Il existe également Sockets de domaine Unix, qui ne peuvent être utilisés que pour communiquer entre les processus sur le même hôte.
Présentation de l’API Socket
Le module socket de Python fournit une interface vers Berkeley sockets API. Il s’agit du module que nous utiliserons et discuterons dans ce didacticiel.
Les fonctions et méthodes principales de l’API socket dans ce module sont:
-
+ socket () + -
+ bind () + -
+ écouter () + -
+ accepter () + -
+ connect () + -
+ connect_ex () + -
+ envoyer () + -
+ recv () + -
+ fermer () +
Python fournit une API pratique et cohérente qui correspond directement à ces appels système, leurs homologues C. Nous verrons comment ils sont utilisés ensemble dans la section suivante.
Dans le cadre de sa bibliothèque standard, Python possède également des classes qui facilitent l’utilisation de ces fonctions de socket de bas niveau. Bien qu’il ne soit pas traité dans ce didacticiel, consultez le socketserver module, une infrastructure pour les serveurs réseau. Il existe également de nombreux modules disponibles qui implémentent des protocoles Internet de niveau supérieur tels que HTTP et SMTP. Pour une vue d’ensemble, voir Protocoles et support Internet.
Sockets TCP
Comme vous le verrez sous peu, nous allons créer un objet socket en utilisant + socket.socket () + et spécifier le type de socket comme + socket.SOCK_STREAM +. Lorsque vous faites cela, le protocole par défaut utilisé est le Transmission Control Protocol (TCP). C’est un bon défaut et probablement ce que vous voulez.
Pourquoi devriez-vous utiliser TCP? Le protocole TCP (Transmission Control Protocol):
-
Est fiable: les paquets abandonnés dans le réseau sont détectés et retransmis par l’expéditeur.
-
A la livraison des données dans l’ordre: les données sont lues par votre application dans l’ordre où elles ont été écrites par l’expéditeur.
En revanche, les sockets User Datagram Protocol (UDP) créées avec + socket.SOCK_DGRAM + ne sont pas fiables et les données lues par le récepteur peuvent être hors de ordre des écritures de l’expéditeur.
Pourquoi est-ce important? Les réseaux sont un système de livraison au mieux. Il n’y a aucune garantie que vos données atteindront leur destination ou que vous recevrez ce qui vous a été envoyé.
Les périphériques réseau (par exemple, les routeurs et les commutateurs) ont une bande passante finie disponible et leurs propres limites système inhérentes. Ils ont des processeurs, de la mémoire, des bus et des tampons de paquets d’interface, tout comme nos clients et serveurs. TCP vous évite d’avoir à vous soucier de la packet loss, des données qui arrivent dans le désordre et de bien d’autres choses qui se produisent invariablement lorsque vous communiquez sur un réseau.
Dans le diagramme ci-dessous, regardons la séquence d’appels d’API socket et le flux de données pour TCP:
La colonne de gauche représente le serveur. À droite, le client.
En commençant dans la colonne en haut à gauche, notez les appels d’API que le serveur effectue pour configurer une socket «d’écoute»:
-
+ socket () + -
+ bind () + -
+ écouter () + -
+ accepter () +
Une prise d’écoute fait exactement ce que cela ressemble. Il écoute les connexions des clients. Lorsqu’un client se connecte, le serveur appelle + accept () + pour accepter ou terminer la connexion.
Le client appelle + connect () + pour établir une connexion avec le serveur et initier la prise de contact à trois. L’étape de prise de contact est importante car elle garantit que chaque côté de la connexion est accessible dans le réseau, en d’autres termes que le client peut atteindre le serveur et vice-versa. Il se peut qu’un seul hôte, client ou serveur, puisse atteindre l’autre.
Au milieu se trouve la section aller-retour, où les données sont échangées entre le client et le serveur à l’aide d’appels à + send () + et + recv () +.
En bas, le client et le serveur + close () + leurs sockets respectifs.
Client et serveur Echo
Maintenant que vous avez vu un aperçu de l’API socket et comment le client et le serveur communiquent, créons notre premier client et serveur. Nous allons commencer par une implémentation simple. Le serveur fera simplement écho à tout ce qu’il recevra au client.
Echo Server
Voici le serveur, + echo-server.py +:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # Standard loopback interface address (localhost)
PORT = 65432 # Port to listen on (non-privileged ports are > 1023)
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((HOST, PORT))
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)*Remarque:* Ne vous inquiétez pas de tout comprendre ci-dessus pour le moment. Il se passe beaucoup de choses dans ces quelques lignes de code. Ce n'est qu'un point de départ pour que vous puissiez voir un serveur de base en action.
Il y a un lien: #reference [section de référence] à la fin de ce tutoriel qui contient plus d’informations et des liens vers des ressources supplémentaires. Je vais créer un lien vers ces ressources et d’autres ressources tout au long du didacticiel.
Parcourons chaque appel d’API et voyons ce qui se passe.
+ socket.socket () + crée un objet socket qui prend en charge le context manager type, vous pouvez donc l’utiliser dans un https://docs.python.org/3/reference/compound_stmts.html#with [+ with + statement]. Il n’est pas nécessaire d’appeler + s.close () +:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
pass # Use the socket object without calling s.close().Les arguments passés à https://docs.python.org/3/library/socket.html#socket.socket [+ socket () +] spécifient le lien: # socket-address-families [famille d’adresse] et socket type. + AF_INET + est la famille d’adresses Internet pour IPv4. + SOCK_STREAM + est le type de socket pour link: # tcp-sockets [TCP], le protocole qui sera utilisé pour transporter nos messages dans le réseau.
+ bind () + est utilisé pour associer le socket à une interface réseau et un numéro de port spécifiques:
HOST = '127.0.0.1' # Standard loopback interface address (localhost)
PORT = 65432 # Port to listen on (non-privileged ports are > 1023)
# ...
s.bind((HOST, PORT))Les valeurs passées à + bind () + dépendent du lien: # socket-address-families [famille d’adresse] du socket. Dans cet exemple, nous utilisons + socket.AF_INET + (IPv4). Il attend donc un 2-tuple: + (hôte, port) +.
+ host + peut être un nom d’hôte, une adresse IP ou une chaîne vide. Si une adresse IP est utilisée, + host + doit être une chaîne d’adresse au format IPv4. L’adresse IP + 127.0.0.1 + est l’adresse IPv4 standard pour l’interface loopback, donc seuls les processus sur l’hôte pourront se connecter au serveur. Si vous passez une chaîne vide, le serveur acceptera les connexions sur toutes les interfaces IPv4 disponibles.
+ port + doit être un entier de + 1 + -` + 65535 + ( + 0 + est réservé). Il s’agit du numéro TCP port pour accepter les connexions des clients. Certains systèmes peuvent nécessiter des privilèges de superutilisateur si le port est <+ 1024 +`.
Voici une note sur l’utilisation des noms d’hôtes avec + bind () +:
_ «Si vous utilisez un nom d’hôte dans la partie hôte de l’adresse de socket IPv4/v6, le programme peut afficher un comportement non déterministe, car Python utilise la première adresse renvoyée par la résolution DNS. L’adresse du socket sera résolue différemment en une adresse IPv4/v6 réelle, en fonction des résultats de la résolution DNS et/ou de la configuration de l’hôte. Pour un comportement déterministe, utilisez une adresse numérique dans la partie hôte. » (Source) _
J’en parlerai plus tard dans le lien: # using-hostnames [Using Hostnames], mais cela vaut la peine d’être mentionné ici. Pour l’instant, comprenez simplement que lorsque vous utilisez un nom d’hôte, vous pouvez voir des résultats différents selon ce qui est retourné par le processus de résolution de nom.
Ça pourrait être n’importe quoi. La première fois que vous exécutez votre application, il peut s’agir de l’adresse + 10.1.2.3 +. La prochaine fois, c’est une adresse différente, + 192.168.0.1 +. La troisième fois, ce pourrait être `+ 172.16.7.8 + ', et ainsi de suite.
En continuant avec l’exemple du serveur, + listen () + permet à un serveur + d’accepter () + les connexions. Cela en fait une prise «d’écoute»:
s.listen()
conn, addr = s.accept()+ listen () + a un paramètre + backlog +. Il spécifie le nombre de connexions non acceptées que le système autorisera avant de refuser de nouvelles connexions. À partir de Python 3.5, il est facultatif. S’il n’est pas spécifié, une valeur par défaut + backlog + est choisie.
Si votre serveur reçoit de nombreuses demandes de connexion simultanément, l’augmentation de la valeur + backlog + peut aider en définissant la longueur maximale de la file d’attente pour les connexions en attente. La valeur maximale dépend du système. Par exemple, sous Linux, voir https://serverfault.com/questions/518862/will-increasing-net-core-somaxconn-make-a-difference/519152 [+/proc/sys/net/core/somaxconn + ].
+ accept () + link: # blocking-calls [blocks] et attend une connexion entrante. Lorsqu’un client se connecte, il renvoie un nouvel objet socket représentant la connexion et un tuple contenant l’adresse du client. Le tuple contiendra + (hôte, port) + pour les connexions IPv4 ou + (hôte, port, flowinfo, scopeid) + pour IPv6. Voir le lien: # socket-address-families [Socket Address Families] dans la section référence pour plus de détails sur les valeurs de tuple.
Il est impératif de comprendre que nous avons maintenant un nouvel objet socket à partir de + accept () +. Ceci est important car c’est le socket que vous utiliserez pour communiquer avec le client. Il est distinct du socket d’écoute que le serveur utilise pour accepter de nouvelles connexions:
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)Après avoir récupéré l’objet socket client + conn + de + accept () +, une boucle infinie + while + est utilisée pour boucler le lien: # blocking-calls [blocking calls] to + conn.recv () + ". Cela lit toutes les données que le client envoie et les renvoie en retour en utilisant `+ conn.sendall () +.
Si + conn.recv () + renvoie un https://docs.python.org/3/library/stdtypes.html#bytes-objects [+ bytes +] objet vide, + b '' +, puis le client a fermé la connexion et la boucle est terminée. L’instruction + with + est utilisée avec + conn + pour fermer automatiquement le socket à la fin du bloc.
Client Echo
Voyons maintenant le client, + echo-client.py +:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # The server's hostname or IP address
PORT = 65432 # The port used by the server
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect((HOST, PORT))
s.sendall(b'Hello, world')
data = s.recv(1024)
print('Received', repr(data))Par rapport au serveur, le client est assez simple. Il crée un objet socket, se connecte au serveur et appelle + s.sendall () + pour envoyer son message. Enfin, il appelle + s.recv () + pour lire la réponse du serveur, puis l’imprime.
Exécution du client et du serveur Echo
Exécutons le client et le serveur pour voir comment ils se comportent et inspectons ce qui se passe.
*Remarque:* Si vous rencontrez des problèmes pour exécuter les exemples ou votre propre code à partir de la ligne de commande, lisez https://dbader.org/blog/how-to-make-command-line-commands-with-python [Comment puis-je créer mes propres commandes de ligne de commande en utilisant Python?] Si vous êtes sous Windows, consultez le https://docs.python.org/3.6/faq/windows.html[Python Windows FAQ].
Ouvrez un terminal ou une invite de commande, accédez au répertoire qui contient vos scripts et exécutez le serveur:
$ ./echo-server.pyVotre terminal semble se bloquer. C’est parce que le serveur est un lien: # blocage-appels [bloqué] (suspendu) dans un appel:
conn, addr = s.accept()Il attend une connexion client. Ouvrez maintenant une autre fenêtre de terminal ou une invite de commande et exécutez le client:
$ ./echo-client.py
Received b'Hello, world'Dans la fenêtre du serveur, vous devriez voir:
$ ./echo-server.py
Connected by ('127.0.0.1', 64623)Dans la sortie ci-dessus, le serveur a imprimé le tuple + addr + retourné par + s.accept () +. Il s’agit de l’adresse IP et du numéro de port TCP du client. Le numéro de port, + 64623 +, sera très probablement différent lorsque vous l’exécuterez sur votre machine.
Affichage de l’état du socket
Pour voir l’état actuel des sockets sur votre hôte, utilisez + netstat +. Il est disponible par défaut sur macOS, Linux et Windows.
Voici la sortie netstat de macOS après le démarrage du serveur:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 127.0.0.1.65432 *. *LISTENNotez que + Local Address + est + 127.0.0.1.65432 + '. Si `+ echo-server.py + avait utilisé + HOST = '' + au lieu de '+ HOST =' 127.0.0.1 '+ `, netstat afficherait ceci:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 * .65432 *. *LISTEN+ Local Address + est +* . 65432 +, ce qui signifie que toutes les interfaces hôtes disponibles qui prennent en charge la famille d’adresses seront utilisées pour accepter les connexions entrantes. Dans cet exemple, dans l’appel à + socket () +, + socket.AF_INET + a été utilisé (IPv4). Vous pouvez le voir dans la colonne + Proto +: + tcp4 +.
J’ai réduit la sortie ci-dessus pour afficher uniquement le serveur d’écho. Vous verrez probablement beaucoup plus de sortie, selon le système sur lequel vous l’exécutez. Les choses à noter sont les colonnes + Proto +, + Adresse locale +, et + (état) +. Dans le dernier exemple ci-dessus, netstat montre que le serveur d’écho utilise un socket TCP IPv4 (+ tcp4 +), sur le port 65432 sur toutes les interfaces (+ *. 65432 +), et qu’il est à l’état d’écoute (`+ LISTEN + ').
Une autre façon de voir cela, avec des informations utiles supplémentaires, est d’utiliser + lsof + (liste des fichiers ouverts). Il est disponible par défaut sur macOS et peut être installé sur Linux à l’aide de votre gestionnaire de packages, s’il n’est pas déjà:
$ lsof -i -n
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
Python 67982 nathan 3u IPv4 0xecf272 0t0 TCP *:65432 (LISTEN)+ lsof + vous donne les + COMMAND +, + PID + (identifiant de processus) et + USER + (id d’utilisateur) des sockets Internet ouvertes lorsqu’il est utilisé avec l’option + -i +. Ci-dessus, le processus du serveur d’écho.
+ netstat + et + lsof + ont beaucoup d’options disponibles et diffèrent selon le système d’exploitation sur lequel vous les exécutez. Consultez la page + man + ou la documentation pour les deux. Ils valent vraiment la peine de passer un peu de temps avec et d’apprendre à connaître. Vous serez récompensé. Sous macOS et Linux, utilisez + man netstat + et + man lsof +. Pour Windows, utilisez + netstat/? +.
Voici une erreur courante que vous verrez lors d’une tentative de connexion à un port sans socket d’écoute:
$ ./echo-client.py
Traceback (most recent call last):
File "./echo-client.py", line 9, in <module>
s.connect((HOST, PORT))
ConnectionRefusedError: [Errno 61] Connection refusedSoit le numéro de port spécifié est incorrect, soit le serveur ne fonctionne pas. Ou peut-être qu’il y a un pare-feu sur le chemin qui bloque la connexion, ce qui peut être facile à oublier. Vous pouvez également voir l’erreur `+ La connexion a expiré + '. Obtenez une règle de pare-feu ajoutée qui permet au client de se connecter au port TCP!
Il existe une liste de liens communs: #errors [erreurs] dans la section référence.
Panne de communication
Voyons de plus près comment le client et le serveur communiquent entre eux:
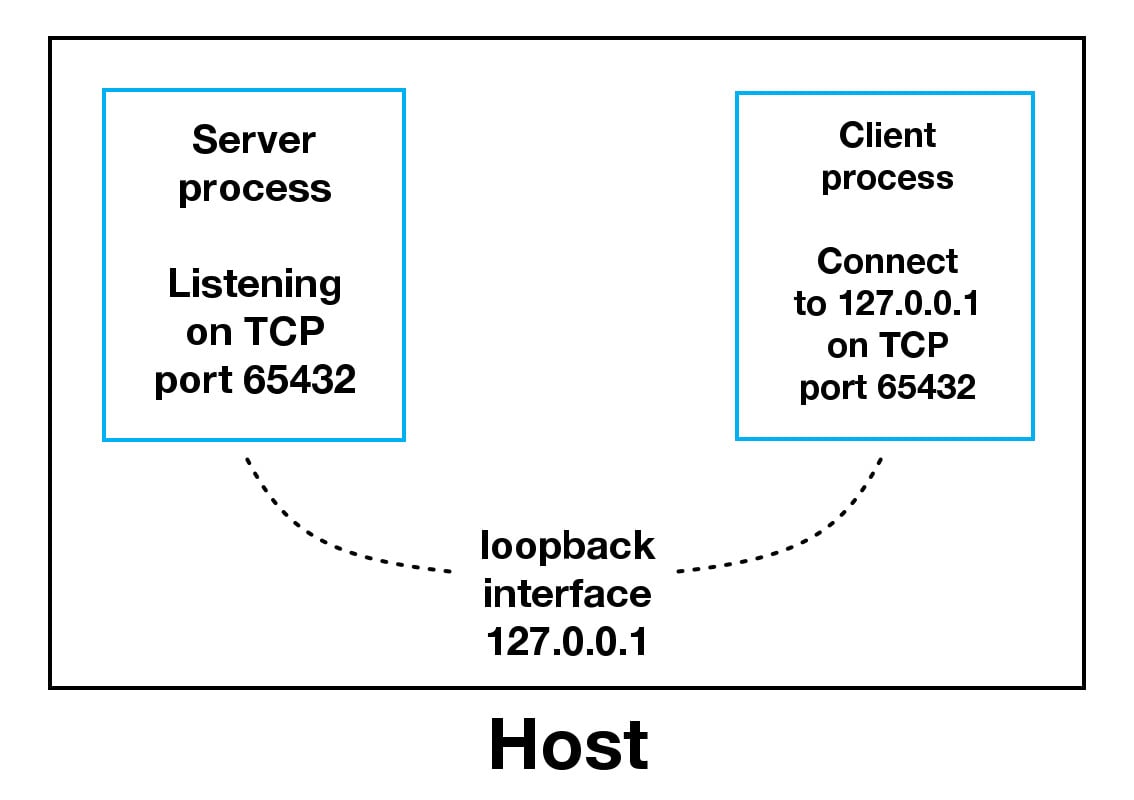
- Lorsque vous utilisez l’interface loopback (adresse IPv4
+ 127.0.0.1 +ou adresse IPv6 `+ -
1 `), les données ne quittent jamais l'hôte ou ne touchent pas le réseau externe. Dans le diagramme ci-dessus, l'interface de bouclage est contenue à l'intérieur de l'hôte. Cela représente la nature interne de l'interface de bouclage et le fait que les connexions et les données qui la transitent sont locales à l'hôte. C’est pourquoi vous entendrez également l’interface de bouclage et l’adresse IP « 127.0.0.1 » ou « :: 1 +» appelés «localhost».
Les applications utilisent l’interface de bouclage pour communiquer avec d’autres processus en cours d’exécution sur l’hôte et pour la sécurité et l’isolement du réseau externe. Puisqu’il est interne et accessible uniquement depuis l’hôte, il n’est pas exposé.
Vous pouvez le voir en action si vous avez un serveur d’applications qui utilise sa propre base de données privée. S’il ne s’agit pas d’une base de données utilisée par d’autres serveurs, elle est probablement configurée pour écouter uniquement les connexions sur l’interface de bouclage. Si tel est le cas, les autres hôtes du réseau ne peuvent pas s’y connecter.
- Lorsque vous utilisez une adresse IP autre que
+ 127.0.0.1 +ou `+ -
1 +` dans vos applications, elle est probablement liée à une interface Ethernet qui est connecté à un réseau externe. Ceci est votre passerelle vers d’autres hôtes en dehors de votre royaume «localhost»:
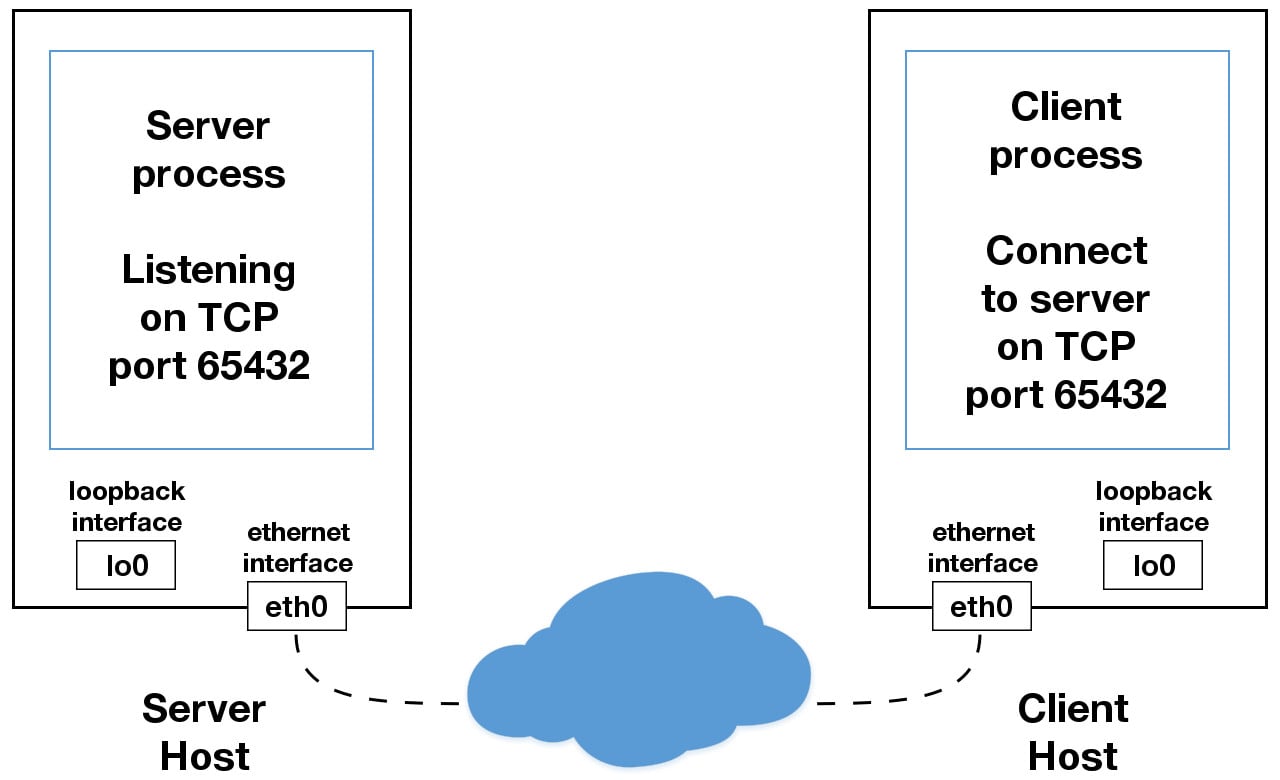
Soyez prudent là-bas. C’est un monde méchant et cruel. Assurez-vous de lire le lien de la section: # using-hostnames [Using Hostnames] avant de vous aventurer hors des limites sûres de "localhost". Il existe une note de sécurité qui s’applique même si vous n’utilisez pas de noms d’hôtes et n’utilisez que des adresses IP.
Gestion de plusieurs connexions
Le serveur d’écho a définitivement ses limites. Le plus gros étant qu’il ne dessert qu’un seul client puis sort. Le client d’écho a également cette limitation, mais il y a un problème supplémentaire. Lorsque le client effectue l’appel suivant, il est possible que + s.recv () + renvoie un seul octet, + b’H '+ de + b’Hello, world' +:
data = s.recv(1024)L’argument + bufsize + de + 1024 + utilisé ci-dessus est la quantité maximale de données à recevoir en une seule fois. Cela ne signifie pas que + recv () + renverra + 1024 + octets.
+ send () + se comporte également de cette façon. + send () + renvoie le nombre d’octets envoyés, qui peut être inférieur à la taille des données transmises. Vous êtes responsable de vérifier cela et d’appeler + send () + autant de fois que nécessaire pour envoyer toutes les données:
_ «Les candidatures sont chargées de vérifier que toutes les données ont bien été envoyées; si seulement une partie des données a été transmise, l’application doit tenter de remettre les données restantes. » (Source) _
Nous avons évité d’avoir à le faire en utilisant + sendall () +:
_ «Contrairement à send (), cette méthode continue d’envoyer des données à partir d’octets jusqu’à ce que toutes les données aient été envoyées ou qu’une erreur se produise. Aucun n’est retourné en cas de succès. » (Source) _
Nous avons deux problèmes à ce stade:
-
Comment traitons-nous plusieurs connexions simultanément?
-
Nous devons appeler
+ send () +et+ recv () +jusqu’à ce que toutes les données soient envoyées ou reçues.
Qu’est-ce qu’on fait? Il existe de nombreuses approches de concurrency. Plus récemment, une approche populaire consiste à utiliser Asynchronous I/O. + asyncio + a été introduit dans la bibliothèque standard de Python 3.4. Le choix traditionnel consiste à utiliser threads.
Le problème avec la concurrence est qu’il est difficile de bien faire les choses. Il y a de nombreuses subtilités à considérer et à éviter. Tout ce qu’il faut, c’est que l’un d’eux se manifeste et votre application peut soudainement échouer de manière pas si subtile.
Je ne dis pas cela pour vous effrayer d’apprendre et d’utiliser la programmation simultanée. Si votre application doit évoluer, c’est une nécessité si vous souhaitez utiliser plus d’un processeur ou d’un cœur. Cependant, pour ce didacticiel, nous utiliserons quelque chose de plus traditionnel que les threads et plus facile à raisonner. Nous allons utiliser le grand-père des appels système: https://docs.python.org/3/library/selectors.html#selectors.BaseSelector.select [+ select () +].
+ select () + vous permet de vérifier l’achèvement des E/S sur plusieurs sockets. Vous pouvez donc appeler + select () + pour voir quelles sockets ont des E/S prêtes pour la lecture et/ou l’écriture. Mais c’est Python, donc il y a plus. Nous allons utiliser le module selectors dans la bibliothèque standard afin que l’implémentation la plus efficace soit utilisée, quel que soit le système d’exploitation que nous exécutons. sur:
_ «Ce module permet un multiplexage d’E/S efficace et de haut niveau, basé sur les primitives de module sélectionnées. Les utilisateurs sont encouragés à utiliser ce module à la place, à moins qu’ils ne souhaitent un contrôle précis sur les primitives de niveau OS utilisées. » (Source) _
Même si, en utilisant + select () +, nous ne pouvons pas exécuter simultanément, en fonction de votre charge de travail, cette approche peut encore être très rapide. Cela dépend de ce que votre application doit faire lorsqu’elle répond à une demande et du nombre de clients qu’elle doit prendre en charge.
https://docs.python.org/3/library/asyncio.html [+ asyncio +] utilise le multitâche coopératif à un seul thread et une boucle d’événements pour gérer les tâches. Avec + select () +, nous allons écrire notre propre version d’une boucle d’événement, quoique plus simplement et de manière synchrone. Lorsque vous utilisez plusieurs threads, même si vous disposez de la concurrence, nous devons actuellement utiliser GIL avec CPython et PyPy . Cela limite effectivement la quantité de travail que nous pouvons faire en parallèle de toute façon.
Je dis tout cela pour expliquer que l’utilisation de + select () + peut être un très bon choix. Ne vous sentez pas obligé d’utiliser "+ asyncio +", des threads ou la dernière bibliothèque asynchrone. En règle générale, dans une application réseau, votre application est liée aux E/S: elle peut être en attente sur le réseau local, des points de terminaison de l’autre côté du réseau, sur un disque, etc.
Si vous recevez des demandes de clients qui lancent un travail lié au processeur, consultez le module concurrent.futures. Il contient la classe ProcessPoolExecutor qui utilise un pool de processus pour exécuter des appels de manière asynchrone.
Si vous utilisez plusieurs processus, le système d’exploitation peut planifier l’exécution de votre code Python en parallèle sur plusieurs processeurs ou cœurs, sans GIL. Pour des idées et de l’inspiration, consultez la conférence PyCon John Reese - Penser en dehors du GIL avec AsyncIO et Multiprocessing - PyCon 2018.
Dans la section suivante, nous examinerons des exemples de serveur et de client qui résolvent ces problèmes. Ils utilisent + select () + pour gérer plusieurs connexions simultanément et appellent + send () + et + recv () + autant de fois que nécessaire.
Client et serveur à connexions multiples
Dans les deux sections suivantes, nous allons créer un serveur et un client qui gèrent plusieurs connexions à l’aide d’un objet + selector + créé à partir du module selectors.
Serveur multiconnexion
Voyons d’abord le serveur multi-connexions, + multiconn-server.py +. Voici la première partie qui configure la prise d’écoute:
import selectors
sel = selectors.DefaultSelector()
# ...
lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
lsock.bind((host, port))
lsock.listen()
print('listening on', (host, port))
lsock.setblocking(False)
sel.register(lsock, selectors.EVENT_READ, data=None)La plus grande différence entre ce serveur et le serveur d’écho est l’appel à + lsock.setblocking (False) + pour configurer le socket en mode non bloquant. Les appels effectués vers cette socket ne lieront plus: # blocking-calls [block]. Lorsqu’il est utilisé avec + sel.select () +, comme vous le verrez ci-dessous, nous pouvons attendre des événements sur un ou plusieurs sockets, puis lire et écrire des données lorsqu’il est prêt.
+ sel.register () + enregistre la socket à surveiller avec + sel.select () + pour les événements qui vous intéressent. Pour la socket d’écoute, nous voulons lire les événements: + selectors.EVENT_READ +.
+ data + est utilisé pour stocker toutes les données arbitraires que vous souhaitez avec le socket. Il est renvoyé lorsque + select () + revient. Nous utiliserons + data + pour garder une trace de ce qui a été envoyé et reçu sur le socket.
Vient ensuite la boucle d’événement:
import selectors
sel = selectors.DefaultSelector()
# ...
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
service_connection(key, mask)https://docs.python.org/3/library/selectors.html#selectors.BaseSelector.select [+ sel.select (timeout = None) +] link: # blocking-calls [blocks] jusqu’à ce qu’il y ait des sockets prêt pour les E/S. Il renvoie une liste de tuples (clé, événements), un pour chaque socket. + key + est un SelectorKey + namedtuple + qui contient un attribut + fileobj +. + key.fileobj + est l’objet socket, et + mask + est un masque d’événement des opérations qui sont prêtes.
Si + key.data + est + None +, alors nous savons que c’est à partir de la prise d’écoute et nous devons + accepter () + la connexion. Nous appellerons notre propre fonction wrapper + accept () + pour obtenir le nouvel objet socket et l’enregistrer avec le sélecteur. Nous allons l’examiner dans un instant.
Si + key.data + n’est pas + None + ', alors nous savons que c’est un socket client qui a déjà été accepté, et nous devons le réparer. `+ service_connection () + est alors appelé et passé + key + et + mask +, qui contient tout ce dont nous avons besoin pour fonctionner sur le socket.
Voyons ce que fait notre fonction + accept_wrapper () +:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
data = types.SimpleNamespace(addr=addr, inb=b'', outb=b'')
events = selectors.EVENT_READ | selectors.EVENT_WRITE
sel.register(conn, events, data=data)Le socket d’écoute étant enregistré pour l’événement + selectors.EVENT_READ +, il doit être prêt à être lu. Nous appelons + sock.accept () + puis appelons immédiatement + conn.setblocking (False) + pour mettre le socket en mode non bloquant.
Rappelez-vous, c’est l’objectif principal de cette version du serveur car nous ne voulons pas qu’il relie: # blocking-calls [block]. S’il bloque, le serveur entier est bloqué jusqu’à ce qu’il revienne. Ce qui signifie que d’autres prises sont laissées en attente. C’est l’état redouté de "blocage" dans lequel vous ne voulez pas que votre serveur soit.
Ensuite, nous créons un objet pour contenir les données que nous voulons inclure avec le socket en utilisant la classe + types.SimpleNamespace +. Puisque nous voulons savoir quand la connexion client est prête pour la lecture et l’écriture, ces deux événements sont définis à l’aide des éléments suivants:
events = selectors.EVENT_READ | selectors.EVENT_WRITELes masques, événements et données + events + sont ensuite passés à + sel.register () +.
Regardons maintenant + service_connection () + pour voir comment une connexion client est gérée lorsqu’elle est prête:
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if data.outb:
print('echoing', repr(data.outb), 'to', data.addr)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]C’est le cœur du simple serveur multi-connexions. + key + est le + namedtuple + renvoyé par + select () + qui contient l’objet socket (+ fileobj +) et l’objet de données. + mask + contient les événements qui sont prêts.
Si le socket est prêt pour la lecture, alors + mask & selectors.EVENT_READ + est vrai, et + sock.recv () + est appelé. Toutes les données lues sont ajoutées à + data.outb + afin de pouvoir être envoyées plus tard.
Notez le bloc + else: + si aucune donnée n’est reçue:
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()Cela signifie que le client a fermé son socket, donc le serveur devrait aussi. Mais n’oubliez pas d’appeler d’abord + sel.unregister () + afin qu’il ne soit plus surveillé par + select () +.
Lorsque le socket est prêt pour l’écriture, ce qui devrait toujours être le cas pour un socket sain, toutes les données reçues stockées dans + data.outb + sont renvoyées au client en utilisant + sock.send () +. Les octets envoyés sont ensuite supprimés du tampon d’envoi:
data.outb = data.outb[sent:]Client à connexions multiples
Voyons maintenant le client multi-connexion, + multiconn-client.py +. Il est très similaire au serveur, mais au lieu d’écouter les connexions, il commence par lancer des connexions via + start_connections () +:
messages = [b'Message 1 from client.', b'Message 2 from client.']
def start_connections(host, port, num_conns):
server_addr = (host, port)
for i in range(0, num_conns):
connid = i + 1
print('starting connection', connid, 'to', server_addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(server_addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
data = types.SimpleNamespace(connid=connid,
msg_total=sum(len(m) for m in messages),
recv_total=0,
messages=list(messages),
outb=b'')
sel.register(sock, events, data=data)+ num_conns + est lu à partir de la ligne de commande, qui est le nombre de connexions à créer sur le serveur. Tout comme le serveur, chaque socket est réglé en mode non bloquant.
+ connect_ex () + est utilisé à la place de + connect () + car + connect () + déclencherait immédiatement une exception + BlockingIOError +. + connect_ex () + renvoie initialement un indicateur d’erreur, + errno.EINPROGRESS +, au lieu de déclencher une exception pendant que la connexion est en cours. Une fois la connexion établie, le socket est prêt pour la lecture et l’écriture et est renvoyé comme tel par + select () +.
Une fois le socket configuré, les données que nous voulons stocker avec le socket sont créées à l’aide de la classe + types.SimpleNamespace +. Les messages que le client enverra au serveur sont copiés en utilisant + list (messages) + car chaque connexion appellera + socket.send () + et modifiera la liste. Tout le nécessaire pour garder une trace de ce que le client doit envoyer, a envoyé et reçu, et le nombre total d’octets dans les messages est stocké dans l’objet + data +.
Regardons + service_connection () +. C’est fondamentalement la même chose que le serveur:
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
print('received', repr(recv_data), 'from connection', data.connid)
data.recv_total += len(recv_data)
if not recv_data or data.recv_total == data.msg_total:
print('closing connection', data.connid)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if not data.outb and data.messages:
data.outb = data.messages.pop(0)
if data.outb:
print('sending', repr(data.outb), 'to connection', data.connid)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]Il y a une différence importante. Il garde une trace du nombre d’octets reçus du serveur afin de pouvoir fermer son côté de la connexion. Lorsque le serveur le détecte, il ferme également son côté de la connexion.
Notez que ce faisant, le serveur dépend du bon comportement du client: le serveur attend du client qu’il ferme son côté de la connexion lorsqu’il a fini d’envoyer des messages. Si le client ne ferme pas, le serveur laisse la connexion ouverte. Dans une application réelle, vous souhaiterez peut-être vous prémunir contre cela sur votre serveur et empêcher les connexions clientes de s’accumuler si elles n’envoient pas de demande après un certain temps.
Exécution du client et du serveur à connexions multiples
Maintenant, exécutons + multiconn-server.py + et + multiconn-client.py +. Ils utilisent tous deux des arguments de ligne de commande. Vous pouvez les exécuter sans arguments pour voir les options.
Pour le serveur, passez un numéro + host + et + port +:
$ ./multiconn-server.py
usage: ./multiconn-server.py <host> <port>Pour le client, passez également le nombre de connexions à créer au serveur, + num_connections +:
$ ./multiconn-client.py
usage: ./multiconn-client.py <host> <port> <num_connections>Voici la sortie du serveur lors de l’écoute sur l’interface de bouclage sur le port 65432:
$ ./multiconn-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)
accepted connection from ('127.0.0.1', 61354)
accepted connection from ('127.0.0.1', 61355)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61354)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61355)
closing connection to ('127.0.0.1', 61354)
closing connection to ('127.0.0.1', 61355)Vous trouverez ci-dessous la sortie client lorsqu’elle crée deux connexions au serveur ci-dessus:
$ ./multiconn-client.py 127.0.0.1 65432 2
starting connection 1 to ('127.0.0.1', 65432)
starting connection 2 to ('127.0.0.1', 65432)
sending b'Message 1 from client.' to connection 1
sending b'Message 2 from client.' to connection 1
sending b'Message 1 from client.' to connection 2
sending b'Message 2 from client.' to connection 2
received b'Message 1 from client.Message 2 from client.' from connection 1
closing connection 1
received b'Message 1 from client.Message 2 from client.' from connection 2
closing connection 2Client et serveur d’application
L’exemple de client et de serveur multi-connexion est certainement une amélioration par rapport à notre point de départ. Cependant, faisons un pas de plus et corrigeons les lacunes de l’exemple précédent "multiconn" dans une implémentation finale: le client et le serveur d’application.
Nous voulons un client et un serveur qui gèrent les erreurs de manière appropriée afin que les autres connexions ne soient pas affectées. De toute évidence, notre client ou serveur ne devrait pas s’écraser dans une boule de fureur si aucune exception n’est détectée. C’est quelque chose dont nous n’avons pas discuté jusqu’à présent. J’ai intentionnellement omis la gestion des erreurs pour des raisons de brièveté et de clarté dans les exemples.
Maintenant que vous connaissez l’API de base, les sockets non bloquants et + select () +, nous pouvons ajouter une gestion des erreurs et discuter de «l’éléphant dans la pièce» que je vous ai caché derrière cela grand rideau là-bas. Oui, je parle de la classe personnalisée que j’ai mentionnée dans l’introduction. Je savais que tu n’oublierais pas.
Commençons par corriger les erreurs:
_
«Toutes les erreurs soulèvent des exceptions. Les exceptions normales pour les types d’arguments non valides et les conditions de mémoire insuffisante peuvent être levées; à partir de Python 3.3, les erreurs liées à la sémantique de socket ou d’adresse déclenchent + OSError + ou l’une de ses sous-classes. " (Source)
_
Nous devons attraper + OSError +. Une autre chose que je n’ai pas mentionnée en ce qui concerne les erreurs est les délais d’attente. Vous les verrez discutés à de nombreux endroits dans la documentation. Les délais d’attente se produisent et sont une erreur «normale». Les hôtes et les routeurs sont redémarrés, les ports de commutation vont mal, les câbles vont mal, les câbles se débranchent, vous l’appelez. Vous devez être préparé à ces erreurs et à d’autres et les gérer dans votre code.
Qu’en est-il de «l’éléphant dans la pièce?» Comme l’indique le type de socket + socket.SOCK_STREAM +, lorsque vous utilisez TCP, vous lisez à partir d’un flux continu d’octets. C’est comme lire un fichier sur le disque, mais à la place, vous lisez des octets sur le réseau.
Cependant, contrairement à la lecture d’un fichier, il n’y a pas https://docs.python.org/3/tutorial/inputoutput.html#methods-of-file-objects [+ f.seek () +]. En d’autres termes, vous ne pouvez pas repositionner le pointeur de socket, s’il y en avait un, et vous déplacer de manière aléatoire dans les données de lecture, quand vous le souhaitez.
Lorsque des octets arrivent sur votre socket, des tampons réseau sont impliqués. Une fois que vous les avez lus, ils doivent être enregistrés quelque part. Appeler + recv () + à nouveau lit le prochain flux d’octets disponible à partir du socket.
Ce que cela signifie, c’est que vous lirez à partir du socket par blocs. Vous devez appeler + recv () + et enregistrer les données dans un tampon jusqu’à ce que vous ayez lu suffisamment d’octets pour avoir un message complet qui a du sens pour votre application.
C’est à vous de définir et de suivre où se trouvent les limites des messages. En ce qui concerne le socket TCP, il s’agit simplement d’envoyer et de recevoir des octets bruts vers et depuis le réseau. Il ne sait pas ce que signifient ces octets bruts.
Cela nous amène à définir un protocole de couche application. Qu’est-ce qu’un protocole de couche application? En termes simples, votre application enverra et recevra des messages. Ces messages sont le protocole de votre application.
En d’autres termes, la longueur et le format que vous choisissez pour ces messages définissent la sémantique et le comportement de votre application. Ceci est directement lié à ce que j’ai expliqué dans le paragraphe précédent concernant la lecture d’octets à partir du socket. Lorsque vous lisez des octets avec + recv () +, vous devez suivre le nombre d’octets lus et déterminer où se trouvent les limites du message.
Comment cela se fait-il? Une façon consiste à toujours envoyer des messages de longueur fixe. S’ils sont toujours de la même taille, c’est facile. Lorsque vous avez lu ce nombre d’octets dans un tampon, vous savez que vous avez un message complet.
Cependant, l’utilisation de messages de longueur fixe est inefficace pour les petits messages où vous devez utiliser un remplissage pour les remplir. De plus, vous ne savez toujours pas quoi faire des données qui ne rentrent pas dans un seul message.
Dans ce didacticiel, nous adopterons une approche générique. Une approche utilisée par de nombreux protocoles, dont HTTP. Nous allons préfixer les messages avec un en-tête qui inclut la longueur du contenu ainsi que tous les autres champs dont nous avons besoin. Ce faisant, nous n’aurons qu’à suivre l’en-tête. Une fois que nous avons lu l’en-tête, nous pouvons le traiter pour déterminer la longueur du contenu du message, puis lire ce nombre d’octets pour le consommer.
Nous allons implémenter cela en créant une classe personnalisée qui peut envoyer et recevoir des messages contenant du texte ou des données binaires. Vous pouvez l’améliorer et l’étendre pour vos propres applications. La chose la plus importante est que vous pourrez voir un exemple de la façon dont cela se fait.
Je dois mentionner quelque chose concernant les sockets et les octets qui peuvent vous affecter. Comme nous l’avons mentionné précédemment, lorsque vous envoyez et recevez des données via des sockets, vous envoyez et recevez des octets bruts.
Si vous recevez des données et que vous souhaitez les utiliser dans un contexte où elles sont interprétées comme plusieurs octets, par exemple un entier sur 4 octets, vous devez tenir compte du fait qu’elles peuvent être dans un format qui n’est pas natif du processeur de votre machine. Le client ou le serveur à l’autre extrémité peut avoir un processeur qui utilise un ordre d’octets différent du vôtre. Si tel est le cas, vous devrez le convertir en ordre d’octets natif de votre hôte avant de l’utiliser.
Cet ordre d’octets est appelé endianness d’un processeur. Voir le lien: # byte-endianness [Byte Endianness] dans la section référence pour plus de détails. Nous éviterons ce problème en profitant d’Unicode pour notre en-tête de message et en utilisant le codage UTF-8. Comme UTF-8 utilise un codage 8 bits, il n’y a pas de problème de commande d’octets.
Vous pouvez trouver une explication dans la documentation Encodings et Unicode de Python. Notez que cela s’applique uniquement à l’en-tête de texte. Nous utiliserons un type et un codage explicites définis dans l’en-tête pour le contenu envoyé, la charge utile du message. Cela nous permettra de transférer toutes les données que nous aimerions (texte ou binaire), dans n’importe quel format.
Vous pouvez facilement déterminer l’ordre des octets de votre machine en utilisant + sys.byteorder +. Par exemple, sur mon ordinateur portable Intel, cela se produit:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'little'Si j’exécute ceci dans une machine virtuelle qui emulate un CPU big-endian (PowerPC), alors cela se produit:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'big'Dans cet exemple d’application, notre protocole de couche application définit l’en-tête comme du texte Unicode avec un codage UTF-8. Pour le contenu réel du message, la charge utile du message, vous devrez toujours permuter manuellement l’ordre des octets si nécessaire.
Cela dépendra de votre application et de la nécessité ou non de traiter des données binaires multi-octets d’une machine avec une endianité différente. Vous pouvez aider votre client ou serveur à implémenter la prise en charge binaire en ajoutant des en-têtes supplémentaires et en les utilisant pour passer des paramètres, comme HTTP.
Ne vous inquiétez pas si cela n’a pas encore de sens. Dans la section suivante, vous verrez comment tout cela fonctionne et s’emboîte.
En-tête de protocole d’application
Définissons entièrement l’en-tête du protocole. L’en-tête du protocole est:
-
Texte de longueur variable
-
Unicode avec l’encodage UTF-8
-
Un dictionnaire Python sérialisé en utilisant JSON
Les en-têtes ou sous-en-têtes requis dans le dictionnaire des en-têtes de protocole sont les suivants:
| Name | Description |
|---|---|
|
The byte order of the machine (uses |
|
The length of the content in bytes. |
|
The type of content in the payload, for example, |
|
The encoding used by the content, for example, |
Ces en-têtes informent le destinataire du contenu de la charge utile du message. Cela vous permet d’envoyer des données arbitraires tout en fournissant suffisamment d’informations pour que le contenu puisse être décodé et interprété correctement par le récepteur. Étant donné que les en-têtes sont dans un dictionnaire, il est facile d’ajouter des en-têtes supplémentaires en insérant des paires clé/valeur selon les besoins.
Envoi d’un message d’application
Il y a toujours un petit problème. Nous avons un en-tête de longueur variable, ce qui est agréable et flexible, mais comment savez-vous la longueur de l’en-tête lorsque vous le lisez avec + recv () +?
Lorsque nous avons déjà parlé de l’utilisation de + recv () + et des limites de message, j’ai mentionné que les en-têtes de longueur fixe peuvent être inefficaces. C’est vrai, mais nous allons utiliser un petit en-tête de longueur fixe de 2 octets pour préfixer l’en-tête JSON qui contient sa longueur.
Vous pouvez considérer cela comme une approche hybride pour l’envoi de messages. En fait, nous démarrons le processus de réception des messages en envoyant d’abord la longueur de l’en-tête. Cela permet à notre destinataire de déconstruire facilement le message.
Pour vous donner une meilleure idée du format du message, regardons un message dans son intégralité:
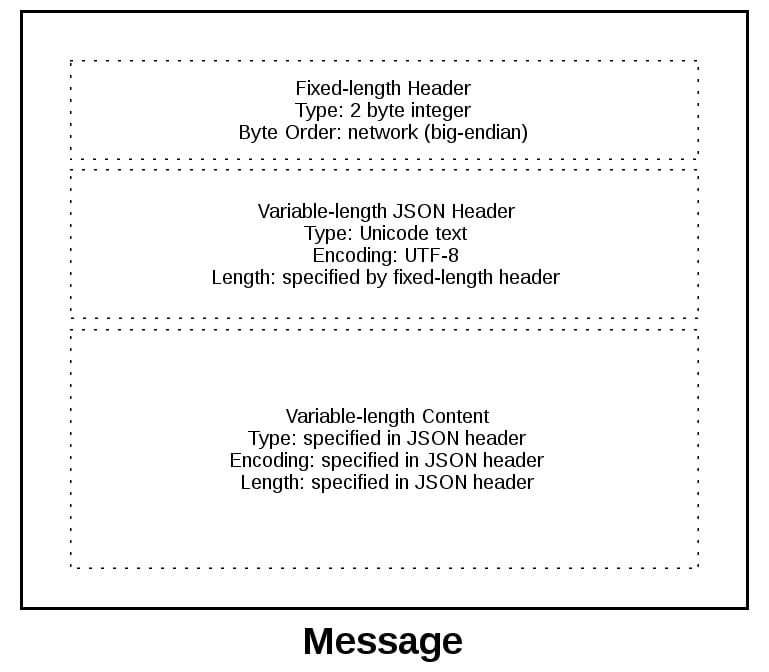
Un message commence par un en-tête de longueur fixe de 2 octets qui est un entier dans l’ordre des octets du réseau. Il s’agit de la longueur de l’en-tête suivant, l’en-tête JSON de longueur variable. Une fois que nous avons lu 2 octets avec + recv () +, nous savons que nous pouvons traiter les 2 octets sous forme d’entier puis lire ce nombre d’octets avant de décoder l’en-tête JSON UTF-8.
Le lien: # application-protocol-header [en-tête JSON] contient un dictionnaire d’en-têtes supplémentaires. L’un d’entre eux est + content-length +, qui est le nombre d’octets du contenu du message (sans inclure l’en-tête JSON). Une fois que nous avons appelé + recv () + et lu + content-length + bytes, nous avons atteint la limite du message et lu un message entier.
Classe de message d’application
Enfin, le gain! Examinons la classe + Message + et voyons comment elle est utilisée avec + select () + lorsque des événements de lecture et d’écriture se produisent sur le socket.
Pour cet exemple d’application, j’ai dû trouver une idée des types de messages que le client et le serveur utiliseraient. Nous sommes bien au-delà des clients et des serveurs d’écho jouet à ce stade.
Pour garder les choses simples et montrer comment les choses fonctionneraient dans une application réelle, j’ai créé un protocole d’application qui implémente une fonction de recherche de base. Le client envoie une demande de recherche et le serveur recherche une correspondance. Si la demande envoyée par le client n’est pas reconnue comme une recherche, le serveur suppose qu’il s’agit d’une demande binaire et renvoie une réponse binaire.
Après avoir lu les sections suivantes, exécuté les exemples et expérimenté le code, vous verrez comment les choses fonctionnent. Vous pouvez ensuite utiliser la classe + Message + comme point de départ et la modifier pour votre propre usage.
Nous ne sommes vraiment pas si loin de l’exemple du client et du serveur «multiconn». Le code de boucle d’événement reste le même dans + app-client.py + et + app-server.py +. Ce que j’ai fait, c’est déplacer le code du message dans une classe nommée + Message + et ajouter des méthodes pour prendre en charge la lecture, l’écriture et le traitement des en-têtes et du contenu. Ceci est un excellent exemple d’utilisation d’une classe.
Comme nous l’avons vu précédemment et vous le verrez ci-dessous, travailler avec des sockets implique de conserver l’état. En utilisant une classe, nous conservons tous les états, données et codes regroupés dans une unité organisée. Une instance de la classe est créée pour chaque socket du client et du serveur lorsqu’une connexion est démarrée ou acceptée.
La classe est essentiellement la même pour le client et le serveur pour les méthodes wrapper et utilitaire. Ils commencent par un trait de soulignement, comme + Message._json_encode () +. Ces méthodes simplifient le travail avec la classe. Ils aident d’autres méthodes en leur permettant de rester plus courts et prennent en charge le principe DRY.
La classe `+ Message + 'du serveur fonctionne essentiellement de la même manière que celle du client et vice-versa. La différence est que le client initie la connexion et envoie un message de demande, suivi du traitement du message de réponse du serveur. Inversement, le serveur attend une connexion, traite le message de demande du client, puis envoie un message de réponse.
Cela ressemble à ceci:
| Step | Endpoint | Action/Message Content |
|---|---|---|
1 |
Client |
Sends a |
2 |
Server |
Receives and processes client request |
3 |
Server |
Sends a |
4 |
Client |
Receives and processes server response |
Voici la disposition des fichiers et du code:
| Application | File | Code |
|---|---|---|
Server |
|
The server’s main script |
Server |
|
The server’s |
Client |
|
The client’s main script |
Client |
|
The client’s |
Point d’entrée de message
Je voudrais discuter du fonctionnement de la classe + Message + en mentionnant d’abord un aspect de sa conception qui n’était pas immédiatement évident pour moi. Ce n’est qu’après l’avoir refactorisé au moins cinq fois que je suis arrivé à ce qu’il est actuellement. Why? Gestion de l’état.
Après avoir créé un objet + Message +, il est associé à une socket surveillée pour les événements à l’aide de + selector.register () +:
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)*Remarque:* Certains des exemples de code de cette section proviennent du script principal du serveur et de la classe `+ Message +`, mais cette section et cette discussion s'appliquent également au client. Je vais montrer et expliquer la version du client lorsqu'elle diffère.
Lorsque les événements sont prêts sur le socket, ils sont renvoyés par + selector.select () +. On peut alors récupérer une référence à l’objet message en utilisant l’attribut + data + sur l’objet + key + et appeler une méthode dans + Message +:
while True:
events = sel.select(timeout=None)
for key, mask in events:
# ...
message = key.data
message.process_events(mask)En regardant la boucle d’événement ci-dessus, vous verrez que + sel.select () + est dans le siège du conducteur. Il bloque, attend en haut de la boucle les événements. Il est chargé de se réveiller lorsque les événements de lecture et d’écriture sont prêts à être traités sur le socket. Ce qui signifie, indirectement, qu’il est également responsable d’appeler la méthode + process_events () +. C’est ce que je veux dire quand je dis que la méthode + process_events () + est le point d’entrée.
Voyons ce que fait la méthode + process_events () +:
def process_events(self, mask):
if mask & selectors.EVENT_READ:
self.read()
if mask & selectors.EVENT_WRITE:
self.write()C’est bien: + process_events () + est simple. Il ne peut faire que deux choses: appeler + read () + et + write () +.
Cela nous ramène à la gestion de l’État. Après quelques refactorisations, j’ai décidé que si une autre méthode dépendait de variables d’état ayant une certaine valeur, alors elles ne seraient appelées qu’à partir de + read () + et + write () +. Cela maintient la logique aussi simple que possible lorsque des événements arrivent sur le socket pour le traitement.
Cela peut sembler évident, mais les premières itérations de la classe étaient un mélange de certaines méthodes qui vérifiaient l’état actuel et, selon leur valeur, appelaient d’autres méthodes pour traiter les données en dehors de + read () + ou `+ write ( ) + `. Au final, cela s’est avéré trop complexe à gérer et à suivre.
Vous devez absolument modifier la classe pour l’adapter à vos propres besoins afin qu’elle fonctionne le mieux pour vous, mais je vous recommande de conserver les vérifications d’état et les appels aux méthodes qui dépendent de cet état dans les + read () + et ` + méthodes write () + `si possible.
Regardons + read () +. Il s’agit de la version du serveur, mais celle du client est la même. Il utilise simplement un nom de méthode différent, + process_response () + au lieu de + process_request () +:
def read(self):
self._read()
if self._jsonheader_len is None:
self.process_protoheader()
if self._jsonheader_len is not None:
if self.jsonheader is None:
self.process_jsonheader()
if self.jsonheader:
if self.request is None:
self.process_request()La méthode + _read () + est appelée en premier. Il appelle + socket.recv () + pour lire les données du socket et les stocker dans un tampon de réception.
N’oubliez pas que lorsque + socket.recv () + est appelé, toutes les données qui composent un message complet peuvent ne pas être encore arrivées. + socket.recv () + peut devoir être appelé à nouveau. C’est pourquoi il existe des vérifications d’état pour chaque partie du message avant d’appeler la méthode appropriée pour le traiter.
Avant qu’une méthode ne traite sa partie du message, elle vérifie d’abord que suffisamment d’octets ont été lus dans le tampon de réception. S’il y en a, il traite ses octets respectifs, les supprime du tampon et écrit sa sortie dans une variable utilisée par la prochaine étape de traitement. Puisqu’il y a trois composants dans un message, il y a trois vérifications d’état et les appels de méthode + process +:
| Message Component | Method | Output |
|---|---|---|
Fixed-length header |
|
|
JSON header |
|
|
Content |
|
|
Ensuite, regardons + write () +. Voici la version du serveur:
def write(self):
if self.request:
if not self.response_created:
self.create_response()
self._write()+ write () + recherche d’abord une + demande +. S’il en existe une et qu’aucune réponse n’a été créée, + create_response () + est appelé. + create_response () + définit la variable d’état + response_created + et écrit la réponse dans le tampon d’envoi.
La méthode + _write () + appelle + socket.send () + s’il y a des données dans le tampon d’envoi.
N’oubliez pas que lorsque + socket.send () + est appelé, toutes les données du tampon d’envoi peuvent ne pas avoir été mises en file d’attente pour la transmission. Les tampons réseau pour le socket peuvent être pleins, et + socket.send () + peut devoir être appelé à nouveau. C’est pourquoi il existe des contrôles d’État. + create_response () + ne devrait être appelé qu’une seule fois, mais il est prévu que + _write () + devra être appelé plusieurs fois.
La version client de + write () + est similaire:
def write(self):
if not self._request_queued:
self.queue_request()
self._write()
if self._request_queued:
if not self._send_buffer:
# Set selector to listen for read events, we're done writing.
self._set_selector_events_mask('r')Puisque le client établit une connexion au serveur et envoie d’abord une demande, la variable d’état + _request_queued + est vérifiée. Si une demande n’a pas été mise en file d’attente, elle appelle + queue_request () +. + queue_request () + crée la requête et l’écrit dans le tampon d’envoi. Il définit également la variable d’état + _request_queued + afin qu’elle ne soit appelée qu’une seule fois.
Tout comme le serveur, + _write () + appelle + socket.send () + s’il y a des données dans le tampon d’envoi.
La différence notable dans la version du client de + write () + est la dernière vérification pour voir si la demande a été mise en file d’attente. Ceci sera expliqué plus en détail dans le lien de la section: # client-main-script [Script principal client], mais la raison en est de dire + selector.select () + d’arrêter de surveiller le socket pour les événements d’écriture. Si la demande a été mise en file d’attente et que le tampon d’envoi est vide, nous avons fini d’écrire et nous ne sommes intéressés que par les événements de lecture. Il n’y a aucune raison d’être informé que le socket est accessible en écriture.
Je terminerai cette section en vous laissant une seule pensée. Le but principal de cette section était d’expliquer que + selector.select () + appelle dans la classe + Message + via la méthode + process_events () + et de décrire comment l’état est géré.
Ceci est important car + process_events () + sera appelé plusieurs fois pendant la durée de la connexion. Par conséquent, assurez-vous que toutes les méthodes qui ne doivent être appelées qu’une seule fois vérifient elles-mêmes une variable d’état ou que la variable d’état définie par la méthode est vérifiée par l’appelant.
Script principal du serveur
Dans le script principal du serveur + app-server.py +, les arguments sont lus à partir de la ligne de commande qui spécifient l’interface et le port sur lesquels écouter:
$ ./app-server.py
usage: ./app-server.py <host> <port>Par exemple, pour écouter sur l’interface de bouclage sur le port + 65432 +, entrez:
$ ./app-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)Utilisez une chaîne vide pour + <hôte> + pour écouter sur toutes les interfaces.
Après avoir créé le socket, un appel est fait à + socket.setsockopt () + avec l’option + socket.SO_REUSEADDR +:
# Avoid bind() exception: OSError: [Errno 48] Address already in use
lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)La définition de cette option de socket évite l’erreur + Adresse déjà utilisée +. Vous verrez cela lors du démarrage du serveur et une socket TCP précédemment utilisée sur le même port a des connexions dans les http://www.serverframework.com/asynchronousevents/2011/01/01/time-wait-and-its-design-implications -pour-protocoles-et-serveurs-évolutifs.html [TIME_WAIT] état.
Par exemple, si le serveur a activement fermé une connexion, il restera dans l’état + TIME_WAIT + pendant deux minutes ou plus, selon le système d’exploitation. Si vous essayez de redémarrer le serveur avant l’expiration de l’état + TIME_WAIT +, vous obtiendrez une exception + OSError + de `+ Adresse déjà utilisée + '. Il s’agit d’une garantie pour vous assurer que les paquets retardés du réseau ne sont pas envoyés à la mauvaise application.
La boucle d’événements intercepte toutes les erreurs afin que le serveur puisse rester en place et continuer à s’exécuter:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()Lorsqu’une connexion client est acceptée, un objet + Message + est créé:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)L’objet + Message + est associé à la socket dans l’appel à + sel.register () + et est initialement configuré pour être surveillé uniquement pour les événements en lecture. Une fois la demande lue, nous la modifierons pour écouter uniquement les événements d’écriture.
Un avantage de cette approche sur le serveur est que, dans la plupart des cas, lorsqu’un socket est sain et qu’il n’y a aucun problème de réseau, il sera toujours accessible en écriture.
Si nous disions à + sel.register () + de surveiller également + EVENT_WRITE +, la boucle d’événement se réveillerait immédiatement et nous informerait que c’est le cas. Cependant, à ce stade, il n’y a aucune raison de se réveiller et d’appeler + send () + sur le socket. Il n’y a pas de réponse à envoyer car une demande n’a pas encore été traitée. Cela consommerait et gaspillerait de précieux cycles CPU.
Classe de message du serveur
Dans le lien de la section: # message-entry-point [Message Entry Point], nous avons examiné comment l’objet + Message + a été appelé à l’action lorsque les événements de socket étaient prêts via + process_events () +. Voyons maintenant ce qui se passe lorsque les données sont lues sur le socket et qu’un composant, ou une partie, du message est prêt à être traité par le serveur.
La classe de message du serveur est dans + libserver.py +. Vous pouvez trouver le source code sur GitHub.
Les méthodes apparaissent dans la classe dans l’ordre dans lequel le traitement a lieu pour un message.
Lorsque le serveur a lu au moins 2 octets, l’en-tête de longueur fixe peut être traité:
def process_protoheader(self):
hdrlen = 2
if len(self._recv_buffer) >= hdrlen:
self._jsonheader_len = struct.unpack('>H',
self._recv_buffer[:hdrlen])[0]
self._recv_buffer = self._recv_buffer[hdrlen:]L’en-tête de longueur fixe est un entier de 2 octets dans l’ordre des octets réseau (big-endian) qui contient la longueur de l’en-tête JSON. https://docs.python.org/3/library/struct.html [struct.unpack ()] est utilisé pour lire la valeur, la décoder et la stocker dans + self._jsonheader_len +. Après avoir traité la partie du message dont il est responsable, + process_protoheader () + le supprime du tampon de réception.
Tout comme l’en-tête de longueur fixe, lorsqu’il y a suffisamment de données dans le tampon de réception pour contenir l’en-tête JSON, elles peuvent également être traitées:
def process_jsonheader(self):
hdrlen = self._jsonheader_len
if len(self._recv_buffer) >= hdrlen:
self.jsonheader = self._json_decode(self._recv_buffer[:hdrlen],
'utf-8')
self._recv_buffer = self._recv_buffer[hdrlen:]
for reqhdr in ('byteorder', 'content-length', 'content-type',
'content-encoding'):
if reqhdr not in self.jsonheader:
raise ValueError(f'Missing required header "{reqhdr}".')La méthode + self._json_decode () + est appelée pour décoder et désérialiser l’en-tête JSON dans un dictionnaire. Étant donné que l’en-tête JSON est défini comme Unicode avec un codage UTF-8, + utf-8 + est codé en dur dans l’appel. Le résultat est enregistré dans + self.jsonheader +. Après avoir traité la partie du message dont il est responsable, + process_jsonheader () + le supprime du tampon de réception.
Vient ensuite le contenu réel, ou charge utile, du message. Il est décrit par l’en-tête JSON dans + self.jsonheader +. Lorsque + content-length + bytes sont disponibles dans le tampon de réception, la demande peut être traitée:
def process_request(self):
content_len = self.jsonheader['content-length']
if not len(self._recv_buffer) >= content_len:
return
data = self._recv_buffer[:content_len]
self._recv_buffer = self._recv_buffer[content_len:]
if self.jsonheader['content-type'] == 'text/json':
encoding = self.jsonheader['content-encoding']
self.request = self._json_decode(data, encoding)
print('received request', repr(self.request), 'from', self.addr)
else:
# Binary or unknown content-type
self.request = data
print(f'received {self.jsonheader["content-type"]} request from',
self.addr)
# Set selector to listen for write events, we're done reading.
self._set_selector_events_mask('w')Après avoir enregistré le contenu du message dans la variable + data +, + process_request () + le supprime du tampon de réception. Ensuite, si le type de contenu est JSON, il le décode et le désérialise. Si ce n’est pas le cas, pour cet exemple d’application, il suppose qu’il s’agit d’une demande binaire et imprime simplement le type de contenu.
La dernière chose que + process_request () + fait est de modifier le sélecteur pour surveiller uniquement les événements d’écriture. Dans le script principal du serveur, + app-server.py +, le socket est initialement configuré pour surveiller uniquement les événements en lecture. Maintenant que la demande a été entièrement traitée, nous ne souhaitons plus la lire.
Une réponse peut maintenant être créée et écrite dans le socket. Lorsque le socket est accessible en écriture, + create_response () + est appelé à partir de + write () +:
def create_response(self):
if self.jsonheader['content-type'] == 'text/json':
response = self._create_response_json_content()
else:
# Binary or unknown content-type
response = self._create_response_binary_content()
message = self._create_message(**response)
self.response_created = True
self._send_buffer += messageUne réponse est créée en appelant d’autres méthodes, selon le type de contenu. Dans cet exemple d’application, une simple recherche par dictionnaire est effectuée pour les requêtes JSON lorsque `+ action == 'search' + '. Vous pouvez définir d’autres méthodes pour vos propres applications qui seront appelées ici.
Après avoir créé le message de réponse, la variable d’état + self.response_created + est définie de sorte que + write () + n’appelle plus + create_response () +. Enfin, la réponse est ajoutée au tampon d’envoi. Ceci est vu et envoyé via + _write () +.
Un élément délicat à comprendre était de savoir comment fermer la connexion après l’écriture de la réponse. Je mets l’appel à + close () + dans la méthode + _write () +:
def _write(self):
if self._send_buffer:
print('sending', repr(self._send_buffer), 'to', self.addr)
try:
# Should be ready to write
sent = self.sock.send(self._send_buffer)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
self._send_buffer = self._send_buffer[sent:]
# Close when the buffer is drained. The response has been sent.
if sent and not self._send_buffer:
self.close()Bien qu’il soit quelque peu «caché», je pense que c’est un compromis acceptable étant donné que la classe + Message + ne gère qu’un seul message par connexion. Une fois la réponse écrite, il ne reste plus rien à faire au serveur. Il a terminé son travail.
Script principal du client
Dans le script principal du client + app-client.py +, les arguments sont lus à partir de la ligne de commande et utilisés pour créer des demandes et démarrer des connexions au serveur:
$ ./app-client.py
usage: ./app-client.py <host> <port> <action> <value>Voici un exemple:
$ ./app-client.py 127.0.0.1 65432 search needleAprès avoir créé un dictionnaire représentant la demande à partir des arguments de la ligne de commande, l’hôte, le port et le dictionnaire de demande sont passés à + start_connection () +:
def start_connection(host, port, request):
addr = (host, port)
print('starting connection to', addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
message = libclient.Message(sel, sock, addr, request)
sel.register(sock, events, data=message)Un socket est créé pour la connexion au serveur ainsi qu’un objet + Message + à l’aide du dictionnaire + request +.
Comme le serveur, l’objet + Message + est associé au socket dans l’appel à + sel.register () +. Cependant, pour le client, le socket est initialement défini pour être surveillé à la fois pour les événements de lecture et d’écriture. Une fois la demande écrite, nous la modifierons pour écouter uniquement les événements en lecture.
Cette approche nous donne le même avantage que le serveur: ne pas gaspiller les cycles CPU. Une fois la demande envoyée, nous ne souhaitons plus écrire d’événements, il n’y a donc aucune raison de les réveiller et de les traiter.
Classe de message client
Dans le lien de la section: # message-entry-point [Message Entry Point], nous avons examiné comment l’objet message a été appelé en action lorsque les événements de socket étaient prêts via + process_events () +. Voyons maintenant ce qui se passe une fois que les données ont été lues et écrites sur le socket et qu’un message est prêt à être traité par le client.
La classe de message du client est dans + libclient.py +. Vous pouvez trouver le source code sur GitHub.
Les méthodes apparaissent dans la classe dans l’ordre dans lequel le traitement a lieu pour un message.
La première tâche du client consiste à mettre la demande en file d’attente:
def queue_request(self):
content = self.request['content']
content_type = self.request['type']
content_encoding = self.request['encoding']
if content_type == 'text/json':
req = {
'content_bytes': self._json_encode(content, content_encoding),
'content_type': content_type,
'content_encoding': content_encoding
}
else:
req = {
'content_bytes': content,
'content_type': content_type,
'content_encoding': content_encoding
}
message = self._create_message(**req)
self._send_buffer += message
self._request_queued = TrueLes dictionnaires utilisés pour créer la demande, selon ce qui a été transmis sur la ligne de commande, se trouvent dans le script principal du client, + app-client.py +. Le dictionnaire de requêtes est passé en argument à la classe lorsqu’un objet + Message + est créé.
Le message de demande est créé et ajouté au tampon d’envoi, qui est ensuite vu et envoyé via + _write () +. La variable d’état + self._request_queued + est définie pour que + queue_request () + ne soit plus appelé.
Une fois la demande envoyée, le client attend une réponse du serveur.
Les méthodes de lecture et de traitement d’un message dans le client sont les mêmes que sur le serveur. Lorsque les données de réponse sont lues à partir du socket, les méthodes d’en-tête + process + sont appelées: + process_protoheader () + et + process_jsonheader () +.
La différence réside dans la dénomination des méthodes finales + processus + et dans le fait qu’elles traitent une réponse, et non en créant une: + process_response () +, + _process_response_json_content () + 'et + _process_response_binary_content ( ) + `.
Le dernier, mais certainement pas le moindre, est le dernier appel à + process_response () +:
def process_response(self):
# ...
# Close when response has been processed
self.close()Récapitulation de la classe de message
Je conclurai la discussion en classe + Message + en mentionnant quelques points importants à noter avec quelques-unes des méthodes de support.
Toutes les exceptions levées par la classe sont interceptées par le script principal dans sa clause `+ except + ':
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()Notez la dernière ligne: + message.close () +.
C’est une ligne vraiment importante, pour plus d’une raison! Non seulement il s’assure que le socket est fermé, mais + message.close () + supprime également le socket d’être surveillé par + select () +. Cela simplifie considérablement le code de la classe et réduit la complexité. S’il y a une exception ou si nous en soulevons explicitement une nous-mêmes, nous savons que + close () + se chargera du nettoyage.
Les méthodes + Message._read () + et + Message._write () + contiennent également quelque chose d’intéressant:
def _read(self):
try:
# Should be ready to read
data = self.sock.recv(4096)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
if data:
self._recv_buffer += data
else:
raise RuntimeError('Peer closed.')Notez la ligne + sauf +: + sauf BlockingIOError: +.
+ _write () + en a un aussi. Ces lignes sont importantes car elles détectent une erreur temporaire et la sautent en utilisant + pass +. L’erreur temporaire est lorsque le socket lierait: # blocking-calls [block], par exemple s’il attend sur le réseau ou à l’autre extrémité de la connexion (son homologue).
En interceptant et en sautant l’exception avec + pass +, + select () + finira par nous appeler à nouveau, et nous aurons une autre chance de lire ou d’écrire les données.
Exécution du client et du serveur d’application
Après tout ce travail acharné, amusons-nous et exécutons quelques recherches!
Dans ces exemples, je vais exécuter le serveur pour qu’il écoute sur toutes les interfaces en passant une chaîne vide pour l’argument + host +. Cela me permettra d’exécuter le client et de me connecter à partir d’une machine virtuelle qui se trouve sur un autre réseau. Il émule une machine PowerPC big-endian.
Commençons par démarrer le serveur:
$ ./app-server.py '' 65432
listening on ('', 65432)Exécutons maintenant le client et entrez une recherche. Voyons si nous pouvons le trouver:
$ ./app-client.py 10.0.1.1 65432 search morpheus
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432)
received response {'result': 'Follow the white rabbit. ????'} from ('10.0.1.1', 65432)
got result: Follow the white rabbit. ????
closing connection to ('10.0.1.1', 65432)Mon terminal exécute un shell qui utilise un encodage de texte Unicode (UTF-8), donc la sortie ci-dessus s’imprime bien avec les emojis.
Voyons si nous pouvons trouver les chiots:
$ ./app-client.py 10.0.1.1 65432 search ????
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
received response {'result': '???? Playing ball! ????'} from ('10.0.1.1', 65432)
got result: ???? Playing ball! ????
closing connection to ('10.0.1.1', 65432)Notez la chaîne d’octets envoyée sur le réseau pour la demande dans la ligne + envoi +. Il est plus facile de voir si vous recherchez les octets imprimés en hexadécimal qui représentent l’emoji du chiot: + \ xf0 \ x9f \ x90 \ xb6 +. J’ai pu entrer l’emoji pour la recherche car mon terminal utilise Unicode avec le codage UTF-8.
Cela montre que nous envoyons des octets bruts sur le réseau et qu’ils doivent être décodés par le récepteur pour être interprétés correctement. C’est pourquoi nous avons fait tout notre possible pour créer un en-tête contenant le type de contenu et l’encodage.
Voici la sortie du serveur des deux connexions client ci-dessus:
accepted connection from ('10.0.2.2', 55340)
received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
closing connection to ('10.0.2.2', 55340)
accepted connection from ('10.0.2.2', 55338)
received request {'action': 'search', 'value': '????'} from ('10.0.2.2', 55338)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
closing connection to ('10.0.2.2', 55338)Regardez la ligne + envoi + pour voir les octets qui ont été écrits dans le socket du client. Il s’agit du message de réponse du serveur.
Vous pouvez également tester l’envoi de requêtes binaires au serveur si l’argument + action + est autre chose que + recherche +:
$ ./app-client.py 10.0.1.1 65432 binary ????
starting connection to ('10.0.1.1', 65432)
sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
closing connection to ('10.0.1.1', 65432)Étant donné que le «+ type de contenu » de la demande n'est pas « text/json », le serveur la traite comme un type binaire personnalisé et n'effectue pas le décodage JSON. Il imprime simplement le ` content-type +` et retourne les 10 premiers octets au client:
$ ./app-server.py '' 65432
listening on ('', 65432)
accepted connection from ('10.0.2.2', 55320)
received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
closing connection to ('10.0.2.2', 55320)Dépannage
Inévitablement, quelque chose ne fonctionnera pas et vous vous demanderez quoi faire. Ne vous inquiétez pas, cela nous arrive à tous. J’espère qu’avec l’aide de ce didacticiel, de votre débogueur et de votre moteur de recherche préféré, vous pourrez recommencer avec la partie code source.
Sinon, votre premier arrêt devrait être la documentation socket de Python. Assurez-vous de lire toute la documentation de chaque fonction ou méthode que vous appelez. Lisez également le lien: #reference [Reference] pour des idées. En particulier, consultez la section lien: #erreurs [Erreurs].
Parfois, ce n’est pas tout à propos du code source. Le code source est peut-être correct, et ce n’est que l’autre hôte, le client ou le serveur. Ou ce pourrait être le réseau, par exemple, un routeur, un pare-feu ou un autre périphérique réseau qui joue l’homme au milieu.
Pour ces types de problèmes, des outils supplémentaires sont essentiels. Vous trouverez ci-dessous quelques outils et utilitaires qui pourraient aider ou au moins fournir des indices.
ping
+ ping + vérifiera si un hôte est vivant et connecté au réseau en envoyant une demande d’écho ICMP. Il communique directement avec la pile de protocoles TCP/IP du système d’exploitation, il fonctionne donc indépendamment de toute application exécutée sur l’hôte.
Voici un exemple d’exécution de ping sur macOS:
$ ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 msNotez les statistiques à la fin de la sortie. Cela peut être utile lorsque vous essayez de découvrir des problèmes de connectivité intermittents. Par exemple, y a-t-il une perte de paquets? Quelle est la latence (voir les temps aller-retour)?
S’il y a un pare-feu entre vous et l’autre hôte, une demande d’écho de ping peut ne pas être autorisée. Certains administrateurs de pare-feu mettent en œuvre des stratégies qui appliquent cela. L’idée étant qu’ils ne veulent pas que leurs hôtes soient découvrables. Si tel est le cas et que des règles de pare-feu ont été ajoutées pour permettre aux hôtes de communiquer, assurez-vous que les règles permettent également à ICMP de passer entre eux.
ICMP est le protocole utilisé par + ping +, mais c’est également le protocole TCP et d’autres protocoles de niveau inférieur utilisés pour communiquer les messages d’erreur. Si vous rencontrez un comportement étrange ou des connexions lentes, cela peut être la raison.
Les messages ICMP sont identifiés par type et code. Pour vous donner une idée des informations importantes qu’ils portent, en voici quelques-uns:
| ICMP Type | ICMP Code | Description |
|---|---|---|
8 |
0 |
Echo request |
0 |
0 |
Echo reply |
3 |
0 |
Destination network unreachable |
3 |
1 |
Destination host unreachable |
3 |
2 |
Destination protocol unreachable |
3 |
3 |
Destination port unreachable |
3 |
4 |
Fragmentation required, and DF flag set |
11 |
0 |
TTL expired in transit |
Voir l’article Path MTU Discovery pour plus d’informations sur la fragmentation et les messages ICMP. Ceci est un exemple de quelque chose qui peut provoquer un comportement étrange que j’ai mentionné précédemment.
netstat
Dans le lien de la section: # visualisation-socket-state [Affichage de l’état du socket], nous avons examiné comment + netstat + peut être utilisé pour afficher des informations sur les sockets et leur état actuel. Cet utilitaire est disponible sur macOS, Linux et Windows.
Je n’ai pas mentionné les colonnes "+ Recv-Q " et " Send-Q +" dans l’exemple de sortie. Ces colonnes vous indiqueront le nombre d’octets contenus dans les tampons réseau mis en file d’attente pour la transmission ou la réception, mais pour une raison quelconque, ils n’ont pas été lus ou écrits par l’application distante ou locale.
En d’autres termes, les octets attendent dans les tampons réseau des files d’attente du système d’exploitation. Une des raisons pourrait être que l’application est liée au processeur ou est autrement incapable d’appeler + socket.recv () + ou + socket.send () + et de traiter les octets. Ou il pourrait y avoir des problèmes de réseau affectant les communications comme la congestion ou une défaillance du matériel ou du câblage réseau.
Pour démontrer cela et voir combien de données je pouvais envoyer avant de voir une erreur, j’ai écrit un client de test qui se connecte à un serveur de test et appelle à plusieurs reprises + socket.send () +. Le serveur de test n’appelle jamais + socket.recv () +. Il accepte simplement la connexion. Cela provoque le remplissage des tampons réseau sur le serveur, ce qui génère éventuellement une erreur sur le client.
Tout d’abord, j’ai démarré le serveur:
$ ./app-server-test.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)Ensuite, j’ai exécuté le client. Voyons quelle est l’erreur:
$ ./app-client-test.py 127.0.0.1 65432 binary test
error: socket.send() blocking io exception for ('127.0.0.1', 65432):
BlockingIOError(35, 'Resource temporarily unavailable')Voici la sortie + netstat + alors que le client et le serveur étaient toujours en cours d’exécution, le client imprimant le message d’erreur ci-dessus plusieurs fois:
$ netstat -an | grep 65432
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
tcp4 0 0 127.0.0.1.65432 *.* LISTENLa première entrée est le serveur (+ Local Address + a le port 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHEDRemarquez le + Recv-Q +: + 408300 +.
La deuxième entrée est le client (+ Adresse étrangère + a le port 65432):
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHEDRemarquez le + Send-Q +: + 269868 +.
Le client essayait certainement d’écrire des octets, mais le serveur ne les lisait pas. Cela a entraîné le remplissage de la file d’attente du tampon réseau du serveur côté réception et la file d’attente du tampon réseau du client côté envoi.
les fenêtres
Si vous travaillez avec Windows, il existe une suite d’utilitaires que vous devez absolument vérifier si vous ne l’avez pas déjà fait: Windows Sysinternals.
L’un d’eux est + TCPView.exe +. TCPView est un "+ netstat " graphique pour Windows. En plus des adresses, des numéros de port et de l'état du socket, il vous montrera les totaux cumulés pour le nombre de paquets et d'octets, envoyés et reçus. Comme l'utilitaire Unix ` lsof +`, vous obtenez également le nom et l’ID du processus. Vérifiez les menus pour les autres options d’affichage.
Wireshark
Parfois, vous devez voir ce qui se passe sur le fil. Oubliez ce que dit le journal des applications ou quelle est la valeur renvoyée par un appel de bibliothèque. Vous voulez voir ce qui est réellement envoyé ou reçu sur le réseau. Tout comme les débogueurs, quand vous avez besoin de le voir, il n’y a pas de substitut.
Wireshark est un analyseur de protocole réseau et une application de capture de trafic qui s’exécute sur macOS, Linux et Windows, entre autres. Il existe une version de l’interface graphique nommée + WireShark +, ainsi qu’une version de terminal, basée sur du texte, nommée + Tshark +.
L’exécution d’une capture de trafic est un excellent moyen de voir comment une application se comporte sur le réseau et de collecter des preuves sur ce qu’elle envoie et reçoit, et à quelle fréquence et combien. Vous pourrez également voir quand un client ou un serveur ferme ou abandonne une connexion ou cesse de répondre. Ces informations peuvent être extrêmement utiles lors du dépannage.
Il existe de nombreux bons didacticiels et autres ressources sur le Web qui vous guideront à travers les bases de l’utilisation de Wireshark et TShark.
Voici un exemple de capture de trafic à l’aide de Wireshark sur l’interface de bouclage:
Voici le même exemple illustré ci-dessus en utilisant + tshark +:
$ tshark -i lo0 'tcp port 65432'
Capturing on 'Loopback'
1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1
2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1
3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635
6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635
8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635
9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635
^C13 packets capturedRéférence
Cette section sert de référence générale avec des informations supplémentaires et des liens vers des ressources externes.
Documentation Python
-
Https://docs.python.org/3/library/socket.html[socket module de Python]
-
Https://docs.python.org/3/howto/sockets.html#socket-howto[Socket Programming HOWTO Python]
les erreurs
Ce qui suit provient de la documentation du module + socket + de Python:
_
«Toutes les erreurs soulèvent des exceptions. Les exceptions normales pour les types d’arguments non valides et les conditions de mémoire insuffisante peuvent être levées; à partir de Python 3.3, les erreurs liées à la sémantique de socket ou d’adresse déclenchent + OSError + ou l’une de ses sous-classes. " (Source)
_
Voici quelques erreurs courantes que vous rencontrerez probablement lorsque vous travaillez avec des sockets:
| Exception | errno Constant |
Description |
|---|---|---|
BlockingIOError |
EWOULDBLOCK |
Resource temporarily unavailable. For example, in non-blocking mode, when calling |
OSError |
EADDRINUSE |
Address already in use. Make sure there’s not another process running that’s using the same port number and your server is setting the socket option |
ConnectionResetError |
ECONNRESET |
Connection reset by peer. The remote process crashed or did not close its socket properly (unclean shutdown). Or there’s a firewall or other device in the network path that’s missing rules or misbehaving. |
TimeoutError |
ETIMEDOUT |
Operation timed out. No response from peer. |
ConnectionRefusedError |
ECONNREFUSED |
Connection refused. No application listening on specified port. |
Familles d’adresses de socket
+ socket.AF_INET + et + socket.AF_INET6 + représentent les familles d’adresses et de protocoles utilisées pour le premier argument de + socket.socket () +. Les API qui utilisent une adresse s’attendent à ce qu’elle soit dans un certain format, selon que le socket a été créé avec + socket.AF_INET + ou + socket.AF_INET6 +.
| Address Family | Protocol | Address Tuple | Description |
|---|---|---|---|
|
IPv4 |
|
|
|
IPv6 |
|
|
Notez l’extrait ci-dessous de la documentation du module socket de Python concernant la valeur + host + du tuple d’adresse:
_ «Pour les adresses IPv4, deux formes spéciales sont acceptées au lieu d’une adresse d’hôte: la chaîne vide représente« + INADDR_ANY + »et la chaîne« + »<broadcast>« + »représente« + INADDR_BROADCAST + ». Ce comportement n’est pas compatible avec IPv6, par conséquent, vous voudrez peut-être les éviter si vous avez l’intention de prendre en charge IPv6 avec vos programmes Python. » (Source) _
Voir la Socket familles documentation de Python pour plus d’informations.
J’ai utilisé des sockets IPv4 dans ce didacticiel, mais si votre réseau le prend en charge, essayez de tester et d’utiliser IPv6 si possible. Une façon de gérer cela facilement est d’utiliser la fonction https://docs.python.org/3/library/socket.html#socket.getaddrinfo [socket.getaddrinfo ()]. Il traduit les arguments + host + et + port + en une séquence de 5 tuples qui contient tous les arguments nécessaires pour créer une socket connectée à ce service. + socket.getaddrinfo () + comprendra et interprètera les adresses IPv6 et les noms d’hôte transmis qui se résolvent en adresses IPv6, en plus d’IPv4.
L’exemple suivant renvoie les informations d’adresse d’une connexion TCP vers + example.org + sur le port + 80 +:
>>>
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP)
[(<AddressFamily.AF_INET6: 10>, <SocketType.SOCK_STREAM: 1>,
6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)),
(<AddressFamily.AF_INET: 2>, <SocketType.SOCK_STREAM: 1>,
6, '', ('93.184.216.34', 80))]Les résultats peuvent différer sur votre système si IPv6 n’est pas activé. Les valeurs renvoyées ci-dessus peuvent être utilisées en les passant à + socket.socket () + et + socket.connect () +. Il existe un exemple de client et de serveur dans la section Example de la documentation du module socket de Python.
Utilisation des noms d’hôtes
Pour le contexte, cette section s’applique principalement à l’utilisation de noms d’hôtes avec + bind () + et + connect () +, ou + connect_ex () +, lorsque vous avez l’intention d’utiliser l’interface de bouclage, "localhost". Cependant, il s’applique chaque fois que vous utilisez un nom d’hôte et que vous vous attendez à ce qu’il se résout à une certaine adresse et ait une signification particulière pour votre application qui affecte son comportement ou ses hypothèses. Cela contraste avec le scénario typique d’un client utilisant un nom d’hôte pour se connecter à un serveur résolu par DNS, comme www.example.com.
Ce qui suit provient de la documentation du module + socket + de Python:
_ «Si vous utilisez un nom d’hôte dans la partie hôte de l’adresse de socket IPv4/v6, le programme peut afficher un comportement non déterministe, car Python utilise la première adresse renvoyée par la résolution DNS. L’adresse du socket sera résolue différemment en une adresse IPv4/v6 réelle, en fonction des résultats de la résolution DNS et/ou de la configuration de l’hôte. Pour un comportement déterministe, utilisez une adresse numérique dans la partie hôte. » (Source) _
- La convention standard pour le nom «https://en.wikipedia.org/wiki/Localhost[localhost]» est pour lui de résoudre à «+ 127.0.0.1 » ou «
-
1 +», l’interface de bouclage. Ce sera plus que probablement le cas pour vous sur votre système, mais peut-être pas. Cela dépend de la façon dont votre système est configuré pour la résolution de noms. Comme pour tout ce qui concerne l’informatique, il y a toujours des exceptions et il n’y a aucune garantie que l’utilisation du nom «localhost» se connecte à l’interface de bouclage.
Par exemple, sous Linux, voir + man nsswitch.conf + ', le fichier de configuration de Name Service Switch. Un autre endroit pour vérifier sur macOS et Linux est le fichier `+/etc/hosts +. Sous Windows, voir + C: \ Windows \ System32 \ drivers \ etc \ hosts +. Le fichier + hosts + contient une table statique de noms pour adresser les mappages dans un format texte simple. DNS est une autre pièce du puzzle.
Chose intéressante, au moment de la rédaction de ce document (juin 2018), il existe un projet RFC https://tools.ietf.org/html/draft-ietf-dnsop-let-localhost-be-localhost-02-02Let 'localhost' be localhost ] qui traite des conventions, des hypothèses et de la sécurité autour de l’utilisation du nom "localhost".
Ce qui est important à comprendre, c’est que lorsque vous utilisez des noms d’hôtes dans votre application, les adresses renvoyées peuvent littéralement être n’importe quoi. Ne faites pas d’hypothèses concernant un nom si vous avez une application sensible à la sécurité. Selon votre application et votre environnement, cela peut ou non vous préoccuper.
*Remarque:* Les précautions de sécurité et les meilleures pratiques s'appliquent toujours, même si votre application n'est pas «sensible à la sécurité». Si votre application accède au réseau, il doit être sécurisé et maintenu. Cela signifie, au minimum:
-
Les mises à jour du logiciel système et les correctifs de sécurité sont appliqués régulièrement, y compris Python. Utilisez-vous des bibliothèques tierces? Si c’est le cas, assurez-vous que ceux-ci sont également vérifiés et mis à jour.
-
Si possible, utilisez un pare-feu dédié ou basé sur l’hôte pour limiter les connexions aux systèmes approuvés uniquement.
-
Quels serveurs DNS sont configurés? Faites-vous confiance à eux et à leurs administrateurs?
-
Assurez-vous que les données de demande sont nettoyées et validées autant que possible avant d’appeler un autre code qui les traite. Utilisez des tests (fuzz) pour cela et exécutez-les régulièrement.
Que vous utilisiez ou non des noms d’hôte, si votre application doit prendre en charge des connexions sécurisées (chiffrement et authentification), vous voudrez probablement envisager d’utiliser TLS . Il s’agit de son propre sujet distinct et au-delà de la portée de ce didacticiel. Consultez la ssl module documentation de Python pour commencer. Il s’agit du même protocole que votre navigateur Web utilise pour se connecter en toute sécurité aux sites Web.
Avec les interfaces, les adresses IP et la résolution de noms à considérer, il existe de nombreuses variables. Que devrais tu faire? Voici quelques recommandations que vous pouvez utiliser si vous ne disposez pas d’un processus d’examen des applications réseau:
| Application | Usage | Recommendation |
|---|---|---|
Server |
loopback interface |
Use an IP address, for example, |
Server |
ethernet interface |
Use an IP address, for example, |
Client |
loopback interface |
Use an IP address, for example, |
Client |
ethernet interface |
Use an IP address for consistency and non-reliance on name resolution. For the typical case, use a hostname. See the security note above. |
Pour les clients ou les serveurs, si vous devez authentifier l’hôte auquel vous vous connectez, envisagez d’utiliser TLS.
Bloquer les appels
Une fonction ou une méthode de socket qui suspend temporairement votre application est un appel de blocage. Par exemple, + accepter () +, + connecter () +, + envoyer () + et + recv () + "bloquer". Ils ne reviennent pas immédiatement. Les appels bloquants doivent attendre les appels système (E/S) pour se terminer avant de pouvoir renvoyer une valeur. Donc, vous, l’appelant, êtes bloqué jusqu’à ce qu’il ait terminé ou qu’un délai d’attente ou une autre erreur se produise.
Les appels de socket bloquants peuvent être définis en mode non bloquant afin qu’ils reviennent immédiatement. Si vous procédez ainsi, vous devrez au moins refactoriser ou reconcevoir votre application pour gérer l’opération de socket lorsqu’elle sera prête.
Étant donné que l’appel revient immédiatement, les données peuvent ne pas être prêtes. L’appelé attend sur le réseau et n’a pas eu le temps de terminer son travail. Si tel est le cas, l’état actuel est la valeur + errno + valeur + socket.EWOULDBLOCK + `. Le mode non bloquant est pris en charge avec https://docs.python.org/3/library/socket.html#socket.socket.setblocking [setblocking ()].
Par défaut, les sockets sont toujours créées en mode blocage. Voir Notes on socket timeouts pour une description des trois modes.
Fermeture des connexions
Une chose intéressante à noter avec TCP est qu’il est tout à fait légal que le client ou le serveur ferme son côté de la connexion pendant que l’autre côté reste ouvert. C’est ce qu’on appelle une connexion «semi-ouverte». C’est la décision de l’application si cela est souhaitable ou non. En général, ce n’est pas le cas. Dans cet état, le côté qui a fermé la fin de la connexion ne peut plus envoyer de données. Ils ne peuvent que le recevoir.
Je ne préconise pas que vous adoptiez cette approche, mais à titre d’exemple, HTTP utilise un en-tête nommé "Connexion" qui est utilisé pour normaliser la façon dont les applications doivent fermer ou conserver les connexions ouvertes. Pour plus de détails, voir section 6.3 dans RFC 7230, Hypertext Transfer Protocol (HTTP/1.1): Syntaxe et routage des messages.
Lorsque vous concevez et écrivez votre application et son protocole de couche application, c’est une bonne idée d’aller de l’avant et de déterminer comment vous vous attendez à ce que les connexions soient fermées. Parfois, cela est évident et simple, ou c’est quelque chose qui peut nécessiter un prototypage et des tests initiaux. Cela dépend de l’application et de la façon dont la boucle de message est traitée avec ses données attendues. Assurez-vous simplement que les prises sont toujours fermées en temps opportun après avoir terminé leur travail.
Octet Endianness
Consultez l’article Wikipedia sur l’endianness pour plus de détails sur la façon dont les différents processeurs stockent les commandes d’octets en mémoire. Lors de l’interprétation des octets individuels, ce n’est pas un problème. Cependant, lors de la gestion de plusieurs octets qui sont lus et traités comme une seule valeur, par exemple un entier de 4 octets, l’ordre des octets doit être inversé si vous communiquez avec une machine qui utilise une endianité différente.
L’ordre des octets est également important pour les chaînes de texte qui sont représentées sous forme de séquences multi-octets, comme Unicode. À moins que vous n’utilisiez toujours «vrai», ASCII strict et que vous contrôliez les implémentations client et serveur, vous feriez probablement mieux d’utiliser Unicode avec un encodage comme UTF-8. ou qui prend en charge un byte order mark (BOM).
Il est important de définir explicitement le codage utilisé dans votre protocole de couche application. Vous pouvez le faire en exigeant que tout le texte soit en UTF-8 ou en utilisant un en-tête «content-encoding» qui spécifie l’encodage. Cela empêche votre application d’avoir à détecter l’encodage, ce que vous devriez éviter si possible.
Cela devient problématique lorsqu’il y a des données impliquées qui sont stockées dans des fichiers ou une base de données et qu’il n’y a pas de métadonnées disponibles qui spécifient leur encodage. Lorsque les données sont transférées vers un autre point de terminaison, il devra essayer de détecter le codage. Pour une discussion, voir Article Unicode de Wikipédia qui fait référence à RFC 3629: UTF-8, un format de transformation ISO 10646:
_ «Cependant, la RFC 3629, la norme UTF-8, recommande que les marques d’ordre des octets soient interdites dans les protocoles utilisant UTF-8, mais examine les cas où cela peut ne pas être possible. De plus, la grande restriction sur les modèles possibles dans UTF-8 (par exemple, il ne peut y avoir d’octets isolés avec le bit élevé défini) signifie qu’il devrait être possible de distinguer UTF-8 des autres encodages de caractères sans compter sur la nomenclature. » (Source) _
La leçon à retenir est de toujours stocker l’encodage utilisé pour les données gérées par votre application si elles peuvent varier. En d’autres termes, essayez de stocker en quelque sorte l’encodage en tant que métadonnées si ce n’est pas toujours UTF-8 ou un autre encodage avec une nomenclature. Ensuite, vous pouvez envoyer cet encodage dans un en-tête avec les données pour dire au récepteur de quoi il s’agit.
L’ordre des octets utilisé dans TCP/IP est big-endian et est appelé ordre réseau. L’ordre du réseau est utilisé pour représenter les entiers dans les couches inférieures de la pile de protocoles, comme les adresses IP et les numéros de port. Le module socket de Python comprend des fonctions qui convertissent les entiers vers et depuis le réseau et l’ordre des octets de l’hôte:
| Function | Description |
|---|---|
|
Convert 32-bit positive integers from network to host byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 4-byte swap operation. |
|
Convert 16-bit positive integers from network to host byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 2-byte swap operation. |
|
Convert 32-bit positive integers from host to network byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 4-byte swap operation. |
|
Convert 16-bit positive integers from host to network byte order. On machines where the host byte order is the same as network byte order, this is a no-op; otherwise, it performs a 2-byte swap operation. |
Vous pouvez également utiliser le module struct pour emballer et décompresser des données binaires à l’aide de chaînes de format:
import struct
network_byteorder_int = struct.pack('>H', 256)
python_int = struct.unpack('>H', network_byteorder_int)[0]Conclusion
Nous avons couvert beaucoup de terrain dans ce tutoriel. La mise en réseau et les sockets sont des sujets importants. Si vous êtes nouveau dans la mise en réseau ou les sockets, ne vous découragez pas avec tous les termes et acronymes.
Il y a beaucoup de pièces à se familiariser pour comprendre comment tout fonctionne ensemble. Cependant, tout comme Python, cela commencera à avoir plus de sens à mesure que vous connaîtrez les pièces individuelles et passerez plus de temps avec elles.
Nous avons examiné l’API socket de bas niveau dans le module Python + socket + et avons vu comment elle peut être utilisée pour créer des applications client-serveur. Nous avons également créé notre propre classe personnalisée et l’avons utilisée comme protocole de couche application pour échanger des messages et des données entre les points de terminaison. Vous pouvez utiliser cette classe et en tirer parti pour apprendre et vous aider à créer vos propres applications socket plus facilement et plus rapidement.
Vous pouvez trouver le source code sur GitHub.
Félicitations pour avoir atteint la fin! Vous êtes maintenant bien parti pour utiliser des sockets dans vos propres applications.
J’espère que ce tutoriel vous a donné les informations, les exemples et l’inspiration nécessaires pour vous lancer dans votre développement de sockets.