Einführung
Dieses Tutorial behandelt das Einrichten eines Hadoop-Clusters auf DigitalOcean. Hadoop software library ist ein Apache-Framework, mit dem Sie große Datenmengen auf verteilte Weise über Servercluster hinweg verarbeiten können, indem Sie grundlegende Programmiermodelle nutzen. Dank der Skalierbarkeit von Hadoop können Sie von einzelnen Servern auf Tausende von Computern hochskalieren. Es bietet auch eine Fehlererkennung auf Anwendungsebene, sodass Fehler als Hochverfügbarkeitsdienst erkannt und behandelt werden können.
Es gibt 4 wichtige Module, mit denen wir in diesem Tutorial arbeiten werden:
-
Hadoop Common ist die Sammlung allgemeiner Dienstprogramme und Bibliotheken, die zur Unterstützung anderer Hadoop-Module erforderlich sind.
-
Hadoop Distributed File System (HDFS), wie durchthe Apache organization angegeben, ist ein hoch fehlertolerantes, verteiltes Dateisystem, das speziell für die Ausführung auf Standardhardware zur Verarbeitung großer Datenmengen entwickelt wurde.
-
Hadoop YARN ist das Framework für die Jobplanung und die Verwaltung von Clusterressourcen.
-
Hadoop MapReduce ist ein YARN-basiertes System zur parallelen Verarbeitung großer Datenmengen.
In diesem Tutorial werden wir einen Hadoop-Cluster auf vier DigitalOcean Droplets einrichten und ausführen.
Voraussetzungen
Dieses Tutorial erfordert Folgendes:
-
Vier Ubuntu 16.04-Droplets mit Nicht-Root-Sudo-Benutzern eingerichtet. Wenn Sie dies nicht eingerichtet haben, befolgen Sie die Schritte 1 bis 4 derInitial Server Setup with Ubuntu 16.04. In diesem Lernprogramm wird davon ausgegangen, dass Sie einen SSH-Schlüssel von einem lokalen Computer verwenden. In der Sprache von Hadoop werden wir diese Tröpfchen mit den folgenden Namen bezeichnen:
-
hadoop-master -
hadoop-worker-01 -
hadoop-worker-02 -
hadoop-worker-03
-
-
Darüber hinaus möchten Sie möglicherweiseDigitalOcean Snapshots nach der Ersteinrichtung des Servers und nach Abschluss vonSteps 1 und2 (unten) Ihres ersten Droplets verwenden.
Wenn diese Voraussetzungen erfüllt sind, können Sie mit dem Einrichten eines Hadoop-Clusters beginnen.
[[Schritt-1 -—- Installations-Setup-für-jedes-Tröpfchen]] == Schritt 1 - Installations-Setup für jedes Tröpfchen
Wir werden Java und Hadoop aufeach unsererfour Droplets installieren. Wenn Sie nicht jeden Schritt für jedes Droplet wiederholen möchten, können SieDigitalOcean Snapshots am Ende vonStep 2 verwenden, um Ihre Erstinstallation und Konfiguration zu replizieren.
Zunächst aktualisieren wir Ubuntu mit den neuesten verfügbaren Software-Patches:
sudo apt-get update && sudo apt-get -y dist-upgradeAls nächstes installieren wir die Headless-Version von Java für Ubuntu auf jedem Droplet. "Headless" bezieht sich auf die Software, die auf einem Gerät ohne grafische Benutzeroberfläche ausgeführt werden kann.
sudo apt-get -y install openjdk-8-jdk-headlessUm Hadoop auf jedem Droplet zu installieren, legen Sie das Verzeichnis fest, in dem Hadoop installiert wird. Wir können esmy-hadoop-install nennen und dann in dieses Verzeichnis wechseln.
mkdir my-hadoop-install && cd my-hadoop-installNachdem wir das Verzeichnis erstellt haben, installieren wir die neueste Binärdatei ausHadoop releases list. Zum Zeitpunkt dieses Tutorials istHadoop 3.0.1 das aktuellste.
[.note] #Note: Beachten Sie, dass diese Downloads über Spiegelseiten verteilt werden. Es wird empfohlen, sie zuerst mit GPG oder SHA-256 auf Manipulationen zu überprüfen.
#
Wenn Sie mit dem ausgewählten Download zufrieden sind, können Sie den Befehlwget mit dem von Ihnen ausgewählten Binärlink verwenden, z.
wget http://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gzWenn der Download abgeschlossen ist, entpacken Sie den Inhalt der Datei mittar, einem Dateiarchivierungs-Tool für Ubuntu:
tar xvzf hadoop-3.0.1.tar.gzJetzt können Sie mit der Erstkonfiguration beginnen.
[[Schritt-2 -—- Update-Hadoop-Umgebungskonfiguration]] == Schritt 2 - Hadoop-Umgebungskonfiguration aktualisieren
Für jeden Droplet-Knoten müssen wirJAVA_HOME einrichten. Öffnen Sie die folgende Datei mit nano oder einem anderen Texteditor Ihrer Wahl, damit wir sie aktualisieren können:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shAktualisieren Sie den folgenden Abschnitt, in dem sichJAVA_HOME befindet:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Um so auszusehen:
hadoop-env.sh
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...Wir müssen auch einige Umgebungsvariablen hinzufügen, um Hadoop und seine Module auszuführen. Sie sollten am Ende der Datei hinzugefügt werden, damit es wie folgt aussieht:sammy wäre der Benutzername Ihres Sudo-Nicht-Root-Benutzers.
[.note] #Note: Wenn Sie in Ihren Cluster-Droplets einen anderen Benutzernamen verwenden, müssen Sie diese Datei bearbeiten, um den richtigen Benutzernamen für jedes bestimmte Droplet wiederzugeben.
#
hadoop-env.sh
...
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
export HDFS_NAMENODE_USER="sammy"
export HDFS_DATANODE_USER="sammy"
export HDFS_SECONDARYNAMENODE_USER="sammy"
export YARN_RESOURCEMANAGER_USER="sammy"
export YARN_NODEMANAGER_USER="sammy"Zu diesem Zeitpunkt können Sie die Datei speichern und beenden. Führen Sie als Nächstes den folgenden Befehl aus, um unsere Exporte anzuwenden:
source ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.shNachdem das Skripthadoop-env.shaktualisiert und bezogen wurde, müssen wir ein Datenverzeichnis für das Hadoop Distributed File System (HDFS) erstellen, um alle relevantenHDFS-Dateien zu speichern.
sudo mkdir -p /usr/local/hadoop/hdfs/dataLegen Sie die Berechtigungen für diese Datei mit Ihrem jeweiligen Benutzer fest. Denken Sie daran, dass Sie Ihrem jeweiligen sudo-Benutzer die folgenden Berechtigungen gewähren müssen, wenn Sie unterschiedliche Benutzernamen für jedes Droplet haben:
sudo chown -R sammy:sammy /usr/local/hadoop/hdfs/dataWenn Sie einen DigitalOcean-Snapshot verwenden möchten, um diese Befehle auf Ihre Droplet-Knoten zu replizieren, können Sie jetzt Ihren Snapshot erstellen und aus diesem Bild neue Droplets erstellen. Als Anleitung hierzu können SieAn Introduction to DigitalOcean Snapshots lesen.
Wenn Sie die obigen Schritte fürall fourUbuntu-Tröpfchen ausgeführt haben, können Sie diese Konfiguration für mehrere Knoten ausführen.
[[Schritt 3 - Vollständige Erstkonfiguration für jeden Knoten]] == Schritt 3 - Vollständige Erstkonfiguration für jeden Knoten
Zu diesem Zeitpunkt müssen wir diecore_site.xml-Datei fürall 4 Ihrer Droplet-Knoten aktualisieren. Öffnen Sie in jedem einzelnen Droplet die folgende Datei:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/core-site.xmlSie sollten die folgenden Zeilen sehen:
core-site.xml
...
Ändern Sie die Datei so, dass sie wie das folgende XML aussieht, sodass wireach Droplet’s respective IP in den Eigenschaftswert aufnehmen, in denserver-ip geschrieben sind. Wenn Sie eine Firewall verwenden, müssen Sie Port 9000 öffnen.
core-site.xml
...
fs.defaultFS
hdfs://server-ip:9000
Wiederholen Sie den obigen Vorgang in der entsprechenden Droplet-IP fürall four Ihrer Server.
Jetzt sollten alle allgemeinen Hadoop-Einstellungen für jeden Serverknoten aktualisiert werden, und wir können fortfahren, unsere Knoten über SSH-Schlüssel zu verbinden.
[[Schritt 4 - Einrichten von SSH für jeden Knoten]] == Schritt 4 - Einrichten von SSH für jeden Knoten
Damit Hadoop ordnungsgemäß funktioniert, müssen Sie zwischen dem Masterknoten und den Arbeitsknoten ein kennwortloses SSH einrichten (die Sprache vonmaster undworker ist die Sprache von Hadoop, die sich aufprimary und bezieht secondary Server).
In diesem Lernprogramm ist der Hauptknotenhadoop-master und die Arbeiterknoten werden gemeinsam alshadoop-worker bezeichnet, aber Sie haben insgesamt drei davon (bezeichnet als-01, -02 und-03). Wir müssen zuerst ein öffentlich-privates Schlüsselpaar auf dem Masterknoten erstellen, das der Knoten mit der IP-Adresse ist, die zuhadoop-master gehört.
Führen Sie auf demhadoop-master-Droplet den folgenden Befehl aus. Sie drückenenter, um die Standardeinstellung für die Tastenposition zu verwenden, und drücken dann zweimalenter, um eine leere Passphrase zu verwenden:
ssh-keygenFür jeden der Arbeitsknoten müssen wir den öffentlichen Schlüssel des Hauptknotens nehmen und ihn in dieauthorized_keys-Datei jedes Arbeitsknotens kopieren.
Rufen Sie den öffentlichen Schlüssel vom Hauptknoten ab, indem Siecat in der Dateiid_rsa.pub in Ihrem Ordner.sshausführen, um auf der Konsole zu drucken:
cat ~/.ssh/id_rsa.pubMelden Sie sich nun bei jedem Worker Node Droplet an und öffnen Sie die Dateiauthorized_keys:
nano ~/.ssh/authorized_keysSie kopieren den öffentlichen Schlüssel des Masterknotens - dies ist die Ausgabe, die Sie mit dem Befehlcat ~/.ssh/id_rsa.pubauf dem Masterknoten generiert haben - in die jeweilige~/.ssh/authorized_keys-Datei jedes Droplets. Stellen Sie sicher, dass Sie jede Datei speichern, bevor Sie sie schließen.
Wenn Sie mit dem Aktualisieren der 3 Arbeitsknoten fertig sind, kopieren Sie auch den öffentlichen Schlüssel des Hauptknotens in die eigeneauthorized_keys-Datei, indem Sie denselben Befehl eingeben:
nano ~/.ssh/authorized_keysBeihadoop-master sollten Sie die Konfiguration vonssho einrichten, dass sie jeden Hostnamen der zugehörigen Knoten enthält. Öffnen Sie die Konfigurationsdatei zum Bearbeiten mit nano:
nano ~/.ssh/configSie sollten die Datei so ändern, dass sie wie folgt aussieht, wobei relevante IP-Adressen und Benutzernamen hinzugefügt werden.
config
Host hadoop-master-server-ip
HostName hadoop-example-node-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-01-server-ip
HostName hadoop-worker-01-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-02-server-ip
HostName hadoop-worker-02-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-03-server-ip
HostName hadoop-worker-03-server-ip
User sammy
IdentityFile ~/.ssh/id_rsaSpeichern und schließen Sie die Datei.
Von denhadoop-master, SSH in jeden Knoten:
ssh sammy@hadoop-worker-01-server-ipDa Sie sich zum ersten Mal mit dem aktuellen System auf jedem Knoten anmelden, werden Sie nach den folgenden Fragen gefragt:
Outputare you sure you want to continue connecting (yes/no)?Antworten Sie auf die Eingabeaufforderung mityes. Dies ist das einzige Mal, dass dies durchgeführt werden muss, es ist jedoch für jeden Arbeitsknoten für die anfängliche SSH-Verbindung erforderlich. Melden Sie sich schließlich von jedem Arbeitsknoten ab, um zuhadoop-master zurückzukehren:
logoutStellen Sie sicher, dassrepeat these steps für die verbleibenden zwei Arbeitsknoten angegeben ist.
Nachdem wir für jeden Worker-Knoten ein passwortloses SSH eingerichtet haben, können wir nun den Master-Knoten weiter konfigurieren.
[[Schritt 5 - Konfigurieren des Masterknotens]] == Schritt 5 - Konfigurieren des Masterknotens
Für unseren Hadoop-Cluster müssen wir die HDFS-Eigenschaften auf dem Masterknoten Droplet konfigurieren.
Bearbeiten Sie auf dem Masterknoten die folgende Datei:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlBearbeiten Sie den Abschnittconfigurationo, dass er wie folgt aussieht:
hdfs-site.xml
...
dfs.replication
3
dfs.namenode.name.dir
file:///usr/local/hadoop/hdfs/data
Speichern und schließen Sie die Datei.
Als nächstes konfigurieren wir die Eigenschaften vonMapReduceauf dem Masterknoten. Öffnen Siemapred.site.xml mit Nano oder einem anderen Texteditor:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mapred-site.xmlAktualisieren Sie dann die Datei so, dass sie wie folgt aussieht:
mapred-site.xml
...
mapreduce.jobtracker.address
hadoop-master-server-ip:54311
mapreduce.framework.name
yarn
Speichern und schließen Sie die Datei. Wenn Sie eine Firewall verwenden, müssen Sie Port 54311 öffnen.
Richten Sie als Nächstes YARN auf dem Masterknoten ein. Auch hier aktualisieren wir den Konfigurationsabschnitt einer anderen XML-Datei. Öffnen wir also die Datei:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/yarn-site.xmlAktualisieren Sie nun die Datei und geben Sie die IP-Adresse Ihres aktuellen Servers ein:
yarn-site.xml
...
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop-master-server-ip
Zuletzt konfigurieren wir den Referenzpunkt von Hadoop für den Master- und Worker-Knoten. Öffnen Sie zunächst die Dateimasters:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mastersIn diese Datei fügen Sie die IP-Adresse Ihres aktuellen Servers ein:
Meister
hadoop-master-server-ipÖffnen und bearbeiten Sie nun die Dateiworkers:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/workersHier fügen Sie die IP-Adressen der einzelnen Worker-Knoten hinzu, darunterlocalhost.
Arbeitskräfte
localhost
hadoop-worker-01-server-ip
hadoop-worker-02-server-ip
hadoop-worker-03-server-ipNachdem Sie die Konfiguration der EigenschaftenMapReduce undYARNabgeschlossen haben, können Sie die Konfiguration der Worker-Knoten abschließen.
[[Schritt 6 - Konfigurieren der Arbeiterknoten]] == Schritt 6 - Konfigurieren der Arbeiterknoten
Jetzt konfigurieren wir die Arbeitsknoten so, dass sie jeweils den richtigen Verweis auf das Datenverzeichnis für HDFS haben.
Bearbeiten Sie diese XML-Datei untereach worker node:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xmlErsetzen Sie den Konfigurationsabschnitt durch Folgendes:
hdfs-site.xml
dfs.replication
3
dfs.datanode.data.dir
file:///usr/local/hadoop/hdfs/data
Speichern und schließen Sie die Datei. Stellen Sie sicher, dass Sie diesen Schritt aufall three Ihrer Worker-Knoten replizieren.
Zu diesem Zeitpunkt verweisen unsere Worker-Knoten-Droplets auf das Datenverzeichnis für HDFS, sodass wir unseren Hadoop-Cluster ausführen können.
[[Schritt 7 - Führen Sie den Hadoop-Cluster aus]] == Schritt 7 - Führen Sie den Hadoop-Cluster aus
Wir haben einen Punkt erreicht, an dem wir unseren Hadoop-Cluster starten können. Bevor wir es starten, müssen wir das HDFS auf dem Masterknoten formatieren. Wechseln Sie auf dem Masterknoten Droplet in das Verzeichnis, in dem Hadoop installiert ist:
cd ~/my-hadoop-install/hadoop-3.0.1/Führen Sie dann den folgenden Befehl aus, um HDFS zu formatieren:
sudo ./bin/hdfs namenode -formatEine erfolgreiche Formatierung des Namensknotens führt zu einer Menge Ausgabe, die hauptsächlich ausINFO-Anweisungen besteht. Unten sehen Sie Folgendes, um zu bestätigen, dass Sie das Speicherverzeichnis erfolgreich formatiert haben.
Output...
2018-01-28 17:58:08,323 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/data has been successfully formatted.
2018-01-28 17:58:08,346 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 using no compression
2018-01-28 17:58:08,490 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds.
2018-01-28 17:58:08,505 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-01-28 17:58:08,519 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-example-node/127.0.1.1
************************************************************/Starten Sie nun den Hadoop-Cluster, indem Sie die folgenden Skripts ausführen (überprüfen Sie die Skripts, bevor Sie sie mit dem Befehllessausführen):
sudo ./sbin/start-dfs.shDaraufhin wird eine Ausgabe angezeigt, die Folgendes enthält:
OutputStarting namenodes on [hadoop-master-server-ip]
Starting datanodes
Starting secondary namenodes [hadoop-master]Führen Sie dann YARN mithilfe des folgenden Skripts aus:
./sbin/start-yarn.shDie folgende Ausgabe wird angezeigt:
OutputStarting resourcemanager
Starting nodemanagersSobald Sie diese Befehle ausgeführt haben, sollten auf dem Masterknoten und auf jedem Arbeitsknoten Dämonen ausgeführt werden.
Wir können die Dämonen überprüfen, indem wir den Befehljpsausführen, um nach Java-Prozessen zu suchen:
jpsNachdem Sie den Befehljps ausgeführt haben, sehen Sie, dassNodeManager,SecondaryNameNode,Jps,NameNode,ResourceManager undDataNode laufen. Es erscheint etwas Ähnliches wie die folgende Ausgabe:
Output9810 NodeManager
9252 SecondaryNameNode
10164 Jps
8920 NameNode
9674 ResourceManager
9051 DataNodeHiermit wird überprüft, ob ein Cluster erfolgreich erstellt wurde und ob die Hadoop-Dämonen ausgeführt werden.
In einem Webbrowser Ihrer Wahl können Sie sich einen Überblick über den Zustand Ihres Clusters verschaffen, indem Sie zu Folgendem navigieren:
http://hadoop-master-server-ip:9870Wenn Sie eine Firewall haben, müssen Sie unbedingt Port 9870 öffnen. Sie werden etwas sehen, das ungefähr so aussieht:
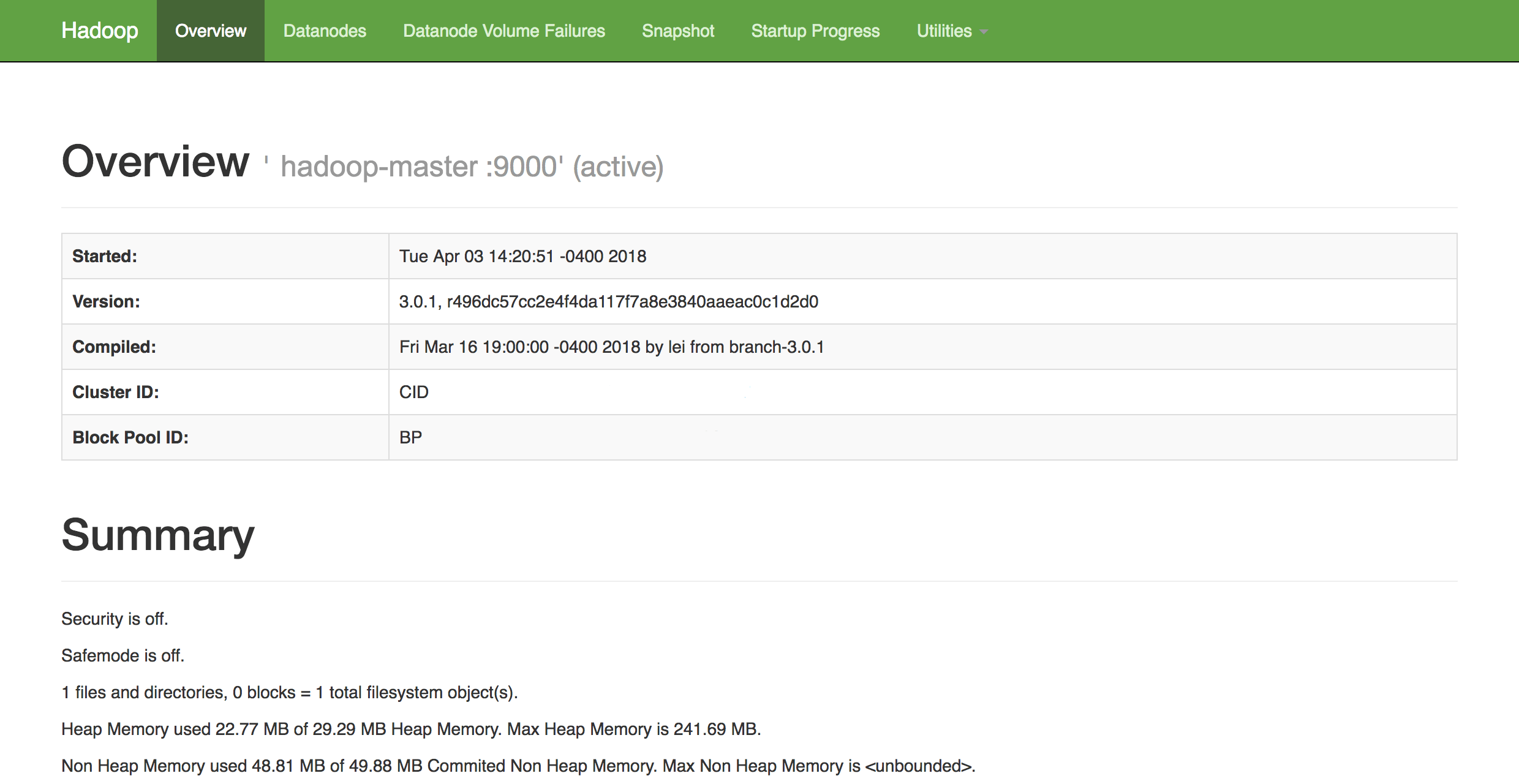
Von hier aus können Sie zum ElementDatanodes in der Menüleiste navigieren, um die Knotenaktivität anzuzeigen.
Fazit
In diesem Tutorial wurde erläutert, wie Sie einen Hadoop-Cluster mit mehreren Knoten mithilfe von DigitalOcean Ubuntu 16.04 Droplets einrichten und konfigurieren. Sie können den Zustand Ihres Clusters jetzt auch über die DFS-Integritäts-Weboberfläche von Hadoop überwachen und überprüfen.
Um eine Vorstellung von möglichen Projekten zu erhalten, an denen Sie arbeiten können, um Ihren neu konfigurierten Cluster zu verwenden, lesen Sie die lange Liste der Projektepowered by Hadoopvon Apache.