Python-Histogramm-Plotten: NumPy, Matplotlib, Pandas & Seaborn
In diesem Tutorial können Sie Python-Histogramm-Diagramme in Produktionsqualität und Präsentationsbereitschaft mit einer Reihe von Auswahlmöglichkeiten und Funktionen erstellen.
Wenn Sie eine Einführung in fortgeschrittene Kenntnisse in Python und Statistik haben, können Sie diesen Artikel als zentrale Anlaufstelle zum Erstellen und Plotten von Histogrammen in Python verwenden, indem Sie Bibliotheken aus dem wissenschaftlichen Stack verwenden, darunter NumPy, Matplotlib, Pandas und Seaborn.
Ein Histogramm ist ein großartiges Werkzeug, um schnell einen Prozentsatz (t0) zu bestimmen, der von fast jedem Publikum intuitiv verstanden wird. Python bietet eine Handvoll verschiedener Optionen zum Erstellen und Zeichnen von Histogrammen. Die meisten Menschen kennen ein Histogramm anhand seiner grafischen Darstellung, die einem Balkendiagramm ähnelt:
Dieser Artikel führt Sie durch die Erstellung von Plots wie dem oben genannten sowie komplexeren. Folgendes werden Sie behandeln:
-
Erstellen von Histogrammen in reinem Python ohne Verwendung von Bibliotheken von Drittanbietern
-
Erstellen von Histogrammen mit NumPy, um die zugrunde liegenden Daten zusammenzufassen
-
Zeichnen des resultierenden Histogramms mit Matplotlib, Pandas und Seaborn
Free Bonus: Zeitmangel? Click here to get access to a free two-page Python histograms cheat sheet, das die in diesem Tutorial erläuterten Techniken zusammenfasst.
Histogramme in Pure Python
Wenn Sie sich darauf vorbereiten, ein Histogramm zu zeichnen, ist es am einfachsten, nicht in Bins zu denken, sondern anzugeben, wie oft jeder Wert angezeigt wird (Häufigkeitstabelle). Ein Pythondictionary ist für diese Aufgabe gut geeignet:
>>>
>>> # Need not be sorted, necessarily
>>> a = (0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> def count_elements(seq) -> dict:
... """Tally elements from `seq`."""
... hist = {}
... for i in seq:
... hist[i] = hist.get(i, 0) + 1
... return hist
>>> counted = count_elements(a)
>>> counted
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}count_elements() gibt ein Wörterbuch mit eindeutigen Elementen aus der Sequenz als Schlüssel und deren Häufigkeit (Anzahl) als Werte zurück. Innerhalb der Schleife überseq sagthist[i] = hist.get(i, 0) + 1: "Erhöhen Sie für jedes Element der Sequenz den entsprechenden Wert inhist um 1."
Genau dies wird von der Klassecollections.Counteraus der Python-Standardbibliothek ausgeführt, diehttps://github.com/python/cpython/blob/7f1bcda9bc3c04100cb047373732db0eba00e581/Lib/collections/init.py # L466 [Unterklassen] eines Python-Wörterbuchs und dessen.update()überschreibt. s Methode:
>>>
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})Sie können bestätigen, dass Ihre handgefertigte Funktion praktisch dasselbe wiecollections.Counter tut, indem Sie die Gleichheit zwischen beiden testen:
>>>
>>> recounted.items() == counted.items()
TrueTechnical Detail: Die Zuordnung voncount_elements() oben erfolgt standardmäßig zu einem höher optimiertenC function, falls verfügbar. Innerhalb der Python-Funktioncount_elements() besteht eine Mikrooptimierung darin,get = hist.get vor der for-Schleife zu deklarieren. Dies würde eine Methode an eine Variable binden, um schnellere Aufrufe innerhalb der Schleife zu ermöglichen.
Es kann hilfreich sein, vereinfachte Funktionen von Grund auf neu zu erstellen, um komplexere Funktionen zu verstehen. Lassen Sie uns das Rad mit einem ASCII-Histogramm, das dieoutput formattingvon Python nutzt, ein wenig neu erfinden:
def ascii_histogram(seq) -> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
for k in sorted(counted):
print('{0:5d} {1}'.format(k, '+' * counted[k]))Diese Funktion erstellt ein sortiertes Frequenzdiagramm, in dem die Anzahl als Summe von Pluszeichen (+) dargestellt wird. Wenn Siesorted() in einem Wörterbuch aufrufen, wird eine sortierte Liste seiner Schlüssel zurückgegeben, und Sie greifen mitcounted[k] auf den entsprechenden Wert für jeden Schlüssel zu. Um dies in Aktion zu sehen, können Sie mit demrandom-Modul von Python einen etwas größeren Datensatz erstellen:
>>>
>>> # No NumPy ... yet
>>> import random
>>> random.seed(1)
>>> vals = [1, 3, 4, 6, 8, 9, 10]
>>> # Each number in `vals` will occur between 5 and 15 times.
>>> freq = (random.randint(5, 15) for _ in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1 +++++++
3 ++++++++++++++
4 ++++++
6 +++++++++
8 ++++++
9 ++++++++++++
10 ++++++++++++Hier simulieren Sie das Zupfen vonvals mit Frequenzen, die durchfreq (agenerator expression) gegeben sind. Die resultierenden Probendaten wiederholen jeden Wert vonvals eine bestimmte Anzahl von Malen zwischen 5 und 15.
Note:random.seed() wird verwendet, um den zugrunde liegenden Pseudozufallszahlengenerator (PRNG), der vonrandom verwendet wird, zu setzen oder zu initialisieren. Es mag wie ein Oxymoron klingen, aber dies ist eine Möglichkeit, zufällige Daten reproduzierbar und deterministisch zu machen. Das heißt, wenn Sie den Code hier so kopieren, wie er ist, sollten Sie genau das gleiche Histogramm erhalten, da der erste Aufruf vonrandom.randint() nach dem Seeding des Generators identische "zufällige" Daten unter Verwendung vonMersenne Twister erzeugt.
Aufbauend auf der Basis: Histogrammberechnungen in NumPy
Bisher haben Sie mit sogenannten „Häufigkeitstabellen“ gearbeitet. Mathematisch gesehen ist ein Histogramm eine Abbildung von Bins (Intervallen) auf Frequenzen. Technischer kann es verwendet werden, um die Wahrscheinlichkeitsdichtefunktion (PDF) der zugrunde liegenden Variablen zu approximieren.
Ausgehend von der obigen „Häufigkeitstabelle“ „gruppiert“ ein echtes Histogramm zuerst den Wertebereich und zählt dann die Anzahl der Werte, die in jeden Bin fallen. Dies ist die Funktion vonNumPy’shistogram() und die Grundlage für andere Funktionen, die Sie später hier in Python-Bibliotheken wie Matplotlib und Pandas sehen werden.
Betrachten Sie eine Stichprobe von Schwimmern, die ausLaplace distribution gezogen wurden. Diese Verteilung hat dickere Schwänze als eine Normalverteilung und zwei beschreibende Parameter (Ort und Maßstab):
>>>
>>> import numpy as np
>>> # `numpy.random` uses its own PRNG.
>>> np.random.seed(444)
>>> np.set_printoptions(precision=3)
>>> d = np.random.laplace(loc=15, scale=3, size=500)
>>> d[:5]
array([18.406, 18.087, 16.004, 16.221, 7.358])In diesem Fall arbeiten Sie mit einer kontinuierlichen Verteilung, und es wäre nicht sehr hilfreich, jeden Gleitkomma unabhängig bis zur x-ten Dezimalstelle zu zählen. Stattdessen können Sie die Daten ablegen oder "Bucket" und die Beobachtungen zählen, die in jeden Bin fallen. Das Histogramm ist die resultierende Anzahl von Werten in jedem Bin:
>>>
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])Dieses Ergebnis ist möglicherweise nicht sofort intuitiv. np.histogram() verwendet standardmäßig 10 gleich große Bins und gibt ein Tupel der Frequenzzählungen und der entsprechenden Bin-Kanten zurück. Sie sind Kanten in dem Sinne, dass es eine Bin-Kante mehr gibt als Mitglieder des Histogramms:
>>>
>>> hist.size, bin_edges.size
(10, 11)Technical Detail: Alle bis auf den letzten (ganz rechts) Behälter sind halb geöffnet. Das heißt, alle Behälter bis auf den letzten sind [inklusive, exklusiv] und der letzte Behälter ist [inklusive, inklusive].
Eine sehr komprimierte Aufschlüsselung der Konstruktion der Behälterby NumPy sieht folgendermaßen aus:
>>>
>>> # The leftmost and rightmost bin edges
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10 # NumPy's default
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23. ])Der obige Fall ist sehr sinnvoll: 10 gleich beabstandete Behälter über einen Spitze-Spitze-Bereich von 23 bedeuten Intervalle mit einer Breite von 2,3.
Von dort delegiert die Funktion entweder annp.bincount() odernp.searchsorted(). bincount() selbst kann verwendet werden, um die „Häufigkeitstabelle“, mit der Sie hier begonnen haben, effektiv zu erstellen, mit der Unterscheidung, dass Werte mit null Vorkommen enthalten sind:
>>>
>>> bcounts = np.bincount(a)
>>> hist, _ = np.histogram(a, range=(0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}Note:hist verwendet hier tatsächlich Bins mit einer Breite von 1,0 anstelle von "diskreten" Zählungen. Daher funktioniert dies nur zum Zählen von ganzen Zahlen, nicht von Gleitkommazahlen wie[3.9, 4.1, 4.15].
Visualisierung von Histogrammen mit Matplotlib und Pandas
Nachdem Sie nun gesehen haben, wie Sie ein Histogramm in Python von Grund auf erstellen, wollen wir sehen, wie andere Python-Pakete diese Aufgabe für Sie erledigen können. Matplotlib bietet die Funktionalität zur sofortigen Visualisierung von Python-Histogrammen mit einem vielseitigen Wrapper umhistogram() von NumPy:
import matplotlib.pyplot as plt
# An "interface" to matplotlib.axes.Axes.hist() method
n, bins, patches = plt.hist(x=d, bins='auto', color='#0504aa',
alpha=0.7, rwidth=0.85)
plt.grid(axis='y', alpha=0.75)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('My Very Own Histogram')
plt.text(23, 45, r'$\mu=15, b=3$')
maxfreq = n.max()
# Set a clean upper y-axis limit.
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10 if maxfreq % 10 else maxfreq + 10)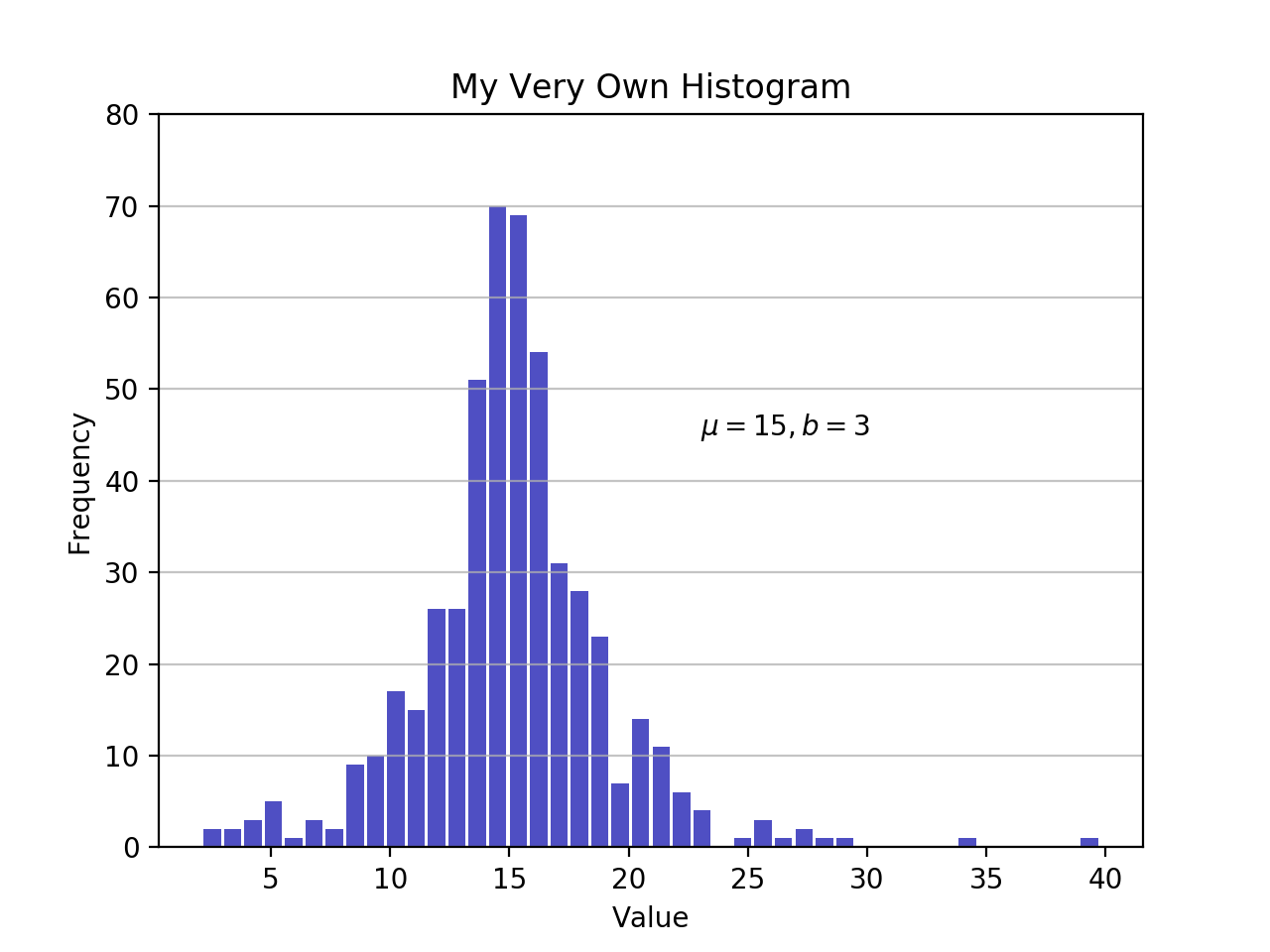
Wie zuvor definiert, verwendet ein Diagramm eines Histogramms seine Bin-Kanten auf der x-Achse und die entsprechenden Frequenzen auf der y-Achse. In der obigen Tabelle wählt das Übergeben vonbins='auto' zwischen zwei Algorithmen, um die „ideale“ Anzahl von Bins zu schätzen. Auf hoher Ebene besteht das Ziel des Algorithmus darin, eine Behälterbreite auszuwählen, die die originalgetreueste Darstellung der Daten erzeugt. Weitere Informationen zu diesem Thema, das ziemlich technisch werden kann, finden Sie inChoosing Histogram Bins in den Astropy-Dokumenten.
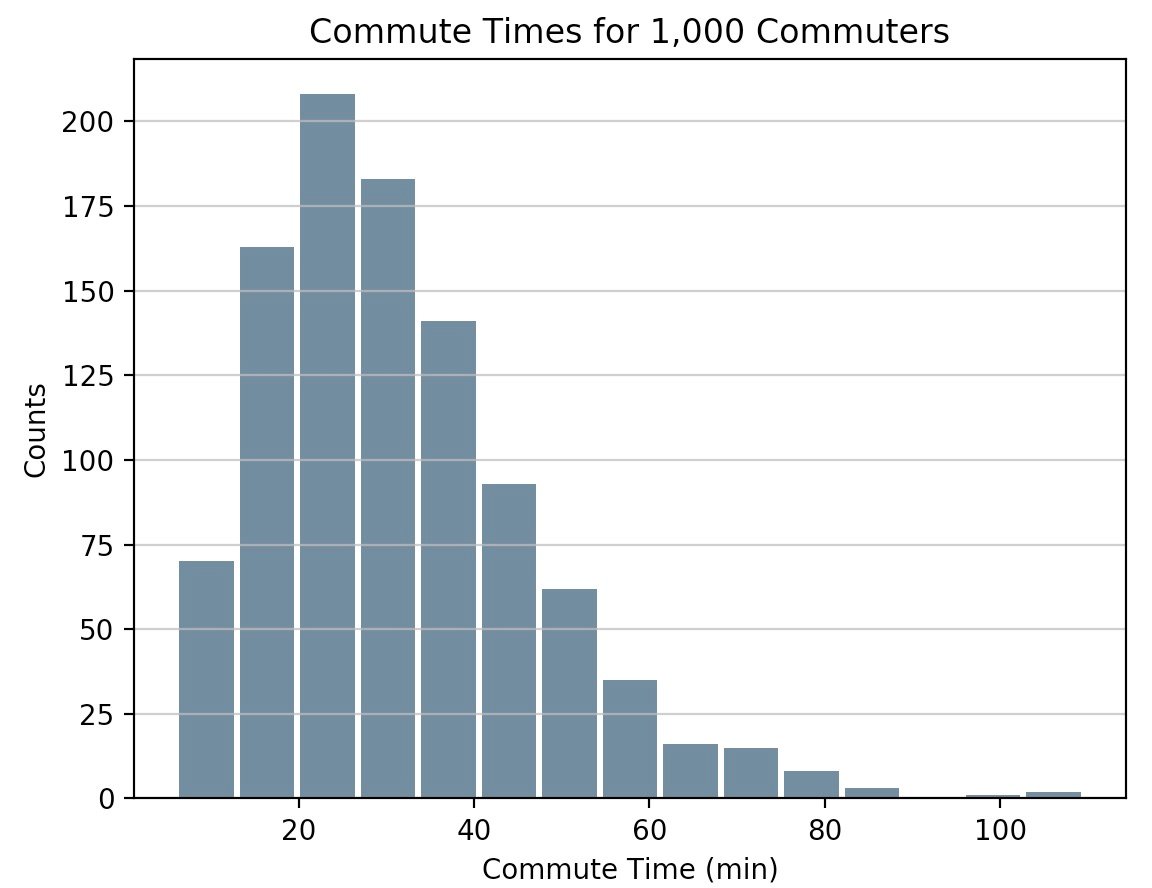
Pandas 'Series.histogram()uses matplotlib.pyplot.hist() bleiben in Pythons wissenschaftlichem Stack, um ein Matplotlib-Histogramm der Eingabeserie zu zeichnen:
import pandas as pd
# Generate data on commute times.
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid=True, bins=20, rwidth=0.9,
color='#607c8e')
plt.title('Commute Times for 1,000 Commuters')
plt.xlabel('Counts')
plt.ylabel('Commute Time')
plt.grid(axis='y', alpha=0.75)
pandas.DataFrame.histogram() ist ähnlich, erstellt jedoch ein Histogramm für jede Datenspalte im DataFrame.
Zeichnen einer Kernel-Dichteschätzung (KDE)
In diesem Tutorial haben Sie statistisch gesehen mit Beispielen gearbeitet. Unabhängig davon, ob die Daten diskret oder kontinuierlich sind, wird angenommen, dass sie aus einer Population stammen, deren wahre, genaue Verteilung durch nur wenige Parameter beschrieben wird.
Eine Kernel-Dichteschätzung (KDE) ist eine Möglichkeit, die Wahrscheinlichkeitsdichtefunktion (PDF) der Zufallsvariablen zu schätzen, die unserer Stichprobe „zugrunde liegt“. KDE ist ein Mittel zur Datenglättung.
Wenn Sie sich an die Pandas-Bibliothek halten, können Sie Dichtediagramme mitplot.kde() erstellen und überlagern, die sowohl fürSeries- als auch fürDataFrame-Objekte verfügbar sind. Lassen Sie uns zunächst zwei unterschiedliche Datenbeispiele zum Vergleich generieren:
>>>
>>> # Sample from two different normal distributions
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=(1000, 2)),
... columns=['a', 'b'])
>>> dist.agg(['min', 'max', 'mean', 'std']).round(decimals=2)
a b
min -1.57 12.46
max 25.32 26.44
mean 10.12 19.94
std 3.94 1.94So zeichnen Sie nun jedes Histogramm auf denselben Matplotlib-Achsen:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend=False, title='Histogram: A vs. B')
dist.plot.hist(density=True, ax=ax)
ax.set_ylabel('Probability')
ax.grid(axis='y')
ax.set_facecolor('#d8dcd6')
Diese Methoden nutzen SciPysgaussian_kde(), was zu einem glatteren PDF führt.
Wenn Sie sich diese Funktion genauer ansehen, können Sie sehen, wie gut sie sich dem „echten“ PDF für eine relativ kleine Stichprobe von 1000 Datenpunkten annähert. Im Folgenden können Sie zunächst die „analytische“ Verteilung mitscipy.stats.norm() erstellen. Dies ist eine Klasseninstanz, die die statistische Standardnormalverteilung, ihre Momente und beschreibenden Funktionen kapselt. Das PDF ist in dem Sinne „genau“, dass es genau alsnorm.pdf(x) = exp(-x**2/2) / sqrt(2*pi) definiert ist.
Von dort aus können Sie eine Zufallsstichprobe von 1000 Datenpunkten aus dieser Verteilung ziehen und dann versuchen, mitscipy.stats.gaussian_kde() zu einer Schätzung des PDF zurückzukehren:
from scipy import stats
# An object representing the "frozen" analytical distribution
# Defaults to the standard normal distribution, N~(0, 1)
dist = stats.norm()
# Draw random samples from the population you built above.
# This is just a sample, so the mean and std. deviation should
# be close to (1, 0).
samp = dist.rvs(size=1000)
# `ppf()`: percent point function (inverse of cdf — percentiles).
x = np.linspace(start=stats.norm.ppf(0.01),
stop=stats.norm.ppf(0.99), num=250)
gkde = stats.gaussian_kde(dataset=samp)
# `gkde.evaluate()` estimates the PDF itself.
fig, ax = plt.subplots()
ax.plot(x, dist.pdf(x), linestyle='solid', c='red', lw=3,
alpha=0.8, label='Analytical (True) PDF')
ax.plot(x, gkde.evaluate(x), linestyle='dashed', c='black', lw=2,
label='PDF Estimated via KDE')
ax.legend(loc='best', frameon=False)
ax.set_title('Analytical vs. Estimated PDF')
ax.set_ylabel('Probability')
ax.text(-2., 0.35, r'$f(x) = \frac{\exp(-x^2/2)}{\sqrt{2*\pi}}$',
fontsize=12)
Dies ist ein größerer Teil des Codes. Nehmen wir uns also eine Sekunde Zeit, um einige wichtige Zeilen zu berühren:
-
Mit
statssubpackage von SciPy können Sie Python-Objekte erstellen, die analytische Verteilungen darstellen, aus denen Sie Stichproben erstellen können, um tatsächliche Daten zu erstellen.dist = stats.norm()stellt also eine normale kontinuierliche Zufallsvariable dar, und Sie generieren daraus Zufallszahlen mitdist.rvs(). -
Um sowohl das analytische PDF als auch das Gaußsche KDE auszuwerten, benötigen Sie ein Array
xvon Quantilen (Standardabweichungen über / unter dem Mittelwert für eine Normalverteilung).stats.gaussian_kde()stellt eine geschätzte PDF-Datei dar, die Sie in einem Array auswerten müssen, um in diesem Fall etwas visuell Sinnvolles zu erzeugen. -
Die letzte Zeile enthält einigeLaTex, die sich gut in Matplotlib integrieren lassen.
Eine ausgefallene Alternative zu Seaborn
Lassen Sie uns noch ein Python-Paket in den Mix bringen. Seaborn hat einedisplot()-Funktion, die das Histogramm und KDE für eine univariate Verteilung in einem Schritt darstellt. Verwendung des NumPy-Arraysd von ealier:
import seaborn as sns
sns.set_style('darkgrid')
sns.distplot(d)
Der obige Aufruf erzeugt eine KDE. Es besteht auch die Möglichkeit, eine bestimmte Verteilung an die Daten anzupassen. Dies unterscheidet sich von einem KDE und besteht aus einer Parameterschätzung für generische Daten und einem angegebenen Verteilungsnamen:
sns.distplot(d, fit=stats.laplace, kde=False)
Beachten Sie auch hier den kleinen Unterschied. Im ersten Fall schätzen Sie ein unbekanntes PDF. Im zweiten Fall nehmen Sie eine bekannte Verteilung und finden heraus, welche Parameter sie anhand der empirischen Daten am besten beschreiben.
Andere Tools in Pandas
Zusätzlich zu seinen Plotwerkzeugen bietet Pandas auch eine praktische.value_counts()-Methode, mit der ein Histogramm von Nicht-Null-Werten zu einem PandasSeriesberechnet wird:
>>>
>>> import pandas as pd
>>> data = np.random.choice(np.arange(10), size=10000,
... p=np.linspace(1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
9 1831
8 1624
7 1423
6 1323
5 1089
4 888
3 770
2 535
1 347
0 170
dtype: int64
>>> s.value_counts(normalize=True).head()
9 0.1831
8 0.1624
7 0.1423
6 0.1323
5 0.1089
dtype: float64An anderer Stelle istpandas.cut() eine bequeme Möglichkeit, Werte in beliebige Intervalle einzuteilen. Nehmen wir an, Sie haben einige Daten zum Alter von Personen und möchten diese vernünftig erfassen:
>>>
>>> ages = pd.Series(
... [1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = (0, 10, 13, 18, 21, np.inf) # The edges
>>> labels = ('child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype: int64
>>> pd.concat((ages, groups), axis=1).rename(columns={0: 'age', 1: 'group'})
age group
0 1 child
1 1 child
2 3 child
3 5 child
4 8 child
5 10 child
6 12 preteen
7 15 teen
8 18 teen
9 18 teen
10 19 military_age
11 20 military_age
12 25 adult
13 30 adult
14 40 adult
15 51 adult
16 52 adultWas schön ist, ist, dass beide Vorgänge letztendlichutilize Cython code sind, was sie in Bezug auf Geschwindigkeit wettbewerbsfähig macht und gleichzeitig ihre Flexibilität beibehält.
Okay, also was soll ich verwenden?
Zu diesem Zeitpunkt haben Sie mehr als eine Handvoll Funktionen und Methoden zum Zeichnen eines Python-Histogramms gesehen. Wie vergleichen sie? Kurz gesagt, es gibt keine „Einheitsgröße“. Hier ist eine Zusammenfassung der Funktionen und Methoden, die Sie bisher behandelt haben und die sich alle auf das Aufteilen und Darstellen von Distributionen in Python beziehen:
| Sie haben / wollen | Erwägen Sie die Verwendung | Anmerkungen) |
|---|---|---|
Bereinigen Sie ganzzahlige Daten, die in einer Datenstruktur wie einer Liste, einem Tupel oder einer Menge enthalten sind, und Sie möchten ein Python-Histogramm erstellen, ohne Bibliotheken von Drittanbietern zu importieren. |
|
Dies ist eine Häufigkeitstabelle, daher wird das Konzept des Binning nicht wie ein "echtes" Histogramm verwendet. |
Große Datenmenge, und Sie möchten das „mathematische“ Histogramm berechnen, das die Bins und die entsprechenden Frequenzen darstellt. |
Die |
Weitere Informationen finden Sie unter |
Tabellarische Daten im Objekt |
Pandas-Methoden wie |
Schauen Sie sich die Pandasvisualization docsan, um sich inspirieren zu lassen. |
Erstellen Sie aus jeder Datenstruktur ein hochgradig anpassbares, fein abgestimmtes Diagramm. |
|
Matplotlib und insbesondere seineobject-oriented framework eignen sich hervorragend zur Feinabstimmung der Details eines Histogramms. Das Beherrschen dieser Benutzeroberfläche kann einige Zeit in Anspruch nehmen, ermöglicht Ihnen jedoch letztendlich eine sehr genaue Darstellung der Visualisierung. |
Vorgefertigtes Design und Integration. |
Seaborns |
Im Wesentlichen ein „Wrapper um einen Wrapper“, der intern ein Matplotlib-Histogramm nutzt, das wiederum NumPy verwendet. |
Free Bonus: Zeitmangel? Click here to get access to a free two-page Python histograms cheat sheet, das die in diesem Tutorial erläuterten Techniken zusammenfasst.
Sie finden die Codefragmente aus diesem Artikel auch zusammen in einemscript auf der Real Python-Materialseite.
Viel Glück beim Erstellen von Histogrammen in freier Wildbahn. Hoffentlich entspricht eines der oben genannten Tools Ihren Anforderungen. Was auch immer Sie tun, nurdon’t use a pie chart.