Im vorherigen Kapitel wurde gezeigt, wie Sie Ausfallzeiten durch Hinzufügen von Redundanz auf der Web-Frontend-Ebene Ihrer Infrastruktur reduzieren können. Wenn Ihr Service mit Dateien und Daten arbeitet, benötigen Sie auch ein zentrales Backend, das ebenfalls redundant sein sollte, um zu vermeiden, dass ein einzelner Fehler auftritt.
Sowohl das Frontend als auch das Backend können eine Load-Balanced-Lösung verwenden, um den Datenverkehr auf mehrere Server zu verteilen. Diese Struktur bietet einige einzigartige Vorteile im Backend, z. B. die Möglichkeit, den Anwendungscode ohne Ausfallzeiten zu aktualisieren und beispielsweise A / B-Tests, Canary-Bereitstellungen und blau / grüne Bereitstellungen zu unterstützen. Dies erhöht jedoch auch die Komplexität Ihrer Infrastruktur. Sie müssen sich überlegen, wie Sie die Konfiguration Ihrer Load Balancer verwalten, wie Sie Ihre Anwendung und die Server verwalten, auf denen sie ausgeführt wird, und wie Sie die Konsistenz für Benutzersitzungen, Dateispeicher und Datenbanken gewährleisten.
Unabhängig davon, ob Sie DigitalOcean Load Balancer oder einen selbstverwalteten Satz von Load Balancern verwenden, müssen Sie die Konsistenz der Konfiguration gewährleisten. Das Verwalten der Konfigurationsdatei mit einem Konfigurationsverwaltungstool in einem selbstverwalteten Load-Balancer-Setup ist praktischer und erfordert zusätzliche Vorarbeit, während DigitalOcean Load Balancer ein verwalteter Dienst ist, der die Load-Balancer-Redundanz automatisch handhabt.
Bei DigitalOcean Load Balancern sind die Konfigurationsoptionen kuratiert, Sie müssen jedoch weiterhin sicherstellen, dass die Einstellungen korrekt und konsistent sind. Die Verwendung eines Droplet-Tags zur Bestimmung des Backends des Load Balancers ist der direkteste Weg zum Erfolg, da Sie Droplets automatisch hinzufügen und entfernen können (anstatt nach individueller IP-Adresse) und Ihre Konfiguration ausschließlich von Terraform ohne Ansible verwaltet werden kann.
Wenn Ihre Lastenausgleichsanforderungen komplexer waren, haben Sie möglicherweise Ihren eigenen Lastenausgleich gewählt (mit HAProxy wie im vorherigen Kapitel oder einer anderen Lastenausgleichssoftware). In diesem Fall müssen Sie mehrere Load-Balancer-Droplets zusammen mit einer DigitalOcean-Floating-IP-Adresse bereitstellen, um Redundanz auf der Load-Balancing-Ebene sicherzustellen.
Unser Setup
Datenkonsistenz ist die Hauptkomplikation, die Sie mit Ihrer Load-Balancer-Konfiguration angehen müssen. Wenn Ihr Backend von einem oder mehreren Servern aus bedient werden kann, müssen Sie sicherstellen, dass jeder Server Zugriff auf dasselbe konsistente Dataset hat oder dass eine bestimmte Sitzung weiterhin eine Verbindung zu einem bestimmten Server herstellt.
Wir werden dies als Gelegenheit nutzen, um eine leistungsfähigere Verwendung der Configuration Management-Software zu demonstrieren. In unserem Beispiel für das Hosten einer Website mit WordPress müssen wir entscheiden, wie sichergestellt werden soll, dass jeder Knoten in unserem Cluster über die richtigen Daten verfügt. Die Endbenutzer müssen eine zusammenhängende Erfahrung haben, unabhängig davon, welcher der Knoten die Anforderung verarbeitet. Ein Endbenutzer kann sporadische Ergebnisse sehen, wenn ein Knoten einen Beitrag oder ein Bild auf unserer WordPress-Site kennt, die anderen jedoch nicht.
Es gibt drei verwandte Komponenten, die wir beim Durchlaufen der Konfiguration überprüfen, um die Konsistenz sicherzustellen: Benutzersitzungen, Dateispeicher und Datenbanken.
Die Konfiguration verstehen
Das eigentliche Einrichten des Clusters nach Abschluss der Konfiguration ist ein relativ kurzer Prozess. Das Verständnis der Konfiguration und der darin enthaltenen Entscheidungen ist jedoch der Schlüssel, um diese Muster auf Ihre eigene Infrastruktur anwenden zu können. Teilen wir es Stück für Stück auf.
Load Balancer-Konfiguration
DigitalOcean Load Balancer
Wie in den vorherigen Kapiteln verwenden wir Terraform, um die Load Balancer-Konfiguration zu verwalten. Der folgende Eintrag erstellt einen Load Balancer und stellt das Back-End-Droplet-Tag, die Weiterleitungsregeln, das zu verwendende TLS-Zertifikat und die Integritätsprüfungen bereit, die der Load Balancer verwenden wird. SSL und andere Sicherheitseinstellungen sind in diesem Kapitel nicht enthalten, werden jedoch in Kapitel 13 ausführlich behandelt.
Hier ist der Ressourcenblock in der Datei + example-code / 02-scale / ch05 / init_deploy / main.tf +:
...
resource "digitalocean_loadbalancer" "public" {
name = "${var.project}-lb"
region = "${var.region}"
droplet_tag = "${digitalocean_tag.backend_tag.id}"
redirect_http_to_https = true
depends_on = ["digitalocean_tag.backend_tag"]
forwarding_rule {
entry_port = 80
entry_protocol = "http"
target_port = 80
target_protocol = "http"
}
healthcheck {
port = 80
protocol = "http"
path = "/"
check_interval_seconds = 5
response_timeout_seconds = 3
unhealthy_threshold = 2
healthy_threshold = 2
}
}Da Load Balancer eher ein Service als eine unveränderliche Ressource (wie ein Droplet) sind, wird durch eine Änderung der Konfigurationsargumente nicht der gesamte Load Balancer neu erstellt. es wird an Ort und Stelle aktualisiert. Weitere Informationen zu den unterstützten Argumenten und Ausgabeattributen finden Sie in der Terraform-Dokumentation.
Wir verwenden einen DigitalOcean Load Balancer, um den Lastausgleich des öffentlichen Webverkehrs zu unseren Webservern durchzuführen.
HAProxy-Cluster
Wenn Sie eine komplexere Konfiguration benötigen, z. B. Zugriff auf Einstellungen für den Lastausgleich auf niedrigerer Ebene oder Unterstützung für mehrere Back-End-Services, können Sie Ihren eigenen Lastausgleichscluster einrichten. Wir werden mit dem HAProxy-Beispiel aus dem vorherigen Kapitel fortfahren.
Ansible verwendet das Jinja2-Vorlagensystem, das das Erstellen und Aktualisieren Ihrer Konfigurationsdateien vereinfacht. Jinja2 unterstützt die Verwendung von Variablen und Kontrollstrukturen, die Sie in einer Programmiersprache finden würden, z. B. if-Anweisungen, Schleifen, mathematische Operationen und eine große Bibliothek integrierter Filter. Diese Zusammenfassung wird dem Templating-System in Ansible nicht gerecht. Wir empfehlen, die Ansible’s Dokumentation für weitere Details zu lesen.
Es gibt verschiedene Möglichkeiten, ein Update auszulösen, wenn sich Ihre Konfiguration ändert. Wenn die Nachfrage auf Ihrer Site nicht stark schwankt oder Sie wissen, wann Änderungen im Voraus erfolgen, müssen oder möchten Sie möglicherweise keine vollautomatische Skalierung einrichten. Stattdessen können Sie Ihr Ansible-Playbook manuell ausführen oder festlegen, dass es ausgeführt wird, wenn Sie eine Änderung an Ihren Terraform-Bereitstellungsskripten in Ihr Git-Repository übertragen.
Eine andere Möglichkeit besteht darin, Consul für die Serviceerkennung zu verwenden und auf Ihrem Load Balancer "+ consul-template" zu konfigurieren, um die Konfigurationsdatei automatisch zu aktualisieren. Dies fügt Ihrer gesamten Infrastruktur zusätzliche Droplets hinzu, aber Sie können Consul auch für andere Dienste verwenden.
Wir verwenden einen HAProxy-Cluster, um den Lastausgleich unseres Datenbank-Clusters durchzuführen.
Benutzersitzungen
-
Sessions Review *
_ Wenn ein Benutzer eine Site besucht, die über einen Load Balancer gehostet wird, kann nicht garantiert werden, dass seine nächste Anforderung vom selben Back-End-Server bearbeitet wird. Bei einfachen statischen Seiten ist dies kein Problem. Wenn der Dienst jedoch Kenntnisse über die Sitzung des Benutzers benötigt (z. B. wenn er angemeldet ist), müssen Sie dies tun. Hierfür gibt es einige Optionen, die an verschiedenen Stellen in Ihrem Stack implementiert werden können. _
Die Methode, die Sie für die Behandlung von Benutzersitzungen auswählen, hängt von Ihrem Anwendungsfall ab. Hier sind einige Optionen:
-
IP-Quellaffinität * leitet alle Anfragen von derselben IP-Adresse an dasselbe Backend weiter. Dies ist nicht die beste Wahl in Situationen, in denen Ihre Benutzer mithilfe von NAT eine Verbindung hinter einem Router herstellen können, da sie alle dieselbe IP-Adresse haben.
Die Optionen * Load Balancer-Sitzung * und * Anwendungssitzung * sind ähnlich. Beide konfigurieren den Load Balancer so, dass anhand der IP-Header-Informationen ermittelt wird, an welches Backend Anforderungen gesendet werden sollen. Anders als bei der IP-Quellenaffinitätsmethode werden Benutzer hinter einem NAT als einzelne Benutzer identifiziert. Sie können dies weiter anpassen, indem Sie auf HAProxy-Load-Balancern eine Stick-Tabelle implementieren, mit der die Benutzeridentifikation auf der Grundlage mehrerer verschiedener Datenpunkte konfiguriert werden kann.
-
Dateisystemreplikation * Repliziert den Pfad in Ihrem Dateisystem, in dem die Sitzungen gespeichert sind, und gewährt allen Back-Ends Zugriff auf alle Sitzungen. Ein wichtiger Aspekt ist die Geschwindigkeit, mit der die Replikation stattfindet. Abhängig von der Methode kann bereits eine moderate Verzögerung zwischen dem Back-End-Knoten und einer großen Anzahl von zu replizierenden Sitzungen zu Problemen für Endbenutzer führen.
Die Verwendung einer * Datenbank * oder eines * In-Memory-Datenspeichers * ist ähnlich. In beiden Fällen müssen Sie Ihre Anwendung so erstellen, dass Benutzersitzungen entweder in einer Datenbank oder in einem speicherinternen Cache wie Redis gespeichert werden. Die Verwendung einer Datenbank kann praktisch sein, da Ihre Anwendung bereits so eingerichtet ist, dass sie für andere Datenanforderungen eine Verbindung zu ihr herstellt. Bei einer hochaktiven Site kann dies zu einem höheren Aufwand für die Datenbank selbst führen. In den meisten Fällen ist die zusätzliche Belastung jedoch vernachlässigbar. Wenn Sie einen speicherinternen Cache wie "Redis" oder "Memcached" verwenden, müssen Sie einige weitere Droplets erstellen. Es handelt sich jedoch um sehr schnelle und vielseitige Lösungen, mit denen Sie auch Datenbankabfrageantworten für Leistungsverbesserungen zwischenspeichern können.
Da WordPress bereits für die Verwendung einer Datenbank für Sitzungen konfiguriert ist, verwenden wir diese Lösung.
Dateispeicher
-
_Dateispeicherüberprüfung: _ *
_ Die Dateien, die Ihre Anwendung verwendet, müssen konsistent sein. Alle Server müssen Zugriff auf die gleichen Ressourcen haben. Ein guter Ansatz für dieses Problem besteht darin, die Speicherfunktionalität von Ihren Back-End-App-Servern zu entkoppeln und stattdessen einen separaten Dienst für die Dateispeicherung zu verwenden. Für statische Assets können Sie eine Objektspeicherlösung verwenden. DigitalOcean Spaces ist ein hochverfügbarer Objektspeicherdienst mit integrierter Redundanz. Wir sprechen in Kapitel 7 mehr über Speicheroptionen, insbesondere Spaces. _
Wie bei Sitzungen können Sie die Dateispeicherung mithilfe der lokalen Dateisystemreplikation zwischen Ihren Anwendungsknoten durchführen. Dies fügt Ihrer Infrastruktur jedoch einen weiteren Dienst sowie zusätzliche Konfigurationsänderungen hinzu.
Eine einfachere Lösung ist die Verwendung von Objektspeicher wie DigitalOcean Spaces, insbesondere weil WordPress bereits ein DigitalOcean Spaces Sync -Plugin enthält. Da das Setup auf die Installation und Konfiguration eines einzelnen Plugins beschränkt ist, verwenden wir diese Lösung in diesem Kapitel.
Datenbank
-
Datenbanküberprüfung *
_ _ Ähnlich wie beim Speichern von Dateien muss Ihre Datenbank für alle Back-End-Droplets zugänglich sein. Die Replikation von Datenbankeinfügungen und -aktualisierungen in einem Cluster ist für eine funktionsfähige Cluster-Datenbanklösung von entscheidender Bedeutung.
Darüber hinaus sollte Ihre Datenbank über eine hohe Verfügbarkeit verfügen, dh Redundanz und automatisches Failover. Dies kann komplizierter sein, als es nur hinter einem Load Balancer zu platzieren, da das System die Datenkonsistenz verwalten muss, z. B. was passiert, wenn widersprüchliche Aktualisierungen an verschiedenen Knoten vorgenommen werden.
In unserem Beispiel verwenden wir einen MariaDB Galera-Cluster, um diese Probleme zu beheben. Galera verwaltet die synchrone Replikation auf jedem Datenbankknoten, von denen jeder als vollständiger primärer Datenbankserver fungiert. Dies bedeutet, dass Sie auf jedem Knoten im Cluster lesen und schreiben können und alles synchron bleibt. Es gibt andere Möglichkeiten, Datenbanken mit primären und sekundären Replikationsformen zu gruppieren, bei denen ein bestimmter Knoten als primärer Schreibserver ausgewählt wird.
Jede Clusterlösung hat ihre Vorzüge. Für unsere Übung bietet Galera die größten Vorteile, da die Datenkonsistenz automatisch verarbeitet wird und jeder Knoten im Cluster als Primärserver fungieren kann. Es sind keine Failover- oder Failback-Schritte erforderlich. _ _
WordPress verlässt sich für fast alles auf seine Datenbank, und ein einzelner externer Datenbankserver ist eine einzige Fehlerquelle. Es gibt einige Optionen für Datenbankcluster, und verschiedene Teile können gemischt und abgeglichen werden, je nachdem, was in Ihrem Fall am besten funktioniert.
In diesem Kapitel erstellen wir einen Galera-Cluster, der auf MariaDB ausgeführt wird, einem Zweig von MySQL. Dies wird hinter einigen HAProxy-Knoten mit einer angehängten DigitalOcean Floating IP ausgeführt.
Sie können das Quell-Repository dafür hier besuchen: https://github.com/DO-Solutions/galera-tf-mod. Es richtet das TCP-Routing für den Cluster ein, der standardmäßig drei Knoten hat. Wenn weniger als drei Knoten verwendet würden, wäre ein Knoten erforderlich, um Split-Brain-Situationen zu vermeiden und den Cluster betriebsbereit zu halten. Sie können auch die Anzahl der Knoten erhöhen, indem Sie die folgende Zeile zum Modulcode-Block in unserer Haupt-Terraform-Datei example-code / 02-scale / ch05 / init_deploy / main.tf hinzufügen. Beachten Sie, dass Sie eine ungerade Anzahl von Knoten haben möchten, damit ein Cluster bei der Durchführung einer Quorum-Abstimmung die Mehrheit haben kann. Ein Beispiel wäre, wenn zwei Knoten der Meinung sind, dass ein Datensatz existieren sollte und zwei andere Knoten, falls der Datensatz nicht existieren sollte, ein zusätzlicher Knoten erforderlich ist, um die entscheidende Stimme abzugeben.
module "sippin_db" {
...
db_node_count = "5"
}Einrichten des WordPress-Clusters
In unserem Projekt sind zum Einrichten des WordPress-Clusters nur wenige Befehle erforderlich. Wir arbeiten an + / root / navigators-guide / beispielcode / 02-scale / ch05 / init_deploy + auf dem Control Droplet, das den Beispielcode für dieses Kapitel enthält.
Führen Sie in diesem Verzeichnis das von uns bereitgestellte Initialisierungsskript aus. Sie werden durch alle Einstellungen und Variablen geführt, die Sie festlegen müssen.
./bin/init_configSie können den Code für das Initialisierungsskript unter GitHub anzeigen. Sie werden sehen, dass das Skript eine ganze Reihe von Funktionen ausführt. In Wirklichkeit werden automatisch die erforderlichen Terraform- und Ansible-Variablendateien erstellt und sichergestellt, dass keine bekannten Probleme vorliegen. Das Skript fordert zunächst zur Eingabe eines gültigen DigitalOcean-API-Tokens auf. Danach erstellt das Skript einige eindeutige Schlüssel, die für die Clustererstellung benötigt werden. Als nächstes werden Sie aufgefordert, das Projekt zu benennen und eine Region auszuwählen. Wenn bereits ein SSH-Schlüssel konfiguriert ist (wie in Kapitel 4 beschrieben), weist das Skript Terraform an, ihn zu verwenden. Wenn noch kein SSH-Schlüssel konfiguriert ist, wird automatisch ein SSH-Schlüssel erstellt und Ihrem DigitalOcean-Konto hinzugefügt. Zuletzt fordert das Skript alle erforderlichen Kennwörter auf.
Sobald das Skript fertig ist, können der Terraform-Plan und das Ansible-Playbook ausgeführt werden. Dies ist den Beispielen in Kapitel 4 sehr ähnlich, es werden jedoch weitere Ressourcen erstellt und konfiguriert.
Wenn Sie alles manuell konfigurieren würden, müssten Sie die Variablen für Terraform in die Datei * terraform.tvfars * eingeben. Ansible hat Variablen in mehreren Ordnern im Ordner * group_vars * benötigt.
Das Initialisierungsskript gibt Anweisungen aus, wie Sie vor dem Beenden mit Terraform fortfahren können. Wir werden jedoch auch hier darauf eingehen.
Wenn Sie zuerst + terraform plan + ausführen, werden die folgenden Elemente in Ihrem DigitalOcean-Konto erstellt:
-
Ein Load Balancer, der den Zugriff auf Ihre WordPress-Site ermöglicht.
-
Drei Tropfen, die als WordPress-Webknoten verwendet werden sollen.
-
Drei Droplets, die als Datenbankknoten verwendet werden sollen.
-
Zwei HAProxy Load Balancer-Knoten für den Datenbankcluster.
-
Eine Floating-IP-Adresse für den Datenbanklastenausgleich.
terraform planAnalysieren Sie als Nächstes die Plandateien und Module, um die Terraform-Bereitstellung mit + init + vorzubereiten.
terraform initFühren Sie abschließend die Erstellungsanforderungen über die DigitalOcean-API mit + apply + aus.
terraform applySobald Terraform alle Infrastrukturkomponenten erstellt hat, können Sie sie mit Ansible konfigurieren. Es müssen drei Ansible-Rollen ausgeführt werden: eine zum Konfigurieren der Datenbankserver, eine zum Konfigurieren der Datenbank-Load-Balancer und eine zum Einrichten von WordPress auf allen Webknoten.
Sie können alle drei Rollen mit einem Befehl ausführen:
ansible-playbook -i /usr/local/bin/terraform-inventory site.ymlSobald das Playbook fertig ist, müssen Sie das WordPress-Setup beenden.
Besuchen Sie die IP-Adresse Ihres Load Balancers in Ihrem Browser und befolgen Sie die Anweisungen auf dem Bildschirm, um Ihre WordPress-Konfiguration abzuschließen. Beachten Sie, dass in Kapitel 13 beschrieben wird, wie Sie Ihre WordPress-Installation mit HTTPS schützen.
Spaces konfigurieren
Wir werden das Plugin DigitalOcean Spaces Sync verwenden, um Mediendateien von den WordPress-App-Servern mit dem Objektspeicher zu synchronisieren. Der Space fungiert als zentraler Speicherort für alle Medien, die Sie zum Hochladen auswählen.
Das DigitalOcean Spaces Sync-Plugin wurde als Teil des Ansible-Playbooks vorinstalliert. Um dieses Plugin verwenden zu können, müssen Sie zuerst create a Space in der Systemsteuerung.
Nachdem der Space erstellt wurde, können Sie unter https://www.digitalocean.com/docs/spaces/how-to/administrative-access/#access-keys im Control Panel auf der Seite „API“ einen Spaces-Zugriffsschlüssel erstellen . Nach dem Generieren des Schlüssels sehen Sie den Hauptschlüssel zusammen mit dem Geheimnis. Notieren Sie sich diese, da Sie sie benötigen, um das WordPress-Plugin einzurichten.
Kehren Sie nun zu WordPress zurück und besuchen Sie die Plugins-Seite. Sie sollten sehen, dass DigitalOcean Spaces Sync dank unseres Ansible-Playbooks bereits installiert ist. Klicken Sie auf den Link Aktivieren, um dieses Plugin zu aktivieren. Nach der Aktivierung wird in Ihren Einstellungen ein neuer Link mit dem Namen „DigitalOcean Spaces Sync“ angezeigt.
Geben Sie auf dieser Einstellungsseite Ihren Spaces-Schlüssel, Spaces secret, den Space-Namen (auf dieser Einstellungsseite als "DO Spaces Container" bezeichnet) und den Endpunkt ein. Beachten Sie, dass der Endpunkt davon abhängt, welches Rechenzentrum Sie für Ihren Space ausgewählt haben. NYC3 würde beispielsweise "https: //nyc3.digitaloceanspaces.com" lauten.
Fügen Sie nach Überprüfung der Verbindung die vollständige URL für Ihren Space unter "Vollständiger URL-Pfad zu Dateien:" hinzu. Für ein Space in NYC3 wäre dies "https: //space-name.nyc3.digitaloceanspaces.com" (wobei "+ space-name +" der Name Ihres Space ist). Sobald dies eingegeben ist, ist es Zeit, Ihre Einstellungen zu speichern und das Plugin durch Hochladen einer Datei zu testen.
Wenn Sie eine Datei auf der Registerkarte "Medien" hochladen, sollte diese automatisch mit Ihrem Space synchronisiert werden. Sie können dies überprüfen, indem Sie die Dateiliste des Space in Ihrem DigitalOcean-Kontrollfeld anzeigen.
In diesem Setup wird standardmäßig kein CDN verwendet. In einer Produktionsumgebung empfehlen wir unbedingt die Verwendung eines CDN, da Sie so diese Mediendateien für alle Besucher schnell und zuverlässig bereitstellen können.
Wenn Sie später eine CDN hinzufügen, müssen Sie den "Vollständigen URL-Pfad zu Dateien" auf die Adresse dieser neuen CDN verweisen. Wir arbeiten auch an einem CDN, das in Spaces integriert ist. Dies befindet sich derzeit in der Beta-Phase. Bei Interesse wenden Sie sich bitte an Ihren Account Manager.
Überprüfen des Setups
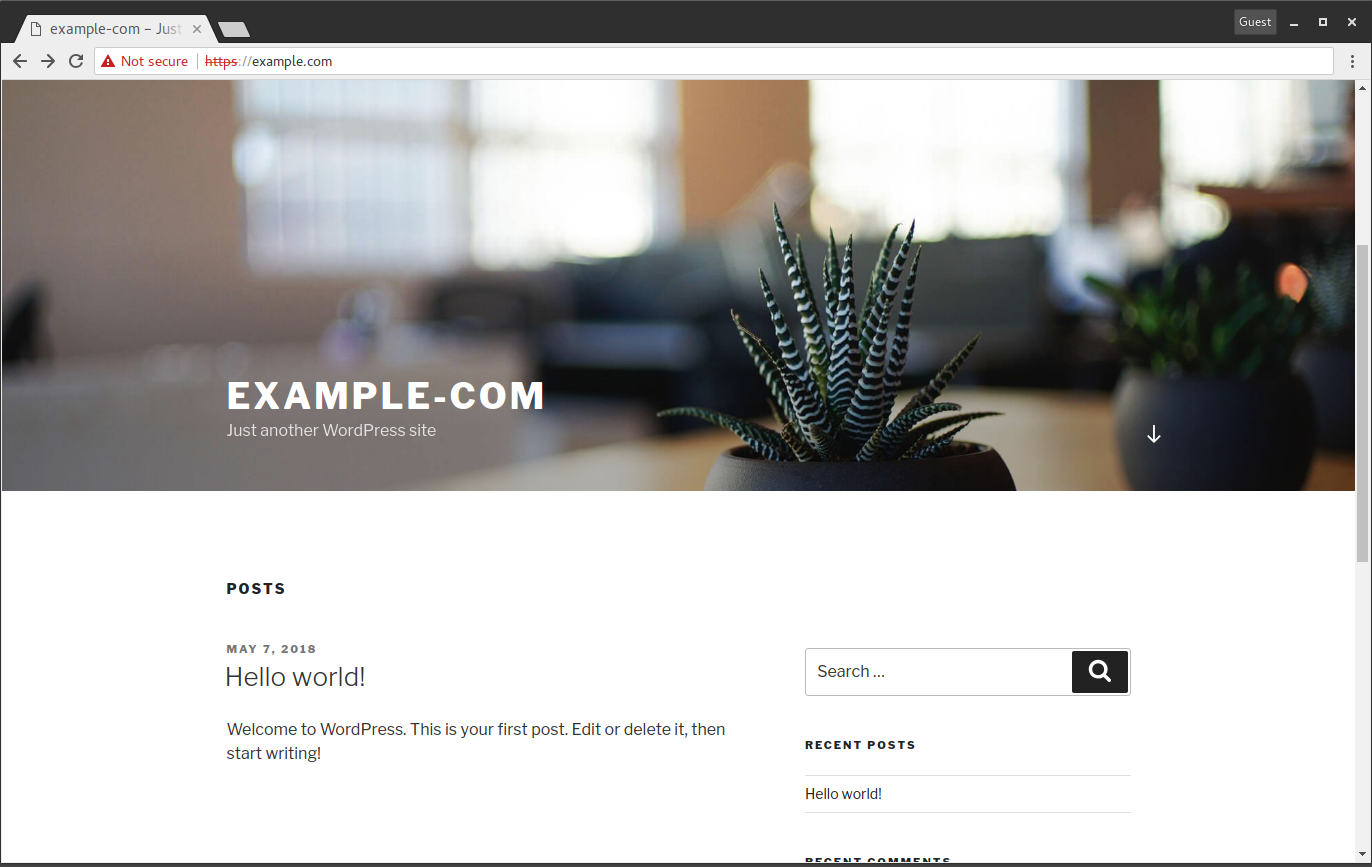
Wenn Sie in Ihrem Browser zu Ihrer Load Balancer-IP-Adresse gehen, können Sie die Standard-WordPress-Site wie folgt anzeigen:
Bild: https://raw.githubusercontent.com/digitalocean/navigators-guide/master/book/02-scale/ch05-wordpress-screenshot.png [WordPress-Standardinstallations-Screenshot]
{kind=link}
Das Endergebnis ist eine voll funktionsfähige WordPress-Site. Sie können testen, indem Sie ein Blog konfigurieren oder Beiträge erstellen. Sie können zwei der Webserver, einen der HAProxy-Server und einen der Datenbankknoten ausschalten, und die Website sollte weiterhin voll funktionsfähig sein.
Sobald Sie mit dem Testen fertig sind, können Sie alle diese Infrastrukturkomponenten mit einem Befehl aus Ihrem DigitalOcean-Konto entfernen. Dadurch wird der gesamte Cluster entfernt, um die Arbeit aus diesem Kapitel zu bereinigen.
terraform destroySie können + apply + erneut ausführen und dann das Ansible-Playbook erneut ausführen, um den Cluster neu zu generieren.
Was kommt als nächstes?
Wir haben unsere Beispiele für Hochverfügbarkeit verwendet und das Konzept auf den gesamten Anwendungsstapel angewendet. Das Beispiel in diesem Kapitel wurde verwendet, um eine vollständig redundante und skalierbare WordPress-Website zu erstellen. Dies wurde mithilfe von Konfigurationsmanagement-Tools erreicht. Im nächsten Kapitel werden wir nach einer Möglichkeit suchen, um unsere Bereitstellungen weiter zu automatisieren und zu verbessern. Der Rest des Buches befasst sich mit Konzepten in Bezug auf Speicherung, Überwachung und Sicherheit. Noch wichtiger ist jedoch, wie sie für Ihr Unternehmen gelten und was bei der Planung Ihrer Infrastruktur zu beachten ist.