introduction
Le cluster MySQL est une technologie logicielle offrant une disponibilité et un débit élevés. Si vous connaissez déjà d'autres technologies de cluster, vous trouverez un cluster MySQL similaire à celui-ci. En bref, il existe un ou plusieurs nœuds de gestion qui contrôlent les nœuds de données (où les données sont stockées). Après avoir consulté le nœud de gestion, les clients (clients MySQL, serveurs ou API natives) se connectent directement aux nœuds de données.
Vous vous demandez peut-être comment la réplication MySQL est liée au cluster MySQL. Avec le cluster, il n'y a pas de réplication typique des données, mais une synchronisation des noeuds de données. À cette fin, un moteur de données spécial doit être utilisé - NDBCluster (NDB). Considérez le cluster comme un environnement MySQL logique unique avec des composants redondants. Ainsi, un cluster MySQL peut participer à la réplication avec d'autres clusters MySQL.
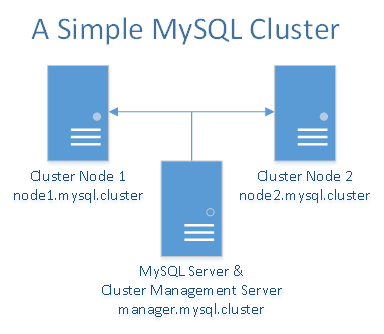
Le cluster MySQL fonctionne mieux dans un environnement sans partage. Idéalement, deux composants ne devraient pas partager le même matériel. Pour des raisons de simplicité et de démonstration, nous nous limiterons à utiliser trois gouttelettes. Deux gouttelettes agissant en tant que nœuds de données synchronisent les données entre elles. Le troisième Droplet sera utilisé pour le gestionnaire de cluster et simultanément pour le serveur / client MySQL. Si vous avez plus de Droplets, vous pouvez ajouter plus de nœuds de données, séparer le gestionnaire de cluster du serveur / client MySQL et même ajouter d'autres Droplets en tant que gestionnaires de cluster et serveurs / clients MySQL.
Conditions préalables
Vous aurez besoin d'un total de trois Droplets - un Droplet pour le gestionnaire de cluster MySQL et le serveur / client MySQL et deux Droplets pour les nœuds de données MySQL redondants.
Dans lessame DigitalOcean data center, créez les gouttelettes suivantes avecprivate networking enabled:
-
Trois gouttelettes Ubuntu 16.04 avec un minimum de 1 Go de RAM etprivate networking activé
-
Utilisateur non root avec des privilèges sudo pour chaque droplet (Initial Server Setup with Ubuntu 16.04 explique comment configurer cela.)
Le cluster MySQL stocke beaucoup d'informations dans la RAM. Chaque Droplet doit avoir au moins 1 Go de RAM.
Comme mentionné dans lesprivate networking tutorial, assurez-vous de configurer des enregistrements personnalisés pour les 3 gouttelettes. Dans un souci de simplicité et de commodité, nous utiliserons les enregistrements personnalisés suivants pour chaque droplet dans le fichier/etc/hosts:
10.XXX.XX.X node1.mysql.cluster
10.YYY.YY.Y node2.mysql.cluster
10.ZZZ.ZZ.Z manager.mysql.cluster
Veuillez remplacer les adresses IP surlignées par les adresses IP privées de vos gouttelettes en conséquence.
Sauf indication contraire, toutes les commandes nécessitant des privilèges root dans ce tutoriel doivent être exécutées en tant qu'utilisateur non root avec des privilèges sudo.
[[step-1 -—- téléchargement-et-installation-mysql-cluster]] == Étape 1 - Téléchargement et installation de MySQL Cluster
Au moment de la rédaction de ce didacticiel, la dernière version sous licence GPL du cluster MySQL est 7.4.11. Le produit est construit sur MySQL 5.6 et comprend:
-
Logiciel de gestion de cluster
-
Logiciel de gestion de noeud de données
-
Fichiers binaires client et serveur MySQL 5.6
Vous pouvez télécharger la version gratuite du cluster MySQL généralement disponible (GA) à partir duofficial MySQL cluster download page. Sur cette page, choisissez le paquet de plateforme Linux Debian, qui convient également à Ubuntu. Veillez également à sélectionner la version 32 bits ou 64 bits en fonction de l'architecture de vos gouttelettes. Téléchargez le package d'installation sur chacune de vos gouttelettes.
Les instructions d’installation seront les mêmes pour toutes les gouttelettes, alors suivez ces étapes sur les 3 gouttelettes.
Avant de démarrer l'installation, le packagelibaio1 doit être installé car il s'agit d'une dépendance:
sudo apt-get install libaio1Après cela, installez le package de cluster MySQL:
sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.debVous pouvez maintenant trouver l'installation du cluster MySQL dans le répertoire/opt/mysql/server-5.6/. Nous travaillerons en particulier avec le répertoire bin (/opt/mysql/server-5.6/bin/) où se trouvent tous les binaires.
Les mêmes étapes d'installation doivent être effectuées sur les trois Droplets, indépendamment du fait que chacune aura une fonction différente - gestionnaire ou nœud de données.
Ensuite, nous allons configurer le gestionnaire de cluster MySQL sur chaque Droplet.
[[step-2 -—- configuration-and-startup-the-cluster-manager]] == Étape 2 - Configuration et démarrage du Cluster Manager
Dans cette étape, nous allons configurer le gestionnaire de cluster MySQL (manager.mysql.cluster). Sa configuration correcte assurera une synchronisation correcte et une répartition de la charge entre les nœuds de données. Toutes les commandes doivent être exécutées sur Dropletmanager.mysql.cluster.
Le gestionnaire de cluster est le premier composant à démarrer dans n'importe quel cluster. Il a besoin d'un fichier de configuration qui est passé comme argument à son fichier binaire. Pour plus de commodité, nous utiliserons le fichier/var/lib/mysql-cluster/config.ini pour sa configuration.
Sur le dropletmanager.mysql.cluster, créez d'abord le répertoire dans lequel ce fichier résidera (/var/lib/mysql-cluster):
sudo mkdir /var/lib/mysql-clusterCréez ensuite un fichier et commencez à le modifier avec nano:
sudo nano /var/lib/mysql-cluster/config.iniCe fichier doit contenir le code suivant:
/var/lib/mysql-cluster/config.ini
[ndb_mgmd]
# Management process options:
hostname=manager.mysql.cluster # Hostname of the manager
datadir=/var/lib/mysql-cluster # Directory for the log files
[ndbd]
hostname=node1.mysql.cluster # Hostname of the first data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[ndbd]
hostname=node2.mysql.cluster # Hostname of the second data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[mysqld]
# SQL node options:
hostname=manager.mysql.cluster # In our case the MySQL server/client is on the same Droplet as the cluster managerPour chacun des composants ci-dessus, nous avons défini un paramètrehostname. Il s'agit d'une mesure de sécurité importante car seul le nom d'hôte spécifié sera autorisé à se connecter au gestionnaire et à participer au cluster en fonction de son rôle désigné.
De plus, les paramètreshostname spécifient sur quelle interface le service sera exécuté. Ceci est important et est important pour la sécurité, car dans notre cas, les noms d'hôte ci-dessus pointent vers les adresses IP privées que nous avons spécifiées dans les fichiers/etc/hosts. Ainsi, vous ne pouvez accéder à aucun des services ci-dessus en dehors du réseau privé.
Dans le fichier ci-dessus, vous pouvez ajouter davantage de composants redondants tels que des nœuds de données (ndbd) ou des serveurs MySQL (mysqld) en définissant simplement des instances supplémentaires de la même manière.
Vous pouvez maintenant démarrer le gestionnaire pour la première fois en exécutant le binairendb_mgmd et en spécifiant le fichier de configuration avec l'argument-f comme ceci:
sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.iniVous devriez voir un message sur le démarrage réussi similaire à ceci:
Output of ndb_mgmdMySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11Vous voudriez probablement que le service de gestion démarre automatiquement avec le serveur. La version du cluster GA n’est pas livrée avec un script de démarrage approprié, mais quelques-uns sont disponibles en ligne. Pour le début, vous pouvez simplement ajouter la commande de démarrage au fichier/etc/rc.local et le service sera automatiquement démarré lors du démarrage. Cependant, vous devrez d'abord vous assurer que/etc/rc.local est exécuté lors du démarrage du serveur. Dans Ubuntu 16.04, cela nécessite l'exécution d'une commande supplémentaire:
sudo systemctl enable rc-local.serviceEnsuite, ouvrez le fichier/etc/rc.local pour le modifier:
sudo nano /etc/rc.localAjoutez-y la commande start avant la ligneexit comme ceci:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0Enregistrez et quittez le fichier.
Le gestionnaire de cluster n'a pas à s'exécuter tout le temps. Il peut être démarré, arrêté et redémarré sans interruption du cluster. Il n'est requis que lors du démarrage initial des nœuds du cluster et du serveur / client MySQL.
[[step-3 -—- configuration-et-démarrage-des-nœuds de données]] == Étape 3 - Configuration et démarrage des nœuds de données
Ensuite, nous allons configurer les nœuds de données (node1.mysql.cluster etnode2.mysql.cluster) pour stocker les fichiers de données et prendre en charge correctement le moteur NDB. Toutes les commandes doivent être exécutées sur les deux nœuds. Vous pouvez commencer parnode1.mysql.cluster puis répéter exactement les mêmes étapes surnode2.mysql.cluster.
Les nœuds de données lisent la configuration à partir du fichier de configuration MySQL standard/etc/my.cnf et plus spécifiquement la partie après la ligne[mysql_cluster]. Créez ce fichier avec nano et commencez à le modifier:
sudo nano /etc/my.cnfSpécifiez le nom d'hôte du gestionnaire comme suit:
/etc/my.cnf
[mysql_cluster]
ndb-connectstring=manager.mysql.clusterEnregistrez et quittez le fichier.
La spécification de l'emplacement du gestionnaire est la seule configuration nécessaire au démarrage du moteur de noeud. Le reste de la configuration sera directement pris en charge par le gestionnaire. Dans notre exemple, le nœud de données découvrira que son répertoire de données est/usr/local/mysql/data selon la configuration du gestionnaire. Ce répertoire doit être créé sur le noeud. Vous pouvez le faire avec la commande:
sudo mkdir -p /usr/local/mysql/dataAprès cela, vous pouvez démarrer le noeud de données pour la première fois avec la commande:
sudo /opt/mysql/server-5.6/bin/ndbdAprès un démarrage réussi, vous devriez voir une sortie similaire:
Output of ndbd2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2Le service ndbd devrait être démarré automatiquement avec le serveur. La version du cluster GA n’est pas livrée avec un script de démarrage approprié pour cela non plus. Tout comme nous l'avons fait pour le gestionnaire de cluster, ajoutons la commande de démarrage au fichier/etc/rc.local. Encore une fois, vous devrez vous assurer que/etc/rc.local est exécuté lors du démarrage du serveur avec la commande:
sudo systemctl enable rc-local.serviceEnsuite, ouvrez le fichier/etc/rc.local pour le modifier:
sudo nano /etc/rc.localAjoutez la commande de démarrage avant la ligneexit comme ceci:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndbd
exit 0Enregistrez et quittez le fichier.
Une fois que vous avez terminé avec le premier nœud, répétez exactement les mêmes étapes sur l'autre nœud, qui estnode2.mysql.cluster dans notre exemple.
[[step-4 -—- configuration-et-démarrage-du-serveur-et-client-mysql]] == Étape 4 - Configuration et démarrage du serveur et du client MySQL
Un serveur MySQL standard, tel que celui disponible dans le référentiel apt par défaut d’Ubuntu, ne prend pas en charge le NDB du moteur de cluster MySQL. C’est pourquoi vous avez besoin d’une installation personnalisée du serveur MySQL. Le package de cluster que nous avons déjà installé sur les trois Droplets est livré avec un serveur MySQL et un client. Comme déjà mentionné, nous utiliserons le serveur et le client MySQL sur le nœud de gestion (manager.mysql.cluster).
La configuration est à nouveau stockée dans le fichier/etc/my.cnf par défaut. Surmanager.mysql.cluster, ouvrez le fichier de configuration:
sudo nano /etc/my.cnfAjoutez ensuite le texte suivant:
/etc/my.cnf
[mysqld]
ndbcluster # run NDB storage engine
...Enregistrez et quittez le fichier.
Conformément aux meilleures pratiques, le serveur MySQL doit fonctionner sous son propre utilisateur (mysql) qui appartient à son propre groupe (encore une foismysql). Alors, commençons par créer le groupe:
sudo groupadd mysqlCréez ensuite l'utilisateurmysql appartenant à ce groupe et assurez-vous qu'il ne peut pas utiliser le shell en définissant son chemin shell sur/bin/false comme ceci:
sudo useradd -r -g mysql -s /bin/false mysqlLa dernière exigence pour l’installation personnalisée du serveur MySQL est de créer la base de données par défaut. Vous pouvez le faire avec la commande:
sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysqlPour démarrer le serveur MySQL, nous utiliserons le script de démarrage de/opt/mysql/server-5.6/support-files/mysql.server. Copiez-le dans le répertoire des scripts d'initialisation par défaut sous le nommysqld comme ceci:
sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqldActivez le script de démarrage et ajoutez-le aux niveaux d'exécution par défaut à l'aide de la commande suivante:
sudo systemctl enable mysqld.serviceMaintenant, nous pouvons démarrer le serveur MySQL pour la première fois manuellement avec la commande:
sudo systemctl start mysqldEn tant que client MySQL, nous allons à nouveau utiliser le fichier binaire personnalisé fourni avec l’installation en cluster. Il a le chemin suivant:/opt/mysql/server-5.6/bin/mysql. Pour plus de commodité, créons un lien symbolique vers celui-ci dans le chemin par défaut de/usr/bin:
sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/Vous pouvez maintenant démarrer le client à partir de la ligne de commande en tapant simplementmysql comme ceci:
mysqlVous devriez voir une sortie semblable à:
Output of ndb_mgmdWelcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL)Pour quitter l'invite MySQL, tapez simplementquit ou appuyez simultanément surCTRL-D.
La vérification ci-dessus est la première à montrer que le cluster, le serveur et le client MySQL fonctionnent. Nous passerons ensuite à des tests plus détaillés pour vérifier que le cluster fonctionne correctement.
Tester le cluster
À ce stade, notre cluster MySQL simple avec un client, un serveur, un gestionnaire et deux nœuds de données doit être complet. À partir du droplet du gestionnaire de cluster (manager.mysql.cluster), ouvrez la console de gestion avec la commande:
sudo /opt/mysql/server-5.6/bin/ndb_mgmL'invite doit maintenant passer à la console de gestion de cluster. Cela ressemble à ceci:
Inside the ndb_mgm console-- NDB Cluster -- Management Client --
ndb_mgm>Une fois à l'intérieur de la console, exécutez la commandeSHOW comme ceci:
SHOWVous devriez voir une sortie similaire à celle-ci:
Output of ndb_mgmConnected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)Ce qui précède montre qu’il existe deux nœuds de données avec les identificateurs 2 et 3. Ils sont actifs et connectés. Il existe également un nœud de gestion avec l'identifiant 1 et un serveur MySQL avec l'identifiant 4. Vous pouvez trouver plus d'informations sur chaque identifiant en tapant son numéro avec la commandeSTATUS comme ceci:
2 STATUSLa commande ci-dessus vous montrerait le statut du noeud 2 avec ses versions MySQL et NDB:
Output of ndb_mgmNode 2: started (mysql-5.6.29 ndb-7.4.11)Pour quitter la console de gestion, tapezquit.
La console de gestion est très puissante et vous offre de nombreuses autres options pour gérer le cluster et ses données, notamment la création d’une sauvegarde en ligne. Pour plus d'informations, consultez lesofficial documentation.
Faisons maintenant un test avec le client MySQL. À partir du même Droplet, démarrez le client avec la commandemysql pour l'utilisateur root MySQL. Rappelez-vous que nous avons créé un lien symbolique plus tôt.
mysql -u root\ Votre console passera à la console client MySQL. Une fois dans le client MySQL, lancez la commande:
SHOW ENGINE NDB STATUS \GVous devriez maintenant voir toutes les informations sur le moteur de cluster NDB commençant par les détails de la connexion:
Output of mysql
*************************** 1. row ***************************
Type: ndbcluster
Name: connection
Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
...Les informations les plus importantes ci-dessus sont le nombre de nœuds prêts - 2. Cette redondance permettra à votre cluster MySQL de continuer à fonctionner même si l'un des nœuds de données tombe en panne. En même temps, vos requêtes SQL seront équilibrées entre les deux nœuds.
Vous pouvez essayer de fermer l'un des nœuds de données afin de tester la stabilité du cluster. La solution la plus simple consiste simplement à redémarrer Droplet dans son intégralité afin de tester complètement le processus de récupération. Vous verrez la valeur denumber_of_ready_data_nodes changer en1 et revenir à2 à nouveau lorsque le nœud est redémarré.
Travailler avec le moteur NDB
Pour voir le fonctionnement réel du cluster, créons une nouvelle table avec le moteur NDB et y insérons des données. Veuillez noter que pour utiliser la fonctionnalité de cluster, le moteur doit être NDB. Si vous utilisez InnoDB (valeur par défaut) ou tout autre moteur que NDB, vous n'utiliserez pas le cluster.
Commençons par créer une base de données appeléecluster avec la commande:
CREATE DATABASE cluster;Ensuite, passez à la nouvelle base de données:
USE cluster;Maintenant, créez une table simple appeléecluster_test comme ceci:
CREATE TABLE cluster_test (name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster;Nous avons explicitement spécifié ci-dessus le moteurndbcluster afin d'utiliser le cluster. Ensuite, nous pouvons commencer à insérer des données avec une requête comme celle-ci:
INSERT INTO cluster_test (name,value) VALUES('some_name','some_value');Pour vérifier que les données ont été insérées, exécutez une requête de sélection comme celle-ci:
SELECT * FROM cluster_test;Lorsque vous insérez et sélectionnez des données de ce type, vous équilibrez la charge de vos requêtes entre tous les nœuds de données disponibles, qui sont deux dans notre exemple. Avec cette évolution, vous bénéficiez à la fois de stabilité et de performance.
Conclusion
Comme nous l'avons vu dans cet article, la configuration d'un cluster MySQL peut être simple et facile. Bien entendu, de nombreuses options et fonctionnalités avancées méritent d'être maîtrisées avant de transférer le cluster dans votre environnement de production. Comme toujours, assurez-vous d'avoir un processus de test adéquat car certains problèmes pourraient être très difficiles à résoudre plus tard. Pour plus d'informations et de plus amples informations, veuillez consulter la documentation officielle deMySQL cluster.