Einführung
Ein hochverfügbares Webanwendungssetup bietet Entwicklern, die einzelne Fehlerquellen beseitigen und Ausfallzeiten minimieren möchten, Vorteile. Innerhalb dieses allgemeinen Rahmens gibt es jedoch eine Reihe von möglichen Variationen. Entwickler treffen Entscheidungen basierend auf den spezifischen Anforderungen ihrer Anwendung und ihren Leistungszielen.
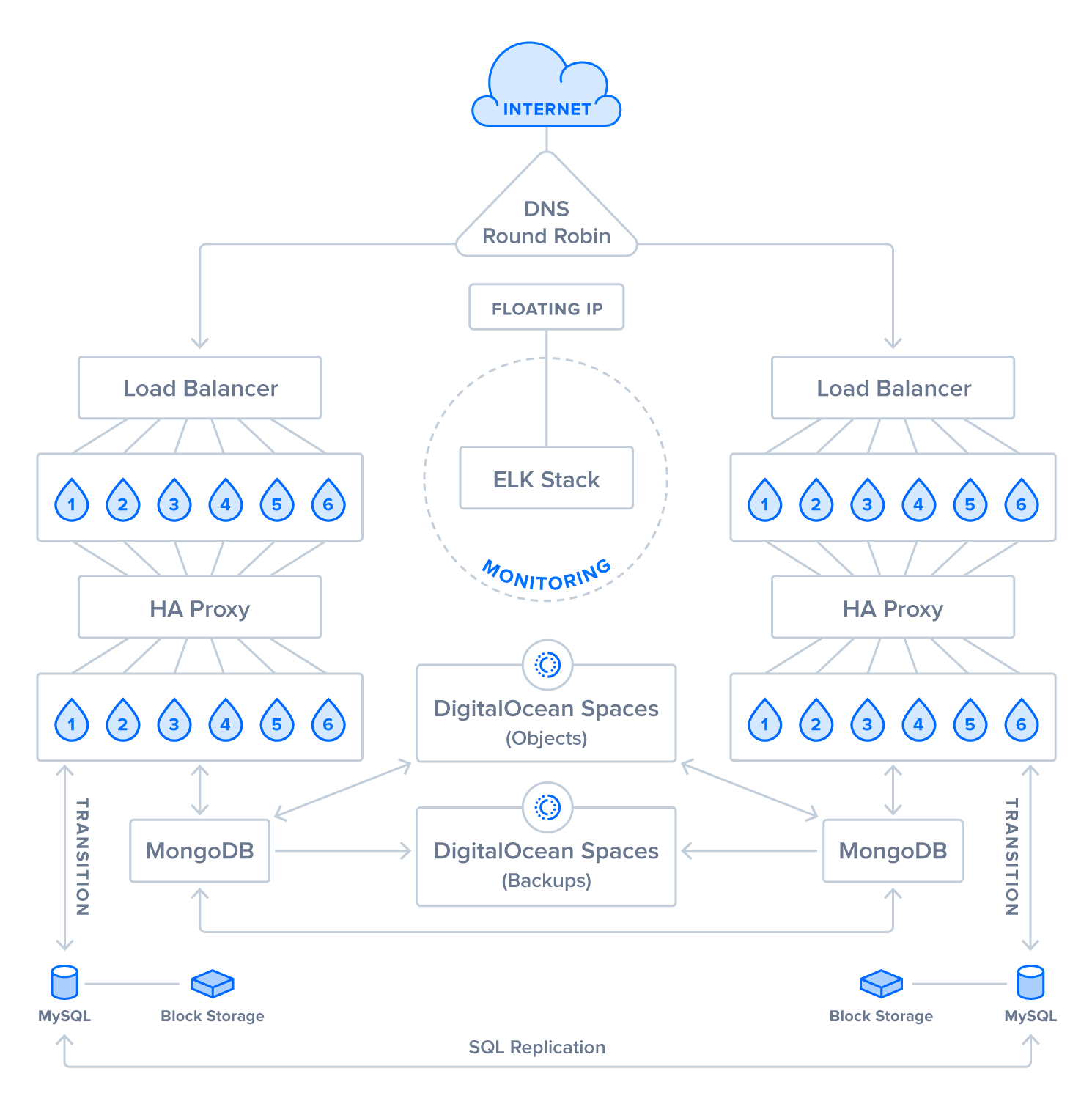
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/full-diagram.png [Vollständiges Diagramm der hochverfügbaren Webanwendung]
{kind=link}
Diese hochverfügbare Anwendungskonfiguration wurde als hypothetische Lösung entwickelt, um möglicherweise Folgendes anzubieten:
-
Eine Verarbeitungslösung für Bilder, Dokumente und Videos mit Schwerpunkt auf Speicherung, Abruf und Verkettung.
-
Eine Scorekeeping-, Leaderboard- oder Einkaufslösung, die skaliert, geändert oder in eine E-Commerce-Lösung integriert werden kann.
-
Eine Blogging-Lösung, die auch in eine E-Commerce-Lösung integriert werden kann.
In diesem Artikel gehen wir auf die Besonderheiten dieses Setups ein und erläutern dessen Komponenten auf einer allgemeineren Ebene. Am Ende jedes Abschnitts finden Sie Links zu weiteren Ressourcen zum Thema, die Sie bei der Betrachtung von Methoden und bewährten Methoden unterstützen.
Schritt 1: Erstellen von Front-End-Servern mit privatem Netzwerk
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-1.png [Diagramm von Schritt 1: Front-End-Server]
{kind=link}
Ein typisches mehrschichtiges Setup trennt die Präsentationsschicht von unserer Anwendungslogik. Die Aufteilung der Anwendungsfunktionen in Ebenen erleichtert die Fehlersuche und Skalierung auf lange Sicht.
Bei der Auswahl der Server und Ressourcen können folgende Faktoren berücksichtigt werden:
-
Welche Art von Arbeit werden wir mit Medien- und Image-Assets machen?
-
Wie sehen unsere Rechenanforderungen aus?
-
Mit welcher Art und mit welchem Verkehrsaufkommen rechnen wir?
-
Was haben wir vor, um es zu überwachen?
Mithilfe unserer Überwachungstools können wir unsere Anwendung skalieren und Ressourcen auf dieser und anderen Ebenen aufbauen. Ein weiterer Schritt, den wir zur Kosteneinsparung und für Sicherheitsmaßnahmen unternehmen können, besteht darin, die Ressourcen unserer Anwendung, einschließlich unserer Front-End-Server, einem gemeinsam genutzten privaten Netzwerk zuzuweisen. Daten können dann zwischen Servern übertragen werden, ohne dass zusätzliche Bandbreitenkosten anfallen oder ein einzelnes Datencenter verlassen wird.
Schritt 2: Erstellen von Load Balancern für Front-End-Server
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-2.png [Diagramm von Schritt 2: Load Balancers]
{kind=link}
Um sicherzustellen, dass die Ressourcen unserer Anwendung hoch verfügbar und leistungsfähig bleiben, können wir Load Balancer erstellen, um unsere Front-End-Workload zu verwalten. Diese Load Balancer leiten eingehenden Datenverkehr mithilfe regelmäßiger Integritätsprüfungen und Failover-Mechanismen um, um Serverausfälle oder -störungen zu verwalten. Sie gleichen auch den Datenverkehr im Allgemeinen aus, um sicherzustellen, dass einzelne Server nicht überlastet werden.
Um ihre Konfiguration zu optimieren, können wir die folgenden Faktoren berücksichtigen:
-
Speichern wir Statusinformationen zu Anfragen und Benutzern?
-
Müssen wir Anforderungen basierend auf der CPU-Auslastung umleiten?
Diese Faktoren ermöglichen es uns, den optimalen Algorithmus für unsere Konfiguration auszuwählen. Es gibt eine zusätzliche Sicherheitskomponente für die Arbeit der Load Balancer: Sie können so konfiguriert werden, dass sie bestimmte Ports überwachen und den Datenverkehr zwischen den Ports umleiten. Sie können sie auch zum Entschlüsseln von Nachrichten für unsere Back-End-Server verwenden.
Schritt 3: Erstellen von Back-End-Servern mit privatem Netzwerk
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-3.png [Diagramm von Schritt 3: Back-End-Server]
{kind=link}
Zum Erstellen des Backends unserer Anwendung sind weitere Ressourcenberechnungen erforderlich. Die Art der Arbeit unserer Anwendung bestimmt wiederum die Größe und die Ressourcen unserer Server. Zu berücksichtigende Faktoren sind die Art und das Volumen der Verarbeitungsarbeit, die unsere Server auf dieser Ebene ausführen werden. Hier kommt die Unterscheidung zwischen Datentypen und Verarbeitungsaufgaben zum Tragen. Wenn wir zum Beispiel mit Image-Assets und Verbraucherdaten arbeiten, können wir die jeweils geltenden Anforderungen an Auslastung und Latenz berücksichtigen.
Die Überwachung wird auch auf dieser Ebene wichtig sein, um Themen wie:
-
Welche Art von Verarbeitung machen wir mit Bild- und Medieninhalten?
-
Ziehen wir Informationen aus diesen Assets oder rufen wir sie einfach ab oder kombinieren sie neu?
-
Welches Volumen und welche Art von Verbrauchertransaktionen haben wir?
Wir können die Ressourcen auf dieser Ebene in unser gemeinsames privates Netzwerk stellen, um mögliche Bandbreitengebühren zu berücksichtigen.
-
https://www.digitalocean.com/community/tutorials/how-to-set-up-a-remote-database-to-optimize-site-performance-with-mysql-on-ubuntu-16-04[How To Richten Sie eine entfernte Datenbank ein, um die Site-Leistung mit MySQL unter Ubuntu 16.04 zu optimieren.
-
https://www.digitalocean.com/community/tutorials/anleitungen zum erstellen einer django-app und zum verbinden einer django-app mit einer datenbank ].
Schritt 4: Installieren von HAProxy
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-4.png [Diagramm von Schritt 4: HAProxy]
{kind=link}
Ähnlich wie unsere Load Balancer externe Anforderungen verarbeiten, verwaltet HAProxy den Kommunikationsfluss zwischen Front-End- und Anwendungsebenen. In seiner Funktion als Load Balancer kann HAProxy so konfiguriert werden, dass Datenverkehr von bestimmten Ports abgehört und umgeleitet wird. Dies kann den internen Vorgängen unserer Anwendung eine weitere Sicherheitsebene hinzufügen. Wenn wir skalieren müssen, können wir HAProxy so konfigurieren, dass Knoten automatisch hinzugefügt und entfernt werden.
-
https://www.digitalocean.com/community/tutorials/how-to-create-a-high-availability-haproxy-setup-with-corosync-pacemaker-and-floating-ips-on-ubuntu-14-04 [ So erstellen Sie ein Hochverfügbarkeits-HAProxy-Setup mit Corosync, Pacemaker und Floating IPs unter Ubuntu 14.04].
Schritt 5: Erstellen von SQL-Datenbanken
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-5.png [Diagramm von Schritt 5: SQL-Datenbanken]
{kind=link}
Für ein bestimmtes Segment unserer Anwendungsdaten verwenden wir eine SQL-Datenbank. Dies gilt für Daten, die aktuell, genau und konsistent sein müssen. Dinge wie Verkaufstransaktionen, Anmelde- / Abmeldeinformationen und Kennwortänderungen, die einheitlich strukturiert sind und sicher sein müssen, sprechen für die Verwendung einer SQL-Datenbank.
Auch hier möchten wir unsere Metriken berücksichtigen: Wie viele Transaktions- oder Sicherheitsanforderungen verarbeiten wir? Wenn unsere Last hoch ist, können Sie Tools wie ProxySQL verwenden, um eingehende Anforderungen auszugleichen. Wenn wir die Replikation zwischen unseren SQL-Datenbanken einrichten, können wir einen zusätzlichen Schritt unternehmen, um die Leistung zu verbessern und eine hohe Verfügbarkeit sicherzustellen. Dies wird sich auch als nützlich erweisen, wenn wir unsere Datenverarbeitung skalieren müssen.
-
https://www.digitalocean.com/community/tutorials/how-to-configure-mysql-group-replication-on-ubuntu-16-04#joining-a-group-automatically-when-mysql-starts[How To Konfigurieren Sie die MySQL-Gruppenreplikation unter Ubuntu 16.04.
Schritt 6: Erstellen von NoSQL-Datenbanken
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-6.png [Diagramm von Schritt 6: NoSQL-Datenbanken]
{kind=link}
Bei Daten, die weniger einheitlich oder schematisch sind, können wir eine NoSQL-Datenbank verwenden. Beispielsweise bietet eine NoSQL-Datenbank für Bilder, Videos oder Blog-Posts die Möglichkeit, Elementmetadaten nicht schematisch zu speichern. Wenn Sie diese Art von Lösung verwenden, sind unsere Daten hoch verfügbar und ihre Konsistenz ist möglicherweise gegeben. Wenn wir über die Leistung nachdenken, möchten wir die Art und das Volumen der Anforderungen berücksichtigen, die wir an diese Datenbanken stellen.
Zu den Faktoren, die die Leistung je nach Anforderungslast und -typ optimieren können, gehören: Verwenden einer Lastausgleichslösung zum Verwalten des Datenverkehrs zwischen Datenbanken, Verteilen von Daten auf Datenbanken und Speicherlösungen sowie Hinzufügen oder Löschen von Datenbanken (anstatt sie zu replizieren).
-
https://www.digitalocean.com/community/tutorials/installations- und konfigurationsanleitung-orientdb-on-ubuntu-16-04[Installation und Konfiguration von OrientDB unter Ubuntu 16.04].
Schritt 7: Blockspeicher hinzufügen
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-7.png [Diagramm von Schritt 7: Blockspeicher]
{kind=link}
Unser Setup trennt die Datenbankspeicherfunktion von den anderen Vorgängen unserer Anwendung. Ziel ist es, die Sicherheit unserer Daten und die Gesamtleistung unserer Anwendung zu verbessern. Als weiterer Teil dieses Isolationsprozesses können wir eine Sicherungslösung für unsere SQL-Datenbankdateien erstellen. Blockspeicherlösungen wie die Blockspeicher-Volumes von DigitalOcean können diese Aufgabe aufgrund ihrer geringen E / A-Latenz und der schematischen Dateisystemstruktur gut erfüllen. Sie bieten auch Optionen für die Skalierung, da sie leicht zerstört, in der Größe geändert oder multipliziert werden können.
Schritt 8: Erstellen eines elastischen / ELK-Stapels
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-8.png [Diagramm von Schritt 8: ELK Stack]
{kind=link}
Das Überwachen der Leistung unserer Anwendung beeinflusst die Entscheidungen, die wir treffen, wenn wir unser Setup skalieren und verfeinern. Zu diesem Zweck können wir eine zentralisierte Protokollierungslösung wie einen Elastic / ELK-Stack verwenden. Unser Stack enthält Komponenten, die Protokolle erfassen und visualisieren: Logstash, das Protokolle verarbeitet; Elasticsearch, die sie speichert; und Kibana, mit dem sie durchsucht und visuell organisiert werden können. Wenn wir diesen Stack hinter einer Floating-IP platzieren, können wir mit einer statischen IP remote darauf zugreifen. Wenn wir unseren Stack in unser gemeinsames privates Netzwerk aufnehmen, haben wir darüber hinaus einen weiteren Sicherheitsvorteil: Unsere Berichtspflichtigen müssen keine Informationen über das Internet auf den Stack übertragen.
-
https://www.digitalocean.com/community/tutorials/an-einführung-zum-metrischen-Überwachen-und-Warnen von EinstellungenEine Einführung in Metriken, Überwachen und Warnen].
-
Installieren von Elasticsearch, Logstash und Kibana ( ELK Stack) unter Ubuntu 16.04.
Schritt 9: Erstellen von Objektspeichern
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-9.png [Diagramm von Schritt 9: Objektspeicherung]
{kind=link}
Beim Speichern der statischen Assets unserer Anwendung möchten wir deren Verfügbarkeit sicherstellen und gleichzeitig eine hohe Leistung gewährleisten. Objektspeicherlösungen wie DigitalOcean Spaces können diesen Bedarf decken. Insbesondere wenn wir uns entscheiden, große Objekte in unseren Datenbanken zu speichern, kann dies zu Leistungsproblemen beim Zufluss von Daten führen, wodurch unsere Sicherungen sehr umfangreich werden. In diesem Szenario könnten wir unsere Daten in den Objektspeicher verschieben. Durch das Speichern einer URL in unserer Datenbank können wir auf unsere Ressourcen aus der Datenbank verweisen, ohne die Speicherkapazität zu beeinträchtigen. Dies ist eine optimale Lösung für Daten, von denen wir erwarten, dass sie statisch bleiben, und bietet zusätzliche Optionen für die Skalierung.
Schritt 10: Konfigurieren von DNS-Einträgen
image: https://assets.digitalocean.com/articles/solutions/highly-available-web-app/step-10.png [Diagramm von Schritt 10: DNS-Einträge]
{kind=link}
Sobald unsere Einrichtung für hohe Verfügbarkeit eingerichtet ist, können wir den Domänennamen unserer Anwendung mithilfe von DNS auf unsere Lastenausgleichsmodule verweisen. Mit einem Round-Robin-Algorithmus können wir die Abfrageantworten zwischen den verteilten Ressourcen unserer Anwendung ausgleichen. Dadurch wird die Verfügbarkeit dieser Ressourcen maximiert und gleichzeitig die Arbeitslast auf Ressourcencluster verteilt. Darüber hinaus können wir geografisches Routing verwenden, um Anforderungen an benachbarte Ressourcen anzupassen.
-
Eine Einführung in die DNS-Terminologie, -Komponenten und -Konzepte.
-
https://www.digitalocean.com/community/tutorials/anleitungen-erstellen-von-herzschlag-und-schwimmenden-ipps-auf-ubuntu-16-04So erstellen Sie eine Hochverfügbarkeits-Setup mit Heartbeat- und Floating-IPs unter Ubuntu 16.04].
Schritt 11: Planen der Wiederherstellungsstrategie
Unsere Wiederherstellungsstrategie umfasst Tools und Funktionen zum Sichern und Wiederherstellen unserer Daten bei administrativen oder anderen Fehlern. Für jedes unserer Droplets können wir DigitalOcean-Snapshots nutzen und automatisieren, um Bilder von Droplets auf DigitalOcean-Servern zu kopieren und zu speichern. Darüber hinaus können wir dedizierte Tools und Dienste wie Percona, Restic oder Bacula sowie Speichergeräte wie DigitalOcean Backups und Spaces zum Kopieren unserer Daten verwenden. Bei der Evaluierung dieser Tools und der Erstellung unserer Strategie werden wir uns Gedanken über die Daten auf jeder Ebene unserer Anwendung machen und darüber, wie oft sie gesichert werden müssen, damit wir einen vernünftigen Zeitpunkt haben, an dem die Funktionalität unserer Anwendung wiederhergestellt werden kann.
Fazit
In diesem Artikel haben wir ein mögliches Setup für eine hochverfügbare Webanwendung erörtert, das von Infrastrukturkomponenten wie Droplets, Load Balancers, Spaces und Block Storage abhängt, um eine hohe Betriebsleistung zu erzielen. Dieses Setup könnte eine Verarbeitungslösung für Bilder und andere Medien unterstützen, wobei der Schwerpunkt auf der Speicherung und dem Abrufen sowie auf den Funktionen für Kauf, Scorekeeping oder Blogging liegt, die in E-Commerce-Lösungen integriert werden könnten.
Letztendlich gibt es viele Möglichkeiten für Entwickler, um bestimmte Anforderungen und Anwendungsfälle zu erfüllen und gleichzeitig eine hohe Verfügbarkeit aufrechtzuerhalten, und jede Anwendungskonfiguration wird diese Unterschiede in der Spezifität ihrer Architektur widerspiegeln.