Einführung
Jede Anwendung oder Website, die ein erhebliches Wachstum verzeichnet, muss möglicherweise skaliert werden, um dem Anstieg des Datenverkehrs Rechnung zu tragen. Bei datengesteuerten Anwendungen und Websites ist es wichtig, dass die Skalierung so erfolgt, dass die Sicherheit und Integrität der Daten gewährleistet ist. Es kann schwierig sein, vorherzusagen, wie beliebt oder wie lange eine Website oder Anwendung sein wird, weshalb einige Unternehmen eine Datenbankarchitektur wählen, mit der sie ihre Datenbanken dynamisch skalieren können.
In diesem konzeptionellen Artikel werden wir eine solche Datenbankarchitektur diskutieren:sharded databases. Sharding hat in den letzten Jahren viel Aufmerksamkeit erhalten, aber viele wissen nicht genau, was es ist oder in welchen Szenarien es sinnvoll sein könnte, eine Datenbank zu sharden. Wir werden uns ansehen, was Scherben sind, welche Vor- und Nachteile sie haben und welche gängigen Scherbenmethoden es gibt.
Was ist Scherben?
Sharding ist ein Datenbankarchitekturmuster, das sich aufhorizontal partitioning bezieht - die Praxis, die Zeilen einer Tabelle in mehrere verschiedene Tabellen zu trennen, die als Partitionen bezeichnet werden. Jede Partition hat dasselbe Schema und dieselben Spalten, aber auch völlig unterschiedliche Zeilen. Ebenso sind die Daten in den einzelnen Partitionen eindeutig und unabhängig von den Daten in den anderen Partitionen.
Es kann hilfreich sein, sich die horizontale Partitionierung in Bezug aufvertical partitioning vorzustellen. In einer vertikal partitionierten Tabelle werden ganze Spalten herausgetrennt und in neue, unterschiedliche Tabellen eingefügt. Die Daten in einer vertikalen Partition sind unabhängig von den Daten in allen anderen Partitionen und enthalten jeweils unterschiedliche Zeilen und Spalten. Das folgende Diagramm zeigt, wie eine Tabelle sowohl horizontal als auch vertikal partitioniert werden kann:
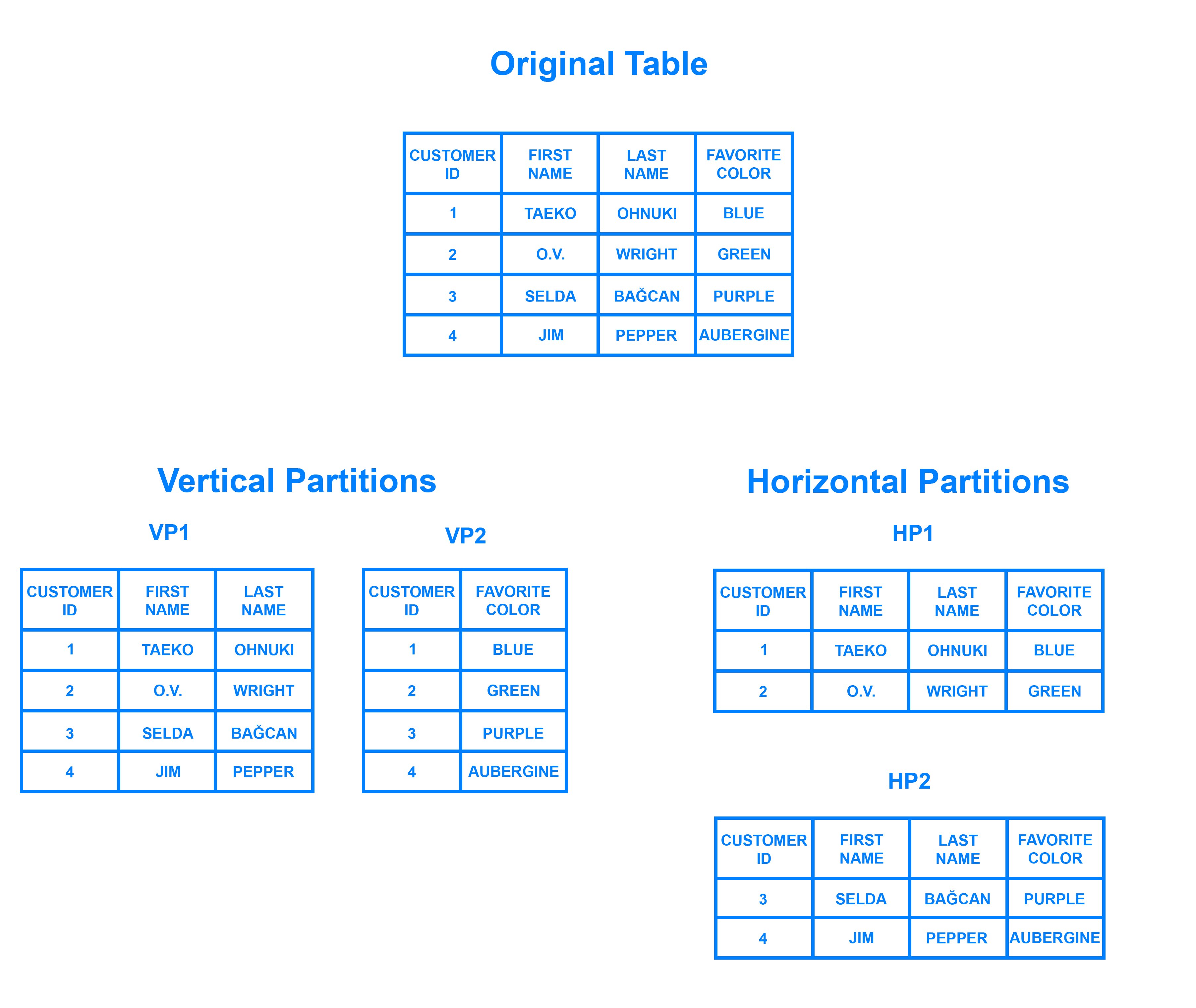
Beim Sharding werden die Daten in zwei oder mehr kleinere Blöcke aufgeteilt, die alslogical shards bezeichnet werden. Die logischen Shards werden dann auf separate Datenbankknoten verteilt, die alsphysical shards bezeichnet werden und mehrere logische Shards enthalten können. Trotzdem stellen die in allen Shards enthaltenen Daten zusammen einen gesamten logischen Datensatz dar.
Datenbank-Shards veranschaulichen einshared-nothing architecture. Dies bedeutet, dass die Scherben autonom sind; Sie teilen sich keine Daten oder Rechenressourcen. In einigen Fällen kann es jedoch sinnvoll sein, bestimmte Tabellen in jeden Shard zu replizieren, um als Referenztabellen zu dienen. Angenommen, es gibt eine Datenbank für eine Anwendung, die von festen Umrechnungskursen für Gewichtsmessungen abhängt. Durch das Replizieren einer Tabelle mit den erforderlichen Conversion-Rate-Daten in jeden Shard kann sichergestellt werden, dass alle für Abfragen erforderlichen Daten in jedem Shard gespeichert sind.
Oft wird das Sharding auf Anwendungsebene implementiert, was bedeutet, dass die Anwendung Code enthält, der definiert, auf welchen Shard Lese- und Schreibvorgänge übertragen werden sollen. Einige Datenbankverwaltungssysteme verfügen jedoch über integrierte Sharding-Funktionen, mit denen Sie Sharding direkt auf Datenbankebene implementieren können.
In Anbetracht dieses allgemeinen Überblicks über das Sharding gehen wir einige der mit dieser Datenbankarchitektur verbundenen positiven und negativen Aspekte durch.
Vorteile von Sharding
Der Hauptanreiz beim Sharding einer Datenbank besteht darin, dass sie dazu beitragen kann,horizontal scaling, auch alsscaling out bezeichnet, zu vereinfachen. Bei der horizontalen Skalierung werden einem vorhandenen Stapel mehr Maschinen hinzugefügt, um die Last zu verteilen und mehr Verkehr und eine schnellere Verarbeitung zu ermöglichen. Dies steht häufig im Gegensatz zuvertical scaling, auch bekannt alsscaling up, bei dem die Hardware eines vorhandenen Servers aktualisiert wird, normalerweise durch Hinzufügen von mehr RAM oder CPU.
Es ist relativ einfach, eine relationale Datenbank auf einem einzelnen Computer auszuführen und sie nach Bedarf zu skalieren, indem die Computerressourcen aktualisiert werden. Letztendlich wird jedoch jede nicht verteilte Datenbank in Bezug auf Speicherplatz und Rechenleistung begrenzt sein, sodass die Möglichkeit der horizontalen Skalierung Ihr Setup wesentlich flexibler macht.
Ein weiterer Grund, warum sich manche für eine Sharded-Datenbankarchitektur entscheiden, ist die schnellere Beantwortung von Anfragen. Wenn Sie eine Abfrage in einer Datenbank senden, die nicht gesharded wurde, muss sie möglicherweise jede Zeile in der Tabelle durchsuchen, die Sie abfragen, bevor die gesuchte Ergebnismenge gefunden werden kann. Bei einer Anwendung mit einer großen, monolithischen Datenbank können Abfragen sehr langsam werden. Durch das Teilen einer Tabelle in mehrere müssen Abfragen jedoch weniger Zeilen umfassen, und ihre Ergebnismengen werden viel schneller zurückgegeben.
Sharding kann auch dazu beitragen, eine Anwendung zuverlässiger zu machen, indem die Auswirkungen von Ausfällen gemindert werden. Wenn Ihre Anwendung oder Website auf einer nicht gesicherten Datenbank basiert, kann ein Ausfall dazu führen, dass die gesamte Anwendung nicht verfügbar ist. Bei einer Sharded-Datenbank wirkt sich ein Ausfall jedoch wahrscheinlich nur auf einen einzigen Shard aus. Auch wenn dies dazu führen kann, dass einige Teile der Anwendung oder Website für einige Benutzer nicht verfügbar sind, ist die Gesamtauswirkung dennoch geringer als bei einem Absturz der gesamten Datenbank.
Nachteile des Splitterns
Das Sharding einer Datenbank kann die Skalierung vereinfachen und die Leistung verbessern, kann jedoch auch bestimmte Einschränkungen mit sich bringen. Hier werden wir einige davon diskutieren und erklären, warum dies Gründe sein könnten, um Scherben zu vermeiden.
Die erste Schwierigkeit, auf die Menschen beim Sharding stoßen, ist die Komplexität der ordnungsgemäßen Implementierung einer Sharded-Datenbankarchitektur. Bei fehlerhafter Ausführung besteht ein erhebliches Risiko, dass der Sharding-Prozess zu Datenverlust oder beschädigten Tabellen führen kann. Selbst wenn dies korrekt durchgeführt wird, hat das Splittern wahrscheinlich einen großen Einfluss auf die Arbeitsabläufe Ihres Teams. Anstatt von einem einzigen Einstiegspunkt aus auf die Daten zuzugreifen und diese zu verwalten, müssen Benutzer Daten über mehrere Shard-Standorte hinweg verwalten, was für einige Teams möglicherweise störend sein kann.
Ein Problem, auf das Benutzer nach dem Löschen einer Datenbank manchmal stoßen, besteht darin, dass die Scherben schließlich aus dem Gleichgewicht geraten. Angenommen, Sie haben eine Datenbank mit zwei separaten Shards, einer für Kunden, deren Nachnamen mit den Buchstaben A bis M beginnen, und einer für Kunden, deren Namen mit den Buchstaben N bis Z beginnen. Ihre Bewerbung dient jedoch einer übermäßigen Anzahl von Personen, deren Nachname mit dem Buchstaben G beginnt. Dementsprechend sammelt der A-M-Shard nach und nach mehr Daten als der N-Z-Shard, sodass die Anwendung langsamer wird und für einen erheblichen Teil Ihrer Benutzer nicht mehr funktioniert. Der A-M-Splitter ist zu einem sogenanntendatabase hotspot geworden. In diesem Fall werden alle Vorteile des Shardings der Datenbank durch die Verlangsamungen und Abstürze aufgehoben. Die Datenbank müsste wahrscheinlich repariert und erneut gesichert werden, um eine gleichmäßigere Datenverteilung zu ermöglichen.
Ein weiterer großer Nachteil ist, dass es nach dem Sharding einer Datenbank sehr schwierig sein kann, sie wieder in ihre nicht gesicherte Architektur zu versetzen. Alle Backups der Datenbank, die vor dem Löschen erstellt wurden, enthalten keine Daten, die seit der Partitionierung geschrieben wurden. Infolgedessen würde das Wiederherstellen der ursprünglichen, nicht gesicherten Architektur das Zusammenführen der neuen, partitionierten Daten mit den alten Sicherungen oder alternativ das Zurücktransformieren der partitionierten Datenbank in eine einzelne Datenbank erfordern, was kostspielig und zeitaufwendig wäre.
Ein letzter zu berücksichtigender Nachteil ist, dass Sharding nicht von jedem Datenbankmodul nativ unterstützt wird. Beispielsweise enthält PostgreSQL kein automatisches Sharding als Feature, obwohl es möglich ist, eine PostgreSQL-Datenbank manuell zu sharden. Es gibt eine Reihe von Postgres-Gabeln, die automatisches Sharding enthalten, die jedoch häufig hinter der neuesten PostgreSQL-Version zurückbleiben und denen bestimmte andere Funktionen fehlen. Einige spezialisierte Datenbanktechnologien - wie MySQL Cluster oder bestimmte Database-as-a-Service-Produkte wie MongoDB Atlas - enthalten als Feature Auto-Sharding, Vanilla-Versionen dieser Datenbankverwaltungssysteme jedoch nicht. Aus diesem Grund erfordert Sharding oft einen eigenen Ansatz. Dies bedeutet, dass die Dokumentation zum Sharding oder Tipps zur Fehlerbehebung häufig schwer zu finden sind.
Dies sind natürlich nur einige allgemeine Punkte, die vor dem Scherben beachtet werden müssen. Je nach Anwendungsfall kann das Sharding einer Datenbank noch viel mehr Nachteile haben.
Nachdem wir uns nun mit einigen Nachteilen und Vorteilen von Sharding befasst haben, gehen wir auf einige unterschiedliche Architekturen für Sharded-Datenbanken ein.
Sharding-Architekturen
Sobald Sie sich entschieden haben, Ihre Datenbank zu speichern, müssen Sie als Nächstes herausfinden, wie Sie dies tun werden. Beim Ausführen von Abfragen oder beim Verteilen eingehender Daten an geshardete Tabellen oder Datenbanken ist es entscheidend, dass die richtigen Shards verwendet werden. Andernfalls können Daten verloren gehen oder Abfragen schmerzhaft verlangsamt werden. In diesem Abschnitt werden einige gängige Sharding-Architekturen vorgestellt, bei denen jeweils ein geringfügig anderer Prozess zum Verteilen von Daten über Shards verwendet wird.
Schlüsselbasiertes Sharding
BeiKey based sharding, auch alshash based sharding bezeichnet, wird ein Wert verwendet, der aus neu geschriebenen Daten stammt, z. B. die ID-Nummer eines Kunden, die IP-Adresse einer Clientanwendung, eine Postleitzahl usw. - und stecken Sie es inhash function, um zu bestimmen, zu welchem Shard die Daten gehen sollen. Eine Hash-Funktion ist eine Funktion, die ein Datenelement (z. B. eine Kunden-E-Mail) als Eingabe verwendet und einen diskreten Wert ausgibt, der alshash value bezeichnet wird. Beim Sharding ist der Hash-Wert eine Shard-ID, mit der bestimmt wird, auf welcher Shard die eingehenden Daten gespeichert werden. Insgesamt sieht der Prozess so aus:

Um sicherzustellen, dass die Einträge in den richtigen Shards und auf konsistente Weise platziert werden, sollten die in die Hash-Funktion eingegebenen Werte alle aus derselben Spalte stammen. Diese Spalte ist alsshard key bekannt. In einfachen Worten, Shard-Schlüssel ähnelnprimary keys, da beide Spalten verwendet werden, um eine eindeutige Kennung für einzelne Zeilen zu erstellen. Allgemein gesagt sollte ein Shard-Schlüssel statisch sein, dh er sollte keine Werte enthalten, die sich im Laufe der Zeit ändern könnten. Andernfalls würde der Arbeitsaufwand für Aktualisierungsvorgänge erhöht und die Leistung beeinträchtigt.
Während schlüsselbasiertes Sharding eine weit verbreitete Sharding-Architektur ist, kann es schwierig sein, zusätzliche Server dynamisch zu einer Datenbank hinzuzufügen oder daraus zu entfernen. Wenn Sie Server hinzufügen, benötigt jeder einen entsprechenden Hash-Wert und viele Ihrer vorhandenen Einträge, wenn nicht alle, müssen ihrem neuen, korrekten Hash-Wert neu zugeordnet und dann auf den entsprechenden Server migriert werden. Wenn Sie beginnen, die Daten neu auszugleichen, sind weder die neuen noch die alten Hashing-Funktionen gültig. Infolgedessen kann Ihr Server während der Migration keine neuen Daten schreiben, und Ihre Anwendung kann Ausfallzeiten aufweisen.
Die Hauptattraktivität dieser Strategie besteht darin, dass sie zur gleichmäßigen Verteilung von Daten verwendet werden kann, um Hotspots zu verhindern. Da die Daten algorithmisch verteilt werden, ist es nicht erforderlich, eine Karte zu führen, in der alle Daten gespeichert sind, wie dies bei anderen Strategien wie bereichs- oder verzeichnisbasiertem Sharding erforderlich ist.
Range Based Sharding
Range based sharding beinhaltet das Sharding von Daten basierend auf Bereichen eines bestimmten Werts. Nehmen wir zur Veranschaulichung an, Sie haben eine Datenbank, in der Informationen zu allen Produkten im Katalog eines Einzelhändlers gespeichert sind. Sie könnten ein paar verschiedene Shards erstellen und die Informationen für jedes Produkt anhand der Preisspanne aufteilen, in die sie fallen:

Der Hauptvorteil von bereichsbasiertem Sharding besteht darin, dass es relativ einfach zu implementieren ist. Jeder Shard enthält einen anderen Datensatz, aber alle haben ein identisches Schema wie der andere und die ursprüngliche Datenbank. Der Anwendungscode liest nur, in welchen Bereich die Daten fallen, und schreibt sie auf den entsprechenden Shard.
Auf der anderen Seite schützt bereichsbasiertes Sharding die Daten nicht vor ungleichmäßiger Verteilung, was zu den oben genannten Datenbank-Hotspots führt. Betrachtet man das Beispieldiagramm, so besteht die Wahrscheinlichkeit, dass bestimmte Produkte mehr Beachtung finden als andere, selbst wenn jeder Shard die gleiche Menge an Daten enthält. Ihre jeweiligen Shards erhalten wiederum eine unverhältnismäßige Anzahl von Lesevorgängen.
Verzeichnisbasiertes Sharding
Umdirectory based sharding zu implementieren, muss einlookup table erstellt und verwaltet werden, das einen Shard-Schlüssel verwendet, um zu verfolgen, welcher Shard welche Daten enthält. Kurz gesagt, eine Nachschlagetabelle ist eine Tabelle, die statische Informationen darüber enthält, wo bestimmte Daten gefunden werden können. Das folgende Diagramm zeigt ein vereinfachtes Beispiel für verzeichnisbasiertes Sharding:
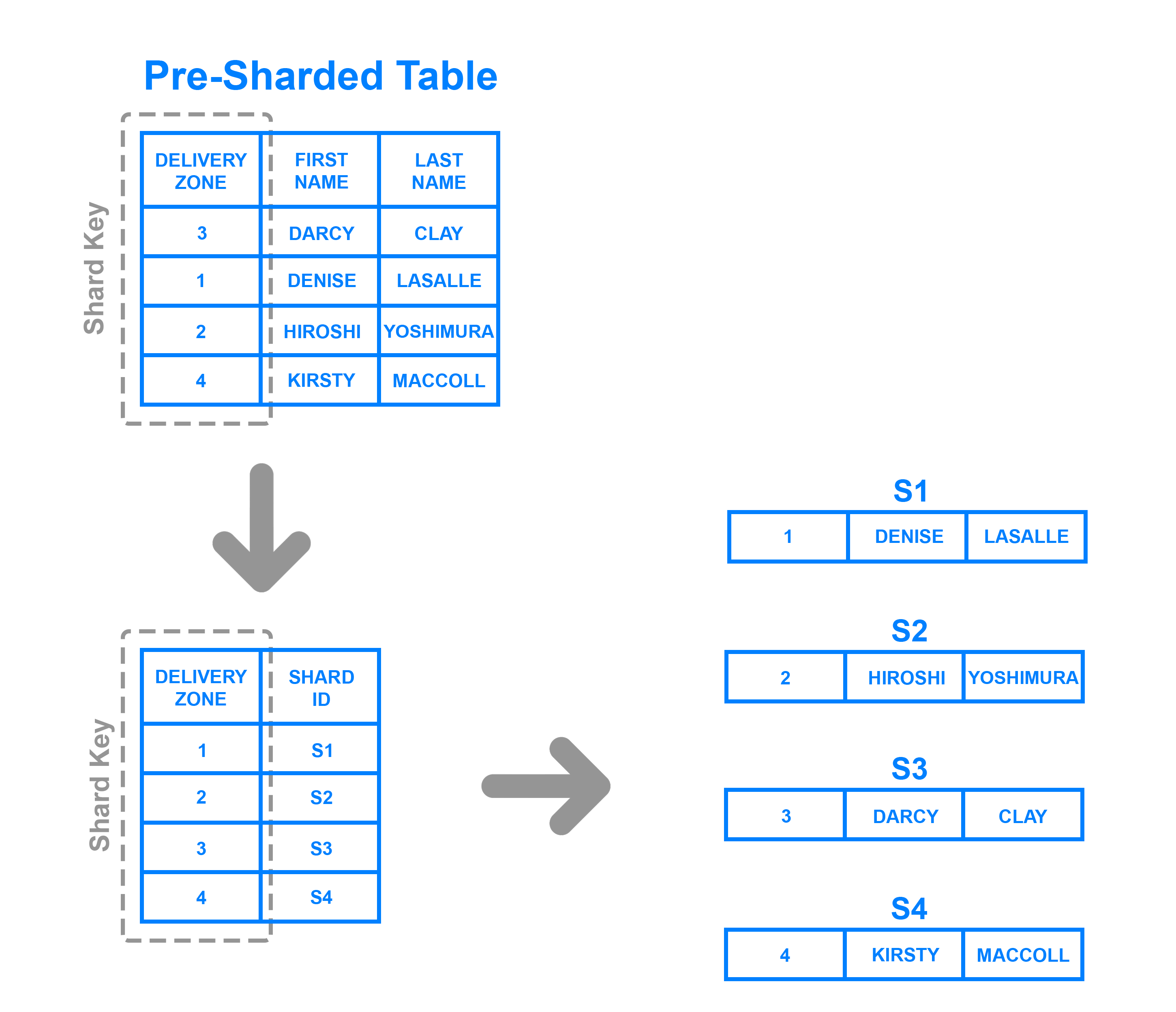
Hier wird die SpalteDelivery Zone als Shard-Schlüssel definiert. Daten vom Shard-Schlüssel werden zusammen mit dem Shard, in den die jeweilige Zeile geschrieben werden soll, in die Nachschlagetabelle geschrieben. Dies ähnelt dem bereichsbasierten Sharding, aber anstatt zu bestimmen, in welchen Bereich die Daten des Shard-Schlüssels fallen, ist jeder Schlüssel an seinen eigenen spezifischen Shard gebunden. Verzeichnisbasiertes Sharding ist eine gute Wahl gegenüber bereichsbasiertem Sharding, wenn der Shard-Schlüssel eine geringe Kardinalität aufweist und es für einen Shard nicht sinnvoll ist, einen Bereich von Schlüsseln zu speichern. Beachten Sie, dass es sich auch dadurch von schlüsselbasiertem Sharding unterscheidet, dass es den Shard-Schlüssel nicht über eine Hash-Funktion verarbeitet. Der Schlüssel wird lediglich anhand einer Nachschlagetabelle überprüft, um festzustellen, wo die Daten geschrieben werden müssen.
Die Hauptattraktivität von verzeichnisbasiertem Sharding ist seine Flexibilität. Auf Bereichen basierende Sharding-Architekturen beschränken Sie auf das Festlegen von Wertebereichen, während auf Schlüsseln basierende Sie auf die Verwendung einer festen Hash-Funktion beschränken, die, wie bereits erwähnt, später möglicherweise nur sehr schwer geändert werden kann. Auf der anderen Seite können Sie mit verzeichnisbasiertem Sharding jedes System oder jeden Algorithmus verwenden, dem Sie Dateneinträge zuweisen möchten. Mit diesem Ansatz ist es relativ einfach, Shards dynamisch hinzuzufügen.
Während das verzeichnisbasierte Sharding die flexibelste der hier diskutierten Sharding-Methoden ist, kann sich die Notwendigkeit, vor jeder Abfrage oder jedem Schreibvorgang eine Verbindung zur Lookup-Tabelle herzustellen, nachteilig auf die Leistung einer Anwendung auswirken. Darüber hinaus kann die Nachschlagetabelle zu einer einzigen Fehlerquelle werden: Wenn sie beschädigt wird oder auf andere Weise ausfällt, kann dies die Fähigkeit beeinträchtigen, neue Daten zu schreiben oder auf vorhandene Daten zuzugreifen.
Soll ich scherben?
Ob man eine Sharded-Datenbankarchitektur implementieren soll oder nicht, ist fast immer umstritten. Einige sehen Sharding als unvermeidliches Ergebnis für Datenbanken, die eine bestimmte Größe erreichen, während andere es als Kopfschmerzen ansehen, die vermieden werden sollten, es sei denn, dies ist aufgrund der durch Sharding verursachten Komplexität unbedingt erforderlich.
Aufgrund dieser zusätzlichen Komplexität wird das Sharding normalerweise nur bei sehr großen Datenmengen durchgeführt. Im Folgenden sind einige häufige Szenarien aufgeführt, in denen das Sharden einer Datenbank von Vorteil sein kann:
-
Die Menge der Anwendungsdaten wächst, um die Speicherkapazität eines einzelnen Datenbankknotens zu überschreiten.
-
Das Volumen der Schreib- oder Lesevorgänge in die Datenbank übersteigt die Anforderungen eines einzelnen Knotens oder seiner Lesereplikate, was zu verlangsamten Antwortzeiten oder Zeitüberschreitungen führt.
-
Die von der Anwendung benötigte Netzwerkbandbreite übersteigt die Bandbreite, die einem einzelnen Datenbankknoten und allen Lesereplikaten zur Verfügung steht, was zu verlangsamten Antwortzeiten oder Timeouts führt.
Vor dem Sharding sollten Sie alle anderen Optionen zur Optimierung Ihrer Datenbank ausschöpfen. Einige Optimierungen, die Sie in Betracht ziehen könnten, umfassen:
-
Setting up a remote database. Wenn Sie mit einer monolithischen Anwendung arbeiten, bei der sich alle Komponenten auf demselben Server befinden, können Sie die Leistung Ihrer Datenbank verbessern, indem Sie sie auf einen eigenen Computer übertragen. Dies erhöht die Komplexität weniger als das Sharding, da die Tabellen der Datenbank intakt bleiben. Es ermöglicht Ihnen jedoch weiterhin, Ihre Datenbank vom Rest Ihrer Infrastruktur vertikal zu skalieren.
-
Implementing caching. Wenn die Leseleistung Ihrer Anwendung zu Problemen führt, kann das Caching helfen, diese zu verbessern. Beim Zwischenspeichern werden bereits angeforderte Daten zwischengespeichert, sodass Sie später viel schneller darauf zugreifen können.
-
Creating one or more read replicas. Eine weitere Strategie, die zur Verbesserung der Leseleistung beitragen kann, besteht darin, die Daten von einem Datenbankserver (primary server) auf einen oder mehreresecondary servers zu kopieren. Anschließend wird jeder neue Schreibvorgang auf den primären Server übertragen, bevor er auf die sekundären Server kopiert wird, während die Lesevorgänge ausschließlich auf den sekundären Servern ausgeführt werden. Durch das Verteilen von Lese- und Schreibvorgängen auf diese Weise wird verhindert, dass ein Computer zu viel Last aufnimmt, wodurch Verlangsamungen und Abstürze vermieden werden. Beachten Sie, dass das Erstellen von Lesereplikaten mehr Rechenressourcen erfordert und daher mehr Geld kostet, was für einige eine erhebliche Einschränkung darstellen kann.
-
Upgrading to a larger server. In den meisten Fällen ist das Skalieren des Datenbankservers auf einen Computer mit mehr Ressourcen weniger aufwändig als das Sharding. Wie beim Erstellen von Lesereplikaten wird ein aktualisierter Server mit mehr Ressourcen wahrscheinlich mehr Geld kosten. Dementsprechend sollten Sie die Größenänderung nur dann durchführen, wenn dies tatsächlich Ihre beste Option ist.
Bedenken Sie, dass keine dieser Strategien ausreicht, wenn Ihre Anwendung oder Website über einen bestimmten Punkt hinaus wächst, um die Leistung selbst zu verbessern. In solchen Fällen ist Sharding in der Tat die beste Option für Sie.
Fazit
Sharding kann eine großartige Lösung für diejenigen sein, die ihre Datenbank horizontal skalieren möchten. Dies erhöht jedoch auch die Komplexität und schafft mehr potenzielle Fehlerquellen für Ihre Anwendung. Für einige mag Sharding erforderlich sein, aber die Zeit und die Ressourcen, die zum Erstellen und Verwalten einer Sharding-Architektur benötigt werden, können die Vorteile für andere aufwiegen.
Wenn Sie diesen konzeptionellen Artikel lesen, sollten Sie die Vor- und Nachteile des Splitterns besser verstehen. In Zukunft können Sie diese Erkenntnis nutzen, um eine fundiertere Entscheidung darüber zu treffen, ob eine Sharded-Datenbankarchitektur für Ihre Anwendung geeignet ist oder nicht.