Erste Schritte mit PySpark und Big Data Processing
Es kommt immer häufiger vor, dass Situationen auftreten, in denen die Datenmenge einfach zu groß ist, um auf einem einzelnen Computer verarbeitet zu werden. Glücklicherweise wurden Technologien wie Apache Spark, Hadoop und andere entwickelt, um genau dieses Problem zu lösen. Die Leistung dieser Systeme kann mit PySpark direkt von Python aus genutzt werden!
Die effiziente Verarbeitung von Datensätzen mit Gigabyte und mehr beträgtwell within the reach of any Python developer, unabhängig davon, ob Sie Datenwissenschaftler, Webentwickler oder etwas dazwischen sind.
In diesem Tutorial lernen Sie:
-
Welche Python-Konzepte können auf Big Data angewendet werden?
-
Verwendung von Apache Spark und PySpark
-
So schreiben Sie grundlegende PySpark-Programme
-
So führen Sie PySpark-Programme lokal auf kleinen Datenmengen aus
-
Wie geht es weiter, um Ihre PySpark-Kenntnisse auf ein verteiltes System zu übertragen?
Free Bonus:Click here to get access to a chapter from Python Tricks: The Book zeigt Ihnen die Best Practices von Python anhand einfacher Beispiele, die Sie sofort anwenden können, um schöneren + Pythonic-Code zu schreiben.
Big Data-Konzepte in Python
Trotz seiner Beliebtheit alsjust ascripting language macht Python mehrereprogramming paradigms wiearray-oriented programming,object-oriented programming,asynchronous programming und viele andere verfügbar. Ein Paradigma, das für angehende Big-Data-Profis von besonderem Interesse ist, istfunctional programming.
Funktionale Programmierung ist ein gängiges Paradigma, wenn Sie mit Big Data arbeiten. Das funktionale Schreiben ergibt den Code vonembarrassingly parallel. Dies bedeutet, dass es einfacher ist, Ihren Code auf mehreren CPUs oder sogar auf ganz anderen Computern auszuführen. Sie können die physischen Speicher- und CPU-Einschränkungen einer einzelnen Workstation umgehen, indem Sie auf mehreren Systemen gleichzeitig ausgeführt werden.
Dies ist die Stärke des PySpark-Ökosystems, mit dem Sie Funktionscode verwenden und automatisch auf einen gesamten Computercluster verteilen können.
Zum Glück für Python-Programmierer sind viele der Kernideen der funktionalen Programmierung in der Standardbibliothek und den integrierten Funktionen von Python verfügbar. Sie können viele der für die Big Data-Verarbeitung erforderlichen Konzepte kennenlernen, ohne jemals den Komfort von Python zu verlassen.
Die Kernidee der funktionalen Programmierung besteht darin, dass Daten durch Funktionen manipuliert werden sollten, ohne einen externen Zustand beizubehalten. Dies bedeutet, dass Ihr Code globale Variablen vermeidet und immernew data zurückgibt, anstatt die Daten direkt zu bearbeiten.
Eine weitere gängige Idee in der funktionalen Programmierung istanonymous functions. Python macht anonyme Funktionen mit dem Schlüsselwortlambdaverfügbar, nicht zu verwechseln mitAWS Lambda functions.
Nachdem Sie einige der Begriffe und Konzepte kennen, können Sie untersuchen, wie sich diese Ideen im Python-Ökosystem manifestieren.
Lambda-Funktionen
lambda functions in Python werden inline definiert und sind auf einen einzelnen Ausdruck beschränkt. Sie haben wahrscheinlichlambda Funktionen gesehen, wenn Sie die integriertesorted() Funktion verwenden:
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(sorted(x))
['Python', 'awesome!', 'is', 'programming']
>>> print(sorted(x, key=lambda arg: arg.lower()))
['awesome!', 'is', 'programming', 'Python']Der Parameterkey bissorted wird für jedes Element initerable aufgerufen. Dies macht die Sortierung unabhängig von Groß- und Kleinschreibung, indem alle Zeichenfolgen in Kleinbuchstabenbeforegeändert werden, wenn die Sortierung stattfindet.
Dies ist ein häufiger Anwendungsfall fürlambda-Funktionen, kleine anonyme Funktionen, die keinen externen Status beibehalten.
In Python gibt es auch andere gängige funktionale Programmierfunktionen wiefilter(),map() undreduce(). Alle diese Funktionen können auf ähnliche Weiselambda Funktionen oder Standardfunktionen verwenden, die mitdef definiert sind.
filter(),map() undreduce()
Die integrierten Funktionenfilter(),map() undreduce() sind in der Funktionsprogrammierung alle üblich. Sie werden bald feststellen, dass diese Konzepte einen erheblichen Teil der Funktionalität eines PySpark-Programms ausmachen können.
Es ist wichtig, diese Funktionen in einem zentralen Python-Kontext zu verstehen. Anschließend können Sie dieses Wissen in PySpark-Programme und die Spark-API übersetzen.
filter() filtert Elemente aus einer Iterable basierend auf einer Bedingung heraus, die normalerweise alslambda-Funktion ausgedrückt wird:
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(filter(lambda arg: len(arg) < 8, x)))
['Python', 'is']filter() nimmt eine Iterable, ruft die Funktionlambda für jedes Element auf und gibt die Elemente zurück, bei denenlambdaTrue zurückgegeben hat.
Note: Der Aufruf vonlist() ist erforderlich, dafilter() ebenfalls iterierbar ist. filter() gibt Ihnen nur die Werte an, wenn Sie sie durchlaufen. list() zwingt alle Elemente gleichzeitig in den Speicher, anstatt eine Schleife verwenden zu müssen.
Sie können sich vorstellen,filter() zu verwenden, um ein allgemeinesfor-Schleifenmuster wie das folgende zu ersetzen:
def is_less_than_8_characters(item):
return len(item) < 8
x = ['Python', 'programming', 'is', 'awesome!']
results = []
for item in x:
if is_less_than_8_characters(item):
results.append(item)
print(results)Dieser Code sammelt alle Zeichenfolgen mit weniger als 8 Zeichen. Der Code ist ausführlicher als das Beispiel vonfilter(), führt jedoch dieselbe Funktion mit denselben Ergebnissen aus.
Ein weiterer weniger offensichtlicher Vorteil vonfilter() ist, dass es eine iterable zurückgibt. Dies bedeutet, dassfilter() nicht erfordert, dass Ihr Computer über genügend Speicher verfügt, um alle Elemente in der Iterable gleichzeitig zu speichern. Dies wird bei Big Data-Sets immer wichtiger, die schnell mehrere Gigabyte groß werden können.
map() istfilter() insofern ähnlich, als es eine Funktion auf jedes Element in einer Iterable anwendet, aber immer eine 1-zu-1-Zuordnung der ursprünglichen Elemente erzeugt. Die iterablenew, diemap() zurückgibt, hat immer die gleiche Anzahl von Elementen wie die ursprüngliche iterable, was beifilter() nicht der Fall war:
>>>
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(list(map(lambda arg: arg.upper(), x)))
['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']map() ruft automatisch die Funktionlambda für alle Elemente auf und ersetzt effektiv einefor-Schleife wie folgt:
results = []
x = ['Python', 'programming', 'is', 'awesome!']
for item in x:
results.append(item.upper())
print(results)Diefor-Schleife hat das gleiche Ergebnis wie dasmap()-Beispiel, bei dem alle Elemente in Großbuchstaben erfasst werden. Wie im Beispiel vonfilter()gibtmap() jedoch eine Iterierbarkeit zurück, die es wiederum ermöglicht, große Datenmengen zu verarbeiten, die zu groß sind, um vollständig in den Speicher zu passen.
Schließlich ist das letzte funktionale Trio in der Python-Standardbibliothekreduce(). Wie beifilter() undmap() wendet "redu ()" eine Funktion auf Elemente in einer Iterable an.
Auch hier kann die angewendete Funktion eine Standard-Python-Funktion sein, die mit dem Schlüsselwortdefoder einer Funktionlambdaerstellt wurde.
reduce() gibt jedoch keine neue Iterable zurück. Stattdessen verwendetreduce() die aufgerufene Funktion, um die Iterierbarkeit auf einen einzelnen Wert zu reduzieren:
>>>
>>> from functools import reduce
>>> x = ['Python', 'programming', 'is', 'awesome!']
>>> print(reduce(lambda val1, val2: val1 + val2, x))
Pythonprogrammingisawesome!Dieser Code kombiniert alle Elemente in der Iterable von links nach rechts zu einem einzigen Element. list() wird hier nicht aufgerufen, dareduce() bereits ein einzelnes Element zurückgibt.
Note: Python 3.x hat die integriertereduce()-Funktion in dasfunctools-Paket verschoben.
lambda,map(),filter() undreduce() sind Konzepte, die in vielen Sprachen existieren und in regulären Python-Programmen verwendet werden können. Bald werden Sie sehen, dass sich diese Konzepte auf die PySpark-API erstrecken, um große Datenmengen zu verarbeiten.
Sets
Sets sind eine weitere häufig verwendete Funktionalität, die in Standard-Python vorhanden ist und in der Big Data-Verarbeitung sehr nützlich ist. Sets sind Listen sehr ähnlich, außer dass sie keine Reihenfolge haben und keine doppelten Werte enthalten können. Sie können sich ein Set vorstellen, das den Schlüsseln in einem Python-Diktat ähnlich ist.
Hallo Welt im PySpark
Wie in jedem guten Programmier-Tutorial möchten Sie mit einemHello World-Beispiel beginnen. Unten ist das PySpark-Äquivalent:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Mach dir noch keine Sorgen um alle Details. Die Hauptidee ist, sich vor Augen zu halten, dass sich ein PySpark-Programm nicht wesentlich von einem normalen Python-Programm unterscheidet.
Note: Dieses Programm löst wahrscheinlich einException auf Ihrem System aus, wenn Sie PySpark noch nicht installiert haben oder nicht über die angegebenecopyright-Datei verfügen später.
Sie werden bald alle Details dieses Programms erfahren, aber schauen Sie genau hin. Das Programm zählt die Gesamtzahl der Zeilen und die Anzahl der Zeilen mit dem Wortpython in einer Datei mit dem Namencopyright.
Denken Sie daran,a PySpark program isn’t that much different from a regular Python program, aberexecution model can be very different aus einem regulären Python-Programm, insbesondere wenn Sie in einem Cluster ausgeführt werden.
Hinter den Kulissen kann eine Menge passieren, die die Verarbeitung auf mehrere Knoten verteilt, wenn Sie sich in einem Cluster befinden. Stellen Sie sich das Programm jedoch vorerst als Python-Programm vor, das die PySpark-Bibliothek verwendet.
Nachdem Sie einige gängige Funktionskonzepte in Python sowie ein einfaches PySpark-Programm kennengelernt haben, ist es an der Zeit, sich eingehender mit Spark und PySpark zu befassen.
Was ist Funke?
Apache Spark besteht aus mehreren Komponenten, daher kann es schwierig sein, dies zu beschreiben. Im Kern ist Spark ein generischesenginefür die Verarbeitung großer Datenmengen.
Spark wird inScala geschrieben und läuft aufJVM. Spark verfügt über integrierte Komponenten für die Verarbeitung von Streaming-Daten, maschinelles Lernen, Grafikverarbeitung und sogar die Interaktion mit Daten über SQL.
In diesem Handbuch erfahren Sie nur mehr über die wichtigsten Spark-Komponenten für die Verarbeitung von Big Data. Alle anderen Komponenten wie maschinelles Lernen, SQL usw. stehen Python-Projekten jedoch auch über PySpark zur Verfügung.
Was ist PySpark?
Spark ist in Scala implementiert, einer Sprache, die auf der JVM ausgeführt wird. Wie können Sie also über Python auf all diese Funktionen zugreifen?
PySpark ist die Antwort.
Die aktuelle Version von PySpark ist 2.4.3 und funktioniert mit Python 2.7, 3.3 und höher.
Sie können sich PySpark als Python-basierten Wrapper über der Scala-API vorstellen. Dies bedeutet, dass Sie zwei Dokumentationssätze haben, auf die Sie sich beziehen können:
Die PySpark-API-Dokumente enthalten Beispiele. Oft möchten Sie jedoch auf die Scala-Dokumentation verweisen und den Code für Ihre PySpark-Programme in die Python-Syntax übersetzen. Glücklicherweise ist Scala eine sehr lesbare funktionsbasierte Programmiersprache.
PySpark kommuniziert mit der Spark Scala-basierten API überPy4J library. Py4J ist nicht spezifisch für PySpark oder Spark. Mit Py4J kann jedes Python-Programm mit JVM-basiertem Code kommunizieren.
Es gibt zwei Gründe, warum PySpark auf dem Funktionsparadigma basiert:
-
Die Muttersprache von Spark, Scala, basiert auf Funktionen.
-
Funktionscode ist viel einfacher zu parallelisieren.
Eine andere Möglichkeit, sich PySpark vorzustellen, ist eine Bibliothek, mit der große Datenmengen auf einem einzelnen Computer oder einem Cluster von Computern verarbeitet werden können.
In einem Python-Kontext bietet PySpark die Möglichkeit, die parallele Verarbeitung zu handhaben, ohne dass die Modulethreading odermultiprocessing erforderlich sind. Die gesamte komplizierte Kommunikation und Synchronisation zwischen Threads, Prozessen und sogar verschiedenen CPUs wird von Spark übernommen.
PySpark API und Datenstrukturen
Für die Interaktion mit PySpark erstellen Sie spezielle Datenstrukturen mit den NamenResilient Distributed Datasets (RDDs).
RDDs verbergen die Komplexität der automatischen Transformation und Verteilung Ihrer Daten auf mehrere Knoten durch einen Scheduler, wenn Sie in einem Cluster ausgeführt werden.
Um die API- und Datenstrukturen von PySpark besser zu verstehen, rufen Sie das zuvor erwähnte ProgrammHello Worldauf:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())Der Einstiegspunkt eines PySpark-Programms ist einSparkContext-Objekt. Mit diesem Objekt können Sie eine Verbindung zu einem Spark-Cluster herstellen und RDDs erstellen. Die Zeichenfolgelocal[*] ist eine spezielle Zeichenfolge, die angibt, dass Sie einenlocal-Cluster verwenden. Dies ist eine andere Art zu sagen, dass Sie im Einzelmaschinenmodus ausgeführt werden. Das* weist Spark an, so viele Arbeitsthreads wie logische Kerne auf Ihrem Computer zu erstellen.
Das Erstellen einesSparkContext kann bei Verwendung eines Clusters aufwändiger sein. Um eine Verbindung zu einem Spark-Cluster herzustellen, müssen Sie möglicherweise die Authentifizierung und einige andere für Ihren Cluster spezifische Informationen verarbeiten. Sie können diese Details ähnlich wie folgt einrichten:
conf = pyspark.SparkConf()
conf.setMaster('spark://head_node:56887')
conf.set('spark.authenticate', True)
conf.set('spark.authenticate.secret', 'secret-key')
sc = SparkContext(conf=conf)Sie können mit der Erstellung von RDDs beginnen, sobald Sie einSparkContexthaben.
Sie können RDDs auf verschiedene Arten erstellen. Eine übliche Methode ist jedoch die Funktion von PySparkparallelize(). parallelize() kann einige Python-Datenstrukturen wie Listen und Tupel in RDDs umwandeln, wodurch Sie Funktionen erhalten, die sie fehlertolerant und verteilt machen.
Betrachten Sie ein anderes Beispiel, um RDDs besser zu verstehen. Der folgende Code erstellt einen Iterator mit 10.000 Elementen und verwendet dannparallelize(), um diese Daten auf zwei Partitionen zu verteilen:
>>>
>>> big_list = range(10000)
>>> rdd = sc.parallelize(big_list, 2)
>>> odds = rdd.filter(lambda x: x % 2 != 0)
>>> odds.take(5)
[1, 3, 5, 7, 9]parallelize() verwandelt diesen Iterator in einen Satz vondistributed und bietet Ihnen alle Funktionen der Spark-Infrastruktur.
Beachten Sie, dass dieser Code diefilter()-Methode des RDD anstelle der zuvor in Python integriertenfilter() verwendet. Das Ergebnis ist das gleiche, aber was hinter den Kulissen passiert, ist drastisch anders. Bei Verwendung der RDDfilter()-Methode erfolgt diese Operation verteilt auf mehrere CPUs oder Computer.
Stellen Sie sich dies erneut als Spark vor, der die Arbeit vonmultiprocessingfür Sie erledigt, alles in der RDD-Datenstruktur gekapselt.
take() ist eine Möglichkeit, den Inhalt Ihrer RDD anzuzeigen, jedoch nur eine kleine Teilmenge. take() zieht diese Teilmenge von Daten aus dem verteilten System auf eine einzelne Maschine.
take() ist wichtig für das Debuggen, da eine Überprüfung Ihres gesamten Datensatzes auf einem einzelnen Computer möglicherweise nicht möglich ist. RDDs sind für die Verwendung in Big Data optimiert, sodass in einem realen Szenario ein einzelner Computer möglicherweise nicht über genügend RAM verfügt, um Ihren gesamten Datensatz zu speichern.
Note: Spark druckt vorübergehend Informationen anstdout, wenn Beispiele wie dieses in der Shell ausgeführt werden. Dies wird in Kürze beschrieben. Ihrestdout zeigen möglicherweise vorübergehend so etwas wie[Stage 0:> (0 + 1) / 1] an.
Der Text vonstdoutzeigt, wie Spark die RDDs aufteilt und Ihre Daten in mehrere Stufen auf verschiedenen CPUs und Maschinen verarbeitet.
Eine andere Möglichkeit, RDDs zu erstellen, besteht darin, eine Datei mittextFile() einzulesen, wie Sie in den vorherigen Beispielen gesehen haben. RDDs sind eine der grundlegenden Datenstrukturen für die Verwendung von PySpark, sodass viele der Funktionen in der API RDDs zurückgeben.
Einer der Hauptunterschiede zwischen RDDs und anderen Datenstrukturen besteht darin, dass die Verarbeitung verzögert wird, bis das Ergebnis angefordert wird. Dies ähnelt aPython generator. Entwickler im Python-Ökosystem verwenden normalerweise den Begrifflazy evaluation, um dieses Verhalten zu erklären.
Sie können mehrere Transformationen auf derselben RDD stapeln, ohne dass eine Verarbeitung stattfindet. Diese Funktionalität ist möglich, da Spark einen Prozentsatz (t0) der Transformationen verwaltet. Das zugrunde liegende Diagramm wird nur aktiviert, wenn die Endergebnisse angefordert werden. Im vorherigen Beispiel wurde keine Berechnung durchgeführt, bis Sie die Ergebnisse durch Aufrufen vontake() angefordert haben.
Es gibt mehrere Möglichkeiten, die Ergebnisse von einem RDD anzufordern. Sie können explizit anfordern, dass Ergebnisse ausgewertet und auf einem einzelnen Clusterknoten gesammelt werden, indem Siecollect() auf einer RDD verwenden. Sie können die Ergebnisse auch implizit auf verschiedene Arten anfordern, von denen einecount() verwendet hat, wie Sie zuvor gesehen haben.
Note: Seien Sie vorsichtig, wenn Sie diese Methoden verwenden, da sie das gesamte Dataset in den Speicher ziehen. Dies funktioniert nicht, wenn das Dataset zu groß ist, um in den RAM eines einzelnen Computers zu passen.
Weitere Informationen zu allen möglichen Funktionen finden Sie inPySpark API documentation.
PySpark installieren
Normalerweise führen Sie PySpark-Programme auf einemHadoop cluster aus, andere Clusterbereitstellungsoptionen werden jedoch unterstützt. Sie könnenSpark’s cluster mode overview für weitere Details lesen.
Note: Das Einrichten eines dieser Cluster kann schwierig sein und liegt außerhalb des Geltungsbereichs dieses Handbuchs. Im Idealfall verfügt Ihr Team über einige AssistentenDevOpsdes Assistenten, um dies zum Laufen zu bringen. Wenn nicht, veröffentlicht Hadoopa guide, um Ihnen zu helfen.
In diesem Handbuch sehen Sie verschiedene Möglichkeiten, um PySpark-Programme auf Ihrem lokalen Computer auszuführen. Dies ist nützlich zum Testen und Lernen, aber Sie möchten Ihre neuen Programme schnell in einem Cluster ausführen, um Big Data wirklich zu verarbeiten.
Manchmal kann es aufgrund aller erforderlichen Abhängigkeiten auch schwierig sein, PySpark selbst einzurichten.
PySpark läuft auf der JVM und erfordert eine Menge zugrunde liegender Java-Infrastruktur, um zu funktionieren. Davon abgesehen leben wir im Alter vonDocker, was das Experimentieren mit PySpark viel einfacher macht.
Noch besser ist, dass die erstaunlichen Entwickler hinterJupyter das ganze schwere Heben für Sie erledigt haben. Sie veröffentlichen einDockerfile, das alle PySpark-Abhängigkeiten zusammen mit Jupyter enthält. Sie können also direkt in einem Jupyter-Notizbuch experimentieren!
Note: Jupyter-Notebooks bieten viele Funktionen. InJupyter Notebook: An Introduction finden Sie weitere Informationen zur effektiven Verwendung von Notebooks.
Zunächst müssen Sie Docker installieren. Sehen Sie sichDocker in Action – Fitter, Happier, More Productive an, wenn Sie Docker noch nicht eingerichtet haben.
Note: Die Docker-Images können sehr groß sein. Stellen Sie daher sicher, dass Sie für die Verwendung von PySpark und Jupyter bis zu 5 GB Festplattenspeicher benötigen.
Als Nächstes können Sie den folgenden Befehl ausführen, um einen Docker-Container mit einem vorgefertigten PySpark-Einzelknoten-Setup herunterzuladen und automatisch zu starten. Dieser Befehl kann einige Minuten dauern, da die Bilder zusammen mit allen Anforderungen für Spark, PySpark und Jupyter direkt vonDockerHub heruntergeladen werden:
$ docker run -p 8888:8888 jupyter/pyspark-notebookSobald dieser Befehl das Drucken der Ausgabe beendet, haben Sie einen laufenden Container, der alles enthält, was Sie zum Testen Ihrer PySpark-Programme in einer Einzelknotenumgebung benötigen.
Um Ihren Container zu stoppen, geben Sie [.keys] #Ctrl [.kbd .key-c] # C ## in dasselbe Fenster ein, in das Sie den Befehl `+ docker run` eingegeben haben.
Jetzt ist es Zeit, endlich einige Programme auszuführen!
Ausführen von PySpark-Programmen
Es gibt verschiedene Möglichkeiten, PySpark-Programme auszuführen, je nachdem, ob Sie eine Befehlszeile oder eine visuellere Oberfläche bevorzugen. Für eine Befehlszeilenschnittstelle können Sie den Befehlspark-submit, die Standard-Python-Shell oder die spezialisierte PySpark-Shell verwenden.
Zunächst sehen Sie die visuellere Oberfläche eines Jupyter-Notebooks.
Jupyter Notizbuch
Sie können Ihr Programm in einem Jupyter-Notizbuch ausführen, indem Sie den folgenden Befehl ausführen, um den zuvor heruntergeladenen Docker-Container zu starten (falls er noch nicht ausgeführt wird):
$ docker run -p 8888:8888 jupyter/pyspark-notebook
Executing the command: jupyter notebook
[I 08:04:22.869 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[I 08:04:25.022 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 08:04:25.022 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 08:04:25.027 NotebookApp] Serving notebooks from local directory: /home/jovyan
[I 08:04:25.028 NotebookApp] The Jupyter Notebook is running at:
[I 08:04:25.029 NotebookApp] http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
[I 08:04:25.029 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 08:04:25.037 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html
Or copy and paste one of these URLs:
http://(4d5ab7a93902 or 127.0.0.1):8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437Jetzt läuft ein Container mit PySpark. Beachten Sie, dass am Ende der Befehlsausgabe vondocker runeine lokale URL erwähnt wird.
Note: Die Ausgabe derdocker-Befehle unterscheidet sich auf jedem Computer geringfügig, da die Token, Container-IDs und Containernamen zufällig generiert werden.
Sie müssen diese URL verwenden, um eine Verbindung zum Docker-Container herzustellen, in dem Jupyter in einem Webbrowser ausgeführt wird. Kopieren Sie die URLfrom your output und fügen Sie sie direkt in Ihren Webbrowser ein. Hier ist ein Beispiel für die URL, die Sie wahrscheinlich sehen werden:
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437Die URL im folgenden Befehl unterscheidet sich wahrscheinlich geringfügig auf Ihrem Computer. Sobald Sie jedoch in Ihrem Browser eine Verbindung zu dieser URL hergestellt haben, können Sie auf eine Jupyter-Notebook-Umgebung zugreifen, die ungefähr so aussehen sollte:
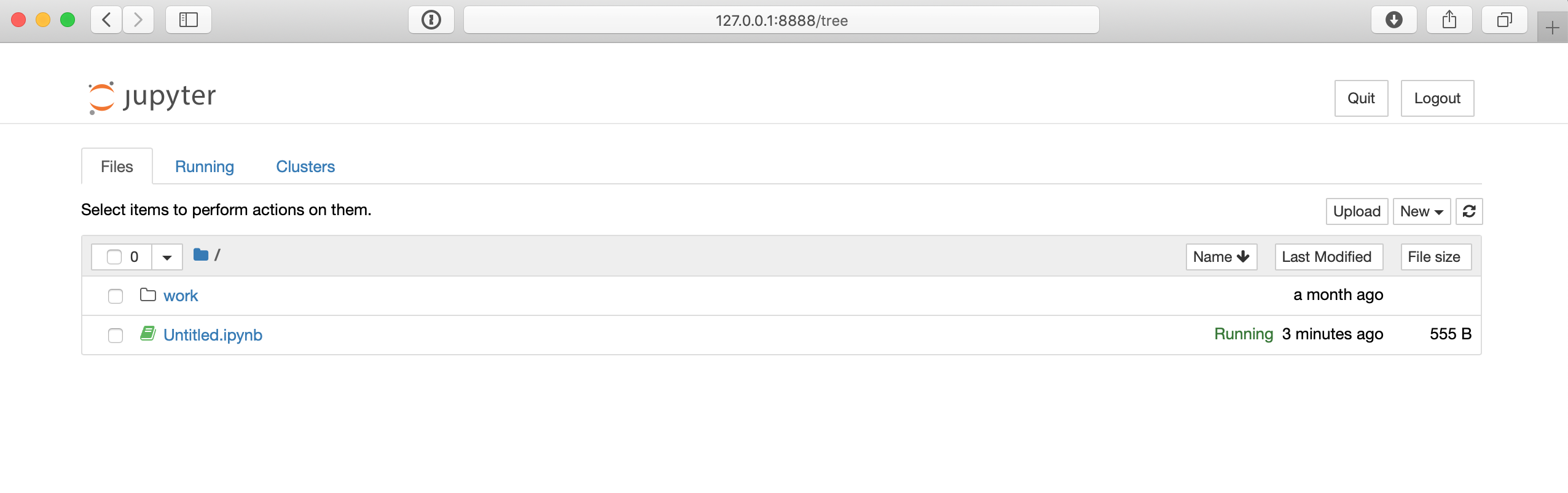
Auf der Jupyter-Notizbuchseite können Sie die SchaltflächeNew ganz rechts verwenden, um eine neue Python 3-Shell zu erstellen. Dann können Sie einen Code testen, wie das Beispiel vonHello Worldvon zuvor:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
print(txt.count())
python_lines = txt.filter(lambda line: 'python' in line.lower())
print(python_lines.count())So sieht das Ausführen dieses Codes im Jupyter-Notizbuch aus:
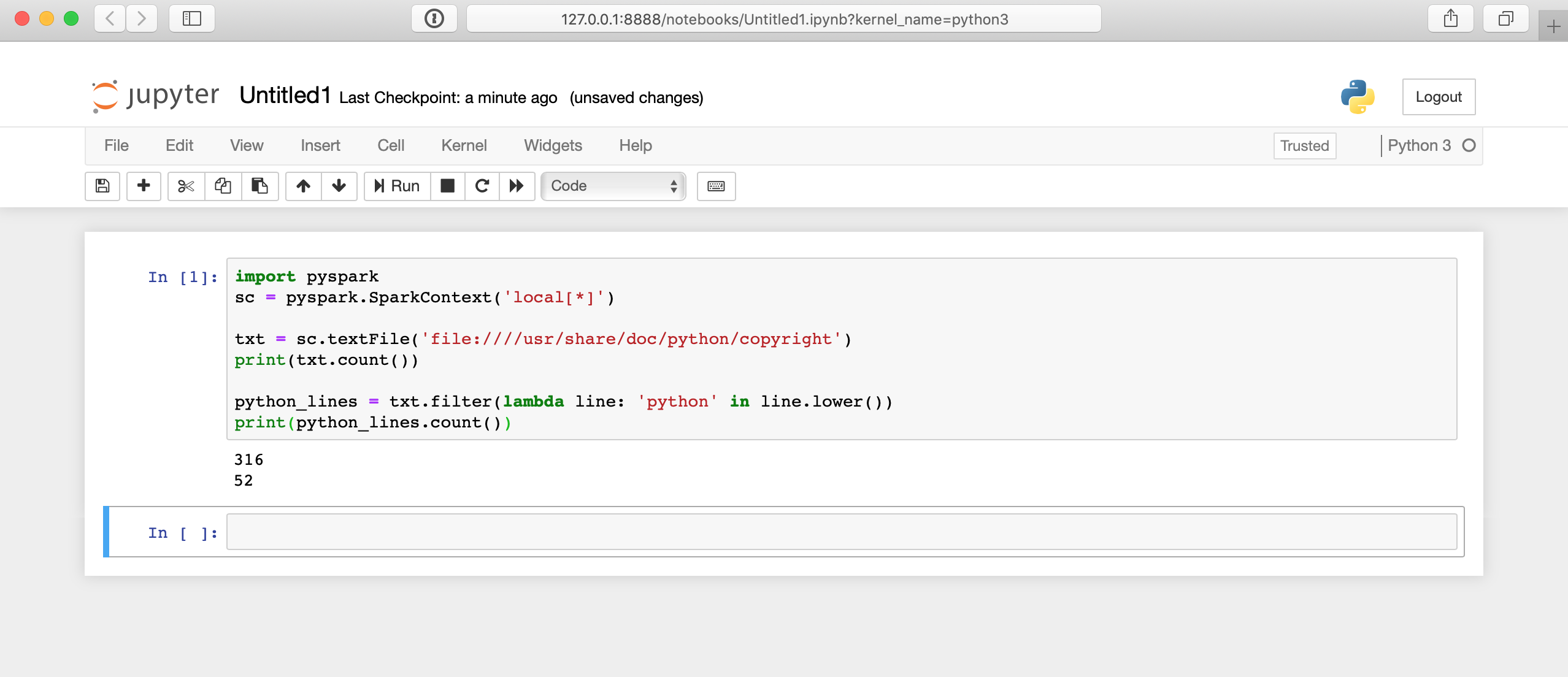
Hinter den Kulissen passiert viel, daher kann es einige Sekunden dauern, bis Ihre Ergebnisse angezeigt werden. Die Antwort wird nicht sofort angezeigt, nachdem Sie auf die Zelle geklickt haben.
Befehlszeilenschnittstelle
Die Befehlszeilenschnittstelle bietet verschiedene Möglichkeiten zum Senden von PySpark-Programmen, einschließlich der PySpark-Shell und des Befehlsspark-submit. Um diese CLI-Ansätze verwenden zu können, müssen Sie zunächst eine Verbindung zur CLI des Systems herstellen, auf dem PySpark installiert ist.
Um eine Verbindung zur CLI des Docker-Setups herzustellen, müssen Sie den Container wie zuvor starten und dann an diesen Container anhängen. Um den Container erneut zu starten, können Sie den folgenden Befehl ausführen:
$ docker run -p 8888:8888 jupyter/pyspark-notebookSobald der Docker-Container ausgeführt wird, müssen Sie anstelle eines Jupyter-Notebooks eine Verbindung über die Shell herstellen. Führen Sie dazu den folgenden Befehl aus, um den Containernamen zu ermitteln:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d5ab7a93902 jupyter/pyspark-notebook "tini -g -- start-no…" 12 seconds ago Up 10 seconds 0.0.0.0:8888->8888/tcp kind_edisonDieser Befehl zeigt Ihnen alle laufenden Container. Suchen Sie dieCONTAINER ID des Containers, auf dem dasjupyter/pyspark-notebook-Image ausgeführt wird, und stellen Sie damit eine Verbindung zurbash-Shellinside des Containers her:
$ docker exec -it 4d5ab7a93902 bash
jovyan@4d5ab7a93902:~$Jetzt sollten Sie mit einerbash-Eingabeaufforderunginside of the container verbunden sein. Sie können überprüfen, ob die Dinge funktionieren, da sich die Eingabeaufforderung Ihrer Shell injovyan@4d5ab7a93902 ändert, jedoch die eindeutige ID Ihres Containers verwendet.
Note: Ersetzen Sie4d5ab7a93902 durchCONTAINER ID, die auf Ihrem Computer verwendet werden.
Cluster
Sie können den zusammen mit Spark installierten Befehlspark-submit verwenden, um PySpark-Code über die Befehlszeile an einen Cluster zu senden. Dieser Befehl nimmt ein PySpark- oder Scala-Programm und führt es in einem Cluster aus. Auf diese Weise führen Sie wahrscheinlich Ihre echten Big Data-Verarbeitungsaufträge aus.
Note: Der Pfad zu diesen Befehlen hängt davon ab, wo Spark installiert wurde, und funktioniert wahrscheinlich nur, wenn der referenzierte Docker-Container verwendet wird.
Um das Beispiel vonHello World(oder ein beliebiges PySpark-Programm) mit dem ausgeführten Docker-Container auszuführen, greifen Sie zunächst wie oben beschrieben auf die Shell zu. Sobald Sie sich in der Shell-Umgebung des Containers befinden, können Sie mitnano text editor Dateien erstellen.
Um die Datei in Ihrem aktuellen Ordner zu erstellen, starten Sie einfachnano mit dem Namen der Datei, die Sie erstellen möchten:
$ nano hello_world.pyGeben Sie den Inhalt des Beispiels vonHello Worldein und speichern Sie die Datei, indem SieCtrl+[.kbd .key-x]#X # eingeben und die Anweisungen zum Speichern befolgen:
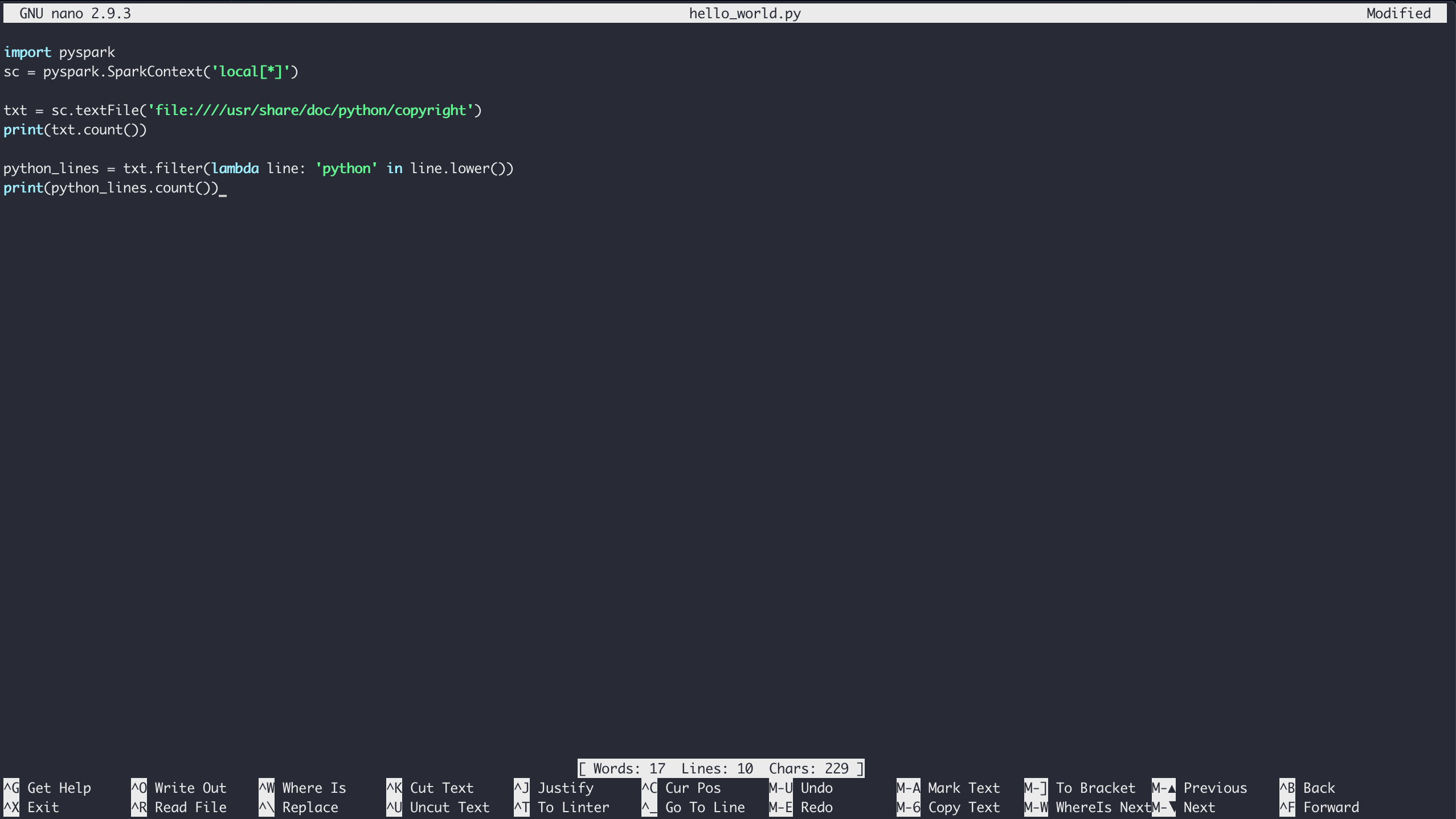
Schließlich können Sie den Code mit dem Befehlpyspark-submit über Spark ausführen:
$ /usr/local/spark/bin/spark-submit hello_world.pyDieser Befehl führt standardmäßig zua lot der Ausgabe, sodass es möglicherweise schwierig ist, die Ausgabe Ihres Programms zu sehen. Sie können die Ausführlichkeit des Protokolls in Ihrem PySpark-Programm etwas steuern, indem Sie die Ebene für die VariableSparkContextändern. Fügen Sie dazu diese Zeile oben in Ihr Skript ein:
sc.setLogLevel('WARN')Dadurch werdensome der Ausgabe vonspark-submit weggelassen, sodass Sie die Ausgabe Ihres Programms klarer sehen können. In einem realen Szenario möchten Sie jedoch eine Ausgabe in eine Datei, eine Datenbank oder einen anderen Speichermechanismus einfügen, um das spätere Debuggen zu vereinfachen.
Glücklicherweise hat ein PySpark-Programm weiterhin Zugriff auf die gesamte Standardbibliothek von Python, sodass das Speichern Ihrer Ergebnisse in einer Datei kein Problem darstellt:
import pyspark
sc = pyspark.SparkContext('local[*]')
txt = sc.textFile('file:////usr/share/doc/python/copyright')
python_lines = txt.filter(lambda line: 'python' in line.lower())
with open('results.txt', 'w') as file_obj:
file_obj.write(f'Number of lines: {txt.count()}\n')
file_obj.write(f'Number of lines with python: {python_lines.count()}\n')Jetzt befinden sich Ihre Ergebnisse in einer separaten Datei mit dem Namenresults.txt, damit Sie später leichter darauf zugreifen können.
Note: Der obige Code verwendetf-strings, die in Python 3.6 eingeführt wurden.
PySpark Shell
Eine andere PySpark-spezifische Möglichkeit, Ihre Programme auszuführen, ist die Verwendung der mit PySpark selbst gelieferten Shell. Mit dem Docker-Setup können Sie erneut wie oben beschrieben eine Verbindung zur CLI des Containers herstellen. Anschließend können Sie die spezialisierte Python-Shell mit dem folgenden Befehl ausführen:
$ /usr/local/spark/bin/pyspark
Python 3.7.3 | packaged by conda-forge | (default, Mar 27 2019, 23:01:00)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 23:01:00)
SparkSession available as 'spark'.Jetzt befinden Sie sich in der Pyspark-Shell-UmgebunginsideIhres Docker-Containers und können Code testen, der dem Beispiel des Jupyter-Notebooks ähnelt:
>>>
>>> txt = sc.textFile('file:////usr/share/doc/python/copyright')
>>> print(txt.count())
316Jetzt können Sie in der Pyspark-Shell genauso arbeiten wie in Ihrer normalen Python-Shell.
Note: Sie mussten im Pyspark-Shell-Beispiel keineSparkContext-Variable erstellen. Die PySpark-Shell erstellt automatisch die Variablesc, um Sie im Einzelknotenmodus mit der Spark-Engine zu verbinden.
Siemust create your ownSparkContext, wenn Sie echte PySpark-Programme mitspark-submit oder einem Jupyter-Notebook einreichen.
Sie können auch die Standard-Python-Shell verwenden, um Ihre Programme auszuführen, solange PySpark in dieser Python-Umgebung installiert ist. Für den Docker-Container, den Siedoes notverwendet haben, ist PySpark für die Standard-Python-Umgebung aktiviert. Sie müssen also eine der vorherigen Methoden verwenden, um PySpark im Docker-Container zu verwenden.
PySpark mit anderen Tools kombinieren
Wie Sie bereits gesehen haben, verfügt PySpark über zusätzliche Bibliotheken, mit denen Sie beispielsweise maschinelles Lernen und SQL-ähnliche Manipulationen an großen Datenmengen durchführen können. Sie können jedoch auch andere gängige wissenschaftliche Bibliotheken wieNumPy undPandas verwenden.
Sie müssen diese in derselben Umgebungon each cluster node installieren, und dann kann Ihr Programm sie wie gewohnt verwenden. Dann können Sie alle bekannten Tricks vonidiomatic Pandasverwenden, die Sie bereits kennen.
Remember:Pandas DataFrames werden eifrig ausgewertet, sodass alle Daten in den Speicheron a single machine passen müssen.
Nächste Schritte für eine echte Big Data-Verarbeitung
Bald nach dem Erlernen der PySpark-Grundlagen möchten Sie sicherlich mit der Analyse großer Datenmengen beginnen, die im Einzelmaschinenmodus wahrscheinlich nicht funktionieren. Die Installation und Wartung eines Spark-Clusters liegt weit außerhalb des Geltungsbereichs dieses Handbuchs und ist wahrscheinlich ein Vollzeitjob für sich.
Daher ist es möglicherweise an der Zeit, die IT-Abteilung in Ihrem Büro zu besuchen oder sich eine gehostete Spark-Cluster-Lösung anzusehen. Eine mögliche gehostete Lösung istDatabricks.
Mit Databricks können Sie Ihre Daten mitMicrosoft Azure oderAWS hosten und habenfree 14-day trial.
Nachdem Sie einen funktionierenden Spark-Cluster haben, möchten Sie alle Ihre Daten zur Analyse in diesen Cluster übertragen. Spark bietet verschiedene Möglichkeiten zum Importieren von Daten:
Sie können Daten sogar direkt aus einem Netzwerkdateisystem lesen. So haben die vorherigen Beispiele funktioniert.
Es gibt keinen Mangel an Möglichkeiten, auf alle Ihre Daten zuzugreifen, unabhängig davon, ob Sie eine gehostete Lösung wie Databricks oder Ihren eigenen Computercluster verwenden.
Fazit
PySpark ist ein guter Einstieg in die Big Data-Verarbeitung.
In diesem Tutorial haben Sie gelernt, dass Sie nicht viel Zeit im Voraus verbringen müssen, wenn Sie mit einigen funktionalen Programmierkonzepten wiemap(),filter() undbasic Pythonvertraut sind ) s. Tatsächlich können Sie alle Python, die Sie bereits kennen, einschließlich bekannter Tools wie NumPy und Pandas direkt in Ihren PySpark-Programmen verwenden.
Sie können jetzt:
-
Understand integrierte Python-Konzepte, die für Big Data gelten
-
Write grundlegende PySpark-Programme
-
Run PySpark-Programme für kleine Datensätze mit Ihrem lokalen Computer
-
Explore leistungsfähigere Big Data-Lösungen wie ein Spark-Cluster oder eine andere benutzerdefinierte, gehostete Lösung