Beschleunigen Sie Ihr Python-Programm mit Parallelität
Wenn Sie viel überasynciobeing added to Python gesprochen haben, aber neugierig sind, wie es mit anderen Parallelitätsmethoden verglichen wird, oder sich fragen, was Parallelität ist und wie es Ihr Programm beschleunigen könnte, sind Sie bei der richtiger Ort.
In diesem Artikel erfahren Sie Folgendes:
-
Wasconcurrency ist
-
Wasparallelism ist
-
Wie einige vonPython’s concurrency methods vergleichen, einschließlich
threading,asyncioundmultiprocessing -
When to use concurrency in Ihrem Programm und welches Modul verwendet werden soll
In diesem Artikel wird davon ausgegangen, dass Sie über ein grundlegendes Verständnis von Python verfügen und mindestens Version 3.6 verwenden, um die Beispiele auszuführen. Sie können die Beispiele vonReal Python GitHub repoherunterladen.
Free Bonus:5 Thoughts On Python Mastery, ein kostenloser Kurs für Python-Entwickler, der Ihnen die Roadmap und die Denkweise zeigt, die Sie benötigen, um Ihre Python-Fähigkeiten auf die nächste Stufe zu bringen.
__ Take the Quiz: Testen Sie Ihr Wissen mit unserem interaktiven Quiz „Python Concurrency“. Nach Abschluss erhalten Sie eine Punktzahl, mit der Sie Ihren Lernfortschritt im Laufe der Zeit verfolgen können:
Was ist Parallelität?
Die Wörterbuchdefinition der Parallelität tritt gleichzeitig auf. In Python werden die Dinge, die gleichzeitig auftreten, mit unterschiedlichen Namen (Thread, Aufgabe, Prozess) aufgerufen, aber auf hoher Ebene beziehen sich alle auf eine Folge von Anweisungen, die der Reihe nach ausgeführt werden.
Ich betrachte sie gerne als verschiedene Gedankengänge. Jeder kann an bestimmten Punkten gestoppt werden, und die CPU oder das Gehirn, das sie verarbeitet, kann zu einem anderen wechseln. Der Status jedes einzelnen wird gespeichert, sodass er genau dort neu gestartet werden kann, wo er unterbrochen wurde.
Sie fragen sich vielleicht, warum Python für dasselbe Konzept unterschiedliche Wörter verwendet. Es stellt sich heraus, dass Threads, Aufgaben und Prozesse nur dann identisch sind, wenn Sie sie von einer hohen Ebene aus betrachten. Sobald Sie sich mit den Details befassen, stellen sie alle leicht unterschiedliche Dinge dar. Sie werden mehr davon sehen, wie sie sich unterscheiden, wenn Sie die Beispiele durcharbeiten.
Lassen Sie uns nun über den gleichzeitigen Teil dieser Definition sprechen. Sie müssen ein wenig vorsichtig sein, denn wenn Sie auf die Details eingehen, führt nurmultiprocessing diese Gedankengänge buchstäblich gleichzeitig aus. Threading undasyncio laufen beide auf einem einzelnen Prozessor und daher jeweils nur auf einem. Sie finden nur geschickt Wege, sich abzuwechseln, um den Gesamtprozess zu beschleunigen. Auch wenn sie nicht gleichzeitig unterschiedliche Gedankengänge ausführen, nennen wir dies immer noch Parallelität.
Die Art und Weise, wie sich die Threads oder Aufgaben abwechseln, ist der große Unterschied zwischenthreading undasyncio. Inthreading kennt das Betriebssystem tatsächlich jeden Thread und kann ihn jederzeit unterbrechen, um einen anderen Thread auszuführen. Dies wird alspre-emptive multitasking bezeichnet, da das Betriebssystem Ihren Thread vorab für den Wechsel freigeben kann.
Präventives Multitasking ist praktisch, da der Code im Thread nichts tun muss, um den Wechsel vorzunehmen. Es kann auch schwierig sein, wegen dieser "jederzeit" Phrase. Dieser Wechsel kann in der Mitte einer einzelnen Python-Anweisung erfolgen, auch in einer trivialen Anweisung wiex = x + 1.
Asyncio verwendet dagegencooperative multitasking. Die Aufgaben müssen zusammenarbeiten, indem sie bekannt geben, wann sie zum Ausschalten bereit sind. Das bedeutet, dass sich der Code in der Aufgabe geringfügig ändern muss, um dies zu erreichen.
Der Vorteil dieser zusätzlichen Arbeit im Voraus besteht darin, dass Sie immer wissen, wo Ihre Aufgabe ausgetauscht wird. Es wird nicht in der Mitte einer Python-Anweisung ausgetauscht, es sei denn, diese Anweisung ist markiert. Sie werden später sehen, wie dies Teile Ihres Designs vereinfachen kann.
Was ist Parallelität?
Bisher haben Sie sich mit der Parallelität befasst, die auf einem einzelnen Prozessor auftritt. Was ist mit all den CPU-Kernen, die Ihr cooler, neuer Laptop hat? Wie können Sie sie nutzen? multiprocessing ist die Antwort.
Mitmultiprocessing erstellt Python neue Prozesse. Ein Prozess kann hier als fast völlig anderes Programm betrachtet werden, obwohl sie technisch normalerweise als eine Sammlung von Ressourcen definiert werden, bei denen die Ressourcen Speicher, Dateihandles und ähnliches enthalten. Eine Möglichkeit, darüber nachzudenken, besteht darin, dass jeder Prozess in einem eigenen Python-Interpreter ausgeführt wird.
Da es sich um unterschiedliche Prozesse handelt, kann jeder Ihrer Gedankengänge in einem Multiprozessor-Programm auf einem anderen Kern ausgeführt werden. Das Laufen auf einem anderen Kern bedeutet, dass sie tatsächlich gleichzeitig laufen können, was fabelhaft ist. Es gibt einige Komplikationen, die sich daraus ergeben, aber Python macht es ziemlich gut, sie die meiste Zeit zu glätten.
Nachdem Sie eine Vorstellung davon haben, was Parallelität und Parallelität sind, wollen wir ihre Unterschiede überprüfen. Anschließend können wir untersuchen, warum sie nützlich sein können:
| Parallelitätstyp | Entscheidung wechseln | Anzahl der Prozessoren |
|---|---|---|
Präventives Multitasking ( |
Das Betriebssystem entscheidet, wann Aufgaben außerhalb von Python gewechselt werden sollen. |
1 |
Kooperatives Multitasking ( |
Die Aufgaben entscheiden, wann die Kontrolle aufgegeben werden soll. |
1 |
Mehrfachverarbeitung ( |
Die Prozesse werden alle gleichzeitig auf verschiedenen Prozessoren ausgeführt. |
Many |
Jede dieser Arten von Parallelität kann nützlich sein. Werfen wir einen Blick darauf, welche Arten von Programmen Ihnen dabei helfen können, schneller zu werden.
Wann ist Parallelität sinnvoll?
Parallelität kann bei zwei Arten von Problemen einen großen Unterschied machen. Diese werden im Allgemeinen als CPU-gebunden und E / A-gebunden bezeichnet.
I/O-bound problems cause your program to slow down because it frequently must wait for input/output (I/O) from some external resource. Sie treten häufig auf, wenn Ihr Programm mit Dingen arbeitet, die viel langsamer als Ihre CPU sind.
Beispiele für Dinge, die langsamer als Ihre CPU sind, sind Legion, aber Ihr Programm interagiert dankenswerterweise nicht mit den meisten von ihnen. Die langsamen Dinge, mit denen Ihr Programm am häufigsten interagiert, sind das Dateisystem und die Netzwerkverbindungen.
Mal sehen, wie das aussieht:
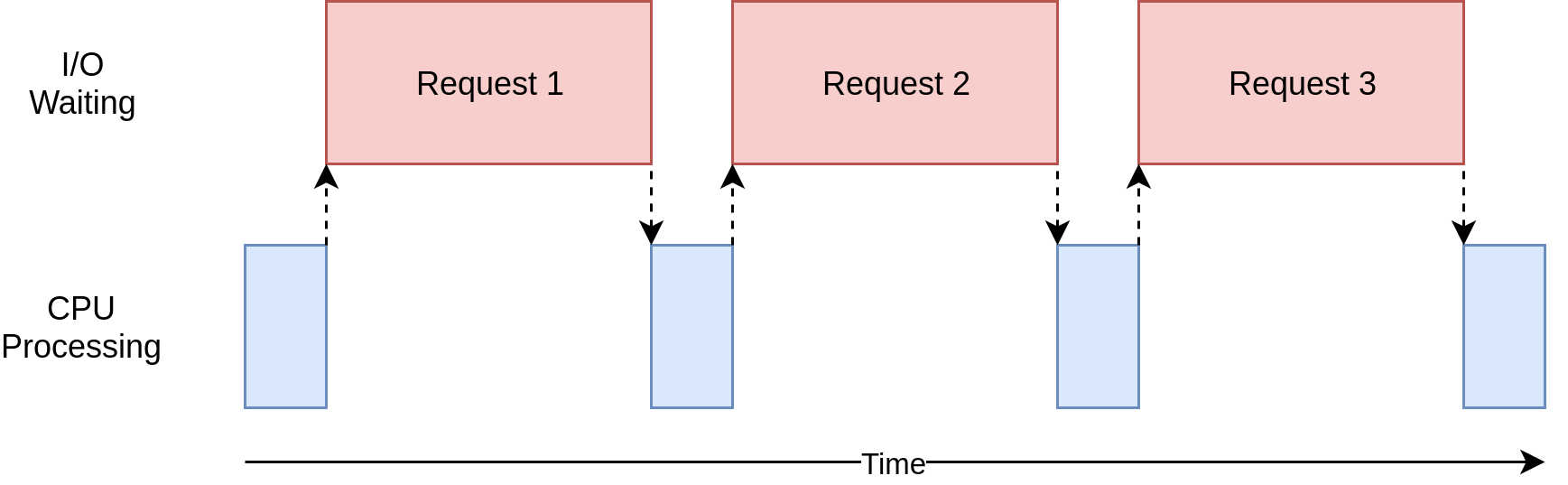
In der obigen Abbildung zeigen die blauen Kästchen die Zeit an, zu der Ihr Programm arbeitet, und die roten Kästchen geben die Zeit an, die für das Warten auf den Abschluss eines E / A-Vorgangs aufgewendet wurde. Dieses Diagramm ist nicht maßstabsgetreu, da Anforderungen im Internet mehrere Größenordnungen länger dauern können als CPU-Anweisungen, sodass Ihr Programm möglicherweise die meiste Zeit mit Warten verbringt. Dies ist, was Ihr Browser die meiste Zeit tut.
Auf der anderen Seite gibt es Programmklassen, die umfangreiche Berechnungen durchführen, ohne mit dem Netzwerk zu sprechen oder auf eine Datei zuzugreifen. Dies sind die CPU-gebundenen Programme, da die Ressource, die die Geschwindigkeit Ihres Programms begrenzt, die CPU ist, nicht das Netzwerk oder das Dateisystem.
Hier ist ein entsprechendes Diagramm für ein CPU-gebundenes Programm:
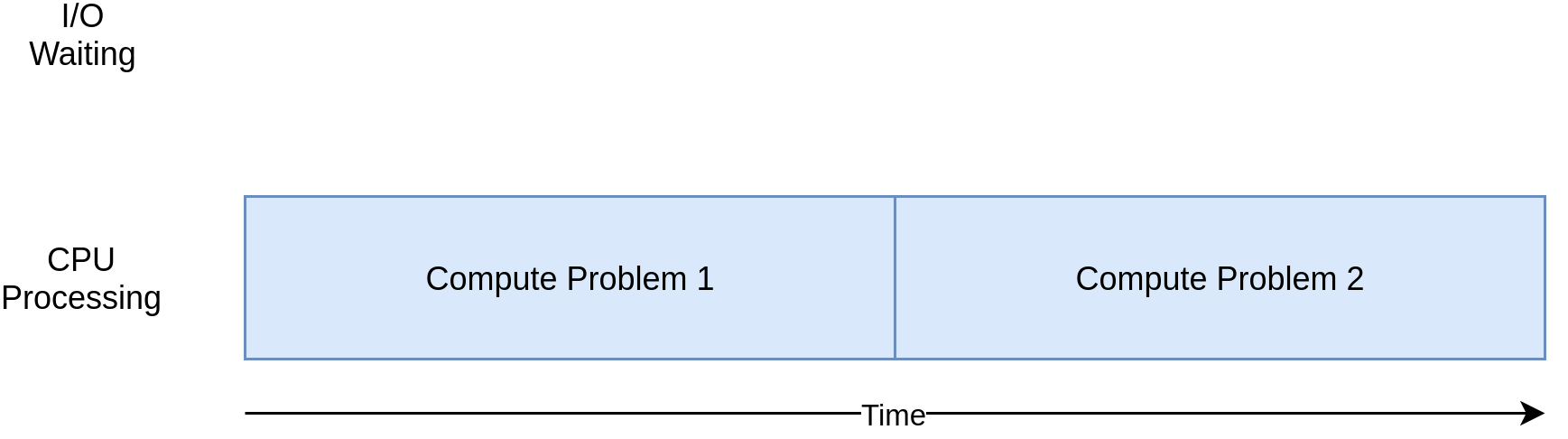
Wenn Sie die Beispiele im folgenden Abschnitt durcharbeiten, werden Sie feststellen, dass verschiedene Formen der Parallelität mit CPU- und E / A-gebundenen Programmen besser oder schlechter funktionieren. Durch Hinzufügen von Parallelität zu Ihrem Programm werden zusätzlicher Code und Komplikationen hinzugefügt. Sie müssen also entscheiden, ob die potenzielle Beschleunigung den zusätzlichen Aufwand wert ist. Am Ende dieses Artikels sollten Sie über genügend Informationen verfügen, um diese Entscheidung treffen zu können.
Hier ist eine kurze Zusammenfassung, um dieses Konzept zu verdeutlichen:
| I/O-Bound Process | CPU-gebundener Prozess |
|---|---|
Ihr Programm verbringt die meiste Zeit damit, mit einem langsamen Gerät wie einer Netzwerkverbindung, einer Festplatte oder einem Drucker zu sprechen. |
Ihr Programm verbringt die meiste Zeit mit CPU-Operationen. |
Um es zu beschleunigen, müssen sich die Wartezeiten auf diese Geräte überschneiden. |
Um es zu beschleunigen, müssen Wege gefunden werden, um mehr Berechnungen in der gleichen Zeit durchzuführen. |
Sie werden sich zuerst die E / A-gebundenen Programme ansehen. Dann sehen Sie Code, der sich mit CPU-gebundenen Programmen befasst.
So beschleunigen Sie ein E / A-gebundenes Programm
Konzentrieren wir uns zunächst auf E / A-gebundene Programme und ein häufiges Problem: das Herunterladen von Inhalten über das Netzwerk. In unserem Beispiel laden Sie Webseiten von einigen Websites herunter, es kann sich jedoch auch um Netzwerkverkehr handeln. Es ist nur einfacher, Webseiten zu visualisieren und einzurichten.
Synchrone Version
Wir beginnen mit einer nicht gleichzeitigen Version dieser Aufgabe. Beachten Sie, dass für dieses Programm das Modulrequestserforderlich ist. Sie solltenpip install requests ausführen, bevor Sie es ausführen, wahrscheinlich mitvirtualenv. Diese Version verwendet überhaupt keine Parallelität:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Wie Sie sehen können, ist dies ein ziemlich kurzes Programm. download_site() lädt nur den Inhalt von einer URL herunter und druckt die Größe. Ein kleiner Punkt ist, dass wir einSession-Objekt vonrequests verwenden.
Es ist möglich,get() einfach vonrequests direkt zu verwenden, aber durch das Erstellen einesSession-Objekts könnenrequests einige ausgefallene Netzwerk-Tricks ausführen und die Dinge wirklich beschleunigen.
download_all_sites() erstellt dieSession und geht dann die Liste der Sites durch, wobei jede nacheinander heruntergeladen wird. Schließlich wird ausgedruckt, wie lange dieser Vorgang gedauert hat, damit Sie zufrieden sein können, zu sehen, wie viel Parallelität uns in den folgenden Beispielen geholfen hat.
Das Verarbeitungsdiagramm für dieses Programm ähnelt stark dem E / A-gebundenen Diagramm im letzten Abschnitt.
Note: Der Netzwerkverkehr hängt von vielen Faktoren ab, die von Sekunde zu Sekunde variieren können. Ich habe gesehen, dass sich die Zeiten dieser Tests aufgrund von Netzwerkproblemen von Lauf zu Lauf verdoppelt haben.
Warum die synchrone Version rockt
Das Tolle an dieser Codeversion ist, dass es einfach ist. Es war vergleichsweise einfach zu schreiben und zu debuggen. Es ist auch einfacher, darüber nachzudenken. Es läuft nur ein Gedankengang durch, sodass Sie vorhersagen können, was der nächste Schritt ist und wie er sich verhalten wird.
Die Probleme mit der synchronen Version
Das große Problem hierbei ist, dass es im Vergleich zu den anderen von uns angebotenen Lösungen relativ langsam ist. Hier ist ein Beispiel dafür, was die endgültige Ausgabe auf meinem Computer ergab:
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 secondsNote: Ihre Ergebnisse können erheblich variieren. Beim Ausführen dieses Skripts habe ich festgestellt, dass die Zeiten zwischen 14,2 und 21,9 Sekunden variieren. Für diesen Artikel habe ich als Zeit den schnellsten von drei Läufen genommen. Die Unterschiede zwischen den Methoden werden immer noch klar sein.
Langsamer zu sein ist jedoch nicht immer ein großes Problem. Wenn das von Ihnen ausgeführte Programm mit einer synchronen Version nur 2 Sekunden dauert und nur selten ausgeführt wird, lohnt es sich wahrscheinlich nicht, Parallelität hinzuzufügen. Sie können hier aufhören.
Was ist, wenn Ihr Programm häufig ausgeführt wird? Was ist, wenn der Betrieb Stunden dauert? Fahren wir mit der Parallelität fort, indem wir dieses Programm mitthreading neu schreiben.
threading Version
Wie Sie wahrscheinlich vermutet haben, erfordert das Schreiben eines Thread-Programms mehr Aufwand. Sie werden überrascht sein, wie wenig zusätzlicher Aufwand für einfache Fälle erforderlich ist. So sieht das gleiche Programm mitthreading aus:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Wenn Siethreading hinzufügen, ist die Gesamtstruktur dieselbe und Sie mussten nur einige Änderungen vornehmen. download_all_sites() wurde vom einmaligen Aufruf der Funktion pro Site zu einer komplexeren Struktur geändert.
In dieser Version erstellen Sie einThreadPoolExecutor, was kompliziert erscheint. Lassen Sie uns das aufschlüsseln:ThreadPoolExecutor =Thread +Pool +Executor.
Sie kennen bereits den Teil vonThread. Das ist nur ein Gedankengang, den wir bereits erwähnt haben. Der Anteil vonPool ist dort, wo es interessant wird. Dieses Objekt erstellt einen Pool von Threads, die jeweils gleichzeitig ausgeführt werden können. Schließlich istExecutor der Teil, der steuert, wie und wann jeder der Threads im Pool ausgeführt wird. Die Anforderung wird im Pool ausgeführt.
Hilfreicherweise implementiert die StandardbibliothekThreadPoolExecutor als Kontextmanager, sodass Sie die Syntax vonwithverwenden können, um das Erstellen und Freigeben des Pools vonThreads zu verwalten.
Sobald Sie einThreadPoolExecutor haben, können Sie die praktische.map()-Methode verwenden. Diese Methode führt die übergebene Funktion auf jeder der Sites in der Liste aus. Der große Teil ist, dass sie automatisch gleichzeitig mit dem von ihnen verwalteten Thread-Pool ausgeführt werden.
Diejenigen von Ihnen, die aus anderen Sprachen oder sogar Python 2 stammen, fragen sich wahrscheinlich, wo sich die üblichen Objekte und Funktionen befinden, die die Details verwalten, an die Sie beim Umgang mitthreading gewöhnt sind, z. B.Thread.start(),Thread.join() undQueue.
Diese sind alle noch vorhanden, und Sie können sie verwenden, um eine detaillierte Kontrolle darüber zu erhalten, wie Ihre Threads ausgeführt werden. Ab Python 3.2 hat die Standardbibliothek jedoch eine übergeordnete Abstraktion namensExecutors hinzugefügt, die viele Details für Sie verwaltet, wenn Sie dieses fein abgestimmte Steuerelement nicht benötigen.
Die andere interessante Änderung in unserem Beispiel ist, dass jeder Thread sein eigenesrequests.Session()-Objekt erstellen muss. Wenn Sie sich die Dokumentation fürrequests ansehen, ist es nicht unbedingt leicht zu sagen, aber beim Lesen vonthis issue scheint es ziemlich klar zu sein, dass Sie für jeden Thread eine separate Sitzung benötigen.
Dies ist eines der interessanten und schwierigen Probleme mitthreading. Da das Betriebssystem die Kontrolle darüber hat, wann Ihre Aufgabe unterbrochen wird und eine andere Aufgabe gestartet wird, müssen alle Daten, die von den Threads gemeinsam genutzt werden, geschützt oder threadsicher sein. Leider istrequests.Session() nicht threadsicher.
Es gibt verschiedene Strategien, um Datenzugriffe threadsicher zu machen, je nachdem, um welche Daten es sich handelt und wie Sie sie verwenden. Eine davon ist die Verwendung von thread-sicheren Datenstrukturen wieQueue aus Pythonsqueue-Modul.
Diese Objekte verwenden Grundelemente auf niedriger Ebene wiethreading.Lock, um sicherzustellen, dass nur ein Thread gleichzeitig auf einen Codeblock oder ein Stück Speicher zugreifen kann. Sie verwenden diese Strategie indirekt über dasThreadPoolExecutor-Objekt.
Eine andere Strategie, die hier verwendet werden kann, ist der sogenannte lokale Thread-Speicher. Threading.local() erstellt ein Objekt, das wie ein globales Objekt aussieht, aber für jeden einzelnen Thread spezifisch ist. In Ihrem Beispiel erfolgt dies mitthreadLocal undget_session():
threadLocal = threading.local()
def get_session():
if not hasattr(threadLocal, "session"):
threadLocal.session = requests.Session()
return threadLocal.sessionThreadLocal befindet sich im Modulthreading, um dieses Problem gezielt zu lösen. Es sieht etwas seltsam aus, aber Sie möchten nur eines dieser Objekte erstellen, nicht eines für jeden Thread. Das Objekt selbst sorgt dafür, dass Zugriffe von verschiedenen Threads auf verschiedene Daten getrennt werden.
Wennget_session() aufgerufen wird, ist das nachgeschlagenesession spezifisch für den jeweiligen Thread, auf dem es ausgeführt wird. Daher erstellt jeder Thread beim ersten Aufruf vonget_session() eine einzelne Sitzung und verwendet diese Sitzung dann einfach bei jedem nachfolgenden Aufruf während seiner gesamten Lebensdauer.
Zum Schluss noch ein kurzer Hinweis zur Auswahl der Anzahl der Threads. Sie können sehen, dass der Beispielcode 5 Threads verwendet. Spielen Sie mit dieser Nummer und sehen Sie, wie sich die Gesamtzeit ändert. Sie könnten erwarten, dass ein Thread pro Download am schnellsten ist, aber zumindest auf meinem System war dies nicht der Fall. Ich habe die schnellsten Ergebnisse zwischen 5 und 10 Threads gefunden. Wenn Sie einen höheren Wert erreichen, werden durch den zusätzlichen Aufwand für das Erstellen und Zerstören der Threads keine Zeiteinsparungen erzielt.
Die schwierige Antwort hier ist, dass die richtige Anzahl von Threads keine Konstante von einer Aufgabe zur anderen ist. Einige Experimente sind erforderlich.
Warum diethreading Version rockt
Es ist schnell! Hier ist der schnellste Lauf meiner Tests. Denken Sie daran, dass die nicht gleichzeitige Version länger als 14 Sekunden dauerte:
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 secondsSo sieht das Ausführungszeitdiagramm aus:
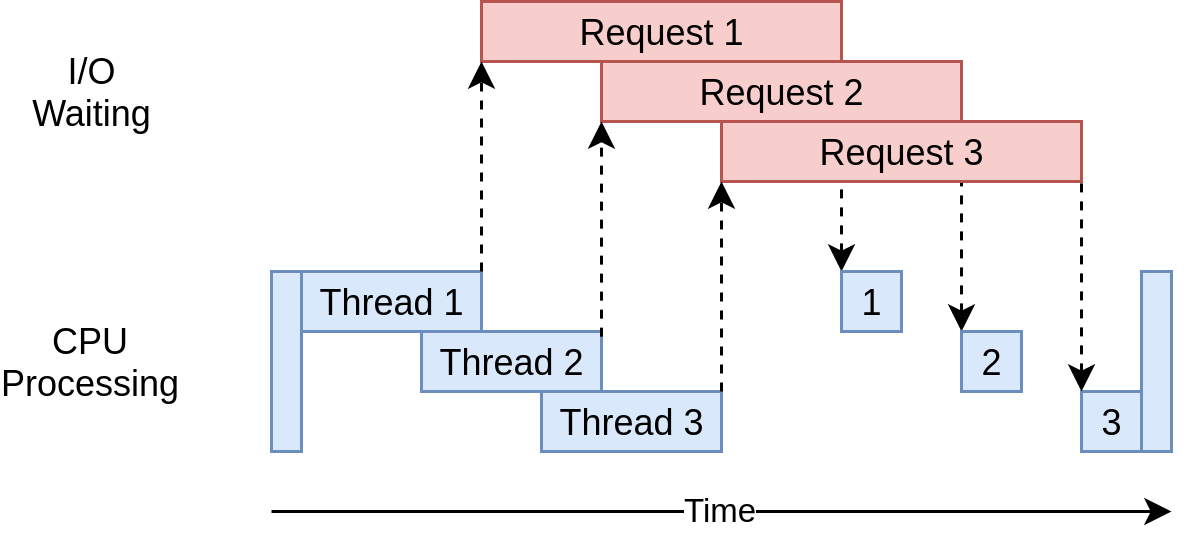
Es werden mehrere Threads verwendet, um mehrere offene Anfragen gleichzeitig an Websites zu senden, sodass Ihr Programm die Wartezeiten überschneiden und das Endergebnis schneller erhalten kann! Hurra! Das war das Ziel.
Die Probleme mit derthreading Version
Wie Sie dem Beispiel entnehmen können, ist etwas mehr Code erforderlich, um dies zu erreichen, und Sie müssen sich wirklich Gedanken darüber machen, welche Daten zwischen Threads geteilt werden.
Threads können auf subtile und schwer zu erkennende Weise interagieren. Diese Interaktionen können zu Rennbedingungen führen, die häufig zu zufälligen, zeitweiligen Fehlern führen, die sehr schwer zu finden sind. Diejenigen unter Ihnen, die mit dem Konzept der Rennbedingungen nicht vertraut sind, möchten möglicherweise den folgenden Abschnitt erweitern und lesen.
asyncio Version
Bevor Sie sich mit dem Beispielcode vonasynciobefassen, wollen wir uns näher mit der Funktionsweise vonasynciobefassen.
asyncio Grundlagen
Dies ist eine vereinfachte Version vonasycio. Es gibt viele Details, die hier beschönigt werden, aber es vermittelt immer noch die Idee, wie es funktioniert.
Das allgemeine Konzept vonasyncio besteht darin, dass ein einzelnes Python-Objekt, die als Ereignisschleife bezeichnet wird, steuert, wie und wann jede Aufgabe ausgeführt wird. Die Ereignisschleife kennt jede Aufgabe und weiß, in welchem Zustand sie sich befindet. In der Realität gibt es viele Zustände, in denen sich Aufgaben befinden könnten. Stellen wir uns jedoch zunächst eine vereinfachte Ereignisschleife vor, die nur zwei Zustände aufweist.
Der Bereitschaftsstatus zeigt an, dass eine Aufgabe zu erledigen ist und ausgeführt werden kann, und der Wartezustand bedeutet, dass die Aufgabe darauf wartet, dass eine externe Sache beendet wird, z. B. ein Netzwerkbetrieb.
Ihre vereinfachte Ereignisschleife verwaltet zwei Aufgabenlisten, eine für jeden dieser Zustände. Es wählt eine der fertigen Aufgaben aus und startet sie wieder. Diese Aufgabe hat die vollständige Kontrolle, bis sie die Steuerung kooperativ an die Ereignisschleife zurückgibt.
Wenn die ausgeführte Aufgabe die Steuerung an die Ereignisschleife zurückgibt, platziert die Ereignisschleife diese Aufgabe entweder in der Bereitschafts- oder in der Warteliste und durchläuft dann jede der Aufgaben in der Warteliste, um festzustellen, ob sie durch eine E / A-Operation bereit ist Abschluss. Es ist bekannt, dass die Aufgaben in der Bereitschaftsliste noch bereit sind, da es weiß, dass sie noch nicht ausgeführt wurden.
Sobald alle Aufgaben wieder in der richtigen Liste sortiert wurden, wählt die Ereignisschleife die nächste auszuführende Aufgabe aus und der Vorgang wird wiederholt. Ihre vereinfachte Ereignisschleife wählt die Aufgabe aus, die am längsten gewartet hat, und führt diese aus. Dieser Vorgang wird wiederholt, bis die Ereignisschleife beendet ist.
Ein wichtiger Punkt vonasyncio ist, dass die Aufgaben niemals die Kontrolle aufgeben, ohne dies absichtlich zu tun. Sie werden nie mitten in einer Operation unterbrochen. Dies ermöglicht es uns, Ressourcen inasyncio etwas einfacher zu teilen als inthreading. Sie müssen sich keine Sorgen machen, dass Ihr Code threadsicher ist.
Dies ist eine allgemeine Ansicht darüber, was mitasyncio passiert. Wenn Sie mehr Details wünschen, bietetthis StackOverflow answer einige gute Details, wenn Sie tiefer graben möchten.
async undawait
Lassen Sie uns nun über zwei neue Schlüsselwörter sprechen, die Python hinzugefügt wurden:async undawait. In Anbetracht der obigen Diskussion können Sieawait als die Magie betrachten, die es der Aufgabe ermöglicht, die Steuerung an die Ereignisschleife zurückzugeben. Wenn Ihr Code auf einen Funktionsaufruf wartet, ist dies ein Signal dafür, dass der Aufruf wahrscheinlich eine Weile dauert und dass die Aufgabe die Kontrolle aufgeben sollte.
Es ist am einfachsten, sichasync als Flag für Python vorzustellen, das besagt, dass die zu definierende Funktionawait verwendet. Es gibt einige Fälle, in denen dies nicht unbedingt zutrifft, wie z. B.asynchronous generators. Dies gilt jedoch für viele Fälle und bietet Ihnen ein einfaches Modell, während Sie beginnen.
Eine Ausnahme davon, die Sie im nächsten Code sehen werden, ist die Anweisungasync with, mit der ein Kontextmanager aus einem Objekt erstellt wird, auf das Sie normalerweise warten würden. Obwohl die Semantik etwas anders ist, ist die Idee dieselbe: Diesen Kontextmanager als etwas zu kennzeichnen, das ausgetauscht werden kann.
Wie Sie sich sicher vorstellen können, ist die Verwaltung der Interaktion zwischen der Ereignisschleife und den Aufgaben etwas komplex. Für Entwickler, die mitasyncio beginnen, sind diese Details nicht wichtig. Sie müssen jedoch berücksichtigen, dass jede Funktion, dieawait aufruft, mitasync markiert werden muss. Andernfalls wird ein Syntaxfehler angezeigt.
Zurück zum Code
Nachdem Sie ein grundlegendes Verständnis dafür haben, wasasyncio ist, gehen wir dieasyncio-Version des Beispielcodes durch und finden heraus, wie es funktioniert. Beachten Sie, dass diese Versionaiohttp hinzufügt. Sie solltenpip install aiohttp ausführen, bevor Sie es ausführen:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")Diese Version ist etwas komplexer als die beiden vorherigen. Es hat eine ähnliche Struktur, aber das Einrichten der Aufgaben erfordert etwas mehr Arbeit als das Erstellen derThreadPoolExecutor. Beginnen wir oben im Beispiel.
download_site()
download_site() oben ist fast identisch mit der Versionthreading, mit Ausnahme des Schlüsselwortsasync in der Funktionsdefinitionszeile und der Schlüsselwörterasync with, wenn Sie tatsächlichsession.get()aufrufen ) s. Sie werden später sehen, warumSession hier übergeben werden können, anstatt threadlokalen Speicher zu verwenden.
download_all_sites()
Indownload_all_sites() sehen Sie die größte Änderung gegenüber dem Beispiel vonthreading.
Sie können die Sitzung für alle Aufgaben freigeben, sodass die Sitzung hier als Kontextmanager erstellt wird. Die Aufgaben können die Sitzung gemeinsam nutzen, da sie alle auf demselben Thread ausgeführt werden. Es gibt keine Möglichkeit, dass eine Aufgabe eine andere unterbricht, während sich die Sitzung in einem schlechten Zustand befindet.
In diesem Kontextmanager wird mitasyncio.ensure_future() eine Liste von Aufgaben erstellt, die sich auch um deren Start kümmert. Sobald alle Aufgaben erstellt wurden, verwendet diese Funktionasyncio.gather(), um den Sitzungskontext am Leben zu erhalten, bis alle Aufgaben abgeschlossen sind.
Der Code vonthreadingmacht etwas Ähnliches, aber die Details werden bequem inThreadPoolExecutorbehandelt. Derzeit gibt es keineAsyncioPoolExecutor-Klasse.
Es gibt jedoch eine kleine, aber wichtige Änderung, die hier in den Details vergraben ist. Erinnerst du dich, wie wir über die Anzahl der zu erstellenden Threads gesprochen haben? Im Beispiel vonthreadingwar nicht ersichtlich, wie viele Threads optimal waren.
Einer der coolen Vorteile vonasyncio ist, dass es weitaus besser skaliert alsthreading. Jede Aufgabe benötigt viel weniger Ressourcen und weniger Zeit zum Erstellen als ein Thread, sodass das Erstellen und Ausführen von mehr davon gut funktioniert. In diesem Beispiel wird nur eine separate Aufgabe für jede herunterzuladende Site erstellt, was recht gut funktioniert.
__main__
Schließlich bedeutet die Art vonasyncio, dass Sie die Ereignisschleife starten und ihr mitteilen müssen, welche Aufgaben ausgeführt werden sollen. Der Abschnitt__main__ am Ende der Datei enthält den Code fürget_event_loop() und dannrun_until_complete(). Wenn nichts anderes, haben sie bei der Benennung dieser Funktionen hervorragende Arbeit geleistet.
Wenn Sie aufPython 3.7 aktualisiert haben, haben die Python-Kernentwickler diese Syntax für Sie vereinfacht. Anstelle des Zungenbrechersasyncio.get_event_loop().run_until_complete()können Sie auchasyncio.run() verwenden.
Warum dieasyncio Version rockt
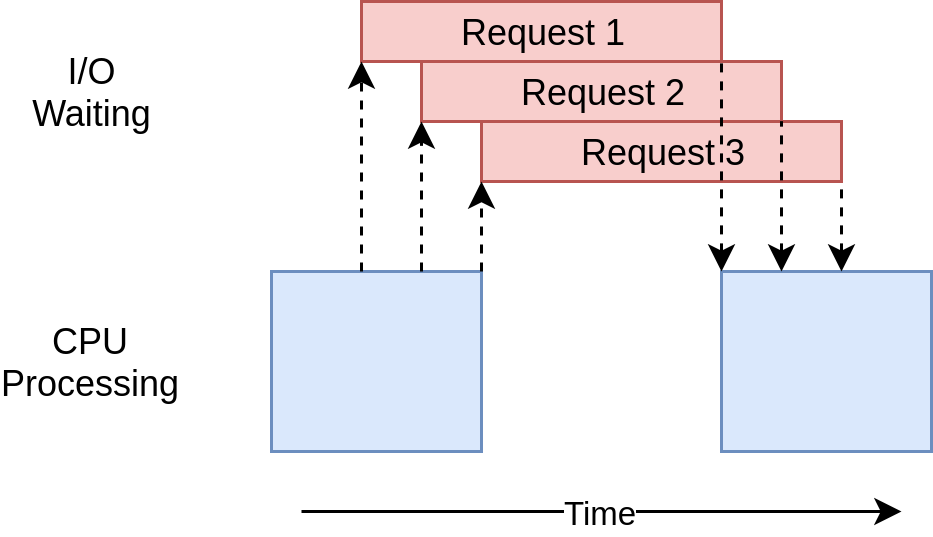
Es ist wirklich schnell! In den Tests auf meinem Computer war dies mit Abstand die schnellste Version des Codes:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 secondsDas Ausführungszeitdiagramm sieht ziemlich ähnlich aus wie im Beispiel vonthreading. Es ist nur so, dass die E / A-Anforderungen alle von demselben Thread ausgeführt werden:
Das Fehlen eines netten Wrappers wieThreadPoolExecutor macht diesen Code etwas komplexer als das Beispiel vonthreading. Dies ist ein Fall, in dem Sie ein wenig zusätzliche Arbeit leisten müssen, um eine viel bessere Leistung zu erzielen.
Es gibt auch ein allgemeines Argument, dass das Hinzufügen vonasync undawait an den richtigen Stellen eine zusätzliche Komplikation darstellt. In geringem Maße ist das wahr. Die Kehrseite dieses Arguments ist, dass Sie gezwungen sind, darüber nachzudenken, wann eine bestimmte Aufgabe ausgetauscht wird, was Ihnen helfen kann, ein besseres, schnelleres Design zu erstellen.
Auch hier spielt das Skalierungsproblem eine große Rolle. Das Ausführen des obigen Beispiels vonthreadingmit einem Thread für jede Site ist merklich langsamer als das Ausführen mit einer Handvoll Threads. Das Ausführen des Beispielsasynciomit Hunderten von Aufgaben hat es überhaupt nicht verlangsamt.
Die Probleme mit derasyncio Version
Zu diesem Zeitpunkt gibt es einige Probleme mitasyncio. Sie benötigen spezielle asynchrone Versionen von Bibliotheken, um den vollen Vorteil vonasycio zu nutzen. Wenn Sie nurrequests zum Herunterladen der Websites verwendet hätten, wäre dies viel langsamer gewesen, darequests nicht dazu gedacht ist, die Ereignisschleife darüber zu informieren, dass sie blockiert ist. Dieses Problem wird mit der Zeit immer kleiner und mehr Bibliotheken umfassenasyncio.
Ein weiteres subtileres Problem ist, dass alle Vorteile des kooperativen Multitasking wegfallen, wenn eine der Aufgaben nicht zusammenarbeitet. Ein kleiner Fehler im Code kann dazu führen, dass eine Aufgabe ausgeführt wird und der Prozessor lange Zeit gehalten wird, wodurch andere Aufgaben, die ausgeführt werden müssen, ausgehungert werden. Die Ereignisschleife kann nicht unterbrochen werden, wenn eine Aufgabe die Steuerung nicht an sie zurückgibt.
Lassen Sie uns in diesem Sinne zu einem radikal anderen Ansatz für die Parallelität übergehen,multiprocessing.
multiprocessing Version
Im Gegensatz zu den vorherigen Ansätzen nutzt diemultiprocessing-Version des Codes die mehreren CPUs Ihres coolen neuen Computers voll aus. Oder in meinem Fall, dass mein klobiger, alter Laptop hat. Beginnen wir mit dem Code:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")Dies ist viel kürzer als das Beispiel vonasynciound sieht dem Beispiel vonthreadingziemlich ähnlich. Bevor wir uns jedoch mit dem Code befassen, lassen Sie uns einen kurzen Überblick darüber geben, wasmultiprocessing für Sie tut.
multiprocessing auf den Punkt gebracht
Bis zu diesem Zeitpunkt werden alle Beispiele für Parallelität in diesem Artikel nur auf einer einzelnen CPU oder einem Kern Ihres Computers ausgeführt. Die Gründe hierfür liegen im aktuellen Design von CPython und der so genannten Global Interpreter Lock (GIL).
Dieser Artikel befasst sich nicht mit dem Wie und Warum derGIL. Im Moment reicht es zu wissen, dass die synchronen Versionenthreading undasyncio dieses Beispiels alle auf einer einzelnen CPU ausgeführt werden.
multiprocessing in der Standardbibliothek wurde entwickelt, um diese Barriere zu überwinden und Ihren Code auf mehreren CPUs auszuführen. Auf hoher Ebene wird dazu eine neue Instanz des Python-Interpreters erstellt, die auf jeder CPU ausgeführt werden soll, und anschließend ein Teil Ihres Programms für die Ausführung auf dieser CPU ausgelagert.
Wie Sie sich vorstellen können, ist das Aufrufen eines separaten Python-Interpreters nicht so schnell wie das Starten eines neuen Threads im aktuellen Python-Interpreter. Es handelt sich um eine Schwergewichtsoperation mit einigen Einschränkungen und Schwierigkeiten, aber für das richtige Problem kann es einen großen Unterschied machen.
multiprocessing Code
Der Code hat einige kleine Änderungen gegenüber unserer synchronen Version. Der erste ist indownload_all_sites(). Anstattdownload_site() einfach wiederholt aufzurufen, wird einmultiprocessing.Pool-Objekt erstellt unddownload_site den iterierbarensites zugeordnet. Dies sollte aus dem Beispiel vonthreadingbekannt sein.
Was hier passiert, ist, dassPool eine Reihe separater Python-Interpreter-Prozesse erstellt und jeweils die angegebene Funktion für einige der Elemente in der Iterable ausführen lässt, in unserem Fall die Liste der Sites. Die Kommunikation zwischen dem Hauptprozess und den anderen Prozessen wird für Sie vommultiprocessing-Modul übernommen.
Die Zeile, diePool erzeugt, ist Ihre Aufmerksamkeit wert. Zunächst wird nicht angegeben, wie viele Prozesse inPool erstellt werden sollen, obwohl dies ein optionaler Parameter ist. Standardmäßig bestimmtmultiprocessing.Pool() die Anzahl der CPUs in Ihrem Computer und stimmt mit dieser überein. Dies ist häufig die beste Antwort, und dies ist in unserem Fall der Fall.
Bei diesem Problem hat die Erhöhung der Anzahl der Prozesse die Dinge nicht schneller gemacht. Dies hat die Dinge tatsächlich verlangsamt, da die Kosten für das Einrichten und Herunterfahren all dieser Prozesse höher waren als der Vorteil der parallelen Ausführung der E / A-Anforderungen.
Als nächstes haben wir deninitializer=set_global_sessionTeil dieses Aufrufs. Denken Sie daran, dass jeder Prozess in unserenPool seinen eigenen Speicherplatz hat. Das bedeutet, dass sie Dinge wie dasSession-Objekt nicht gemeinsam nutzen können. Sie möchten nicht bei jedem Aufruf der Funktion ein neuesSessionerstellen, sondern für jeden Prozess eines erstellen.
Der Funktionsparameterinitializer ist nur für diesen Fall erstellt. Es gibt keine Möglichkeit, einen Rückgabewert voninitializer an die vom Prozessdownload_site() aufgerufene Funktion zurückzugeben, aber Sie können eine globalesession-Variable initialisieren, um die einzelne Sitzung für jede zu halten Prozess. Da jeder Prozess seinen eigenen Speicherplatz hat, ist der globale Speicher für jeden unterschiedlich.
Das ist wirklich alles. Der Rest des Codes ähnelt dem, was Sie zuvor gesehen haben.
Warum diemultiprocessing Version rockt
Diemultiprocessing-Version dieses Beispiels ist großartig, da sie relativ einfach einzurichten ist und wenig zusätzlichen Code erfordert. Es nutzt auch die CPU-Leistung Ihres Computers voll aus. Das Ausführungszeitdiagramm für diesen Code sieht folgendermaßen aus:
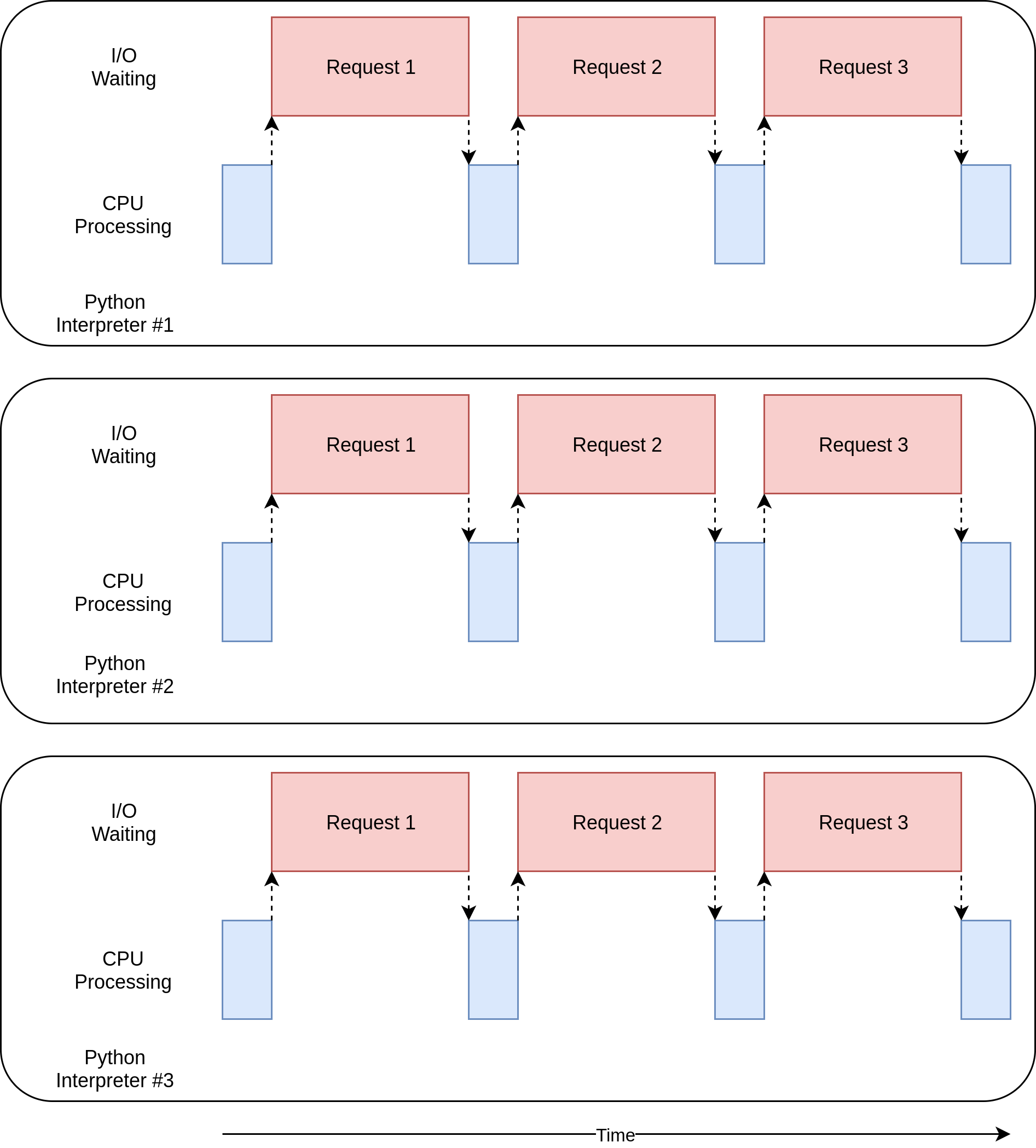
Die Probleme mit dermultiprocessing Version
Diese Version des Beispiels erfordert einige zusätzliche Einstellungen, und das globalesession-Objekt ist seltsam. Sie müssen einige Zeit damit verbringen, darüber nachzudenken, auf welche Variablen in jedem Prozess zugegriffen wird.
Schließlich ist es deutlich langsamer als die Versionenasyncio undthreading in diesem Beispiel:
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 secondsDies ist nicht überraschend, da E / A-gebundene Probleme nicht wirklich der Grund dafür sind, dassmultiprocessing existieren. Sie werden mehr sehen, wenn Sie in den nächsten Abschnitt eintreten und sich CPU-gebundene Beispiele ansehen.
So beschleunigen Sie ein CPU-gebundenes Programm
Lassen Sie uns hier ein wenig schalten. Die bisherigen Beispiele haben sich alle mit einem E / A-gebundenen Problem befasst. Nun werden Sie sich mit einem CPU-gebundenen Problem befassen. Wie Sie gesehen haben, verbringt ein E / A-gebundenes Problem die meiste Zeit damit, auf externe Vorgänge wie einen Netzwerkanruf zu warten. Ein CPU-gebundenes Problem führt dagegen nur wenige E / A-Operationen aus, und seine Gesamtausführungszeit ist ein Faktor dafür, wie schnell es die erforderlichen Daten verarbeiten kann.
In unserem Beispiel verwenden wir eine etwas alberne Funktion, um etwas zu erstellen, dessen Ausführung auf der CPU lange dauert. Diese Funktion berechnet die Summe der Quadrate jeder Zahl von 0 bis zum übergebenen Wert:
def cpu_bound(number):
return sum(i * i for i in range(number))Sie werden in großer Zahl vorbeikommen, daher wird dies eine Weile dauern. Denken Sie daran, dass dies nur ein Platzhalter für Ihren Code ist, der tatsächlich etwas Nützliches bewirkt und erhebliche Verarbeitungszeit erfordert, z. B. das Berechnen der Wurzeln von Gleichungen oder das Sortieren einer großen Datenstruktur.
CPU-gebundene synchrone Version
Schauen wir uns nun die nicht gleichzeitige Version des Beispiels an:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Dieser Code ruftcpu_bound() 20 Mal mit jeweils einer anderen großen Zahl auf. All dies wird auf einem einzelnen Thread in einem einzelnen Prozess auf einer einzelnen CPU ausgeführt. Das Ausführungszeitdiagramm sieht folgendermaßen aus:
Im Gegensatz zu den E / A-gebundenen Beispielen sind die CPU-gebundenen Beispiele in ihrer Laufzeit normalerweise ziemlich konsistent. Dieser dauert auf meinem Computer ungefähr 7,8 Sekunden:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 secondsNatürlich können wir es besser machen. Dies alles läuft auf einer einzelnen CPU ohne Parallelität. Mal sehen, was wir tun können, um es besser zu machen.
threading undasyncio Versionen
Wie viel wird das Umschreiben dieses Codes mitthreading oderasyncio Ihrer Meinung nach beschleunigen?
Wenn Sie mit "Überhaupt nicht" geantwortet haben, geben Sie sich einen Cookie. Wenn Sie geantwortet haben: "Es wird es verlangsamen", geben Sie sich zwei Cookies.
Hier ist der Grund: In Ihrem obigen E / A-gebundenen Beispiel wurde ein Großteil der Gesamtzeit damit verbracht, auf den Abschluss langsamer Vorgänge zu warten. threading undasyncio haben dies beschleunigt, indem Sie die Wartezeiten überlappen konnten, anstatt sie nacheinander auszuführen.
Bei einem CPU-gebundenen Problem gibt es jedoch kein Warten. Die CPU dreht sich so schnell wie möglich weg, um das Problem zu beheben. In Python werden sowohl Threads als auch Tasks im selben Prozess auf derselben CPU ausgeführt. Dies bedeutet, dass die eine CPU die gesamte Arbeit des nicht gleichzeitigen Codes sowie die zusätzliche Arbeit zum Einrichten von Threads oder Aufgaben erledigt. Es dauert mehr als 10 Sekunden:
$ ./cpu_threading.py
Duration 10.407078266143799 secondsIch habe einethreading-Version dieses Codes geschrieben und sie zusammen mit dem anderen Beispielcode inGitHub repo eingefügt, damit Sie dies selbst testen können. Schauen wir uns das jedoch noch nicht an.
CPU-gebundenemultiprocessing Version
Jetzt haben Sie endlich erreicht, womultiprocessing wirklich leuchtet. Im Gegensatz zu den anderen Parallelitätsbibliotheken istmultiprocessing explizit so konzipiert, dass schwere CPU-Workloads auf mehrere CPUs verteilt werden. So sieht das Ausführungszeitdiagramm aus:
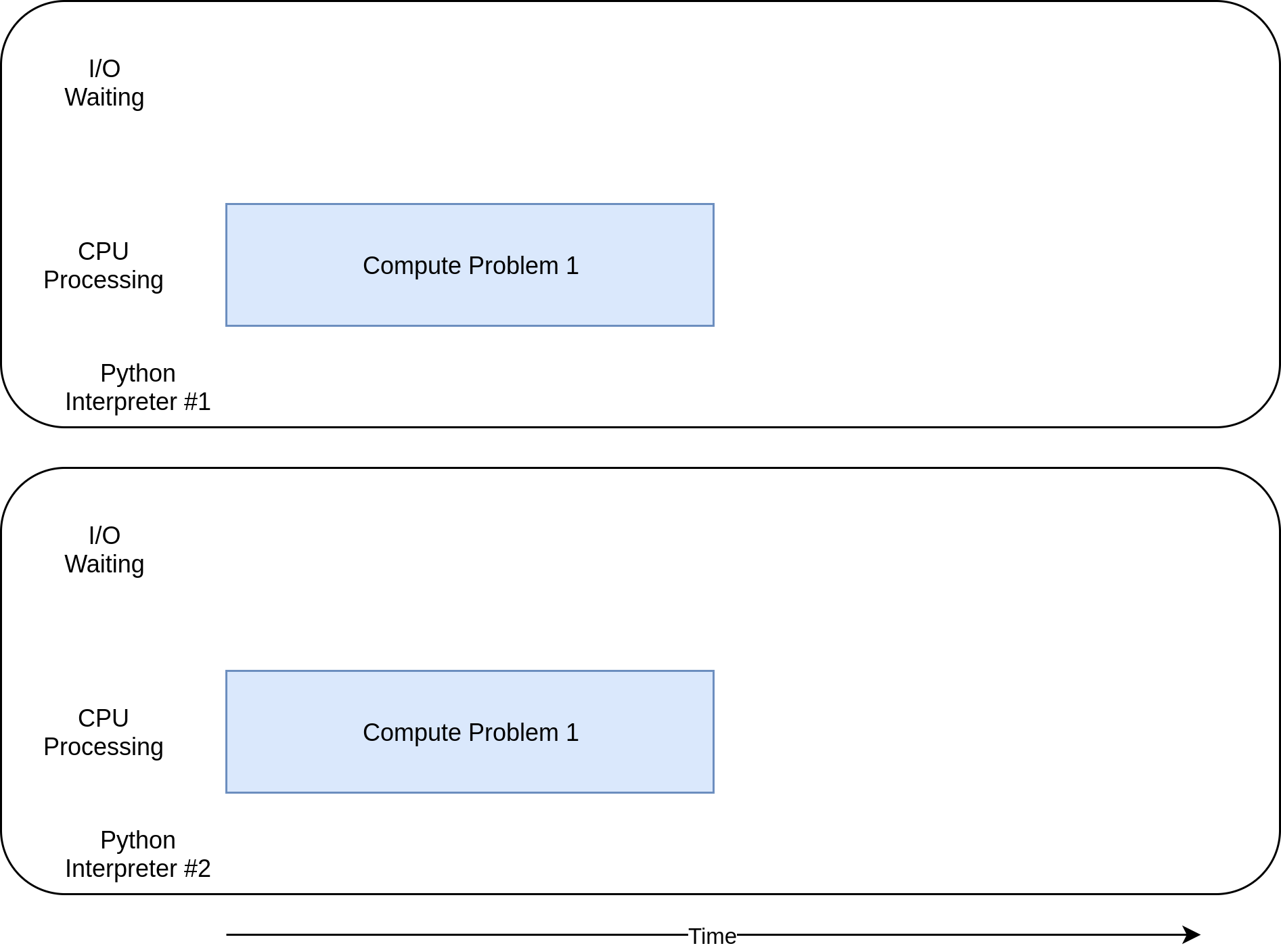
So sieht der Code aus:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")Von der nicht gleichzeitigen Version musste sich wenig an diesem Code ändern. Sie musstenimport multiprocessing und dann einfach von der Schleife durch die Zahlen zum Erstellen einesmultiprocessing.Pool-Objekts und der.map()-Methode wechseln, um einzelne Zahlen an Worker-Prozesse zu senden, sobald diese frei werden.
Dies war genau das, was Sie für den E / A-gebundenenmultiprocessing-Code getan haben, aber hier müssen Sie sich keine Gedanken über dasSession-Objekt machen.
Wie oben erwähnt, verdient der optionale Parameterprocessesfür den Konstruktormultiprocessing.Pool()einige Aufmerksamkeit. Sie können angeben, wie vieleProcess-Objekte inPool erstellt und verwaltet werden sollen. Standardmäßig wird festgelegt, wie viele CPUs sich in Ihrem Computer befinden, und für jede wird ein Prozess erstellt. Während dies für unser einfaches Beispiel hervorragend funktioniert, möchten Sie möglicherweise etwas mehr Kontrolle in einer Produktionsumgebung haben.
Wie bereits im ersten Abschnitt überthreading erwähnt, basiert der Code vonmultiprocessing.Poolauf Bausteinen wieQueue undSemaphore, die denen von Ihnen bekannt sind Multithread- und Multiprozesscode in anderen Sprachen ausgeführt.
Warum diemultiprocessing Version rockt
Diemultiprocessing-Version dieses Beispiels ist großartig, da sie relativ einfach einzurichten ist und wenig zusätzlichen Code erfordert. Es nutzt auch die CPU-Leistung Ihres Computers voll aus.
Hey, genau das habe ich gesagt, als wir uns das letzte Malmultiprocessing angesehen haben. Der große Unterschied ist, dass diesmal eindeutig die beste Option ist. Auf meinem Computer dauert es 2,5 Sekunden:
$ ./cpu_mp.py
Duration 2.5175397396087646 secondsDas ist viel besser als bei den anderen Optionen.
Die Probleme mit dermultiprocessing Version
Die Verwendung vonmultiprocessing weist einige Nachteile auf. Sie werden in diesem einfachen Beispiel nicht wirklich angezeigt, aber es kann manchmal schwierig sein, Ihr Problem aufzuteilen, damit jeder Prozessor unabhängig arbeiten kann.
Viele Lösungen erfordern auch mehr Kommunikation zwischen den Prozessen. Dies kann zu einer gewissen Komplexität Ihrer Lösung führen, mit der sich ein nicht gleichzeitig ablaufendes Programm nicht befassen müsste.
Wann wird Parallelität verwendet?
Sie haben hier viel unternommen. Lassen Sie uns daher einige der wichtigsten Ideen überprüfen und dann einige Entscheidungspunkte erörtern, anhand derer Sie bestimmen können, welches Parallelitätsmodul Sie gegebenenfalls in Ihrem Projekt verwenden möchten.
Der erste Schritt dieses Prozesses besteht darin, zu entscheiden, ob Sieshouldein Parallelitätsmodul verwenden. Während die Beispiele hier jede der Bibliotheken ziemlich einfach aussehen lassen, ist die Parallelität immer mit einer zusätzlichen Komplexität verbunden und kann häufig zu Fehlern führen, die schwer zu finden sind.
Halten Sie das Hinzufügen von Parallelität so lange an, bis Sie ein bekanntes Leistungsproblem haben undthen bestimmen, welche Art von Parallelität Sie benötigen. WieDonald Knuth gesagt hat: "Vorzeitige Optimierung ist die Wurzel allen Übels (oder zumindest des größten Teils davon) in der Programmierung."
Sobald Sie sich entschieden haben, Ihr Programm zu optimieren, ist es ein guter nächster Schritt, herauszufinden, ob Ihr Programm CPU- oder E / A-gebunden ist. Denken Sie daran, dass E / A-gebundene Programme die meiste Zeit darauf warten, dass etwas passiert, während CPU-gebundene Programme ihre Zeit damit verbringen, Daten zu verarbeiten oder Zahlen so schnell wie möglich zu verarbeiten.
Wie Sie gesehen haben, profitieren CPU-gebundene Probleme nur durch die Verwendung vonmultiprocessing. threading undasyncio haben dieser Art von Problem überhaupt nicht geholfen.
Für E / A-gebundene Probleme gibt es in der Python-Community eine allgemeine Faustregel: „Verwenden Sieasyncio, wenn Sie können,threading, wenn Sie müssen.“ asyncio kann die beste Geschwindigkeit für diese Art von Programm bieten, aber manchmal benötigen Sie kritische Bibliotheken, die nicht portiert wurden, umasyncio zu nutzen. Denken Sie daran, dass jede Aufgabe, die die Kontrolle über die Ereignisschleife nicht aufgibt, alle anderen Aufgaben blockiert.
Fazit
Sie haben jetzt die grundlegenden Arten der Parallelität gesehen, die in Python verfügbar sind:
-
threading -
asyncio -
multiprocessing
Sie haben das Verständnis zu entscheiden, welche Parallelitätsmethode Sie für ein bestimmtes Problem verwenden sollten oder ob Sie überhaupt eine verwenden sollten! Darüber hinaus haben Sie ein besseres Verständnis für einige der Probleme erzielt, die bei der Verwendung von Parallelität auftreten können.
Ich hoffe, Sie haben viel aus diesem Artikel gelernt und finden eine gute Verwendung für die Parallelität in Ihren eigenen Projekten! Nehmen Sie unbedingt an unserem unten verlinkten Quiz „Python Concurrency“ teil, um Ihr Lernen zu überprüfen:
__ Take the Quiz: Testen Sie Ihr Wissen mit unserem interaktiven Quiz „Python Concurrency“. Nach Abschluss erhalten Sie eine Punktzahl, mit der Sie Ihren Lernfortschritt im Laufe der Zeit verfolgen können: