introduction
Ce tutoriel couvrira la configuration d'un cluster Hadoop sur DigitalOcean. LeHadoop software library est un framework Apache qui vous permet de traiter de grands ensembles de données de manière distribuée sur des clusters de serveurs en exploitant des modèles de programmation de base. L'évolutivité fournie par Hadoop vous permet de passer de serveurs uniques à des milliers de machines. Il fournit également une détection des défaillances au niveau de l'application afin de pouvoir détecter et gérer les défaillances en tant que service à haute disponibilité.
Nous allons travailler avec 4 modules importants dans ce tutoriel:
-
Hadoop Common est la collection d'utilitaires et de bibliothèques communs nécessaires pour prendre en charge d'autres modules Hadoop.
-
LeHadoop Distributed File System (HDFS), comme indiqué parthe Apache organization, est un système de fichiers distribué hautement tolérant aux pannes, spécialement conçu pour fonctionner sur du matériel standard pour traiter de grands ensembles de données.
-
Hadoop YARN est le cadre utilisé pour la planification des travaux et la gestion des ressources de cluster.
-
Hadoop MapReduce est un système basé sur YARN pour le traitement parallèle de grands ensembles de données.
Dans ce didacticiel, nous allons configurer et exécuter un cluster Hadoop sur quatre droplets DigitalOcean.
Conditions préalables
Ce tutoriel nécessitera les éléments suivants:
-
Quatre gouttelettes Ubuntu 16.04 configurées avec des utilisateurs sudo non root. Si vous ne disposez pas de cette configuration, suivez les étapes 1 à 4 desInitial Server Setup with Ubuntu 16.04. Ce tutoriel supposera que vous utilisez une clé SSH depuis un ordinateur local. Selon le langage de Hadoop, nous allons faire référence à ces gouttelettes sous les noms suivants:
-
hadoop-master -
hadoop-worker-01 -
hadoop-worker-02 -
hadoop-worker-03
-
-
En outre, vous souhaiterez peut-être utiliserDigitalOcean Snapshots après la configuration initiale du serveur et la fin desSteps 1 et2 (ci-dessous) de votre premier Droplet.
Avec ces conditions préalables en place, vous serez prêt à commencer à configurer un cluster Hadoop.
[[step-1 -—- installation-setup-for-each-droplet]] == Étape 1 - Configuration de l'installation pour chaque droplet
Nous allons installer Java et Hadoop sureach de nosfour Droplets. Si vous ne souhaitez pas répéter chaque étape sur chaque Droplet, vous pouvez utiliserDigitalOcean Snapshots à la fin deStep 2 afin de répliquer votre installation et configuration initiales.
Tout d’abord, nous allons mettre à jour Ubuntu avec les derniers correctifs logiciels disponibles:
sudo apt-get update && sudo apt-get -y dist-upgradeEnsuite, installons la version sans tête de Java pour Ubuntu sur chaque Droplet. «Sans tête» fait référence au logiciel capable de fonctionner sur un périphérique sans interface utilisateur graphique.
sudo apt-get -y install openjdk-8-jdk-headlessPour installer Hadoop sur chaque Droplet, créons le répertoire dans lequel Hadoop sera installé. Nous pouvons l'appelermy-hadoop-install puis nous déplacer dans ce répertoire.
mkdir my-hadoop-install && cd my-hadoop-installUne fois que nous avons créé le répertoire, installons le binaire le plus récent à partir desHadoop releases list. Au moment de ce tutoriel, le plus récent estHadoop 3.0.1.
[.note] #Note: gardez à l'esprit que ces téléchargements sont distribués via des sites miroirs, et il est recommandé de vérifier d'abord les falsifications à l'aide de GPG ou SHA-256.
#
Lorsque vous êtes satisfait du téléchargement que vous avez sélectionné, vous pouvez utiliser la commandewget avec le lien binaire que vous avez choisi, tel que:
wget http://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gzUne fois votre téléchargement terminé, décompressez le contenu du fichier à l'aide detar, un outil d'archivage de fichiers pour Ubuntu:
tar xvzf hadoop-3.0.1.tar.gzNous sommes maintenant prêts à commencer notre configuration initiale.
[[step-2 -—- update-hadoop-environment-configuration]] == Étape 2 - Mettre à jour la configuration de l'environnement Hadoop
Pour chaque nœud Droplet, nous devrons configurerJAVA_HOME. Ouvrez le fichier suivant avec nano ou un autre éditeur de texte de votre choix afin que nous puissions le mettre à jour:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shMettez à jour la section suivante, où se trouveJAVA_HOME:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Pour ressembler à ceci:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Nous devrons également ajouter des variables d’environnement pour exécuter Hadoop et ses modules. Ils doivent être ajoutés au bas du fichier pour qu'il ressemble à ce qui suit, oùsammy serait le nom d'utilisateur de votre utilisateur sudo non root.
[.note] #Note: Si vous utilisez un nom d'utilisateur différent dans vos Droplets de cluster, vous devrez modifier ce fichier afin de refléter le nom d'utilisateur correct pour chaque Droplet spécifique.
#
hadoop-env.sh
...
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
export HDFS_NAMENODE_USER="sammy"
export HDFS_DATANODE_USER="sammy"
export HDFS_SECONDARYNAMENODE_USER="sammy"
export YARN_RESOURCEMANAGER_USER="sammy"
export YARN_NODEMANAGER_USER="sammy"À ce stade, vous pouvez enregistrer et quitter le fichier. Ensuite, exécutez la commande suivante pour appliquer nos exportations:
source ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shAvec le scripthadoop-env.sh mis à jour et généré, nous devons créer un répertoire de données pour le système de fichiers distribués Hadoop (HDFS) afin de stocker tous les fichiersHDFS pertinents.
sudo mkdir -p /usr/local/hadoop/hdfs/dataDéfinissez les autorisations pour ce fichier avec votre utilisateur respectif. N'oubliez pas que si vous avez différents noms d'utilisateur sur chaque Droplet, veillez à autoriser votre utilisateur sudo respectif à disposer des autorisations suivantes:
sudo chown -R sammy:sammy /usr/local/hadoop/hdfs/dataSi vous souhaitez utiliser un instantané DigitalOcean pour répliquer ces commandes sur vos nœuds Droplet, vous pouvez créer votre instantané maintenant et créer de nouvelles gouttelettes à partir de cette image. Pour obtenir des conseils à ce sujet, vous pouvez lireAn Introduction to DigitalOcean Snapshots.
Lorsque vous avez terminé les étapes ci-dessus sur les gouttelettes Ubuntu deall four, vous pouvez passer à la finalisation de cette configuration sur les nœuds.
[[step-3 -—- complete-initial-configuration-for-each-node]] == Étape 3 - Terminer la configuration initiale pour chaque nœud
À ce stade, nous devons mettre à jour le fichiercore_site.xml pourall 4 de vos nœuds Droplet. Dans chaque Droplet, ouvrez le fichier suivant:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/core-site.xmlVous devriez voir les lignes suivantes:
core-site.xml
...
Modifiez le fichier pour qu'il ressemble au XML suivant afin que nous incluionseach Droplet’s respective IP à l'intérieur de la valeur de la propriété, où nous avons écritserver-ip. Si vous utilisez un pare-feu, vous devez ouvrir le port 9000.
core-site.xml
...
fs.defaultFS
hdfs://server-ip:9000
Répétez l'écriture ci-dessus dans l'adresse IP Droplet appropriée pourall four de vos serveurs.
Maintenant, tous les paramètres généraux de Hadoop doivent être mis à jour pour chaque nœud de serveur et nous pouvons continuer à connecter nos nœuds via des clés SSH.
[[step-4 -—- set-up-ssh-for-each-node]] == Étape 4 - Configurer SSH pour chaque nœud
Pour que Hadoop fonctionne correctement, nous devons configurer SSH sans mot de passe entre le nœud maître et les nœuds worker (la langue demaster etworker est la langue de Hadoop pour faire référence àprimary et serveurssecondary).
Pour ce tutoriel, le nœud maître serahadoop-master et les nœuds de travail seront collectivement appeléshadoop-worker, mais vous en aurez trois au total (appelés-01, -02 et-03). Nous devons d'abord créer une paire de clés publique-privée sur le nœud maître, qui sera le nœud avec l'adresse IP appartenant àhadoop-master.
Sur le droplethadoop-master, exécutez la commande suivante. Vous appuierez surenter pour utiliser la valeur par défaut pour l’emplacement de la clé, puis appuyez deux fois surenter pour utiliser une phrase de passe vide:
ssh-keygenPour chacun des nœuds worker, nous devons prendre la clé publique du nœud maître et la copier dans le fichierauthorized_keysde chacun des nœuds worker.
Obtenez la clé publique du nœud maître en exécutantcat sur le fichierid_rsa.pub situé dans votre dossier.ssh, pour imprimer sur la console:
cat ~/.ssh/id_rsa.pubConnectez-vous maintenant à chaque droplet de nœud de travail et ouvrez le fichierauthorized_keys:
nano ~/.ssh/authorized_keysVous copiez la clé publique du nœud maître - qui est la sortie que vous avez générée à partir de la commandecat ~/.ssh/id_rsa.pub sur le nœud maître - dans le fichier~/.ssh/authorized_keys respectif de chaque droplet. Assurez-vous de sauvegarder chaque fichier avant de fermer.
Lorsque vous avez terminé de mettre à jour les 3 nœuds de calcul, copiez également la clé publique du nœud maître dans son propre fichierauthorized_keys en exécutant la même commande:
nano ~/.ssh/authorized_keysSurhadoop-master, vous devez configurer la configuration dessh pour inclure chacun des noms d'hôte des nœuds associés. Ouvrez le fichier de configuration pour le modifier, en utilisant nano:
nano ~/.ssh/configVous devez modifier le fichier pour qu'il ressemble à ce qui suit, avec les adresses IP et les noms d'utilisateur pertinents ajoutés.
config
Host hadoop-master-server-ip
HostName hadoop-example-node-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-01-server-ip
HostName hadoop-worker-01-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-02-server-ip
HostName hadoop-worker-02-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-03-server-ip
HostName hadoop-worker-03-server-ip
User sammy
IdentityFile ~/.ssh/id_rsaEnregistrez et fermez le fichier.
À partir deshadoop-master, SSH dans chaque nœud:
ssh sammy@hadoop-worker-01-server-ipComme vous vous connectez pour la première fois à chaque noeud avec le système actuel configuré, il vous demandera ce qui suit:
Outputare you sure you want to continue connecting (yes/no)?Répondez à l'invite avecyes. Ce sera le seul moment où cela doit être fait, mais cela est requis pour chaque nœud de travail pour la connexion SSH initiale. Enfin, déconnectez-vous de chaque nœud de travail pour revenir àhadoop-master:
logoutAssurez-vous derepeat these steps pour les deux nœuds de travail restants.
Maintenant que nous avons correctement configuré SSH sans mot de passe pour chaque nœud de travail, nous pouvons maintenant continuer à configurer le nœud maître.
[[step-5 -—- configure-the-master-node]] == Étape 5 - Configurer le nœud maître
Pour notre cluster Hadoop, nous devons configurer les propriétés HDFS sur le noeud maître Droplet.
Sur le nœud maître, éditez le fichier suivant:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlModifiez la sectionconfiguration pour qu'elle ressemble au XML ci-dessous:
hdfs-site.xml
...
dfs.replication
3
dfs.namenode.name.dir
file:///usr/local/hadoop/hdfs/data
Enregistrez et fermez le fichier.
Nous allons ensuite configurer les propriétésMapReduce sur le nœud maître. Ouvrezmapred.site.xml avec nano ou un autre éditeur de texte:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mapred-site.xmlPuis mettez à jour le fichier pour qu’il ressemble à ceci, avec l’adresse IP de votre serveur actuel reflétée ci-dessous:
mapred-site.xml
...
mapreduce.jobtracker.address
hadoop-master-server-ip:54311
mapreduce.framework.name
yarn
Enregistrez et fermez le fichier. Si vous utilisez un pare-feu, veillez à ouvrir le port 54311.
Ensuite, configurez YARN sur le nœud maître. Encore une fois, nous mettons à jour la section de configuration d’un autre fichier XML, alors ouvrons le fichier:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/yarn-site.xmlMaintenant, mettez à jour le fichier, en vous assurant de saisir l'adresse IP de votre serveur actuel:
yarn-site.xml
...
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop-master-server-ip
Enfin, configurons le point de référence de Hadoop pour ce que devraient être les nœuds maître et travailleur. Tout d'abord, ouvrez le fichiermasters:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mastersDans ce fichier, vous ajouterez l’adresse IP de votre serveur actuel:
maîtrise
hadoop-master-server-ipMaintenant, ouvrez et éditez le fichierworkers:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/workersIci, vous allez ajouter les adresses IP de chacun de vos nœuds de calcul, sous où il est indiquélocalhost.
travailleurs
localhost
hadoop-worker-01-server-ip
hadoop-worker-02-server-ip
hadoop-worker-03-server-ipAprès avoir terminé la configuration des propriétésMapReduce etYARN, nous pouvons maintenant terminer la configuration des nœuds worker.
[[step-6 -—- configure-the-worker-nodes]] == Étape 6 - Configurer les nœuds de travail
Nous allons maintenant configurer les nœuds de travail afin qu’ils aient chacun la référence correcte au répertoire de données pour HDFS.
Sureach worker node, modifiez ce fichier XML:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlRemplacez la section de configuration par ce qui suit:
hdfs-site.xml
dfs.replication
3
dfs.datanode.data.dir
file:///usr/local/hadoop/hdfs/data
Enregistrez et fermez le fichier. Assurez-vous de répliquer cette étape surall three de vos nœuds worker.
À ce stade, nos Droplets de nœud de travail pointent vers le répertoire de données pour HDFS, ce qui nous permettra d’exécuter notre cluster Hadoop.
[[step-7 -—- run-the-hadoop-cluster]] == Étape 7 - Exécutez le cluster Hadoop
Nous avons atteint un point où nous pouvons démarrer notre cluster Hadoop. Avant de commencer, nous devons formater le HDFS sur le nœud maître. Sur le noeud maître Droplet, modifiez les répertoires dans lesquels Hadoop est installé:
cd ~/my-hadoop-install/hadoop-3.0.1/Ensuite, exécutez la commande suivante pour formater HDFS:
sudo ./bin/hdfs namenode -formatUn formatage réussi du namenode entraînera beaucoup de sortie, composée principalement d'instructionsINFO. En bas, vous verrez ce qui suit, confirmant que vous avez correctement formaté le répertoire de stockage.
Output...
2018-01-28 17:58:08,323 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/data has been successfully formatted.
2018-01-28 17:58:08,346 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 using no compression
2018-01-28 17:58:08,490 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds.
2018-01-28 17:58:08,505 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-01-28 17:58:08,519 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-example-node/127.0.1.1
************************************************************/Maintenant, démarrez le cluster Hadoop en exécutant les scripts suivants (assurez-vous de vérifier les scripts avant de les exécuter à l'aide de la commandeless):
sudo ./sbin/start-dfs.shVous verrez alors une sortie contenant les éléments suivants:
OutputStarting namenodes on [hadoop-master-server-ip]
Starting datanodes
Starting secondary namenodes [hadoop-master]Ensuite, lancez YARN en utilisant le script suivant:
./sbin/start-yarn.shLa sortie suivante apparaîtra:
OutputStarting resourcemanager
Starting nodemanagersUne fois ces commandes exécutées, les démons doivent s'exécuter sur le nœud maître et un sur chacun des nœuds de travail.
Nous pouvons vérifier les démons en exécutant la commandejps pour vérifier les processus Java:
jpsAprès avoir exécuté la commandejps, vous verrez que lesNodeManager,SecondaryNameNode,Jps,NameNode,ResourceManager etDataNode sont en cours d'exécution. Quelque chose de semblable à la sortie suivante apparaîtra:
Output9810 NodeManager
9252 SecondaryNameNode
10164 Jps
8920 NameNode
9674 ResourceManager
9051 DataNodeCela vérifie que nous avons créé un cluster et que les démons Hadoop sont en cours d'exécution.
Dans un navigateur Web de votre choix, vous pouvez obtenir un aperçu de la santé de votre cluster en naviguant jusqu'à:
http://hadoop-master-server-ip:9870Si vous avez un pare-feu, veillez à ouvrir le port 9870. Vous verrez quelque chose qui ressemble à ce qui suit:
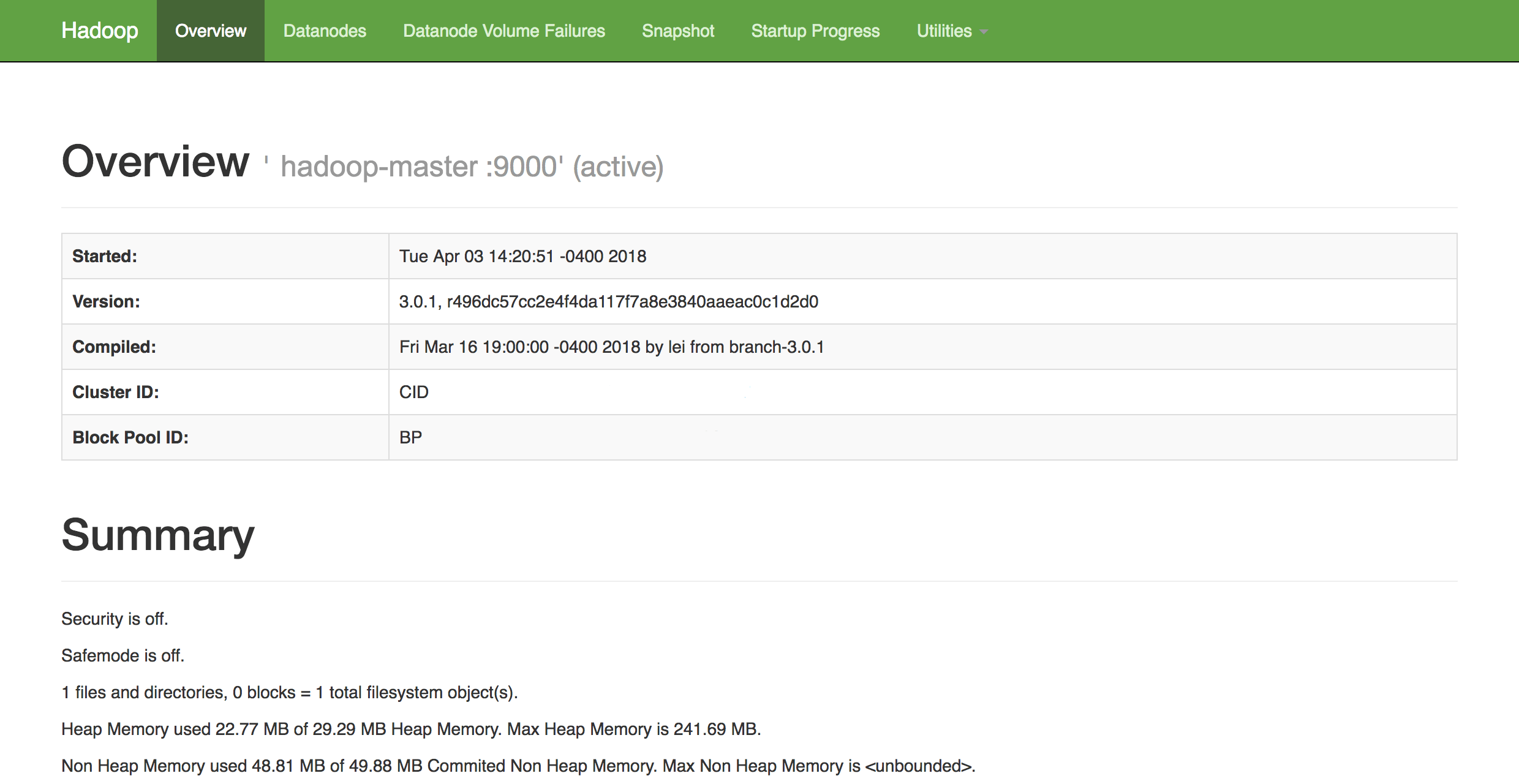
De là, vous pouvez accéder à l'élémentDatanodes dans la barre de menus pour voir l'activité du nœud.
Conclusion
Dans ce didacticiel, nous avons expliqué comment configurer et configurer un cluster à plusieurs nœuds Hadoop à l'aide de droplets DigitalOcean Ubuntu 16.04. Vous pouvez également désormais surveiller et vérifier l’intégrité de votre cluster à l’aide de l’interface Web Dado Health de Hadoop.
Pour avoir une idée des projets possibles sur lesquels vous pouvez travailler pour utiliser votre cluster nouvellement configuré, consultez la longue liste de projets d'Apachepowered by Hadoop.