Python, Boto3 und AWS S3: Entmystifiziert
Amazon Web Services (AWS) hat sich zu einem führenden Anbieter von Cloud Computing entwickelt. Eine seiner Kernkomponenten ist S3, der von AWS angebotene Objektspeicherdienst. Mit seiner beeindruckenden Verfügbarkeit und Haltbarkeit ist es zum Standard für die Speicherung von Videos, Bildern und Daten geworden. Sie können S3 mit anderen Diensten kombinieren, um unendlich skalierbare Anwendungen zu erstellen.
Boto3 ist der Name des Python SDK für AWS. Sie können damit direkt AWS-Ressourcen in Ihren Python-Skripten erstellen, aktualisieren und löschen.
Wenn Sie zuvor AWS-Kenntnisse hatten, verfügen Sie über ein eigenes AWS-Konto und möchten Ihre Fähigkeiten auf die nächste Stufe heben, indem Sie AWS-Services in Ihrem Python-Code verwenden. Lesen Sie dann weiter.
Am Ende dieses Tutorials werden Sie:
-
Seien Sie sicher, dass Sie mit Buckets und Objekten direkt aus Ihren Python-Skripten arbeiten
-
Wissen, wie Sie häufige Fallstricke vermeiden, wenn Sie Boto3 und S3 verwenden
-
Verstehen Sie, wie Sie Ihre Daten von Anfang an einrichten, um später Leistungsprobleme zu vermeiden
-
Erfahren Sie, wie Sie Ihre Objekte so konfigurieren, dass die besten Funktionen von S3 genutzt werden
Bevor Sie die Eigenschaften von Boto3 untersuchen, erfahren Sie zunächst, wie Sie das SDK auf Ihrem Computer konfigurieren. Dieser Schritt bereitet Sie auf den Rest des Tutorials vor.
Free Bonus:5 Thoughts On Python Mastery, ein kostenloser Kurs für Python-Entwickler, der Ihnen die Roadmap und die Denkweise zeigt, die Sie benötigen, um Ihre Python-Fähigkeiten auf die nächste Stufe zu bringen.
Installation
Um Boto3 auf Ihrem Computer zu installieren, gehen Sie zu Ihrem Terminal und führen Sie Folgendes aus:
$ pip install boto3Sie haben das SDK. Sie können es derzeit jedoch nicht verwenden, da nicht bekannt ist, mit welchem AWS-Konto eine Verbindung hergestellt werden soll.
Damit es für Ihr AWS-Konto ausgeführt wird, müssen Sie einige gültige Anmeldeinformationen angeben. Wenn Sie bereits einen IAM-Benutzer haben, der über die vollständigen Berechtigungen für S3 verfügt, können Sie die Anmeldeinformationen dieses Benutzers (seinen Zugriffsschlüssel und seinen geheimen Zugriffsschlüssel) verwenden, ohne einen neuen Benutzer erstellen zu müssen. Andernfalls ist es am einfachsten, einen neuen AWS-Benutzer zu erstellen und dann die neuen Anmeldeinformationen zu speichern.
Um einen neuen Benutzer zu erstellen, gehen Sie zu Ihrem AWS-Konto, gehen Sie zuServices und wählen SieIAM aus. Wählen Sie dannUsers und klicken Sie aufAdd user.
Geben Sie dem Benutzer einen Namen (z. B.boto3user). Aktivieren Sieprogrammatic access. Dadurch wird sichergestellt, dass dieser Benutzer mit jedem von AWS unterstützten SDK arbeiten oder separate API-Aufrufe ausführen kann:
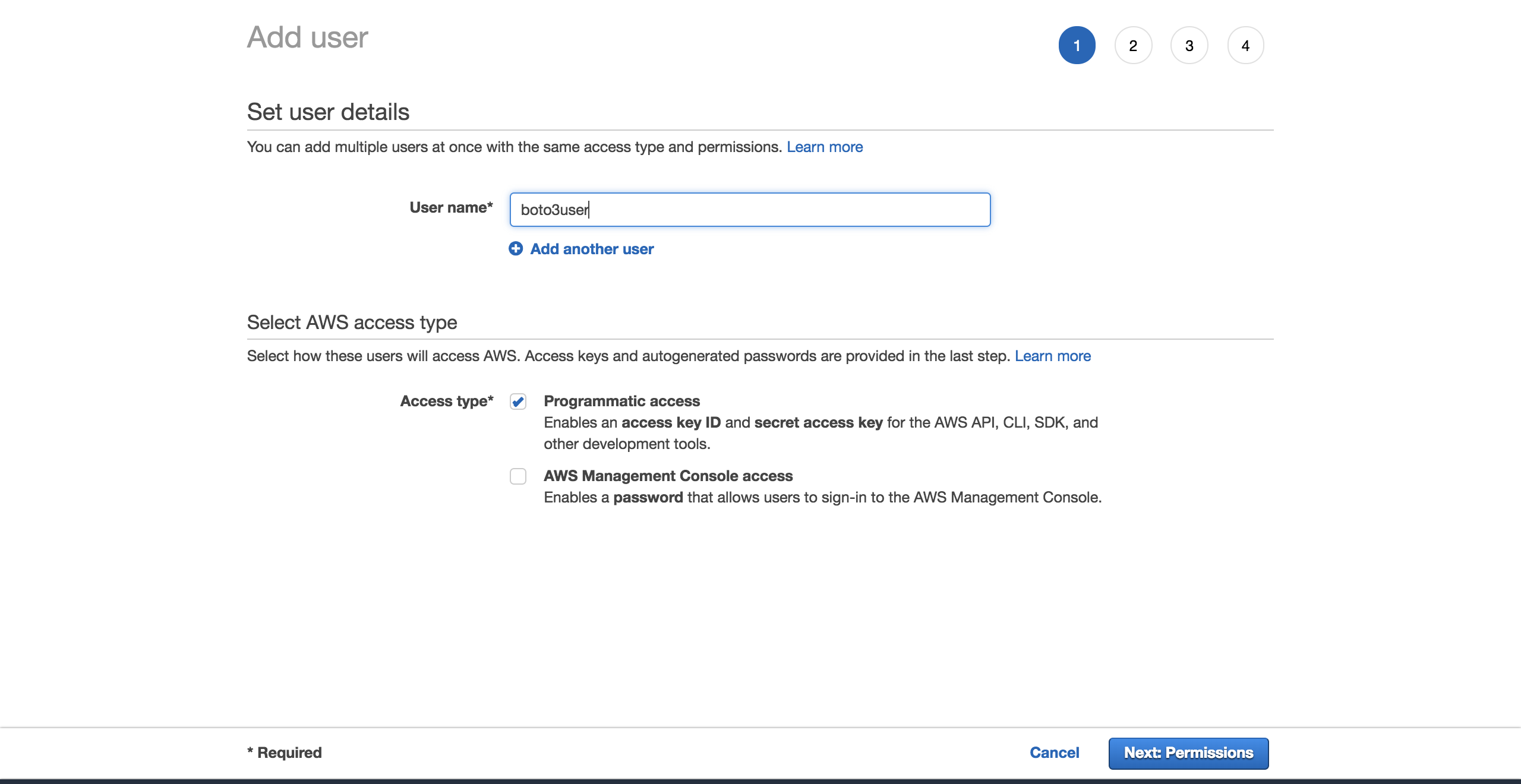
Um die Dinge einfach zu halten, wählen Sie die vorkonfigurierteAmazonS3FullAccess-Richtlinie. Mit dieser Richtlinie kann der neue Benutzer die volle Kontrolle über S3 haben. Klicken Sie aufNext: Review:
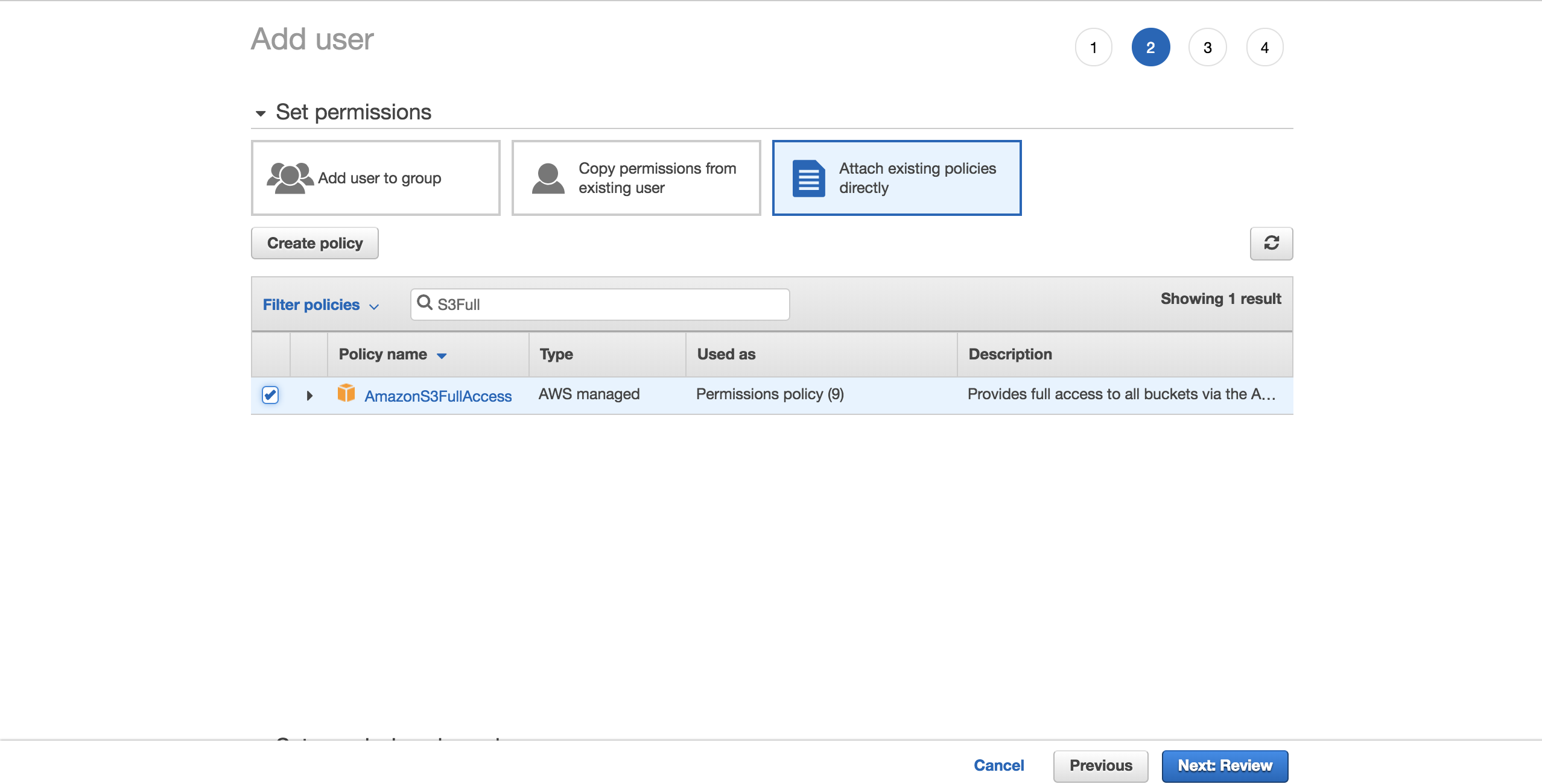
Wählen SieCreate user:
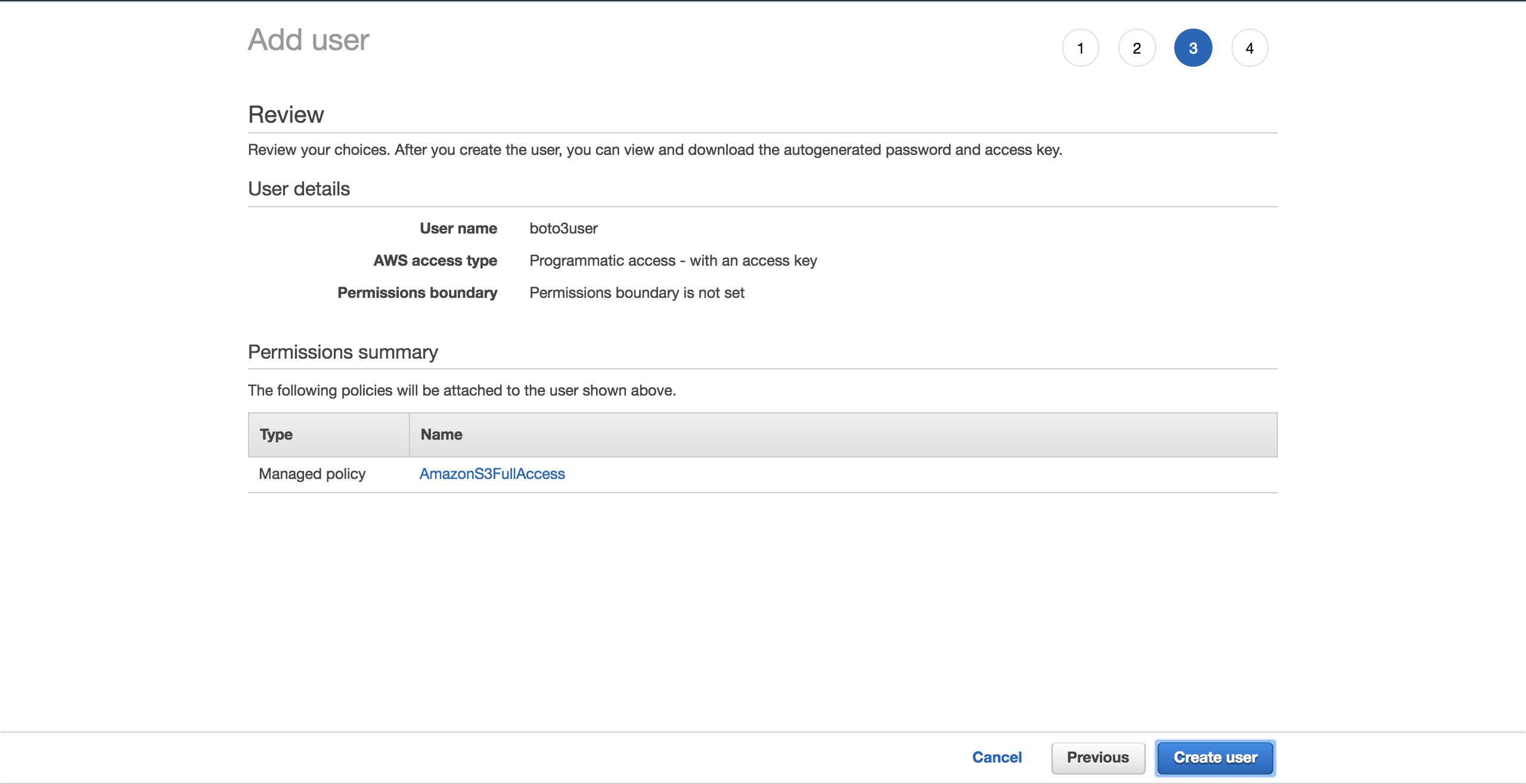
Ein neuer Bildschirm zeigt Ihnen die vom Benutzer generierten Anmeldeinformationen. Klicken Sie auf die SchaltflächeDownload .csv, um eine Kopie der Anmeldeinformationen zu erstellen. Sie benötigen sie, um Ihre Einrichtung abzuschließen.
Nachdem Sie Ihren neuen Benutzer haben, erstellen Sie eine neue Datei,~/.aws/credentials:
$ touch ~/.aws/credentialsÖffnen Sie die Datei und fügen Sie die folgende Struktur ein. Füllen Sie die Platzhalter mit den neuen Benutzeranmeldeinformationen aus, die Sie heruntergeladen haben:
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEYSpeicher die Datei.
Nachdem Sie diese Anmeldeinformationen eingerichtet haben, verfügen Sie über eindefault-Profil, das von Boto3 für die Interaktion mit Ihrem AWS-Konto verwendet wird.
Es muss noch eine weitere Konfiguration eingerichtet werden: die Standardregion, mit der Boto3 interagieren soll. Sie können diecomplete table of the supported AWS regions überprüfen. Wählen Sie die Region aus, die Ihnen am nächsten liegt. Kopieren Sie Ihre bevorzugte Region aus der SpalteRegion. In meinem Fall verwende icheu-west-1 (Irland).
Erstellen Sie eine neue Datei,~/.aws/config:
$ touch ~/.aws/configFügen Sie Folgendes hinzu und ersetzen Sie den Platzhalter durch dieregion, die Sie kopiert haben:
[default]
region = YOUR_PREFERRED_REGIONSpeichern Sie Ihre Datei.
Sie sind jetzt offiziell für den Rest des Tutorials eingerichtet.
Als Nächstes sehen Sie die verschiedenen Optionen, mit denen Sie mit Boto3 eine Verbindung zu S3 und anderen AWS-Diensten herstellen können.
Client versus Ressource
Im Kern ruft Boto3 lediglich AWS-APIs in Ihrem Namen auf. Für die meisten AWS-Services bietet Boto3 zwei verschiedene Möglichkeiten, auf diese abstrahierten APIs zuzugreifen:
-
Client: Low-Level-Servicezugriff
-
Resource: übergeordneter objektorientierter Servicezugriff
Sie können entweder verwenden, um mit S3 zu interagieren.
Um eine Verbindung zur Low-Level-Client-Schnittstelle herzustellen, müssen Sieclient()von Boto3 verwenden. Anschließend übergeben Sie den Namen des Dienstes, zu dem Sie eine Verbindung herstellen möchten. In diesem Falls3:
import boto3
s3_client = boto3.client('s3')Um eine Verbindung zur übergeordneten Schnittstelle herzustellen, verfolgen Sie einen ähnlichen Ansatz, verwenden jedochresource():
import boto3
s3_resource = boto3.resource('s3')Sie haben erfolgreich eine Verbindung zu beiden Versionen hergestellt, fragen sich jetzt jedoch möglicherweise: "Welche soll ich verwenden?"
Bei Kunden muss mehr programmatische Arbeit geleistet werden. Die Mehrheit der Client-Vorgänge gibt Ihnen einedictionaryAntwort. Um die genauen Informationen zu erhalten, die Sie benötigen, müssen Sie das Wörterbuch selbst analysieren. Mit Ressourcenmethoden erledigt das SDK das für Sie.
Beim Client können geringfügige Leistungsverbesserungen auftreten. Der Nachteil ist, dass Ihr Code weniger lesbar ist als bei Verwendung der Ressource. Ressourcen bieten eine bessere Abstraktion, und Ihr Code ist leichter zu verstehen.
Es ist auch wichtig zu verstehen, wie der Client und die Ressource generiert werden, wenn Sie überlegen, welche Sie auswählen sollen:
-
Boto3 generiert den Client aus einer JSON-Dienstdefinitionsdatei. Die Methoden des Clients unterstützen jede einzelne Art der Interaktion mit dem Ziel-AWS-Service.
-
Ressourcen hingegen werden aus JSON-Ressourcendefinitionsdateien generiert.
Boto3 generiert den Client und die Ressource aus verschiedenen Definitionen. Infolgedessen finden Sie möglicherweise Fälle, in denen eine vom Client unterstützte Operation von der Ressource nicht angeboten wird. Hier ist der interessante Teil: Sie müssen Ihren Code nicht ändern, um den Client überall zu verwenden. Für diesen Vorgang können Sie direkt über die Ressource auf den Client zugreifen:s3_resource.meta.client.
Eine solcheclient-Operation ist.generate_presigned_url(), mit der Sie Ihren Benutzern für einen festgelegten Zeitraum Zugriff auf ein Objekt in Ihrem Bucket gewähren können, ohne dass sie über AWS-Anmeldeinformationen verfügen müssen.
Gemeinsame Operationen
Nachdem Sie nun die Unterschiede zwischen Clients und Ressourcen kennen, können Sie damit einige neue S3-Komponenten erstellen.
Einen Eimer erstellen
Zu Beginn benötigen Sie S3bucket. Um einen programmgesteuert zu erstellen, müssen Sie zuerst einen Namen für Ihren Bucket auswählen. Beachten Sie, dass dieser Name auf der gesamten AWS-Plattform eindeutig sein muss, da Bucket-Namen DNS-kompatibel sind. Wenn Sie versuchen, einen Bucket zu erstellen, aber ein anderer Benutzer Ihren gewünschten Bucket-Namen bereits beansprucht hat, schlägt Ihr Code fehl. Anstelle von Erfolg wird der folgende Fehler angezeigt:botocore.errorfactory.BucketAlreadyExists.
Sie können Ihre Erfolgschancen beim Erstellen Ihres Buckets erhöhen, indem Sie einen zufälligen Namen auswählen. Sie können Ihre eigene Funktion generieren, die das für Sie erledigt. In dieser Implementierung werden Sie sehen, wie Sie mit dem Moduluuiddies erreichen können. Die Zeichenfolgendarstellung einer UUID4 ist 36 Zeichen lang (einschließlich Bindestriche). Sie können ein Präfix hinzufügen, um anzugeben, wofür die einzelnen Buckets bestimmt sind.
So können Sie das erreichen:
import uuid
def create_bucket_name(bucket_prefix):
# The generated bucket name must be between 3 and 63 chars long
return ''.join([bucket_prefix, str(uuid.uuid4())])Sie haben Ihren Bucket-Namen, aber jetzt müssen Sie noch eines beachten: Sofern sich Ihre Region nicht in den USA befindet, müssen Sie die Region beim Erstellen des Buckets explizit definieren. Andernfalls erhalten Sie einIllegalLocationConstraintException.
Sehen Sie sich den folgenden Code an, um zu veranschaulichen, was dies bedeutet, wenn Sie Ihren S3-Bucket in einer Region außerhalb der USA erstellen:
s3_resource.create_bucket(Bucket=YOUR_BUCKET_NAME,
CreateBucketConfiguration={
'LocationConstraint': 'eu-west-1'})Sie müssen sowohl einen Bucket-Namen als auch eine Bucket-Konfiguration angeben, in der Sie die Region angeben müssen, in meinem Falleu-west-1.
Dies ist nicht ideal. Stellen Sie sich vor, Sie möchten Ihren Code übernehmen und in der Cloud bereitstellen. Ihre Aufgabe wird immer schwieriger, da Sie die Region jetzt fest codiert haben. Sie könnten die Region umgestalten und in eine Umgebungsvariable umwandeln, aber dann müssten Sie noch etwas verwalten.
Glücklicherweise gibt es eine bessere Möglichkeit, die Region programmgesteuert abzurufen, indem Sie das Objektsessionnutzen. Boto3 erstellt diesession aus Ihren Anmeldeinformationen. Sie müssen nur die Region nehmen und sie alsLocationConstraint-Konfiguration ancreate_bucket() übergeben. So geht's:
def create_bucket(bucket_prefix, s3_connection):
session = boto3.session.Session()
current_region = session.region_name
bucket_name = create_bucket_name(bucket_prefix)
bucket_response = s3_connection.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={
'LocationConstraint': current_region})
print(bucket_name, current_region)
return bucket_name, bucket_responseDas Schöne daran ist, dass dieser Code unabhängig davon funktioniert, wo Sie ihn bereitstellen möchten: lokal / EC2 / Lambda. Außerdem müssen Sie Ihre Region nicht fest codieren.
Da sowohl der Client als auch die Ressource Buckets auf dieselbe Weise erstellen, können Sie eines als Parameters3_connectionübergeben.
Sie erstellen jetzt zwei Eimer. Erstellen Sie zuerst eine mit dem Client, der Ihnen diebucket_response als Wörterbuch zurückgibt:
>>>
>>> first_bucket_name, first_response = create_bucket(
... bucket_prefix='firstpythonbucket',
... s3_connection=s3_resource.meta.client)
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304 eu-west-1
>>> first_response
{'ResponseMetadata': {'RequestId': 'E1DCFE71EDE7C1EC', 'HostId': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amz-id-2': 'r3AP32NQk9dvbHSEPIbyYADT769VQEN/+xT2BPM6HCnuCb3Z/GhR2SBP+GM7IjcxbBN7SQ+k+9B=', 'x-amz-request-id': 'E1DCFE71EDE7C1EC', 'date': 'Fri, 05 Oct 2018 15:00:00 GMT', 'location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/', 'content-length': '0', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'Location': 'http://firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304.s3.amazonaws.com/'}Erstellen Sie dann mit der Ressource einen zweiten Bucket, der Ihnen eineBucket-Instanz alsbucket_response zurückgibt:
>>>
>>> second_bucket_name, second_response = create_bucket(
... bucket_prefix='secondpythonbucket', s3_connection=s3_resource)
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644 eu-west-1
>>> second_response
s3.Bucket(name='secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644')Du hast deine Eimer. Als Nächstes möchten Sie einige Dateien hinzufügen.
Benennen Sie Ihre Dateien
Sie können Ihre Objekte mithilfe der Standardkonventionen für die Benennung von Dateien benennen. Sie können einen beliebigen gültigen Namen verwenden. In diesem Artikel sehen Sie sich einen genaueren Fall an, der Ihnen hilft, die Funktionsweise von S3 unter der Haube zu verstehen.
Wenn Sie vorhaben, eine große Anzahl von Dateien in Ihrem S3-Bucket zu hosten, sollten Sie Folgendes beachten. Wenn alle Ihre Dateinamen ein deterministisches Präfix haben, das für jede Datei wiederholt wird, z. B. ein Zeitstempelformat wie „JJJJ-MM-TTThh: mm: ss“, werden Sie bald feststellen, dass Sie aufperformance issues stoßen wenn Sie versuchen, mit Ihrem Eimer zu interagieren.
Dies geschieht, weil S3 das Präfix der Datei nimmt und es einer Partition zuordnet. Je mehr Dateien Sie hinzufügen, desto mehr werden derselben Partition zugewiesen, und diese Partition ist sehr schwer und reagiert weniger schnell.
Was können Sie tun, um dies zu verhindern?
Die einfachste Lösung besteht darin, den Dateinamen zufällig zu sortieren. Sie können sich viele verschiedene Implementierungen vorstellen. In diesem Fall verwenden Sie jedoch das vertrauenswürdige Moduluuid, um dies zu unterstützen. Um das Lesen der Dateinamen für dieses Lernprogramm zu vereinfachen, nehmen Sie die ersten sechs Zeichen derhex-Darstellung der generierten Zahl und verknüpfen sie mit Ihrem Basisdateinamen.
Mit der folgenden Hilfsfunktion können Sie die Anzahl der Bytes, die die Datei haben soll, den Dateinamen und einen Beispielinhalt für die Datei übergeben, die wiederholt werden soll, um die gewünschte Dateigröße zu erhalten:
def create_temp_file(size, file_name, file_content):
random_file_name = ''.join([str(uuid.uuid4().hex[:6]), file_name])
with open(random_file_name, 'w') as f:
f.write(str(file_content) * size)
return random_file_nameErstellen Sie Ihre erste Datei, die Sie in Kürze verwenden werden:
first_file_name = create_temp_file(300, 'firstfile.txt', 'f')Durch Hinzufügen von Zufälligkeiten zu Ihren Dateinamen können Sie Ihre Daten effizient in Ihrem S3-Bucket verteilen.
Erstellen vonBucket- undObject-Instanzen
Der nächste Schritt nach dem Erstellen Ihrer Datei besteht darin, zu sehen, wie Sie sie in Ihren S3-Workflow integrieren können.
Hier spielen die Klassen der Ressource eine wichtige Rolle, da diese Abstraktionen die Arbeit mit S3 erleichtern.
Durch die Verwendung der Ressource haben Sie Zugriff auf die übergeordneten Klassen (Bucket undObject). So können Sie jeweils eines erstellen:
first_bucket = s3_resource.Bucket(name=first_bucket_name)
first_object = s3_resource.Object(
bucket_name=first_bucket_name, key=first_file_name)Der Grund, warum Sie beim Erstellen der Variablenfirst_objectkeine Fehler gesehen haben, ist, dass Boto3 AWS nicht aufruft, um die Referenz zu erstellen. Diebucket_name und diekey werden als Bezeichner bezeichnet und sind die notwendigen Parameter, um einObject zu erstellen. Jedes andere Attribut einesObject, wie z. B. seine Größe, wird träge geladen. Dies bedeutet, dass Boto3, um die angeforderten Attribute zu erhalten, AWS aufrufen muss.
Unterressourcen verstehen
Bucket undObject sind Unterressourcen voneinander. Unterressourcen sind Methoden, die eine neue Instanz einer untergeordneten Ressource erstellen. Die Bezeichner der Eltern werden an die untergeordnete Ressource übergeben.
Wenn Sie eineBucket-Variable haben, können Sie direkt eineObject erstellen:
first_object_again = first_bucket.Object(first_file_name)Oder wenn Sie eineObject-Variable haben, können Sie dieBucket erhalten:
first_bucket_again = first_object.Bucket()Gut, Sie verstehen jetzt, wie man einBucket und einObject erzeugt. Als Nächstes können Sie Ihre neu generierte Datei mithilfe dieser Konstrukte in S3 hochladen.
Hochladen einer Datei
Es gibt drei Möglichkeiten, eine Datei hochzuladen:
-
Aus einer
ObjectInstanz -
Aus einer
BucketInstanz -
Aus den
client
In jedem Fall müssen SieFilename angeben. Dies ist der Pfad der Datei, die Sie hochladen möchten. Sie werden nun die drei Alternativen untersuchen. Wählen Sie aus, was Ihnen am besten gefällt, um diefirst_file_name in S3 hochzuladen.
Objektinstanzversion
Sie können mit einerObject-Instanz hochladen:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
Filename=first_file_name)Oder Sie können die Instanz vonfirst_objectverwenden:
first_object.upload_file(first_file_name)Bucket Instance Version
So können Sie mit einerBucket-Instanz hochladen:
s3_resource.Bucket(first_bucket_name).upload_file(
Filename=first_file_name, Key=first_file_name)Client-Version
Sie können auch mitclient hochladen:
s3_resource.meta.client.upload_file(
Filename=first_file_name, Bucket=first_bucket_name,
Key=first_file_name)Sie haben Ihre Datei mit einer der drei verfügbaren Methoden erfolgreich in S3 hochgeladen. In den nächsten Abschnitten werden Sie hauptsächlich mit der KlasseObjectarbeiten, da die Operationen zwischen den Versionenclient undBucketehr ähnlich sind.
Herunterladen einer Datei
Um eine Datei lokal von S3 herunterzuladen, führen Sie ähnliche Schritte aus wie beim Hochladen. In diesem Fall wird der ParameterFilenamejedoch Ihrem gewünschten lokalen Pfad zugeordnet. Dieses Mal wird die Datei in das Verzeichnistmpheruntergeladen:
s3_resource.Object(first_bucket_name, first_file_name).download_file(
f'/tmp/{first_file_name}') # Python 3.6+Sie haben Ihre Datei erfolgreich von S3 heruntergeladen. Als Nächstes erfahren Sie, wie Sie dieselbe Datei mit einem einzigen API-Aufruf zwischen Ihre S3-Buckets kopieren.
Kopieren eines Objekts zwischen Buckets
Wenn Sie Dateien von einem Bucket in einen anderen kopieren müssen, bietet Ihnen Boto3 diese Möglichkeit. In diesem Beispiel kopieren Sie die Datei mit.copy() vom ersten Bucket in den zweiten:
def copy_to_bucket(bucket_from_name, bucket_to_name, file_name):
copy_source = {
'Bucket': bucket_from_name,
'Key': file_name
}
s3_resource.Object(bucket_to_name, file_name).copy(copy_source)
copy_to_bucket(first_bucket_name, second_bucket_name, first_file_name)Note: Wenn Sie Ihre S3-Objekte in einen Bucket in einer anderen Region replizieren möchten, sehen Sie sichCross Region Replication an.
Objekt löschen
Löschen Sie die neue Datei aus dem zweiten Bucket, indem Sie.delete() für die entsprechende Instanz vonObjectaufrufen:
s3_resource.Object(second_bucket_name, first_file_name).delete()Sie haben jetzt gesehen, wie Sie die Kernoperationen von S3 verwenden. Sie sind bereit, Ihr Wissen in den kommenden Abschnitten mit komplexeren Merkmalen auf die nächste Stufe zu heben.
Erweiterte Konfigurationen
In diesem Abschnitt werden Sie ausführlichere S3-Funktionen untersuchen. Sie sehen Beispiele für deren Verwendung und die Vorteile, die sie für Ihre Anwendungen haben können.
ACL (Zugriffssteuerungslisten)
Mithilfe von Zugriffssteuerungslisten (Access Control Lists, ACLs) können Sie den Zugriff auf Ihre Buckets und die darin enthaltenen Objekte verwalten. Sie gelten als die bisherige Methode zum Verwalten von Berechtigungen für S3. Warum sollten Sie über sie wissen? Wenn Sie den Zugriff auf einzelne Objekte verwalten müssen, verwenden Sie eine Objekt-ACL.
Wenn Sie ein Objekt in S3 hochladen, ist dieses Objekt standardmäßig privat. Wenn Sie dieses Objekt einer anderen Person zur Verfügung stellen möchten, können Sie festlegen, dass die ACL des Objekts zum Zeitpunkt der Erstellung öffentlich ist. So laden Sie eine neue Datei in den Bucket hoch und machen sie für alle zugänglich:
second_file_name = create_temp_file(400, 'secondfile.txt', 's')
second_object = s3_resource.Object(first_bucket.name, second_file_name)
second_object.upload_file(second_file_name, ExtraArgs={
'ACL': 'public-read'})Sie können die InstanzObjectAclvonObject abrufen, da es sich um eine der Unterressourcenklassen handelt:
second_object_acl = second_object.Acl()Verwenden Sie das Attributgrants, um zu sehen, wer Zugriff auf Ihr Objekt hat:
>>>
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}, {'Grantee': {'Type': 'Group', 'URI': 'http://acs.amazonaws.com/groups/global/AllUsers'}, 'Permission': 'READ'}]Sie können Ihr Objekt wieder privat machen, ohne es erneut hochladen zu müssen:
>>>
>>> response = second_object_acl.put(ACL='private')
>>> second_object_acl.grants
[{'Grantee': {'DisplayName': 'name', 'ID': '24aafdc2053d49629733ff0141fc9fede3bf77c7669e4fa2a4a861dd5678f4b5', 'Type': 'CanonicalUser'}, 'Permission': 'FULL_CONTROL'}]Sie haben gesehen, wie Sie ACLs verwenden können, um den Zugriff auf einzelne Objekte zu verwalten. Als Nächstes sehen Sie, wie Sie Ihren Objekten mithilfe der Verschlüsselung eine zusätzliche Sicherheitsebene hinzufügen können.
Note: Wenn Sie Ihre Daten in mehrere Kategorien aufteilen möchten, sehen Sie sichtags an. Sie können den Objekten basierend auf ihren Tags Zugriff gewähren.
Verschlüsselung
Mit S3 können Sie Ihre Daten durch Verschlüsselung schützen. Sie untersuchen die serverseitige Verschlüsselung mithilfe des AES-256-Algorithmus, bei dem AWS sowohl die Verschlüsselung als auch die Schlüssel verwaltet.
Erstellen Sie eine neue Datei und laden Sie sie mitServerSideEncryption hoch:
third_file_name = create_temp_file(300, 'thirdfile.txt', 't')
third_object = s3_resource.Object(first_bucket_name, third_file_name)
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256'})Sie können den Algorithmus überprüfen, der zum Verschlüsseln der Datei verwendet wurde, in diesem FallAES256:
>>>
>>> third_object.server_side_encryption
'AES256'Sie wissen jetzt, wie Sie Ihren Objekten mithilfe des von AWS angebotenen serverseitigen Verschlüsselungsalgorithmus AES-256 eine zusätzliche Schutzschicht hinzufügen können.
Lager
Jedes Objekt, das Sie Ihrem S3-Bucket hinzufügen, ist mit einemstorage class verknüpft. Alle verfügbaren Speicherklassen bieten eine hohe Haltbarkeit. Sie legen fest, wie Sie Ihre Objekte basierend auf den Leistungszugriffsanforderungen Ihrer Anwendung speichern möchten.
Derzeit können Sie mit S3 die folgenden Speicherklassen verwenden:
-
STANDARD: Standard für Daten, auf die häufig zugegriffen wird
-
STANDARD_IA: für selten verwendete Daten, die auf Anfrage schnell abgerufen werden müssen
-
ONEZONE_IA: Für denselben Anwendungsfall wie STANDARD_IA, speichert die Daten jedoch in einer Verfügbarkeitszone anstelle von drei
-
REDUCED_REDUNDANCY: für häufig verwendete unkritische Daten, die leicht reproduzierbar sind
Wenn Sie die Speicherklasse eines vorhandenen Objekts ändern möchten, müssen Sie das Objekt neu erstellen.
Laden Sie beispielsweisethird_object erneut hoch und setzen Sie die Speicherklasse aufStandard_IA:
third_object.upload_file(third_file_name, ExtraArgs={
'ServerSideEncryption': 'AES256',
'StorageClass': 'STANDARD_IA'})Note: Wenn Sie Änderungen an Ihrem Objekt vornehmen, werden Sie möglicherweise feststellen, dass Ihre lokale Instanz diese nicht anzeigt. Zu diesem Zeitpunkt müssen Sie.reload() aufrufen, um die neueste Version Ihres Objekts abzurufen.
Laden Sie das Objekt neu, und Sie können die neue Speicherklasse sehen:
>>>
>>> third_object.reload()
>>> third_object.storage_class
'STANDARD_IA'Note: Verwenden SieLifeCycle Configurations, um Objekte durch die verschiedenen Klassen zu wechseln, wenn Sie feststellen, dass sie benötigt werden. Sie werden diese Objekte automatisch für Sie übertragen.
Versionierung
Sie sollten die Versionierung verwenden, um Ihre Objekte im Laufe der Zeit vollständig aufzuzeichnen. Es dient auch als Schutzmechanismus gegen versehentliches Löschen Ihrer Objekte. Wenn Sie ein versioniertes Objekt anfordern, ruft Boto3 die neueste Version ab.
Wenn Sie eine neue Version eines Objekts hinzufügen, ist der Speicher, den das Objekt insgesamt belegt, die Summe der Größe seiner Versionen. Wenn Sie also ein Objekt mit 1 GB speichern und 10 Versionen erstellen, müssen Sie für 10 GB Speicher bezahlen.
Aktivieren Sie die Versionierung für den ersten Bucket. Dazu müssen Sie die KlasseBucketVersioningverwenden:
def enable_bucket_versioning(bucket_name):
bkt_versioning = s3_resource.BucketVersioning(bucket_name)
bkt_versioning.enable()
print(bkt_versioning.status)>>>
>>> enable_bucket_versioning(first_bucket_name)
EnabledErstellen Sie dann zwei neue Versionen für die erste DateiObject, eine mit dem Inhalt der Originaldatei und eine mit dem Inhalt der dritten Datei:
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
first_file_name)
s3_resource.Object(first_bucket_name, first_file_name).upload_file(
third_file_name)Laden Sie nun die zweite Datei erneut hoch, wodurch eine neue Version erstellt wird:
s3_resource.Object(first_bucket_name, second_file_name).upload_file(
second_file_name)Sie können die neueste verfügbare Version Ihrer Objekte wie folgt abrufen:
>>>
>>> s3_resource.Object(first_bucket_name, first_file_name).version_id
'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'In diesem Abschnitt haben Sie gesehen, wie Sie mit einigen der wichtigsten S3-Attribute arbeiten und sie Ihren Objekten hinzufügen. Als Nächstes erfahren Sie, wie Sie Ihre Eimer und Objekte problemlos durchqueren können.
Durchquerungen
Wenn Sie Informationen von all Ihren S3-Ressourcen abrufen oder eine Operation auf diese anwenden müssen, bietet Ihnen Boto3 verschiedene Möglichkeiten, Ihre Buckets und Objekte iterativ zu durchlaufen. Zunächst durchlaufen Sie alle erstellten Eimer.
Bucket Traversal
Um alle Buckets in Ihrem Konto zu durchlaufen, können Sie dasbuckets-Attribut der Ressource neben.all() verwenden, wodurch Sie die vollständige Liste derBucket-Instanzen erhalten:
>>>
>>> for bucket in s3_resource.buckets.all():
... print(bucket.name)
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Sie können auchclient verwenden, um die Bucket-Informationen abzurufen. Der Code ist jedoch komplexer, da Sie ihn aus dem Wörterbuch extrahieren müssen, dasclient zurückgibt:
>>>
>>> for bucket_dict in s3_resource.meta.client.list_buckets().get('Buckets'):
... print(bucket_dict['Name'])
...
firstpythonbucket7250e773-c4b1-422a-b51f-c45a52af9304
secondpythonbucket2d5d99c5-ab96-4c30-b7f7-443a95f72644Sie haben gesehen, wie Sie die Eimer in Ihrem Konto durchlaufen können. Im nächsten Abschnitt wählen Sie einen Ihrer Buckets aus und zeigen iterativ die darin enthaltenen Objekte an.
Objektdurchquerung
Wenn Sie alle Objekte aus einem Bucket auflisten möchten, generiert der folgende Code einen Iterator für Sie:
>>>
>>> for obj in first_bucket.objects.all():
... print(obj.key)
...
127367firstfile.txt
616abesecondfile.txt
fb937cthirdfile.txtDie Variableobj istObjectSummary. Dies ist eine einfache Darstellung vonObject. Die Zusammenfassungsversion unterstützt nicht alle Attribute vonObject. Wenn Sie darauf zugreifen müssen, verwenden Sie die UnterressourceObject(), um einen neuen Verweis auf den zugrunde liegenden gespeicherten Schlüssel zu erstellen. Dann können Sie die fehlenden Attribute extrahieren:
>>>
>>> for obj in first_bucket.objects.all():
... subsrc = obj.Object()
... print(obj.key, obj.storage_class, obj.last_modified,
... subsrc.version_id, subsrc.metadata)
...
127367firstfile.txt STANDARD 2018-10-05 15:09:46+00:00 eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv {}
616abesecondfile.txt STANDARD 2018-10-05 15:09:47+00:00 WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6 {}
fb937cthirdfile.txt STANDARD_IA 2018-10-05 15:09:05+00:00 null {}Sie können jetzt iterativ Operationen an Ihren Buckets und Objekten ausführen. Du bist fast fertig. Zu diesem Zeitpunkt sollten Sie noch eines wissen: Löschen aller in diesem Lernprogramm erstellten Ressourcen.
Löschen von Buckets und Objekten
Um alle von Ihnen erstellten Buckets und Objekte zu entfernen, müssen Sie zunächst sicherstellen, dass sich in Ihren Buckets keine Objekte befinden.
Löschen eines nicht leeren Buckets
Um einen Bucket löschen zu können, müssen Sie zuerst jedes einzelne Objekt im Bucket löschen. Andernfalls wird die Ausnahme vonBucketNotEmptyausgelöst. Wenn Sie einen versionierten Bucket haben, müssen Sie jedes Objekt und alle seine Versionen löschen.
Wenn Sie feststellen, dass eine LifeCycle-Regel, die dies automatisch für Sie erledigt, nicht Ihren Anforderungen entspricht, können Sie die Objekte folgendermaßen programmgesteuert löschen:
def delete_all_objects(bucket_name):
res = []
bucket=s3_resource.Bucket(bucket_name)
for obj_version in bucket.object_versions.all():
res.append({'Key': obj_version.object_key,
'VersionId': obj_version.id})
print(res)
bucket.delete_objects(Delete={'Objects': res})Der obige Code funktioniert unabhängig davon, ob Sie die Versionierung für Ihren Bucket aktiviert haben oder nicht. Wenn Sie dies nicht tun, ist die Version der Objekte null. Sie können bis zu 1000 Löschvorgänge in einem API-Aufruf stapeln, indem Sie.delete_objects() auf IhrerBucket-Instanz verwenden. Dies ist kostengünstiger als das individuelle Löschen jedes Objekts.
Führen Sie die neue Funktion für den ersten Bucket aus, um alle versionierten Objekte zu entfernen:
>>>
>>> delete_all_objects(first_bucket_name)
[{'Key': '127367firstfile.txt', 'VersionId': 'eQgH6IC1VGcn7eXZ_.ayqm6NdjjhOADv'}, {'Key': '127367firstfile.txt', 'VersionId': 'UnQTaps14o3c1xdzh09Cyqg_hq4SjB53'}, {'Key': '127367firstfile.txt', 'VersionId': 'null'}, {'Key': '616abesecondfile.txt', 'VersionId': 'WIaExRLmoksJzLhN7jU5YzoJxYSu6Ey6'}, {'Key': '616abesecondfile.txt', 'VersionId': 'null'}, {'Key': 'fb937cthirdfile.txt', 'VersionId': 'null'}]Als letzten Test können Sie eine Datei in den zweiten Bucket hochladen. In diesem Bucket ist die Versionierung nicht aktiviert. Daher ist die Version null. Wenden Sie dieselbe Funktion an, um den Inhalt zu entfernen:
>>>
>>> s3_resource.Object(second_bucket_name, first_file_name).upload_file(
... first_file_name)
>>> delete_all_objects(second_bucket_name)
[{'Key': '9c8b44firstfile.txt', 'VersionId': 'null'}]Sie haben erfolgreich alle Objekte aus Ihren beiden Eimern entfernt. Sie können jetzt die Buckets löschen.
Buckets löschen
Zum Abschluss verwenden Sie.delete() auf IhrerBucket-Instanz, um den ersten Bucket zu entfernen:
s3_resource.Bucket(first_bucket_name).delete()Wenn Sie möchten, können Sie den zweiten Bucket mit der Versioncliententfernen:
s3_resource.meta.client.delete_bucket(Bucket=second_bucket_name)Beide Vorgänge waren erfolgreich, da Sie jeden Bucket geleert haben, bevor Sie versucht haben, ihn zu löschen.
Sie führen jetzt einige der wichtigsten Vorgänge aus, die Sie mit S3 und Boto3 ausführen können. Herzlichen Glückwunsch zum Weiterkommen! Lassen Sie uns als Bonus einige der Vorteile der Verwaltung von S3-Ressourcen mit Infrastruktur als Code untersuchen.
Python-Code oder Infrastruktur als Code (IaC)?
Wie Sie gesehen haben, hatten die meisten Interaktionen mit S3 in diesem Lernprogramm mit Objekten zu tun. Sie haben nicht viele Bucket-bezogene Vorgänge gesehen, z. B. das Hinzufügen von Richtlinien zum Bucket, das Hinzufügen einer LifeCycle-Regel zum Übertragen Ihrer Objekte durch die Speicherklassen, das Archivieren in Glacier oder das vollständige Löschen oder das Erzwingen der Verschlüsselung aller Objekte durch Konfigurieren von Bucket Verschlüsselung.
Die manuelle Verwaltung des Status Ihrer Buckets über die Clients oder Ressourcen von Boto3 wird immer schwieriger, da Ihre Anwendung weitere Dienste hinzufügt und komplexer wird. Um Ihre Infrastruktur gemeinsam mit Boto3 zu überwachen, sollten Sie ein IaC-Tool (Infrastructure as Code) wie CloudFormation oder Terraform verwenden, um die Infrastruktur Ihrer Anwendung zu verwalten. Mit einem dieser Tools wird der Status Ihrer Infrastruktur beibehalten und Sie über die von Ihnen vorgenommenen Änderungen informiert.
Wenn Sie sich für diesen Weg entscheiden, beachten Sie Folgendes:
-
Jede Bucket-bezogene Operation, die den Bucket in irgendeiner Weise modifiziert, sollte über IaC erfolgen.
-
Wenn Sie möchten, dass alle Ihre Objekte auf dieselbe Weise funktionieren (z. B. alle verschlüsselt oder alle öffentlich), gibt es normalerweise eine Möglichkeit, dies direkt über IaC zu tun, indem Sie eine Bucket-Richtlinie oder eine bestimmte Bucket-Eigenschaft hinzufügen.
-
Bucket-Lesevorgänge, z. B. das Durchlaufen des Inhalts eines Buckets, sollten mit Boto3 durchgeführt werden.
-
Objektbezogene Operationen auf individueller Objektebene sollten mit Boto3 durchgeführt werden.
Fazit
Herzlichen Glückwunsch zum Ende dieses Tutorials!
Sie können jetzt programmgesteuert mit S3 arbeiten. Sie wissen jetzt, wie Sie Objekte erstellen, in S3 hochladen, deren Inhalt herunterladen und ihre Attribute direkt aus Ihrem Skript ändern können, während Sie mit Boto3 häufige Fallstricke vermeiden.
Möge dieses Tutorial ein Sprungbrett auf Ihrem Weg sein, mit AWS etwas Großartiges aufzubauen!
Weitere Lektüre
Wenn Sie mehr erfahren möchten, lesen Sie Folgendes: