introduction
Le package Pythonpandas est utilisé pour la manipulation et l'analyse des données, conçu pour vous permettre de travailler avec des données étiquetées ou relationnelles de manière intuitive.
Le packagepandas offre une fonctionnalité de feuille de calcul, mais comme vous travaillez avec Python, il est beaucoup plus rapide et efficace qu'un programme de feuille de calcul graphique traditionnel.
Dans ce tutoriel, nous allons passer en revue la configuration d'un ensemble de données volumineux avec lequel travailler, les fonctionsgroupby() etpivot_table() depandas, et enfin comment visualiser les données.
Pour vous familiariser avec le packagepandas, vous pouvez lire notre tutorielAn Introduction to the pandas Package and its Data Structures in Python 3.
Conditions préalables
Ce guide explique comment travailler avec des données enpandas sur un bureau local ou un serveur distant. Travailler avec de grands ensembles de données peut demander beaucoup de mémoire, donc dans les deux cas, l'ordinateur aura besoin d'au moins2GB of memory pour effectuer certains des calculs de ce guide.
Pour ce didacticiel, nous utiliseronsJupyter Notebook pour travailler avec les données. Si vous ne l'avez pas déjà, vous devriez suivre nostutorial to install and set up Jupyter Notebook for Python 3.
Configuration des données
Pour ce didacticiel, nous allons travailler avec les données de la sécurité sociale des États-Unis sur les noms de bébé disponibles à partir desSocial Security website sous forme de fichier zip de 8 Mo.
Activons notre environnement de programmation Python 3 sur noslocal machine, ou sur nosserver à partir du bon répertoire:
cd environments. my_env/bin/activateCréons maintenant un nouveau répertoire pour notre projet. On peut l'appelernames puis se déplacer dans le répertoire:
mkdir names
cd namesDans ce répertoire, nous pouvons extraire le fichier zip du site Web de la sécurité sociale avec la commandecurl:
curl -O https://www.ssa.gov/oact/babynames/names.zipUne fois le fichier téléchargé, vérifions que nous avons tous les packages installés que nous utiliserons:
-
numpypour prendre en charge les tableaux multidimensionnels -
matplotlibpour visualiser les données -
pandaspour notre analyse de données -
seabornpour rendre nos graphiques statistiques matplotlib plus esthétiques
Si aucun des packages n'est déjà installé, installez-les avecpip, comme dans:
pip install pandas
pip install matplotlib
pip install seabornLe packagenumpy sera également installé si vous ne l’avez pas déjà.
Nous pouvons maintenant lancer Jupyter Notebook:
jupyter notebookUne fois que vous êtes sur l'interface Web de Jupyter Notebook, vous y verrez le fichiernames.zip.
Pour créer un nouveau fichier notebook, sélectionnezNew>Python 3 dans le menu déroulant en haut à droite:
Cela ouvrira un cahier.
Commençons parimporting les packages que nous allons utiliser. En haut de notre cahier, nous devrions écrire ce qui suit:
import numpy as np
import matplotlib.pyplot as pp
import pandas as pd
import seabornNous pouvons exécuter ce code et passer à un nouveau bloc de code en tapantALT + ENTER.
Disons également à Python Notebook de garder nos graphiques en ligne:
matplotlib inlineExécutons le code et continuons en tapantALT + ENTER.
À partir de là, nous allons décompresser l'archive zip, charger l'ensemble de données CSV danspandas, puis concaténerpandasDataFrames.
Décompresser l'archive Zip
Pour décompresser l'archive zip dans le répertoire courant, nous allons importer le modulezipfile puis appeler la fonctionZipFile avec le nom du fichier (dans notre casnames.zip):
import zipfile
zipfile.ZipFile('names.zip').extractall('.')Nous pouvons exécuter le code et continuer en tapantALT + ENTER.
Maintenant, si vous regardez de nouveau dans votre répertoirenames, vous aurez les fichiers.txt de données de nom au format CSV. Ces fichiers correspondront aux années de données archivées, de 1881 à 2015. Chacun de ces fichiers suit une convention d'appellation similaire. Le fichier 2015, par exemple, s'appelleyob2015.txt, tandis que le fichier 1927 s'appelleyob1927.txt.
Pour examiner le format de l’un de ces fichiers, utilisons Python pour en ouvrir un et afficher les 5 premières lignes:
open('yob2015.txt','r').readlines()[:5]Exécutez le code et continuez avecALT + ENTER.
Output['Emma,F,20355\n',
'Olivia,F,19553\n',
'Sophia,F,17327\n',
'Ava,F,16286\n',
'Isabella,F,15504\n']La façon dont les données sont formatées est le nom en premier (comme dansEmma ouOlivia), le sexe ensuite (comme dansF pour le nom féminin etM pour le nom masculin) puis le nombre de bébés nés cette année-là avec ce nom (il y avait 20 355 bébés nommés Emma qui sont nés en 2015).
Avec ces informations, nous pouvons charger les données danspandas.
Charger les données CSV enpandas
Pour charger des données de valeurs séparées par des virgules danspandas, nous utiliserons la fonctionpd.read_csv(), en passant le nom du fichier texte ainsi que les noms de colonne que nous choisissons. Nous allons l'attribuer à une variable, dans ce casnames2015 puisque nous utilisons les données du fichier de l'année de naissance 2015.
names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])TapezALT + ENTER pour exécuter le code et continuer.
Pour vous assurer que cela fonctionne, affichons le haut du tableau:
names2015.head()Lorsque nous exécutons le code et continuons avecALT + ENTER, nous verrons une sortie qui ressemble à ceci:

Notre tableau contient maintenant des informations sur les noms, le sexe et le nombre de bébés nés avec chaque nom organisé par colonne.
Concaténer les objetspandas
La concaténation des objetspandas nous permettra de travailler avec tous les fichiers texte séparés dans le répertoirenames.
Pour concaténer ces derniers, nous devons d'abord initialiser une liste en affectant une variable à unlist data type non peuplé:
all_years = []Une fois que nous aurons fait cela, nous utiliserons unfor loop pour parcourir tous les fichiers par année, qui vont de 1880 à 2015. Nous ajouterons+1 à la fin de 2015 afin que 2015 soit inclus dans la boucle.
all_years = []
for year in range(1880, 2015+1):Dans la boucle, nous ajouterons à la liste chacune des valeurs du fichier texte, en utilisant unstring formatter pour gérer les différents noms de chacun de ces fichiers. Nous transmettrons ces valeurs à la variableyear. Encore une fois, nous allons spécifier les colonnes pourName,Sex et le nombre deBabies:
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))De plus, nous allons créer une colonne pour chacune des années afin de conserver les commandes. Nous pouvons le faire après chaque itération en utilisant l'index de-1 pour les pointer au fur et à mesure que la boucle progresse.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = yearEnfin, nous l’ajouterons à l’objetpandas avec concaténation à l’aide de la fonctionpd.concat(). Nous utiliserons la variableall_names pour stocker ces informations.
all_years = []
for year in range(1880, 2015+1):
all_years.append(pd.read_csv('yob{}.txt'.format(year),
names = ['Name', 'Sex', 'Babies']))
all_years[-1]['Year'] = year
all_names = pd.concat(all_years)Nous pouvons maintenant exécuter la boucle avecALT + ENTER, puis inspecter la sortie en appelant la queue (les lignes les plus basses) de la table résultante:
all_names.tail()
Notre ensemble de données est maintenant complet et prêt pour un travail supplémentaire avec lui enpandas.
Regroupement des données
Avecpandas, vous pouvez regrouper les données par colonnes avec la fonction.groupby(). En utilisant notre variableall_names pour notre ensemble de données complet, nous pouvons utilisergroupby() pour diviser les données en différents compartiments.
Groupons l’ensemble de données par sexe et par année. Nous pouvons le configurer comme suit:
group_name = all_names.groupby(['Sex', 'Year'])Nous pouvons exécuter le code et continuer avecALT + ENTER.
À ce stade, si nous appelons simplement la variablegroup_name, nous obtiendrons cette sortie:
OutputCela nous montre qu'il s'agit d'un objetDataFrameGroupBy. Cet objet contient des instructions sur la manière de regrouper les données, mais il ne donne pas d'instructions sur la manière d'afficher les valeurs.
Pour afficher les valeurs, nous devrons donner des instructions. Nous pouvons calculer.size(),.mean() et.sum(), par exemple, pour renvoyer une table.
Commençons par.size():
group_name.size()Lorsque nous exécutons le code et continuons avecALT + ENTER, notre sortie ressemblera à ceci:
OutputSex Year
F 1880 942
1881 938
1882 1028
1883 1054
1884 1172
...Ces données semblent bonnes, mais elles pourraient être plus lisibles. Nous pouvons le rendre plus lisible en ajoutant la fonction.unstack:
group_name.size().unstack()Maintenant, lorsque nous exécutons le code et continuons en tapantALT + ENTER, la sortie ressemble à ceci:

Ce que ces données nous disent, c'est combien il y avait de noms de femmes et d'hommes chaque année. En 1889, par exemple, il y avait 1 479 prénoms féminins et 1 111 prénoms masculins. En 2015, il y avait 18 993 prénoms féminins et 13 959 prénoms masculins. Cela montre qu'il y a une plus grande diversité de noms dans le temps.
Si nous voulons obtenir le nombre total de bébés nés, nous pouvons utiliser la fonction.sum(). Appliquons cela à un ensemble de données plus petit, l'ensemblenames2015 du fichieryob2015.txt unique que nous avons créé auparavant:
names2015.groupby(['Sex']).sum()TaponsALT + ENTER pour exécuter le code et continuer:
 ) .sum () sortie]
) .sum () sortie]
Cela nous indique le nombre total de bébés garçons et filles nés en 2015, bien que seuls les bébés dont le nom ait été utilisé au moins 5 fois cette année soient comptabilisés dans l'ensemble de données.
La fonctionpandas.groupby() nous permet de segmenter nos données en groupes significatifs.
Tableau Pivot
Les tableaux croisés dynamiques sont utiles pour résumer les données. Ils peuvent automatiquement trier, compter, additionner ou calculer la moyenne des données stockées dans une table. Ensuite, ils peuvent afficher les résultats de ces actions dans un nouveau tableau de ces données résumées.
Danspandas, la fonctionpivot_table() est utilisée pour créer des tableaux croisés dynamiques.
Pour construire un tableau croisé dynamique, nous allons d’abord appeler le DataFrame avec lequel nous souhaitons travailler, puis les données que nous voulons afficher et leur mode de regroupement.
Dans cet exemple, nous allons travailler avec les donnéesall_names et afficher les données Babies regroupées par nom dans une dimension et par année dans l'autre:
pd.pivot_table(all_names, 'Babies', 'Name', 'Year')Lorsque nous taponsALT + ENTER pour exécuter le code et continuer, nous verrons le résultat suivant:
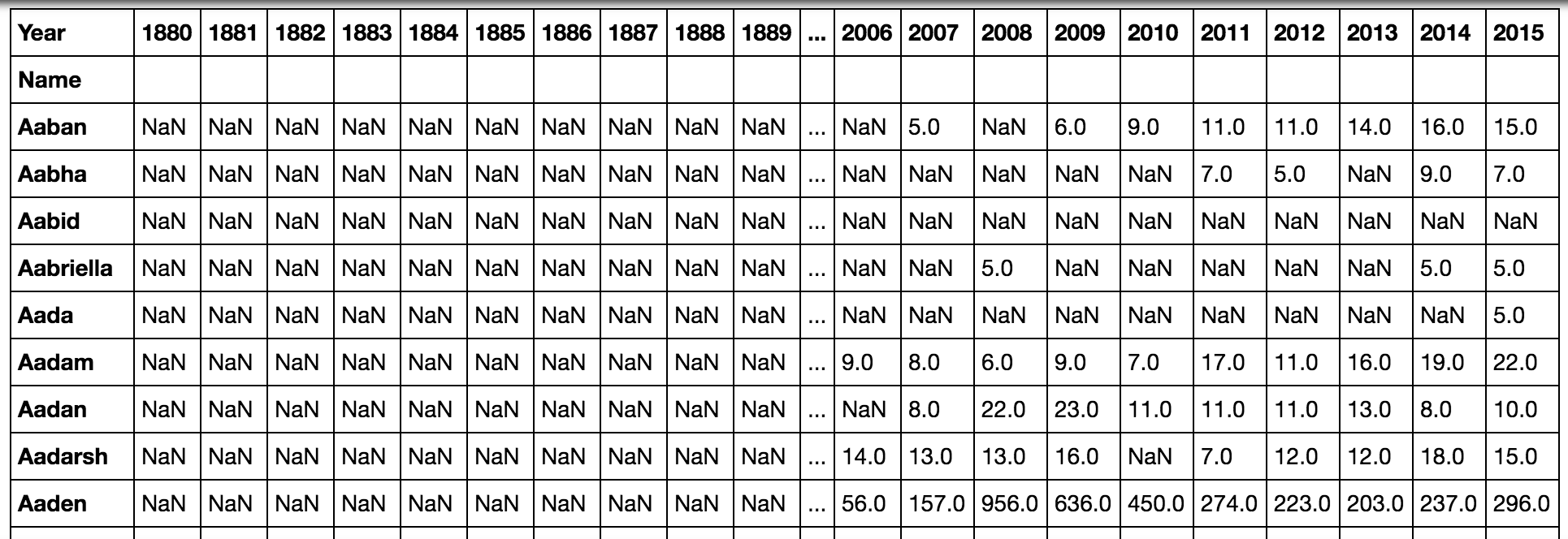
Comme cela affiche beaucoup de valeurs vides, nous pouvons souhaiter conserver Nom et Année sous forme de colonnes plutôt que sous forme de lignes dans un cas et de colonnes dans l'autre. Nous pouvons le faire en regroupant les données entre crochets:
pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])Une fois que nous avons tapéALT + ENTER pour exécuter le code et continuer, ce tableau n'affichera désormais que les données des années enregistrées pour chaque nom:
OutputName Year
Aaban 2007 5.0
2009 6.0
2010 9.0
2011 11.0
2012 11.0
2013 14.0
2014 16.0
2015 15.0
Aabha 2011 7.0
2012 5.0
2014 9.0
2015 7.0
Aabid 2003 5.0
Aabriella 2008 5.0
2014 5.0
2015 5.0De plus, nous pouvons regrouper les données pour avoir le nom et le sexe comme une dimension et l'année pour l'autre, comme dans:
pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')Lorsque nous exécutons le code et continuons avecALT + ENTER, nous verrons le tableau suivant:
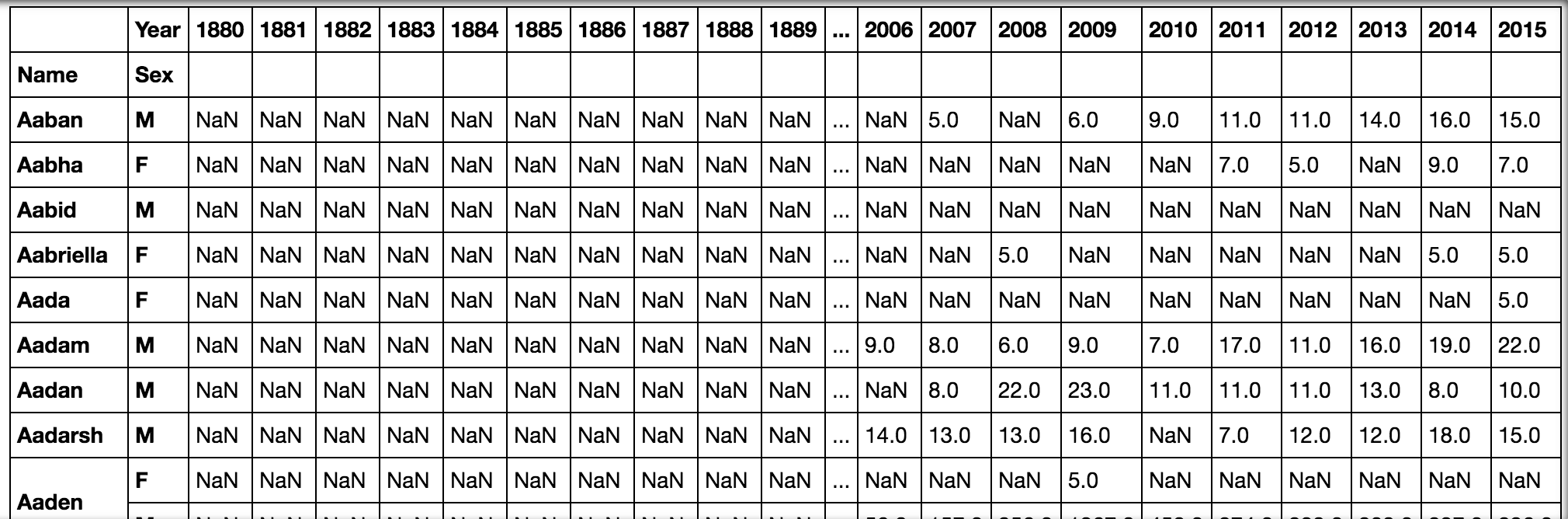 , sortie 'Année')]
, sortie 'Année')]
Les tableaux croisés dynamiques nous permettent de créer de nouvelles tables à partir de tables existantes, ce qui nous permet de décider comment nous voulons que ces données soient regroupées.
Visualiser les données
En utilisantpandas avec d'autres packages commematplotlib, nous pouvons visualiser les données dans notre notebook.
Nous allons visualiser des données sur la popularité d’un prénom au cours des années. Pour ce faire, nous devons définir et trier des index afin de retravailler les données, ce qui nous permettra de voir l'évolution de la popularité d'un nom particulier.
Le packagepandas nous permet d'effectuer une indexation hiérarchique ou multi-niveaux qui nous permet de stocker et de manipuler des données avec un nombre arbitraire de dimensions.
Nous allons indexer nos données avec des informations sur le sexe, puis sur le nom, puis sur l’année. Nous voudrons également trier l’index:
all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()TapezALT + ENTER à exécuter et passez à la ligne suivante, où nous allons demander au notebook d'afficher le nouveau DataFrame indexé:
all_names_indexExécutez le code et continuez avecALT + ENTER, et la sortie ressemblera à ceci:

Ensuite, nous voudrons écrire une fonction qui établira la popularité d’un nom au fil du temps. Nous allons appeler la fonctionname_plot et passersex etname comme paramètres que nous appellerons lorsque nous exécuterons la fonction.
def name_plot(sex, name):Nous allons maintenant configurer une variable appeléedata pour contenir la table que nous avons créée. Nous utiliserons également lespandas DataFrameloc afin de sélectionner notre ligne par la valeur de l'index. Dans notre cas, nous voulons queloc soit basé sur une combinaison de champs dans le MultiIndex, faisant référence à la fois aux donnéessex etname.
Écrivons cette construction dans notre fonction:
def name_plot(sex, name):
data = all_names_index.loc[sex, name]Enfin, nous souhaitons tracer les valeurs avecmatplotlib.pyplot que nous avons importées en tant quepp. Nous allons ensuite tracer les valeurs des données de sexe et de nom par rapport à l’indice, qui pour nous est un nombre d’années.
def name_plot(sex, name):
data = all_names_index.loc[sex, name]
pp.plot(data.index, data.values)TapezALT + ENTER pour exécuter et passer à la cellule suivante. Nous pouvons maintenant appeler la fonction avec le sexe et le nom de notre choix, commeF pour le prénom féminin avec le prénomDanica.
name_plot('F', 'Danica')Lorsque vous tapezALT + ENTER maintenant, vous recevez le résultat suivant:
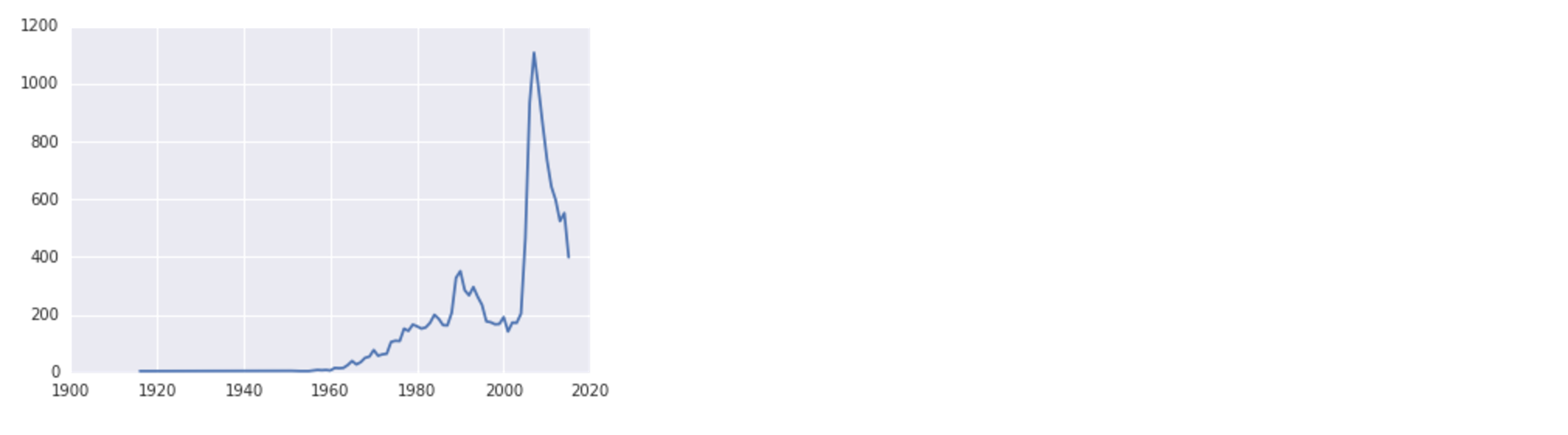
Notez que, selon le système que vous utilisez, vous pouvez être averti de la substitution d'une police, mais les données continueront à être correctement tracées.
En regardant la visualisation, nous pouvons voir que le nom féminin Danica a eu une légère augmentation de popularité vers 1990 et a culminé juste avant 2010.
La fonction que nous avons créée peut être utilisée pour tracer des données à partir de plusieurs noms, afin que nous puissions voir les tendances dans le temps sous différents noms.
Commençons par élargir un peu notre intrigue:
pp.figure(figsize = (18, 8))Ensuite, créons une liste avec tous les noms que nous aimerions tracer:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']Maintenant, nous pouvons parcourir la liste avec une bouclefor et tracer les données pour chaque nom. Premièrement, nous allons essayer ces noms neutres en tant que noms féminins:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)Pour rendre ces données plus faciles à comprendre, incluons une légende:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('F', name)
pp.legend(names)Nous allons taperALT + ENTER pour exécuter le code et continuer, puis nous recevrons le résultat suivant:
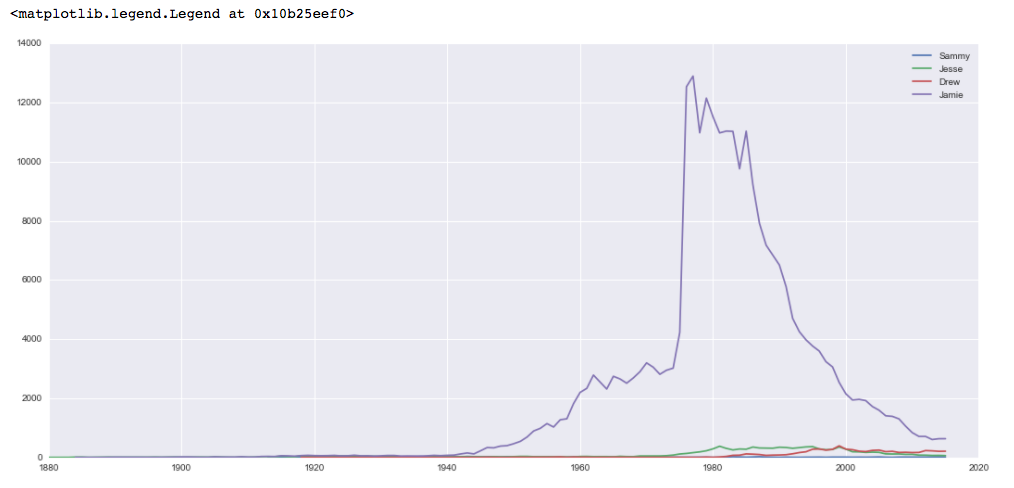
Alors que chacun des noms gagne lentement en popularité en tant que prénom féminin, le nom Jamie était extrêmement populaire en tant que prénom féminin vers 1980.
Nous allons tracer les mêmes noms mais cette fois-ci comme des noms masculins:
pp.figure(figsize = (18, 8))
names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
for name in names:
name_plot('M', name)
pp.legend(names)Encore une fois, tapezALT + ENTER pour exécuter le code et continuer. Le graphique ressemblera à ceci:
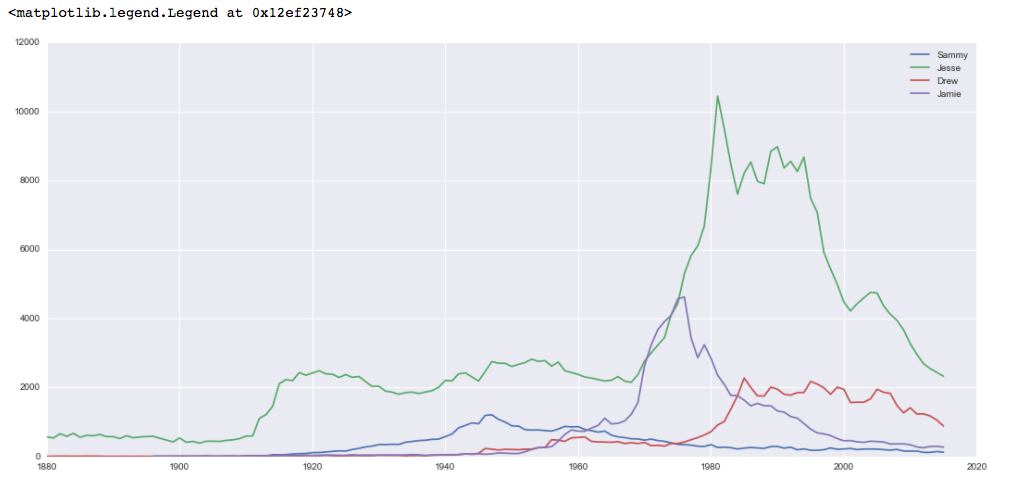
Ces données montrent plus de popularité parmi les noms, Jesse étant généralement le choix le plus populaire et particulièrement populaire dans les années 1980 et 1990.
À partir de là, vous pouvez continuer à jouer avec les données de nom, créer des visualisations sur différents noms et leur popularité, et créer d'autres scripts pour examiner différentes données à visualiser.
Conclusion
Ce didacticiel vous a présenté des méthodes de travail avec de grands ensembles de données, de la configuration des données au regroupement des données avecgroupby() etpivot_table(), à l'indexation des données avec un MultiIndex et à la visualisation des donnéespandas en utilisant le packagematplotlib.
De nombreuses organisations et institutions fournissent des ensembles de données avec lesquels vous pouvez continuer à en savoir plus surpandas et la visualisation des données. Le gouvernement américain fournit des données viadata.gov, par exemple.
Vous pouvez en savoir plus sur la visualisation des données avecmatplotlib en suivant nos guides surHow to Plot Data in Python 3 Using matplotlib etHow To Graph Word Frequency Using matplotlib with Python 3.