Accélérez votre programme Python avec la concurrence
Si vous avez beaucoup entendu parler de + asyncio + être ajouté à Python, mais vous êtes curieux de savoir comment il se compare à d’autres méthodes de concurrence ou vous demandez ce qu’est la concurrence et comment cela pourrait accélérer votre programme, vous êtes au bon endroit.
*Dans cet article, vous apprendrez ce qui suit:*
*Qu'est-ce que* l'accès simultané * *Qu'est-ce que le* parallélisme *? *Comparaison de certaines des* méthodes d'accès simultané de Python, y compris `+ threading +`, `+ asyncio +` et `+ multiprocessing +` * *Quand utiliser la simultanéité* dans votre programme et quel module utiliser
Cet article suppose que vous avez une compréhension de base de Python et que vous utilisez au moins la version 3.6 pour exécuter les exemples. Vous pouvez télécharger les exemples à partir du Real Python GitHub repo.
*Bonus gratuit:* lien: [5 réflexions sur la maîtrise de Python], un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour faire passer vos compétences Python au niveau supérieur.
*__ Répondez au questionnaire:* Testez vos connaissances avec notre quiz interactif "Python Concurrency". À la fin, vous recevrez un score afin que vous puissiez suivre vos progrès d'apprentissage au fil du temps:
lien:/quiz/python-concurrency/[Participez au quiz »]
Qu’est-ce que la concurrence?
La définition du dictionnaire de la simultanéité est occurrence simultanée. En Python, les choses qui se produisent simultanément sont appelées par des noms différents (thread, tâche, processus) mais à un niveau élevé, elles se réfèrent toutes à une séquence d’instructions qui s’exécutent dans l’ordre.
J’aime les considérer comme des courants de pensée différents. Chacun peut être arrêté à certains points, et le processeur ou le cerveau qui les traite peut passer à un autre. L’état de chacun est enregistré afin qu’il puisse être redémarré là où il a été interrompu.
Vous vous demandez peut-être pourquoi Python utilise des mots différents pour le même concept. Il s’avère que les threads, les tâches et les processus ne sont identiques que si vous les visualisez à un niveau élevé. Une fois que vous commencez à creuser dans les détails, ils représentent tous des choses légèrement différentes. Vous verrez de plus en plus comment ils sont différents au fur et à mesure que vous progressez dans les exemples.
Parlons maintenant de la partie simultanée de cette définition. Vous devez être un peu prudent car, lorsque vous descendez dans les détails, seul + multiprocessing + gère réellement ces courants de pensée littéralement en même temps. + Threading + et + asyncio + s’exécutent tous les deux sur un seul processeur et ne s’exécutent donc qu’un par un. Ils trouvent simplement intelligemment des façons de se relayer pour accélérer le processus global. Même s’ils n’exécutent pas différents courants de pensée simultanément, nous appelons toujours cette concurrence.
La façon dont les threads ou les tâches se relaient est la grande différence entre + threading + et + asyncio +. Dans + threading +, le système d’exploitation connaît réellement chaque thread et peut l’interrompre à tout moment pour commencer à exécuter un autre thread. Cela s’appelle pre-emptive multitasking car le système d’exploitation peut préempter votre thread pour effectuer le changement.
Le multitâche préventif est pratique dans la mesure où le code dans le thread n’a rien à faire pour effectuer le changement. Cela peut aussi être difficile à cause de cette phrase «à tout moment». Ce changement peut se produire au milieu d’une seule instruction Python, même triviale comme + x = x + 1 +.
+ Asyncio +, d’autre part, utilise cooperative multitasking. Les tâches doivent coopérer en annonçant quand elles sont prêtes à être retirées. Cela signifie que le code de la tâche doit légèrement changer pour que cela se produise.
L’avantage de faire ce travail supplémentaire à l’avance est que vous savez toujours où votre tâche sera échangée. Il ne sera pas échangé au milieu d’une instruction Python à moins que cette instruction ne soit marquée. Vous verrez plus tard comment cela peut simplifier certaines parties de votre conception.
Qu’est-ce que le parallélisme?
Jusqu’à présent, vous avez examiné la concurrence qui se produit sur un seul processeur. Qu’en est-il de tous les cœurs de processeur de votre nouveau portable cool? Comment pouvez-vous les utiliser? + multiprocessing + est la réponse.
Avec + multiprocessing +, Python crée de nouveaux processus. Un processus ici peut être considéré comme un programme presque complètement différent, bien que techniquement ils soient généralement définis comme une collection de ressources où les ressources incluent la mémoire, les descripteurs de fichiers et des choses comme ça. Une façon d’y penser est que chaque processus s’exécute dans son propre interpréteur Python.
Puisqu’il s’agit de processus différents, chacun de vos courants de pensée dans un programme de multitraitement peut fonctionner sur un noyau différent. Fonctionner sur un noyau différent signifie qu’ils peuvent réellement fonctionner en même temps, ce qui est fabuleux. Il y a quelques complications qui découlent de cette opération, mais Python fait un très bon travail pour les lisser la plupart du temps.
Maintenant que vous avez une idée de ce que sont la concurrence et le parallélisme, examinons leurs différences, puis nous verrons pourquoi elles peuvent être utiles:
| Concurrency Type | Switching Decision | Number of Processors |
|---|---|---|
Pre-emptive multitasking ( |
The operating system decides when to switch tasks external to Python. |
1 |
Cooperative multitasking ( |
The tasks decide when to give up control. |
1 |
Multiprocessing ( |
The processes all run at the same time on different processors. |
Many |
Chacun de ces types de simultanéité peut être utile. Voyons quels types de programmes ils peuvent vous aider à accélérer.
Quand la concurrence est-elle utile?
La concurrence peut faire une grande différence pour deux types de problèmes. Ceux-ci sont généralement appelés liés au processeur et liés aux E/S.
Les problèmes liés aux E/S ralentissent votre programme car il doit souvent attendre les entrées/sorties (E/S) d’une ressource externe. Ils surviennent fréquemment lorsque votre programme fonctionne avec des choses beaucoup plus lentes que votre CPU.
Des exemples de choses plus lentes que votre CPU sont légion, mais heureusement, votre programme n’interagit pas avec la plupart d’entre eux. Les éléments lents avec lesquels votre programme interagira le plus souvent sont le système de fichiers et les connexions réseau.
Voyons à quoi ça ressemble:
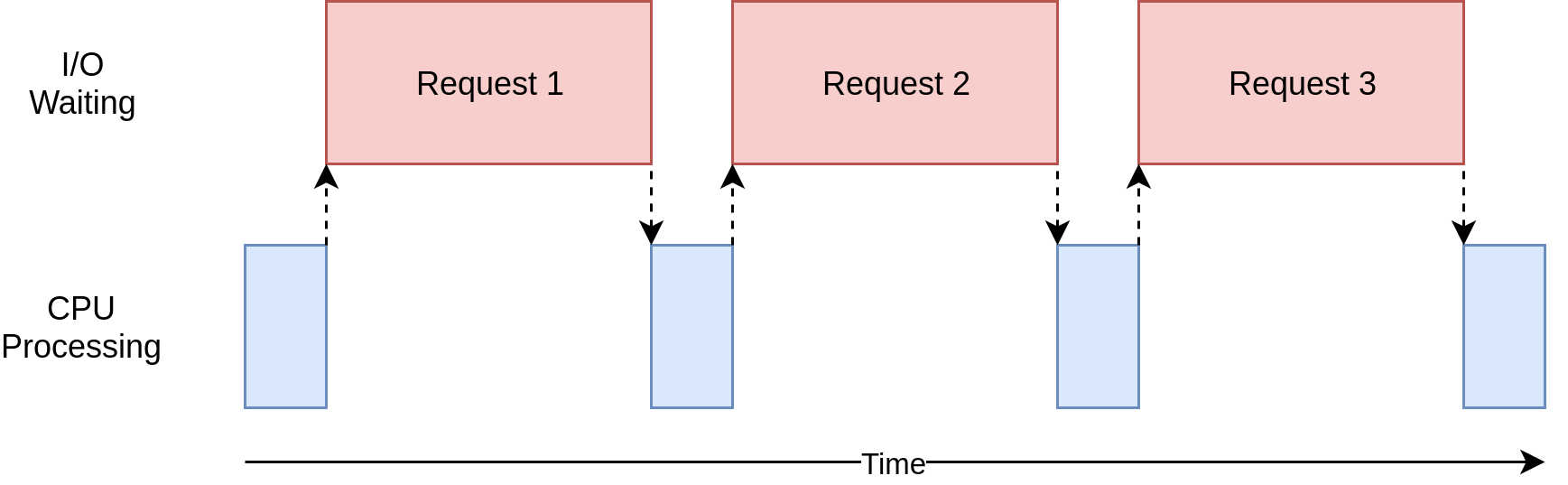
Dans le diagramme ci-dessus, les cases bleues indiquent l’heure à laquelle votre programme fonctionne et les cases rouges représentent le temps passé à attendre la fin d’une opération d’E/S. Ce diagramme n’est pas à l’échelle, car les demandes sur Internet peuvent prendre plusieurs ordres de grandeur plus longtemps que les instructions du processeur, de sorte que votre programme peut finir par passer la plupart de son temps à attendre. C’est ce que fait la plupart du temps votre navigateur.
D’un autre côté, il existe des classes de programmes qui effectuent des calculs importants sans parler au réseau ni accéder à un fichier. Ce sont les programmes liés au CPU, car la ressource limitant la vitesse de votre programme est le CPU, pas le réseau ou le système de fichiers.
Voici un diagramme correspondant pour un programme lié au processeur:
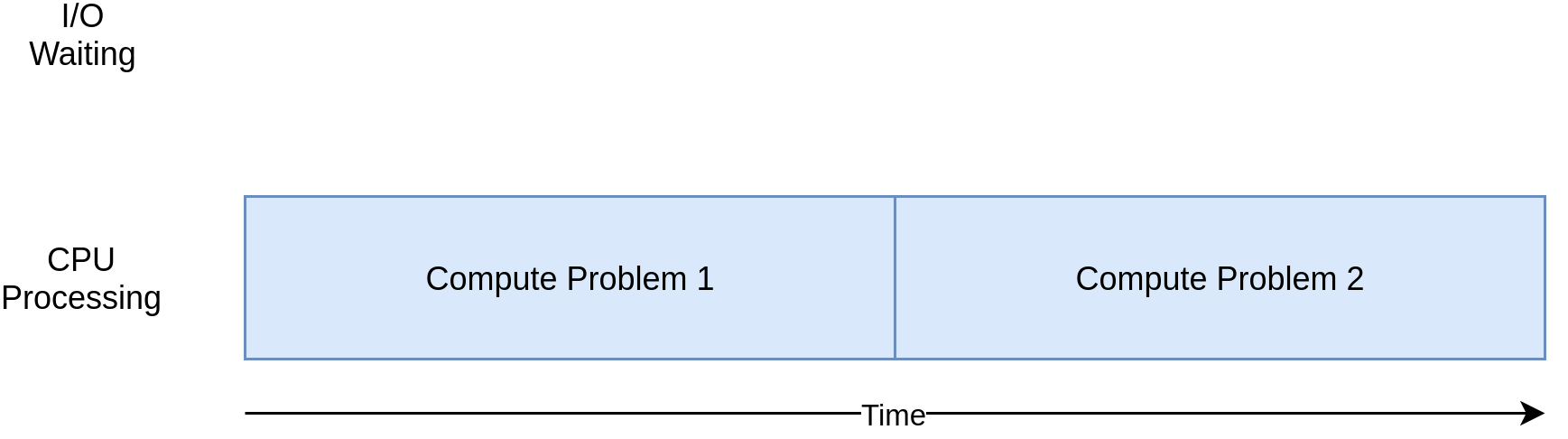
Au fur et à mesure que vous parcourez les exemples de la section suivante, vous verrez que différentes formes de concurrence fonctionnent mieux ou moins bien avec les programmes liés au processeur et aux E/S. L’ajout de simultanéité à votre programme ajoute du code supplémentaire et des complications. Vous devrez donc décider si l’accélération potentielle vaut l’effort supplémentaire. À la fin de cet article, vous devriez avoir suffisamment d’informations pour commencer à prendre cette décision.
Voici un bref résumé pour clarifier ce concept:
| I/O-Bound Process | CPU-Bound Process |
|---|---|
Your program spends most of its time talking to a slow device, like a network connection, a hard drive, or a printer. |
You program spends most of its time doing CPU operations. |
Speeding it up involves overlapping the times spent waiting for these devices. |
Speeding it up involves finding ways to do more computations in the same amount of time. |
Vous examinerez d’abord les programmes liés aux E/S. Ensuite, vous pourrez voir du code traitant des programmes liés au processeur.
Comment accélérer un programme lié aux E/S
Commençons par nous concentrer sur les programmes liés aux E/S et sur un problème commun: le téléchargement de contenu sur le réseau. Pour notre exemple, vous téléchargerez des pages Web à partir de quelques sites, mais il pourrait s’agir de n’importe quel trafic réseau. Il est tout simplement plus facile de visualiser et de configurer des pages Web.
Version synchrone
Nous allons commencer par une version non simultanée de cette tâche. Notez que ce programme nécessite le module + demandes +. Vous devez exécuter + pip install requests + avant de l’exécuter, probablement à l’aide d’un virtualenv. Cette version n’utilise pas du tout la concurrence:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Comme vous pouvez le voir, il s’agit d’un programme assez court. + download_site () + télécharge simplement le contenu à partir d’une URL et imprime la taille. Une petite chose à souligner est que nous utilisons un http://docs.python-requests.org/en/master/user/advanced/#session-objects [+ Session +] objet de + requests +.
Il est possible d’utiliser simplement + get () + à partir de + demandes + directement, mais la création d’un objet + Session + permet à + demandes + de faire quelques astuces de mise en réseau et d’accélérer vraiment les choses.
+ download_all_sites () + crée la + Session + puis parcourt la liste des sites, téléchargeant chacun à son tour. Enfin, il affiche la durée de ce processus afin que vous puissiez avoir la satisfaction de voir à quel point la concurrence nous a aidés dans les exemples suivants.
Le diagramme de traitement de ce programme ressemblera beaucoup au diagramme lié aux E/S dans la dernière section.
*Remarque:* Le trafic réseau dépend de nombreux facteurs qui peuvent varier d'une seconde à l'autre. J'ai vu le temps de ces tests doubler d'une exécution à l'autre en raison de problèmes de réseau.
*Pourquoi la version synchrone bascule*
La grande chose à propos de cette version de code est que, eh bien, c’est facile. Il était relativement facile à écrire et à déboguer. Il est également plus simple d’y penser. Il n’y a qu’un seul train de pensées qui le traverse, vous pouvez donc prédire quelle sera la prochaine étape et comment elle se comportera.
*Les problèmes avec la version synchrone*
Le gros problème ici est qu’il est relativement lent par rapport aux autres solutions que nous proposons. Voici un exemple de ce que la sortie finale a donné sur ma machine:
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 seconds*Remarque:* Vos résultats peuvent varier considérablement. Lors de l'exécution de ce script, j'ai vu les temps varier de 14,2 à 21,9 secondes. Pour cet article, j'ai pris le temps le plus rapide des trois runs. Les différences entre les méthodes seront toujours claires.
Cependant, être plus lent n’est pas toujours un gros problème. Si le programme que vous exécutez ne prend que 2 secondes avec une version synchrone et n’est exécuté que rarement, cela ne vaut probablement pas la peine d’ajouter une concurrence. Vous pouvez vous arrêter ici.
Et si votre programme est exécuté fréquemment? Et si cela prend des heures à fonctionner? Passons à la concurrence en réécrivant ce programme en utilisant + threading +.
+ enfilage + version
Comme vous l’avez probablement deviné, l’écriture d’un programme threadé demande plus d’efforts. Cependant, vous pourriez être surpris du peu d’efforts supplémentaires nécessaires pour les cas simples. Voici à quoi ressemble le même programme avec + threading +:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Lorsque vous ajoutez + threading +, la structure globale est la même et vous n’avez eu qu’à effectuer quelques modifications. + download_all_sites () + est passé de l’appel de la fonction une fois par site à une structure plus complexe.
Dans cette version, vous créez un + ThreadPoolExecutor +, ce qui semble compliqué. Décomposons cela: + ThreadPoolExecutor + = + Thread + + + Pool + + + Executor +.
Vous connaissez déjà la partie + Thread +. C’est juste un courant de pensée que nous avons mentionné plus tôt. La partie + Pool + est l’endroit où cela commence à devenir intéressant. Cet objet va créer un pool de threads, chacun pouvant s’exécuter simultanément. Enfin, le "+ Executor +" est la partie qui va contrôler comment et quand chacun des threads du pool s’exécutera. Il exécutera la demande dans le pool.
Utilement, la bibliothèque standard implémente + ThreadPoolExecutor + comme gestionnaire de contexte afin que vous puissiez utiliser la syntaxe + avec + pour gérer la création et la libération du pool de + Threads +.
Une fois que vous avez un + ThreadPoolExecutor +, vous pouvez utiliser sa méthode pratique + .map () +. Cette méthode exécute la fonction transmise sur chacun des sites de la liste. La grande partie est qu’il les exécute automatiquement simultanément en utilisant le pool de threads qu’il gère.
Ceux d’entre vous qui viennent d’autres langages, ou même de Python 2, se demandent probablement où sont les objets et fonctions habituels qui gèrent les détails auxquels vous êtes habitué lorsque vous traitez avec + threading +, des choses comme + Thread.start () + `, + Thread.join () + et + Queue + `.
Tout cela est toujours là, et vous pouvez les utiliser pour obtenir un contrôle précis de la façon dont vos threads sont exécutés. Mais, à partir de Python 3.2, la bibliothèque standard a ajouté une abstraction de niveau supérieur appelée + Executors + qui gère la plupart des détails pour vous si vous n’avez pas besoin de ce contrôle fin.
L’autre changement intéressant dans notre exemple est que chaque thread doit créer son propre objet + requests.Session () +. Lorsque vous consultez la documentation de + demandes +, ce n’est pas nécessairement facile à dire, mais en lisant this issue, il semble assez clair que vous avez besoin une session distincte pour chaque thread.
C’est l’un des problèmes intéressants et difficiles avec + threading +. Étant donné que le système d’exploitation contrôle le moment où votre tâche est interrompue et une autre tâche démarre, toutes les données partagées entre les threads doivent être protégées ou sécurisées pour les threads. Malheureusement, + requests.Session () + n’est pas thread-safe.
Il existe plusieurs stratégies pour rendre les accès aux données thread-safe en fonction de ce que sont les données et de la façon dont vous les utilisez. L’une d’elles consiste à utiliser des structures de données thread-safe comme + Queue + du module Python + queue +.
Ces objets utilisent des primitives de bas niveau comme https://docs.python.org/2/library/threading.html#lock-objects [+ threading.Lock +] pour garantir qu’un seul thread peut accéder à un bloc de code ou un peu de mémoire en même temps. Vous utilisez cette stratégie indirectement au moyen de l’objet + ThreadPoolExecutor +.
Une autre stratégie à utiliser ici est quelque chose appelé stockage local de threads. + Threading.local () + crée un objet qui ressemble à un global mais qui est spécifique à chaque thread individuel. Dans votre exemple, cela se fait avec + threadLocal + et + get_session () +:
threadLocal = threading.local()
def get_session():
if not hasattr(threadLocal, "session"):
threadLocal.session = requests.Session()
return threadLocal.session+ ThreadLocal + est dans le module + threading + pour résoudre spécifiquement ce problème. Cela semble un peu étrange, mais vous ne voulez créer qu’un seul de ces objets, pas un pour chaque thread. L’objet lui-même se charge de séparer les accès de différents threads à différentes données.
Lorsque + get_session () + est appelé, la + session + qu’il recherche est spécifique au thread particulier sur lequel il s’exécute. Ainsi, chaque thread créera une seule session la première fois qu’il appellera + get_session () +, puis utilisera simplement cette session à chaque appel suivant tout au long de sa durée de vie.
Enfin, une note rapide sur le choix du nombre de threads. Vous pouvez voir que l’exemple de code utilise 5 threads. N’hésitez pas à jouer avec ce numéro et à voir comment le temps global change. Vous pourriez vous attendre à avoir un thread par téléchargement, mais ce n’est pas le cas sur mon système. J’ai trouvé les résultats les plus rapides entre 5 et 10 threads. Si vous allez plus haut que cela, la surcharge supplémentaire de création et de destruction des threads efface tout gain de temps.
La réponse difficile ici est que le nombre correct de threads n’est pas une constante d’une tâche à l’autre. Une certaine expérimentation est nécessaire.
*Pourquoi la version `+ threading +` Rocks*
C’est rapide! Voici la course la plus rapide de mes tests. N’oubliez pas que la version non simultanée a pris plus de 14 secondes:
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 secondsVoici à quoi ressemble son chronogramme d’exécution:
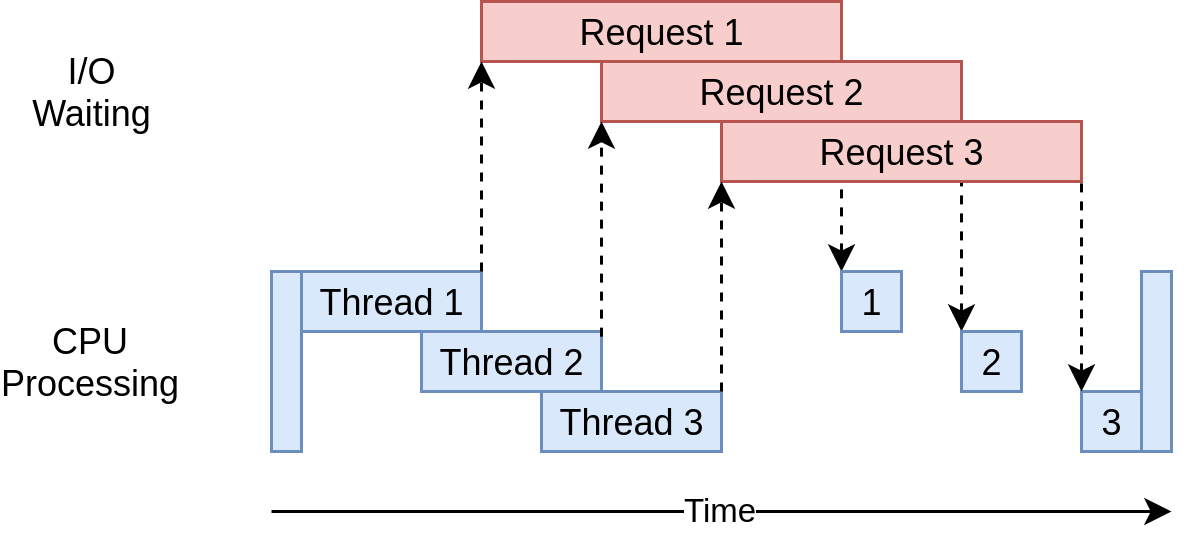
Il utilise plusieurs threads pour envoyer simultanément plusieurs demandes ouvertes à des sites Web, ce qui permet à votre programme de chevaucher les temps d’attente et d’obtenir le résultat final plus rapidement! Hourra! C’était le but.
*Les problèmes avec la version `+ threading +`*
Eh bien, comme vous pouvez le voir dans l’exemple, il faut un peu plus de code pour que cela se produise, et vous devez vraiment réfléchir aux données partagées entre les threads.
Les threads peuvent interagir de manière subtile et difficile à détecter. Ces interactions peuvent provoquer des conditions de concurrence qui entraînent fréquemment des bogues aléatoires et intermittents qui peuvent être assez difficiles à trouver. Ceux d’entre vous qui ne sont pas familiers avec le concept des conditions de course pourraient vouloir développer et lire la section ci-dessous.
Version + asyncio +
Avant de passer à l’examen de l’exemple de code + asyncio +, parlons davantage du fonctionnement de + asyncio +.
*`+ asyncio +` Bases*
Ce sera une version simplifiée de + asycio +. Il y a beaucoup de détails qui sont passés sous silence ici, mais cela transmet toujours l’idée de comment cela fonctionne.
Le concept général de + asyncio + est qu’un seul objet Python, appelé la boucle d’événements, contrôle comment et quand chaque tâche est exécutée. La boucle d’événements est consciente de chaque tâche et sait dans quel état elle se trouve. En réalité, il existe de nombreux états dans lesquels les tâches pourraient être, mais pour l’instant, imaginons une boucle d’événements simplifiée qui ne comporte que deux états.
L’état prêt indique qu’une tâche a du travail à faire et est prête à être exécutée, et l’état d’attente signifie que la tâche attend que quelque chose externe se termine, comme une opération réseau.
Votre boucle d’événements simplifiée gère deux listes de tâches, une pour chacun de ces états. Il sélectionne l’une des tâches prêtes et la redémarre. Cette tâche est sous contrôle complet jusqu’à ce qu’elle remette en coopération le contrôle à la boucle d’événements.
Lorsque la tâche en cours d’exécution redonne le contrôle à la boucle d’événements, la boucle d’événements place cette tâche dans la liste prête ou en attente, puis passe en revue chacune des tâches de la liste d’attente pour voir si elle est devenue prête par une opération d’E/S achèvement. Il sait que les tâches de la liste prête sont toujours prêtes car il sait qu’elles n’ont pas encore été exécutées.
Une fois que toutes les tâches ont été triées à nouveau dans la bonne liste, la boucle d’événements sélectionne la tâche suivante à exécuter et le processus se répète. Votre boucle d’événements simplifiée sélectionne la tâche qui a attendu le plus longtemps et l’exécute. Ce processus se répète jusqu’à la fin de la boucle d’événements.
Un point important de + asyncio + est que les tâches ne perdent jamais le contrôle sans le faire intentionnellement. Ils ne sont jamais interrompus au milieu d’une opération. Cela nous permet de partager les ressources un peu plus facilement dans + asyncio + que dans + threading +. Vous n’avez pas à vous soucier de rendre votre code thread-safe.
C’est une vue d’ensemble de ce qui se passe avec + asyncio +. Si vous voulez plus de détails, cette réponse StackOverflow fournit de bons détails si vous voulez creuser plus profondément.
*`+ async +` et `+ attendre +`*
Parlons maintenant de deux nouveaux mots clés ajoutés à Python: + async + et `+ wait + '. À la lumière de la discussion ci-dessus, vous pouvez voir «+ attendre +» comme la magie qui permet à la tâche de remettre le contrôle à la boucle d’événements. Lorsque votre code attend un appel de fonction, c’est un signal que l’appel est susceptible d’être quelque chose qui prend un certain temps et que la tâche doit abandonner le contrôle.
Il est plus facile de penser à + async + 'comme un indicateur pour Python lui indiquant que la fonction sur le point d’être définie utilise + wait +'. Il y a des cas où cela n’est pas strictement vrai, comme asynchronous generators, mais cela vaut pour de nombreux cas et vous donne un modèle simple pendant que vous " re pour commencer.
Une exception à cela que vous verrez dans le code suivant est l’instruction + async avec +, qui crée un gestionnaire de contexte à partir d’un objet que vous attendez normalement. Bien que la sémantique soit un peu différente, l’idée est la même: signaler ce gestionnaire de contexte comme quelque chose qui peut être échangé.
Comme vous pouvez l’imaginer, il existe une certaine complexité dans la gestion de l’interaction entre la boucle d’événements et les tâches. Pour les développeurs commençant par + asyncio +, ces détails ne sont pas importants, mais vous devez vous rappeler que toute fonction qui appelle + wait + doit être marquée avec `+ async + '. Sinon, vous obtiendrez une erreur de syntaxe.
*Retour au code*
Maintenant que vous avez une compréhension de base de ce qu’est "+ asyncio ", parcourons la version " asyncio " de l'exemple de code et voyons comment cela fonctionne. Notez que cette version ajoute https://aiohttp.readthedocs.io/en/stable/[` aiohttp `]. Vous devez exécuter ` pip install aiohttp +` avant de l’exécuter:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")Cette version est un peu plus complexe que les deux précédentes. Il a une structure similaire, mais il y a un peu plus de travail pour configurer les tâches que pour créer le + ThreadPoolExecutor +. Commençons par le haut de l’exemple.
*`+ download_site () +`*
+ download_site () + en haut est presque identique à la version + threading + à l’exception du mot clé + async + sur la ligne de définition de fonction et des mots clés + async with + lorsque vous appelez réellement + session .get () + `. Vous verrez plus tard pourquoi `+ Session + peut être passé ici plutôt que d’utiliser le stockage local de thread.
*`+ download_all_sites () +`*
+ download_all_sites () + est l’endroit où vous verrez le plus grand changement par rapport à l’exemple + threading +.
Vous pouvez partager la session entre toutes les tâches, de sorte que la session est créée ici en tant que gestionnaire de contexte. Les tâches peuvent partager la session car elles s’exécutent toutes sur le même thread. Il est impossible qu’une tâche en interrompe une autre alors que la session est en mauvais état.
Dans ce gestionnaire de contexte, il crée une liste de tâches en utilisant + asyncio.ensure_future () +, qui s’occupe également de les démarrer. Une fois toutes les tâches créées, cette fonction utilise + asyncio.gather () + pour maintenir le contexte de session en vie jusqu’à ce que toutes les tâches soient terminées.
Le code + threading + fait quelque chose de similaire, mais les détails sont commodément gérés dans le + ThreadPoolExecutor +. Il n’y a actuellement pas de classe + AsyncioPoolExecutor +.
Il y a cependant un petit mais important changement enterré dans les détails. Rappelez-vous comment nous avons parlé du nombre de threads à créer? Dans l’exemple + threading +, le nombre optimal de threads n’était pas évident.
L’un des avantages intéressants de + asyncio + est qu’il évolue bien mieux que + threading +. Chaque tâche prend beaucoup moins de ressources et moins de temps à créer qu’un thread, donc la création et l’exécution d’un plus grand nombre d’entre elles fonctionnent bien. Cet exemple crée simplement une tâche distincte pour chaque site à télécharger, ce qui fonctionne très bien.
*`+ __ principal __ +`*
Enfin, la nature de + asyncio + signifie que vous devez démarrer la boucle d’événements et lui indiquer les tâches à exécuter. La section + main + au bas du fichier contient le code à + get_event_loop () + puis + run_until_complete () +. À tout le moins, ils ont fait un excellent travail pour nommer ces fonctions.
Si vous avez mis à jour Python 3.7, les développeurs principaux de Python ont simplifié cette syntaxe pour vous. Au lieu de + asyncio.get_event_loop (). Run_until_complete () + tongue-twister, vous pouvez simplement utiliser + asyncio.run () +.
*Pourquoi la version `+ asyncio +` Rocks*
C’est vraiment rapide! Dans les tests sur ma machine, c’était la version la plus rapide du code par une bonne marge:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 secondsLe chronogramme d’exécution ressemble assez à ce qui se passe dans l’exemple + threading +. C’est juste que les requêtes d’E/S sont toutes effectuées par le même thread:
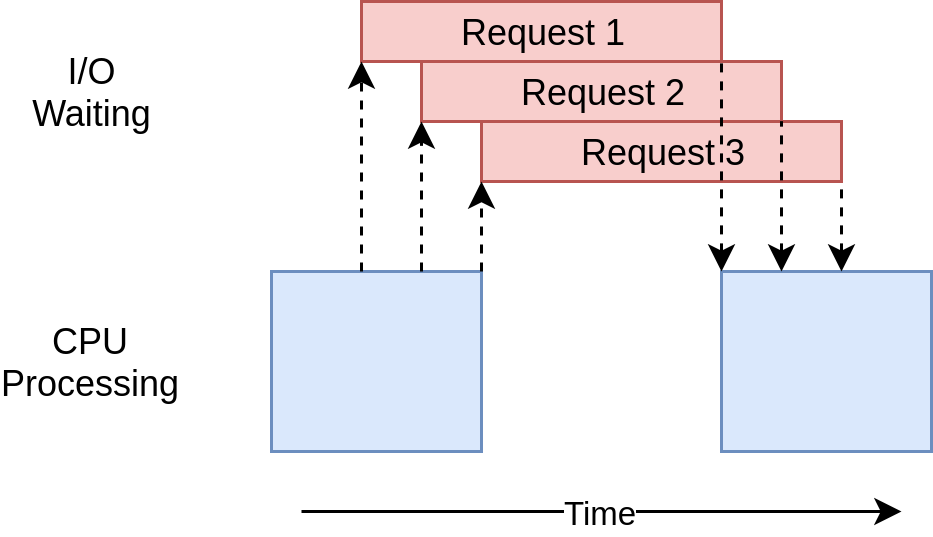
L’absence d’un joli wrapper comme le + ThreadPoolExecutor + rend ce code un peu plus complexe que l’exemple + threading +. C’est un cas où vous devez faire un peu de travail supplémentaire pour obtenir de bien meilleures performances.
Il existe également un argument commun selon lequel le fait d’ajouter + async + et `+ wait + 'aux emplacements appropriés est une complication supplémentaire. Dans une petite mesure, c’est vrai. Le revers de cet argument est qu’il vous oblige à réfléchir au moment où une tâche donnée sera remplacée, ce qui peut vous aider à créer une conception meilleure et plus rapide.
Le problème de mise à l’échelle est également important ici. L’exécution de l’exemple + threading + ci-dessus avec un thread pour chaque site est sensiblement plus lente que son exécution avec une poignée de threads. L’exécution de l’exemple + asyncio + avec des centaines de tâches ne l’a pas du tout ralenti.
*Les problèmes avec la version `+ asyncio +`*
Il y a quelques problèmes avec + asyncio + à ce stade. Vous avez besoin de versions spéciales asynchrones des bibliothèques pour profiter pleinement de + asycio +. Si vous veniez d’utiliser + demandes + pour télécharger les sites, cela aurait été beaucoup plus lent car + demandes + n’est pas conçu pour signaler à la boucle d’événements qu’elle est bloquée. Ce problème devient de plus en plus petit avec le temps et de plus en plus de bibliothèques embrassent + asyncio +.
Un autre problème, plus subtil, est que tous les avantages du multitâche coopératif sont perdus si l’une des tâches ne coopère pas. Une erreur mineure dans le code peut entraîner l’exécution d’une tâche et maintenir le processeur pendant une longue période, ce qui affame d’autres tâches qui doivent être exécutées. Il n’y a aucun moyen pour la boucle d’événement d’interrompre si une tâche ne lui rend pas le contrôle.
Dans cet esprit, passons à une approche radicalement différente de la concurrence, + multiprocessing +.
+ multiprocessing + Version
Contrairement aux approches précédentes, la version + multiprocessing + du code tire pleinement parti des multiples processeurs de votre nouvel ordinateur. Ou, dans mon cas, que mon vieux portable maladroit a. Commençons par le code:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")C’est beaucoup plus court que l’exemple + asyncio + et ressemble en fait assez à l’exemple + threading +, mais avant de nous plonger dans le code, voyons ce que `+ multiprocessing + 'fait pour vous.
*`+ multiprocessing +` en bref*
Jusqu’à ce stade, tous les exemples de concurrence dans cet article ne s’exécutent que sur un seul processeur ou cœur de votre ordinateur. Les raisons en sont liées à la conception actuelle de CPython et à quelque chose appelé Global Interpreter Lock, ou GIL.
Cet article ne plonge pas dans le comment et le pourquoi du GIL. Il suffit pour le moment de savoir que les versions synchrones, + threading + et + asyncio + de cet exemple fonctionnent toutes sur un seul processeur.
+ multiprocessing + dans la bibliothèque standard a été conçu pour briser cette barrière et exécuter votre code sur plusieurs processeurs. À un niveau élevé, il le fait en créant une nouvelle instance de l’interpréteur Python à exécuter sur chaque CPU, puis en développant une partie de votre programme pour l’exécuter.
Comme vous pouvez l’imaginer, faire apparaître un interpréteur Python séparé n’est pas aussi rapide que de démarrer un nouveau thread dans l’interpréteur Python actuel. C’est une opération lourde et comporte quelques restrictions et difficultés, mais pour le problème correct, cela peut faire une énorme différence.
*`+ multiprocessing +` Code*
Le code a quelques petits changements par rapport à notre version synchrone. Le premier est dans + download_all_sites () +. Au lieu d’appeler simplement + download_site () + à plusieurs reprises, il crée un objet + multiprocessing.Pool + et le fait mapper + download_site + sur l’itérable + sites + '. Cela devrait sembler familier dans l’exemple `+ threading +.
Ce qui se passe ici est que le + Pool + crée un certain nombre de processus d’interpréteur Python distincts et a chacun exécuté la fonction spécifiée sur certains des éléments de l’itérable, qui dans notre cas est la liste des sites. La communication entre le processus principal et les autres processus est gérée par le module + multiprocessing + pour vous.
La ligne qui crée + Pool + mérite votre attention. Tout d’abord, il ne spécifie pas le nombre de processus à créer dans le + Pool +, bien qu’il s’agisse d’un paramètre facultatif. Par défaut, + multiprocessing.Pool () + déterminera le nombre de CPU de votre ordinateur et correspondra à cela. C’est souvent la meilleure réponse, et c’est dans notre cas.
Pour ce problème, l’augmentation du nombre de processus n’a pas accéléré les choses. Cela a en fait ralenti les choses car le coût de configuration et de suppression de tous ces processus était plus important que l’avantage de faire les demandes d’E/S en parallèle.
Ensuite, nous avons la partie + initializer = set_global_session + de cet appel. N’oubliez pas que chaque processus de notre + Pool + 'a son propre espace mémoire. Cela signifie qu’ils ne peuvent pas partager des choses comme un objet `+ Session +. Vous ne voulez pas créer une nouvelle + Session + à chaque appel de la fonction, vous voulez en créer une pour chaque processus.
Le paramètre de fonction + initializer + est construit uniquement pour ce cas. Il n’y a aucun moyen de renvoyer une valeur de retour du + initializer + à la fonction appelée par le processus + download_site () +, mais vous pouvez initialiser une variable globale + session + pour contenir la session unique pour chaque processus. Parce que chaque processus a son propre espace mémoire, le global de chacun sera différent.
C’est vraiment tout. Le reste du code est assez similaire à ce que vous avez vu auparavant.
*Pourquoi la version `+ multiprocessing +` Rocks*
La version + multiprocessing + de cet exemple est excellente car elle est relativement facile à configurer et nécessite peu de code supplémentaire. Il tire également pleinement parti de la puissance du processeur de votre ordinateur. Le chronogramme d’exécution de ce code ressemble à ceci:
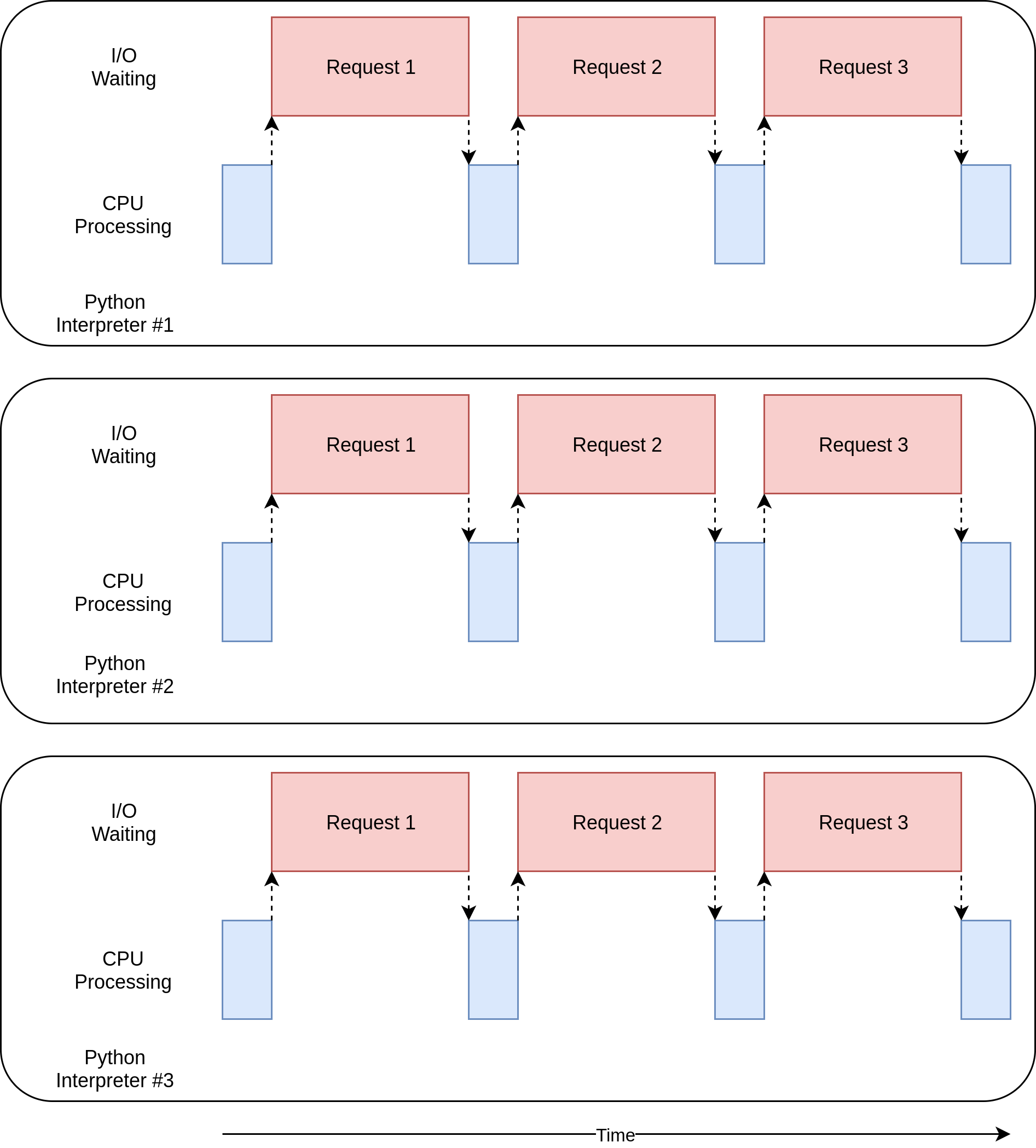
*Les problèmes avec la version `+ multiprocessing +`*
Cette version de l’exemple nécessite une configuration supplémentaire, et l’objet global + session + est étrange. Vous devez passer du temps à réfléchir aux variables qui seront accessibles dans chaque processus.
Enfin, il est clairement plus lent que les versions + asyncio + et + threading + dans cet exemple:
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 secondsCe n’est pas surprenant, car les problèmes liés aux E/S ne sont pas vraiment la raison pour laquelle + multiprocessing + existe. Vous en verrez plus en entrant dans la section suivante et en examinant des exemples liés au processeur.
Comment accélérer un programme lié au processeur
Passons un peu aux engrenages ici. Jusqu’à présent, les exemples ont tous traité d’un problème lié aux E/S. Vous allez maintenant examiner un problème lié au processeur. Comme vous l’avez vu, un problème lié aux E/S passe la plupart de son temps à attendre la fin des opérations externes, comme un appel réseau. Un problème lié au processeur, d’autre part, fait peu d’opérations d’E/S et son temps d’exécution global est un facteur de la rapidité avec laquelle il peut traiter les données requises.
Pour les besoins de notre exemple, nous allons utiliser une fonction quelque peu idiote pour créer quelque chose qui prend beaucoup de temps à s’exécuter sur le CPU. Cette fonction calcule la somme des carrés de chaque nombre de 0 à la valeur transmise:
def cpu_bound(number):
return sum(i *i for i in range(number))Vous passerez en grand nombre, cela prendra donc un certain temps. N’oubliez pas qu’il s’agit simplement d’un espace réservé pour votre code qui fait réellement quelque chose d’utile et nécessite un temps de traitement important, comme le calcul des racines des équations ou le tri d’une grande structure de données.
Version synchrone liée au CPU
Voyons maintenant la version non simultanée de l’exemple:
import time
def cpu_bound(number):
return sum(i* i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Ce code appelle 20 fois + cpu_bound () + avec un grand nombre différent à chaque fois. Il fait tout cela sur un seul thread dans un seul processus sur un seul processeur. Le chronogramme d’exécution ressemble à ceci:
Contrairement aux exemples liés aux E/S, les exemples liés au processeur sont généralement assez cohérents dans leurs temps d’exécution. Celui-ci prend environ 7,8 secondes sur ma machine:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 secondsDe toute évidence, nous pouvons faire mieux que cela. Tout cela fonctionne sur un seul processeur sans concurrence. Voyons ce que nous pouvons faire pour l’améliorer.
Versions + threading + et + asyncio +
Dans quelle mesure pensez-vous que la réécriture de ce code en utilisant + threading + ou + asyncio + accélérera cela?
Si vous avez répondu «Pas du tout», donnez-vous un cookie. Si vous avez répondu: «Cela va ralentir», donnez-vous deux cookies.
Voici pourquoi: dans votre exemple lié aux E/S ci-dessus, une grande partie du temps global a été consacrée à attendre la fin des opérations lentes. + threading + et + asyncio + ont accéléré cela en vous permettant de chevaucher les temps que vous attendiez au lieu de les faire séquentiellement.
Sur un problème lié au processeur, cependant, il n’y a pas d’attente. Le processeur démarre aussi vite que possible pour résoudre le problème. En Python, les threads et les tâches s’exécutent sur le même processeur dans le même processus. Cela signifie que le seul processeur effectue tout le travail du code non simultané ainsi que le travail supplémentaire de configuration des threads ou des tâches. Cela prend plus de 10 secondes:
$ ./cpu_threading.py
Duration 10.407078266143799 secondsJ’ai rédigé une version `+ + threading + 'de ce code et l’ai placée avec l’autre exemple de code dans le GitHub repo afin que vous puissiez allez tester vous-même. Mais ne regardons pas cela pour l’instant.
CPU-Bound + multiprocessing + Version
Maintenant, vous êtes enfin arrivé là où "+ multiprocessing " brille vraiment. Contrairement aux autres bibliothèques de concurrence, ` multiprocessing +` est explicitement conçu pour partager des charges de travail CPU importantes entre plusieurs processeurs. Voici à quoi ressemble son chronogramme d’exécution:
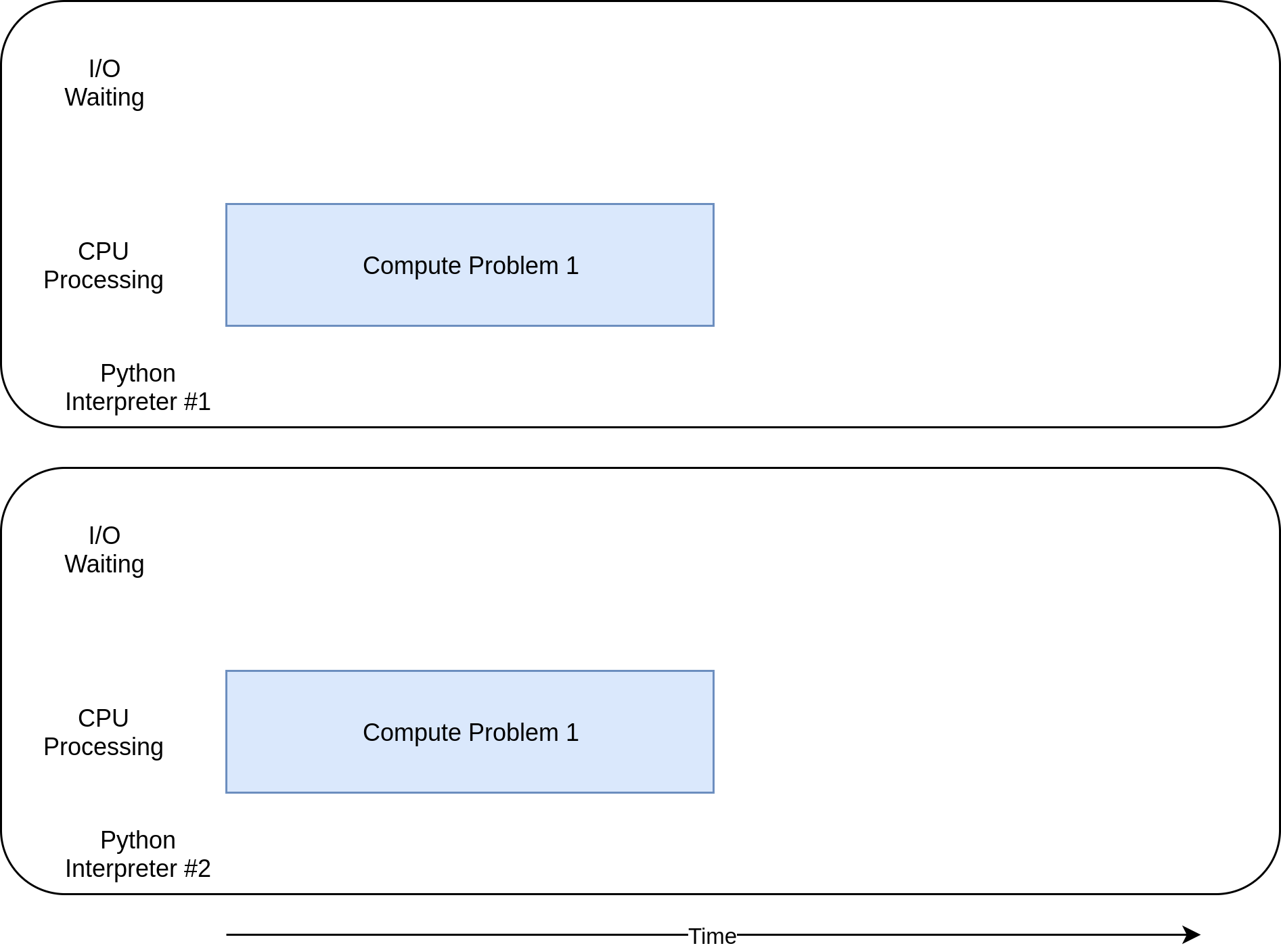
Voici à quoi ressemble le code:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Peu de ce code a dû changer par rapport à la version non simultanée. Vous avez dû + importer le multiprocessing +, puis passer de la boucle aux numéros à la création d’un objet + multiprocessing.Pool + et utiliser sa méthode + .map () + pour envoyer des numéros individuels aux processus de travail à mesure qu’ils deviennent gratuit.
C’est exactement ce que vous avez fait pour le code + multiprocessing + lié aux E/S, mais ici, vous n’avez pas à vous soucier de l’objet + Session +.
Comme mentionné ci-dessus, le paramètre facultatif + processus + du constructeur + multiprocessing.Pool () + mérite une certaine attention. Vous pouvez spécifier le nombre d’objets + Process + 'que vous souhaitez créer et gérer dans le + Pool + `. Par défaut, il déterminera le nombre de CPU dans votre machine et créera un processus pour chacun. Bien que cela fonctionne très bien pour notre exemple simple, vous souhaiterez peut-être avoir un peu plus de contrôle dans un environnement de production.
De plus, comme nous l’avons mentionné dans la première section sur + threading +, le code + multiprocessing.Pool + est construit sur des blocs de construction comme + Queue + et + Semaphore + qui seront familiers à ceux d’entre vous qui ont fait du multithread et le code de multitraitement dans d’autres langues.
*Pourquoi la version `+ multiprocessing +` Rocks*
La version + multiprocessing + de cet exemple est excellente car elle est relativement facile à configurer et nécessite peu de code supplémentaire. Il tire également pleinement parti de la puissance du processeur de votre ordinateur.
Hé, c’est exactement ce que j’ai dit la dernière fois que nous avons examiné + multiprocessing +. La grande différence est que cette fois c’est clairement la meilleure option. Cela prend 2,5 secondes sur ma machine:
$ ./cpu_mp.py
Duration 2.5175397396087646 secondsC’est beaucoup mieux que ce que nous avons vu avec les autres options.
*Les problèmes avec la version `+ multiprocessing +`*
Il y a quelques inconvénients à utiliser + multiprocessing +. Ils n’apparaissent pas vraiment dans cet exemple simple, mais diviser votre problème afin que chaque processeur puisse fonctionner indépendamment peut parfois être difficile.
De plus, de nombreuses solutions nécessitent davantage de communication entre les processus. Cela peut ajouter une certaine complexité à votre solution qu’un programme non simultané n’aurait pas besoin de gérer.
Quand utiliser la simultanéité
Vous avez parcouru beaucoup de terrain ici. Passons en revue certaines des idées clés, puis discutons de certains points de décision qui vous aideront à déterminer, le cas échéant, le module de concurrence que vous souhaitez utiliser dans votre projet.
La première étape de ce processus consiste à décider si vous devez utiliser un module de concurrence. Bien que les exemples ici rendent chacune des bibliothèques assez simple, la concurrence s’accompagne toujours d’une complexité supplémentaire et peut souvent entraîner des bogues difficiles à trouver.
Attendez l’ajout de concurrence jusqu’à ce que vous ayez un problème de performances connu et puis déterminez le type de concurrence dont vous avez besoin. Comme Donald Knuth l’a dit, "L’optimisation prématurée est la racine de tout mal (ou du moins la majeure partie) dans la programmation."
Une fois que vous avez décidé d’optimiser votre programme, déterminer si votre programme est lié au processeur ou aux E/S est une excellente étape suivante. N’oubliez pas que les programmes liés aux E/S sont ceux qui passent la plupart de leur temps à attendre que quelque chose se produise, tandis que les programmes liés au processeur passent leur temps à traiter les données ou à chiffrer les nombres aussi rapidement qu’ils le peuvent.
Comme vous l’avez vu, les problèmes liés au processeur ne gagnent vraiment qu’en utilisant + multiprocessing +. + threading + et + asyncio + n’a pas du tout aidé ce type de problème.
Pour les problèmes liés aux E/S, il existe une règle générale dans la communauté Python: "Utilisez` + asyncio + quand vous le pouvez, + threading + quand vous le devez." `+ asyncio + peut fournir la meilleure vitesse pour ce type de programme, mais parfois vous aurez besoin de bibliothèques critiques qui n’ont pas été portées pour profiter de + asyncio +. N’oubliez pas que toute tâche qui n’abandonne pas le contrôle de la boucle d’événements bloquera toutes les autres tâches.
Conclusion
Vous avez maintenant vu les types de base de concurrence disponibles en Python:
-
`+ enfilage + '
-
+ asyncio + -
+ multitraitement +
Vous avez compris comment décider de la méthode de concurrence à utiliser pour un problème donné ou si vous devez en utiliser une! De plus, vous avez mieux compris certains des problèmes qui peuvent survenir lorsque vous utilisez la simultanéité.
J’espère que vous avez beaucoup appris de cet article et que vous trouvez une excellente utilisation de la concurrence dans vos propres projets! Assurez-vous de répondre à notre quiz «Python Concurrency» lié ci-dessous pour vérifier votre apprentissage:
*__ Répondez au questionnaire:* Testez vos connaissances avec notre quiz interactif "Python Concurrency". À la fin, vous recevrez un score afin que vous puissiez suivre vos progrès d'apprentissage au fil du temps:
lien:/quiz/python-concurrency/[Participez au quiz »]