Itertools en Python 3, par exemple
Il a été appelé un“gem” et“pretty much the coolest thing ever,” et si vous n'en avez pas entendu parler, vous passez à côté de l'un des plus grands coins de la bibliothèque standard Python 3:itertools.
Il existe une poignée d'excellentes ressources pour apprendre quelles fonctions sont disponibles dans le moduleitertools. Lesdocseux-mêmes sont un excellent point de départ. Il en va de même pourthis post.
Le problème avecitertools, cependant, est qu'il ne suffit pas de connaître les définitions des fonctions qu'il contient. Le vrai pouvoir réside dans la composition de ces fonctions pour créer un code rapide, efficace en mémoire et beau.
Cet article adopte une approche différente. Plutôt que de vous présenteritertools une fonction à la fois, vous construirez des exemples pratiques conçus pour vous encourager à «penser de manière itérative». En général, les exemples commenceront simplement et gagneront progressivement en complexité.
Un mot d'avertissement: cet article est long et destiné au programmeur Python intermédiaire à avancé. Avant de plonger, vous devez être sûr d'utiliser des itérateurs et des générateurs en Python 3, une affectation multiple et un déballage de tuple. Si ce n'est pas le cas, ou si vous avez besoin de mettre à jour vos connaissances, pensez à vérifier ce qui suit avant de continuer:
Free Bonus:Click here to get our itertools cheat sheet qui résume les techniques illustrées dans ce didacticiel.
Tout est prêt? Commençons comme tout bon voyage devrait-avec une question.
Qu'est-ce queItertools et pourquoi devriez-vous l'utiliser?
Selon lesitertools docs, il s'agit d'un «module [qui] implémente un certain nombre de blocs de construction d'itérateurs inspirés des constructions d'APL, Haskell et SML… Ensemble, ils forment une 'algèbre d'itérateur' permettant de construire des des outils succinctement et efficacement en pur Python. »
En gros, cela signifie que les fonctions deitertools «opèrent» sur des itérateurs pour produire des itérateurs plus complexes. Considérez, par exemple, lebuilt-in zip() function, qui prend n'importe quel nombre d'itérables comme arguments et renvoie un itérateur sur les tuples de leurs éléments correspondants:
>>>
>>> list(zip([1, 2, 3], ['a', 'b', 'c']))
[(1, 'a'), (2, 'b'), (3, 'c')]Comment, exactement, fonctionnezip()?
[1, 2, 3] et['a', 'b', 'c'], comme toutes les listes, sont itérables, ce qui signifie qu'ils peuvent renvoyer leurs éléments un à la fois. Techniquement, tout objet Python qui implémente les méthodes.__iter__() ou.__getitem__() est itérable. (Voir lesPython 3 docs glossary pour une explication plus détaillée.)
Leiter() built-in function, lorsqu'il est appelé sur un itérable, retourne uniterator object pour cet itérable:
>>>
>>> iter([1, 2, 3, 4])
Sous le capot, la fonctionzip() fonctionne, en substance, en appelantiter() sur chacun de ses arguments, puis en avançant chaque itérateur retourné pariter() avecnext() et en agrégeant les résultats en tuples. L'itérateur renvoyé parzip() itère sur ces tuples.
The map() built-in function est un autre «opérateur itérateur» qui, dans sa forme la plus simple, applique une fonction à un seul paramètre à chaque élément d'un élément itérable à la fois:
>>>
>>> list(map(len, ['abc', 'de', 'fghi']))
[3, 2, 4]La fonctionmap() fonctionne en appelantiter() sur son deuxième argument, en faisant avancer cet itérateur avecnext() jusqu'à ce que l'itérateur soit épuisé, et en appliquant la fonction passée à son premier argument à la valeur renvoyée parnext() à chaque étape. Dans l'exemple ci-dessus,len() est appelé sur chaque élément de['abc', 'de', 'fghi'] pour renvoyer un itérateur sur les longueurs de chaque chaîne de la liste.
Depuisiterators are iterable, vous pouvez composerzip() etmap() pour produire un itérateur sur des combinaisons d'éléments dans plus d'un itérable. Par exemple, les sommes suivantes résument les éléments correspondants de deux listes:
>>>
>>> list(map(sum, zip([1, 2, 3], [4, 5, 6])))
[5, 7, 9]C'est ce que l'on entend par les fonctions enitertools formant une «algèbre d'itérateur». itertools est mieux considéré comme un ensemble de blocs de construction qui peuvent être combinés pour former des «pipelines de données» spécialisés comme celui de l'exemple ci-dessus.
Historical Note: En Python 2, les fonctions intégrées
zip()etmap()ne renvoient pas d'itérateur, mais plutôt une liste. Pour renvoyer un itérateur, les fonctionsizip()etimap()deitertoolsdoivent être utilisées. Dans Python 3,izip()etimap()ont étéremoved fromitertoolset ont remplacé les intégrészip()etmap(). Donc, d'une certaine manière, si vous avez déjà utilisézip()oumap()dans Python 3, vous avez déjà utiliséitertools!
Il y a deux raisons principales pour lesquelles une telle «algèbre d'itération» est utile: une meilleure efficacité de la mémoire (vialazy evaluation) et un temps d'exécution plus rapide. Pour voir cela, considérez le problème suivant:
Étant donné une liste de valeurs
inputset un entier positifn, écrivez une fonction qui diviseinputsen groupes de longueurn. Par souci de simplicité, supposons que la longueur de la liste d'entrée soit divisible parn. Par exemple, siinputs = [1, 2, 3, 4, 5, 6]etn = 2, votre fonction doit renvoyer[(1, 2), (3, 4), (5, 6)].
En adoptant une approche naïve, vous pourriez écrire quelque chose comme ceci:
def naive_grouper(inputs, n):
num_groups = len(inputs) // n
return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)]Lorsque vous le testez, vous voyez qu'il fonctionne comme prévu:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> naive_grouper(nums, 2)
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]Que se passe-t-il lorsque vous essayez de lui transmettre une liste avec, disons, 100 millions d'éléments? Vous aurez besoin de beaucoup de mémoire disponible! Même si vous disposez de suffisamment de mémoire, votre programme se bloque pendant un certain temps jusqu'à ce que la liste de sortie soit remplie.
Pour voir cela, stockez les éléments suivants dans un script appelénaive.py:
def naive_grouper(inputs, n):
num_groups = len(inputs) // n
return [tuple(inputs[i*n:(i+1)*n]) for i in range(num_groups)]
for _ in naive_grouper(range(100000000), 10):
passDepuis la console, vous pouvez utiliser la commandetime (sur les systèmes UNIX) pour mesurer l'utilisation de la mémoire et le temps utilisateur du processeur. Make sure you have at least 5GB of free memory before executing the following:
$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 naive.py
Memory used (kB): 4551872
User time (seconds): 11.04Note: Sur Ubuntu, vous devrez peut-être exécuter
/usr/bin/timeau lieu detimepour que l'exemple ci-dessus fonctionne.
L'implémentation delist ettuple dansnaive_grouper() nécessite environ 4,5 Go de mémoire pour traiterrange(100000000). Travailler avec des itérateurs améliore considérablement cette situation. Considérer ce qui suit:
def better_grouper(inputs, n):
iters = [iter(inputs)] * n
return zip(*iters)Il se passe beaucoup de choses dans cette petite fonction, alors décomposons-la avec un exemple concret. L'expression[iters(inputs)] * n crée une liste de référencesn vers le même itérateur:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> iters = [iter(nums)] * 2
>>> list(id(itr) for itr in iters) # IDs are the same.
[139949748267160, 139949748267160]Ensuite,zip(*iters) renvoie un itérateur sur des paires d'éléments correspondants de chaque itérateur eniters. Lorsque le premier élément,1, est extrait du «premier» itérateur, le «deuxième» itérateur commence maintenant à2 puisqu'il ne s'agit que d'une référence au «premier» itérateur et a donc été avancé un pas. Ainsi, le premier tuple produit parzip() est(1, 2).
À ce stade, «les deux» itérateurs deiters commencent à3, donc lorsquezip() extrait3 du «premier» itérateur, il obtient4 de le «second» pour produire le tuple(3, 4). Ce processus se poursuit jusqu'à ce quezip() produise finalement(9, 10) et que les «deux» itérateurs deiters soient épuisés:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(better_grouper(nums, 2))
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]La fonctionbetter_grouper() est meilleure pour plusieurs raisons. Premièrement, sans la référence auxlen() intégrés,better_grouper() peut prendre n'importe quel itérable comme argument (même des itérateurs infinis). Deuxièmement, en renvoyant un itérateur plutôt qu'une liste,better_grouper() peut traiter d'énormes itérables sans problème et utilise beaucoup moins de mémoire.
Stockez les éléments suivants dans un fichier appelébetter.py et exécutez-le à nouveau avectime depuis la console:
def better_grouper(inputs, n):
iters = [iter(inputs)] * n
return zip(*iters)
for _ in better_grouper(range(100000000), 10):
pass$ time -f "Memory used (kB): %M\nUser time (seconds): %U" python3 better.py
Memory used (kB): 7224
User time (seconds): 2.48Cela représente 630 fois moins de mémoire utilisée quenaive.py en moins d’un quart du temps!
Maintenant que vous avez vu ce qu'estitertools («algèbre d'itérateur») et pourquoi vous devriez l'utiliser (efficacité de la mémoire améliorée et temps d'exécution plus rapide), voyons comment amenerbetter_grouper() au niveau suivant avecitertools.
La recettegrouper
Le problème avecbetter_grouper() est qu'il ne gère pas les situations où la valeur passée au deuxième argument n'est pas un facteur de la longueur de l'itérable dans le premier argument:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(better_grouper(nums, 4))
[(1, 2, 3, 4), (5, 6, 7, 8)]Les éléments 9 et 10 sont absents de la sortie groupée. Cela se produit carzip() arrête d'agréger les éléments une fois que l'itérable le plus court qui lui est passé est épuisé. Il serait plus logique de renvoyer un troisième groupe contenant 9 et 10.
Pour ce faire, vous pouvez utiliseritertools.zip_longest(). Cette fonction accepte n'importe quel nombre d'itérables comme arguments et un argument de mot-cléfillvalue qui vaut par défautNone. Le moyen le plus simple de se faire une idée de la différence entrezip() etzip_longest() est de regarder un exemple de sortie:
>>>
>>> import itertools as it
>>> x = [1, 2, 3, 4, 5]
>>> y = ['a', 'b', 'c']
>>> list(zip(x, y))
[(1, 'a'), (2, 'b'), (3, 'c')]
>>> list(it.zip_longest(x, y))
[(1, 'a'), (2, 'b'), (3, 'c'), (4, None), (5, None)]Dans cet esprit, remplacezzip() dansbetter_grouper() parzip_longest():
import itertools as it
def grouper(inputs, n, fillvalue=None):
iters = [iter(inputs)] * n
return it.zip_longest(*iters, fillvalue=fillvalue)Maintenant, vous obtenez un meilleur résultat:
>>>
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> print(list(grouper(nums, 4)))
[(1, 2, 3, 4), (5, 6, 7, 8), (9, 10, None, None)]La fonctiongrouper() se trouve dans lesRecipes section de la documentationitertools. Les recettes sont une excellente source d'inspiration pour des façons d'utiliseritertools à votre avantage.
Note: A partir de ce point, la ligneimport itertools as it ne sera pas incluse au début des exemples. Toutes les méthodesitertools dans les exemples de code sont précédées deit. L'importation du module est implicite.
Si vous obtenez une exceptionNameError: name 'itertools' is not defined ouNameError: name 'it' is not defined lors de l'exécution de l'un des exemples de ce didacticiel, vous devrez d'abord importer le moduleitertools.
Et tu, Brute Force?
Voici un problème courant de style interview:
Vous avez trois billets de 20 $, cinq billets de 10 $, deux billets de 5 $ et cinq billets de 1 $. De combien de façons pouvez-vous changer un billet de 100 $?
Pour“brute force” ce problème, il vous suffit de commencer à répertorier les moyens de choisir une facture dans votre portefeuille, de vérifier si l'un de ces éléments apporte un changement de 100 $, puis de répertorier les moyens de choisir deux factures dans votre portefeuille, vérifiez à nouveau , et ainsi de suite.
Mais vous êtes programmeur, vous souhaitez donc naturellement automatiser ce processus.
Commencez par créer une liste des factures que vous avez dans votre portefeuille:
bills = [20, 20, 20, 10, 10, 10, 10, 10, 5, 5, 1, 1, 1, 1, 1]Un choix de chosesk à partir d'un ensemble de chosesn s'appelle uncombination, etitertools est là pour vous. La fonctionitertools.combinations() prend deux arguments - uninputs itérable et un entier positifn - et produit un itérateur sur les tuples de toutes les combinaisons d'élémentsn dansinputs .
Par exemple, pour répertorier les combinaisons de trois factures dans votre portefeuille, faites simplement:
>>>
>>> list(it.combinations(bills, 3))
[(20, 20, 20), (20, 20, 10), (20, 20, 10), ... ]Pour résoudre le problème, vous pouvez faire une boucle sur les entiers positifs de 1 àlen(bills), puis vérifier quelles combinaisons de chaque taille totalisent 100 $:
>>>
>>> makes_100 = []
>>> for n in range(1, len(bills) + 1):
... for combination in it.combinations(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)Si vous imprimezmakes_100, vous remarquerez qu'il y a beaucoup de combinaisons répétées. Cela a du sens parce que vous pouvez faire de la monnaie pour 100 $ avec trois billets de 20 $ et quatre billets de 10 $, maiscombinations() le fait avec les quatre premiers billets de 10 $ dans votre portefeuille; les premier, troisième, quatrième et cinquième billets de 10 dollars; les premier, deuxième, quatrième et cinquième billets de 10 $; etc.
Pour supprimer les doublons demakes_100, vous pouvez le convertir enset:
>>>
>>> set(makes_100)
{(20, 20, 10, 10, 10, 10, 10, 5, 1, 1, 1, 1, 1),
(20, 20, 10, 10, 10, 10, 10, 5, 5),
(20, 20, 20, 10, 10, 10, 5, 1, 1, 1, 1, 1),
(20, 20, 20, 10, 10, 10, 5, 5),
(20, 20, 20, 10, 10, 10, 10)}Donc, il y a cinq façons de changer une facture de 100 $ avec les factures que vous avez dans votre portefeuille.
Voici une variante du même problème:
De combien de façons existe-t-il de modifier un billet de 100 $ en utilisant un nombre quelconque de billets de 50 $, 20 $, 10 $, 5 $ et 1 $?
Dans ce cas, vous n'avez pas de collection de factures prédéfinie, vous avez donc besoin d'un moyen de générer toutes les combinaisons possibles en utilisant un nombre quelconque de factures. Pour cela, vous aurez besoin de la fonctionitertools.combinations_with_replacement().
Il fonctionne exactement commecombinations(), en acceptant uninputs itérable et un entier positifn, et retourne un itérateur surn-uplets d'éléments deinputs. La différence est quecombinations_with_replacement() permet aux éléments d'être répétés dans les tuples qu'il renvoie.
Par exemple:
>>>
>>> list(it.combinations_with_replacement([1, 2], 2))
[(1, 1), (1, 2), (2, 2)]Comparez cela àcombinations():
>>>
>>> list(it.combinations([1, 2], 2))
[(1, 2)]Voici à quoi ressemble la solution au problème révisé:
>>>
>>> bills = [50, 20, 10, 5, 1]
>>> make_100 = []
>>> for n in range(1, 101):
... for combination in it.combinations_with_replacement(bills, n):
... if sum(combination) == 100:
... makes_100.append(combination)Dans ce cas, vous n’avez pas besoin de supprimer les doublons carcombinations_with_replacement() n’en produira aucun:
>>>
>>> len(makes_100)
343Si vous exécutez la solution ci-dessus, vous pouvez remarquer qu'il faut un certain temps pour que la sortie s'affiche. En effet, il doit traiter 96 560 645 combinaisons!
Une autre fonctionitertools «force brute» estpermutations(), qui accepte un seul itérable et produit toutes les permutations possibles (réarrangements) de ses éléments:
>>>
>>> list(it.permutations(['a', 'b', 'c']))
[('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'),
('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')]Tout itérable de trois éléments aura six permutations, et le nombre de permutations d'itérables plus longs croît extrêmement rapidement. En fait, un itérable de longueurn an! permutations, où
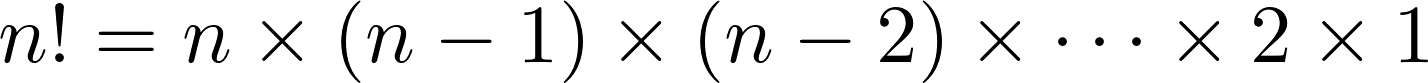
Pour mettre cela en perspective, voici un tableau de ces nombres pourn = 1 àn = 10:
| n | n! |
|---|---|
2 |
2 |
3 |
6 |
4 |
24 |
5 |
120 |
6 |
720 |
7 |
5 040 |
8 |
40 320 |
9 |
362 880 |
10 |
3 628 800 |
Le phénomène de quelques entrées produisant un grand nombre de résultats est appelé uncombinatorial explosion et doit être gardé à l'esprit lorsque vous travaillez aveccombinations(),combinations_with_replacement() etpermutations().
Il est généralement préférable d'éviter les algorithmes de force brute, bien qu'il soit parfois nécessaire d'en utiliser un (par exemple, si l'exactitude de l'algorithme est critique ou si chaque résultat possiblemust doit être pris en compte). Dans ce cas,itertools vous a couvert.
Récapitulation de la section
Dans cette section, vous avez rencontré trois fonctionsitertools:combinations(),combinations_with_replacement() etpermutations().
Passons en revue ces fonctions avant de poursuivre:
itertools.combinations Exemple
combinations(iterable, n)Renvoie des combinaisons successives d'éléments de longueur n dans l'itérable.
>>>
>>> combinations([1, 2, 3], 2)
(1, 2), (1, 3), (2, 3)itertools.combinations_with_replacement Exemple
combinations_with_replacement(iterable, n)Renvoie des combinaisons successives d'éléments de longueur n dans l'itérable permettant aux éléments individuels d'avoir des répétitions successives.
>>>
>>> combinations_with_replacement([1, 2], 2)
(1, 1), (1, 2), (2, 2)itertools.permutations Exemple
permutations(iterable, n=None)Renvoie des permutations successives de longueur n d'éléments dans l'itérable.
>>>
>>> permutations('abc')
('a', 'b', 'c'), ('a', 'c', 'b'), ('b', 'a', 'c'),
('b', 'c', 'a'), ('c', 'a', 'b'), ('c', 'b', 'a')Séquences de nombres
Avecitertools, vous pouvez facilement générer des itérateurs sur des séquences infinies. Dans cette section, vous explorerez les séquences numériques, mais les outils et techniques présentés ici ne sont en aucun cas limités aux nombres.
Evens and Odds
Pour le premier exemple, vous allez créer une paire d'itérateurs sur des entiers pairs et impairswithout explicitly doing any arithmetic. Avant de plonger, examinons une solution arithmétique utilisant des générateurs:
>>>
>>> def evens():
... """Generate even integers, starting with 0."""
... n = 0
... while True:
... yield n
... n += 2
...
>>> evens = evens()
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> def odds():
... """Generate odd integers, starting with 1."""
... n = 1
... while True:
... yield n
... n += 2
...
>>> odds = odds()
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]C'est assez simple, mais avecitertools, vous pouvez le faire de manière beaucoup plus compacte. La fonction dont vous avez besoin estitertools.count(), qui fait exactement ce à quoi elle ressemble: elle compte, en commençant par défaut par le nombre 0.
>>>
>>> counter = it.count()
>>> list(next(counter) for _ in range(5))
[0, 1, 2, 3, 4]Vous pouvez commencer à compter à partir de n'importe quel nombre de votre choix en définissant l'argument de mot-cléstart, qui vaut par défaut 0. Vous pouvez même définir un argument de mot-cléstep pour déterminer l'intervalle entre les nombres renvoyés parcount() - la valeur par défaut est 1.
Aveccount(), les itérateurs sur des entiers pairs et impairs deviennent des one-liners littéraux:
>>>
>>> evens = it.count(step=2)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = it.count(start=1, step=2)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]Ever since Python 3.1, la fonctioncount() accepte également les arguments non entiers:
>>>
>>> count_with_floats = it.count(start=0.5, step=0.75)
>>> list(next(count_with_floats) for _ in range(5))
[0.5, 1.25, 2.0, 2.75, 3.5]Vous pouvez même lui transmettre des nombres négatifs:
>>>
>>> negative_count = it.count(start=-1, step=-0.5)
>>> list(next(negative_count) for _ in range(5))
[-1, -1.5, -2.0, -2.5, -3.0]À certains égards,count() est similaire à la fonction intégréerange(), maiscount() renvoie toujours une séquence infinie. Vous vous demandez peut-être à quoi sert une séquence infinie car il est impossible de répéter complètement. C’est une question valable, et j’admets que la première fois que j’ai été initié à des itérateurs infinis, je n’ai pas trop compris
L'exemple qui m'a fait réaliser la puissance de l'itérateur infini était le suivant, qui émule le comportement desbuilt-in enumerate() function:
>>>
>>> list(zip(it.count(), ['a', 'b', 'c']))
[(0, 'a'), (1, 'b'), (2, 'c')]C'est un exemple simple, mais réfléchissez-y: vous venez d'énumérer une liste sans bouclefor et sans connaître la longueur de la liste à l'avance.
Relations de récurrence
Unrecurrence relation est une manière de décrire une suite de nombres avec une formule récursive. L'une des relations de récurrence les plus connues est celle qui décrit lesFibonacci sequence.
La séquence de Fibonacci est la séquence0, 1, 1, 2, 3, 5, 8, 13, .... Il commence par 0 et 1, et chaque nombre suivant de la séquence est la somme des deux précédents. Les nombres de cette séquence sont appelés les nombres de Fibonacci. En notation mathématique, la relation de récurrence décrivant le nombre de Fibonaccin-ème ressemble à ceci:
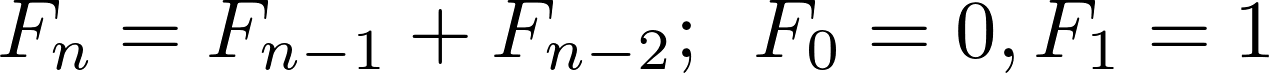
Note: Si vous recherchez Google, vous trouverez une foule d'implémentations de ces nombres en Python. Vous pouvez trouver une fonction récursive qui les produit dans l'article deThinking Recursively in Python ici sur Real Python.
Il est courant de voir la séquence de Fibonacci produite avec un générateur:
def fibs():
a, b = 0, 1
while True:
yield a
a, b = b, a + bLa relation de récurrence décrivant les nombres de Fibonacci est appelée unsecond order recurrence relation parce que, pour calculer le nombre suivant dans la séquence, vous devez regarder en arrière deux nombres derrière.
En général, les relations de récurrence de second ordre ont la forme:
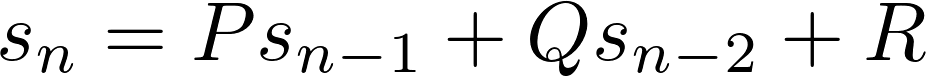
Ici,P,Q etR sont des constantes. Pour générer la séquence, vous avez besoin de deux valeurs initiales. Pour les nombres de Fibonacci,P =Q = 1,R = 0 et les valeurs initiales sont 0 et 1.
Comme vous pouvez le deviner, unfirst order recurrence relation a la forme suivante:
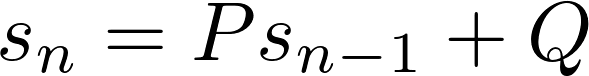
Il existe d'innombrables séquences de nombres qui peuvent être décrites par des relations de récurrence de premier et de second ordre. Par exemple, les entiers positifs peuvent être décrits comme une relation de récurrence de premier ordre avecP =Q = 1 et la valeur initiale 1. Pour les entiers pairs, prenezP = 1 etQ = 2 avec la valeur initiale 0.
Dans cette section, vous allez construire des fonctions pour produire la séquenceany dont les valeurs peuvent être décrites avec une relation de récurrence du premier ou du second ordre.
Relations de récurrence du premier ordre
Vous avez déjà vu commentcount() peut générer la séquence d'entiers non négatifs, les entiers pairs et les entiers impairs. Vous pouvez également l'utiliser pour générer la séquence3n = 0, 3, 6, 9, 12, … et4n = 0, 4, 8, 12, 16, ….
count_by_three = it.count(step=3)
count_by_four = it.count(step=4)En fait,count() peut produire des séquences de multiples de n'importe quel nombre que vous souhaitez. Ces séquences peuvent être décrites avec des relations de récurrence de premier ordre. Par exemple, pour générer la séquence de multiples d'un certain nombren, prenez simplementP = 1,Q =n et la valeur initiale 0.
Un autre exemple simple de relation de récurrence de premier ordre est la séquence constanten, n, n, n, n…, oùn est n'importe quelle valeur que vous souhaitez. Pour cette séquence, définissezP = 1 etQ = 0 avec la valeur initialen. itertools fournit également un moyen simple d'implémenter cette séquence, avec la fonctionrepeat():
all_ones = it.repeat(1) # 1, 1, 1, 1, ...
all_twos = it.repeat(2) # 2, 2, 2, 2, ...Si vous avez besoin d'une séquence finie de valeurs répétées, vous pouvez définir un point d'arrêt en passant un entier positif comme deuxième argument:
five_ones = it.repeat(1, 5) # 1, 1, 1, 1, 1
three_fours = it.repeat(4, 3) # 4, 4, 4Ce qui n'est peut-être pas aussi évident, c'est que la séquence1, -1, 1, -1, 1, -1, ... d'alternance des 1 et -1 peut également être décrite par une relation de récurrence du premier ordre. Prenez simplementP = -1,Q = 0 et la valeur initiale 1.
Il existe un moyen simple de générer cette séquence avec la fonctionitertools.cycle(). Cette fonction prend uninputs itérable comme argument et retourne un itérateur infini sur les valeurs deinputs qui revient au début une fois que la fin deinputs est atteinte. Donc, pour produire la séquence alternée de 1 et -1, vous pouvez faire ceci:
alternating_ones = it.cycle([1, -1]) # 1, -1, 1, -1, 1, -1, ...Le but de cette section, cependant, est de produire une fonction unique qui peut générer une relation de récurrence de premier ordreany - il suffit de la transmettreP,Q et une valeur initiale. Une façon de faire est d'utiliseritertools.accumulate().
La fonctionaccumulate() prend deux arguments - uninputs itérable et unbinary functionfunc (c'est-à-dire une fonction avec exactement deux entrées) - et renvoie un itérateur sur les résultats cumulés de appliquerfunc aux éléments deinputs. Il est à peu près équivalent au générateur suivant:
def accumulate(inputs, func):
itr = iter(inputs)
prev = next(itr)
for cur in itr:
yield prev
prev = func(prev, cur)Par exemple:
>>>
>>> import operator
>>> list(it.accumulate([1, 2, 3, 4, 5], operator.add))
[1, 3, 6, 10, 15]La première valeur de l'itérateur renvoyée paraccumulate() est toujours la première valeur de la séquence d'entrée. Dans l'exemple ci-dessus, il s'agit de 1 - la première valeur en[1, 2, 3, 4, 5].
La valeur suivante dans l'itérateur de sortie est la somme des deux premiers éléments de la séquence d'entrée:add(1, 2) = 3. Pour produire la valeur suivante,accumulate() prend le résultat deadd(1, 2) et l'ajoute à la troisième valeur de la séquence d'entrée:
add(3, 3) = add(add(1, 2), 3) = 6
La quatrième valeur produite paraccumulate() estadd(add(add(1, 2), 3), 4) = 10, et ainsi de suite.
Le deuxième argument deaccumulate() est par défautoperator.add(), donc l'exemple précédent peut être simplifié à:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5]))
[1, 3, 6, 10, 15]Passer lesmin() intégrés àaccumulate() gardera une trace d'un minimum en cours:
>>>
>>> list(it.accumulate([9, 21, 17, 5, 11, 12, 2, 6], min))
[9, 9, 9, 5, 5, 5, 2, 2]Des fonctions plus complexes peuvent être passées àaccumulate() avec les expressionslambda:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: (x + y) / 2))
[1, 1.5, 2.25, 3.125, 4.0625]L'ordre des arguments dans la fonction binaire passés àaccumulate() est important. Le premier argument est toujours le résultat accumulé précédemment et le deuxième argument est toujours l'élément suivant de l'itérable d'entrée. Par exemple, considérez la différence de sortie des expressions suivantes:
>>>
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: x - y))
[1, -1, -4, -8, -13]
>>> list(it.accumulate([1, 2, 3, 4, 5], lambda x, y: y - x))
[1, 1, 2, 2, 3]Pour modéliser une relation de récurrence, vous pouvez simplement ignorer le deuxième argument de la fonction binaire passée àaccumulate(). Autrement dit, les valeurs donnéesp,q ets,lambda x, _: p*s + q renverront la valeur suivantx dans la relation de récurrence définie parsᵢ =Psᵢ₋₁ +Q.
Pour queaccumulate() itère sur la relation de récurrence résultante, vous devez lui passer une séquence infinie avec la bonne valeur initiale. Peu importe les autres valeurs de la séquence, tant que la valeur initiale est la valeur initiale de la relation de récurrence. Vous pouvez le faire avecrepeat():
def first_order(p, q, initial_val):
"""Return sequence defined by s(n) = p * s(n-1) + q."""
return it.accumulate(it.repeat(initial_val), lambda s, _: p*s + q)En utilisantfirst_order(), vous pouvez créer les séquences ci-dessus comme suit:
>>> evens = first_order(p=1, q=2, initial_val=0)
>>> list(next(evens) for _ in range(5))
[0, 2, 4, 6, 8]
>>> odds = first_order(p=1, q=2, initial_val=1)
>>> list(next(odds) for _ in range(5))
[1, 3, 5, 7, 9]
>>> count_by_threes = first_order(p=1, q=3, initial_val=0)
>>> list(next(count_by_threes) for _ in range(5))
[0, 3, 6, 9, 12]
>>> count_by_fours = first_order(p=1, q=4, initial_val=0)
>>> list(next(count_by_fours) for _ in range(5))
[0, 4, 8, 12, 16]
>>> all_ones = first_order(p=1, q=0, initial_val=1)
>>> list(next(all_ones) for _ in range(5))
[1, 1, 1, 1, 1]
>>> all_twos = first_order(p=1, q=0, initial_val=2)
>>> list(next(all_twos) for _ in range(5))
[2, 2, 2, 2, 2]
>>> alternating_ones = first_order(p=-1, 0, initial_val=1)
>>> list(next(alternating_ones) for _ in range(5))
[1, -1, 1, -1, 1]Relations de récurrence du second ordre
La génération de séquences décrites par des relations de récurrence de second ordre, comme la séquence de Fibonacci, peut être accomplie en utilisant une technique similaire à celle utilisée pour les relations de récurrence de premier ordre.
La différence ici est que vous devez créer une séquence intermédiaire de tuples qui gardent une trace des deux éléments précédents de la séquence, puismap() chacun de ces tuples vers leur premier composant pour obtenir la séquence finale.
Voici à quoi ça ressemble:
def second_order(p, q, r, initial_values):
"""Return sequence defined by s(n) = p * s(n-1) + q * s(n-2) + r."""
intermediate = it.accumulate(
it.repeat(initial_values),
lambda s, _: (s[1], p*s[1] + q*s[0] + r)
)
return map(lambda x: x[0], intermediate)En utilisantsecond_order(), vous pouvez générer la séquence de Fibonacci comme ceci:
>>> fibs = second_order(p=1, q=1, r=0, initial_values=(0, 1))
>>> list(next(fibs) for _ in range(8))
[0, 1, 1, 2, 3, 5, 8, 13]D'autres séquences peuvent être facilement générées en modifiant les valeurs dep,q etr. Par exemple, lesPell numbers et lesLucas numbers peuvent être générés comme suit:
pell = second_order(p=2, q=1, r=0, initial_values=(0, 1))
>>> list(next(pell) for _ in range(6))
[0, 1, 2, 5, 12, 29]
>>> lucas = second_order(p=1, q=1, r=0, initial_values=(2, 1))
>>> list(next(lucas) for _ in range(6))
[2, 1, 3, 4, 7, 11]Vous pouvez même générer les numéros de Fibonacci alternés:
>>> alt_fibs = second_order(p=-1, q=1, r=0, initial_values=(-1, 1))
>>> list(next(alt_fibs) for _ in range(6))
[-1, 1, -2, 3, -5, 8]Tout cela est vraiment cool si vous êtes un géant des maths comme moi, mais prenez du recul pendant une seconde et comparezsecond_order() au générateurfibs() du début de cette section. Laquelle est la plus facile à comprendre?
Ceci est une leçon précieuse. La fonctionaccumulate() est un outil puissant à avoir dans votre boîte à outils, mais son utilisation peut parfois signifier sacrifier la clarté et la lisibilité.
Récapitulation de la section
Vous avez vu plusieurs fonctionsitertools dans cette section. Examinons-les maintenant.
itertools.count Exemple
count(start=0, step=1)Renvoie un objet count dont la méthode.
__next__()renvoie des valeurs consécutives.
>>>
>>> count()
0, 1, 2, 3, 4, ...
>>> count(start=1, step=2)
1, 3, 5, 7, 9, ...itertools.repeat Exemple
repeat(object, times=1)Créez un itérateur qui retourne l'objet le nombre de fois spécifié. S'il n'est pas spécifié, renvoie l'objet sans fin.
>>>
>>> repeat(2)
2, 2, 2, 2, 2 ...
>>> repeat(2, 5) # Stops after 5 repititions.
2, 2, 2, 2, 2itertools.cycle Exemple
cycle(iterable)Renvoyez les éléments de l'itérable jusqu'à ce qu'il soit épuisé. Répétez ensuite la séquence indéfiniment.
>>>
>>> cycle(['a', 'b', 'c'])
a, b, c, a, b, c, a, ...itertools accumulate Exemple
accumulate(iterable, func=operator.add)Renvoie une série de sommes cumulées (ou d'autres résultats de fonctions binaires).
>>>
>>> accumulate([1, 2, 3])
1, 3, 6Très bien, prenons une pause dans le calcul et amusons-nous avec les cartes.
Traiter un jeu de cartes
Supposons que vous construisez une application de poker. Vous aurez besoin d'un jeu de cartes. Vous pouvez commencer par définir une liste de rangs (as, roi, reine, valet, 10, 9, etc.) et une liste de costumes (cœurs, diamants, massues et piques):
ranks = ['A', 'K', 'Q', 'J', '10', '9', '8', '7', '6', '5', '4', '3', '2']
suits = ['H', 'D', 'C', 'S']Vous pouvez représenter une carte comme un tuple dont le premier élément est un rang et le deuxième élément est une couleur. Un jeu de cartes serait une collection de tels tuples. Le jeu doit agir comme la vraie chose, il est donc logique de définir un générateur qui rapporte les cartes une à la fois et s'épuise une fois que toutes les cartes sont distribuées.
Une façon d'y parvenir est d'écrire un générateur avec une bouclefor imbriquée surranks etsuits:
def cards():
"""Return a generator that yields playing cards."""
for rank in ranks:
for suit in suits:
yield rank, suitVous pouvez écrire ceci de manière plus compacte avec une expression de générateur:
cards = ((rank, suit) for rank in ranks for suit in suits)Cependant, certains pourraient argumenter que c'est en fait plus difficile à comprendre que la bouclefor imbriquée plus explicite.
Il permet de visualiser les bouclesfor imbriquées d'un point de vue mathématique, c'est-à-dire en tant queCartesian product de deux ou plusieurs itérables. En mathématiques, le produit cartésien de deux ensemblesA etB est l'ensemble de tous les tuples de la forme(a, b) oùa est un élément deA et b est un élément deB.
Voici un exemple avec les itérables Python: le produit cartésien deA = [1, 2] etB = ['a', 'b'] est[(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')].
La fonctionitertools.product() est exactement pour cette situation. Il prend n'importe quel nombre d'itérables comme arguments et retourne un itérateur sur les tuples dans le produit cartésien:
it.product([1, 2], ['a', 'b']) # (1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')La fonctionproduct() n'est en aucun cas limitée à deux itérables. Vous pouvez le passer autant que vous le souhaitez - ils n'ont même pas besoin d'être tous de la même taille! Voyez si vous pouvez prédire ce qu'estproduct([1, 2, 3], ['a', 'b'], ['c']), puis vérifiez votre travail en l'exécutant dans l'interpréteur.
Warning: La fonction
product()est une autre fonction de «force brute» et peut conduire à une explosion combinatoire si vous ne faites pas attention.
En utilisantproduct(), vous pouvez réécrire lescards sur une seule ligne:
cards = it.product(ranks, suits)Tout va bien et dandy, mais toute application de poker digne de ce nom vaut mieux commencer par un jeu mélangé:
import random
def shuffle(deck):
"""Return iterator over shuffled deck."""
deck = list(deck)
random.shuffle(deck)
return iter(tuple(deck))
cards = shuffle(cards)Note: La fonction
random.shuffle()utilise lesFisher-Yates shuffle pour mélanger une liste (ou toute séquence mutable) à la placein O(n) time. Cet algorithme est bien adapté pour mélangercardscar il produit une permutation non biaisée, c'est-à-dire que toutes les permutations de l'itérable sont également susceptibles d'être renvoyées parrandom.shuffle().Cela dit, vous avez probablement remarqué que
shuffle()crée une copie de son entréedecken mémoire en appelantlist(deck). Bien que cela semble aller à l'encontre de l'esprit de cet article, cet auteur ne connaît pas une bonne façon de mélanger un itérateur sans faire de copie.
Par courtoisie envers vos utilisateurs, vous souhaitez leur donner la possibilité de couper le jeu. Si vous imaginez que les cartes sont empilées proprement sur une table, vous demandez à l'utilisateur de choisir un nombren, puis de retirer les premières cartesn du haut de la pile et de les déplacer vers le bas.
Si vous connaissez une ou deux choses à propos deslicing, vous pourriez accomplir ceci comme ceci:
def cut(deck, n):
"""Return an iterator over a deck of cards cut at index `n`."""
if n < 0:
raise ValueError('`n` must be a non-negative integer')
deck = list(deck)
return iter(deck[n:] + deck[:n])
cards = cut(cards, 26) # Cut the deck in half.La fonctioncut() convertit d'aborddeck en une liste afin que vous puissiez la découper pour effectuer la découpe. Pour garantir que vos tranches se comportent comme prévu, vous devez vérifier quen n'est pas négatif. Si ce n'est pas le cas, vous feriez mieux de lever une exception pour que rien de fou ne se passe.
Découper le paquet est assez simple: le haut du paquet coupé est justedeck[:n], et le bas est les cartes restantes, oudeck[n:]. Pour construire le nouveau deck avec la «moitié» supérieure déplacée vers le bas, il vous suffit de l'ajouter en bas:deck[n:] + deck[:n].
La fonctioncut() est assez simple, mais elle souffre de quelques problèmes. Lorsque vous découpez une liste, vous faites une copie de la liste d'origine et renvoyez une nouvelle liste avec les éléments sélectionnés. Avec un jeu de seulement 52 cartes, cette augmentation de la complexité de l'espace est insignifiante, mais vous pouvez réduire la surcharge mémoire en utilisantitertools. Pour ce faire, vous aurez besoin de trois fonctions:itertools.tee(),itertools.islice() etitertools.chain().
Voyons comment ces fonctions fonctionnent.
La fonctiontee() peut être utilisée pour créer n'importe quel nombre d'itérateurs indépendants à partir d'un seul itérable. Il prend deux arguments: le premier est uninputs itérable, et le second est le nombren d'itérateurs indépendants surinputs à renvoyer (par défaut,n est défini sur 2). Les itérateurs sont renvoyés dans un tuple de longueurn.
>>>
>>> iterator1, iterator2 = it.tee([1, 2, 3, 4, 5], 2)
>>> list(iterator1)
[1, 2, 3, 4, 5]
>>> list(iterator1) # iterator1 is now exhausted.
[]
>>> list(iterator2) # iterator2 works independently of iterator1
[1, 2, 3, 4, 5].Bien quetee() soit utile pour créer des itérateurs indépendants, il est important de comprendre un peu comment cela fonctionne sous le capot. Lorsque vous appeleztee() pour créer des itérateurs indépendants den, chaque itérateur travaille essentiellement avec sa propre file d'attente FIFO.
Lorsqu'une valeur est extraite d'un itérateur, cette valeur est ajoutée aux files d'attente pour les autres itérateurs. Ainsi, si un itérateur est épuisé avant les autres, chaque itérateur restant conservera une copie de l'itérable entier en mémoire. (Vous pouvez trouver une fonction Python qui émuletee() dans lesitertoolsdocs.)
Pour cette raison,tee() doit être utilisé avec précaution. Si vous épuisez de grandes portions d'un itérateur avant de travailler avec l'autre retourné partee(), vous feriez peut-être mieux de convertir l'itérateur d'entrée enlist outuple.
La fonctionislice() fonctionne à peu près de la même manière que le découpage d'une liste ou d'un tuple. Vous lui passez un point itérable, un point de départ et un point d'arrêt, et, tout comme le découpage d'une liste, la tranche renvoyée s'arrête à l'index juste avant le point d'arrêt. Vous pouvez également inclure éventuellement une valeur de pas. La plus grande différence ici est, bien sûr, queislice() renvoie un itérateur.
>>>
>>> # Slice from index 2 to 4
>>> list(it.islice('ABCDEFG', 2, 5)))
['C' 'D' 'E']
>>> # Slice from beginning to index 4, in steps of 2
>>> list(it.islice([1, 2, 3, 4, 5], 0, 5, 2))
[1, 3, 5]
>>> # Slice from index 3 to the end
>>> list(it.islice(range(10), 3, None))
[3, 4, 5, 6, 7, 8, 9]
>>> # Slice from beginning to index 3
>>> list(it.islice('ABCDE', 4))
['A', 'B', 'C', 'D']Les deux derniers exemples ci-dessus sont utiles pour tronquer les itérables. Vous pouvez l'utiliser pour remplacer le découpage de liste utilisé danscut() pour sélectionner le «haut» et le «bas» de la platine. En prime,islice() n'acceptera pas les indices négatifs pour les positions de départ / arrêt et la valeur de pas, vous n'aurez donc pas besoin de lever une exception sin est négatif.
La dernière fonction dont vous avez besoin estchain(). Cette fonction prend un nombre illimité d'itérables comme arguments et les «enchaîne» ensemble. Par exemple:
>>>
>>> list(it.chain('ABC', 'DEF'))
['A' 'B' 'C' 'D' 'E' 'F']
>>> list(it.chain([1, 2], [3, 4, 5, 6], [7, 8, 9]))
[1, 2, 3, 4, 5, 6, 7, 8, 9]Maintenant que vous avez une puissance de feu supplémentaire dans votre arsenal, vous pouvez réécrire la fonctioncut() pour couper le jeu de cartes sans faire une copie complète decards en mémoire:
def cut(deck, n):
"""Return an iterator over a deck of cards cut at index `n`."""
deck1, deck2 = it.tee(deck, 2)
top = it.islice(deck1, n)
bottom = it.islice(deck2, n, None)
return it.chain(bottom, top)
cards = cut(cards, 26)Maintenant que vous avez mélangé et coupé les cartes, il est temps de distribuer quelques mains. Vous pouvez écrire une fonctiondeal() qui prend un jeu, le nombre de mains et la taille de la main comme arguments et retourne un tuple contenant le nombre de mains spécifié.
Vous n'avez pas besoin de nouvelles fonctionsitertools pour écrire cette fonction. Voyez ce que vous pouvez trouver par vous-même avant de lire à l'avance.
Voici une solution:
def deal(deck, num_hands=1, hand_size=5):
iters = [iter(deck)] * hand_size
return tuple(zip(*(tuple(it.islice(itr, num_hands)) for itr in iters)))Vous commencez par créer une liste de référenceshand_size à un itérateur surdeck. Vous parcourez ensuite cette liste, en supprimant les cartesnum_hands à chaque étape et en les stockant dans des tuples.
Ensuite, vouszip() ces tuples jusqu'à émuler le fait de distribuer une carte à la fois à chaque joueur. Cela produit des tuplesnum_hands, chacun contenant des carteshand_size. Enfin, vous empaquetez les mains en un tuple pour les retourner toutes à la fois.
Cette implémentation définit les valeurs par défaut pournum_hands sur1 ethand_size sur5 - peut-être que vous créez une application «Five Card Draw». Voici comment vous utiliseriez cette fonction, avec quelques exemples de sortie:
>>>
>>> p1_hand, p2_hand, p3_hand = deal(cards, num_hands=3)
>>> p1_hand
(('A', 'S'), ('5', 'S'), ('7', 'H'), ('9', 'H'), ('5', 'H'))
>>> p2_hand
(('10', 'H'), ('2', 'D'), ('2', 'S'), ('J', 'C'), ('9', 'C'))
>>> p3_hand
(('2', 'C'), ('Q', 'S'), ('6', 'C'), ('Q', 'H'), ('A', 'C'))Selon vous, quel est l'état decards maintenant que vous avez distribué trois mains de cinq cartes?
>>>
>>> len(tuple(cards))
37Les quinze cartes distribuées sont consommées à partir de l'itérateurcards, ce qui est exactement ce que vous voulez. De cette façon, au fur et à mesure que le jeu continue, l'état de l'itérateurcards reflète l'état du deck en jeu.
Récapitulation de la section
Passons en revue les fonctionsitertools que vous avez vues dans cette section.
itertools.product Exemple
product(*iterables, repeat=1)Produit cartésien des itérables d'entrée. Équivalent aux boucles for imbriquées.
>>>
>>> product([1, 2], ['a', 'b'])
(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')itertools.tee Exemple
tee(iterable, n=2)Créez un nombre illimité d'itérateurs indépendants à partir d'une seule entrée itérable.
>>>
>>> iter1, iter2 = it.tee(['a', 'b', 'c'], 2)
>>> list(iter1)
['a', 'b', 'c']
>>> list(iter2)
['a', 'b', 'c']itertools.islice Exemple
islice(iterable, stop)islice(iterable, start, stop, step=1)Renvoie un itérateur dont la méthode
__next__()renvoie les valeurs sélectionnées à partir d'un itérable. Fonctionne comme unslice()sur une liste mais renvoie un itérateur.
>>>
>>> islice([1, 2, 3, 4], 3)
1, 2, 3
>>> islice([1, 2, 3, 4], 1, 2)
2, 3itertools.chain Exemple
chain(*iterables)Renvoie un objet chaîne dont la méthode
__next__()renvoie les éléments du premier itérable jusqu'à ce qu'il soit épuisé, puis les éléments de l'itérable suivant, jusqu'à ce que tous les itérables soient épuisés.
>>>
>>> chain('abc', [1, 2, 3])
'a', 'b', 'c', 1, 2, 3Entracte: aplanir une liste de listes
Dans l'exemple précédent, vous avez utiliséchain() pour placer un itérateur à la fin d'un autre. La fonctionchain() a une méthode de classe.from_iterable() qui prend un seul itérable comme argument. Les éléments de l'itérable doivent eux-mêmes être itérables, donc l'effet net est quechain.from_iterable() aplatit son argument:
>>>
>>> list(it.chain.from_iterable([[There’s no reason the argument of `+chain.from_iterable()+` needs to be finite. You could emulate the behavior of `+cycle()+`, for example:>>> cycle = it.chain.from_iterable(it.repeat('abc'))
>>> list(it.islice(cycle, 8))
['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b']La fonctionchain.from_iterable() est utile lorsque vous devez créer un itérateur sur des données qui ont été «fragmentées».
Dans la section suivante, vous verrez comment utiliseritertools pour effectuer une analyse de données sur un grand ensemble de données. Mais vous méritez une pause pour être resté fidèle à cela jusqu'ici. Pourquoi ne pas vous hydrater et vous détendre un peu? Peut-être même jouer un peuStar Trek: The Nth Iteration.
Retour? Génial! Faisons quelques analyses de données.
Analyse du S & P500
Dans cet exemple, vous aurez un premier aperçu de l'utilisation deitertools pour manipuler un ensemble de données volumineux, en particulier les données de prix journalier historiques de l'indice S & P500. Un fichier CSVSP500.csv avec ces données peut être trouvéhere (source:Yahoo Finance). Le problème que vous allez résoudre est le suivant:
Déterminez le gain quotidien maximal, la perte quotidienne (en pourcentage de changement) et la plus longue séquence de croissance de l'histoire du S & P500.
Pour avoir une idée de ce à quoi vous avez affaire, voici les dix premières lignes deSP500.csv:
$ head -n 10 SP500.csv
Date,Open,High,Low,Close,Adj Close,Volume
1950-01-03,16.660000,16.660000,16.660000,16.660000,16.660000,1260000
1950-01-04,16.850000,16.850000,16.850000,16.850000,16.850000,1890000
1950-01-05,16.930000,16.930000,16.930000,16.930000,16.930000,2550000
1950-01-06,16.980000,16.980000,16.980000,16.980000,16.980000,2010000
1950-01-09,17.080000,17.080000,17.080000,17.080000,17.080000,2520000
1950-01-10,17.030001,17.030001,17.030001,17.030001,17.030001,2160000
1950-01-11,17.090000,17.090000,17.090000,17.090000,17.090000,2630000
1950-01-12,16.760000,16.760000,16.760000,16.760000,16.760000,2970000
1950-01-13,16.670000,16.670000,16.670000,16.670000,16.670000,3330000Comme vous pouvez le voir, les premières données sont limitées. Les données s'améliorent pour les dates ultérieures et, dans l'ensemble, sont suffisantes pour cet exemple.
La stratégie pour résoudre ce problème est la suivante:
-
Lisez les données du fichier CSV et transformez-les en une séquence
gainsde changements quotidiens en pourcentage à l'aide de la colonne «Adj Close». -
Trouvez les valeurs maximale et minimale de la séquence
gainset la date à laquelle elles se produisent. (Notez qu'il est possible que ces valeurs soient atteintes plus d'une date; dans ce cas, la date la plus récente suffira.) -
Transformez
gainsen une séquencegrowth_streaksde tuples de valeurs positives consécutives engains. Déterminez ensuite la longueur du tuple le plus long engrowth_streakset les dates de début et de fin de la séquence. (Il est possible que la longueur maximale soit atteinte par plus d'un tuple engrowth_streaks; dans ce cas, le tuple avec les dates de début et de fin les plus récentes suffira.)
Lepercent change entre deux valeursx ety est donné par la formule suivante:
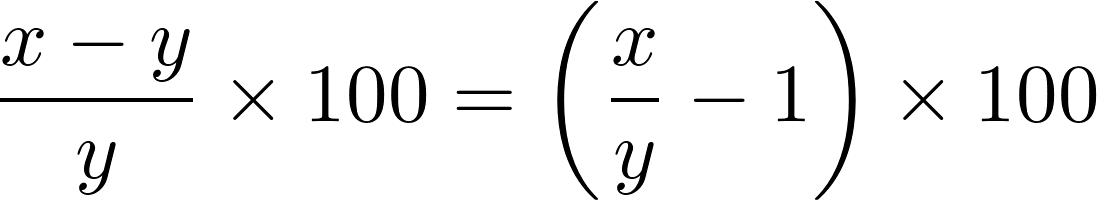
Pour chaque étape de l'analyse, il est nécessaire de comparer les valeurs associées aux dates. Pour faciliter ces comparaisons, vous pouvez sous-classer lesnamedtuple object descollections module:
from collections import namedtuple
class DataPoint(namedtuple('DataPoint', ['date', 'value'])):
__slots__ = ()
def __le__(self, other):
return self.value <= other.value
def __lt__(self, other):
return self.value < other.value
def __gt__(self, other):
return self.value > other.valueLa classeDataPoint a deux attributs:date (une instancedatetime.datetime) etvalue. Leshttps://docs.python.org/3/reference/datamodel.html#object.le [.__le__()],https://docs.python.org/3/reference/datamodel.html#object.lt [.__lt__()] ethttps://docs.python.org/3/reference/datamodel.html#object.gt [.__gt__()]dunder methods sont implémentés afin que les comparateurs booléens<=,< et> puissent être utilisés pour comparer les valeurs de deuxDataPointobjets de s. Cela permet également aux fonctions intégréesmax() etmin() d'être appelées avec les argumentsDataPoint.
Note: Si vous n'êtes pas familier avec
namedtuple, vérifiezthis excellent resource. L'implémentation denamedtuplepourDataPointn'est qu'une des nombreuses façons de construire cette structure de données. Par exemple, dans Python 3.7, vous pouvez implémenterDataPointen tant que classe de données. Consultez nosUltimate Guide to Data Classes pour plus d'informations.
Ce qui suit lit les données deSP500.csv vers un tuple d'objetsDataPoint:
import csv
from datetime import datetime
def read_prices(csvfile, _strptime=datetime.strptime):
with open(csvfile) as infile:
reader = csv.DictReader(infile)
for row in reader:
yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(),
value=float(row['Adj Close']))
prices = tuple(read_prices('SP500.csv'))Le générateurread_prices() ouvreSP500.csv et lit chaque ligne avec un objetcsv.DictReader(). DictReader() renvoie chaque ligne sous la forme d'unOrderedDict dont les clés sont les noms de colonne de la ligne d'en-tête du fichier CSV.
Pour chaque ligne,read_prices() renvoie un objetDataPoint contenant les valeurs des colonnes «Date» et «Adj Close». Enfin, la séquence complète de points de données est mise en mémoire en tant quetuple et stockée dans la variableprices.
Ensuite,prices doit être transformé en une séquence de changements quotidiens en pourcentage:
gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.))
for day, prev_day in zip(prices[1:], prices))Le choix de stocker les données dans untuple est intentionnel. Bien que vous puissiez pointergains vers un itérateur, vous devrez parcourir les données deux fois pour trouver les valeurs minimale et maximale.
Si vous utiliseztee() pour créer deux itérateurs indépendants, épuiser un itérateur pour trouver le maximum créera une copie de toutes les données en mémoire pour le deuxième itérateur. En créant untuple à l'avance, vous ne perdez rien en termes de complexité d'espace par rapport àtee(), et vous pouvez même gagner un peu de vitesse.
Note: Cet exemple se concentre sur l'utilisation de
itertoolspour analyser les données du S & P500. Ceux qui souhaitent travailler avec un grand nombre de données financières de séries chronologiques peuvent également vouloir consulter la bibliothèquePandas, qui est bien adaptée à de telles tâches.
Gain et perte maximum
Pour déterminer le gain maximum sur une seule journée, vous pouvez faire quelque chose comme ceci:
max_gain = DataPoint(None, 0)
for data_point in gains:
max_gain = max(data_point, max_gain)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)Vous pouvez simplifier la bouclefor en utilisant lesfunctools.reduce() function. Cette fonction accepte une fonction binairefunc et uninputs itérable comme arguments, et «réduit»inputs à une valeur unique en appliquantfunc cumulativement à des paires d'objets dans l'itérable .
Par exemple,functools.reduce(operator.add, [1, 2, 3, 4, 5]) renverra la somme1 + 2 + 3 + 4 + 5 = 15. Vous pouvez penser quereduce() fonctionne à peu près de la même manière queaccumulate(), sauf qu'il ne renvoie que la valeur finale dans la nouvelle séquence.
En utilisantreduce(), vous pouvez vous débarrasser complètement de la bouclefor dans l'exemple ci-dessus:
import functools as ft
max_gain = ft.reduce(max, gains)
print(max_gain) # DataPoint(date='2008-10-28', value=11.58)La solution ci-dessus fonctionne, mais elle n’est pas équivalente à la bouclefor que vous aviez auparavant. Voyez-vous pourquoi? Supposons que les données de votre fichier CSV enregistrent une perte chaque jour. Quelle serait la valeur demax_gain?
Dans la bouclefor, vous définissez d'abordmax_gain = DataPoint(None, 0), donc s'il n'y a pas de gains, la valeur finale demax_gain sera cet objetDataPoint vide. Cependant, la solutionreduce() renvoie la plus petite perte. Ce n'est pas ce que vous voulez et pourrait introduire un bug difficile à trouver.
C'est là queitertools peut vous aider. La fonctionitertools.filterfalse() prend deux arguments: une fonction qui renvoieTrue ouFalse (appeléepredicate) et uninputs itérable. Il renvoie un itérateur sur les éléments deinputs pour lesquels le prédicat renvoieFalse.
Voici un exemple simple:
>>> only_positives = it.filterfalse(lambda x: x <= 0, [0, 1, -1, 2, -2])
>>> list(only_positives)
[1, 2]Vous pouvez utiliserfilterfalse() pour filtrer les valeurs engains qui sont négatives ou nulles afin quereduce() ne fonctionne que sur des valeurs positives:
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, gains))Que se passe-t-il s'il n'y a jamais de gains? Considérer ce qui suit:
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]))
Traceback (most recent call last):
File "", line 1, in
TypeError: reduce() of empty sequence with no initial value Eh bien, ce n’est pas ce que vous voulez! Mais cela a du sens car l'itérateur renvoyé parfilterflase() est vide. Vous pouvez gérer lesTypeError en encapsulant l’appel dereduce() avectry...except, mais il existe un meilleur moyen.
La fonctionreduce() accepte un troisième argument facultatif pour une valeur initiale. Passer0 à ce troisième argument vous donne le comportement attendu:
>>>
>>> ft.reduce(max, it.filterfalse(lambda x: x <= 0, [-1, -2, -3]), 0)
0Appliquer ceci à l'exemple du S & P500:
zdp = DataPoint(None, 0) # zero DataPoint
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= 0, diffs), zdp)Génial! Vous l'avez fait fonctionner comme il se doit! Maintenant, trouver la perte maximale est facile:
max_loss = ft.reduce(min, it.filterfalse(lambda p: p > 0, gains), zdp)
print(max_loss) # DataPoint(date='2018-02-08', value=-20.47)Séquence de croissance la plus longue
Trouver la plus longue séquence de croissance de l'histoire du S & P500 équivaut à trouver le plus grand nombre de points de données positifs consécutifs dans la séquencegains. Les fonctionsitertools.takewhile() etitertools.dropwhile() sont parfaites pour cette situation.
La fonctiontakewhile() prend un prédicat et uninputs itérable comme arguments et renvoie un itérateur surinputs qui s'arrête à la première instance d'un élément pour lequel le prédicat renvoieFalse:
it.takewhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 0, 1, 2La fonctiondropwhile() fait exactement le contraire. Il renvoie un itérateur commençant au premier élément pour lequel le prédicat renvoieFalse:
it.dropwhile(lambda x: x < 3, [0, 1, 2, 3, 4]) # 3, 4Dans la fonction de générateur suivante,takewhile() etdropwhile() sont composés pour produire des tuples d'éléments positifs consécutifs d'une séquence:
def consecutive_positives(sequence, zero=0):
def _consecutives():
for itr in it.repeat(iter(sequence)):
yield tuple(it.takewhile(lambda p: p > zero,
it.dropwhile(lambda p: p <= zero, itr)))
return it.takewhile(lambda t: len(t), _consecutives())La fonctionconsecutive_positives() fonctionne carrepeat() continue de renvoyer un pointeur vers un itérateur sur l'argumentsequence, qui est partiellement consommé à chaque itération par l'appel àtuple() dans leyield déclaration.
Vous pouvez utiliserconsecutive_positives() pour obtenir un générateur qui produit des tuples de points de données positifs consécutifs engains:
growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0))Vous pouvez maintenant utiliserreduce() pour extraire la plus longue séquence de croissance:
longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y,
growth_streaks)En résumé, voici un script complet qui lira les données du fichierSP500.csv et affichera le gain / la perte maximum et la plus longue séquence de croissance:
from collections import namedtuple
import csv
from datetime import datetime
import itertools as it
import functools as ft
class DataPoint(namedtuple('DataPoint', ['date', 'value'])):
__slots__ = ()
def __le__(self, other):
return self.value <= other.value
def __lt__(self, other):
return self.value < other.value
def __gt__(self, other):
return self.value > other.value
def consecutive_positives(sequence, zero=0):
def _consecutives():
for itr in it.repeat(iter(sequence)):
yield tuple(it.takewhile(lambda p: p > zero,
it.dropwhile(lambda p: p <= zero, itr)))
return it.takewhile(lambda t: len(t), _consecutives())
def read_prices(csvfile, _strptime=datetime.strptime):
with open(csvfile) as infile:
reader = csv.DictReader(infile)
for row in reader:
yield DataPoint(date=_strptime(row['Date'], '%Y-%m-%d').date(),
value=float(row['Adj Close']))
# Read prices and calculate daily percent change.
prices = tuple(read_prices('SP500.csv'))
gains = tuple(DataPoint(day.date, 100*(day.value/prev_day.value - 1.))
for day, prev_day in zip(prices[1:], prices))
# Find maximum daily gain/loss.
zdp = DataPoint(None, 0) # zero DataPoint
max_gain = ft.reduce(max, it.filterfalse(lambda p: p <= zdp, gains))
max_loss = ft.reduce(min, it.filterfalse(lambda p: p > zdp, gains), zdp)
# Find longest growth streak.
growth_streaks = consecutive_positives(gains, zero=DataPoint(None, 0))
longest_streak = ft.reduce(lambda x, y: x if len(x) > len(y) else y,
growth_streaks)
# Display results.
print('Max gain: {1:.2f}% on {0}'.format(*max_gain))
print('Max loss: {1:.2f}% on {0}'.format(*max_loss))
print('Longest growth streak: {num_days} days ({first} to {last})'.format(
num_days=len(longest_streak),
first=longest_streak[0].date,
last=longest_streak[-1].date
))L'exécution du script ci-dessus produit la sortie suivante:
Max gain: 11.58% on 2008-10-13
Max loss: -20.47% on 1987-10-19
Longest growth streak: 14 days (1971-03-26 to 1971-04-15)Récapitulation de la section
Dans cette section, vous avez couvert beaucoup de terrain, mais vous n'avez vu que quelques fonctions deitertools. Examinons-les maintenant.
itertools.filterfalse Exemple
filterfalse(pred, iterable)Renvoie les éléments de séquence pour lesquels
pred(item)est faux. SipredestNone, renvoie les éléments qui sont faux.
>>>
>>> filterfalse(bool, [1, 0, 1, 0, 0])
0, 0, 0itertools.takewhile Exemple
takewhile(pred, iterable)Renvoie les entrées successives d'un itérable tant que
predest évalué à vrai pour chaque entrée.
>>>
>>> takewhile(bool, [1, 1, 1, 0, 0])
1, 1, 1itertools.dropwhile Exemple
dropwhile(pred, iterable)Supprimez les éléments de l'itérable tant que
pred(item)est vrai. Ensuite, renvoyez chaque élément jusqu'à ce que l'itérable soit épuisé.
>>>
>>> dropwhile(bool, [1, 1, 1, 0, 0, 1, 1, 0])
0, 0, 1, 1, 0Vous commencez vraiment à maîtriser tout ce truc deitertools! L'équipe de natation communautaire aimerait vous commander un petit projet.
Construire des équipes de relais à partir des données des nageurs
Dans cet exemple, vous lirez les données d'un fichier CSV contenant les heures des événements de natation pour une équipe de natation communautaire de toutes les compétitions de natation au cours d'une saison. Le but est de déterminer quels nageurs devraient faire partie des équipes de relais pour chaque coup la saison prochaine.
Chaque coup devrait avoir une équipe de relais «A» et «B» avec quatre nageurs chacun. L'équipe «A» devrait comprendre les quatre nageurs avec les meilleurs temps pour le coup et l'équipe «B» les nageurs avec les quatre meilleurs temps suivants.
Les données de cet exemple peuvent être trouvéeshere. Si vous voulez suivre, téléchargez-le dans votre répertoire de travail actuel et enregistrez-le sousswimmers.csv.
Voici les 10 premières lignes deswimmers.csv:
$ head -n 10 swimmers.csv
Event,Name,Stroke,Time1,Time2,Time3
0,Emma,freestyle,00:50:313667,00:50:875398,00:50:646837
0,Emma,backstroke,00:56:720191,00:56:431243,00:56:941068
0,Emma,butterfly,00:41:927947,00:42:062812,00:42:007531
0,Emma,breaststroke,00:59:825463,00:59:397469,00:59:385919
0,Olivia,freestyle,00:45:566228,00:46:066985,00:46:044389
0,Olivia,backstroke,00:53:984872,00:54:575110,00:54:932723
0,Olivia,butterfly,01:12:548582,01:12:722369,01:13:105429
0,Olivia,breaststroke,00:49:230921,00:49:604561,00:49:120964
0,Sophia,freestyle,00:55:209625,00:54:790225,00:55:351528Les trois temps de chaque ligne représentent les temps enregistrés par trois chronomètres différents, et sont donnés au formatMM:SS:mmmmmm (minutes, secondes, microsecondes). Le temps accepté pour un événement est lemedian de ces trois temps,not la moyenne.
Commençons par créer une sous-classeEvent de l'objetnamedtuple, comme nous l'avons fait dans lesSP500 example:
from collections import namedtuple
class Event(namedtuple('Event', ['stroke', 'name', 'time'])):
__slots__ = ()
def __lt__(self, other):
return self.time < other.timeLa propriété.stroke stocke le nom du coup dans l'événement,.name stocke le nom du nageur et.time enregistre l'heure acceptée pour l'événement. La méthode dunder de.__lt__() permettra àmin() d'être appelé sur une séquence d'objetsEvent.
Pour lire les données du CSV dans un tuple d'objetsEvent, vous pouvez utiliser l'objetcsv.DictReader:
import csv
import datetime
import statistics
def read_events(csvfile, _strptime=datetime.datetime.strptime):
def _median(times):
return statistics.median((_strptime(time, '%M:%S:%f').time()
for time in row['Times']))
fieldnames = ['Event', 'Name', 'Stroke']
with open(csvfile) as infile:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
next(reader) # skip header
for row in reader:
yield Event(row['Stroke'], row['Name'], _median(row['Times']))
events = tuple(read_events('swimmers.csv'))Le générateurread_events() lit chaque ligne du fichierswimmers.csv dans un objetOrderedDict dans la ligne suivante:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')En affectant le champ'Times' àrestkey, les colonnes «Time1», «Time2» et «Time3» de chaque ligne du fichier CSV seront stockées dans une liste sur les'Times' clé desOrderedDict renvoyés parcsv.DictReader.
Par exemple, la première ligne du fichier (à l'exclusion de la ligne d'en-tête) est lue dans l'objet suivant:
OrderedDict([('Event', '0'),
('Name', 'Emma'),
('Stroke', 'freestyle'),
('Times', ['00:50:313667', '00:50:875398', '00:50:646837'])])Ensuite,read_events() renvoie un objetEvent avec le coup, le nom du nageur et le temps médian (sous forme dedatetime.time object) renvoyé par la fonction_median(), qui appellestatistics.median() sur la liste des heures de la ligne.
Puisque chaque élément de la liste des heures est lu comme une chaîne parcsv.DictReader(),_median() utilise lesdatetime.datetime.strptime() classmethod pour instancier un objet temporel à partir de chaque chaîne.
Enfin, un tuple d'objetsEvent est créé:
events = tuple(read_events('swimmers.csv'))Les cinq premiers éléments deevents ressemblent à ceci:
>>>
>>> events[:5]
(Event(stroke='freestyle', name='Emma', time=datetime.time(0, 0, 50, 646837)),
Event(stroke='backstroke', name='Emma', time=datetime.time(0, 0, 56, 720191)),
Event(stroke='butterfly', name='Emma', time=datetime.time(0, 0, 42, 7531)),
Event(stroke='breaststroke', name='Emma', time=datetime.time(0, 0, 59, 397469)),
Event(stroke='freestyle', name='Olivia', time=datetime.time(0, 0, 46, 44389)))Maintenant que vous avez les données en mémoire, que faites-vous avec? Voici le plan d'attaque:
-
Regroupez les événements par trait.
-
Pour chaque coup:
-
Regroupez ses épreuves par nom de nageur et déterminez le meilleur temps pour chaque nageur.
-
Commandez les nageurs par meilleur temps.
-
Les quatre premiers nageurs font partie de l'équipe «A» pour le coup, et les quatre suivants font partie de l'équipe «B».
-
La fonctionitertools.groupby() permet de regrouper des objets dans un itérable en un clin d'œil. Il faut uninputs itérable et unkey pour regrouper par, et retourne un objet contenant des itérateurs sur les éléments deinputs regroupés par la clé.
Voici un exemple simple degroupby():
>>>
>>> data = [{'name': 'Alan', 'age': 34},
... {'name': 'Catherine', 'age': 34},
... {'name': 'Betsy', 'age': 29},
... {'name': 'David', 'age': 33}]
...
>>> grouped_data = it.groupby(data, key=lambda x: x['age'])
>>> for key, grp in grouped_data:
... print('{}: {}'.format(key, list(grp)))
...
34: [{'name': 'Alan', 'age': 34}, {'name': 'Betsy', 'age': 34}]
29: [{'name': 'Catherine', 'age': 29}]
33: [{'name': 'David', 'age': 33}]Si aucune clé n'est spécifiée,groupby() utilise par défaut le regroupement par «identité», c'est-à-dire l'agrégation d'éléments identiques dans l'itérable:
>>>
>>> for key, grp in it.groupby([1, 1, 2, 2, 2, 3]:
... print('{}: {}'.format(key, list(grp)))
...
1: [1, 1]
2: [2, 2, 2]
3: [3]L'objet renvoyé pargroupby() est un peu comme un dictionnaire dans le sens où les itérateurs renvoyés sont associés à une clé. Cependant, contrairement à un dictionnaire, il ne vous permettra pas d'accéder à ses valeurs par nom de clé:
>>> grouped_data[1]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'itertools.groupby' object is not subscriptable En fait,groupby() returns an iterator over tuples whose first components are keys and second components are iterators over the grouped data:
>>>
>>> grouped_data = it.groupby([1, 1, 2, 2, 2, 3])
>>> list(grouped_data)
[(1, ),
(2, ),
(3, )] Une chose à garder à l'esprit avecgroupby() est que ce n'est pas aussi intelligent que vous pourriez le souhaiter. Au fur et à mesure quegroupby() parcourt les données, il agrège les éléments jusqu'à ce qu'un élément avec une clé différente soit rencontré, auquel point il démarre un nouveau groupe:
>>>
>>> grouped_data = it.groupby([1, 2, 1, 2, 3, 2])
>>> for key, grp in grouped_data:
... print('{}: {}'.format(key, list(grp)))
...
1: [1]
2: [2]
1: [1]
2: [2]
3: [3]
2: [2]Comparez cela à, par exemple, la commande SQLGROUP BY, qui regroupe les éléments quel que soit leur ordre d'apparition.
Lorsque vous travaillez avecgroupby(), vous devez trier vos données sur la même clé que vous souhaitez regrouper. Sinon, vous risquez d'obtenir des résultats inattendus. Ceci est si courant qu'il est utile d'écrire une fonction utilitaire pour s'en occuper à votre place:
def sort_and_group(iterable, key=None):
"""Group sorted `iterable` on `key`."""
return it.groupby(sorted(iterable, key=key), key=key)Pour revenir à l'exemple des nageurs, la première chose à faire est de créer une boucle for qui itère sur les données du tupleevents regroupées par trait:
for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke):Ensuite, vous devez regrouper l'itérateurevts par nom de nageur à l'intérieur de la bouclefor ci-dessus:
events_by_name = sort_and_group(evts, key=lambda evt: evt.name)Pour calculer le meilleur temps pour chaque nageur enevents_by_name, vous pouvez appelermin() sur les épreuves de ce groupe de nageurs. (Cela fonctionne car vous avez implémenté la méthode dunder.__lt__() dans la classeEvents.)
best_times = (min(evt) for _, evt in events_by_name)Notez que le générateurbest_times donne des objetsEvent contenant le meilleur temps de nage pour chaque nageur. Pour constituer les équipes de relais, vous devez trier lesbest_times par heure et regrouper le résultat en groupes de quatre. Pour agréger les résultats, vous pouvez utiliser la fonctiongrouper() de la sectionThe grouper() recipe et utiliserislice() pour saisir les deux premiers groupes.
sorted_by_time = sorted(best_times, key=lambda evt: evt.time)
teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2))Maintenantteams est un itérateur sur exactement deux tuples représentant l'équipe «A» et «B» pour le trait. Le premier composant de chaque tuple est la lettre «A» ou «B», et le second composant est un itérateur sur les objetsEvent contenant les nageurs de l'équipe. Vous pouvez maintenant imprimer les résultats:
for team, swimmers in teams:
print('{stroke} {team}: {names}'.format(
stroke=stroke.capitalize(),
team=team,
names=', '.join(swimmer.name for swimmer in swimmers)
))Voici le script complet:
from collections import namedtuple
import csv
import datetime
import itertools as it
import statistics
class Event(namedtuple('Event', ['stroke', 'name', 'time'])):
__slots__ = ()
def __lt__(self, other):
return self.time < other.time
def sort_and_group(iterable, key=None):
return it.groupby(sorted(iterable, key=key), key=key)
def grouper(iterable, n, fillvalue=None):
iters = [iter(iterable)] * n
return it.zip_longest(*iters, fillvalue=fillvalue)
def read_events(csvfile, _strptime=datetime.datetime.strptime):
def _median(times):
return statistics.median((_strptime(time, '%M:%S:%f').time()
for time in row['Times']))
fieldnames = ['Event', 'Name', 'Stroke']
with open(csvfile) as infile:
reader = csv.DictReader(infile, fieldnames=fieldnames, restkey='Times')
next(reader) # Skip header.
for row in reader:
yield Event(row['Stroke'], row['Name'], _median(row['Times']))
events = tuple(read_events('swimmers.csv'))
for stroke, evts in sort_and_group(events, key=lambda evt: evt.stroke):
events_by_name = sort_and_group(evts, key=lambda evt: evt.name)
best_times = (min(evt) for _, evt in events_by_name)
sorted_by_time = sorted(best_times, key=lambda evt: evt.time)
teams = zip(('A', 'B'), it.islice(grouper(sorted_by_time, 4), 2))
for team, swimmers in teams:
print('{stroke} {team}: {names}'.format(
stroke=stroke.capitalize(),
team=team,
names=', '.join(swimmer.name for swimmer in swimmers)
))Si vous exécutez le code ci-dessus, vous obtiendrez le résultat suivant:
Backstroke A: Sophia, Grace, Penelope, Addison
Backstroke B: Elizabeth, Audrey, Emily, Aria
Breaststroke A: Samantha, Avery, Layla, Zoe
Breaststroke B: Lillian, Aria, Ava, Alexa
Butterfly A: Audrey, Leah, Layla, Samantha
Butterfly B: Alexa, Zoey, Emma, Madison
Freestyle A: Aubrey, Emma, Olivia, Evelyn
Freestyle B: Elizabeth, Zoe, Addison, MadisonOù aller en partant d'ici
Si vous êtes arrivé jusqu'ici, félicitations! J'espère que vous avez apprécié le voyage.
itertools est un module puissant dans la bibliothèque standard Python, et un outil essentiel à avoir dans votre boîte à outils. Avec lui, vous pouvez écrire du code plus rapide et plus efficace en mémoire qui est souvent plus simple et plus facile à lire (bien que ce ne soit pas toujours le cas, comme vous l'avez vu dans la section sursecond order recurrence relations).
Si quelque chose, cependant,itertools témoigne de la puissance des itérateurs et deslazy evaluation. Même si vous avez vu de nombreuses techniques, cet article ne fait qu'effleurer la surface.
Donc je suppose que cela signifie que votre voyage ne fait que commencer.
Free Bonus:Click here to get our itertools cheat sheet qui résume les techniques illustrées dans ce didacticiel.
En fait, cet article a ignoré deux fonctionsitertools:starmap() etcompress(). D'après mon expérience, ce sont deux des fonctionsitertools les moins utilisées, mais je vous conseille vivement de lire leurs documents et d'expérimenter vos propres cas d'utilisation!
Voici quelques endroits où vous pouvez trouver plus d'exemples deitertools en action (merci à Brad Solomon pour ces belles suggestions):
Enfin, pour encore plus d'outils de construction d'itérateurs, jetez un œil àmore-itertools.
Avez-vous des recettes / cas d'utilisation préférés deitertools? Nous serions ravis d'en entendre parler dans les commentaires!
Nous remercions nos lecteurs Putcher et Samir Aghayev d'avoir signalé quelques erreurs dans la version originale de cet article.