Ein Artikel von Prometheus Mitschöpfer Julius Volz
Einführung
Prometheus ist ein Open-Source-Überwachungssystem und eine Zeitreihendatenbank. Einer der wichtigsten Aspekte von Prometheus ist das mehrdimensionale Datenmodell zusammen mit der zugehörigen Abfragesprache. Mit dieser Abfragesprache können Sie Ihre Dimensionsdaten in Segmente aufteilen und aufteilen, um betriebliche Fragen ad-hoc zu beantworten, Trends in Dashboards anzuzeigen oder Warnungen zu Fehlern in Ihren Systemen zu generieren.
In diesem Tutorial lernen wir, wie man Prometheus 1.3.1 abfragt. Damit Sie mit passenden Beispieldaten arbeiten können, werden drei identische Demo-Service-Instanzen eingerichtet, die synthetische Metriken verschiedener Art exportieren. Wir werden dann einen Prometheus-Server einrichten, um diese Metriken zu durchsuchen und zu speichern. Anhand der Beispielmetriken lernen wir, wie man Prometheus abfragt, angefangen bei einfachen Abfragen bis hin zu fortgeschritteneren.
Nach diesem Lernprogramm erfahren Sie, wie Sie Zeitreihen anhand ihrer Dimensionen auswählen und filtern, Zeitreihen aggregieren und transformieren sowie zwischen verschiedenen Metriken arithmetisch arbeiten. In einem weiteren Tutorial finden Sie unter How To Query Prometheus on Ubuntu 14.04 Part 2 , bauen wir auf den Kenntnissen aus diesem Tutorial auf, um fortgeschrittenere Anwendungsfälle für das Abfragen zu behandeln.
Voraussetzungen
Um diesem Tutorial zu folgen, benötigen Sie:
-
Ein Ubuntu 14.04-Server, der gemäß https://www.digitalocean.com/community/tutorials/initial-server-setup-with-ubuntu-14-04 eingerichtet wurde, einschließlich eines Handbuchs zur Einrichtung des ersten Servers für Ubuntu 14.04], einschließlich eines sudo non -root Benutzer.
Schritt 1 - Prometheus installieren
In diesem Schritt werden wir einen Prometheus-Server herunterladen, konfigurieren und ausführen, um drei (noch nicht ausgeführte) Demo-Service-Instanzen zu sichern.
Laden Sie zuerst Prometheus herunter:
wget https://github.com/prometheus/prometheus/releases/download/v1.3.1/prometheus-1.3.1.linux-amd64.tar.gzExtrahieren Sie den Tarball:
tar xvfz prometheus-1.3.1.linux-amd64.tar.gzErstellen Sie eine minimale Prometheus-Konfigurationsdatei auf dem Host-Dateisystem unter + ~ / prometheus.yml +:
nano ~/prometheus.ymlFügen Sie der Datei den folgenden Inhalt hinzu:
~ / prometheus.yml
# Scrape the three demo service instances every 5 seconds.
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'demo'
static_configs:
- targets:
- 'localhost:8080'
- 'localhost:8081'
- 'localhost:8082'Speichern und beenden Sie Nano.
Diese Beispielkonfiguration bewirkt, dass Prometheus die Demo-Instanzen entfernt. Prometheus arbeitet mit einem Pull-Modell. Aus diesem Grund muss es konfiguriert werden, um die Endpunkte zu kennen, von denen Metriken abgerufen werden sollen. Die Demo-Instanzen werden noch nicht ausgeführt, aber später auf den Ports "+ 8080 ", " 8081 " und " 8082 +" ausgeführt.
Starten Sie Prometheus mit + nohup + und als Hintergrundprozess:
nohup ./prometheus-1.3.1.linux-amd64/prometheus -storage.local.memory-chunks=10000 &Das "+ nohup" am Anfang des Befehls sendet die Ausgabe an die Datei "+ ~ / nohup.out" anstelle von "+ stdout". Das "+ & " am Ende des Befehls ermöglicht es dem Prozess, im Hintergrund weiterzulaufen, während Sie aufgefordert werden, weitere Befehle einzugeben. Um den Prozess wieder in den Vordergrund zu bringen (d. H. Zum laufenden Prozess des Terminals), verwenden Sie den Befehl " fg +" am selben Terminal.
Wenn alles in Ordnung ist, sollten Sie in der Datei "+ ~ / nohup.out +" eine Ausgabe ähnlich der folgenden sehen:
Ausgabe vom Start von Prometheus
time="2016-11-23T03:10:33Z" level=info msg="Starting prometheus (version=1.3.1, branch=master, revision=be476954e80349cb7ec3ba6a3247cd712189dfcb)" source="main.go:75"
time="2016-11-23T03:10:33Z" level=info msg="Build context (go=go1.7.3, user=root@37f0aa346b26, date=20161104-20:24:03)" source="main.go:76"
time="2016-11-23T03:10:33Z" level=info msg="Loading configuration file prometheus.yml" source="main.go:247"
time="2016-11-23T03:10:33Z" level=info msg="Loading series map and head chunks..." source="storage.go:354"
time="2016-11-23T03:10:33Z" level=info msg="0 series loaded." source="storage.go:359"
time="2016-11-23T03:10:33Z" level=warning msg="No AlertManagers configured, not dispatching any alerts" source="notifier.go:176"
time="2016-11-23T03:10:33Z" level=info msg="Starting target manager..." source="targetmanager.go:76"
time="2016-11-23T03:10:33Z" level=info msg="Listening on :9090" source="web.go:240"In einem anderen Terminal können Sie den Inhalt dieser Datei mit dem Befehl + tail -f ~ / nohup.out + überwachen. Wenn Inhalte in die Datei geschrieben werden, werden sie auf dem Terminal angezeigt.
Standardmäßig lädt Prometheus seine Konfiguration aus der soeben erstellten Datei "+ prometheus.yml " und speichert die Metrikdaten in ". / Data +" im aktuellen Arbeitsverzeichnis.
Das Flag "+ -storage.local.memory-chunks +" passt die Speichernutzung von Prometheus an die sehr geringe RAM-Größe (nur 512 MB) und die geringe Anzahl gespeicherter Zeitreihen in diesem Lernprogramm an.
Sie sollten jetzt in der Lage sein, Ihren Prometheus-Server unter + http: //: 9090 / + zu erreichen. Stellen Sie sicher, dass es so konfiguriert ist, dass Messdaten aus den drei Demo-Instanzen erfasst werden, indem Sie auf "+ http: //: 9090 / status " gehen und die drei Zielendpunkte für den " Demo +" - Job im Abschnitt "Ziele" suchen. Die Spalte * State * für alle drei Ziele sollte den Status des Ziels als * DOWN * anzeigen, da die Demo-Instanzen noch nicht gestartet wurden und daher nicht gelöscht werden können:
image: https: //assets.digitalocean.com/articles/prometheus_querying/demo.png [Die Demo-Instanzen sollten als DOWN angezeigt werden.]
Schritt 2 - Installieren der Demo-Instanzen
In diesem Abschnitt werden die drei Demo-Service-Instanzen installiert und ausgeführt.
Laden Sie den Demo-Service herunter:
wget https://github.com/juliusv/prometheus_demo_service/releases/download/0.0.4/prometheus_demo_service-0.0.4.linux-amd64.tar.gzExtrahiere es:
tar xvfz prometheus_demo_service-0.0.4.linux-amd64.tar.gzFühren Sie den Demo-Service dreimal an verschiedenen Ports aus:
./prometheus_demo_service -listen-address=:8080 &
./prometheus_demo_service -listen-address=:8081 &
./prometheus_demo_service -listen-address=:8082 &Das + & + startet die Demo-Dienste im Hintergrund. Sie werden nichts protokollieren, aber Prometheus-Metriken auf dem HTTP-Endpunkt "+ / metrics +" an ihren jeweiligen Ports verfügbar machen.
Diese Demo-Services exportieren synthetische Metriken über mehrere simulierte Subsysteme. Diese sind:
-
Ein HTTP-API-Server, der Anforderungszählungen und Latenzen offenlegt (durch Pfad, Methode und Antwortstatuscode verschlüsselt)
-
Ein periodischer Stapeljob, der den Zeitstempel seiner letzten erfolgreichen Ausführung und die Anzahl der verarbeiteten Bytes anzeigt
-
Synthetische Metriken zur Anzahl der CPUs und deren Verwendung
-
Synthetische Metriken über die Gesamtgröße einer Festplatte und ihre Verwendung
Die einzelnen Metriken werden in den Abfragebeispielen in späteren Abschnitten vorgestellt.
Der Prometheus-Server sollte nun automatisch mit dem Scraping Ihrer drei Demo-Instanzen beginnen. Gehen Sie zur Statusseite Ihres Prometheus-Servers unter "+ http: //: 9090 / status " und überprüfen Sie, ob die Ziele für den " demo +" - Auftrag jetzt den Status "UP" aufweisen:
image: https: //assets.digitalocean.com/articles/prometheus_querying/demo_up.png [Die Demo-Ziele sollten als UP angezeigt werden.]
Schritt 3 - Verwenden des Abfragebrowsers
In diesem Schritt werden wir uns mit der integrierten Abfrage- und Grafik-Weboberfläche von Prometheus vertraut machen. Diese Benutzeroberfläche eignet sich hervorragend für die Ad-hoc-Untersuchung von Daten und das Erlernen der Abfragesprache von Prometheus. Sie eignet sich jedoch nicht zum Erstellen persistenter Dashboards und unterstützt keine erweiterten Visualisierungsfunktionen. Informationen zum Erstellen von Dashboards finden Sie im Beispiel How To Add a Prometheus Dashboard to Grafana.
Gehen Sie auf Ihrem Prometheus-Server zu "+ http: //: 9090 / graph +". Es sollte so aussehen:
image: https://assets.digitalocean.com/articles/prometheus_querying/interface.png [Prometheus Abfrage- und Grafikoberfläche]
{kind=link}
Wie Sie sehen, gibt es zwei Registerkarten: * Graph * und * Console *. Mit Prometheus können Sie Daten in zwei verschiedenen Modi abfragen:
-
Auf der Registerkarte * Konsole * können Sie einen Abfrageausdruck zum aktuellen Zeitpunkt auswerten. Nach dem Ausführen der Abfrage wird in einer Tabelle der aktuelle Wert jeder Ergebniszeitreihe angezeigt (eine Tabellenzeile pro Ausgabeserie).
-
Auf der Registerkarte * Graph * können Sie einen Abfrageausdruck über einen bestimmten Zeitraum grafisch darstellen.
Da Prometheus auf Millionen von Zeitreihen skalieren kann, ist es möglich, sehr teure Abfragen zu erstellen (dies ähnelt dem Auswählen aller Zeilen aus einer großen Tabelle in einer SQL-Datenbank). Um zu vermeiden, dass bei Abfragen eine Zeitüberschreitung auftritt oder der Server überlastet wird, wird empfohlen, zunächst Abfragen in der Ansicht "Konsole" zu durchsuchen und zu erstellen, anstatt sie sofort grafisch darzustellen. Das Auswerten einer potenziell kostspieligen Abfrage zu einem bestimmten Zeitpunkt erfordert weitaus weniger Ressourcen als der Versuch, dieselbe Abfrage über einen bestimmten Zeitraum hinweg grafisch darzustellen.
Sobald Sie eine Abfrage ausreichend eingegrenzt haben (in Bezug auf die zum Laden ausgewählten Reihen, die durchzuführenden Berechnungen und die Anzahl der Ausgabezeitreihen), können Sie zur Registerkarte * Graph * wechseln, um den ausgewerteten Ausdruck über die Zeit anzuzeigen . Zu wissen, wann eine Abfrage kostengünstig genug ist, um grafisch dargestellt zu werden, ist keine exakte Wissenschaft und hängt von Ihren Daten, Ihren Latenzanforderungen und der Leistung des Computers ab, auf dem Sie Ihren Prometheus-Server ausführen. Sie werden mit der Zeit ein Gefühl dafür bekommen.
Da unser Test-Prometheus-Server nicht viele Daten kratzt, können wir in diesem Lernprogramm keine kostspieligen Abfragen formulieren. Beispielabfragen können sowohl in der * Grafik * als auch in der * Konsole * ohne Risiko angezeigt werden.
Klicken Sie auf die Schaltflächen * - * oder * + *, um den Grafikzeitbereich zu verkleinern oder zu vergrößern. Um die Endzeit der Grafik zu verschieben, drücken Sie die Tasten * << * oder * >> *. Sie können ein Diagramm stapeln, indem Sie das Kontrollkästchen * gestapelt * aktivieren. Schließlich wird die * Res. (s) * Mit der Eingabe können Sie eine benutzerdefinierte Abfrageauflösung angeben (in diesem Lernprogramm nicht erforderlich).
Schritt 4 - Durchführen einfacher Zeitreihenabfragen
Bevor wir mit der Abfrage beginnen, lassen Sie uns das Prometheus-Datenmodell und die Terminologie kurz überprüfen. Prometheus speichert grundsätzlich alle Daten als Zeitreihen. Jede Zeitreihe wird durch einen Metriknamen sowie eine Reihe von Schlüssel-Wert-Paaren identifiziert, die Prometheus labels nennt. Der Metrikname gibt den Gesamtaspekt eines zu messenden Systems an (z. B. die Anzahl der seit dem Prozessstart verarbeiteten HTTP-Anforderungen, + http_requests_total +). Beschriftungen dienen zur Unterscheidung von Unterdimensionen einer Metrik wie der HTTP-Methode (z. "+ method =" POST "") oder der Pfad (z. ` path =" / api / foo "+`). Schließlich bildet eine Folge von Stichproben die eigentlichen Daten für eine Serie. Jedes Sample besteht aus einem Zeitstempel und einem Wert, wobei Zeitstempel eine Millisekundengenauigkeit aufweisen und die Werte immer 64-Bit-Gleitkommawerte sind.
Die einfachste Abfrage, die wir formulieren können, gibt alle Reihen zurück, die einen bestimmten Metriknamen haben. Beispielsweise exportiert der Demo-Service eine Metrik "+ demo_api_request_duration_seconds_count ", die die Anzahl der vom Dummy-Service verarbeiteten synthetischen API-HTTP-Anforderungen darstellt. Sie fragen sich vielleicht, warum der Metrikname die Zeichenfolge " duration_seconds " enthält. Dies liegt daran, dass dieser Leistungsindikator Teil einer größeren Histogrammmetrik mit dem Namen " demo_api_request_duration_seconds " ist, die in erster Linie eine Verteilung der Anforderungsdauern verfolgt, aber auch die Gesamtanzahl der verfolgten Anforderungen (hier mit dem Zusatz " _count +" versehen) als nützliches Nebenprodukt anzeigt.
Stellen Sie sicher, dass die Registerkarte * Konsole * ausgewählt ist, geben Sie die folgende Abfrage in das Textfeld oben auf der Seite ein und klicken Sie auf die Schaltfläche * Ausführen *, um die Abfrage auszuführen:
demo_api_request_duration_seconds_countDa Prometheus drei Dienstinstanzen überwacht, sollte eine tabellarische Ausgabe mit 27 resultierenden Zeitreihen mit diesem Metriknamen angezeigt werden, eine für jede nachverfolgte Dienstinstanz, Pfad, HTTP-Methode und HTTP-Statuscode. Neben den von den Dienstinstanzen selbst festgelegten Bezeichnungen ("+ method", "+ path" und "+ status") enthält die Serie die entsprechenden "+ job" - und "+ instance +" - Bezeichnungen, mit denen die verschiedenen Dienstinstanzen voneinander unterschieden werden . Prometheus bringt diese Etiketten automatisch an, wenn Zeitreihen von abgekratzten Zielen gespeichert werden. Die Ausgabe sollte folgendermaßen aussehen:
image: https://assets.digitalocean.com/articles/prometheus_querying/api_requests.png [API-Anforderung zählt als tabellarische Ausgabe]
{kind=link}
Der in der rechten Tabellenspalte angezeigte numerische Wert ist der aktuelle Wert jeder Zeitreihe. Sie können die Ausgabe grafisch darstellen (klicken Sie auf die Registerkarte * Graph * und anschließend erneut auf * Execute *), um zu sehen, wie sich die Werte im Laufe der Zeit entwickeln.
Wir können jetzt Label Matcher hinzufügen, um die zurückgegebenen Serien basierend auf ihren Labels einzuschränken. Label Matcher folgen direkt dem Metriknamen in geschweiften Klammern. In der einfachsten Form filtern sie nach Serien, die für ein bestimmtes Etikett einen genauen Wert haben. Diese Abfrage zeigt beispielsweise nur die Anzahl der Anfragen für alle "+ GET +" - Anfragen an:
demo_api_request_duration_seconds_count{method="GET"}Matcher können mit Kommas kombiniert werden. Zum Beispiel könnten wir zusätzlich nur nach Metriken filtern, die aus der Instanz "+ localhost: 8080 " und dem Job " demo +" stammen:
demo_api_request_duration_seconds_count{instance="localhost:8080",method="GET",job="demo"}Das Ergebnis sieht dann so aus:
image: https://assets.digitalocean.com/articles/prometheus_querying/api_filtered.png [Gefilterte API-Anforderung zählt als tabellarische Ausgabe]
{kind=link}
Wenn Sie mehrere Matcher kombinieren, müssen alle übereinstimmen, um eine Serie auszuwählen. Der obige Ausdruck gibt nur die Anzahl der API-Anforderungen für die Dienstinstanz zurück, die auf Port 8080 ausgeführt wird und bei der die HTTP-Methode "+ GET " lautete. Wir stellen außerdem sicher, dass wir nur Metriken auswählen, die zum Job " demo +" gehören.
Prometheus unterstützt neben Gleichheitsübereinstimmungen auch Nichtgleichheitsübereinstimmungen (+! = +), Übereinstimmungen mit regulären Ausdrücken (+ = ~ +) sowie Übereinstimmungen mit negativen regulären Ausdrücken (+! ~ +). Es ist auch möglich, den Metriknamen vollständig wegzulassen und nur mit Label-Matchern abzufragen. Um beispielsweise alle Serien (unabhängig von Metrikname oder Job) aufzulisten, bei denen die Bezeichnung "+ path " mit " / api +" beginnt, können Sie diese Abfrage ausführen:
{path=~"/api.*"}Der obige reguläre Ausdruck muss mit "+. * +" Enden, da reguläre Ausdrücke in Prometheus immer mit einer vollständigen Zeichenfolge übereinstimmen.
Die resultierende Zeitreihe ist eine Mischung aus Reihen mit verschiedenen Metriknamen:
image: https: //assets.digitalocean.com/articles/prometheus_querying/regex_matched.png [Regex-Matched-Serie als tabellarische Ausgabe]
Sie können jetzt Zeitreihen anhand ihrer Metriknamen sowie anhand einer Kombination ihrer Beschriftungswerte auswählen.
Schritt 5 - Berechnung von Kursen und anderen Derivaten
In diesem Abschnitt erfahren Sie, wie Sie Raten oder Deltas einer Metrik über die Zeit berechnen.
Eine der häufigsten Funktionen, die Sie in Prometheus verwenden, ist "+ rate () ". Anstatt Ereignisraten direkt im instrumentierten Dienst zu berechnen, ist es in Prometheus üblich, Ereignisse mithilfe von unformatierten Zählern zu verfolgen und den Prometheus-Server die Rate während der Abfragezeit ad-hoc berechnen zu lassen (dies hat eine Reihe von Vorteilen, z. B. den Verlust von Geschwindigkeitsspitzen zwischen Kratzern sowie in der Lage zu sein, dynamische Mittelungsfenster zur Abfragezeit zu wählen). Die Zähler beginnen bei " 0 ", wenn ein überwachter Dienst gestartet wird, und werden über die Lebensdauer des Dienstprozesses kontinuierlich erhöht. Wenn ein überwachter Prozess neu gestartet wird, werden seine Zähler gelegentlich auf " 0 +" zurückgesetzt und beginnen von dort aus erneut zu klettern. Das Zeichnen von Rohdaten-Zählern ist normalerweise nicht sehr nützlich, da Sie nur eine ständig wachsende Linie mit gelegentlichen Zurücksetzungen sehen. Sie können dies sehen, indem Sie die Anzahl der API-Anforderungen des Demo-Service grafisch darstellen:
demo_api_request_duration_seconds_count{job="demo"}Es wird ungefähr so aussehen:
image: https: //assets.digitalocean.com/articles/prometheus_querying/raw_counters.png [Grafische Darstellung von Rohzählern]
Um Zähler nützlich zu machen, können wir die Funktion + rate () + verwenden, um die Steigerungsrate pro Sekunde_ zu berechnen. Wir müssen "+ rate () " angeben, über welches Zeitfenster die Rate gemittelt werden soll, indem wir nach dem Serien-Matcher einen Range-Selector bereitstellen (wie " [5m] +"). Um beispielsweise den Anstieg der obigen Indikatormetrik pro Sekunde zu berechnen, der in den letzten fünf Minuten gemittelt wurde, stellen Sie die folgende Abfrage grafisch dar:
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])Das Ergebnis ist jetzt viel nützlicher:
image: https://assets.digitalocean.com/articles/prometheus_querying/graphing_rates.png [Grafische Darstellung der Zählerraten]
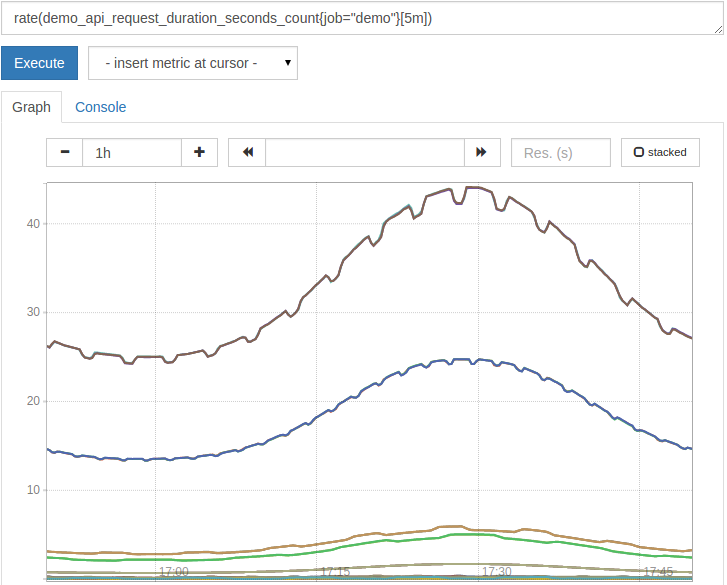{kind=link}
+ rate () + ist intelligent und passt sich automatisch an Zählerrücksetzungen an, indem angenommen wird, dass jede Verringerung eines Zählerwerts eine Rücksetzung ist.
Eine Variante von "+ rate () " ist " irate () ". Während ` rate () ` die Rate über alle Samples im angegebenen Zeitfenster (in diesem Fall fünf Minuten) mittelt, blickt ` irate () ` immer nur zwei Samples in die Vergangenheit zurück. Es ist weiterhin erforderlich, ein Zeitfenster (wie z. B. " [5m] ") anzugeben, um zu wissen, wie weit die Zeit für diese beiden Stichproben maximal zurückverfolgt werden kann. ` irate () ` reagiert schneller auf Geschwindigkeitsänderungen und wird daher normalerweise für die Verwendung in Diagrammen empfohlen. Im Gegensatz dazu liefert " rate () +" weichere Raten und wird zur Verwendung bei Alarmierungsausdrücken empfohlen (da kurze Ratenspitzen gedämpft werden und Sie nachts nicht aufwecken).
Mit + irate () + würde das obige Diagramm so aussehen und kurze zeitweilige Einbrüche in den Anforderungsraten aufdecken:
image: https://assets.digitalocean.com/articles/prometheus_querying/graphing_instant.png [Grafische Darstellung der augenblicklichen Zählerraten]
{kind=link}
+ rate () + und + irate () + berechnen immer eine per-second rate. Manchmal möchten Sie den Gesamtbetrag wissen, um den sich ein Zähler über ein Zeitfenster erhöht hat, der jedoch für das Zurücksetzen des Zählers noch korrekt ist. Dies erreichen Sie mit der Funktion + raise () +. Um beispielsweise die Gesamtzahl der in der letzten Stunde bearbeiteten Anforderungen zu berechnen, fragen Sie nach:
increase(demo_api_request_duration_seconds_count{job="demo"}[1h])Neben Zählern (die nur erhöht werden können) gibt es Messgrößen. Anzeigen sind Werte, die mit der Zeit steigen oder fallen können, z. B. die Temperatur oder der freie Speicherplatz. Wenn wir Änderungen der Anzeigen über die Zeit berechnen möchten, können wir die Funktionsfamilie + rate () + / + irate () + / + raise () + nicht verwenden. Diese sind alle auf Zähler ausgerichtet, da sie jede Abnahme des Metrikwerts als Zählerrücksetzung interpretieren und kompensieren. Stattdessen können wir die Funktion + deriv () + verwenden, die die sekundengenaue Ableitung des Messgeräts basierend auf der linearen Regression berechnet.
Um beispielsweise zu sehen, wie schnell die von unserem Demo-Service exportierte Nutzung fiktiver Festplatten (in MB pro Sekunde) aufgrund einer linearen Regression der letzten 15 Minuten zunimmt oder abnimmt, können wir Folgendes abfragen:
deriv(demo_disk_usage_bytes{job="demo"}[15m])Das Ergebnis sollte so aussehen:
image: https://assets.digitalocean.com/articles/prometheus_querying/disk_usage.png [Darstellung der Ableitung der Festplattennutzung]
{kind=link}
Weitere Informationen zum Berechnen von Deltas und Trends in Messgeräten finden Sie unter http://prometheus.io/docs/querying/functions/#delta [+ delta () +] und http://prometheus.io/docs/ query / functions / # predict_linear [+ predict_linear () +] Funktionen.
Wir wissen jetzt, wie man sekundengenaue Raten mit unterschiedlichem Durchschnittsverhalten berechnet, wie Zählerrücksetzungen in Ratenberechnungen behandelt und wie man Ableitungen für Messgeräte berechnet.
Schritt 6 - Aggregation über Zeitreihen
In diesem Abschnitt lernen wir, wie man über einzelne Serien aggregiert.
Prometheus sammelt Daten mit hohen dimensionalen Details, was zu vielen Reihen für jeden Metriknamen führen kann. Häufig interessieren Sie sich jedoch nicht für alle Dimensionen, und es können sogar zu viele Reihen vorhanden sein, um alle auf vernünftige Weise gleichzeitig grafisch darzustellen. Die Lösung besteht darin, einige Dimensionen zu aggregieren und nur die zu erhalten, die Sie interessieren. Beispielsweise verfolgt der Demo-Service die API-HTTP-Anforderungen nach "+ Methode ", " Pfad " und " Status ". Prometheus fügt dieser Metrik weitere Dimensionen hinzu, wenn sie aus dem Node Exporter entfernt wird: die Bezeichnungen " instance " und " job ", die protokollieren, von welchem Prozess die Metriken stammen. Um nun die gesamte Anforderungsrate über alle Dimensionen zu sehen, können wir den Aggregationsoperator ` sum () +` verwenden:
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))Dies aggregiert jedoch über alle Dimensionen und erstellt eine einzelne Ausgabeserie:
image: https://assets.digitalocean.com/articles/prometheus_querying/summing.png [Summierung über alle Dimensionen der Anfragerate]
{kind=link}
In der Regel möchten Sie jedoch einige der Dimensionen in der Ausgabe beibehalten. Dazu unterstützen + sum () + und andere Aggregatoren eine Klausel + without (<label names>) +, die die Dimensionen angibt, über die aggregiert werden soll. Gegenüber der Klausel + by (<label names>) + gibt es auch eine Alternative, mit der Sie angeben können, welche Labelnamen beibehalten werden sollen. Wenn wir die gesamte Anforderungsrate wissen möchten, die über alle drei Dienstinstanzen und alle Pfade summiert wurde, aber das Ergebnis nach Methode und Statuscode aufteilen möchten, können wir Folgendes abfragen:
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))Dies ist äquivalent zu:
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))Die resultierende Summe ist jetzt gruppiert nach + Instanz +, + Pfad + und + Job +:
image: https://assets.digitalocean.com/articles/prometheus_querying/preserving.png [Einige Dimensionen beim Summieren beibehalten]
{kind=link}
Prometheus unterstützt die folgenden Aggregationsoperatoren, die jeweils eine Klausel + by () + oder + without () + unterstützen, um auszuwählen, welche Dimensionen beibehalten werden sollen:
-
+ sum +: summiert alle Werte innerhalb einer aggregierten Gruppe. -
+ min +: Wählt das Minimum aller Werte innerhalb einer aggregierten Gruppe aus. -
+ max +: Wählt das Maximum aller Werte innerhalb einer aggregierten Gruppe aus. -
+ avg +: berechnet den Durchschnitt (arithmetisches Mittel) aller Werte innerhalb einer aggregierten Gruppe. -
+ stddev +: berechnet die Standardabweichung aller Werte innerhalb einer aggregierten Gruppe. -
+ stdvar +: berechnet die standard varianz aller Werte innerhalb einer aggregierten Gruppe. -
+ count +: berechnet die Gesamtzahl der Reihen innerhalb einer aggregierten Gruppe.
Sie haben jetzt gelernt, wie Sie eine Liste von Serien zusammenfassen und nur die Dimensionen beibehalten, die Sie interessieren.
Schritt 7 - Durchführen von Arithmetik
In diesem Abschnitt lernen wir, wie man in Prometheus rechnet.
Als einfachstes Rechenbeispiel können Sie Prometheus als numerischen Taschenrechner verwenden. Führen Sie beispielsweise die folgende Abfrage in der Ansicht * Console * aus:
(4 + 7) * 3Sie erhalten einen einzelnen skalaren Ausgabewert von + 33 +:
image: https://assets.digitalocean.com/articles/prometheus_querying/scalar.png [Skalararithmetisches Ergebnis]
{kind=link}
Ein Skalarwert ist ein einfacher numerischer Wert ohne Beschriftungen. Um dies nützlicher zu machen, können Sie in Prometheus allgemeine arithmetische Operatoren (+, + - +, + * +, + / +, +% +) auf ganze Zeitreihenvektoren anwenden . Die folgende Abfrage konvertiert beispielsweise die Anzahl der von einem simulierten letzten Batch-Job verarbeiteten Bytes in MiB:
demo_batch_last_run_processed_bytes{job="demo"} / 1024 / 1024Das Ergebnis wird in MiB angezeigt:
image: https: //assets.digitalocean.com/articles/prometheus_querying/mib.png [MiB-konvertierte verarbeitete Bytes]
Es ist üblich, einfache Arithmetik für diese Arten von Einheitenumrechnungen zu verwenden, obwohl gute Visualisierungstools (wie Grafana) auch Konvertierungen für Sie durchführen.
Eine Spezialität von Prometheus (und wo Prometheus wirklich glänzt!) Ist die binäre Arithmetik zwischen zwei Zeitreihen. Wenn Sie einen binären Operator zwischen zwei Serien verwenden, vergleicht Prometheus Elemente mit identischen Beschriftungssätzen auf der linken und rechten Seite der Operation automatisch und wendet den Operator auf jedes passende Paar an, um die Ausgabeserie zu erstellen.
Beispielsweise gibt die Metrik "+ demo_api_request_duration_seconds_sum " an, wie viele Sekunden für die Beantwortung von HTTP-Anforderungen aufgewendet wurden, während " demo_api_request_duration_seconds_count " angibt, wie viele HTTP-Anforderungen vorhanden waren. Beide Metriken haben die gleichen Dimensionen (` Methode n`,` + Pfad + , + Status`, + Instanz,` + Job`). Um die durchschnittliche Anforderungslatenz für jede dieser Dimensionen zu berechnen, können Sie einfach das Verhältnis der in Anforderungen aufgewendeten Gesamtzeit geteilt durch die Gesamtzahl der Anforderungen abfragen.
rate(demo_api_request_duration_seconds_sum{job="demo"}[5m])
/
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])Beachten Sie, dass wir auch eine "+ rate () +" - Funktion um jede Seite der Operation wickeln, um nur die Latenz für Anforderungen zu berücksichtigen, die in den letzten 5 Minuten aufgetreten sind. Dies erhöht auch die Ausfallsicherheit gegen Zurücksetzen des Zählers.
Das resultierende Diagramm für die durchschnittliche Anforderungslatenz sollte folgendermaßen aussehen:
image: https://assets.digitalocean.com/articles/prometheus_querying/average_latency.png [Grafische Darstellung der durchschnittlichen Anforderungslatenz]
{kind=link}
Aber was tun wir, wenn die Etiketten auf beiden Seiten nicht genau übereinstimmen? Dies ist insbesondere dann der Fall, wenn auf beiden Seiten des Vorgangs Zeitreihen unterschiedlicher Größe vorliegen, da eine Seite mehr Dimensionen aufweist als die andere. Beispielsweise exportiert der Demo-Job die fiktive CPU-Zeit, die in verschiedenen Modi ("+ Leerlauf", "+ Benutzer", "+ System") verbracht wurde, als Metrik "+ demo_cpu_usage_seconds_total " mit der Etikettendimension " mode ". Es exportiert auch eine fiktive Gesamtanzahl von CPUs als " demo_num_cpus +" (keine zusätzlichen Dimensionen für diese Metrik). Wenn Sie versuchen, eine durch die andere zu teilen, um die durchschnittliche CPU-Auslastung in Prozent für jeden der drei Modi zu ermitteln, wird bei der Abfrage keine Ausgabe generiert:
# BAD!
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/
demo_num_cpus{job="demo"}Bei diesen Eins-zu-Viele- oder Viele-zu-Eins-Übereinstimmungen müssen wir Prometheus mitteilen, welche Teilmenge der Bezeichnungen für die Übereinstimmung verwendet werden soll, und wir müssen auch angeben, wie mit der zusätzlichen Dimensionalität umgegangen werden soll. Um die Übereinstimmung zu lösen, fügen wir dem binären Operator eine Klausel + on (<label names>) + hinzu, die die zu vergleichenden Bezeichnungen angibt. Um die Berechnung nach den einzelnen Werten der zusätzlichen Dimensionen auf der größeren Seite aufzufächern und zu gruppieren, fügen wir eine Klausel + group_left (<label names>) + oder + group_right (<label names>) + hinzu, in der die zusätzliche Maße auf der linken bzw. rechten Seite.
Die richtige Abfrage in diesem Fall wäre:
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/ on(job, instance) group_left(mode)
demo_num_cpus{job="demo"}Das Ergebnis sollte so aussehen:
image: https://assets.digitalocean.com/articles/prometheus_querying/average_cpu.png [Darstellung der durchschnittlichen CPU-Auslastung pro Modus]
{kind=link}
Das "+ on (job, instance) " weist den Operator an, nur Serien von links und rechts auf seinen " job " - und " instance " -Labels abzugleichen (und somit nicht auf dem " mode " - Label, was nicht der Fall ist existieren auf der rechten Seite), während die Klausel ` group_left (mode) ` den Bediener anweist, die CPU-Auslastung pro Modus zu verringern und anzuzeigen. Hierbei handelt es sich um eine Eins-zu-Eins-Übereinstimmung. Um den umgekehrten (Eins-zu-Viele-) Abgleich durchzuführen, verwenden Sie auf die gleiche Weise eine Klausel ` group_right (<label names>) +`.
Sie wissen jetzt, wie Sie zwischen Zeitreihen arithmetisch vorgehen und wie Sie mit unterschiedlichen Dimensionen umgehen.
Fazit
In diesem Tutorial haben wir eine Gruppe von Demo-Service-Instanzen eingerichtet und diese mit Prometheus überwacht. Anschließend haben wir gelernt, wie verschiedene Abfragetechniken auf die gesammelten Daten angewendet werden, um uns interessierende Fragen zu beantworten. Sie wissen jetzt, wie Sie Reihen auswählen und filtern, über Dimensionen aggregieren sowie Raten oder Ableitungen berechnen oder arithmetisch arbeiten. Sie haben auch gelernt, wie Sie mit der Erstellung von Abfragen im Allgemeinen umgehen und eine Überlastung Ihres Prometheus-Servers vermeiden.
Weitere Informationen zur Abfragesprache von Prometheus, beispielsweise zum Berechnen von Perzentilen aus Histogrammen, zum Umgang mit auf Zeitstempeln basierenden Metriken oder zum Abfragen des Zustands von Dienstinstanzen, finden Sie unter https://www.digitalocean.com/community/. Tutorials / Abfrage von Prometheus auf Ubuntu-14-04-Teil-2 [Abfrage von Prometheus auf Ubuntu 14.04 Teil 2].