Async IO en Python: une solution complète
Async IO est une conception de programmation concurrente qui a reçu un support dédié en Python, évoluant rapidement de Python 3.4 à 3.7 etprobably beyond.
Vous pensez peut-être avec crainte: «Concurrence, parallélisme, threading, multiprocessing. C’est déjà beaucoup à comprendre. Où async IO s'intègre-t-il? »
Ce didacticiel est conçu pour vous aider à répondre à cette question, vous donnant une compréhension plus précise de l'approche de Python pour les asynchrones d'E / S.
Voici ce que vous allez couvrir:
-
Asynchronous IO (async IO): un paradigme (modèle) indépendant du langage qui a des implémentations dans une multitude de langages de programmation
-
async/await: deux nouveaux mots-clés Python utilisés pour définir les coroutines -
asyncio: le package Python qui fournit une base et une API pour exécuter et gérer les coroutines
Les coroutines (fonctions de générateur spécialisées) sont au cœur des E / S asynchrones en Python, et nous y plongerons plus tard.
Note: Dans cet article, j'utilise le termeasync IO pour désigner la conception indépendante du langage des E / S asynchrones, tandis queasyncio fait référence au package Python.
Avant de commencer, vous devez vous assurer que vous êtes configuré pour utiliserasyncio et d'autres bibliothèques trouvées dans ce didacticiel.
Free Bonus:5 Thoughts On Python Mastery, un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour faire passer vos compétences Python au niveau supérieur.
Configuration de votre environnement
Vous aurez besoin de Python 3.7 ou supérieur pour suivre cet article dans son intégralité, ainsi que des packagesaiohttp etaiofiles:
$ python3.7 -m venv ./py37async
$ source ./py37async/bin/activate # Windows: .\py37async\Scripts\activate.bat
$ pip install --upgrade pip aiohttp aiofiles # Optional: aiodnsPour obtenir de l'aide sur l'installation de Python 3.7 et la configuration d'un environnement virtuel, consultezPython 3 Installation & Setup Guide ouVirtual Environments Primer.
Avec cela, allons-y.
La vue de 10 000 pieds d'Async IO
Async IO est un peu moins connu que ses cousins éprouvés, le multiprocessing et le threading. Cette section vous donnera une image plus complète de ce qu'est l'async IO et comment il s'intègre dans son paysage environnant.
Où Async IO s'intègre-t-il?
La concurrence et le parallélisme sont des sujets vastes qui ne sont pas faciles à pénétrer. Bien que cet article se concentre sur Async IO et son implémentation dans Python, il vaut la peine de prendre une minute pour comparer Async IO à ses homologues afin d'avoir un contexte sur la façon dont Async IO s'intègre dans le puzzle plus grand, parfois vertigineux.
Parallelism consiste à effectuer plusieurs opérations en même temps. Multiprocessing est un moyen d’effectuer le parallélisme, et cela implique la répartition des tâches sur les unités centrales de traitement d’un ordinateur (CPU ou cœurs). Le multitraitement est bien adapté aux tâches liées au processeur: les bouclesfor étroitement liées et les calculs mathématiques entrent généralement dans cette catégorie.
Concurrency est un terme légèrement plus large que le parallélisme. Cela suggère que plusieurs tâches ont la capacité de s'exécuter de manière superposée. (Il y a un dicton selon lequel la simultanéité n'implique pas le parallélisme.)
Threading est un modèle d'exécution simultanée dans lequel plusieursthreads exécutent des tâches à tour de rôle. Un processus peut contenir plusieurs threads. Python a une relation compliquée avec le threading grâce à sesGIL, mais cela dépasse le cadre de cet article.
Ce qui est important à savoir sur le threading, c'est qu'il est préférable pour les tâches liées aux E / S. Alors qu'une tâche liée au processeur se caractérise par le fait que les cœurs de l'ordinateur travaillent continuellement dur du début à la fin, un travail lié aux E / S est dominé par beaucoup d'attente pour terminer les entrées / sorties.
Pour récapituler ce qui précède, la concurrence englobe à la fois le multitraitement (idéal pour les tâches liées au processeur) et le thread (adapté aux tâches liées aux E / S). Le multitraitement est une forme de parallélisme, le parallélisme étant un type (sous-ensemble) spécifique de concurrence. La bibliothèque standard Python propose depuis longtemps dessupport for both of these via ses packagesmultiprocessing,threading etconcurrent.futures.
Il est maintenant temps d'amener un nouveau membre au mix. Au cours des dernières années, une conception distincte a été intégrée de manière plus complète dans CPython: les E / S asynchrones, activées via le packageasyncio de la bibliothèque standard et les nouveaux mots-clés de langageasync etawait. Pour être clair, async IO n'est pas un concept nouvellement inventé, et il a existé ou est en cours de construction dans d'autres langages et environnements d'exécution, tels queGo,C# ouScala.
Le packageasyncio est facturé par la documentation Python commea library to write concurrent code. Cependant, async IO n'est pas un filetage, ni un multitraitement. Il n'est construit sur aucun de ces éléments.
En fait, Async IO est une conception à un seul thread et à un seul processus: elle utilisecooperative multitasking, un terme que vous expliquerez à la fin de ce didacticiel. Il a été dit en d'autres termes qu'Async IO donne un sentiment de concurrence malgré l'utilisation d'un seul thread dans un seul processus. Les coroutines (une caractéristique centrale d'Async IO) peuvent être planifiées simultanément, mais elles ne sont pas intrinsèquement concurrentes.
Pour réitérer, async IO est un style de programmation simultanée, mais ce n'est pas du parallélisme. Il est plus étroitement aligné avec le filetage qu'avec le multitraitement, mais il est très distinct des deux et est un membre autonome dans le sac d'astuces de la concurrence.
Cela laisse un terme de plus. Qu'est-ce que cela signifie pour quelque chose d'êtreasynchronous? Ce n'est pas une définition rigoureuse, mais pour nos besoins ici, je peux penser à deux propriétés:
-
Les routines asynchrones peuvent «faire une pause» en attendant leur résultat final et laisser les autres routines s'exécuter en attendant.
-
Le code asynchrone, grâce au mécanisme ci-dessus, facilite l'exécution simultanée. En d'autres termes, le code asynchrone donne l'apparence de la concurrence.
Voici un schéma pour tout rassembler. Les termes blancs représentent des concepts et les termes verts représentent des façons de les mettre en œuvre ou de les effectuer:
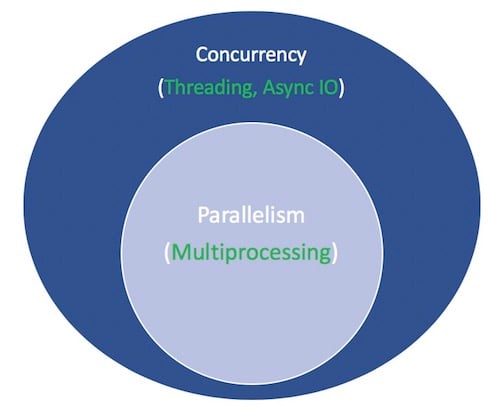
Je m'arrêterai là sur les comparaisons entre les modèles de programmation simultanés. Ce didacticiel se concentre sur le sous-composant qu'est asynchrone IO, comment l'utiliser et les API qui ont surgi autour de lui. Pour une exploration approfondie du thread, du multitraitement et des E / S asynchrones, faites une pause ici et découvrez lesoverview of concurrency in Python de Jim Anderson. Jim est bien plus drôle que moi et a participé à plus de réunions que moi, pour commencer.
Async IO expliqué
Async IO peut à première vue sembler contre-intuitif et paradoxal. Comment quelque chose qui facilite le code simultané utilise-t-il un seul thread et un seul cœur de processeur? Je n'ai jamais été très bon pour évoquer des exemples, donc je voudrais en paraphraser un extrait de la conférence PyCon 2017 de Miguel Grinberg, qui explique tout très bien:
Le maître d'échecs Judit Polgár organise une exposition d'échecs dans laquelle elle joue plusieurs joueurs amateurs. Elle a deux manières de diriger l'exposition: de manière synchrone et asynchrone.
Hypothèses:
24 adversaires
Judit fait bouger chaque échecs en 5 secondes
Les adversaires prennent chacun 55 secondes pour faire un mouvement
Jeux en moyenne 30 coups de paire (60 coups au total)
Synchronous version: Judit joue une partie à la fois, jamais deux en même temps, jusqu'à ce que la partie soit terminée. Chaque partie dure(55 + 5) * 30 == 1800 secondes, soit 30 minutes. L'exposition entière prend24 * 30 == 720 minutes, ou12 hours.
Asynchronous version: Judit se déplace de table en table, effectuant un mouvement à chaque table. Elle quitte la table et laisse l'adversaire effectuer son prochain mouvement pendant le temps d'attente. Un coup sur les 24 parties prend Judit24 * 5 == 120 secondes, soit 2 minutes. L'exposition entière est maintenant réduite à120 * 30 == 3600 secondes, ou juste à1 hour. (Source)
Il n'y a qu'une seule Judit Polgár, qui n'a que deux mains et ne fait qu'un seul mouvement à la fois. Mais jouer de manière asynchrone réduit le temps d'exposition de 12 heures à une heure. Ainsi, le multitâche coopératif est une façon élégante de dire que la boucle d'événements d'un programme (plus à ce sujet plus tard) communique avec plusieurs tâches pour permettre à chaque tour de fonctionner à tour de rôle au moment optimal.
Async IO prend de longues périodes d'attente pendant lesquelles des fonctions seraient autrement bloquantes et permet à d'autres fonctions de s'exécuter pendant ce temps d'arrêt. (Une fonction qui bloque empêche efficacement les autres de s'exécuter à partir du moment où elle démarre jusqu'au moment où elle revient.)
Async IO n'est pas facile
J'ai entendu dire: «Utilisez async IO lorsque vous le pouvez; utilisez le filetage quand vous le devez. La vérité est que la création de code multithread durable peut être difficile et source d'erreurs. Async IO évite certains des accélérations potentielles que vous pourriez rencontrer autrement avec une conception filetée.
Mais cela ne veut pas dire que les E / S asynchrones en Python sont faciles. Soyez averti: lorsque vous vous aventurez un peu en dessous du niveau de la surface, la programmation asynchrone peut aussi être difficile! Le modèle asynchrone de Python est construit autour de concepts tels que les rappels, les événements, les transports, les protocoles et les futurs - seule la terminologie peut être intimidante. Le fait que son API ait constamment changé ne facilite pas la tâche.
Heureusement,asyncio a mûri à un point où la plupart de ses fonctionnalités ne sont plus provisoires, tandis que sa documentation a fait l'objet d'une refonte énorme et que des ressources de qualité sur le sujet commencent également à émerger.
Le packageasyncio etasync /await
Maintenant que vous avez des informations sur async IO en tant que conception, examinons l'implémentation de Python. Le packageasyncio de Python (introduit dans Python 3.4) et ses deux mots-clés,async etawait, ont des objectifs différents mais se réunissent pour vous aider à déclarer, construire, exécuter et gérer du code asynchrone.
La syntaxeasync /await et les coroutines natives
A Word of Caution: Faites attention à ce que vous lisez sur Internet. L'API asynchrone IO de Python a évolué rapidement de Python 3.4 à Python 3.7. Certains anciens modèles ne sont plus utilisés, et certaines choses qui étaient initialement interdites sont désormais autorisées par le biais de nouvelles introductions. Pour autant que je sache, ce tutoriel rejoindra bientôt le club des obsolètes.
Au cœur de l'async IO se trouvent les coroutines. Une coroutine est une version spécialisée d'une fonction de générateur Python. Commençons par une définition de base, puis construisons-en au fur et à mesure que vous progressez ici: une coroutine est une fonction qui peut suspendre son exécution avant d'atteindrereturn, et elle peut indirectement passer le contrôle à une autre coroutine pendant un certain temps.
Plus tard, vous approfondirez la façon dont le générateur traditionnel est transformé en coroutine. Pour l'instant, le moyen le plus simple de savoir comment fonctionnent les coroutines est de commencer à en faire.
Prenons l'approche immersive et écrivons du code d'E / S asynchrone. Ce programme court est leHello World d'Async IO, mais va un long chemin vers l'illustration de ses fonctionnalités de base:
#!/usr/bin/env python3
# countasync.py
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")Lorsque vous exécutez ce fichier, notez ce qui semble différent que si vous deviez définir les fonctions avec seulementdef ettime.sleep():
$ python3 countasync.py
One
One
One
Two
Two
Two
countasync.py executed in 1.01 seconds.L'ordre de cette sortie est au cœur de Async IO. Parler à chacun des appels àcount() est une boucle d'événement unique, ou coordinateur. Lorsque chaque tâche atteintawait asyncio.sleep(1), la fonction crie jusqu'à la boucle d'événements et lui redonne le contrôle, en disant: «Je vais dormir pendant 1 seconde. Allez-y et laissez quelque chose d'autre significatif être fait en attendant. »
Comparez cela à la version synchrone:
#!/usr/bin/env python3
# countsync.py
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")Lors de l'exécution, il y a un changement léger mais critique dans l'ordre et le temps d'exécution:
$ python3 countsync.py
One
Two
One
Two
One
Two
countsync.py executed in 3.01 seconds.Bien que l'utilisation detime.sleep() etasyncio.sleep() puisse sembler banale, elles sont utilisées comme substituts pour tous les processus chronophages qui impliquent des temps d'attente. (La chose la plus banale sur laquelle vous pouvez attendre est un appelsleep() qui ne fait fondamentalement rien.) Autrement dit,time.sleep() peut représenter n'importe quel appel de fonction de blocage chronophage, tandis queasyncio.sleep() est utilisé pour remplacer un appel non bloquant (mais qui prend également un certain temps à terminer).
Comme vous le verrez dans la section suivante, l’avantage d’attendre quelque chose, y comprisasyncio.sleep(), est que la fonction environnante peut temporairement céder le contrôle à une autre fonction qui est plus facilement capable de faire quelque chose immédiatement. En revanche,time.sleep() ou tout autre appel de blocage est incompatible avec le code Python asynchrone, car il arrêtera tout ce qui se trouve dans ses traces pendant la durée du temps de sommeil.
Les règles d'Async IO
À ce stade, une définition plus formelle deasync,await et les fonctions coroutines qu'ils créent sont en ordre. Cette section est un peu dense, mais obtenirasync /await est instrumental, alors revenez-y si vous avez besoin de:
-
La syntaxe
async defintroduit soit unnative coroutine soit unasynchronous generator. Les expressionsasync withetasync forsont également valides et vous les verrez plus tard. -
Le mot-clé
awaitrenvoie le contrôle de la fonction à la boucle d'événements. (Il suspend l'exécution de la coroutine environnante.) Si Python rencontre une expressionawait f()dans la portée deg(), voici commentawaitdit à la boucle d'événements, «Suspend l'exécution deg()jusqu'à ce que ce que j'attends - le résultat def()- soit renvoyé. En attendant, allez laisser courir autre chose. »
Dans le code, ce deuxième point ressemble à peu près à ceci:
async def g():
# Pause here and come back to g() when f() is ready
r = await f()
return rIl existe également un ensemble de règles strictes indiquant quand et comment vous pouvez et ne pouvez pas utiliserasync /await. Ceux-ci peuvent être utiles que vous soyez toujours en train de saisir la syntaxe ou que vous soyez déjà familiarisé avec l'utilisation deasync /await:
-
Une fonction que vous introduisez avec
async defest une coroutine. Il peut utiliserawait,returnouyield, mais tous sont facultatifs. La déclaration deasync def noop(): passest valide:-
L'utilisation de
awaitet / oureturncrée une fonction coroutine. Pour appeler une fonction coroutine, vous devez laawaitpour obtenir ses résultats. -
Il est moins courant (et récemment légal en Python) d'utiliser
yielddans un blocasync def. Cela crée unasynchronous generator, que vous répétez avecasync for. Oubliez les générateurs asynchrones pour le moment et concentrez-vous sur la syntaxe des fonctions coroutine, qui utilisentawaitet / oureturn. -
Tout ce qui est défini avec
async defne peut pas utiliseryield from, ce qui augmentera unSyntaxError.
-
-
Tout comme c'est un
SyntaxErrord'utiliseryielden dehors d'une fonctiondef, c'est unSyntaxErrord'utiliserawaiten dehors d'une coroutineasync def. Vous ne pouvez utiliser queawaitdans le corps des coroutines.
Voici quelques exemples concis destinés à résumer les quelques règles ci-dessus:
async def f(x):
y = await z(x) # OK - `await` and `return` allowed in coroutines
return y
async def g(x):
yield x # OK - this is an async generator
async def m(x):
yield from gen(x) # No - SyntaxError
def m(x):
y = await z(x) # Still no - SyntaxError (no `async def` here)
return yEnfin, lorsque vous utilisezawait f(), il est nécessaire quef() soit un objet qui estawaitable. Eh bien, ce n'est pas très utile, n'est-ce pas? Pour l'instant, sachez simplement qu'un objet en attente est soit (1) une autre coroutine, soit (2) un objet définissant une méthode dunder.__await__() qui retourne un itérateur. Si vous écrivez un programme, dans la grande majorité des cas, vous ne devez vous soucier que du cas n ° 1.
Cela nous amène à une autre distinction technique que vous pouvez voir apparaître: une façon plus ancienne de marquer une fonction comme coroutine est de décorer une fonctiondef normale avec@asyncio.coroutine. Le résultat est ungenerator-based coroutine. Cette construction est obsolète depuis la mise en place de la syntaxeasync /await dans Python 3.5.
Ces deux coroutines sont essentiellement équivalentes (les deux sont attendues), mais la première estgenerator-based, tandis que la seconde est unnative coroutine:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine, older syntax"""
yield from stuff()
async def py35_coro():
"""Native coroutine, modern syntax"""
await stuff()Si vous écrivez vous-même un code, préférez les coroutines natives pour être explicites plutôt qu'implicites. Les coroutines basées sur les générateurs serontremoved en Python 3.10.
Vers la dernière moitié de ce didacticiel, nous aborderons les coroutines basées sur le générateur à titre d'explication uniquement. La raison pour laquelleasync /await ont été introduits est de faire des coroutines une fonctionnalité autonome de Python qui peut être facilement différenciée d'une fonction génératrice normale, réduisant ainsi l'ambiguïté.
Ne vous enlisez pas dans les coroutines basées sur des générateurs, qui ont étédeliberately outdated parasync /await. Ils ont leur propre petit ensemble de règles (par exemple,await ne peut pas être utilisé dans une coroutine basée sur un générateur) qui sont largement sans intérêt si vous vous en tenez à la syntaxeasync /await.
Sans plus tarder, prenons quelques exemples plus impliqués.
Voici un exemple de la façon dont les E / S asynchrones réduisent le temps d'attente: étant donné une coroutinemakerandom() qui continue de produire des entiers aléatoires dans la plage [0, 10], jusqu'à ce que l'un d'entre eux dépasse un seuil, vous voulez laisser plusieurs appels de cette coroutine n'a pas besoin d'attendre les uns les autres pour se terminer successivement. Vous pouvez suivre en grande partie les modèles des deux scripts ci-dessus, avec de légères modifications:
#!/usr/bin/env python3
# rand.py
import asyncio
import random
# ANSI colors
c = (
"\033[0m", # End of color
"\033[36m", # Cyan
"\033[91m", # Red
"\033[35m", # Magenta
)
async def makerandom(idx: int, threshold: int = 6) -> int:
print(c[idx + 1] + f"Initiated makerandom({idx}).")
i = random.randint(0, 10)
while i <= threshold:
print(c[idx + 1] + f"makerandom({idx}) == {i} too low; retrying.")
await asyncio.sleep(idx + 1)
i = random.randint(0, 10)
print(c[idx + 1] + f"---> Finished: makerandom({idx}) == {i}" + c[0])
return i
async def main():
res = await asyncio.gather(*(makerandom(i, 10 - i - 1) for i in range(3)))
return res
if __name__ == "__main__":
random.seed(444)
r1, r2, r3 = asyncio.run(main())
print()
print(f"r1: {r1}, r2: {r2}, r3: {r3}")La sortie colorisée en dit beaucoup plus que moi et vous donne une idée de la façon dont ce script est exécuté:
Ce programme utilise une coroutine principale,makerandom(), et l'exécute simultanément sur 3 entrées différentes. La plupart des programmes contiendront de petites coroutines modulaires et une fonction de wrapper qui sert à enchaîner chacune des petites coroutines. main() est ensuite utilisé pour rassembler des tâches (futures) en mappant la coroutine centrale sur un itérable ou un pool.
Dans cet exemple miniature, le pool estrange(3). Dans un exemple plus complet présenté plus loin, il s'agit d'un ensemble d'URL qui doivent être demandées, analysées et traitées simultanément, etmain() encapsule toute cette routine pour chaque URL.
Alors que «créer des entiers aléatoires» (qui est lié au processeur plus que tout) n'est peut-être pas le meilleur choix en tant que candidat pourasyncio, c'est la présence deasyncio.sleep() dans l'exemple qui est conçu pour imiter un Processus lié aux EI où il y a un temps d'attente incertain. Par exemple, l'appelasyncio.sleep() peut représenter l'envoi et la réception d'entiers pas si aléatoires entre deux clients dans une application de messagerie.
Modèles de conception Async IO
Async IO est livré avec son propre ensemble de conceptions de scripts possibles, que vous découvrirez dans cette section.
Chaînage des coroutines
Une caractéristique clé des coroutines est qu'elles peuvent être enchaînées ensemble. (Souvenez-vous qu'un objet coroutine est en attente, donc une autre coroutine peut leawait.) Cela vous permet de diviser les programmes en coroutines plus petites, gérables et recyclables:
#!/usr/bin/env python3
# chained.py
import asyncio
import random
import time
async def part1(n: int) -> str:
i = random.randint(0, 10)
print(f"part1({n}) sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-1"
print(f"Returning part1({n}) == {result}.")
return result
async def part2(n: int, arg: str) -> str:
i = random.randint(0, 10)
print(f"part2{n, arg} sleeping for {i} seconds.")
await asyncio.sleep(i)
result = f"result{n}-2 derived from {arg}"
print(f"Returning part2{n, arg} == {result}.")
return result
async def chain(n: int) -> None:
start = time.perf_counter()
p1 = await part1(n)
p2 = await part2(n, p1)
end = time.perf_counter() - start
print(f"-->Chained result{n} => {p2} (took {end:0.2f} seconds).")
async def main(*args):
await asyncio.gather(*(chain(n) for n in args))
if __name__ == "__main__":
import sys
random.seed(444)
args = [1, 2, 3] if len(sys.argv) == 1 else map(int, sys.argv[1:])
start = time.perf_counter()
asyncio.run(main(*args))
end = time.perf_counter() - start
print(f"Program finished in {end:0.2f} seconds.")Faites très attention à la sortie, oùpart1() dort pendant une durée variable etpart2() commence à travailler avec les résultats dès qu'ils deviennent disponibles:
$ python3 chained.py 9 6 3
part1(9) sleeping for 4 seconds.
part1(6) sleeping for 4 seconds.
part1(3) sleeping for 0 seconds.
Returning part1(3) == result3-1.
part2(3, 'result3-1') sleeping for 4 seconds.
Returning part1(9) == result9-1.
part2(9, 'result9-1') sleeping for 7 seconds.
Returning part1(6) == result6-1.
part2(6, 'result6-1') sleeping for 4 seconds.
Returning part2(3, 'result3-1') == result3-2 derived from result3-1.
-->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds).
Returning part2(6, 'result6-1') == result6-2 derived from result6-1.
-->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds).
Returning part2(9, 'result9-1') == result9-2 derived from result9-1.
-->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds).
Program finished in 11.01 seconds.Dans cette configuration, le temps d'exécution demain() sera égal au temps d'exécution maximum des tâches qu'il rassemble et planifie.
Utilisation d'une file d'attente
Le packageasyncio fournit desqueue classes qui sont conçus pour être similaires aux classes du modulequeue. Jusqu'à présent, dans nos exemples, nous n'avions pas vraiment besoin d'une structure de file d'attente. Enchained.py, chaque tâche (future) est composée d'un ensemble de coroutines qui s'attendent explicitement et passent par une seule entrée par chaîne.
Il existe une structure alternative qui peut également fonctionner avec async IO: un certain nombre de producteurs, qui ne sont pas associés les uns aux autres, ajoutent des éléments à une file d'attente. Chaque producteur peut ajouter plusieurs éléments à la file d'attente à des moments décalés, aléatoires et inopinés. Un groupe de consommateurs sort des objets de la file d'attente alors qu'ils se présentent, avidement et sans attendre d'autre signal.
Dans cette conception, aucun consommateur individuel n'est enchaîné à un producteur. Les consommateurs ne connaissent pas à l'avance le nombre de producteurs, ni même le nombre cumulé d'articles qui seront ajoutés à la file d'attente.
Il faut au producteur ou au consommateur individuel un temps variable pour placer et extraire des éléments de la file d'attente, respectivement. La file d'attente sert de débit qui peut communiquer avec les producteurs et les consommateurs sans qu'ils se parlent directement.
Note: Bien que les files d'attente soient souvent utilisées dans les programmes threadés en raison de la sécurité des threads dequeue.Queue(), vous ne devriez pas avoir à vous soucier de la sécurité des threads lorsqu'il s'agit d'E / S asynchrones. (L'exception est lorsque vous combinez les deux, mais cela n'est pas fait dans ce didacticiel.)
Un cas d'utilisation pour les files d'attente (comme c'est le cas ici) est que la file d'attente agisse comme un émetteur pour les producteurs et les consommateurs qui ne sont pas autrement directement enchaînés ou associés les uns aux autres.
La version synchrone de ce programme aurait l'air assez lugubre: un groupe de producteurs bloquants ajoutent en série des éléments à la file d'attente, un producteur à la fois. Ce n'est qu'une fois que tous les producteurs ont terminé que la file d'attente peut être traitée, par un consommateur à la fois, en traitant article par article. Il y a une tonne de latence dans cette conception. Les éléments peuvent rester inactifs dans la file d'attente plutôt que d'être récupérés et traités immédiatement.
Une version asynchrone,asyncq.py, est ci-dessous. La partie difficile de ce flux de travail est qu'il doit y avoir un signal aux consommateurs que la production est terminée. Sinon,await q.get() se bloquera indéfiniment, car la file d'attente aura été entièrement traitée, mais les consommateurs n'auront aucune idée que la production est terminée.
(Un grand merci pour l'aide d'un StackOverflowuser pour avoir aidé à redressermain(): la clé est àawait q.join(), qui bloque jusqu'à ce que tous les éléments de la file d'attente aient été reçus et traités, et puis pour annuler les tâches du consommateur, qui autrement raccrocheraient et attendraient sans cesse que des éléments de file d'attente supplémentaires apparaissent.)
Voici le script complet:
#!/usr/bin/env python3
# asyncq.py
import asyncio
import itertools as it
import os
import random
import time
async def makeitem(size: int = 5) -> str:
return os.urandom(size).hex()
async def randsleep(a: int = 1, b: int = 5, caller=None) -> None:
i = random.randint(0, 10)
if caller:
print(f"{caller} sleeping for {i} seconds.")
await asyncio.sleep(i)
async def produce(name: int, q: asyncio.Queue) -> None:
n = random.randint(0, 10)
for _ in it.repeat(None, n): # Synchronous loop for each single producer
await randsleep(caller=f"Producer {name}")
i = await makeitem()
t = time.perf_counter()
await q.put((i, t))
print(f"Producer {name} added <{i}> to queue.")
async def consume(name: int, q: asyncio.Queue) -> None:
while True:
await randsleep(caller=f"Consumer {name}")
i, t = await q.get()
now = time.perf_counter()
print(f"Consumer {name} got element <{i}>"
f" in {now-t:0.5f} seconds.")
q.task_done()
async def main(nprod: int, ncon: int):
q = asyncio.Queue()
producers = [asyncio.create_task(produce(n, q)) for n in range(nprod)]
consumers = [asyncio.create_task(consume(n, q)) for n in range(ncon)]
await asyncio.gather(*producers)
await q.join() # Implicitly awaits consumers, too
for c in consumers:
c.cancel()
if __name__ == "__main__":
import argparse
random.seed(444)
parser = argparse.ArgumentParser()
parser.add_argument("-p", "--nprod", type=int, default=5)
parser.add_argument("-c", "--ncon", type=int, default=10)
ns = parser.parse_args()
start = time.perf_counter()
asyncio.run(main(**ns.__dict__))
elapsed = time.perf_counter() - start
print(f"Program completed in {elapsed:0.5f} seconds.")Les premières coroutines sont des fonctions d'assistance qui renvoient une chaîne aléatoire, un compteur de performances fractionnaire et un entier aléatoire. Un producteur place de 1 à 5 articles dans la file d'attente. Chaque élément est un tuple de(i, t) oùi est une chaîne aléatoire ett est le moment auquel le producteur tente de mettre le tuple dans la file d'attente.
Lorsqu'un consommateur extrait un élément, il calcule simplement le temps écoulé pendant lequel l'élément s'est assis dans la file d'attente à l'aide de l'horodatage avec lequel l'élément a été inséré.
Gardez à l'esprit queasyncio.sleep() est utilisé pour imiter une autre coroutine plus complexe qui prendrait du temps et bloquerait toute autre exécution s'il s'agissait d'une fonction de blocage normale.
Voici un essai avec deux producteurs et cinq consommateurs:
$ python3 asyncq.py -p 2 -c 5
Producer 0 sleeping for 3 seconds.
Producer 1 sleeping for 3 seconds.
Consumer 0 sleeping for 4 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 sleeping for 3 seconds.
Consumer 3 sleeping for 5 seconds.
Consumer 4 sleeping for 4 seconds.
Producer 0 added <377b1e8f82> to queue.
Producer 0 sleeping for 5 seconds.
Producer 1 added <413b8802f8> to queue.
Consumer 1 got element <377b1e8f82> in 0.00013 seconds.
Consumer 1 sleeping for 3 seconds.
Consumer 2 got element <413b8802f8> in 0.00009 seconds.
Consumer 2 sleeping for 4 seconds.
Producer 0 added <06c055b3ab> to queue.
Producer 0 sleeping for 1 seconds.
Consumer 0 got element <06c055b3ab> in 0.00021 seconds.
Consumer 0 sleeping for 4 seconds.
Producer 0 added <17a8613276> to queue.
Consumer 4 got element <17a8613276> in 0.00022 seconds.
Consumer 4 sleeping for 5 seconds.
Program completed in 9.00954 seconds.Dans ce cas, les éléments sont traités en quelques fractions de seconde. Un retard peut être dû à deux raisons:
-
Frais généraux standard, largement inévitables
-
Situations où tous les consommateurs dorment lorsqu'un article apparaît dans la file d'attente
En ce qui concerne la deuxième raison, heureusement, il est parfaitement normal de s’adapter à des centaines ou des milliers de consommateurs. Vous ne devriez avoir aucun problème avecpython3 asyncq.py -p 5 -c 100. Le point ici est que, théoriquement, vous pourriez avoir différents utilisateurs sur différents systèmes contrôlant la gestion des producteurs et des consommateurs, la file d'attente servant de débit central.
Jusqu'à présent, vous avez été jeté directement dans le feu et vu trois exemples connexes de coroutines d'appelasyncio définies avecasync etawait. Si vous ne suivez pas complètement ou voulez simplement approfondir les mécanismes de la façon dont les coroutines modernes sont devenues en Python, vous commencerez à la case départ avec la section suivante.
Racines d'Async IO dans les générateurs
Plus tôt, vous avez vu un exemple des coroutines basées sur un générateur à l'ancienne, qui ont été dépassées par des coroutines natives plus explicites. L'exemple mérite d'être re-montré avec un petit ajustement:
import asyncio
@asyncio.coroutine
def py34_coro():
"""Generator-based coroutine"""
# No need to build these yourself, but be aware of what they are
s = yield from stuff()
return s
async def py35_coro():
"""Native coroutine, modern syntax"""
s = await stuff()
return s
async def stuff():
return 0x10, 0x20, 0x30À titre expérimental, que se passe-t-il si vous appelezpy34_coro() oupy35_coro() seul, sansawait, ou sans aucun appel àasyncio.run() ou autreasyncio «porcelaine» " les fonctions? L'appel d'une coroutine de manière isolée renvoie un objet coroutine:
>>>
>>> py35_coro()
Ce n'est pas très intéressant à première vue. Le résultat de l'appel d'une coroutine seule est uncoroutine object attendu.
Temps pour un quiz: à quoi ressemble une autre fonctionnalité de Python? (Quelle fonctionnalité de Python ne «fait pas grand-chose» quand elle est appelée seule?)
J'espère que vous pensez àgenerators comme une réponse à cette question, car les coroutines sont des générateurs améliorés sous le capot. Le comportement est similaire à cet égard:
>>>
>>> def gen():
... yield 0x10, 0x20, 0x30
...
>>> g = gen()
>>> g # Nothing much happens - need to iterate with `.__next__()`
>>> next(g)
(16, 32, 48) Les fonctions de générateur sont, en l'occurrence, la base des E / S asynchrones (que vous déclariez ou non des coroutines avecasync def plutôt qu'avec l'ancien wrapper@asyncio.coroutine). Techniquement,await est plus proche deyield from que deyield. (Mais rappelez-vous queyield from x() n'est qu'un sucre syntaxique pour remplacerfor i in x(): yield i.)
Une caractéristique essentielle des générateurs en ce qui concerne les E / S asynchrones est qu'ils peuvent être effectivement arrêtés et redémarrés à volonté. Par exemple, vous pouvezbreak hors d'itération sur un objet générateur, puis reprendre l'itération sur les valeurs restantes plus tard. Lorsqu'une fonction de générateur atteintyield, elle donne cette valeur, mais elle reste inactive jusqu'à ce qu'on lui dise de donner sa valeur suivante.
Cela peut être étoffé à travers un exemple:
>>>
>>> from itertools import cycle
>>> def endless():
... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever"""
... yield from cycle((9, 8, 7, 6))
>>> e = endless()
>>> total = 0
>>> for i in e:
... if total < 30:
... print(i, end=" ")
... total += i
... else:
... print()
... # Pause execution. We can resume later.
... break
9 8 7 6 9 8 7 6 9 8 7 6 9 8
>>> # Resume
>>> next(e), next(e), next(e)
(6, 9, 8)Le mot cléawait se comporte de la même manière, marquant un point d'arrêt auquel la coroutine se suspend et laisse les autres coroutines travailler. «Suspendu», dans ce cas, signifie une coroutine qui a temporairement cédé le contrôle mais qui n'est pas totalement sortie ou terminée. Gardez à l'esprit queyield, et par extensionyield from etawait, marquent un point d'arrêt dans l'exécution d'un générateur.
C'est la différence fondamentale entre les fonctions et les générateurs. Une fonction est tout ou rien. Une fois qu'il démarre, il ne s'arrête pas jusqu'à ce qu'il atteigne unreturn, puis pousse cette valeur à l'appelant (la fonction qui l'appelle). Un générateur, par contre, fait une pause chaque fois qu'il atteint unyield et ne va pas plus loin. Non seulement il peut pousser cette valeur vers la pile d'appel, mais il peut conserver ses variables locales lorsque vous le reprenez en appelantnext() dessus.
Il existe une deuxième caractéristique moins connue des générateurs qui compte également. Vous pouvez également envoyer une valeur dans un générateur via sa méthode.send(). Cela permet aux générateurs (et aux coroutines) de s'appeler (await) sans se bloquer. Je n'irai pas plus loin dans les détails de cette fonctionnalité, car elle importe principalement pour la mise en œuvre de coroutines en arrière-plan, mais vous ne devriez jamais vraiment avoir besoin de l'utiliser directement vous-même.
Si vous souhaitez en savoir plus, vous pouvez commencer àPEP 342, où les coroutines ont été officiellement introduites. LesHow the Heck Does Async-Await Work in Python de Brett Cannon sont également une bonne lecture, tout comme lesPYMOTW writeup on asyncio. Enfin, il y aCurious Course on Coroutines and Concurrency de David Beazley, qui plonge profondément dans le mécanisme par lequel les coroutines fonctionnent.
Essayons de condenser tous les articles ci-dessus en quelques phrases: il existe un mécanisme particulièrement non conventionnel par lequel ces coroutines sont réellement gérées. Leur résultat est un attribut de l'objet d'exception qui est levé lorsque leur méthode.send() est appelée. Il y a quelques détails plus compliqués à tout cela, mais cela ne vous aidera probablement pas à utiliser cette partie du langage dans la pratique, alors allons-y pour l'instant.
Pour lier les choses, voici quelques points clés sur le thème des coroutines en tant que générateurs:
-
Les coroutines sont desrepurposed generators qui tirent parti des particularités des méthodes génératrices.
-
Les anciennes coroutines basées sur des générateurs utilisent
yield frompour attendre un résultat de coroutine. La syntaxe Python moderne dans les coroutines natives remplace simplementyield fromparawaitcomme moyen d'attendre un résultat de coroutine. Leawaitest analogue àyield from, et il est souvent utile de le considérer comme tel. -
L'utilisation de
awaitest un signal qui marque un point de rupture. Il permet à une coroutine de suspendre temporairement l'exécution et permet au programme d'y revenir plus tard.
Autres fonctionnalités:async for et générateurs Async + Comprehensions
En plus desasync /await simples, Python permet également àasync for d'itérer sur unasynchronous iterator. Un itérateur asynchrone a pour but de pouvoir appeler du code asynchrone à chaque étape lorsqu'il est itéré.
Une extension naturelle de ce concept est unasynchronous generator. Rappelez-vous que vous pouvez utiliserawait,return ouyield dans une coroutine native. L'utilisation deyield dans une coroutine est devenue possible dans Python 3.6 (via PEP 525), qui a introduit des générateurs asynchrones dans le but de permettre àawait etyield d'être utilisés dans le même corps de fonction coroutine:
>>>
>>> async def mygen(u: int = 10):
... """Yield powers of 2."""
... i = 0
... while i < u:
... yield 2 ** i
... i += 1
... await asyncio.sleep(0.1)Enfin et surtout, Python activeasynchronous comprehension avecasync for. Comme son cousin synchrone, il s'agit en grande partie de sucre syntaxique:
>>>
>>> async def main():
... # This does *not* introduce concurrent execution
... # It is meant to show syntax only
... g = [i async for i in mygen()]
... f = [j async for j in mygen() if not (j // 3 % 5)]
... return g, f
...
>>> g, f = asyncio.run(main())
>>> g
[1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
>>> f
[1, 2, 16, 32, 256, 512]C'est une distinction cruciale:neither asynchronous generators nor comprehensions make the iteration concurrent. Tout ce qu'ils font est de fournir l'apparence de leurs homologues synchrones, mais avec la possibilité pour la boucle en question de céder le contrôle à la boucle d'événements pour qu'une autre coroutine s'exécute.
En d'autres termes, les itérateurs asynchrones et les générateurs asynchrones ne sont pas conçus pour mapper simultanément certaines fonctions sur une séquence ou un itérateur. Ils sont simplement conçus pour laisser la coroutine englobante autoriser d'autres tâches à leur tour. Les instructionsasync for etasync with ne sont nécessaires que dans la mesure où l'utilisation defor ouwith "briserait" la nature deawait dans la coroutine. Cette distinction entre l'asynchronicité et la concurrence est une clé à saisir.
La boucle d'événements et lesasyncio.run()
Vous pouvez considérer une boucle d'événements comme quelque chose comme une bouclewhile True qui surveille les coroutines, prend en compte les informations sur ce qui est inactif et recherche les choses qui peuvent être exécutées entre-temps. Il est capable de réveiller une coroutine inactive lorsque tout ce que cette coroutine attend est disponible.
Jusqu'à présent, la gestion complète de la boucle d'événements a été implicitement gérée par un appel de fonction:
asyncio.run(main()) # Python 3.7+asyncio.run(), introduit dans Python 3.7, est chargé d'obtenir la boucle d'événements, d'exécuter les tâches jusqu'à ce qu'elles soient marquées comme terminées, puis de fermer la boucle d'événements.
Il existe un moyen plus long de gérer la boucle d’événementsasyncio, avecget_event_loop(). Le modèle typique ressemble à ceci:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.close()Vous verrez probablementloop.get_event_loop() flotter dans les exemples plus anciens, mais à moins que vous n'ayez un besoin spécifique d'affiner le contrôle de la gestion de la boucle d'événements,asyncio.run() devrait être suffisant pour la plupart des programmes.
Si vous avez besoin d'interagir avec la boucle d'événements dans un programme Python,loop est un objet Python à l'ancienne qui prend en charge l'introspection avecloop.is_running() etloop.is_closed(). Vous pouvez le manipuler si vous avez besoin d'obtenir un contrôle plus précis, comme dansscheduling a callback en passant la boucle comme argument.
Ce qui est plus crucial, c'est de comprendre un peu sous la surface la mécanique de la boucle d'événements. Voici quelques points à souligner à propos de la boucle d'événements.
Les Coroutines#1: ne font pas grand-chose d'elles-mêmes tant qu'elles ne sont pas liées à la boucle d'événements.
Vous avez déjà vu ce point dans l'explication sur les générateurs, mais cela vaut la peine d'être réaffirmé. Si vous avez une coroutine principale qui attend les autres, simplement l'appeler de manière isolée a peu d'effet:
>>>
>>> import asyncio
>>> async def main():
... print("Hello ...")
... await asyncio.sleep(1)
... print("World!")
>>> routine = main()
>>> routine
N'oubliez pas d'utiliserasyncio.run() pour forcer réellement l'exécution en planifiant la coroutine demain() (objet futur) pour l'exécution sur la boucle d'événements:
>>>
>>> asyncio.run(routine)
Hello ...
World!(D'autres coroutines peuvent être exécutées avecawait. Il est typique d'envelopper seulementmain() dansasyncio.run(), et les coroutines chaînées avecawait seront appelées à partir de là.)
#2: Par défaut, une boucle d'événement d'E / S asynchrone s'exécute dans un seul thread et sur un seul cœur de processeur. Habituellement, l'exécution d'une boucle d'événements à thread unique dans un cœur de processeur est plus que suffisante. Il est également possible d'exécuter des boucles d'événements sur plusieurs cœurs. Consultez cetalk by John Reese pour en savoir plus et soyez averti que votre ordinateur portable peut brûler spontanément.
Les boucles d'événements#3. sont enfichables. Autrement dit, vous pourriez, si vous le vouliez vraiment, écrire votre propre implémentation de boucle d'événements et lui faire exécuter des tâches de la même manière. Ceci est merveilleusement démontré dans le packageuvloop, qui est une implémentation de la boucle d'événements en Cython.
C'est ce que l'on entend par le terme «boucle d'événement enfichable»: vous pouvez utiliser n'importe quelle implémentation fonctionnelle d'une boucle d'événement, sans rapport avec la structure des coroutines elles-mêmes. Le packageasyncio lui-même est livré avectwo different event loop implementations, la valeur par défaut étant basée sur le moduleselectors. (La deuxième implémentation est conçue pour Windows uniquement.)
Un programme complet: demandes asynchrones
Vous avez fait jusqu'ici, et maintenant il est temps pour la partie amusante et indolore. Dans cette section, vous allez créer un collecteur d'URL de capture Web,areq.py, à l'aide deaiohttp, une infrastructure client / serveur HTTP asynchrone incroyablement rapide. (Nous avons juste besoin de la partie client.) Un tel outil pourrait être utilisé pour cartographier les connexions entre un cluster de sites, les liens formant undirected graph.
Note: Vous vous demandez peut-être pourquoi le packagerequests de Python n'est pas compatible avec Async IO. requests est construit sururllib3, qui à son tour utilise les moduleshttp etsocket de Python.
Par défaut, les opérations de socket bloquent. Cela signifie que Python n’aimera pasawait requests.get(url) car.get() n’est pas en attente. En revanche, presque tout dansaiohttp est une coroutine attendue, commesession.request() etresponse.text(). Sinon, c’est un excellent package, mais vous ne vous rendez pas service en utilisantrequests dans du code asynchrone.
La structure du programme de haut niveau ressemblera à ceci:
-
Lire une séquence d'URL à partir d'un fichier local,
urls.txt. -
Envoyez des requêtes GET pour les URL et décodez le contenu résultant. Si cela échoue, arrêtez-vous là pour une URL.
-
Recherchez les URL dans les balises
hrefdans le HTML des réponses. -
Écrivez les résultats dans
foundurls.txt. -
Faites tout ce qui précède aussi asynchrone et simultanément que possible. (Utilisez
aiohttppour les requêtes etaiofilespour les fichiers-appends. Ce sont deux exemples principaux d'E / S qui conviennent bien au modèle d'E / S asynchrone.)
Voici le contenu deurls.txt. Ce n'est pas énorme et contient principalement des sites très fréquentés:
$ cat urls.txt
https://regex101.com/
https://docs.python.org/3/this-url-will-404.html
https://www.nytimes.com/guides/
https://www.mediamatters.org/
https://1.1.1.1/
https://www.politico.com/tipsheets/morning-money
https://www.bloomberg.com/markets/economics
https://www.ietf.org/rfc/rfc2616.txtLa deuxième URL de la liste doit renvoyer une réponse 404, que vous devrez gérer avec élégance. Si vous exécutez une version étendue de ce programme, vous devrez probablement faire face à des problèmes beaucoup plus épineux que celui-ci, comme des déconnexions de serveur et des redirections sans fin.
Les demandes elles-mêmes doivent être effectuées à l'aide d'une seule session, pour profiter de la réutilisation du pool de connexions internes de la session.
Jetons un œil au programme complet. Nous allons parcourir les choses étape par étape après:
#!/usr/bin/env python3
# areq.py
"""Asynchronously get links embedded in multiple pages' HMTL."""
import asyncio
import logging
import re
import sys
from typing import IO
import urllib.error
import urllib.parse
import aiofiles
import aiohttp
from aiohttp import ClientSession
logging.basicConfig(
format="%(asctime)s %(levelname)s:%(name)s: %(message)s",
level=logging.DEBUG,
datefmt="%H:%M:%S",
stream=sys.stderr,
)
logger = logging.getLogger("areq")
logging.getLogger("chardet.charsetprober").disabled = True
HREF_RE = re.compile(r'href="(.*?)"')
async def fetch_html(url: str, session: ClientSession, **kwargs) -> str:
"""GET request wrapper to fetch page HTML.
kwargs are passed to `session.request()`.
"""
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()
logger.info("Got response [%s] for URL: %s", resp.status, url)
html = await resp.text()
return html
async def parse(url: str, session: ClientSession, **kwargs) -> set:
"""Find HREFs in the HTML of `url`."""
found = set()
try:
html = await fetch_html(url=url, session=session, **kwargs)
except (
aiohttp.ClientError,
aiohttp.http_exceptions.HttpProcessingError,
) as e:
logger.error(
"aiohttp exception for %s [%s]: %s",
url,
getattr(e, "status", None),
getattr(e, "message", None),
)
return found
except Exception as e:
logger.exception(
"Non-aiohttp exception occured: %s", getattr(e, "__dict__", {})
)
return found
else:
for link in HREF_RE.findall(html):
try:
abslink = urllib.parse.urljoin(url, link)
except (urllib.error.URLError, ValueError):
logger.exception("Error parsing URL: %s", link)
pass
else:
found.add(abslink)
logger.info("Found %d links for %s", len(found), url)
return found
async def write_one(file: IO, url: str, **kwargs) -> None:
"""Write the found HREFs from `url` to `file`."""
res = await parse(url=url, **kwargs)
if not res:
return None
async with aiofiles.open(file, "a") as f:
for p in res:
await f.write(f"{url}\t{p}\n")
logger.info("Wrote results for source URL: %s", url)
async def bulk_crawl_and_write(file: IO, urls: set, **kwargs) -> None:
"""Crawl & write concurrently to `file` for multiple `urls`."""
async with ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
write_one(file=file, url=url, session=session, **kwargs)
)
await asyncio.gather(*tasks)
if __name__ == "__main__":
import pathlib
import sys
assert sys.version_info >= (3, 7), "Script requires Python 3.7+."
here = pathlib.Path(__file__).parent
with open(here.joinpath("urls.txt")) as infile:
urls = set(map(str.strip, infile))
outpath = here.joinpath("foundurls.txt")
with open(outpath, "w") as outfile:
outfile.write("source_url\tparsed_url\n")
asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls))Ce script est plus long que nos programmes de jouets initiaux, alors décomposons-le.
La constanteHREF_RE est une expression régulière pour extraire ce que nous recherchons finalement, les baliseshref dans HTML:
>>>
>>> HREF_RE.search('Go to Real Python')
La coroutinefetch_html() est un wrapper autour d'une requête GET pour effectuer la requête et décoder le HTML de la page résultante. Il fait la demande, attend la réponse, et lève tout de suite dans le cas d'un statut non-200:
resp = await session.request(method="GET", url=url, **kwargs)
resp.raise_for_status()Si l'état est correct,fetch_html() renvoie la page HTML (astr). Notamment, aucune gestion des exceptions n'est effectuée dans cette fonction. La logique est de propager cette exception à l'appelant et de la laisser y être gérée:
html = await resp.text()Nousawaitsession.request() etresp.text() parce que ce sont des coroutines attendues. Le cycle de demande / réponse serait autrement la partie longue traîne et monopolisant le temps de l'application, mais avec les E / S asynchrones,fetch_html() laisse la boucle d'événements fonctionner sur d'autres tâches facilement disponibles telles que l'analyse et l'écriture d'URL qui ont déjà été récupéré.
Ensuite dans la chaîne de coroutines vientparse(), qui attend surfetch_html() une URL donnée, puis extrait toutes les baliseshref du HTML de cette page, en s'assurant que chacune est valide et le formatant comme un chemin absolu.
Certes, la deuxième partie deparse() est bloquante, mais elle consiste en une correspondance rapide de regex et en s'assurant que les liens découverts sont transformés en chemins absolus.
Dans ce cas spécifique, ce code synchrone doit être rapide et discret. Mais rappelez-vous simplement que toute ligne dans une coroutine donnée bloquera les autres coroutines à moins que cette ligne n'utiliseyield,await oureturn. Si l'analyse était un processus plus intensif, vous voudrez peut-être envisager d'exécuter cette partie dans son propre processus avecloop.run_in_executor().
Ensuite, la coroutinewrite() prend un objet fichier et une seule URL, et attend leparse() pour renvoyer unset des URL analysées, en écrivant chacune dans le fichier de manière asynchrone avec son URL source via l'utilisation deaiofiles, un package pour les E / S de fichiers asynchrones.
Enfin,bulk_crawl_and_write() sert de point d’entrée principal dans la chaîne de coroutines du script. Il utilise une seule session et une tâche est créée pour chaque URL qui est finalement lue à partir deurls.txt.
Voici quelques points supplémentaires qui méritent d'être mentionnés:
-
Le
ClientSessionpar défaut a unadapter avec un maximum de 100 connexions ouvertes. Pour changer cela, passez une instance deasyncio.connector.TCPConnectoràClientSession. Vous pouvez également spécifier des limites par hôte. -
Vous pouvez spécifier maxtimeouts pour la session dans son ensemble et pour les demandes individuelles.
-
Ce script utilise également
async with, qui fonctionne avec unasynchronous context manager. Je n'ai pas consacré une section entière à ce concept car la transition des gestionnaires de contexte synchrones aux gestionnaires de contexte asynchrones est assez simple. Ce dernier doit définir.__aenter__()et.__aexit__()plutôt que.__exit__()et.__enter__(). Comme vous vous en doutez,async withne peut être utilisé qu'à l'intérieur d'une fonction coroutine déclarée avecasync def.
Si vous souhaitez explorer un peu plus, lescompanion files de ce tutoriel sur GitHub ont également des commentaires et des docstrings attachés.
Voici l'exécution dans toute sa splendeur, carareq.py obtient, analyse et enregistre les résultats de 9 URL en moins d'une seconde:
$ python3 areq.py
21:33:22 DEBUG:asyncio: Using selector: KqueueSelector
21:33:22 INFO:areq: Got response [200] for URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 115 links for https://www.mediamatters.org/
21:33:22 INFO:areq: Got response [200] for URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Got response [200] for URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.ietf.org/rfc/rfc2616.txt
21:33:22 ERROR:areq: aiohttp exception for https://docs.python.org/3/this-url-will-404.html [404]: Not Found
21:33:22 INFO:areq: Found 120 links for https://www.nytimes.com/guides/
21:33:22 INFO:areq: Found 143 links for https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Wrote results for source URL: https://www.mediamatters.org/
21:33:22 INFO:areq: Found 0 links for https://www.ietf.org/rfc/rfc2616.txt
21:33:22 INFO:areq: Got response [200] for URL: https://1.1.1.1/
21:33:22 INFO:areq: Wrote results for source URL: https://www.nytimes.com/guides/
21:33:22 INFO:areq: Wrote results for source URL: https://www.politico.com/tipsheets/morning-money
21:33:22 INFO:areq: Got response [200] for URL: https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Found 3 links for https://www.bloomberg.com/markets/economics
21:33:22 INFO:areq: Wrote results for source URL: https://www.bloomberg.com/markets/economics
21:33:23 INFO:areq: Found 36 links for https://1.1.1.1/
21:33:23 INFO:areq: Got response [200] for URL: https://regex101.com/
21:33:23 INFO:areq: Found 23 links for https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://regex101.com/
21:33:23 INFO:areq: Wrote results for source URL: https://1.1.1.1/Ce n'est pas trop minable! À titre de vérification d'esprit, vous pouvez vérifier le nombre de lignes sur la sortie. Dans mon cas, c'est 626, mais gardez à l'esprit que cela peut varier:
$ wc -l foundurls.txt
626 foundurls.txt
$ head -n 3 foundurls.txt
source_url parsed_url
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/feedback
https://www.bloomberg.com/markets/economics https://www.bloomberg.com/notices/tosNext Steps: si vous souhaitez augmenter la mise, rendez ce webcrawler récursif. Vous pouvez utiliseraio-redis pour garder une trace des URL qui ont été explorées dans l’arborescence pour éviter de les demander deux fois, et connecter des liens avec la bibliothèquenetworkx de Python.
N'oubliez pas d'être gentil. L'envoi de 1000 demandes simultanées à un petit site Web sans méfiance est mauvais, mauvais, mauvais. Il existe des moyens de limiter le nombre de requêtes simultanées que vous effectuez dans un lot, par exemple en utilisant les objetssempahore deasyncio ou en utilisant un modèlelike this one. Si vous ne tenez pas compte de cet avertissement, vous risquez d’obtenir un lot massif d’exceptionsTimeoutError et de nuire à votre propre programme.
Async IO dans le contexte
Maintenant que vous avez vu une bonne dose de code, prenons un peu de recul et considérons quand async IO est une option idéale et comment vous pouvez faire la comparaison pour arriver à cette conclusion ou choisir un autre modèle de concurrence.
Quand et pourquoi Async IO est-il le bon choix?
Ce tutoriel n'est pas un endroit pour un traité étendu sur asynchrone IO versus threading contre multiprocessing. Cependant, il est utile de savoir quand async IO est probablement le meilleur candidat des trois.
La bataille entre Async IO et multiprocessing n'est pas vraiment une bataille du tout. En fait, ils peuvent êtreused in concert. Si vous avez plusieurs tâches liées au processeur assez uniformes (un bon exemple est ungrid search dans des bibliothèques telles quescikit-learn oukeras), le multitraitement devrait être un choix évident.
Mettre simplementasync avant chaque fonction est une mauvaise idée si toutes les fonctions utilisent des appels de blocage. (Cela peut en fait ralentir votre code.) Mais comme mentionné précédemment, il y a des endroits où les E / S asynchrones et le multitraitement peuventlive in harmony.
Le concours entre async IO et threading est un peu plus direct. J'ai mentionné dans l'introduction que «l'enfilage est difficile». L'histoire complète est que, même dans les cas où le filetage semble facile à mettre en œuvre, il peut toujours conduire à des infâmes bogues impossibles à tracer en raison des conditions de concurrence et de l'utilisation de la mémoire, entre autres.
Le threading a également tendance à évoluer de manière moins élégante que les asynchrones d'E / S, car les threads sont une ressource système avec une disponibilité limitée. La création de milliers de threads échouera sur de nombreuses machines et je ne recommande pas de l'essayer en premier lieu. La création de milliers de tâches d'E / S asynchrones est tout à fait possible.
Async IO brille lorsque vous avez plusieurs tâches liées aux E / S où les tâches seraient sinon dominées par le blocage du temps d'attente lié aux E / S, comme:
-
E / S réseau, que votre programme soit côté serveur ou côté client
-
Conceptions sans serveur, comme un réseau multi-utilisateurs peer-to-peer comme un salon de discussion de groupe
-
Read/write operations where you want to mimic a “fire-and-forget” style but worry less about holding a lock on whatever you’re reading and writing to
La principale raison de ne pas l'utiliser est queawait ne prend en charge qu'un ensemble spécifique d'objets qui définissent un ensemble spécifique de méthodes. Si vous souhaitez effectuer des opérations de lecture asynchrone avec un certain SGBD, vous devez trouver non seulement un wrapper Python pour ce SGBD, mais aussi un qui prend en charge la syntaxeasync /await. Les coroutines qui contiennent des appels synchrones bloquent l'exécution d'autres coroutines et tâches.
Pour une liste restreinte des bibliothèques qui fonctionnent avecasync /await, consultez leslist à la fin de ce didacticiel.
Async IO It Is, mais lequel?
Ce didacticiel se concentre sur les E / S asynchrones, la syntaxeasync /await et l'utilisation deasyncio pour la gestion de la boucle d'événements et la spécification des tâches. asyncio n'est certainement pas la seule bibliothèque d'E / S asynchrones disponible. Cette observation de Nathaniel J. Smith en dit long:
[Dans] quelques années,
asynciopourrait se trouver relégué pour devenir l'une de ces bibliothèques stdlib que les développeurs avertis évitent, commeurllib2.…
Ce que j’affirme, en fait, c’est que
asyncioest victime de son propre succès: lorsqu’il a été conçu, il a utilisé la meilleure approche possible; mais depuis, le travail inspiré deasyncio- comme l'ajout deasync/await- a déplacé le paysage pour que nous puissions faire encore mieux, et maintenantasyncioest paralysé par ses engagements antérieurs. (Source)
À cette fin, quelques grandes alternatives qui font ce que faitasyncio, bien qu'avec différentes API et différentes approches, sontcurio ettrio. Personnellement, je pense que si vous construisez un programme simple et de taille moyenne, le simple fait d’utiliserasyncio est largement suffisant et compréhensible, et vous permet d’éviter d’ajouter une autre grande dépendance en dehors de la bibliothèque standard de Python.
Mais par tous les moyens, vérifiezcurio ettrio, et vous constaterez peut-être qu'ils font la même chose d'une manière plus intuitive pour vous en tant qu'utilisateur. De nombreux concepts indépendants des packages présentés ici devraient également se propager à d'autres packages d'E / S asynchrones.
Bouts
Dans ces prochaines sections, vous couvrirez quelques parties diverses deasyncio etasync /await qui ne rentrent pas parfaitement dans le didacticiel jusqu'à présent, mais qui sont toujours importantes pour la construction et comprendre un programme complet.
Autres fonctionsasyncio de niveau supérieur
En plus deasyncio.run(), vous avez vu quelques autres fonctions au niveau du package telles queasyncio.create_task() etasyncio.gather().
Vous pouvez utilisercreate_task() pour planifier l'exécution d'un objet coroutine, suivi deasyncio.run():
>>>
>>> import asyncio
>>> async def coro(seq) -> list:
... """'IO' wait time is proportional to the max element."""
... await asyncio.sleep(max(seq))
... return list(reversed(seq))
...
>>> async def main():
... # This is a bit redundant in the case of one task
... # We could use `await coro([3, 2, 1])` on its own
... t = asyncio.create_task(coro([3, 2, 1])) # Python 3.7+
... await t
... print(f't: type {type(t)}')
... print(f't done: {t.done()}')
...
>>> t = asyncio.run(main())
t: type
t done: True Il y a une subtilité dans ce modèle: si vous n’avez pasawait t dans lesmain(), il peut se terminer avant quemain() lui-même ne signale qu’il est terminé. Parce queasyncio.run(main())calls loop.run_until_complete(main()), la boucle d'événements est uniquement concernée (sansawait t présent) quemain() est terminé, pas que les tâches créées dansmain() sont terminé. Sansawait t, les autres tâches de la bouclewill be cancelled, peut-être avant qu’elles ne soient terminées. Si vous avez besoin d'obtenir une liste des tâches actuellement en attente, vous pouvez utiliserasyncio.Task.all_tasks().
Note:asyncio.create_task() a été introduit dans Python 3.7. Dans Python 3.6 ou version antérieure, utilisezasyncio.ensure_future() à la place decreate_task().
Séparément, il y aasyncio.gather(). Bien qu'il ne fasse rien de très spécial,gather() est censé placer proprement une collection de coroutines (futurs) dans un seul avenir. Par conséquent, il renvoie un seul objet futur et, si vousawait asyncio.gather() et spécifiez plusieurs tâches ou coroutines, vous attendez qu’elles soient toutes terminées. (Cela ressemble quelque peu àqueue.join() de notre exemple précédent.) Le résultat degather() sera une liste des résultats à travers les entrées:
>>>
>>> import time
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0])) # Python 3.7+
... print('Start:', time.strftime('%X'))
... a = await asyncio.gather(t, t2)
... print('End:', time.strftime('%X')) # Should be 10 seconds
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
... return a
...
>>> a = asyncio.run(main())
Start: 16:20:11
End: 16:20:21
Both tasks done: True
>>> aVous avez probablement remarqué quegather() attend sur l'ensemble de résultats des Futures ou des coroutines que vous le transmettez. Vous pouvez également effectuer une boucle surasyncio.as_completed() pour obtenir les tâches au fur et à mesure qu'elles sont terminées, dans l'ordre d'achèvement. La fonction renvoie un itérateur qui produit des tâches à mesure qu'elles se terminent. Ci-dessous, le résultat decoro([3, 2, 1]) sera disponible avant quecoro([10, 5, 0]) ne soit terminé, ce qui n'est pas le cas avecgather():
>>>
>>> async def main():
... t = asyncio.create_task(coro([3, 2, 1]))
... t2 = asyncio.create_task(coro([10, 5, 0]))
... print('Start:', time.strftime('%X'))
... for res in asyncio.as_completed((t, t2)):
... compl = await res
... print(f'res: {compl} completed at {time.strftime("%X")}')
... print('End:', time.strftime('%X'))
... print(f'Both tasks done: {all((t.done(), t2.done()))}')
...
>>> a = asyncio.run(main())
Start: 09:49:07
res: [1, 2, 3] completed at 09:49:10
res: [0, 5, 10] completed at 09:49:17
End: 09:49:17
Both tasks done: TrueEnfin, vous pouvez également voirasyncio.ensure_future(). Vous devriez rarement en avoir besoin, car il s'agit d'une API de plomberie de niveau inférieur et largement remplacée parcreate_task(), qui a été introduite plus tard.
La précédence deawait
Bien qu'ils se comportent quelque peu de la même manière, le mot cléawait a une priorité significativement plus élevée queyield. Cela signifie que, comme il est plus étroitement lié, il existe un certain nombre d’instances où vous auriez besoin de parenthèses dans une instructionyield from qui ne sont pas requises dans une instructionawait analogue. Pour plus d'informations, voirexamples of await expressions de PEP 492.
Conclusion
Vous êtes maintenant équipé pour utiliserasync /await et les bibliothèques qui en sont issues. Voici un récapitulatif de ce que vous avez couvert:
-
E / S asynchrone en tant que modèle indépendant du langage et moyen d'effectuer la concurrence en permettant aux coroutines de communiquer indirectement les unes avec les autres
-
Les spécificités des nouveaux mots-clés
asyncetawaitde Python, utilisés pour marquer et définir les coroutines -
asyncio, le package Python qui fournit l'API pour exécuter et gérer les coroutines
Ressources
Spécificités de la version de Python
Async IO en Python a évolué rapidement, et il peut être difficile de garder une trace de ce qui s'est passé et quand. Voici une liste des modifications et introductions des versions mineures de Python liées àasyncio:
-
3.3: The
yield fromexpression allows for generator delegation. -
3.4:
asynciowas introduced in the Python standard library with provisional API status. -
3.5:
asyncandawaitbecame a part of the Python grammar, used to signify and wait on coroutines. Ce n'étaient pas encore des mots clés réservés. (Vous pouvez toujours définir des fonctions ou des variables nomméesasyncetawait.) -
3.6: Asynchronous generators and asynchronous comprehensions were introduced. L'API de
asyncioa été déclarée stable plutôt que provisoire. -
3.7:
asyncandawaitbecame reserved keywords. (Ils ne peuvent pas être utilisés comme identificateurs.) Ils sont destinés à remplacer le décorateur deasyncio.coroutine().asyncio.run()a été introduit dans le packageasyncio, parmi lesa bunch of other features.
Si vous voulez être en sécurité (et pouvoir utiliserasyncio.run()), utilisez Python 3.7 ou supérieur pour obtenir l'ensemble complet des fonctionnalités.
Des articles
Voici une liste organisée de ressources supplémentaires:
-
Python réel:Speed up your Python Program with Concurrency
-
Python réel:What is the Python Global Interpreter Lock?
-
CPython: Le package
asynciosource -
Documentation Python:Data model > Coroutines
-
TalkPython:Async Techniques and Examples in Pythonhttps://github.com/talkpython/async-techniques-python-course
-
Canon Brett:How the Heck Does Async-Await Work in Python 3.5?
-
PYMOTW:
asyncio -
A. Jesse Jiryu Davis et Guido van Rossum:A Web Crawler With asyncio Coroutines
-
Andy Pearce:The State of Python Coroutines:
yield from -
Nathaniel J. Smith:Some Thoughts on Asynchronous API Design in a Post-
async/awaitWorld -
Armin Ronacher:I don’t understand Python’s Asyncio
-
Andy Balaam:series on
asyncio(4 messages) -
Dépassement de pile:Python
asyncio.semaphoreinasync-awaitfunction -
Yeray Diaz:
Quelques sections de PythonWhat’s Newexpliquent plus en détail la motivation derrière les changements de langage:
-
What’s New in Python 3.3 (
yield fromet PEP 380) -
What’s New in Python 3.6 (PEP 525 et 530)
De David Beazley:
Discussions sur YouTube:
-
John Reese - Penser en dehors du GIL avec AsyncIO et le multitraitement - PyCon 2018
-
David Beazley - Python Concurrency From the Ground Up: LIVE! - PyCon 2015
-
Réflexion sur la concurrence, Raymond Hettinger, développeur principal Python
-
Miguel Grinberg Asynchronous Python pour la PyCon débutant complète 2017
-
Yury Selivanov asyncawait et asyncio dans Python 3 6 et au-delà PyCon 2017
-
Fear and Awaiting in Async: A Savage Journey to the Heart of the Coroutine Dream
-
Qu'est-ce qu'Async, comment fonctionne-t-il et quand dois-je l'utiliser? (PyCon APAC 2014)
PEP liés
| PEP | date créée |
|---|---|
2005-05 |
|
2009-02 |
|
2011-05 |
|
PEP 3156 - Prise en charge d'E / S asynchrones redémarrée: le module «asyncio» |
2012-12 |
2015-04 |
|
07/2016 |
|
09/2016 |
Bibliothèques qui fonctionnent avecasync /await
À partir deaio-libs:
-
aiohttp: structure client / serveur HTTP asynchrone -
aioredis: prise en charge Async IO Redis -
aiopg: prise en charge Async IO PostgreSQL -
aiomcache: client memcached Async IO -
aiokafka: client Async IO Kafka -
aiozmq: prise en charge Async IO ZeroMQ -
aiojobs: planificateur de travaux pour gérer les tâches en arrière-plan -
async_lru: cache LRU simple pour les E / S asynchrones
À partir demagicstack:
Des autres hôtes:
-
trio: Friendlierasynciodestiné à présenter une conception radicalement plus simple -
aiofiles: E / S de fichier asynchrone -
asks: bibliothèque http de type requêtes asynchrones -
asyncio-redis: prise en charge Async IO Redis -
aioprocessing: intègre le modulemultiprocessingavecasyncio -
umongo: client Async IO MongoDB -
unsync: désynchroniserasyncio -
aiostream: commeitertools, mais asynchrone