Python, Boto3 et AWS S3: démystifiés
Amazon Web Services (AWS) est devenu un leader dans le cloud computing. L'un de ses principaux composants est S3, le service de stockage d'objets proposé par AWS. Avec sa disponibilité et sa durabilité impressionnantes, il est devenu le moyen standard de stocker des vidéos, des images et des données. Vous pouvez combiner S3 avec d'autres services pour créer des applications évolutives à l'infini.
Boto3 est le nom du SDK Python pour AWS. Il vous permet de créer, mettre à jour et supprimer directement des ressources AWS de vos scripts Python.
Si vous avez déjà été exposé à AWS, possédez votre propre compte AWS et souhaitez faire passer vos compétences au niveau supérieur en commençant à utiliser les services AWS à partir de votre code Python, puis continuez à lire.
À la fin de ce didacticiel, vous allez:
-
Soyez assuré de travailler avec des compartiments et des objets directement à partir de vos scripts Python
-
Savoir comment éviter les pièges courants lors de l'utilisation de Boto3 et S3
-
Comprendre comment configurer vos données dès le départ pour éviter des problèmes de performances plus tard
-
Découvrez comment configurer vos objets pour tirer parti des meilleures fonctionnalités de S3
Avant d'explorer les caractéristiques de Boto3, vous verrez d'abord comment configurer le SDK sur votre machine. Cette étape vous préparera pour le reste du didacticiel.
Free Bonus:5 Thoughts On Python Mastery, un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour faire passer vos compétences Python au niveau supérieur.
Installation
Pour installer Boto3 sur votre ordinateur, accédez à votre terminal et exécutez ce qui suit:
$ pip install boto3Vous avez le SDK. Mais, vous ne pourrez pas l'utiliser pour le moment, car il ne sait pas à quel compte AWS il doit se connecter.
Pour le faire fonctionner sur votre compte AWS, vous devrez fournir des informations d'identification valides. Si vous avez déjà un utilisateur IAM qui dispose des autorisations complètes sur S3, vous pouvez utiliser les informations d'identification de cet utilisateur (sa clé d'accès et sa clé d'accès secrète) sans avoir à créer un nouvel utilisateur. Sinon, la façon la plus simple de procéder consiste à créer un nouvel utilisateur AWS, puis à stocker les nouvelles informations d'identification.
Pour créer un nouvel utilisateur, accédez à votre compte AWS, puis accédez àServices et sélectionnezIAM. Puis choisissezUsers et cliquez surAdd user.
Donnez un nom à l'utilisateur (par exemple,boto3user). Activezprogrammatic access. Cela garantira que cet utilisateur pourra travailler avec n'importe quel SDK pris en charge par AWS ou effectuer des appels d'API distincts:
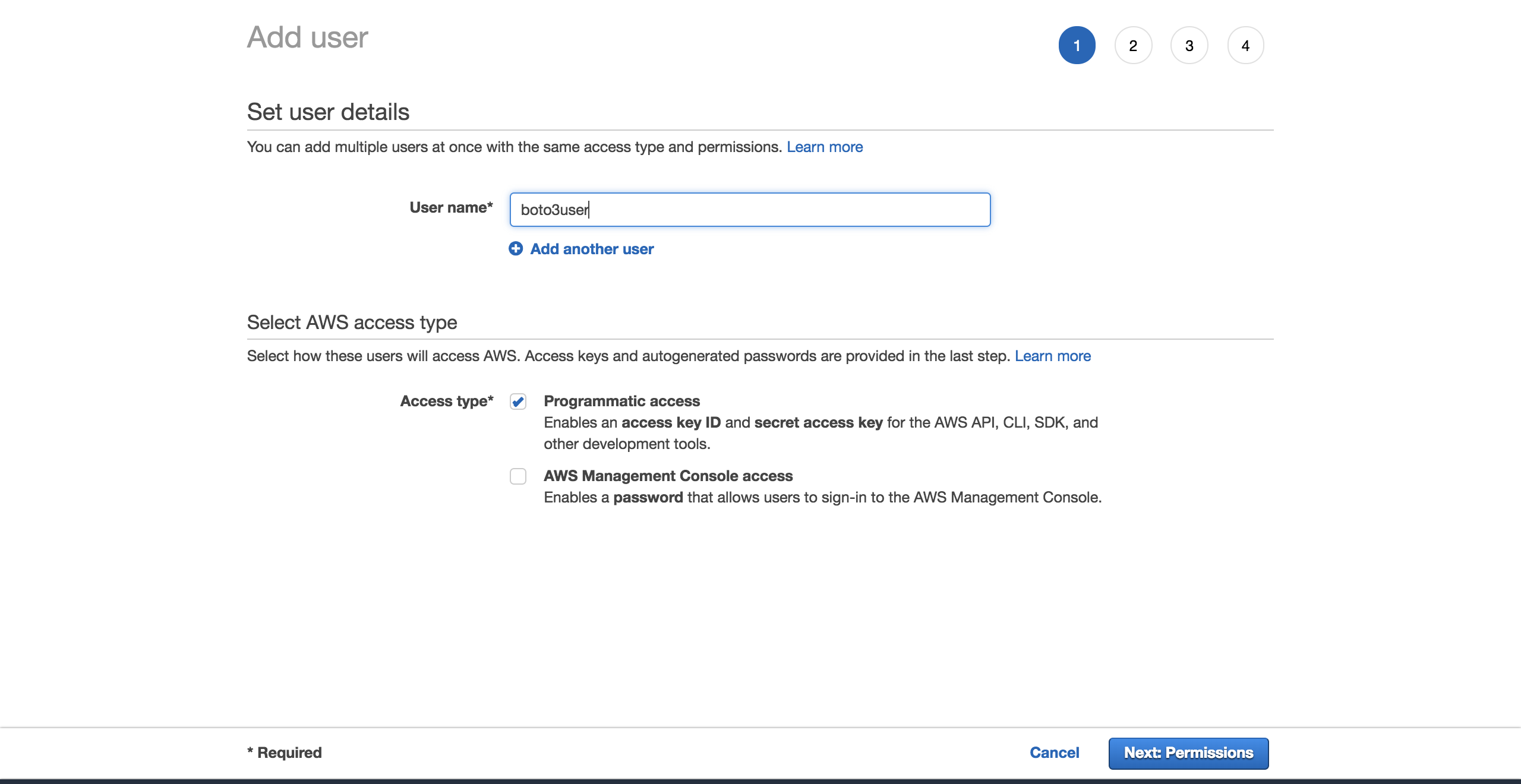
Pour simplifier les choses, choisissez la stratégieAmazonS3FullAccess préconfigurée. Avec cette politique, le nouvel utilisateur pourra avoir un contrôle total sur S3. Cliquez surNext: Review:
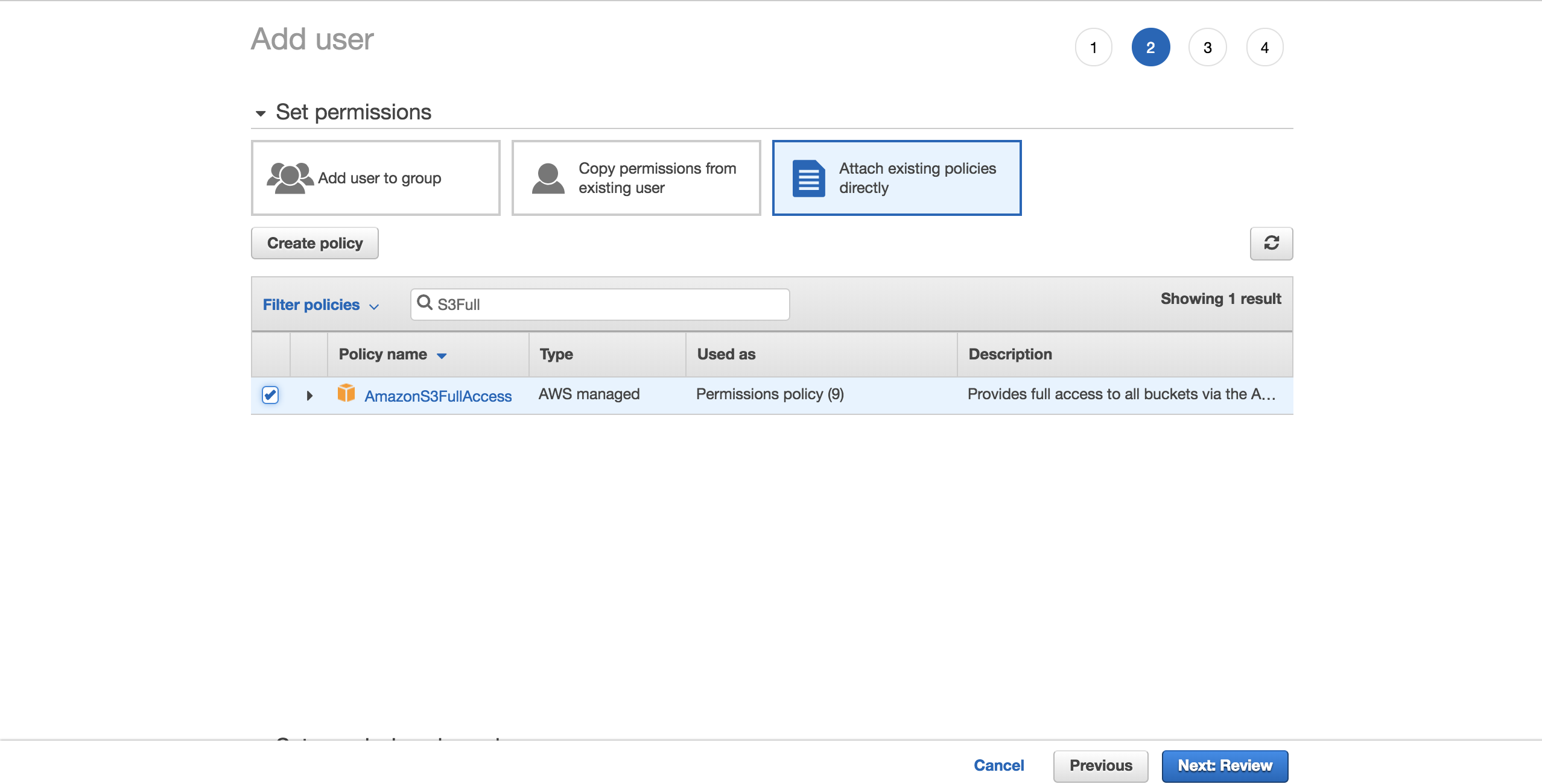
SélectionnezCreate user:
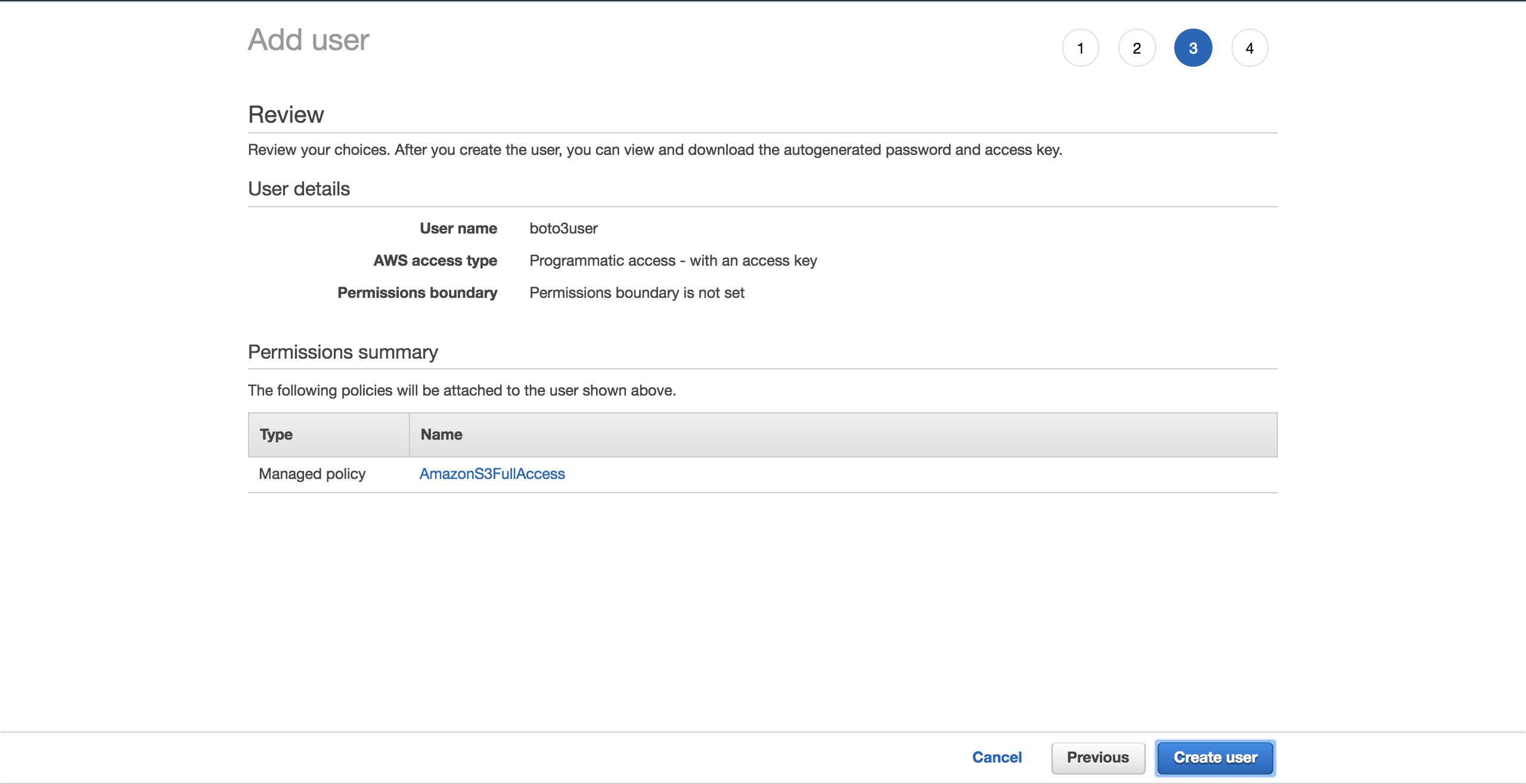
Un nouvel écran vous montrera les informations d'identification générées par l'utilisateur. Cliquez sur le boutonDownload .csv pour faire une copie des informations d'identification. Vous en aurez besoin pour terminer votre configuration.
Maintenant que vous avez votre nouvel utilisateur, créez un nouveau fichier,~/.aws/credentials:
$ touch ~/.aws/credentialsOuvrez le fichier et collez la structure ci-dessous. Remplissez les espaces réservés avec les nouvelles informations d'identification que vous avez téléchargées:
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEYEnregistrez le fichier.
Maintenant que vous avez configuré ces informations d'identification, vous disposez d'un profildefault, qui sera utilisé par Boto3 pour interagir avec votre compte AWS.
Il y a une configuration de plus à configurer: la région par défaut avec laquelle Boto3 doit interagir. Vous pouvez consulter lescomplete table of the supported AWS regions. Choisissez la région la plus proche de vous. Copiez votre région préférée de la colonneRegion. Dans mon cas, j'utiliseeu-west-1 (Irlande).
Créez un nouveau fichier,~/.aws/config:
$ touch ~/.aws/configAjoutez ce qui suit et remplacez l'espace réservé par lesregion que vous avez copiés:
[default]
region = YOUR_PREFERRED_REGIONSauvegardez votre fichier.
Vous êtes maintenant officiellement configuré pour le reste du didacticiel.
Ensuite, vous verrez les différentes options que Boto3 vous offre pour vous connecter à S3 et à d'autres services AWS.
Client versus ressource
À la base, tout ce que fait Boto3, c'est d'appeler des API AWS en votre nom. Pour la majorité des services AWS, Boto3 offre deux façons distinctes d'accéder à ces API abstraites:
-
Accès aux services de bas niveauClient:
-
Resource: accès au service orienté objet de niveau supérieur
Vous pouvez utiliser l'un ou l'autre pour interagir avec S3.
Pour vous connecter à l’interface client de bas niveau, vous devez utiliser lesclient() de Boto3. Vous passez ensuite le nom du service auquel vous souhaitez vous connecter, dans ce cas,s3:
import boto3
s3_client = boto3.client('s3')Pour vous connecter à l'interface de haut niveau, vous suivrez une approche similaire, mais utilisezresource():
import boto3
s3_resource = boto3.resource('s3')Vous avez réussi à vous connecter aux deux versions, mais vous vous demandez peut-être maintenant: "Laquelle dois-je utiliser?"
Avec les clients, il y a plus de travail programmatique à faire. La majorité des opérations client vous donnent une réponsedictionary. Pour obtenir les informations exactes dont vous avez besoin, vous devrez analyser ce dictionnaire vous-même. Avec les méthodes de ressources, le SDK fait cela pour vous.
Avec le client, vous pouvez constater de légères améliorations des performances. L'inconvénient est que votre code devient moins lisible qu'il ne le serait si vous utilisiez la ressource. Les ressources offrent une meilleure abstraction et votre code sera plus facile à comprendre.
Comprendre comment le client et la ressource sont générés est également important lorsque vous envisagez lequel choisir:
-
Boto3 génère le client à partir d'un fichier de définition de service JSON. Les méthodes du client prennent en charge chaque type d'interaction avec le service AWS cible.
-
Les ressources, en revanche, sont générées à partir de fichiers de définition de ressources JSON.
Boto3 génère le client et la ressource à partir de différentes définitions. Par conséquent, vous pouvez trouver des cas dans lesquels une opération prise en charge par le client n'est pas proposée par la ressource. Voici la partie intéressante: vous n'avez pas besoin de changer votre code pour utiliser le client partout. Pour cette opération, vous pouvez accéder directement au client via la ressource comme ceci:s3_resource.meta.client.
Une telle opérationclient est.generate_presigned_url(), qui vous permet de donner à vos utilisateurs l'accès à un objet dans votre compartiment pendant une période de temps définie, sans qu'ils aient besoin d'informations d'identification AWS.
Opérations courantes
Maintenant que vous connaissez les différences entre les clients et les ressources, commençons à les utiliser pour créer de nouveaux composants S3.
Création d'un compartiment
Pour commencer, vous avez besoin d'un S3bucket. Pour en créer un par programme, vous devez d'abord choisir un nom pour votre compartiment. N'oubliez pas que ce nom doit être unique sur toute la plateforme AWS, car les noms de compartiment sont conformes DNS. Si vous essayez de créer un compartiment, mais qu'un autre utilisateur a déjà réclamé le nom de votre compartiment souhaité, votre code échouera. Au lieu de succès, vous verrez l'erreur suivante:botocore.errorfactory.BucketAlreadyExists.
Vous pouvez augmenter vos chances de succès lors de la création de votre bucket en choisissant un nom aléatoire. Vous pouvez générer votre propre fonction qui le fait pour vous. Dans cette implémentation, vous verrez comment l'utilisation du moduleuuid vous aidera à y parvenir. La représentation sous forme de chaîne d'un UUID4 comporte 36 caractères (tirets compris) et vous pouvez ajouter un préfixe pour spécifier à quoi sert chaque compartiment.
Voici un moyen d'y parvenir:
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])Vous avez le nom de votre compartiment, mais il y a maintenant une autre chose dont vous devez être conscient: à moins que votre région ne se trouve aux États-Unis, vous devrez définir la région explicitement lorsque vous créez le compartiment. Sinon, vous obtiendrez unIllegalLocationConstraintException.
Pour illustrer ce que cela signifie lorsque vous créez votre compartiment S3 dans une région non américaine, jetez un œil au code ci-dessous:
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})Vous devez fournir à la fois un nom de compartiment et une configuration de compartiment où vous devez spécifier la région, qui dans mon cas esteu-west-1.
Ce n'est pas idéal. Imaginez que vous souhaitez prendre votre code et le déployer sur le cloud. Votre tâche deviendra de plus en plus difficile car vous avez maintenant codé en dur la région. Vous pourriez refactoriser la région et la transformer en une variable d'environnement, mais vous auriez alors une dernière chose à gérer.
Heureusement, il existe un meilleur moyen d'obtenir la région par programme, en tirant parti d'un objetsession. Boto3 créera lessession à partir de vos informations d'identification. Il vous suffit de prendre la région et de la passer àcreate_bucket() comme sa configurationLocationConstraint. Voici comment procéder:
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_responseLa bonne partie est que ce code fonctionne peu importe où vous voulez le déployer: localement / EC2 / Lambda. De plus, vous n'avez pas besoin de coder en dur votre région.
Comme le client et la ressource créent des compartiments de la même manière, vous pouvez passer l'un ou l'autre comme paramètres3_connection.
Vous allez maintenant créer deux compartiments. Créez d'abord un en utilisant le client, qui vous rend lesbucket_response sous forme de dictionnaire:
>>>
>>> first_bucket_name, first_response = create_bucket(
... bucket_prefix='firstpythonbucket',
... s3_connection=s3_resource.meta.client)
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1
>>> first_response
{'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}Ensuite, créez un deuxième compartiment à l'aide de la ressource, qui vous rend une instanceBucket en tant quebucket_response:
>>>
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')Vous avez vos seaux. Ensuite, vous souhaiterez commencer à leur ajouter des fichiers.
Nommer vos fichiers
Vous pouvez nommer vos objets à l'aide des conventions de dénomination de fichier standard. Vous pouvez utiliser n'importe quel nom valide. Dans cet article, vous examinerez un cas plus spécifique qui vous aidera à comprendre comment S3 fonctionne sous le capot.
Si vous prévoyez d'héberger un grand nombre de fichiers dans votre compartiment S3, vous devez garder à l'esprit quelque chose. Si tous vos noms de fichiers ont un préfixe déterministe qui se répète pour chaque fichier, tel qu'un format d'horodatage tel que «AAAA-MM-JJThh: mm: ss», vous constaterez bientôt que vous êtes en train de rencontrerperformance issues lorsque vous essayez d'interagir avec votre bucket.
Cela se produira car S3 prend le préfixe du fichier et le mappe sur une partition. Plus vous ajoutez de fichiers, plus ils seront affectés à la même partition, et cette partition sera très lourde et moins réactive.
Que pouvez-vous faire pour empêcher que cela se produise?
La solution la plus simple consiste à randomiser le nom du fichier. Vous pouvez imaginer de nombreuses implémentations différentes, mais dans ce cas, vous utiliserez le module de confianceuuid pour vous aider. Pour faciliter la lecture des noms de fichiers pour ce didacticiel, vous allez prendre les six premiers caractères de la représentationhexdu nombre généré et les concaténer avec votre nom de fichier de base.
La fonction d'assistance ci-dessous vous permet de transmettre le nombre d'octets que vous souhaitez que le fichier ait, le nom du fichier et un exemple de contenu à répéter pour créer la taille de fichier souhaitée:
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_nameCréez votre premier fichier, que vous utiliserez sous peu:
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')En ajoutant un caractère aléatoire à vos noms de fichiers, vous pouvez distribuer efficacement vos données au sein de votre compartiment S3.
Création d'instancesBucket etObject
L'étape suivante après la création de votre fichier est de voir comment l'intégrer dans votre flux de travail S3.
C'est là que les classes de la ressource jouent un rôle important, car ces abstractions facilitent le travail avec S3.
En utilisant la ressource, vous avez accès aux classes de haut niveau (Bucket etObject). Voici comment vous pouvez en créer un de chacun:
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)La raison pour laquelle vous n'avez constaté aucune erreur lors de la création de la variablefirst_object est que Boto3 ne fait pas d'appels à AWS pour créer la référence. Lesbucket_name et leskey sont appelés identificateurs, et ce sont les paramètres nécessaires pour créer unObject. Tout autre attribut d'unObject, tel que sa taille, est chargé paresseusement. Cela signifie que pour que Boto3 obtienne les attributs demandés, il doit passer des appels à AWS.
Comprendre les sous-ressources
Bucket etObject sont des sous-ressources l'une de l'autre. Les sous-ressources sont des méthodes qui créent une nouvelle instance d'une ressource enfant. Les identifiants du parent sont transmis à la ressource enfant.
Si vous avez une variableBucket, vous pouvez créer directement unObject:
first_object_again = first_bucket.Object(first_file_name)Ou si vous avez une variableObject, alors vous pouvez obtenir lesBucket:
first_bucket_again = first_object.Bucket()Génial, vous savez maintenant comment générer unBucket et unObject. Ensuite, vous pourrez télécharger votre fichier nouvellement généré vers S3 en utilisant ces constructions.
Téléchargement d'un fichier
Vous pouvez télécharger un fichier de trois manières:
-
Depuis une instance
Object -
Depuis une instance
Bucket -
À partir des
client
Dans chaque cas, vous devez fournir leFilename, qui est le chemin du fichier que vous souhaitez télécharger. Vous allez maintenant explorer les trois alternatives. N'hésitez pas à choisir celui que vous préférez pour télécharger lesfirst_file_name sur S3.
Version de l'instance d'objet
Vous pouvez télécharger en utilisant une instanceObject:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)Ou vous pouvez utiliser l'instancefirst_object:
first_object.upload_file(first_file_name)Version de l'instance de bucket
Voici comment importer à l'aide d'une instanceBucket:
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)Version du client
Vous pouvez également télécharger en utilisant lesclient:
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)Vous avez correctement téléchargé votre fichier sur S3 en utilisant l'une des trois méthodes disponibles. Dans les sections à venir, vous travaillerez principalement avec la classeObject, car les opérations sont très similaires entre les versionsclient etBucket.
Téléchargement d'un fichier
Pour télécharger un fichier à partir de S3 localement, vous suivrez des étapes similaires à celles que vous avez suivies lors du téléchargement. Mais dans ce cas, le paramètreFilename correspondra au chemin local souhaité. Cette fois, il téléchargera le fichier dans le répertoiretmp:
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+Vous avez correctement téléchargé votre fichier depuis S3. Ensuite, vous verrez comment copier le même fichier entre vos compartiments S3 à l'aide d'un seul appel d'API.
Copie d'un objet entre des compartiments
Si vous avez besoin de copier des fichiers d'un compartiment à un autre, Boto3 vous offre cette possibilité. Dans cet exemple, vous allez copier le fichier du premier bucket vers le second, en utilisant.copy():
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)Note: Si vous souhaitez répliquer vos objets S3 dans un compartiment d'une autre région, jetez un œil àCross Region Replication.
Supprimer un objet
Supprimons le nouveau fichier du second bucket en appelant.delete() sur l'instance équivalenteObject:
s3_resource.Object(second_bucket_name, first_file_name).delete()Vous avez maintenant vu comment utiliser les opérations principales de S3. Vous êtes prêt à porter vos connaissances au niveau supérieur avec des caractéristiques plus complexes dans les sections à venir.
Configurations avancées
Dans cette section, vous allez explorer des fonctionnalités S3 plus élaborées. Vous verrez des exemples sur la façon de les utiliser et les avantages qu’ils peuvent apporter à vos applications.
ACL (listes de contrôle d'accès)
Les listes de contrôle d'accès (ACL) vous aident à gérer l'accès à vos compartiments et aux objets qu'ils contiennent. Ils sont considérés comme la manière traditionnelle d'administrer les autorisations sur S3. Pourquoi devriez-vous les connaître? Si vous devez gérer l'accès à des objets individuels, vous utiliserez alors une ACL d'objet.
Par défaut, lorsque vous téléchargez un objet vers S3, cet objet est privé. Si vous souhaitez mettre cet objet à la disposition de quelqu'un d'autre, vous pouvez définir la liste de contrôle d'accès de l'objet pour qu'elle soit publique au moment de la création. Voici comment télécharger un nouveau fichier dans le bucket et le rendre accessible à tous:
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})Vous pouvez obtenir l'instanceObjectAcl à partir desObject, car c'est l'une de ses sous-classes de ressources:
second_object_acl = second_object.Acl()Pour voir qui a accès à votre objet, utilisez l'attributgrants:
>>>
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]Vous pouvez à nouveau rendre votre objet privé, sans avoir à le télécharger à nouveau:
>>>
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]Vous avez vu comment utiliser les ACL pour gérer l'accès à des objets individuels. Ensuite, vous verrez comment ajouter une couche de sécurité supplémentaire à vos objets à l'aide du chiffrement.
Note: Si vous souhaitez diviser vos données en plusieurs catégories, jetez un œil àtags. Vous pouvez accorder l'accès aux objets en fonction de leurs balises.
Chiffrement
Avec S3, vous pouvez protéger vos données à l'aide du cryptage. Vous explorerez le chiffrement côté serveur à l'aide de l'algorithme AES-256 où AWS gère à la fois le chiffrement et les clés.
Créez un nouveau fichier et téléchargez-le en utilisantServerSideEncryption:
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})Vous pouvez vérifier l'algorithme qui a été utilisé pour crypter le fichier, dans ce casAES256:
>>>
>>> third_object.server_side_encryption
'AES256'Vous savez maintenant comment ajouter une couche de protection supplémentaire à vos objets à l'aide de l'algorithme de chiffrement côté serveur AES-256 proposé par AWS.
Espace de rangement
Chaque objet que vous ajoutez à votre compartiment S3 est associé à unstorage class. Toutes les classes de stockage disponibles offrent une grande durabilité. Vous choisissez la façon dont vous souhaitez stocker vos objets en fonction des exigences d'accès aux performances de votre application.
À l'heure actuelle, vous pouvez utiliser les classes de stockage suivantes avec S3:
-
STANDARD: valeur par défaut pour les données fréquemment consultées
-
STANDARD_IA: pour les données rarement utilisées qui doivent être récupérées rapidement sur demande
-
ONEZONE_IA: pour le même cas d'utilisation que STANDARD_IA, mais stocke les données dans une zone de disponibilité au lieu de trois
-
REDUCED_REDUNDANCY: pour les données non critiques fréquemment utilisées et facilement reproductibles
Si vous souhaitez modifier la classe de stockage d'un objet existant, vous devez recréer l'objet.
Par exemple, remettez en ligne lethird_object et définissez sa classe de stockage surStandard_IA:
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256',
'StorageClass': 'STANDARD_IA'})Note: Si vous apportez des modifications à votre objet, vous constaterez peut-être que votre instance locale ne les affiche pas. Ce que vous devez faire à ce stade est d'appeler.reload() pour récupérer la dernière version de votre objet.
Rechargez l'objet et vous pouvez voir sa nouvelle classe de stockage:
>>>
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'Note: UtilisezLifeCycle Configurations pour faire la transition d'objets entre les différentes classes lorsque vous en trouvez le besoin. Ils effectueront automatiquement la transition de ces objets pour vous.
Versioning
Vous devez utiliser le contrôle de version pour conserver un enregistrement complet de vos objets au fil du temps. Il agit également comme un mécanisme de protection contre la suppression accidentelle de vos objets. Lorsque vous demandez un objet versionné, Boto3 récupère la dernière version.
Lorsque vous ajoutez une nouvelle version d'un objet, le stockage que cet objet prend au total est la somme de la taille de ses versions. Donc, si vous stockez un objet de 1 Go et que vous créez 10 versions, vous devez payer 10 Go de stockage.
Activez le contrôle de version pour le premier compartiment. Pour ce faire, vous devez utiliser la classeBucketVersioning:
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)>>>
>>> enable_bucket_versioning(first_bucket_name)
EnabledCréez ensuite deux nouvelles versions pour le premier fichierObject, une avec le contenu du fichier d'origine et une avec le contenu du troisième fichier:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
first_file_name)
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
third_file_name)Maintenant, téléchargez à nouveau le deuxième fichier, ce qui créera une nouvelle version:
s3_resource.Object(first_bucket_name, second_file_name).upload_file(
second_file_name)Vous pouvez récupérer la dernière version disponible de vos objets comme ceci:
>>>
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'Dans cette section, vous avez vu comment utiliser certains des attributs S3 les plus importants et les ajouter à vos objets. Ensuite, vous verrez comment parcourir facilement vos compartiments et objets.
Traversées
Si vous devez récupérer des informations ou appliquer une opération à toutes vos ressources S3, Boto3 vous propose plusieurs façons de parcourir de manière itérative vos compartiments et vos objets. Vous commencerez par parcourir tous vos compartiments créés.
Traversée du godet
Pour parcourir tous les buckets de votre compte, vous pouvez utiliser l'attributbuckets de la ressource à côté de.all(), ce qui vous donne la liste complète des instances deBucket:
>>>
>>> for bucket in s3_resource.buckets.all():
... print(bucket.name)
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Vous pouvez également utiliser lesclient pour récupérer les informations du compartiment, mais le code est plus complexe, car vous devez l'extraire du dictionnaire renvoyé parclient:
>>>
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Vous avez vu comment parcourir les compartiments que vous avez dans votre compte. Dans la section à venir, vous allez choisir l'un de vos compartiments et afficher de manière itérative les objets qu'il contient.
Traversée d'objet
Si vous souhaitez répertorier tous les objets d'un compartiment, le code suivant va générer un itérateur pour vous:
>>>
>>> for obj in first_bucket.objects.all():
... print(obj.key)
...
127367firstfile.txt
616abesecondfile.txt
fb937cthirdfile.txtLa variableobj est unObjectSummary. Il s'agit d'une représentation légère d'unObject. La version récapitulative ne prend pas en charge tous les attributs duObject. Si vous devez y accéder, utilisez la sous-ressourceObject() pour créer une nouvelle référence à la clé stockée sous-jacente. Ensuite, vous pourrez extraire les attributs manquants:
>>>
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}Vous pouvez désormais effectuer de manière itérative des opérations sur vos compartiments et objets. Vous avez presque fini. Il y a encore une chose que vous devez savoir à ce stade: comment supprimer toutes les ressources que vous avez créées dans ce didacticiel.
Suppression de compartiments et d'objets
Pour supprimer tous les compartiments et objets que vous avez créés, vous devez d'abord vous assurer que vos compartiments ne contiennent aucun objet.
Suppression d'un compartiment non vide
Pour pouvoir supprimer un bucket, vous devez d'abord supprimer chaque objet du bucket, sinon l'exceptionBucketNotEmpty sera déclenchée. Lorsque vous disposez d'un compartiment versionné, vous devez supprimer chaque objet et toutes ses versions.
Si vous trouvez qu'une règle LifeCycle qui le fera automatiquement pour vous ne convient pas à vos besoins, voici comment vous pouvez supprimer par programme les objets:
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})Le code ci-dessus fonctionne, que vous ayez ou non activé la gestion des versions sur votre compartiment. Sinon, la version des objets sera nulle. Vous pouvez regrouper jusqu'à 1000 suppressions en un seul appel d'API, en utilisant.delete_objects() sur votre instanceBucket, ce qui est plus rentable que la suppression individuelle de chaque objet.
Exécutez la nouvelle fonction sur le premier compartiment pour supprimer tous les objets versionnés:
>>>
>>> delete_all_objects(first_bucket_name)
[{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]Comme test final, vous pouvez télécharger un fichier dans le deuxième compartiment. Le contrôle de version n'est pas activé dans ce compartiment et la version sera donc nulle. Appliquez la même fonction pour supprimer le contenu:
>>>
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]Vous avez réussi à supprimer tous les objets de vos deux compartiments. Vous êtes maintenant prêt à supprimer les compartiments.
Suppression de compartiments
Pour terminer, vous utiliserez.delete() sur votre instanceBucket pour supprimer le premier bucket:
s3_resource.Bucket(first_bucket_name).delete()Si vous le souhaitez, vous pouvez utiliser la versionclient pour supprimer le deuxième compartiment:
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)Les deux opérations ont réussi car vous avez vidé chaque compartiment avant de tenter de le supprimer.
Vous avez maintenant exécuté certaines des opérations les plus importantes que vous pouvez effectuer avec S3 et Boto3. Félicitations d'avoir réussi jusqu'ici! En prime, examinons certains des avantages de la gestion des ressources S3 avec Infrastructure en tant que code.
Code Python ou infrastructure en tant que code (IaC)?
Comme vous l'avez vu, la plupart des interactions que vous avez eues avec S3 dans ce didacticiel concernaient des objets. Vous n'avez pas vu de nombreuses opérations liées au compartiment, telles que l'ajout de stratégies au compartiment, l'ajout d'une règle LifeCycle pour faire la transition de vos objets à travers les classes de stockage, les archiver sur Glacier ou les supprimer complètement ou imposer que tous les objets soient chiffrés en configurant Bucket Chiffrement.
La gestion manuelle de l'état de vos compartiments via les clients ou les ressources de Boto3 devient de plus en plus difficile à mesure que votre application commence à ajouter d'autres services et devient plus complexe. Pour surveiller votre infrastructure de concert avec Boto3, envisagez d'utiliser un outil Infrastructure as Code (IaC) tel que CloudFormation ou Terraform pour gérer l'infrastructure de votre application. L'un ou l'autre de ces outils maintiendra l'état de votre infrastructure et vous informera des modifications que vous avez appliquées.
Si vous décidez d'emprunter cette voie, gardez à l'esprit les points suivants:
-
Toute opération liée au compartiment qui modifie le compartiment de quelque manière que ce soit doit être effectuée via IaC.
-
Si vous souhaitez que tous vos objets agissent de la même manière (tous cryptés ou tous publics, par exemple), il existe généralement un moyen de le faire directement à l'aide d'IaC, en ajoutant une stratégie de compartiment ou une propriété de compartiment spécifique.
-
Les opérations de lecture de compartiment, telles que l'itération à travers le contenu d'un compartiment, doivent être effectuées à l'aide de Boto3.
-
Les opérations liées aux objets au niveau d'un objet individuel doivent être effectuées à l'aide de Boto3.
Conclusion
Félicitations d'avoir atteint la fin de ce tutoriel!
Vous êtes maintenant équipé pour commencer à travailler par programmation avec S3. Vous savez maintenant comment créer des objets, les télécharger sur S3, télécharger leur contenu et modifier leurs attributs directement à partir de votre script, tout en évitant les pièges courants avec Boto3.
Que ce didacticiel soit un tremplin dans votre cheminement vers la construction de quelque chose de génial à l'aide d'AWS!
Lectures complémentaires
Si vous souhaitez en savoir plus, consultez les informations suivantes: