Tracé d'histogramme Python: NumPy, Matplotlib, Pandas & Seaborn
Dans ce didacticiel, vous serez équipé pour créer des tracés d'histogramme Python de qualité production, prêts pour la présentation, avec une gamme de choix et de fonctionnalités.
Si vous avez une introduction aux connaissances intermédiaires en Python et aux statistiques, vous pouvez utiliser cet article comme un guichet unique pour créer et tracer des histogrammes en Python à l'aide des bibliothèques de sa pile scientifique, y compris NumPy, Matplotlib, Pandas et Seaborn.
Un histogramme est un excellent outil pour évaluer rapidement unprobability distribution qui est intuitivement compris par presque tous les publics. Python offre une poignée d'options différentes pour construire et tracer des histogrammes. La plupart des gens connaissent un histogramme par sa représentation graphique, qui est similaire à un graphique à barres:
Cet article vous guidera à travers la création de tracés comme celui ci-dessus ainsi que ceux plus complexes. Voici ce que vous allez couvrir:
-
Construire des histogrammes en Python pur, sans utiliser de bibliothèques tierces
-
Construire des histogrammes avec NumPy pour résumer les données sous-jacentes
-
Tracer l'histogramme résultant avec Matplotlib, Pandas et Seaborn
Free Bonus: Manque de temps? Click here to get access to a free two-page Python histograms cheat sheet qui résume les techniques expliquées dans ce didacticiel.
Histogrammes en Pure Python
Lorsque vous vous préparez à tracer un histogramme, il est plus simple de ne pas penser en termes de bacs, mais plutôt de signaler le nombre de fois que chaque valeur apparaît (un tableau des fréquences). Un Pythondictionary est bien adapté pour cette tâche:
>>>
>>> # Need not be sorted, necessarily
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> def count_elements(seq) -> dict:
... """Tally elements from `seq`."""
... hist = {}
... for i in seq:
... hist[i] = hist.get(i, 0) + 1
... return hist
>>> counted = count_elements(a)
>>> counted
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}count_elements() renvoie un dictionnaire avec des éléments uniques de la séquence sous forme de clés et leurs fréquences (comptage) sous forme de valeurs. Dans la boucle surseq,hist[i] = hist.get(i, 0) + 1 dit: "pour chaque élément de la séquence, incrémentez sa valeur correspondante enhist de 1."
En fait, c'est précisément ce qui est fait par la classecollections.Counter de la bibliothèque standard de Python, quihttps://github.com/python/cpython/blob/7f1bcda9bc3c04100cb047373732db0eba00e581/Lib/collections/init.py # L466 [sous-classes] un dictionnaire Python et remplace son.update()méthode s:
>>>
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})Vous pouvez confirmer que votre fonction artisanale fait pratiquement la même chose quecollections.Counter en testant l'égalité entre les deux:
>>>
>>> recounted.items() == counted.items()
TrueTechnical Detail: le mappage decount_elements() ci-dessus est par défaut unC function plus optimisé s'il est disponible. Dans la fonction Pythoncount_elements(), une micro-optimisation que vous pourriez faire est de déclarerget = hist.get avant la boucle for. Cela lierait une méthode à une variable pour des appels plus rapides dans la boucle.
Il peut être utile de créer des fonctions simplifiées à partir de zéro dans un premier temps pour comprendre des fonctions plus complexes. Réinventons encore un peu la roue avec un histogramme ASCII qui tire parti desoutput formatting de Python:
def ascii_histogram(seq) -> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
for k in sorted(counted):
print('{0:5d} {1}'.format(k, '+' * counted[k]))Cette fonction crée un tracé de fréquence trié où les décomptes sont représentés comme des totaux de symboles plus (+). L'appel desorted() sur un dictionnaire renvoie une liste triée de ses clés, puis vous accédez à la valeur correspondante pour chacune aveccounted[k]. Pour voir cela en action, vous pouvez créer un ensemble de données légèrement plus grand avec le modulerandom de Python:
>>>
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++Ici, vous simulez le prélèvement à partir devals avec des fréquences données parfreq (agenerator expression). Les données d'échantillon obtenues répètent chaque valeur devals un certain nombre de fois entre 5 et 15.
Note:random.seed() est utilisé pour amorcer ou initialiser le générateur de nombres pseudo-aléatoires sous-jacent (PRNG) utilisé parrandom. Cela peut ressembler à un oxymore, mais c'est une façon de rendre les données aléatoires reproductibles et déterministes. Autrement dit, si vous copiez le code ici tel quel, vous devriez obtenir exactement le même histogramme car le premier appel àrandom.randint() après l'amorçage du générateur produira des données «aléatoires» identiques en utilisant lesMersenne Twister.
Création à partir de la base: calculs d'histogramme dans NumPy
Jusqu'à présent, vous avez travaillé avec ce que l'on pourrait mieux appeler des «tables de fréquences». Mais mathématiquement, un histogramme est un mappage de bacs (intervalles) aux fréquences. Plus techniquement, il peut être utilisé pour approximer la fonction de densité de probabilité (PDF) de la variable sous-jacente.
En partant du «tableau des fréquences» ci-dessus, un véritable histogramme «classe» d'abord la plage de valeurs, puis compte le nombre de valeurs qui tombent dans chaque catégorie. C'est ce que fait la fonctionNumPy’shistogram(), et c'est la base pour d'autres fonctions que vous verrez ici plus tard dans les bibliothèques Python telles que Matplotlib et Pandas.
Prenons un échantillon de flottants tirés desLaplace distribution. Cette distribution a une queue plus grosse qu'une distribution normale et a deux paramètres descriptifs (emplacement et échelle):
>>>
>>> import numpy as np
>>> # `numpy.random` uses its own PRNG.
>>> np.random.seed(444)
>>> np.set_printoptions(precision=3)
>>> d = np.random.laplace(loc=15, scale=3, size=500)
>>> d[:5]
array([18.406, 18.087, 16.004, 16.221, 7.358])Dans ce cas, vous travaillez avec une distribution continue, et il ne serait pas très utile de comptabiliser chaque flottant indépendamment, jusqu'à la énième décimale. Au lieu de cela, vous pouvez regrouper ou «regrouper» les données et compter les observations qui tombent dans chaque groupe. L'histogramme est le nombre de valeurs résultant dans chaque bac:
>>>
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])Ce résultat peut ne pas être immédiatement intuitif. np.histogram() par défaut utilise 10 bins de taille égale et renvoie un tuple des comptages de fréquence et des bords de bin correspondants. Ce sont des bords dans le sens où il y aura un bord de bac de plus qu'il n'y a de membres de l'histogramme:
>>>
>>> hist.size, bin_edges.size
(10, 11)Technical Detail: tous sauf le dernier (le plus à droite) sont à moitié ouverts. Autrement dit, tous les bacs, sauf le dernier, sont [inclusifs, exclusifs] et le dernier bac est [inclusif, inclusif].
Une ventilation très condensée de la façon dont les bacs sont construitsby NumPy ressemble à ceci:
>>>
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23. ])Le cas ci-dessus a beaucoup de sens: 10 bacs également espacés sur une plage crête à crête de 23 signifie des intervalles de largeur 2,3.
À partir de là, la fonction délègue soit ànp.bincount() soit ànp.searchsorted(). bincount() lui-même peut être utilisé pour construire efficacement la «table de fréquences» avec laquelle vous avez commencé ici, avec la distinction que les valeurs avec aucune occurrence sont incluses:
>>>
>>> bcounts = np.bincount(a)
>>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}Note:hist ici utilise en réalité des bins de largeur 1.0 plutôt que des comptages «discrets». Par conséquent, cela ne fonctionne que pour compter les entiers, pas les flottants tels que[3.9, 4.1, 4.15].
Visualisation des histogrammes avec Matplotlib et Pandas
Maintenant que vous avez vu comment créer un histogramme à partir de zéro, voyons comment d'autres packages Python peuvent faire le travail pour vous. Matplotlib fournit la fonctionnalité pour visualiser les histogrammes Python prêts à l'emploi avec un wrapper polyvalent autour deshistogram() de NumPy:
import matplotlib.pyplot as plt
# An "interface" to matplotlib.axes.Axes.hist() method
n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa',
alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('My Very Own Histogram')
plt.text(23, 45, r'$\mu=15, b=3$')
maxfreq = n.max()
# Set a clean upper y-axis limit.
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)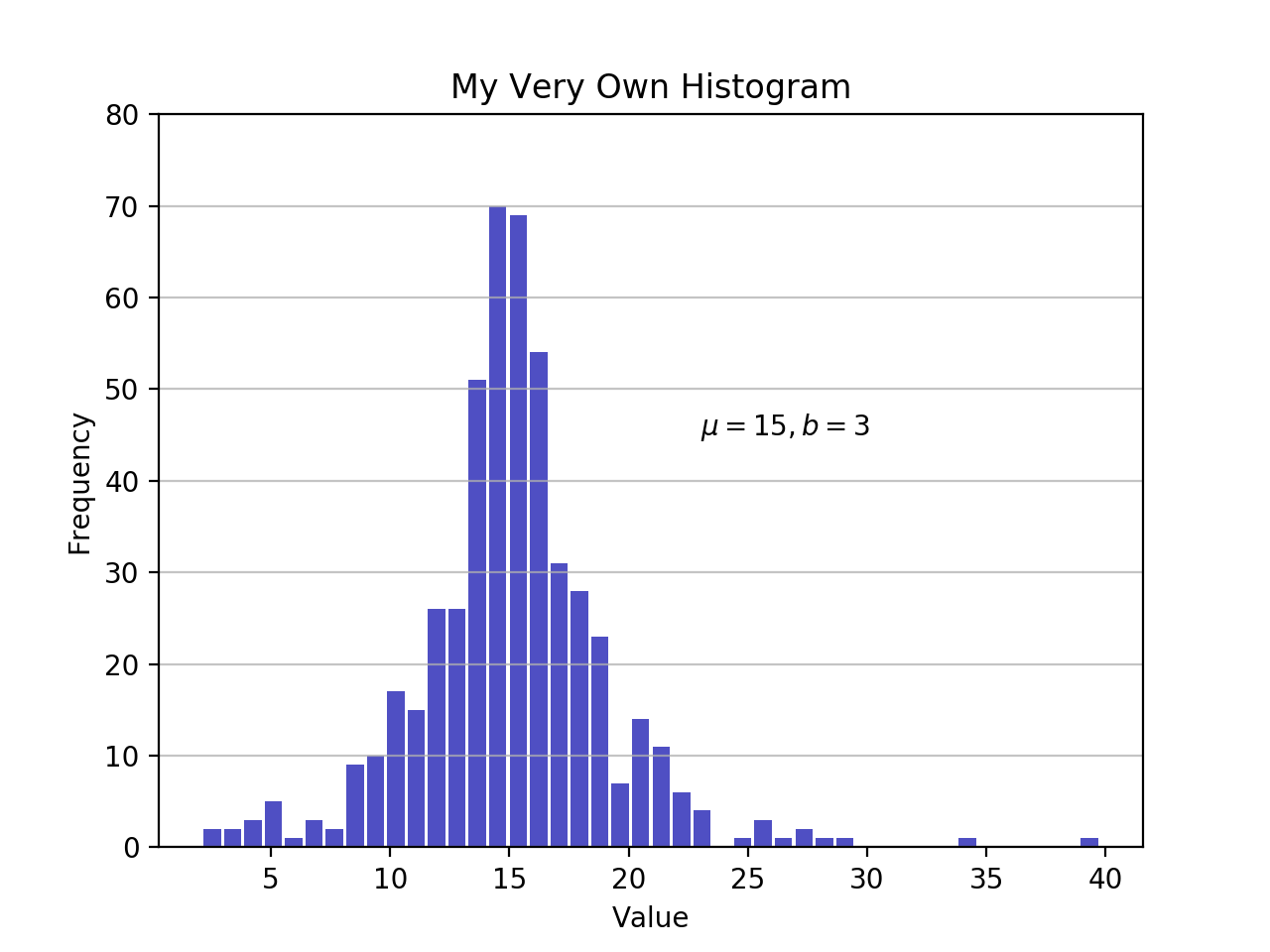
Comme défini précédemment, un tracé d'un histogramme utilise ses bords de bac sur l'axe des x et les fréquences correspondantes sur l'axe des y. Dans le graphique ci-dessus, la réussite debins='auto' choisit entre deux algorithmes pour estimer le nombre «idéal» de segments. À un niveau élevé, l'objectif de l'algorithme est de choisir une largeur de bac qui génère la représentation la plus fidèle des données. Pour en savoir plus sur ce sujet, qui peut devenir assez technique, consultezChoosing Histogram Bins de la documentation Astropy.
En restant dans la pile scientifique de Python,Series.histogram()uses matplotlib.pyplot.hist()de Pandas pour dessiner un histogramme Matplotlib de la série d'entrée:
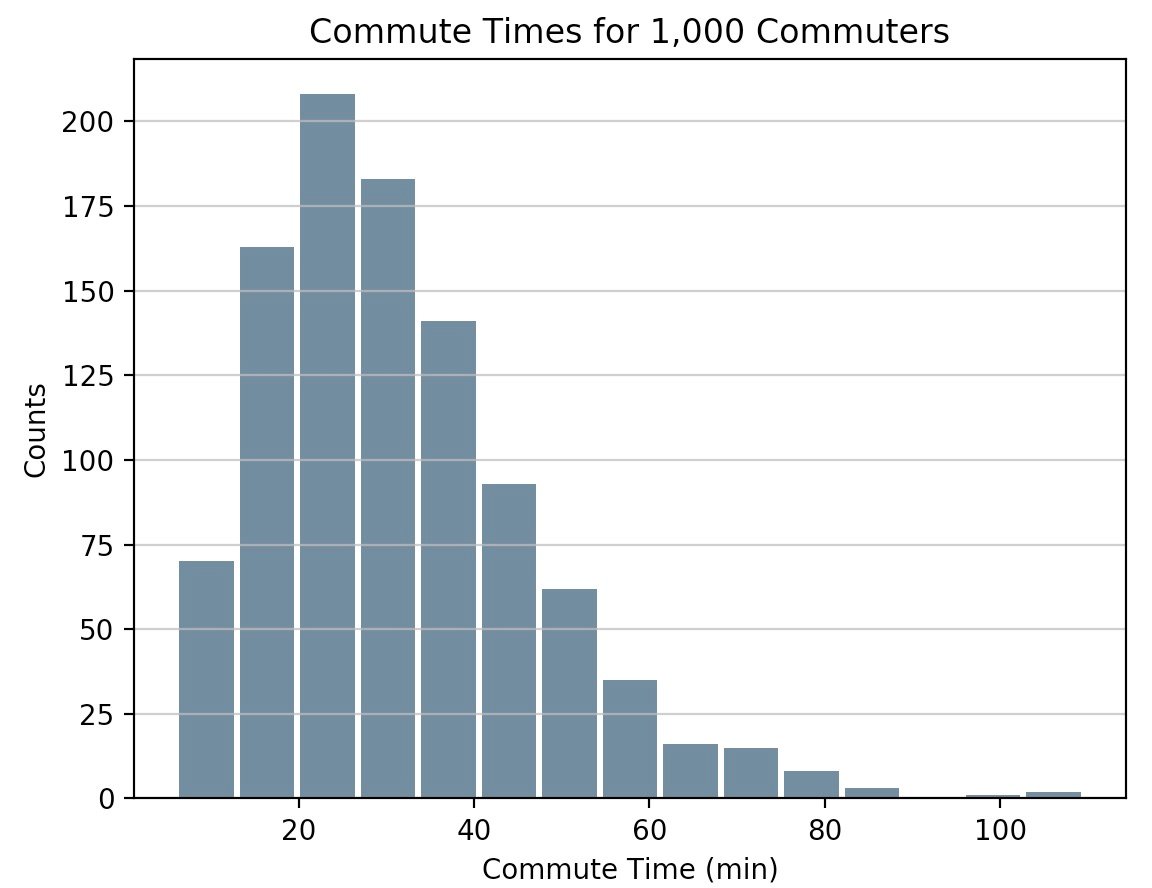
import pandas as pd
# Generate data on commute times.
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid=True, bins=20, rwidth=0.9,
color='#607c8e')
plt.title('Commute Times for 1,000 Commuters')
plt.xlabel('Counts')
plt.ylabel('Commute Time')
plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram() est similaire mais produit un histogramme pour chaque colonne de données dans le DataFrame.
Tracer une estimation de la densité du noyau (KDE)
Dans ce didacticiel, vous avez travaillé avec des échantillons, statistiquement parlant. Que les données soient discrètes ou continues, elles sont supposées provenir d'une population dont la distribution vraie et exacte est décrite par quelques paramètres seulement.
Une estimation de la densité du noyau (KDE) est un moyen d'estimer la fonction de densité de probabilité (PDF) de la variable aléatoire qui «sous-tend» notre échantillon. KDE est un moyen de lissage des données.
En utilisant la bibliothèque Pandas, vous pouvez créer et superposer des graphiques de densité à l'aide deplot.kde(), qui est disponible pour les objetsSeries etDataFrame. Mais d'abord, générons deux échantillons de données distincts pour comparaison:
>>>
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94Maintenant, pour tracer chaque histogramme sur les mêmes axes Matplotlib:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')
Ces méthodes tirent parti desgaussian_kde() de SciPy, ce qui donne un PDF plus lisse.
Si vous regardez de plus près cette fonction, vous pouvez voir à quel point elle se rapproche du «vrai» PDF pour un échantillon relativement petit de 1 000 points de données. Ci-dessous, vous pouvez d'abord construire la distribution «analytique» avecscipy.stats.norm(). Il s'agit d'une instance de classe qui encapsule la distribution normale standard statistique, ses moments et ses fonctions descriptives. Son PDF est «exact» dans le sens où il est défini précisément commenorm.pdf(x) = exp(-x**2/2) / sqrt(2*pi).
À partir de là, vous pouvez prendre un échantillon aléatoire de 1000 points de données de cette distribution, puis tenter de revenir à une estimation du PDF avecscipy.stats.gaussian_kde():
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)
Il s'agit d'un plus gros morceau de code, alors prenons une seconde pour toucher quelques lignes clés:
-
Les
statssubpackage de SciPy vous permettent de créer des objets Python qui représentent des distributions analytiques à partir desquelles vous pouvez échantillonner pour créer des données réelles. Doncdist = stats.norm()représente une variable aléatoire continue normale, et vous générez des nombres aléatoires à partir de celle-ci avecdist.rvs(). -
Pour évaluer à la fois le PDF analytique et le KDE gaussien, vous avez besoin d'un tableau
xde quantiles (écarts types au-dessus / en dessous de la moyenne, pour une distribution normale).stats.gaussian_kde()représente un PDF estimé que vous devez évaluer sur un tableau pour produire quelque chose de visuellement significatif dans ce cas. -
La dernière ligne contient quelquesLaTex, qui s'intègrent bien avec Matplotlib.
Une alternative de fantaisie avec Seaborn
Apportons un package Python supplémentaire dans le mix. Seaborn a une fonctiondisplot() qui trace l'histogramme et KDE pour une distribution univariée en une seule étape. Utilisation du tableau NumPyd d'ealier:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)
L'appel ci-dessus produit un KDE. Il existe également une option pour adapter une distribution spécifique aux données. Ceci est différent d'un KDE et consiste en une estimation de paramètre pour des données génériques et un nom de distribution spécifié:
sns.distplot(d, fit=stats.laplace, kde=False)
Encore une fois, notez la légère différence. Dans le premier cas, vous estimez un PDF inconnu; dans la seconde, vous prenez une distribution connue et trouvez les paramètres qui la décrivent le mieux compte tenu des données empiriques.
Autres outils dans Pandas
En plus de ses outils de traçage, Pandas propose également une méthode.value_counts() pratique qui calcule un histogramme de valeurs non nulles en PandasSeries:
>>>
>>> import pandas as pd
>>> data = np.random.choice(np.arange(10), size=10000,
... p=np.linspace(1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
9 1831
8 1624
7 1423
6 1323
5 1089
4 888
3 770
2 535
1 347
0 170
dtype: int64
>>> s.value_counts(normalize=True).head()
9 0.1831
8 0.1624
7 0.1423
6 0.1323
5 0.1089
dtype: float64Ailleurs,pandas.cut() est un moyen pratique de regrouper les valeurs dans des intervalles arbitraires. Supposons que vous disposiez de données sur l'âge des individus et que vous souhaitiez les regrouper de manière raisonnable:
>>>
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adultCe qui est bien, c’est que ces deux opérations sont en fin de compteutilize Cython code qui les rendent compétitives en termes de vitesse tout en conservant leur flexibilité.
Bon, alors lequel dois-je utiliser?
À ce stade, vous avez vu plus d'une poignée de fonctions et de méthodes parmi lesquelles choisir pour tracer un histogramme Python. Comment se comparent-ils? Bref, il n'y a pas de «taille unique». Voici un récapitulatif des fonctions et méthodes que vous avez couvertes jusqu'à présent, qui concernent toutes la décomposition et la représentation des distributions en Python:
| Vous avez / voulez | Pensez à utiliser | Remarques) |
|---|---|---|
Des données entières épurées hébergées dans une structure de données telle qu'une liste, un tuple ou un ensemble, et vous souhaitez créer un histogramme Python sans importer de bibliothèques tierces. |
|
Il s’agit d’un tableau de fréquences, il n’utilise donc pas le concept de regroupement comme le fait un «vrai» histogramme. |
Grand tableau de données, et vous souhaitez calculer l'histogramme «mathématique» qui représente les classes et les fréquences correspondantes. |
Les |
Pour en savoir plus, consultez |
Données tabulaires dans l’objet |
Méthodes Pandas telles que |
Découvrez les Pandasvisualization docs pour vous inspirer. |
Créez un tracé hautement personnalisable et affiné à partir de n'importe quelle structure de données. |
|
Matplotlib, et en particulier sesobject-oriented framework, est idéal pour affiner les détails d'un histogramme. Cette interface peut prendre un peu de temps à maîtriser, mais vous permet finalement d'être très précis dans la présentation de toute visualisation. |
Conception et intégration prédéfinies. |
Seaborn's |
Essentiellement un «wrapper autour d'un wrapper» qui exploite un histogramme Matplotlib en interne, qui à son tour utilise NumPy. |
Free Bonus: Manque de temps? Click here to get access to a free two-page Python histograms cheat sheet qui résume les techniques expliquées dans ce didacticiel.
Vous pouvez également trouver les extraits de code de cet article ensemble dans unscript sur la page des matériaux Real Python.
Avec cela, bonne chance pour créer des histogrammes dans la nature. J'espère que l'un des outils ci-dessus répondra à vos besoins. Quoi que vous fassiez, seulementdon’t use a pie chart.